微服务 分片 运维管理
微服务 分片 运维管理
- 分片
- 分片的概念
- 分片案例环境搭建
- 案例改造成任务分片
- Dataflow类型调度
- 代码示例
- 运维管理
- 事件追踪
- 运维平台
- 搭建步骤
- 使用步骤
分片
分片的概念
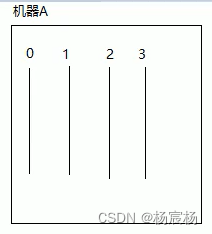
当只有一台机器的情况下,给定时任务分片四个,在机器A启动四个线程,分别处理四个分片的内容
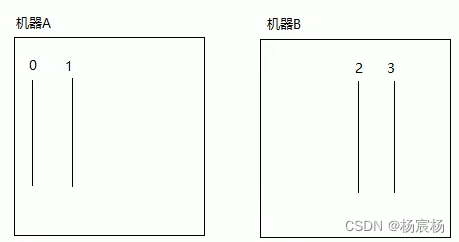
当有两台机器的情况下,分片由两个机器进行分配,机器A负责索引为0,1分片内容,机器B负责2,3分片内容
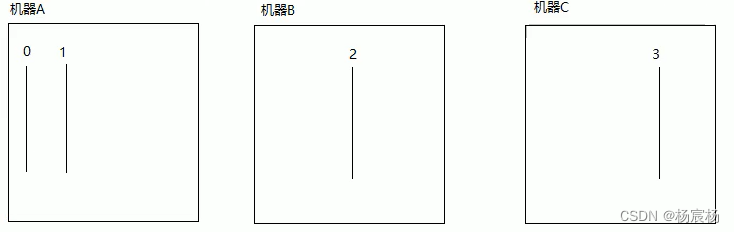
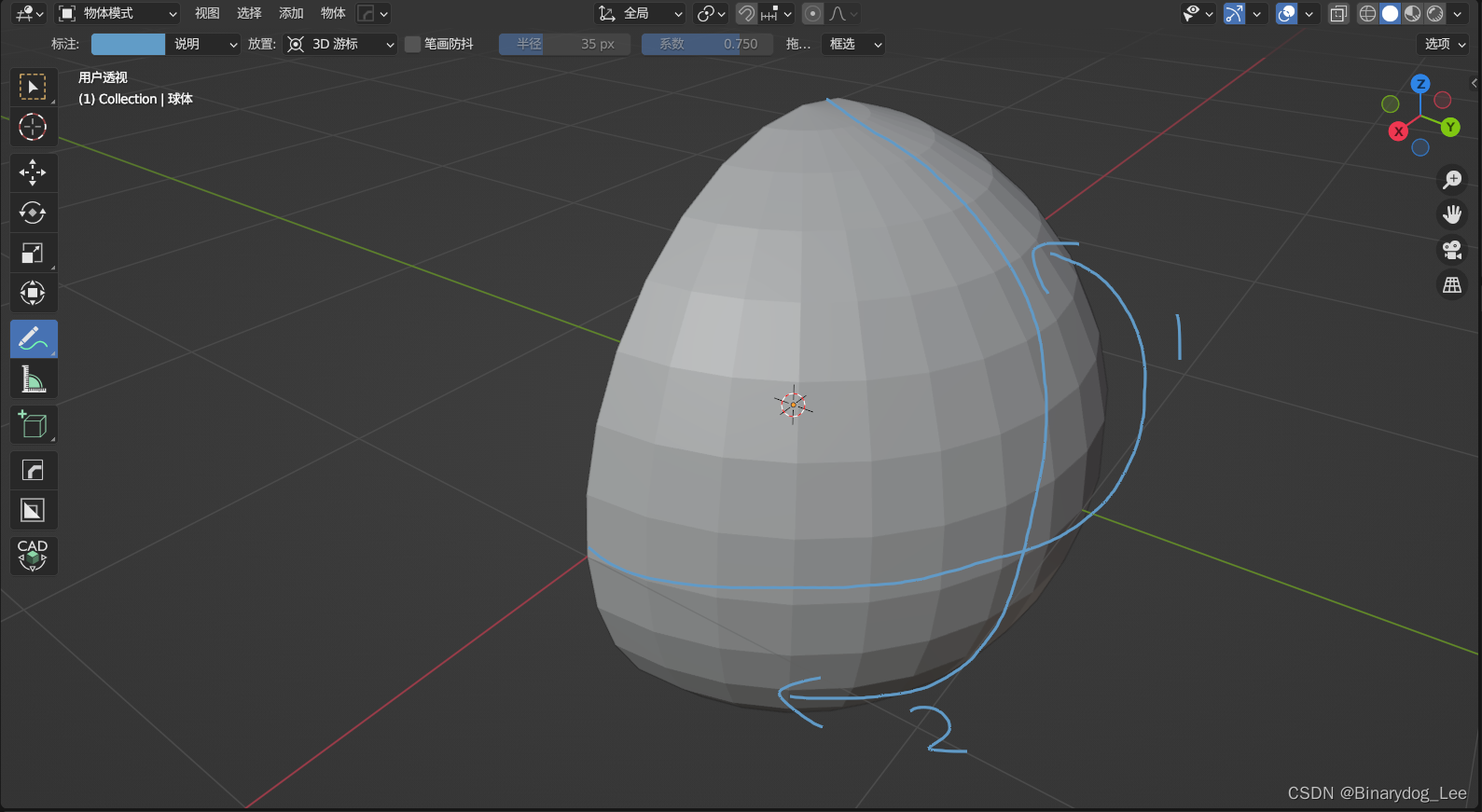
当有三台机器的时候,情况如图所示
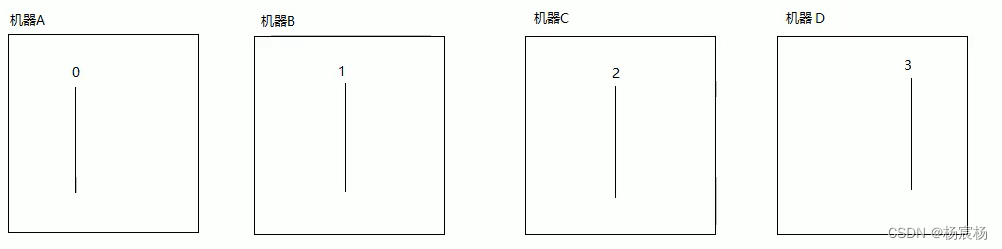
当有四台机器的时候
当有五台机器的时候

当分片消耗资源少的时候,第一种情况和第二种情况没有太大区别,反之,如果消耗资源很大的时候,CPU的利用率效率会降低
分片数建议服务器个数倍数
分片案例环境搭建
案例需求
数据库中有一些列的数据,需要对这些数据进行备份操作,备份完之后,修改数据的状态,标记已经备份了
第一步:添加依赖
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.10</version>
</dependency>
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>1.2.0</version>
</dependency>
<!--mysql驱动-->
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId>
</dependency>
第二步:添加配置
spring:datasource:url: jdbc:mysql://localhost:3306/elastic-job-demo?serverTimezone=GMT%2B8driverClassName: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSourceusername: rootpassword: 2022
第三步:添加实体类
@Datapublic class FileCustom {//唯⼀标识private Long id;//⽂件名private String name;//⽂件类型private String type;//⽂件内容private String content;//是否已备份private Boolean backedUp = false;public FileCustom(){}public FileCustom(Long id, String name, String type, String content){this.id = id;this.name = name;this.type = type;this.content = content;}}
第四步:添加任务类
@Autowiredprivate FileCustomMapper fileCustomMapper;@Overridepublic void execute(ShardingContext shardingContext) {doWork();}private void doWork() {//查询出所有的备份任务List<FileCustom> fileCustoms = fileCustomMapper.selectAll();for (FileCustom custom:fileCustoms){backUp(custom);}}private void backUp(FileCustom custom){System.out.println("备份的方法名:"+custom.getName()+"备份的类型:"+custom.getType());System.out.println("=======================");//模拟进行备份操作try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}fileCustomMapper.changeState(custom.getId(),1);}}
第五步: 添加任务调度配置
@Bean(initMethod = "init")public SpringJobScheduler fileScheduler(FileCustomElasticjob job, CoordinatorRegistryCenter registryCenter){LiteJobConfiguration jobConfiguration = createJobConfiguration(job.getClass(),"0/5 * * * * ?",1);return new SpringJobScheduler(job,registryCenter,jobConfiguration);}
案例改造成任务分片
第一步:修改任务配置类
@Configurationpublic class JobConfig {@Beanpublic static CoordinatorRegistryCenter registryCenter(@Value("${zookeeper.url}") String url, @Value("${zookeeper.groupName}") String groupName) {ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(url, groupName);//设置节点超时时间zookeeperConfiguration.setSessionTimeoutMilliseconds(100);//zookeeperConfiguration("zookeeper地址","项目名")CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);regCenter.init();return regCenter;}//功能的方法private static LiteJobConfiguration createJobConfiguration(Class clazz, String corn, int shardingCount,String shardingParam) {JobCoreConfiguration.Builder jobBuilder = JobCoreConfiguration.newBuilder(clazz.getSimpleName(), corn, shardingCount);if(!StringUtils.isEmpty(shardingParam)){jobBuilder.shardingItemParameters(shardingParam);}//定义作业核心配置newBuilder("任务名称","corn表达式","分片数量")JobCoreConfiguration simpleCoreConfig = jobBuilder.build();// 定义SIMPLE类型配置 cn.wolfcode.MyElasticJobSystem.out.println("MyElasticJob.class.getCanonicalName---->"+ MyElasticJob.class.getCanonicalName());SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig,clazz.getCanonicalName());//定义Lite作业根配置LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).overwrite(true).build();return simpleJobRootConfig;}@Bean(initMethod = "init")public SpringJobScheduler fileScheduler(FileCustomElasticjob job, CoordinatorRegistryCenter registryCenter){LiteJobConfiguration jobConfiguration = createJobConfiguration(job.getClass(),"0/10 * * * * ?",4,"0=text,1=image,2=radio,3=vedio");return new SpringJobScheduler(job,registryCenter,jobConfiguration);}}
第二步:修改任务类
@Component@Slf4jpublic class FileCustomElasticjob implements SimpleJob {@Autowiredprivate FileCustomMapper fileCustomMapper;@Overridepublic void execute(ShardingContext shardingContext) {doWork(shardingContext.getShardingParameter());log.info("线程ID:{},任务的名称:{},任务的参数:{},分片个数:{},分片索引号:{},分片参数:{}",Thread.currentThread().getId(),shardingContext.getJobName(),shardingContext.getJobParameter(),shardingContext.getShardingTotalCount(),shardingContext.getShardingItem(),shardingContext.getShardingParameter());}private void doWork(String shardingParameter) {//查询出所有的备份任务List<FileCustom> fileCustoms = fileCustomMapper.selectByType(shardingParameter);for (FileCustom custom:fileCustoms){backUp(custom);}}private void backUp(FileCustom custom){System.out.println("备份的方法名:"+custom.getName()+"备份的类型:"+custom.getType());System.out.println("=======================");//模拟进行备份操作try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}fileCustomMapper.changeState(custom.getId(),1);}}
第三步:修改Mapper映射文件
@Mapperpublic interface FileCustomMapper {@Select("select * from t_file_custom where backedUp = 0")List<FileCustom> selectAll();@Update("update t_file_custom set backedUp = #{state} where id = #{id}")int changeState(@Param("id") Long id, @Param("state")int state);@Select("select * from t_file_custom where backedUp = 0 and type = #{type}")List<FileCustom> selectByType(String shardingParameter);}
Dataflow类型调度
Dataflow类型的定时任务需要实现Dataflowjob接口,该接口提供2个方法供覆盖,分别用于抓取(fetchData)和处理( processData)数据,我们继续对例子进行改造。
Dataflow类型用于处理数据流,他和SimpleJob不同,它以数据流的方式执行,调用fetchData抓取数据,知道抓取不到数据才停止作业。
定时任务开始的时候,先抓取数据,判断数据是否为空,若不为空则进行处理数据
代码示例
第一步:创建任务类
@Componentpublic class FileDataflowJob implements DataflowJob<FileCustom> {@Autowiredprivate FileCustomMapper fileCustomMapper;//抓取数据@Overridepublic List<FileCustom> fetchData(ShardingContext shardingContext) {System.out.println("开始抓取数据......");List<FileCustom> fileCustoms = fileCustomMapper.selectLimit(2);return fileCustoms;}//处理数据@Overridepublic void processData(ShardingContext shardingContext, List<FileCustom> data) {for(FileCustom custom:data){backUp(custom);}}private void backUp(FileCustom custom){System.out.println("备份的方法名:"+custom.getName()+"备份的类型:"+custom.getType());System.out.println("=======================");//模拟进行备份操作try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}fileCustomMapper.changeState(custom.getId(),1);}}
第二步:创建任务配置类
@Configurationpublic class JobConfig {@Beanpublic static CoordinatorRegistryCenter registryCenter(@Value("${zookeeper.url}") String url, @Value("${zookeeper.groupName}") String groupName) {ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(url, groupName);//设置节点超时时间zookeeperConfiguration.setSessionTimeoutMilliseconds(100);//zookeeperConfiguration("zookeeper地址","项目名")CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);regCenter.init();return regCenter;}//功能的方法private static LiteJobConfiguration createJobConfiguration(Class clazz, String corn, int shardingCount,String shardingParam,boolean isDateFlowJob) {JobCoreConfiguration.Builder jobBuilder = JobCoreConfiguration.newBuilder(clazz.getSimpleName(), corn, shardingCount);if(!StringUtils.isEmpty(shardingParam)){jobBuilder.shardingItemParameters(shardingParam);}//定义作业核心配置newBuilder("任务名称","corn表达式","分片数量")JobCoreConfiguration simpleCoreConfig = jobBuilder.build();// 定义SIMPLE类型配置 cn.wolfcode.MyElasticJobJobTypeConfiguration jobConfiguration;if(isDateFlowJob){jobConfiguration = new DataflowJobConfiguration(simpleCoreConfig,clazz.getCanonicalName(),true);}else{jobConfiguration = new SimpleJobConfiguration(simpleCoreConfig,clazz.getCanonicalName());}//定义Lite作业根配置LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(jobConfiguration).overwrite(true).build();return simpleJobRootConfig;}@Bean(initMethod = "init")public SpringJobScheduler fileDatFlowaScheduler(FileDataflowJob job, CoordinatorRegistryCenter registryCenter){LiteJobConfiguration jobConfiguration = createJobConfiguration(job.getClass(),"0/10 * * * * ?",1,null,true);return new SpringJobScheduler(job,registryCenter,jobConfiguration);}}第三步:创建Mapper映射文件
@Mapperpublic interface FileCustomMapper {@Update("update t_file_custom set backedUp = #{state} where id = #{id}")int changeState(@Param("id") Long id, @Param("state")int state);@Select("select * from t_file_custom where backedUp = 0 limit #{count}")List<FileCustom> selectLimit(int count);}
运维管理
事件追踪
Elastic-Job-Lite在配置中提供了JobEventConfiguration,支持数据库方式配置,会在数据库中自动创建JOB_EXECUTION_LOG和JOB_STATUS_TRACE_LOG两张表以及若干索引来近路作业的相关信息。
修改Elastic-job配置类
第一步:在ElasticJobConfig配置类中注入DataSource

第二步:在任务配置中增加事件追踪配置

运行结果
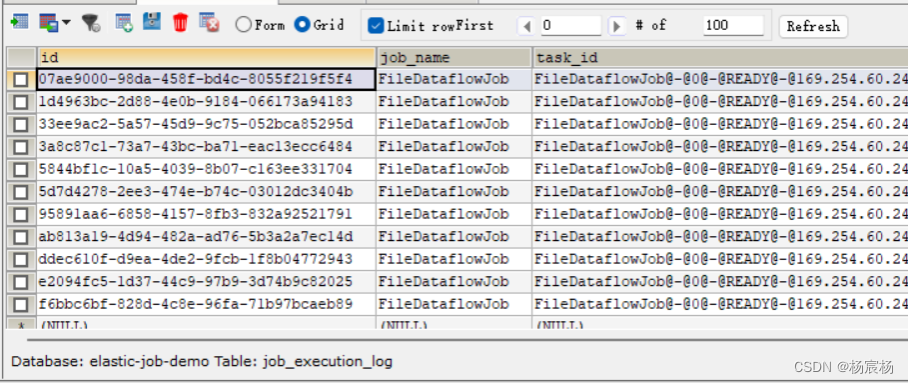
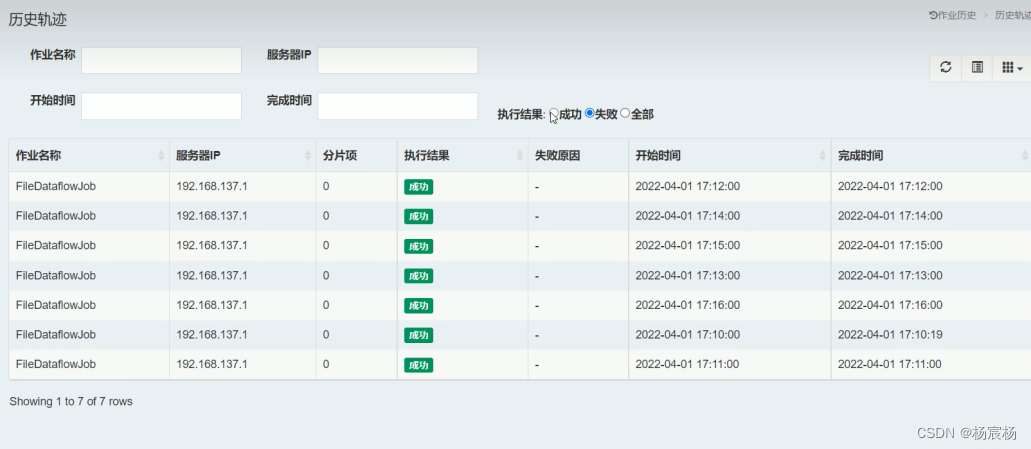
该表记录每次作业的执行历史,分为两个步骤:
1.作业开始执行时间想数据库插入数据
2.作业完成执行时向数据库更新数据,更新is_success,complete_time和failure_cause(如果任务执行失败)
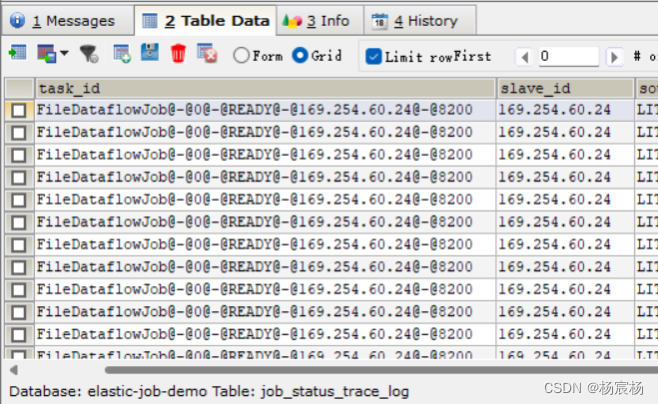
该表记录作业状态变更痕迹表,可通过每次作业运行的task_id查询作业状态变化的生命轨迹和运行轨迹
运维平台
搭建步骤
1.解压缩

2.进入bin目录,并执行
bin\start.bat
3.打开浏览器访问http://localhost:8899
用户名:root 密码:root
使用步骤
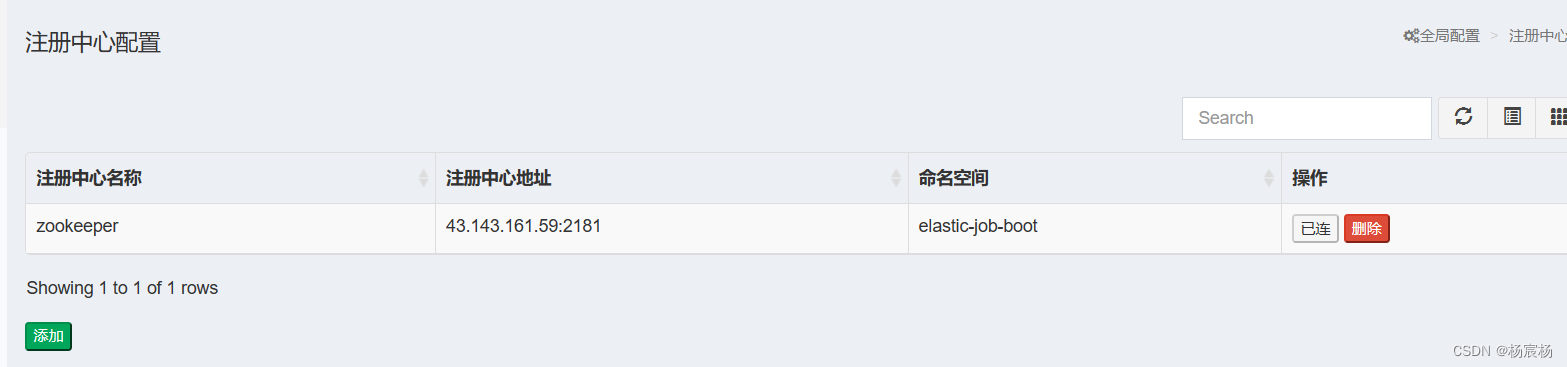
第一步:注册中心配置
第二步:事件追踪数据源配置
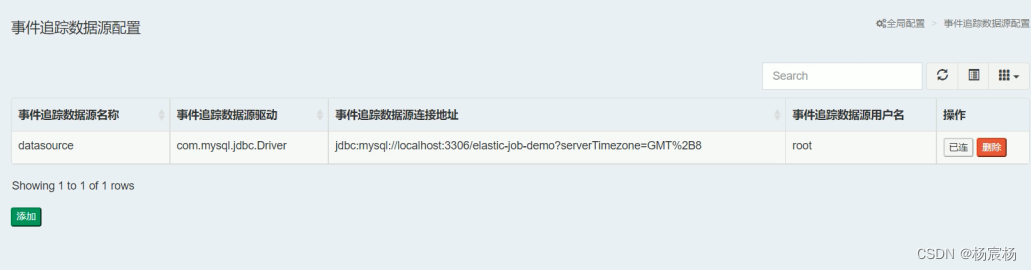
之后就可以使用了
相关文章:
微服务 分片 运维管理
微服务 分片 运维管理分片分片的概念分片案例环境搭建案例改造成任务分片Dataflow类型调度代码示例运维管理事件追踪运维平台搭建步骤使用步骤分片 分片的概念 当只有一台机器的情况下,给定时任务分片四个,在机器A启动四个线程,分别处理四个…...

批量占满TEMP表空间问题处理与排查
批量占满TEMP表空间问题处理与排查应急处置问题排查查看占用TEMP表空间高的SQL获取目标SQL执行计划方法一:EXPLAIN PLAN FOR方法二:DBMS_XPLAN.DISPLAY_CURSOR方法三:DBMS_XPLAN.DISPLAY_AWR方法四:AUTOTRACE数据库跑批任务占满TE…...

Pytorch中的tensor和variable
Tensor与Variable pytorch两个基本对象:Tensor(张量)和Variable(变量) 其中,tensor不能反向传播,variable可以反向传播(forword)。 反向传播是为了让神经网络更新前面…...
暗月内网渗透实战——项目七
首先环境配置 VMware的网络配置图 环境拓扑图 开始渗透 信息收集 使用kali扫描一下靶机的IP地址 靶机IP:192.168.0.114 攻击机IP:192.168.0.109 获取到了ip地址之后,我们扫描一下靶机开放的端口 靶机开放了21,80,999,3389,5985,6588端口…...

【Java 面试合集】描述下Objec类中常用的方法(未完待续中...)
描述下Objec类中常用的方法 1. 概述 首先我们要知道Object 类是所有的对象的基类,也就是所有的方法都是可以被重写的。 那么到底哪些方法是我们常用的方法呢??? cloneequalsfinalizegetClasshashCodenotifynotifyAlltoStringw…...

SQLSERVER 的 truncate 和 delete 有区别吗?
一:背景 1. 讲故事 在面试中我相信有很多朋友会被问到 truncate 和 delete 有什么区别 ,这是一个很有意思的话题,本篇我就试着来回答一下,如果下次大家遇到这类问题,我的答案应该可以帮你成功度过吧。 二࿱…...

【C++】CC++内存管理
就是你被爱情困住了?Wake up bro! 文章目录一、C/C内存分布二、C语言中动态内存管理方式三、C中内存管理方式1.new和delete操作内置类型2.new和delete操作自定义类型(仅限vs的底层实现机制,new和delete一定要匹配使用,…...

数据预处理之图像去空白
数据预处理之图像去空白图像去空白介绍方法边缘检测阈值处理形态学图像剪切图像去空白 介绍 图像去空白是指在图像处理中去除图像中的空白区域的过程。空白区域通常是指图像中的白色或其他颜色,其不包含有用的信息。去空白的目的是为了节省存储空间、提高图像处理…...

真的麻了,别再为难软件测试员了......
前言 有不少技术友在测试群里讨论,近期的面试越来越难了,要背的八股文越来越多了,考察得越来越细,越来越底层,明摆着就是想让我们徒手造航母嘛!实在是太为难我们这些测试工程师了。 这不,为了帮大家节约时…...

2月9日,30秒知全网,精选7个热点
///货拉拉将推出同城门到门跑腿服务 据介绍,两轮电动车将成为该业务的主要运力,预计将于3月中旬全面开放骑手注册和用户人气征集活动,并根据人气和线上骑手注册情况选择落地城市,于4月正式开放服务和骑手接单 ///三菱、乐天和莱茵…...
球面坐标系下的三重积分
涉及知识点 三重积分球面坐标系点火公式一些常见积分处理手法 球面坐标系定义 球面坐标系由方位角φ\varphiφ、仰角θ\thetaθ和距离rrr构成 直角坐标系(x,y,z)(x,y,z)(x,y,z)到球面坐标系的(r,φ,θ)(r,\varphi,\theta)(r,φ,θ)的转化规则如下: {xrsinφco…...

谷歌 Jason Wei | AI 研究的 4 项基本技能
文章目录 一、前言二、主要内容三、总结CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 原文作者为 Jason Wei,2020 年达特茅斯学院本科毕业,之后加入 Google Brain 工作。 Jason Wei 的博客主页:https://www.jasonwei.net/ 其实我不算是一个特别有经验的研究员…...

excel数据整理:合并计算快速查看人员变动
相信大家平时在整理数据时,都会对比数据是否有重复的地方,或者该数据与源数据相比是否有增加或者减少。数据量不大还好,数据量大的话,对比就比较费劲了。接下来我们将进入数据对比系列课程的学习。该系列一共有两篇教程࿰…...

vit-pytorch实现 MobileViT注意力可视化
项目链接 https://github.com/lucidrains/vit-pytorch 注意一下参数设置: Parameters image_size: int. Image size. If you have rectangular images, make sure your image size is the maximum of the width and heightpatch_size: int. Number of patches. im…...

Python将字典转换为csv
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理…...
EasyX精准帧率控制打气球小游戏
🎆音乐分享 New Boy —— 房东的猫 之前都用Sleep()来控制画面帧率,忽略了绘制画面的时间 如果绘制画面需要很长的时间,那么就不能忽略了。 并且Sleep()函数也不是特别准确,那么就…...

你知道 GO 中什么情况会变量逃逸吗?
你知道 GO 中什么情况会变量逃逸吗?首先我们先来看看什么是变量逃逸 Go 语言将这个以前我们写 C/C 时候需要做的内存规划和分配,全部整合到了 GO 的编译器中,GO 中将这个称为 变量逃逸 GO 通过编译器分析代码的特征和代码的生命周期&#x…...

一篇文章学懂C++和指针与链表
指针 目录 指针 C的指针学习 指针的基本概念 指针变量的定义和使用 指针的所占的内存空间 空指针和野指针 const修饰指针 指针和数组 指针和函数 指针、数组、函数 接下来让我们开始进入学习吧! C的指针学习 指针的基本概念 指针的作用:可…...

TPGS-cisplatin顺铂修饰维生素E聚乙二醇1000琥珀酸酯
TPGS-cisplatin顺铂修饰维生素E聚乙二醇1000琥珀酸酯(TPGS)溶于大部分有机溶剂,和水有很好的溶解性。 长期保存需要在-20℃,避光,干燥条件下存放,注意取用一定要干燥,避免频繁的溶解和冻干。 维生素E聚乙二醇琥珀酸酯(简称TPGS)是维生素E的水溶性衍生物,由维生素E…...
【20230206-0209】哈希表小结
哈希表一般哈希表都是用来快速判断一个元素是否出现在集合里。哈希函数哈希碰撞--解决方法:拉链法和线性探测法。拉链法:冲突的元素都被存储在链表中线性探测法:一定要保证tableSize大于dataSize,利用哈希表中的空位解决碰撞问题。…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...