HashMap 面试专题
1、HashMap 的底层结构
①JDK1.8 以前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的hashCode 函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
②JDK1.8
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。

拉链法
Java中HashMap 是利用“拉链法”处理 HashCode 的碰撞问题。在调用 HashMap 的 put 方法或 get 方法时,都会首先调用 hashcode 方法,去查找相关的 key,当有冲突时,再调用 equals 方法。hashMap 基于 hasing 原理,我们通过 put 和 get 方法存取对象。当我们将键值对传递给 put 方法时,他调用键对象的 hashCode() 方法来计算 hashCode,然后找到 bucket(哈希桶)位置来存储对象。当获取对象时,通过键对象的 equals() 方法找到正确的键值对,然后返回值对象。HashMap 使用链表来解决碰撞问题,当碰撞发生了,对象将会存储在链表的下一个节点中。hashMap 在每个链表节点存储键值对对象。
2、HashMap 的 put 和 get 方法
map.put(k,v) 实现原理:
①先将键值对 k,v 封装到 Node 对象中;
②底层会调用 k 的 hashCode() 方法得出 hash 值;
③通过哈希函数,将 hash 值转换为数组的下标;
④进行比较:下标位置如果没有任何元素,就把 Node 添加到这个位置上;如果下标位置上有链表,此时会拿着 k 和链表上的每一个节点的 k 用 equals() 方法进行比较(因为 Map 是不可重复的),如果没有重复的新节点就会加到链表末尾,否则则会覆盖有相同 k 值的节点。
map.get(k) 实现原理:
①调用 k 的 hashCode() 方法得出 hash 值;
②通过哈希函数,将 hash 值转换为数组的下标;
③进行比较:下标位置如果没有任何元素,返回 null,如果下标位置上有链表,此时会拿着 k 和链表上的每一个节点的 k 用 equals() 方法进行比较,如果结果都是 false,则返回 null;如果有一个节点用了equals 方法后结果为 true,则返回这个节点的 value 值。
3、为什么重写 equals() 就一定要重写 hashCode() 方法?
如果两个对象相同(即用 equals 比较返回 true),那么它们的 hashCode 值一定要相同!!!!;
如果两个对象不同(即用 equals 比较返回 false),那么它们的 hashCode 值可能相同也可能不同;
如果两个对象的 hashCode 相同(存在哈希冲突),那么它们可能相同也可能不同(即 equals 比较可能是false 也可能是 true);
如果两个对象的 hashCode 不同,那么他们肯定不同(即用 equals 比较返回 false)。
对于对象集合的判重,如果一个集合含有 10000 个对象实例,仅仅使用 equals() 方法的话,那么对于一个对象判重就需要比较 10000 次,随着集合规模的增大,时间开销是很大的。
但是同时使用哈希表的话,就能快速定位到对象的大概存储位置,并且在定位到大概存储位置后,后续比较过程中,如果两个对象的 hashCode 不相同,也不再需要调用 equals() 方法,从而大大减少了 equals()比较次数。
所以从程序实现原理上来讲的话,既需要 equals() 方法,也需要 hashCode() 方法。那么既然重写了equals(),那么也要重写 hashCode() 方法,以保证两者之间的配合关系。
我们在实际应用过程中,如果仅仅重写了 equals(),而没有重写 hashCode() 方法,会出现什么情况?
字段属性值完全相同的两个对象因为 hashCode 不同,所以在 hashMap 中的 table 数组的下标不同,从而这两个对象就会同时存在于集合中,所以重写 equals() 就一定要重写 hashCode() 方法。
4、HashMap 为什么线程不安全,想要线程安全怎么办?
HashMap 的线程不安全主要体现在下面两个方面:
①在 JDK1.7 中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
②在 JDK1.8 中,在并发执行 put 操作时会发生数据覆盖的情况。
想要线程安全,可以使用 HashTable 或 ConcurrentHashMap。
5、HashMap 与 HashTable 的区别
①线程是否安全: HashMap 是非线程安全的,HashTable 是线程安全的,因为 HashTable 内部的方法基本都经过 synchronized 修饰。(如果要保证线程安全的话就使用 ConcurrentHashMap 吧!);
② 效率:因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
③对 Null key 和 Null value 的支持: HashMap可以存储 null 的key和value,但null作为键只能有一个,null作为值可以有多个;HashTable 不允许有 null 键和 null 值,否则会抛出 NullPointerException。
④初始容量大小和每次扩充容量大小的不同:1、创建时如果不指定容量初始值,Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap 默认的初始化大小为 16 。之后每次扩充,容量变为原来的 2 倍。2、 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为 2 的幂次方大小(HashMap 中的 tableSizeFor() 方法保证)。也就是说 HashMap 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
⑤底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8,将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
6、HashMap 扩容
①首先判断 OldCap 有没有超过最大值;
②当 hashmap 中的元素个数超过 数组大小 * loadFactor 时,就会进行数组扩容,loadFactor 的默认值为 0.75,也就是说,默认情况下,数组大小为 16,那么当 hashmap 中元素个数超过 16 * 0.75=12 的时候,就把数组的大小扩展为 2 * 16=32,即扩大一倍;
③然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知 hashmap 中元素的个数,那么预设元素的个数能够有效的提高 hashmap 的性能。比如说,我们有 1000 个元素 new HashMap(1000), 但是理论上来讲 new HashMap(1024) 更合适,不过上面已经说过,即使是 1000,hashmap 也自动会将其设置为 1024;
但是 new HashMap(1024) 还不是更合适的,因为 0.75*1000 < 1000, 也就是说为了让 0.75 * size > 1000, 我们必须这样 new HashMap(2048)才最合适,既考虑了 & 的问题,也避免了 resize 的问题。
7、为什么是 2 的幂次方
我们首先可能会想到采用 % 取余的操作来实现。但是,重点来了 :“取余 (%) 操作中如果除数是 2 的幂次则等价于与其除数减一的与 (&) 操作(也就是说 hash % length == hash & (length - 1)的前提是 length 是 2 的 n 次方)。” 并且采用二进制位操作 &,相对于 % 能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
8、为什么会产生 Hash 碰撞
key 值无界(任意的),计算出对应的 hash 值有界。
9、红黑树
①为什么使用红黑树,不使用其他的树?
因为红黑树不追求完美的平衡,只要求达到部分平衡,可以减少增删结点时的左旋转和右旋转的次数。
②为什么 JDK8 中 HashMap 底层使用红黑树?
因为链表查询的时间复杂度是 O(n),红黑树的时间复杂度为 O(logn)。可以提升效率。
③为什么链表长度大于阈值 8 时才将链表转为红黑树?
因为树结点占用的存储空间是普通结点的两倍。因此红黑树比链表更加耗费空间。结点较少的时候,时间复杂度上链表不会比红黑树高太多,但是能大大减少空间。
当链表元素个数大于等于 8 时,链表换成树结构;若桶中链表元素个数小于等于 6 时,树结构还原成链表。因为红黑树的平均查找长度是 log(n),长度为 8 的时候,平均查找长度为 3,如果继续使用链表,平均查找长度为 8/2=4,这才有转换为树的必要。
④当长度减小的时候红黑树还会转换为链表吗
如果 loHead 不为空,且链表长度小于等于 6 ,则将红黑树转成链表。
10、HashMap 的长度为什么是 2 的幂次方
“取余 (%) 操作中如果除数是 2 的幂次则等价于与其除数减一的与 (&) 操作(也就是说 hash % length == hash & (length - 1)的前提是 length 是 2 的 n 次方)。” 并且采用二进制位操作 &,相对于 % 能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
11、ConcurrentHashMap 和 HashTable 的区别
底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采用分段的数组+链表实现,JDK1.8 采用的数据结构跟 HashMap1.8 的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用数组+链表的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
实现线程安全的方式(重要):
① 在 JDK1.7 的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段 (Segment) ,每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率,在读的过程中,是不会进行加锁的。 JDK1.8 的时候已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6 以后对 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
② Hashtable(同一把锁):使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈,效率越低。

JDK1.8 的 ConcurrentHashMap(TreeBin:红黑树结点,Node:链表节点)。ConcurrentHashMap 取消了 Segment 分段锁,采用 CAS 和 synchronized 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))
synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。

相关文章:
HashMap 面试专题
1、HashMap 的底层结构 ①JDK1.8 以前 JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的hashCode 函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度…...
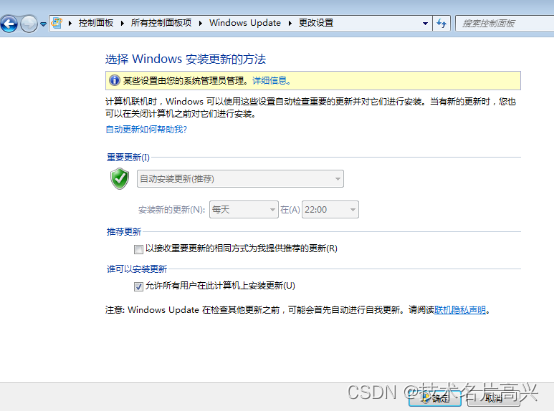
域组策略自动更新实验报告
域组策略自动更新实验报告 域组策略自动更新实验报告 作者: 高兴源 1要求、我公司为了完善员工的安全性和系统正常漏洞的维护,所以采用域组策略自动更新的方法来提高账户安全性,减少了用户的错误。 1.实验环境如下1台2008r2一台创建域,一台wi…...

Java自定义生成二维码(兼容你所有的需求)
1、概述作为Java开发人员,说到生成二维码就会想到zxing开源二维码图像处理库,不可否认的是zxing确实很强大,但是实际需求中会遇到各种各样的需求是zxing满足不了的,于是就有了想法自己扩展zxing满足历史遇到的各种需求,…...

Spring事务的隔离级别
事务隔离级别解决的是多个事务同时调⽤⼀个数据库的问题 事务传播机制解决的是⼀个事务在多个节点(⽅法)中传递的问题 事务的特性: 隔离性:多个事务在并发执行的时候,多个事务执行的一个行为模式,当一个事务执行的时候,另一个事务执行的一个行…...

JVM系统优化实践(4):以支付系统为例
您好,我是湘王,这是我的CSDN博客,欢迎您来,欢迎您再来~前面说过,JVM会将堆内存划分为年轻代、老年代两个区域。年轻代会将创建和使用完之后马上就要回收的对象放在里面,而老年代则将创建之后需要…...

16- TensorFlow实现线性回归和逻辑回归 (TensorFlow系列) (深度学习)
知识要点 线性回归要点: 生成线性数据: x np.linspace(0, 10, 20) np.random.rand(20)画点图: plt.scatter(x, y)TensorFlow定义变量: w tf.Variable(np.random.randn() * 0.02)tensor 转换为 numpy数组: b.numpy()定义优化器: optimizer tf.optimizers.SGD()定义损失: …...

无自动化测试系统设计方法论
灵活 敏捷 迭代。 自动化测试 辩思 测试必不可少 想想看没有充分测试的代码, 哪一次是一次过的? 哪一次不需要经历下测试的鞭挞? 不要以为软件代码容易改, 就对于质量不切实际的自信—那是自大! 不适用自动化测试的case 遗留系统。太多的依赖方, 不想用过多的mock > …...
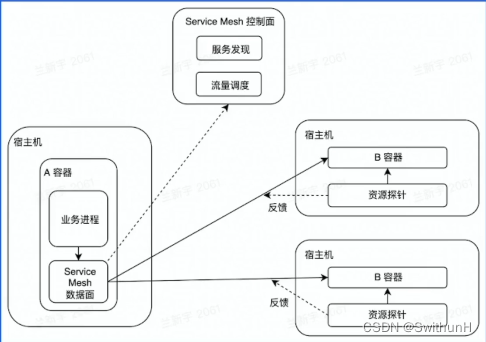
架构初探-学习笔记
1 什么是架构 有关软件整体结构与组件的抽象描述,用于指导软件系统各个方面的设计。 1.1 单机架构 所有功能都实现在一个进程里,并部署在一台机器上。 1.2 单体架构 分布式部署单机架构 1.3 垂直应用架构 按应用垂直切分的单体架构 1.4 SOA架构 将…...

在成都想转行IT,选择什么专业比较好?
很多创新型的互联网服务公司的核心其实都是软件,创新的基础、运行的支撑都是软件。例如,软件应用到了出租车行业,就形成了巅覆行业的滴滴;软件应用到了金融领域,就形成互联网金融;软件运用到餐饮行业,就形成美团;软件运…...
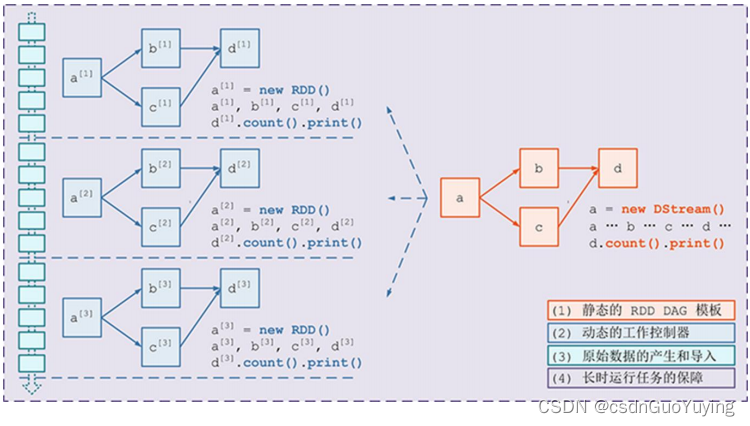
【Spark分布式内存计算框架——Spark Streaming】4.入门案例(下)Streaming 工作原理
2.3 Streaming 工作原理 SparkStreaming处理流式数据时,按照时间间隔划分数据为微批次(Micro-Batch),每批次数据当做RDD,再进行处理分析。 以上述词频统计WordCount程序为例,讲解Streaming工作原理。 创…...
2、算法先导---思维能力与工具
题目 碎纸片的拼接复原(2013B) 内容 破碎文件的拼接在司法物证复原、历史文献修复以及军事情报获取等领域都有着重要的应用。传统上,拼接复原工作需由人工完成,准确率较高,但效率很低。特别是当碎片数量巨大,人工拼接很难在短时…...

WordPress 函数:add_theme_support() 开启主题自定义功能(全面)
add_theme_support() 用于在我们的当前使用的主题添加一些特殊的功能,函数一般写在主题的functions.php文件中,当然也可以再插件中使用钩子来调用该函数,如果是挂在钩子上,那他必须挂在after_setup_theme钩子上,因为 i…...

Winform控件开发(16)——Timer(史上最全)
前言: Timer控件的作用是按用户定义的时间间隔引发事件的计时器,说的直白点就是,他就像一个定时炸弹一样到了一定时间就爆炸一次,区别在于定时炸弹炸完了就不会再次爆炸了,但是Timer这个计时器到了下一个固定时间还会触发一次,上面那张图片就是一个典型的计时器,该定时器…...

游戏高度可配置化:通用数据引擎(data-e)及其在模块化游戏开发中的应用构想图解
游戏高度可配置化:通数据引擎在模块化游戏开发中的应用构想图解 ygluu 码客 卢益贵 目录 一、前言 二、模块化与插件 1、常规模块化 2、插件式模块化(插件开发) 三、通用数据引擎理论与构成 1、名字系统(数据类型…...
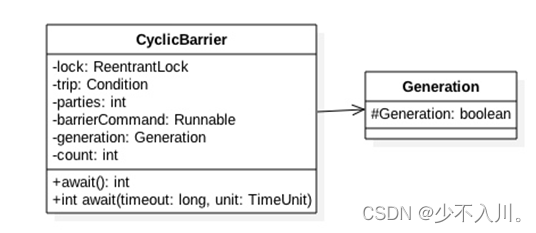
CountDownLatch与CyclicBarrier原理剖析
1.CountDownLatch 1.1 什么是CountDownLatch CountDownLatch是一个同步工具类,用来协调多个线程之间的同步,或者说起到线程之间的通信(而不是用作互斥的作用)。 CountDownLatch能够使一个线程在等待另外一些线程完成各自工作之…...
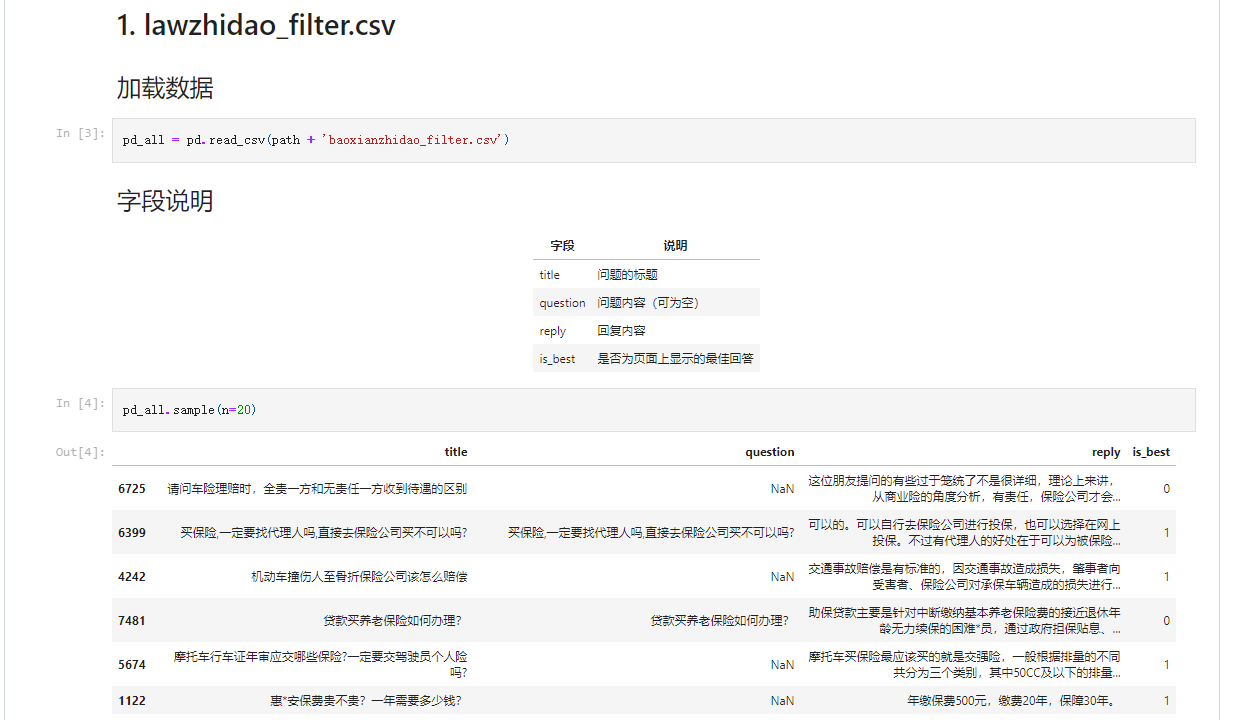
NLP中的对话机器人——预训练基准模型
引言 本文是七月在线《NLP中的对话机器人》的视频笔记,主要介绍FAQ问答型聊天机器人的实现。 场景二 上篇文章中我们解决了给定一个问题和一些回答,从中找到最佳回答的任务。 在场景二中,我们来实现: 给定新问题,从…...

C语言学习及复习笔记-【14】C文件读写
14 C文件读写 14.1打开文件 您可以使用 fopen( ) 函数来创建一个新的文件或者打开一个已有的文件,这个调用会初始化类型 FILE 的一个对象,类型 FILE包含了所有用来控制流的必要的信息。下面是这个函数调用的原型: FILE *fopen( const char…...

模拟退火算法优化灰色
clc; clear; close all; warning off; %% tic T01000; % 初始温度 Tend1e-3; % 终止温度 L200; % 各温度下的迭代次数(链长) q0.9; %降温速率 X[16.4700 96.1000 16.4700 94.4400 20.0900 92.5400 22.3900 93.3700 25.…...
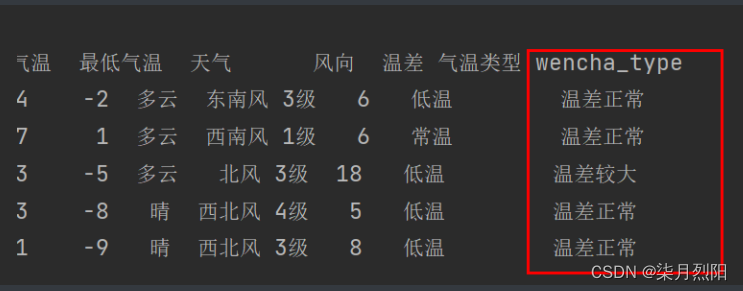
Pandas怎么添加数据列删除列
Pandas怎么添加数据列 1、直接赋值 # 1、直接赋值df.loc[:, "最高气温"] df["最高气温"].str.replace("℃", "").astype("int32")df.loc[:, "最低气温"] df["最低气温"].str.replace("℃"…...

C++类和对象:构造函数和析构函数
目录 一. 类的六个默认成员函数 二. 构造函数 2.1 什么是构造函数 2.2 编译器自动生成的默认构造函数 2.3 构造函数的特性总结 三. 析构函数 3.1 什么是析构函数 3.2 编译器自动生成的析构函数 3.3 析构函数的特性总结 一. 类的六个默认成员函数 对于任意一个C类&…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...
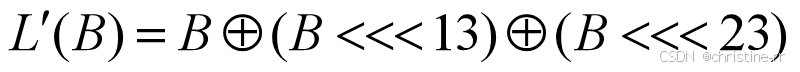
密码学基础——SM4算法
博客主页:christine-rr-CSDN博客 专栏主页:密码学 📌 【今日更新】📌 对称密码算法——SM4 目录 一、国密SM系列算法概述 二、SM4算法 2.1算法背景 2.2算法特点 2.3 基本部件 2.3.1 S盒 2.3.2 非线性变换 编辑…...