Vision Transformer(ViT)
1. 概述
Transformer[1]是Google在2017年提出的一种Seq2Seq结构的语言模型,在Transformer中首次使用Self-Atttention机制完全代替了基于RNN的模型结构,使得模型可以并行化训练,同时解决了在基于RNN模型中出现了长距离依赖问题,因为在Self-Attention中能够对全局的信息建模。
Transformer结构是一个标准的Seq2Seq结构,包含了Encoder和Decoder两个部分。其中基于Encoder的Bert[2]模型和基于Decoder的GPT[3]模型刷新了NLP中多个任务的记录,在NLP多种应用中取得了巨大的成功。以BERT模型为例,在BERT模型中,首先在大规模数据上利用无监督学习训练语言模型,对于具体的下游任务,如文本分类,利用预训练模型在下游数据上Fine-tuning。
基于Transformer框架的模型在NLP领域大获成功,而在CV领域还是基于CNN模型的情况下,能否将Transformer引入到CV中呢?ViT(Vision Transformer)[4]作为一种尝试,希望能够通过尽可能少的模型改动,实现Transformer在CV中的应用。
2. 算法原理
2.1. Transformer的基本原理
Transformer框架是一个典型的Seq2Seq结构,包括了Encoder和Decoder两个部分,其框架结构如下图所示:
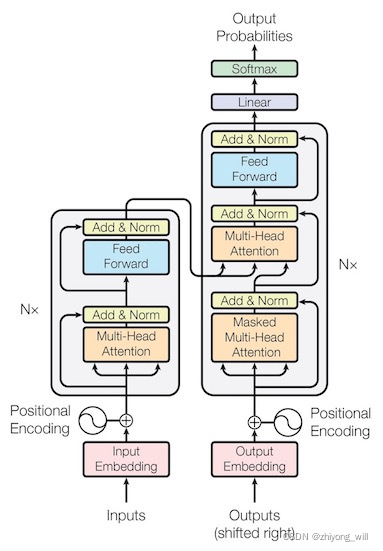
在Transformer框架结构中,Encoder部分如上图的左半部分,Decoder部分如上图的右半部分。由于在ViT中是以Encoder部分为主要部分,同时,BERT模型也是以Transformer中Encoder为原型的模型,因此在这里对Bert模型做简单介绍,对于完整的Transformer框架的介绍可见参考文献[5]。BERT是基于上下文的预训练模型,BERT模型的训练分为两步:第一,pre-training;第二,fine-tuning。其中,在pre-training阶段,首先会通过大量的文本对BERT模型进行预训练,然而,标注样本是非常珍贵的,在BERT中则是选用大量的未标注样本来预训练BERT模型。在fine-tuning阶段,会针对不同的下游任务适当改造模型结构,同时,通过具体任务的样本,重新调整模型中的参数。
2.1.1. BERT模型的网络结构
BERT模型是Transformer结构的Encoder部分,其基本的网络结构如下图所示:

这个结构与Transformer中的Encoder结构是完全一致的。
2.1.2. BERT模型的输入Embedding
为了使得BERT能够适配更多的应用,模型在pre-training阶段,使用了Masked Language Model(MLM)和Next Sentence Prediction(NSP)两种任务作为模型预训练的任务,其中MLM可以学习到词的Embedding,NSP可以学习到句子的Embedding。在Transformer中,输入中会将词向量与位置向量相加,而在BERT中,为了能适配上述的两个任务,即MLM和NSP,这里的Embedding包含了三种Embedding的和,如下图所示:

其中,Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任,Segment Embeddings用来区别两种句子,这是在预训练阶段,针对NSP任务的输入,Position Embeddings是位置向量,但是和Transformer中不一样,与词向量一样,是通过学习出来的。此处包含了两种标记,一个是[CLS],可以理解为整个输入特征的向量表示;另一个是[SEP],用于区分不同的句子。
2.1.3. 重要的Multi-Head Attention
Multi-Head Attention结构是所以基于Transformer框架模型的灵魂,Multi-Head Attention结构是由多个Scaled Dot-Product Attention模块组合而成,如下图所示:
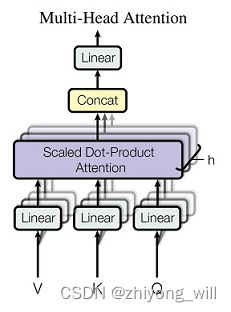
其过程可以表示为:
MultiHead(Q,K,V)=Concat(head1,⋯,headh)WoMultiHead\left ( Q,K,V \right ) =Concat\left ( head_1,\cdots, head_h \right ) W^oMultiHead(Q,K,V)=Concat(head1,⋯,headh)Wo
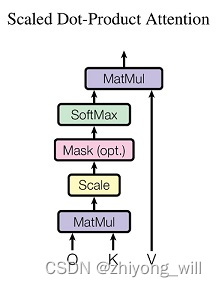
其中,每一个headihead_iheadi就是一个Scaled Dot-Product Attention。Multi-head Attention相当于多个不同的Scaled Dot-Product Attention的集成,引入Multi-head Attention可以扩大模型的表征能力,同时这里面的hhh个Scaled Dot-Product Attention模块是可以并行的,没有层与层之间的依赖,相比于RNN,可以提升效率。而Scaled Dot-Product Attention的计算方法为:
Attention(Q,K,V)=softmax(QKTdk)VAttention\left ( Q,K,V \right )=softmax\left ( \frac{QK^T}{\sqrt{d_k} }\right )VAttention(Q,K,V)=softmax(dkQKT)V
其中1dk\frac{1}{\sqrt{d_k} }dk1最主要的目的是对点积缩放。计算过程可由下图表示:
2.1.4. 下游任务的fine-tuning
在预训练阶段,BERT采用了Masked Language Model和Next Sentence Prediction两个训练任务作为其语言模型的训练,其中,Masked Language Model的原理是随机将一些词替换成[MASK],在训练的过程中,通过上下文信息来预测被mask的词;Next Sentence Prediction的目的是让模型理解两个橘子之间的关系,训练的输入是两个句子,BERT模型需要判断后一个句子是不是前一个句子的下一句。这两个任务最大的特点就是可以无监督学习,这样就可以避免模型对大规模标注数据依赖的问题。
在预训练模型完成后,就可以在具体的下游任务中应用BERT模型。这里以文本分类为例,句子对的分类任务,即输入是两个句子,输入如下图所示:

输出是BERT的第一个[CLS]的隐含层向量C∈RHC\in \mathbb{R}^HC∈RH,在Fine-Tune阶段,加上一个权重矩阵W∈RK×HW\in \mathbb{R}^{K\times H}W∈RK×H,其中,KKK为分类的类别数。最终通过Softmax函数得到最终的输出概率。
2.2. ViT的基本原理
ViT模型是希望能够尽可能少对Transformer模型修改,并将Transformer应用于图像分类任务的模型。ViT模型也是基于Transformer的Encoder部分,这一点与BERT较为相似,同时对Encoder部分尽可能少的修改。
2.2.1. ViT的网络结构
ViT的网络结构如下图所示:

ViT模型的网络结构如上图的右半部分所示,与原始的Transformer中的Encoder不同的是Norm所在的位置不同,类似BERT模型中[class]标记位的设置,ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位,并且该位置的Transformer Encoder输出作为图像特征。
Vision Transformer(ViT)将输入图片拆分成16×1616\times 1616×16个patches,每个patch做一次线性变换降维同时嵌入位置信息,然后送入Transformer。类似BERT[CLS]标记位的设计,在ViT中,在输入序列前增加了一个额外可学习的[class]标记位,并将其最终的输出作为图像特征,最后利用MLP做最后的分类,如上图中的左半部分所示,其中,[class]标记位为上图中Transformer Encoder的0*。那么现在的问题就是两个部分,第一,如何将图像转换成一维的序列数据,因为BERT处理的文本数据是一维的序列数据;第二,如何增加位置信息,因为在Transformer中是需要对位置信息编码的,在BERT中是通过学习出来,而在Transformer中是利用sin和cos这两个公式生成出来。
2.2.2. 图像到一维序列数据的转换
对于x∈RH×W×C\mathbf{x}\in \mathbb{R}^{H\times W\times C}x∈RH×W×C的图像,首先需要将其变成xp∈RN×(P2⋅C)\mathbf{x}_p\in \mathbb{R}^{N\times \left (P^2\cdot C \right )}xp∈RN×(P2⋅C)的2D的patch的序列,这里面,(H,W)\left ( H,W \right )(H,W)表示的是原图的分辨率,CCC表示的通道(channel)的数目,(P,P)\left ( P,P \right )(P,P)表示的是每个patch的分辨率,N=HW/p2N=HW/p^2N=HW/p2表示的是patch的个数,对于一个通道,上述的这个过程可以如下图所示:

假设输入图片大小是256×256256\times 256256×256,每个patch的大小为32×3232\times 3232×32,则最后的总的patch个数为64。对于每个patch,我们还需要将其转换成embeding的表示,ViT中使用到了线性变换,即:
z0=[xclass;xp1E;xp2E;⋯;xpNE]+Epos\mathbf{z}_0=\left [ \mathbf{x}_{class};\mathbf{x}_p^1\mathbf{E};\mathbf{x}_p^2\mathbf{E};\cdots ;\mathbf{x}_p^N\mathbf{E} \right ]+\mathbf{E}_{pos}z0=[xclass;xp1E;xp2E;⋯;xpNE]+Epos
其中,E∈R(P2⋅C)×D\mathbf{E}\in \mathbb{R}^{\left ( P^2\cdot C \right )\times D}E∈R(P2⋅C)×D,Epos∈R(N+1)×D\mathbf{E}_{pos}\in \mathbb{R}^{\left ( N+1 \right )\times D}Epos∈R(N+1)×D。首先对于第iii个patch,我们看到xpiE\mathbf{x}_p^i\mathbf{E}xpiE是将patch转换成DDD维的向量,具体过程如下:

这里的卷积操作中卷积核大小为P×PP\times PP×P,步长为PPP。参考文献[6]给出了较为容易理解的代码,注释的代码如下:
class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):super().__init__()img_size = (img_size, img_size) # 图片原始大小patch_size = (patch_size, patch_size) # 每个patch的大小self.img_size = img_sizeself.patch_size = patch_sizeself.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) # 拆分成每个patch后,每个维度的patch个数self.num_patches = self.grid_size[0] * self.grid_size[1] # 总共的patch个数self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) # 对每个patch做线性变换self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() # 归一化def forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = self.proj(x).flatten(2).transpose(1, 2) # 这里C即为向量的维度,HW表示的是patch的个数x = self.norm(x)return x
除此之外还有两个向量,分别为xclass\mathbf{x}_{class}xclass和Epos\mathbf{E}_{pos}Epos。xclass\mathbf{x}_{class}xclass表示的给到一个用于最后图像表示的向量,用于最后的分类任务,Epos\mathbf{E}_{pos}Epos表示的是位置向量,这两个向量都是通过随机初始化的,并在训练过程中得到的,在参考文献[6]中的代码如下:
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
通过以上的过程后,便可以直接使用标准的BERT流程开始训练,这部分不再赘述,可参见参考文献[5]和参考文献[6]的具体实现。
2.2.3. 训练目标以及fine-tune
ViT的训练与BERT是不一样的,在BERT中采用的无监督的训练,而在ViT中使用的是监督训练,使用的数据集是有标签的分类数据集,如ILSVRC-2012 ImageNet数据集,该数据集是一个包含了1000个类别的带标签的数据集。[class]标记的向量最初为z00=xclass\mathbf{z}_0^0=\mathbf{x}_{class}z00=xclass,在训练过程中,通过Transformer Encoder得到[class]标记的最终向量为zL0\mathbf{z}_L^0zL0,对其进行归一化并以此作为图像的表示y\mathbf{y}y:
y=LN(zL0)\mathbf{y}=LN\left ( \mathbf{z}_L^0 \right )y=LN(zL0)
在训练过程中,后接一个带一个隐含层的MLP,得到整个网络的结构。在Fine-tuning时,去掉最终的这部分,直接用一个线性曾代替这部分重新训练。
在参考文献[4]中,作者设计了不同大小的网络结构,如下图所示:

从最终的效果上来看,ViT模型的效果还是要优于传统的基于CNN的模型的:

2.2.4. 一个有意思的点
在上述的ViT的过程中,位置的向量Epos\mathbf{E}_{pos}Epos是随机初始化的,那么最终训练出来的这个向量的值能表示其在原始图像中的真实位置吗?在参考文献[4]中设计了这样一个方法,假设有7×77\times 77×7个patch,每个patch的位置向量与其他patch的位置向量计算相似度,得到了如下的一张图,其中自身的相似度为111。
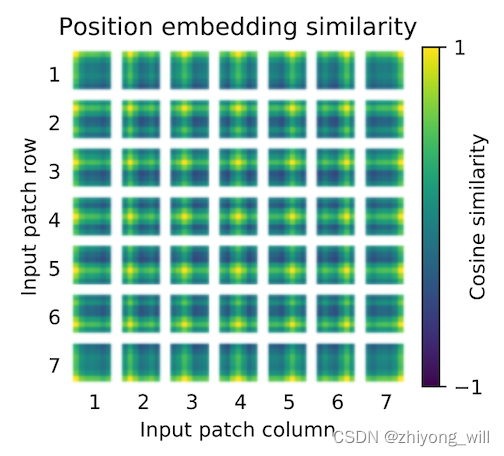
我们发现最终训练出来的位置向量已经具有了空间了信息,即与同行同列之间具有相对较高的相似度。
3. 总结
ViT模型将Transformer引入到图像的分类中,更准确的说是Transformer中的Encoder模块。为了能够尽可能少地对原始模型的修改,在ViT中将图像转换成一维的序列表示,以改成标准的文本形式,通过这种方式实现Transformer在CV中的应用。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[2] Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
[3] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[4] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[5] Transformer的基本原理
[6] vision_transformer 代码
相关文章:
Vision Transformer(ViT)
1. 概述 Transformer[1]是Google在2017年提出的一种Seq2Seq结构的语言模型,在Transformer中首次使用Self-Atttention机制完全代替了基于RNN的模型结构,使得模型可以并行化训练,同时解决了在基于RNN模型中出现了长距离依赖问题,因…...

104-JVM优化
JVM优化为什么要学习JVM优化: 1:深入地理解 Java 这门语言 我们常用的布尔型 Boolean,我们都知道它有两个值,true 和 false,但你们知道其实在运行时,Java 虚拟机是 没有布尔型 Boolean 这种类型的&#x…...

QML 颜色表示法
作者: 一去、二三里 个人微信号: iwaleon 微信公众号: 高效程序员 如果你经常需要美化样式(最常见的有:文本色、背景色、边框色、阴影色等),那一定离不开颜色。而在 QML 中,颜色的表示方法有多种:颜色名、十六进制颜色值、颜色相关的函数,一起来学习一下吧。 老规矩…...
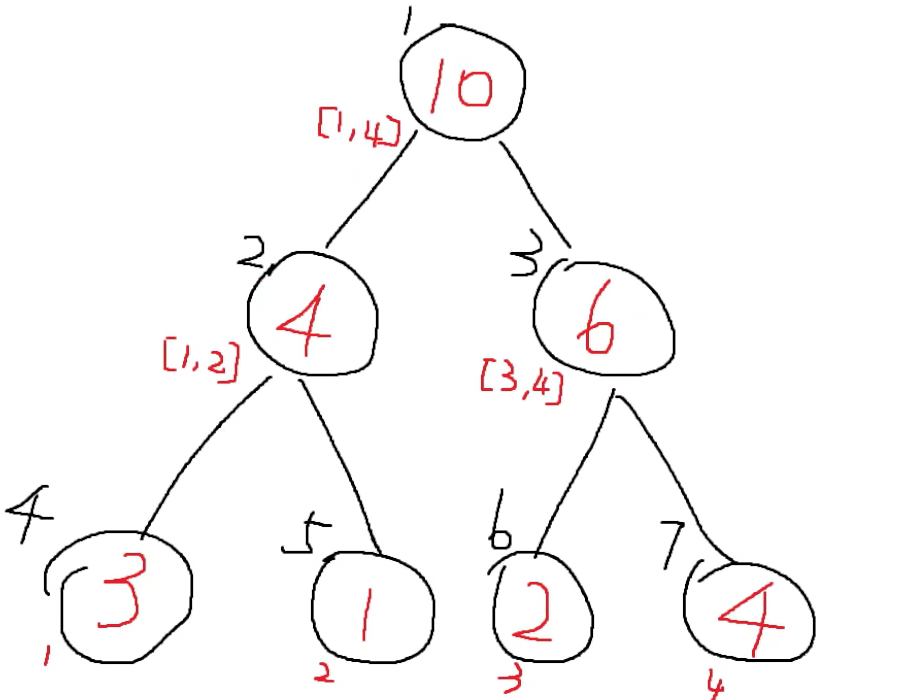
基础数据结构--线段树(Python版本)
文章目录前言特点操作数据存储updateLazy下移查询实现前言 月末了,划个水,赶一下指标(更新一些活跃值,狗头) 本文主要是关于线段树的内容。这个线段树的话,主要是适合求解我们一个数组的一些区间的问题&am…...

【micropython】SPI触摸屏开发
背景:最近买了几块ESP32模块,看了下mircopython支持还不错,所以买了个SPI触摸屏试试水,记录一下使用过程。硬件相关:SPI触摸屏使用2.4寸屏幕,常见淘宝均可买到,驱动为ILI9341,具体参…...
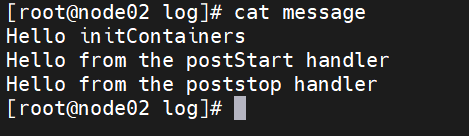
【云原生】k8s中Pod进阶资源限制与探针
一、Pod 进阶 1、资源限制 当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源。 当为 Pod 中的容器指定了 request 资源时,调度器就使用该信息来决定将 Pod 调度到哪个节点上。当还…...
AI - stable-diffusion(AI绘画)的搭建与使用
最近 AI 火的一塌糊涂,除了 ChatGPT 以外,AI 绘画领域也有很大的进步,以下几张图片都是 AI 绘制的,你能看出来么? 一、环境搭建 上面的效果图其实是使用了开源的 AI 绘画项目 stable-diffusion 绘制的,这是…...
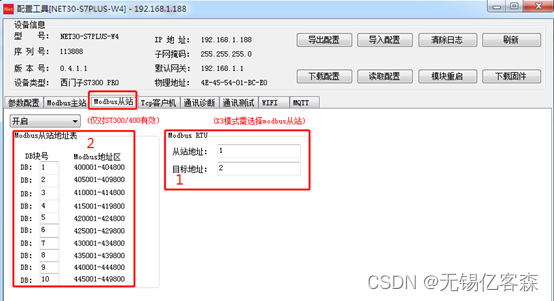
应用场景五: 西门子PLC通过Modbus协议连接DCS系统
应用描述: 西门子PLC(S7200/300/400/200SMART)通过桥接器可以支持ModbusRTU串口和ModbusTCP以太网(有线和无线WIFI同时支持)两种通讯方式连接DCS系统,不需要编程PLC通讯程序,直接在模块中进行地…...

我继续问了ChatGPT关于SAP顾问职业发展前景的问题,大家感受一下
目录 SAP 顾问 跟其他IT工作收入情况相比是怎么样的? 如何成为SAP FICO 优秀的顾问 要想成为SAP FICO 优秀的顾问 ,需要ABA开发技能吗 SAP 顾问中哪个类型收入最多? 中国的ERP软件能够取代SAP吗? 今天我继续撩 ChatGPT。随便问…...
)
Python小白入门---00开篇介绍(简单了解一下)
Python 小白入门 系列教程 第一部分:Python 基础 介绍 Python 编程语言安装 Python 环境变量和数据类型运算符和表达式控制流程语句函数和模块异常处理 第二部分:Python 标准库和常用模块 Python 标准库简介文本处理和正则表达式文件操作和目录操作时…...

【算法基础】C++STL容器
一、Vector 1. 初始化(定义) (1)vector最基本的初始化: vector <int> a;(2)定义长度为10的vector: vector <int> a(10);(3)定义长度为10的vector,并且把所有元素都初始化为-3: vector <int...

【经典蓝牙】蓝牙 A2DP协议分析
A2DP 介绍 A2DP(Advanced Audio Distribution Profile)是蓝牙高音质音频传输协议, 用于传输单声道, 双声道音乐(一般在 A2DP 中用于 stereo 双声道) , 典型应用为蓝牙耳机。 A2DP旨在通过蓝牙连接传输高质量的立体声音…...
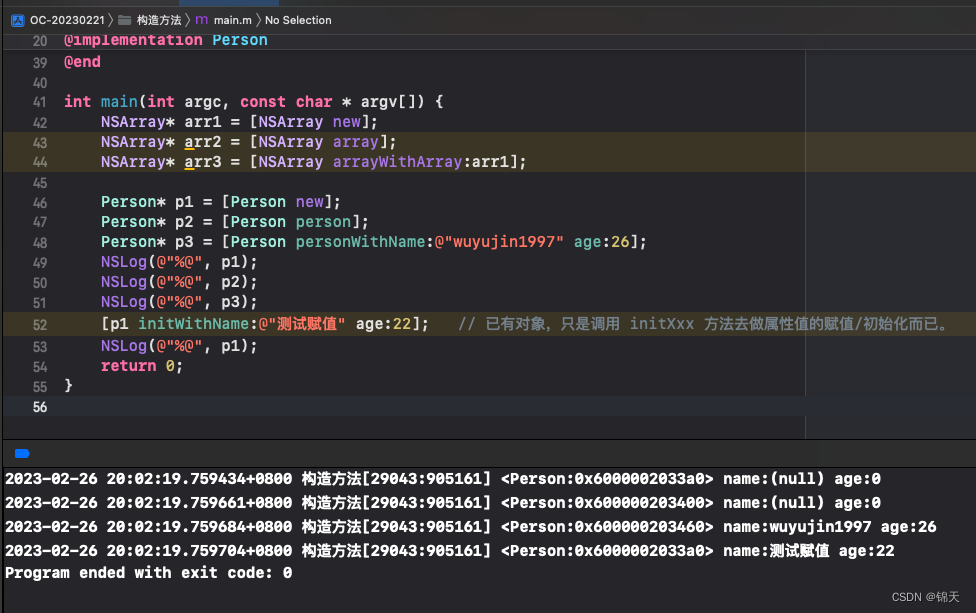
Objective-C 构造方法的定义和声明规范
总目录 iOS开发笔记目录 从一无所知到入门 文章目录源码中 NSArray 的构造方法与命名规律自定义类的构造方法命名截图代码输出源码中 NSArray 的构造方法与命名规律 interface NSArray<ObjectType> (NSArrayCreation) (instancetype)array;(instancetype)arrayWithObject…...

Matlab图像处理学习笔记
Matlab图像处理 Matlab基础 数组 1、向量 生成方式1: x = [值] x = [1 2 3] % 行向量 y = [4; 5; 6] % 列向量 z = x % 行向量转列向量...
——迭代器的基础理论知识)
笔记(三)——迭代器的基础理论知识
迭代器是一种检查容器内元素并且遍历容器内元素的数据类型。它提供对一个容器中的对象的访问方法,并且定义了容器中对象的范围。一、vector容器的iterator类型vector容器的迭代器属于随机访问迭代器,一次可以移动多个位置。vector<int>::iterator …...
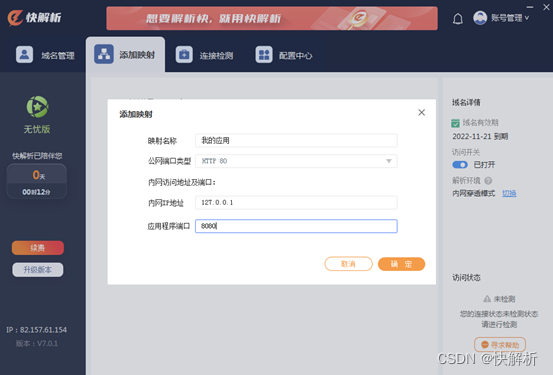
没有公网ip怎么外网访问nas?快解析内网端口映射到公网
对于NAS用户而言,外网访问是永远绕不开的话题。拥有NAS后的第一个问题,就是搞定NAS的外网访问。不过众所周知,并不是所有的小伙伴都能得到公网IP,由于IPV4资源的枯竭,一般不会被分配到公网IP。公网IP在很大程度上除了让…...
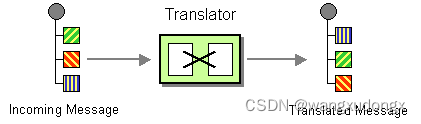
spring integration使用:消息转换器
系列文章目录 …TODO spring integration开篇:说明 …TODO spring integration使用:消息路由 spring integration使用:消息转换器 spring integration使用:消息转换器系列文章目录前言消息转换器(或者叫翻译器&#x…...
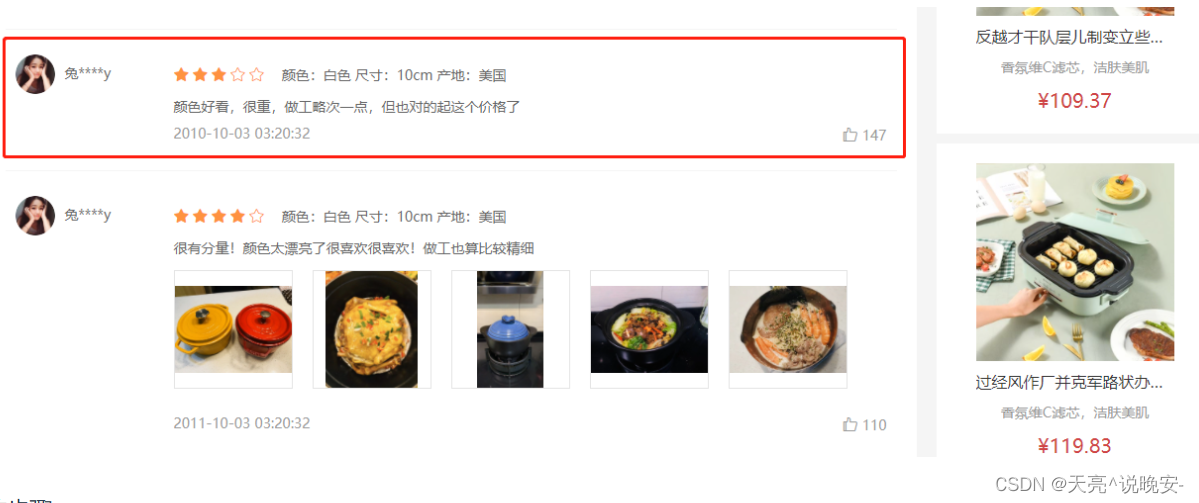
Vue3电商项目实战-商品详情模块7【21-商品详情-评价组件-头部渲染、22-商品详情-评价组件-实现列表】
文章目录21-商品详情-评价组件-头部渲染22-商品详情-评价组件-实现列表21-商品详情-评价组件-头部渲染 目的:根据后台返回的评价信息渲染评价头部内容。 yapi 平台可提供模拟接口,当后台接口未开发完毕或者没有数据的情况下,可以支持前端的开…...

地址,指针,指针变量是什么?他们的区别?符号(*)在不同位置的解释?
指针是C语言中的一个重要概念,也是C语言的一个重要特色;使用指针,可以使程序简洁、紧凑、高效。不掌握指针,就没有掌握C语言的精华。 目录 一、定义 1.1地址 1.2指针 1.3指针变量 1.4指针和指针变量的区别 二、使用指针变量…...
【MongoDB】一、MongoDB的安装与部署
【MongoDB】一、MongoDB的安装与部署实验目的实验内容实验步骤一、下载MongoDB安装包二、创建文件夹data及子文件夹db和log三、启动MongDB服务1. 在命令行窗口执行启动MongoDB服务命令2. 打开mongodb.log3. 打开浏览器进行启动验证四、登录MongoDB五、配置环境变量六、将MongDB…...

时间窗约束下的取送货路径优化:模型、挑战与实战解析
1. 时间窗约束下的取送货问题是什么? 想象一下你每天使用的快递服务:快递小哥需要从仓库取件,然后在指定时间范围内送到你家。这就是典型的时间窗约束取送货问题(PDPTW)。但现实情况往往更复杂——比如网约车拼车场景&…...

QtWebApp实战指南【构建高效HTTP服务的Qt解决方案】
1. QtWebApp入门:从零搭建HTTP服务器 第一次接触QtWebApp时,我被它的轻量级设计惊艳到了。这个基于Qt网络模块的库,能让C开发者像搭积木一样快速构建HTTP服务。与常见的Web框架不同,QtWebApp没有复杂的依赖链,一个pri文…...
)
Windows 11 + RTX 40系显卡,手把手带你搞定3D Gaussian Splatting复现(附CUDA版本选择避坑指南)
Windows 11 RTX 40系显卡实战3D Gaussian Splatting:从环境配置到可视化全流程指南 当最新硬件遇上前沿3D重建技术,往往既带来性能红利也暗藏兼容性陷阱。本文将带你用RTX 40系显卡在Windows 11上完整复现3D Gaussian Splatting(3DGS&#x…...

QtCreator文件命名避坑指南:取消默认小写设置的正确姿势
QtCreator文件命名避坑指南:取消默认小写设置的正确姿势 在Qt开发中,文件命名规范往往直接影响项目的可维护性和团队协作效率。许多开发者在使用QtCreator创建新文件时,都曾遇到过这样的困扰:明明输入了大写字母开头的类名&#x…...

用Python实战随机森林回归:从数据准备到模型评估的完整流程
Python实战随机森林回归:从数据清洗到模型调优的全流程指南 在数据科学领域,随机森林算法因其出色的预测能力和易用性,已成为解决回归问题的首选工具之一。不同于教科书式的理论讲解,本文将带您亲历一个完整的数据分析项目&#x…...

嵌入式ARM方向毕设入门指南:从开发环境搭建到第一个裸机程序
最近在帮学弟学妹们看嵌入式方向的毕业设计,发现很多同学卡在了第一步:开发环境都搭不起来,或者对着芯片型号一脸茫然。今天我就以最主流的ARM Cortex-M平台(比如STM32)为例,梳理一份从零到一的实战指南&am…...

立知模型性能优化指南:GPU加速与批量处理技巧
立知模型性能优化指南:GPU加速与批量处理技巧 1. 这不是调参,是让模型真正跑起来 你刚部署好 lychee-rerank-mm,输入一张图加几句话,等了七八秒才出分——这感觉熟悉吗?别急着怀疑模型能力,问题大概率不在…...

Cursor 的 .cursorrules 终极配置指南:写出让 AI 秒懂项目的规则文件
分类:前端工具 | 标签:Cursor、cursorrules、AI编程、前端开发、效率提升 作为前端工程师,用好 Cursor 能显著提升开发效率。而 .cursorrules(以及新版 .cursor/rules/)就是让 AI 真正「懂」你项目的关键。本文从概念、语法、到 Vue3/React/小程序等不同技术栈的配置,再到…...

Prompt Engineering入门指南:从入门到精通的实战笔记
👋 大家好,欢迎来到我的技术博客! 📚 在这里,我会分享学习笔记、实战经验与技术思考,力求用简单的方式讲清楚复杂的问题。 🎯 本文将围绕人工智能这个话题展开,希望能为你带来一些启…...

ReAct模式实战解析:从接口调用到智能决策的完整流程
1. ReAct模式入门:从理论到实践 ReAct(Reasoning and Acting)模式是当前大模型应用中的热门技术框架,它通过推理-行动-观察的循环机制,让AI系统能够像人类一样逐步解决问题。我第一次接触这个概念时,发现它…...