Day901.内部临时表 -MySQL实战
内部临时表
Hi,我是阿昌,今天学习记录的是关于内部临时表的内容。
sort buffer、内存临时表和 join buffer。这三个数据结构都是用来存放语句执行过程中的中间数据,以辅助 SQL 语句的执行的。
其中,在排序的时候用到了 sort buffer,在使用 join 语句的时候用到了 join buffer。
MySQL 什么时候会使用内部临时表呢?
一、union 执行流程
用下面的表 t1 来举例。
create table t1(id int primary key, a int, b int, index(a));
delimiter ;;
create procedure idata()
begindeclare i int;set i=1;while(i<=1000)doinsert into t1 values(i, i, i);set i=i+1;end while;
end;;
delimiter ;
call idata();
然后,我们执行下面这条语句:
(select 1000 as f) union (select id from t1 order by id desc limit 2);
这条语句用到了 union,它的语义是,取这两个子查询结果的并集。
并集的意思就是这两个集合加起来,重复的行只保留一行。
下图是这个语句的 explain 结果。

可以看到:
- 第二行的 key=PRIMARY,说明第二个子句用到了索引 id。
- 第三行的 Extra 字段,表示在对子查询的结果集做 union 的时候,使用了临时表 (Using temporary)。
这个语句的执行流程是这样的:
- 创建一个内存临时表,这个临时表只有一个整型字段 f,并且 f 是主键字段。
- 执行第一个子查询,得到 1000 这个值,并存入临时表中。
- 执行第二个子查询:
- 拿到第一行 id=1000,试图插入临时表中。但由于 1000 这个值已经存在于临时表了,违反了唯一性约束,所以插入失败,然后继续执行;
- 取到第二行 id=999,插入临时表成功。
- 从临时表中按行取出数据,返回结果,并删除临时表,结果中包含两行数据分别是 1000 和 999。
这个过程的流程图如下所示:
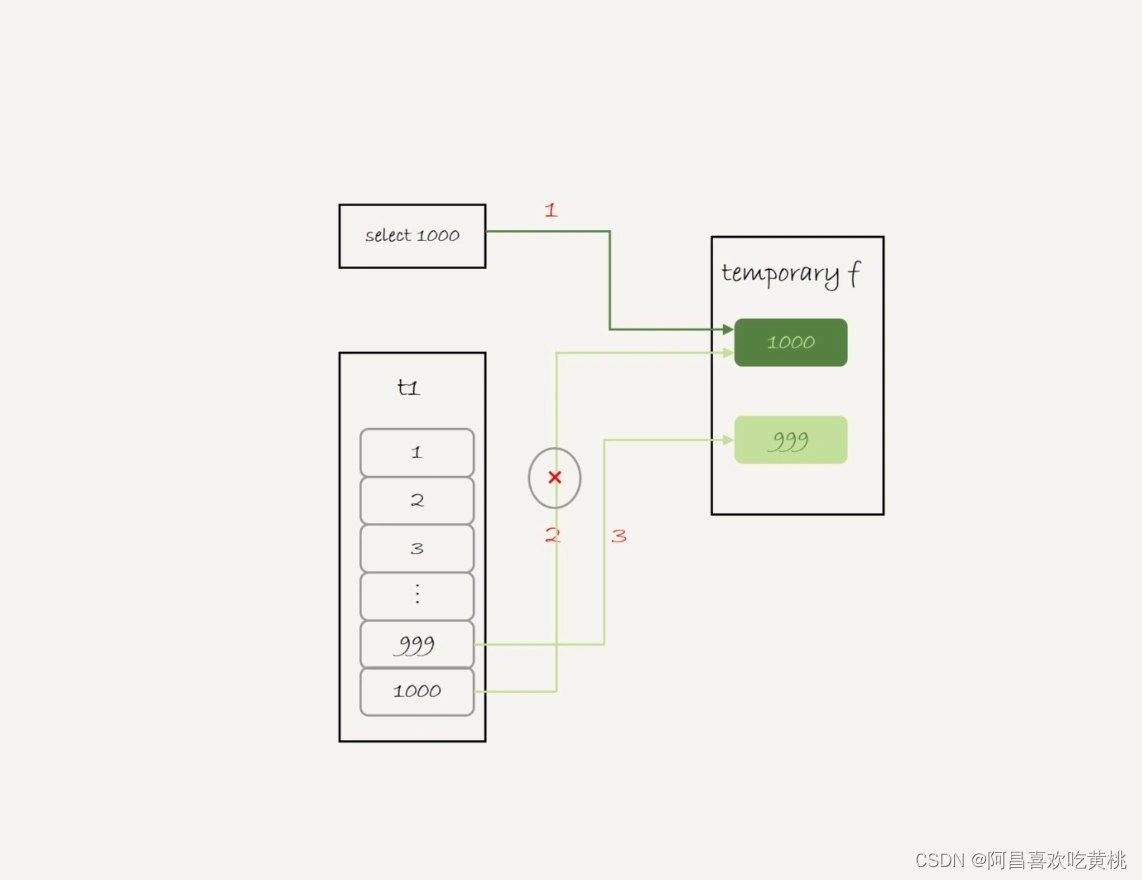
可以看到,这里的内存临时表起到了暂存数据的作用,而且计算过程还用上了临时表主键 id 的唯一性约束,实现了 union 的语义。
顺便提一下,如果把上面这个语句中的 union 改成 union all 的话,就没有了“去重”的语义。
这样执行的时候,就依次执行子查询,得到的结果直接作为结果集的一部分,发给客户端。
因此也就不需要临时表了。

可以看到,第二行的 Extra 字段显示的是 Using index,表示只使用了覆盖索引,没有用临时表了。
二、group by 执行流程
看一下这个语句:
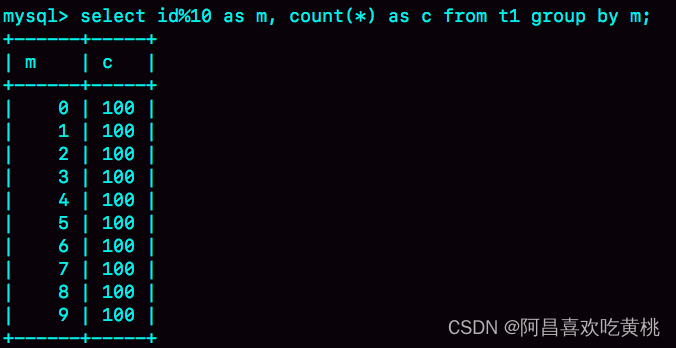
select id%10 as m, count(*) as c from t1 group by m;
这个语句的逻辑是把表 t1 里的数据,按照 id%10 进行分组统计,并按照 m 的结果排序后输出。
它的 explain 结果如下:

在 Extra 字段里面,我们可以看到三个信息:
- Using index,表示这个语句使用了覆盖索引,选择了索引 a,不需要回表;
- Using temporary,表示使用了临时表;
- Using filesort,表示需要排序。
这个语句的执行流程是这样的:
- 创建内存临时表,表里有两个字段 m 和 c,主键是 m;
- 扫描表 t1 的索引 a,依次取出叶子节点上的 id 值,计算 id%10 的结果,记为 x;
- 如果临时表中没有主键为 x 的行,就插入一个记录 (x,1);
- 如果表中有主键为 x 的行,就将 x 这一行的 c 值加 1;
- 遍历完成后,再根据字段 m 做排序,得到结果集返回给客户端。
这个流程的执行图如下:
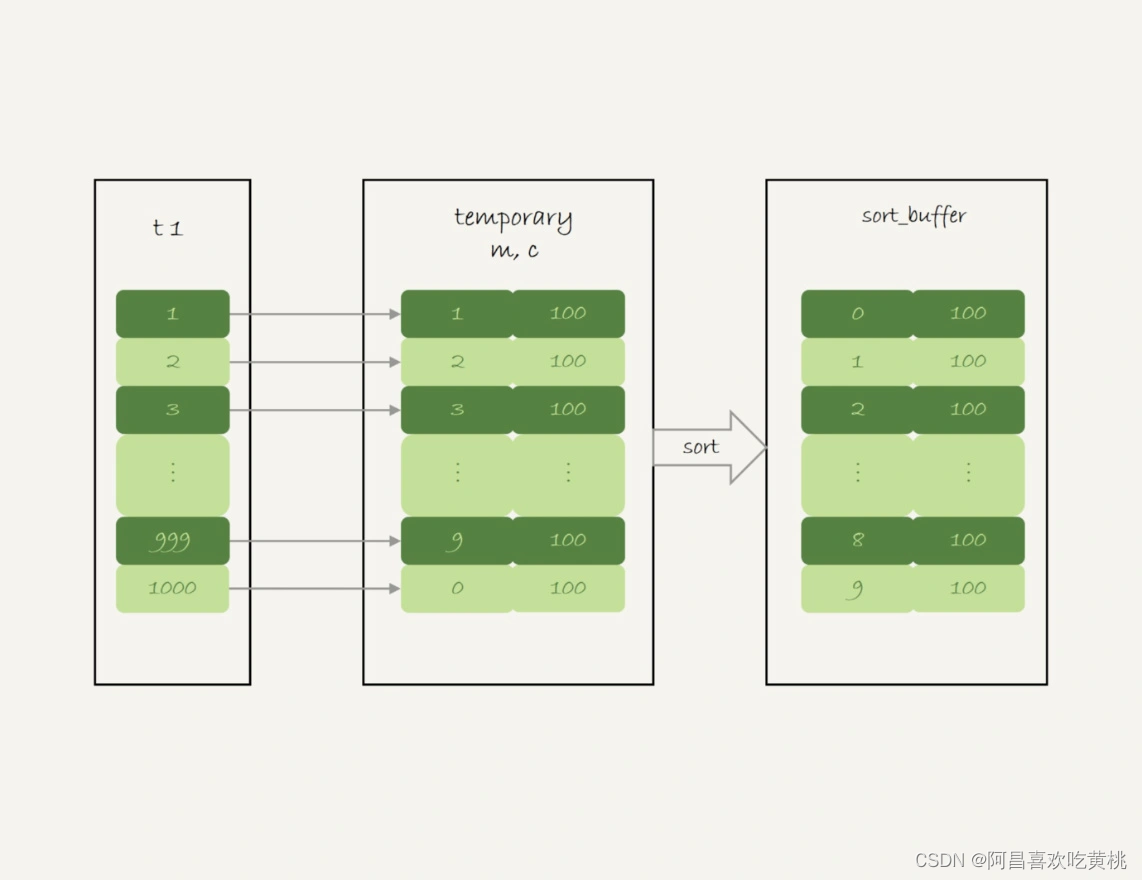
图中最后一步,对内存临时表的排序,在临时表排序中已经有过介绍。
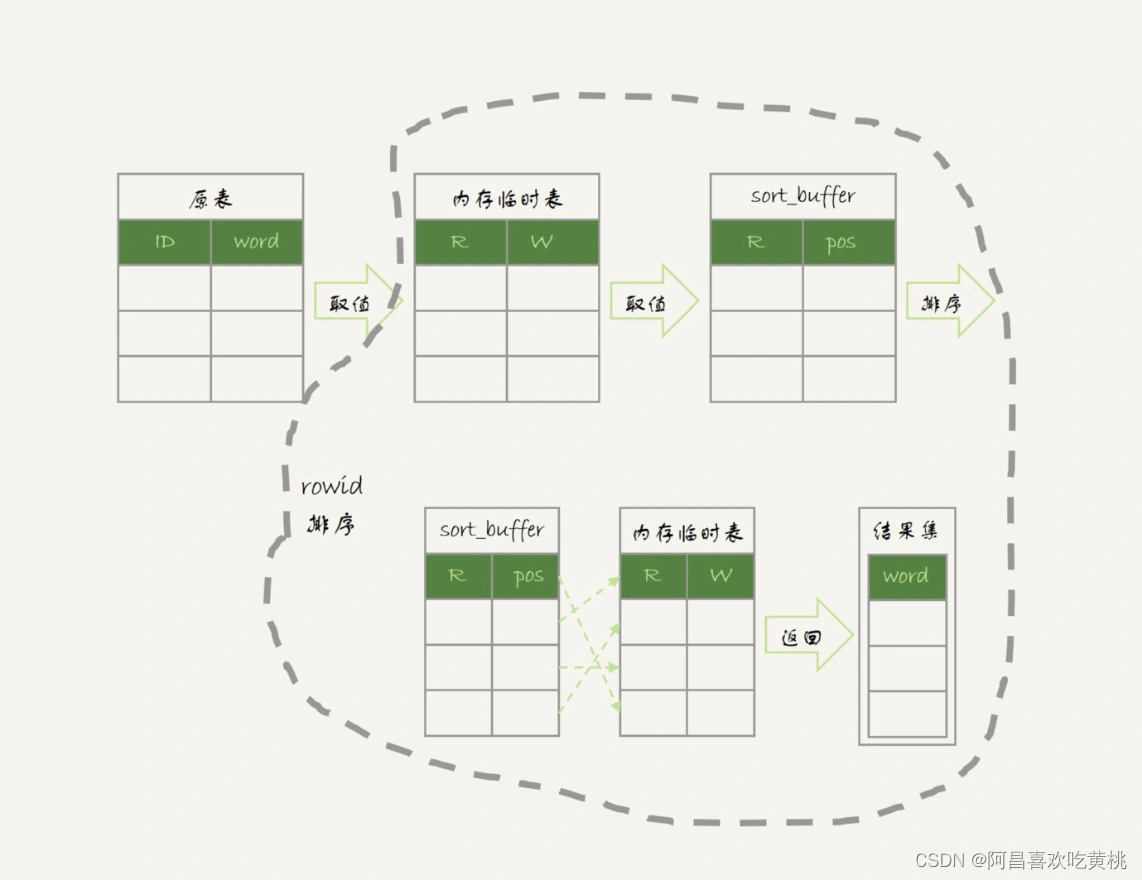
其中,临时表的排序过程就是图 6 中虚线框内的过程。
接下来,再看一下这条语句的执行结果:
如果你的需求并不需要对结果进行排序,那你可以在 SQL 语句末尾增加 order by null,也就是改成:
select id%10 as m, count(*) as c from t1 group by m order by null;
这样就跳过了最后排序的阶段,直接从临时表中取数据返回。
返回的结果如图 8 所示。
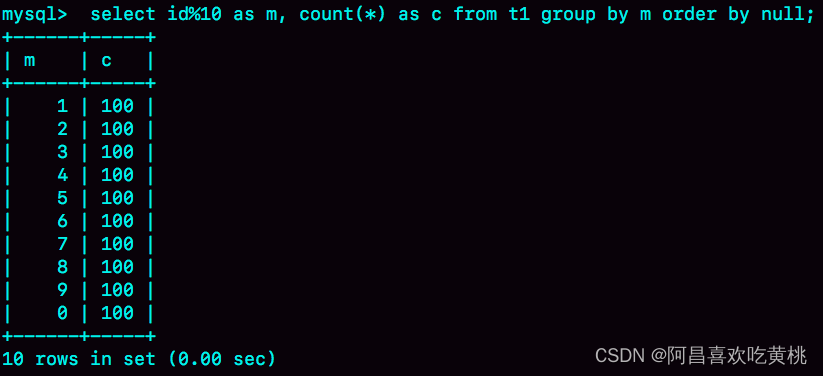
由于表 t1 中的 id 值是从 1 开始的,因此返回的结果集中第一行是 id=1;
扫描到 id=10 的时候才插入 m=0 这一行,因此结果集里最后一行才是 m=0。
这个例子里由于临时表只有 10 行,内存可以放得下,因此全程只使用了内存临时表。
但是,内存临时表的大小是有限制的,参数 tmp_table_size 就是控制这个内存大小的,默认是 16M。
如果执行下面这个语句序列:
set tmp_table_size=1024;
select id%100 as m, count(*) as c from t1 group by m order by null limit 10;
把内存临时表的大小限制为最大 1024 字节,并把语句改成 id % 100,这样返回结果里有 100 行数据。但是,这时的内存临时表大小不够存下这 100 行数据,也就是说,执行过程中会发现内存临时表大小到达了上限(1024 字节)。这时候就会把内存临时表转成磁盘临时表,磁盘临时表默认使用的引擎是 InnoDB。
这时,返回的结果如图 9 所示。
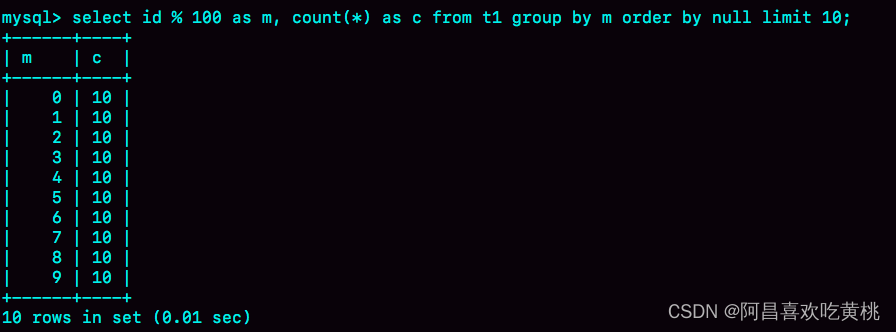
如果这个表 t1 的数据量很大,很可能这个查询需要的磁盘临时表就会占用大量的磁盘空间。
三、group by 优化方法 – 索引
可以看到,不论是使用内存临时表还是磁盘临时表,group by 逻辑都需要构造一个带唯一索引的表,执行代价都是比较高的。
如果表的数据量比较大,上面这个 group by 语句执行起来就会很慢,有什么优化的方法呢?
要解决 group by 语句的优化问题,可以先想一下这个问题:执行 group by 语句为什么需要临时表?
group by 的语义逻辑,是统计不同的值出现的个数。但是,由于每一行的 id%100 的结果是无序的,所以就需要有一个临时表,来记录并统计结果。
那么,如果扫描过程中可以保证出现的数据是有序的,是不是就简单了呢?
假设,现在有一个类似图 10 的这么一个数据结构,来看看 group by 可以怎么做。
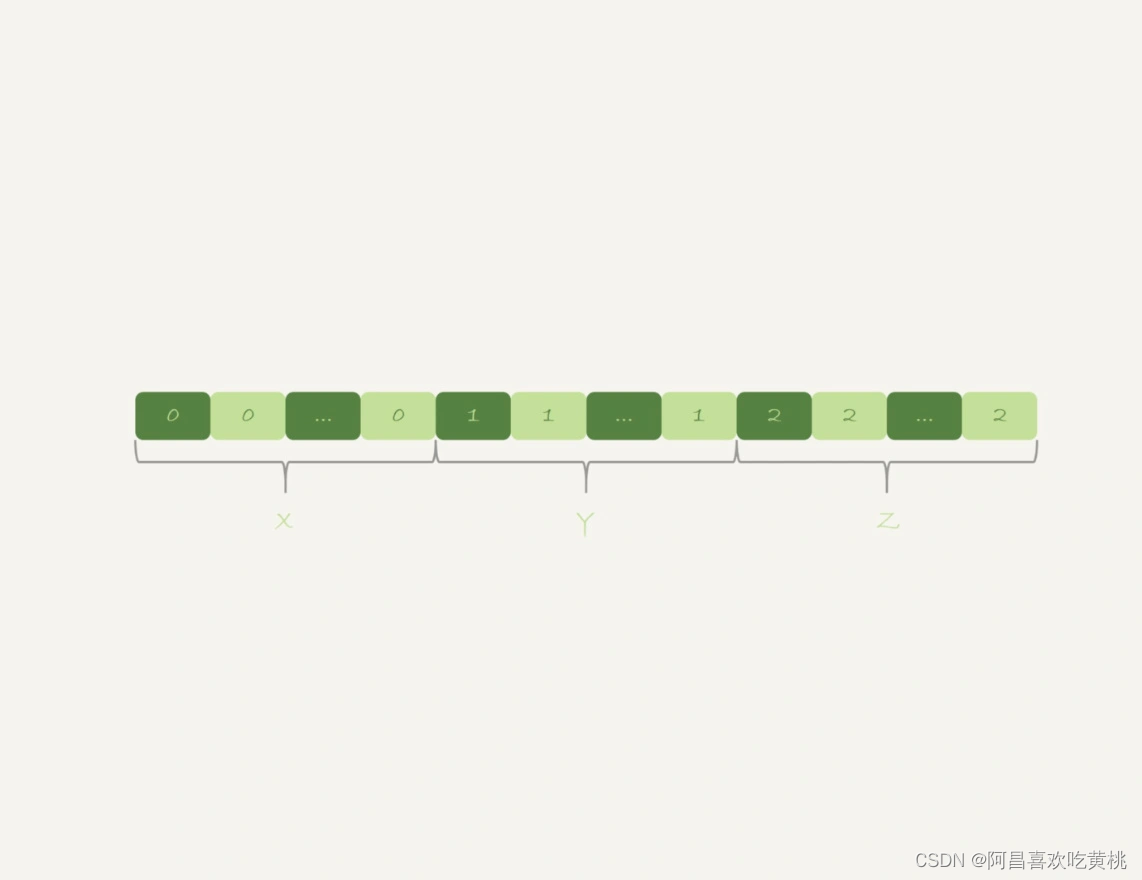
可以看到,如果可以确保输入的数据是有序的,那么计算 group by 的时候,就只需要从左到右,顺序扫描,依次累加。
也就是下面这个过程:
- 当碰到第一个 1 的时候,已经知道累积了 X 个 0,结果集里的第一行就是 (0,X);
- 当碰到第一个 2 的时候,已经知道累积了 Y 个 1,结果集里的第二行就是 (1,Y);
按照这个逻辑执行的话,扫描到整个输入的数据结束,就可以拿到 group by 的结果,不需要临时表,也不需要再额外排序。
InnoDB 的索引,就可以满足这个输入有序的条件。
在 MySQL 5.7 版本支持了 generated column 机制,用来实现列数据的关联更新。
可以用下面的方法创建一个列 z,然后在 z 列上创建一个索引(如果是 MySQL 5.6 及之前的版本,也可以创建普通列和索引,来解决这个问题)。
alter table t1 add column z int generated always as(id % 100), add index(z);
这样,索引 z 上的数据就是类似图 10 这样有序的了。
上面的 group by 语句就可以改成:
select z, count(*) as c from t1 group by z;
优化后的 group by 语句的 explain 结果,如下图所示:

从 Extra 字段可以看到,这个语句的执行不再需要临时表,也不需要排序了。
四、group by 优化方法 – 直接排序
所以,如果可以通过加索引来完成 group by 逻辑就再好不过了。但是,如果碰上不适合创建索引的场景,还是要老老实实做排序的。那么,这时候的 group by 要怎么优化呢?
如果明明知道,一个 group by 语句中需要放到临时表上的数据量特别大,却还是要按照“先放到内存临时表,插入一部分数据后,发现内存临时表不够用了再转成磁盘临时表”,看上去就有点儿傻。
MySQL 有没有让我们直接走磁盘临时表的方法呢?答案是,有的。
在group by 语句中加入 SQL_BIG_RESULT 这个提示(hint),就可以告诉优化器:这个语句涉及的数据量很大,请直接用磁盘临时表。
MySQL 的优化器一看,磁盘临时表是 B+ 树存储,存储效率不如数组来得高。所以,既然告诉我数据量很大,那从磁盘空间考虑,还是直接用数组来存吧。
因此,下面这个语句的执行流程就是这样的:
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
- 初始化 sort_buffer,确定放入一个整型字段,记为 m;
- 扫描表 t1 的索引 a,依次取出里面的 id 值, 将 id%100 的值存入 sort_buffer 中;
- 扫描完成后,对 sort_buffer 的字段 m 做排序(如果 sort_buffer 内存不够用,就会利用磁盘临时文件辅助排序);
- 排序完成后,就得到了一个有序数组。
根据有序数组,得到数组里面的不同值,以及每个值的出现次数。
这一步的逻辑,已经从前面的图 10 中了解过了。
下面两张图分别是执行流程图和执行 explain 命令得到的结果。
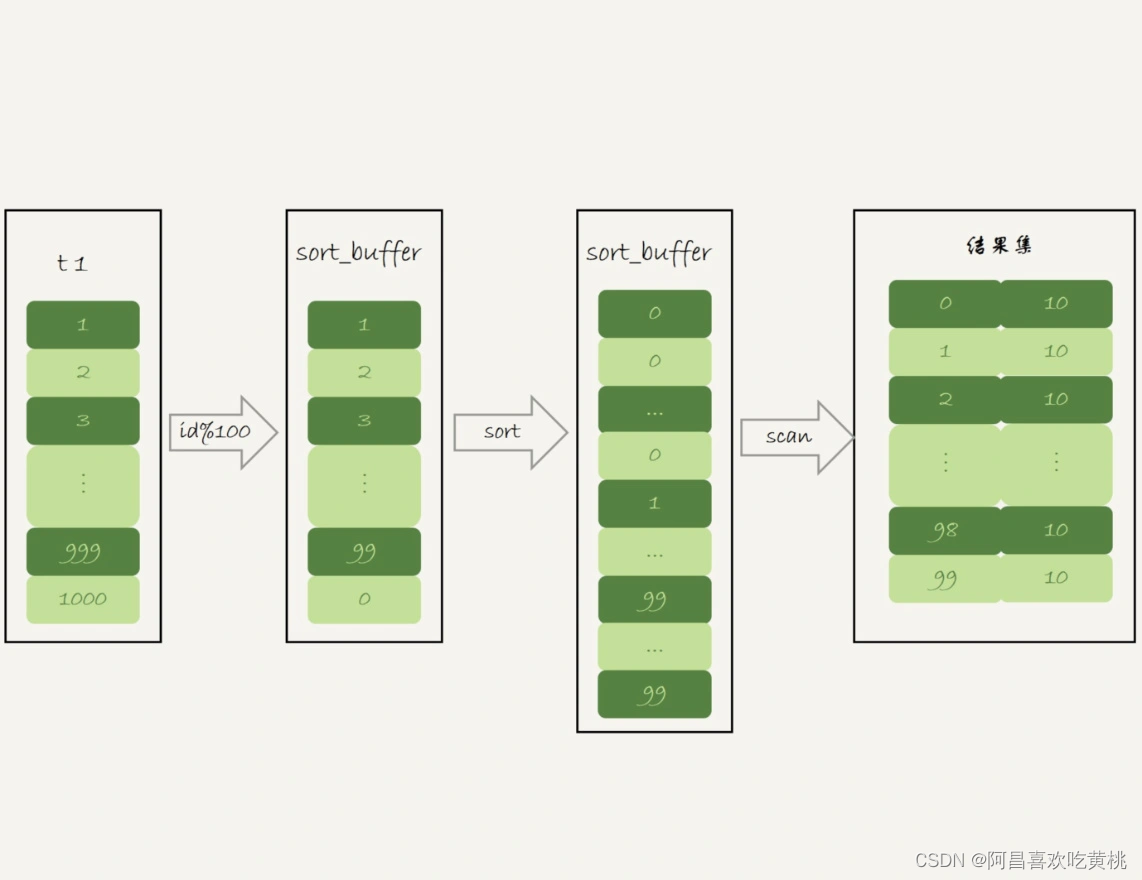

从 Extra 字段可以看到,这个语句的执行没有再使用临时表,而是直接用了排序算法。
基于上面的 union、union all 和 group by 语句的执行过程的分析,来回答文章开头的问题:
MySQL 什么时候会使用内部临时表?
- 如果语句执行过程可以一边读数据,一边直接得到结果,是不需要额外内存的,否则就需要额外的内存,来保存中间结果;
- join_buffer 是无序数组,sort_buffer 是有序数组,临时表是二维表结构;
- 如果执行逻辑需要用到二维表特性,就会优先考虑使用临时表。比如例子中,union 需要用到唯一索引约束, group by 还需要用到另外一个字段来存累积计数。
五、总结
group by 的几种实现算法,从中可以总结一些使用的指导原则:
- 如果对 group by 语句的结果
没有排序要求,要在语句后面加 order by null; 尽量让 group by 过程用上表的索引,确认方法是 explain 结果里没有 Using temporary 和 Using filesort;- 如果 group by 需要
统计的数据量不大,尽量只使用内存临时表; - 也可以通过
适当调大 tmp_table_size 参数,来避免用到磁盘临时表; - 如果数据量实在太大,
使用 SQL_BIG_RESULT这个提示,来告诉优化器直接使用排序算法得到 group by 的结果。
文章中图 8 和图 9 都是 order by null,为什么图 8 的返回结果里面,0 是在结果集的最后一行,而图 9 的结果里面,0 是在结果集的第一行?
内存临时表和磁盘临时表的存储格式不一样。
-
内存临时表,按照
扫描的顺序,第一个是1 ; -
磁盘临时表,走B+树,按照
id主键递增的顺序
相关文章:
Day901.内部临时表 -MySQL实战
内部临时表 Hi,我是阿昌,今天学习记录的是关于内部临时表的内容。 sort buffer、内存临时表和 join buffer。这三个数据结构都是用来存放语句执行过程中的中间数据,以辅助 SQL 语句的执行的。 其中,在排序的时候用到了 sort bu…...

jstatd的启动方式与关闭方式
启动方式与注意事项: 启动方式: 前台启动不打印日志: jstatd -J-Djava.security.policyjstatd.all.policy -J-Djava.rmi.server.hostname服务器IP 前台启动并打印日志: ./jstatd -J-Djava.security.policyjstatd.all.policy -…...

_improve-3
createElement过程 React.createElement(): 根据指定的第一个参数创建一个React元素 React.createElement(type,[props],[...children] )第一个参数是必填,传入的是似HTML标签名称,eg: ul, li第二个参数是选填,表示的是属性&#…...
C++——异常
目录 C语言传统的处理错误的方式 C异常概念 异常的使用 异常的抛出和匹配原则 在函数调用链中异常栈展开匹配原则 自定义异常体系 异常的重新抛出 编辑 异常安全 异常规范 C标准库的异常体系 异常的优缺点 C语言传统的处理错误的方式 传统的错误处理机制: …...
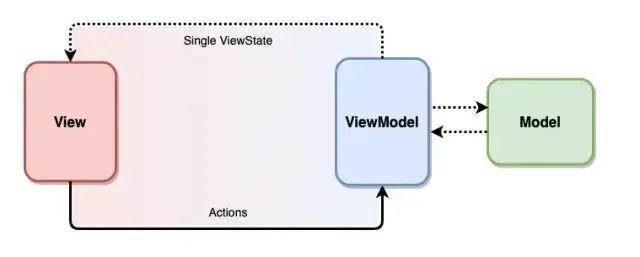
MVVM 架构进阶:MVI 架构详解
前言Android开发发展到今天已经相当成熟了,各种架构大家也都耳熟能详,如MVC,MVP,MVVM等,其中MVVM更是被官方推荐,成为Android开发中的显学。不过软件开发中没有银弹,MVVM架构也不是尽善尽美的,在使用过程中…...
有没有必要考PMP证书?
其实针对有没有必要考试吗,这个可以根本不同行业的人来决定的。 1.高等教育项目管理专业科班出身的人员。 在我国本科学历和硕士研究生学历中,项目管理也有开设。不管以后从事的工作是否为项目管理或其他管理,作为本专业的同学,…...
1 机器学习基础
1 机器学习概述 1.1 数据驱动的问题求解 大数据-Big Data 大数据的多面性 1.2 数据分析 机器学习:海量的数据,获取有用的信息 专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之…...
java基础系列(六) sleep()和wait() 区别
一.前言 关于并发编程这块, 线程的一些基础知识我们得搞明白, 本篇文章来说一下这两个方法的区别,对Android中的HandlerThread机制原理可以有更深的理解, HandlerThread源码理解,请查看笔者的这篇博客: HandlerThread源码理解_handlerthread 源码_broadview_java的博客-CSDN博…...

Urho3D序列化
从Serializable派生的类可以通过定义属性将其自动序列化为二进制或XML格式。属性存储到每个类的上下文中。场景加载/保存和网络复制都是通过从Serializable派生Node和Component类来实现的。 支持的属性类型是Variant支持的所有属性类型,不包括指针和自定义值。 属性…...
企业级信息系统开发学习1.3——利用注解配置取代Spring配置文件
文章目录一、利用注解配置类取代Spring配置文件(一)打开项目(二)创建新包(三)拷贝类与接口(四)创建注解配置类(五)创建测试类(六)运行…...

VUE DIFF算法之快速DIFF
VUE DIFF算法系列讲解 VUE 简单DIFF算法 VUE 双端DIFF算法 文章目录VUE DIFF算法系列讲解前言一、快速DIFF的代码实现二、实践练习1练习2总结前言 本节我们来写一下VUE3中新的DIFF算法-快速DIFF,顾名思义,也就是目前最快的DIFF算法(在VUE中&…...

一文掌握如何轻松稿定项目风险管理【静说】
风险管理对于每个项目经理和PMO都非常重要,如果管理不当会出现很多问题,咱们以前分享过很多风险管理的内容: 风险无处不在,一旦发生,会对一个或多个项目目标产生积极或消极影响的确定事件或条件。那么接下来介绍下五大…...
操作系统权限提升(十四)之绕过UAC提权-基于白名单AutoElevate绕过UAC提权
系列文章 操作系统权限提升(十二)之绕过UAC提权-Windows UAC概述 操作系统权限提升(十三)之绕过UAC提权-MSF和CS绕过UAC提权 注:阅读本编文章前,请先阅读系列文章,以免造成看不懂的情况!! 基于白名单AutoElevate绕过…...
ecology9-谷歌浏览器下-pdf.js在渲染时部分发票丢失文字 问题定位及解决
问题 问题描述 : 在谷歌浏览器下,pdf.js在渲染时部分发票丢失文字;360浏览器兼容模式不存在此问题 排查思路:1、对比谷歌浏览器的css样式和360浏览器兼容模式下的样式,没有发现关键差别 2、✔使用Fiddler修改网页js D…...

JavaScript Window Navigator
文章目录JavaScript Window NavigatorWindow Navigator警告!!!浏览器检测JavaScript Window Navigator window.navigator 对象包含有关访问者浏览器的信息。 Window Navigator window.navigator 对象在编写时可不使用 window 这个前缀。 实例 <div id"example"…...

Linux基础命令-du查看文件的大小
文章目录 du 命令介绍 语法格式 基本参数 参考实例 1)以人类可读形式显示指定的文件大小 2)显示当前目录下所有文件大小 3)只显示目录的大小 4)显示根下哪个目录文件最大 5)显示所有文件的大小 6࿰…...
文献计量分析方法:Citespace安装教程
Citespace是一款由陈超美教授开发的可用于海量文献可视化分析的软件,可对Web of Science,Scopus,Pubmed,CNKI等数据库的海量文献进行主题、关键词,作者单位、合作网络,期刊、发表时间,文献被引等…...

MVI 架构更佳实践:支持 LiveData 属性监听
前言MVI架构为了解决MVVM在逻辑复杂时需要写多个LiveData(可变不可变)的问题,使用ViewState对State集中管理,只需要订阅一个 ViewState 便可获取页面的所有状态通过集中管理ViewState,只需对外暴露一个LiveData,解决了MVVM模式下LiveData膨胀…...

LeetCode438 找到字符串中所有字母异位词 带输入和输出
题目: 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。 示例 1: 输入: s “cbaebabacd”, …...

ACSC 2023 比赛复现
Admin Dashboard 在 index.php 中可以看到需要访问者是 admin 权限,才可以看到 flag。 report.php 中可以让 admin bot 访问我们输入的 url,那么也就是说可以访问 addadmin.php 添加用户。 在 addadmin.php 中可以添加 admin 用户,但是需…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...