【Spark分布式内存计算框架——Spark Streaming】4.入门案例(下)Streaming 工作原理
2.3 Streaming 工作原理
SparkStreaming处理流式数据时,按照时间间隔划分数据为微批次(Micro-Batch),每批次数据当做RDD,再进行处理分析。

以上述词频统计WordCount程序为例,讲解Streaming工作原理。
创建 StreamingContext
当SparkStreaming流式应用启动(streamingContext.start)时,首先创建StreamingContext流式上下文实例对象,整个流式应用环境构建,底层还是SparkContext。

当StreamingContext对象构建以后,启动接收器Receiver,专门从数据源端接收数据,此接收器作为Task任务运行在Executor中,一直运行(Long Runing),一直接收数据。
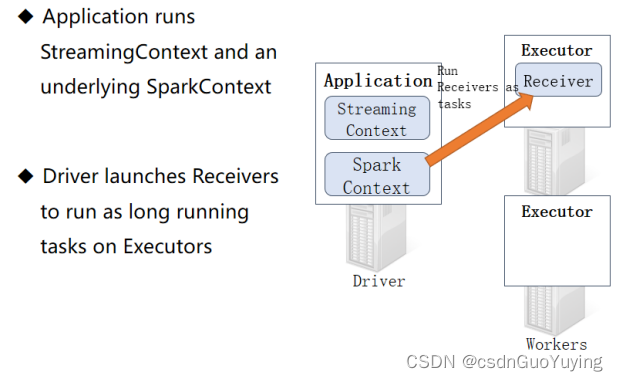
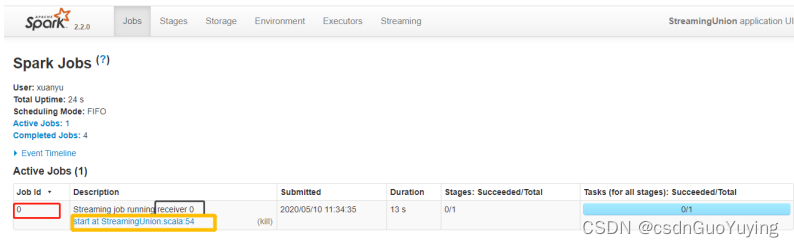
从WEB UI界面【Jobs Tab】可以看到【Job-0】是一个Receiver接收器,一直在运行,以Task方式运行,需要1Core CPU。
可以从多个数据源端实时消费数据进行处理,例如从多个TCP Socket接收数据,对每批次数据进行词频统计,使用DStream#union函数合并接收数据流,演示代码如下:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 从TCP Socket 中读取数据,对每批次(时间为5秒)数据进行词频统计,将统计结果输出到控制台。
* TODO: 从多个Socket读取流式数据,进行union合并
*/
object StreamingDStreamUnion {
def main(args: Array[String]): Unit = {
// TODO: 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[4]")
// b.创建流式上下文对象, 传递SparkConf对象,TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// TODO: 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream01: DStream[String] = ssc.socketTextStream("node1.itcast.cn", 9999)
val inputDStream02: DStream[String] = ssc.socketTextStream("node1.itcast.cn", 9988)
// 合并两个DStream流
val inputDStream: DStream[String] = inputDStream01.union(inputDStream02)
// TODO: 3. 对每批次的数据进行词频统计
val resultDStream: DStream[(String, Int)] = inputDStream
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
// TODO: 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.print(10)
// TODO: 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
接收器接收数据
启动每个接收器Receiver以后,实时从数据源端接收数据(比如TCP Socket),也是按照时间间隔将接收的流式数据划分为很多Block(块)。
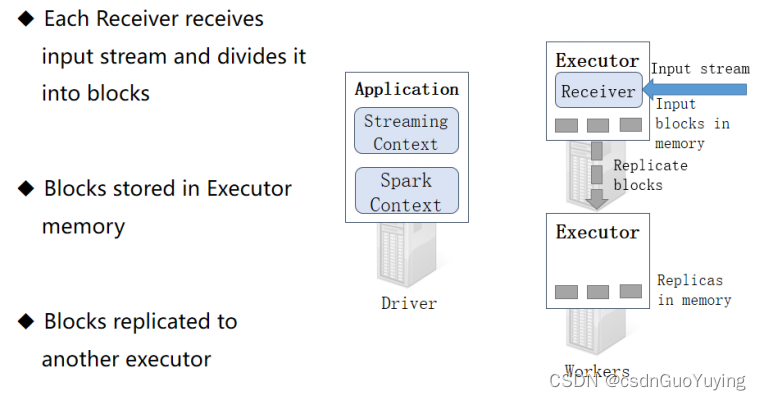
接收器 Receiver划分流式数据的时间间隔BlockInterval ,默认值为 200ms,通过属性【spark.streaming.blockInterval】设置。接收器将接收的数据划分为Block以后,按照设置的存储级别对Block进行存储,从TCP Socket中接收数据默认的存储级别为:MEMORY_AND_DISK_SER_2,先存储内存,不足再存储磁盘,存储2副本。
从TCP Socket消费数据时可以设置Block存储级别,演示代码如下:
// TODO: 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream(
"node1.itcast.cn", //
9999, //
// TODO: 设置Block存储级别为先内存,不足磁盘,副本为1
storageLevel = StorageLevel.MEMORY_AND_DISK
)
汇报接收Block报告
接收器Receiver将实时汇报接收的数据对应的Block信息,当BatchInterval时间达到以后,StreamingContext将对应时间范围内数据block当做RDD,加载SparkContextt处理数据。
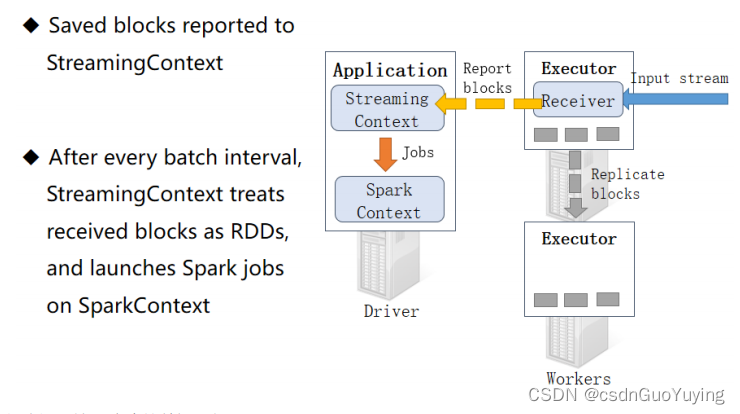
以此循环处理流式的数据,如下图所示:
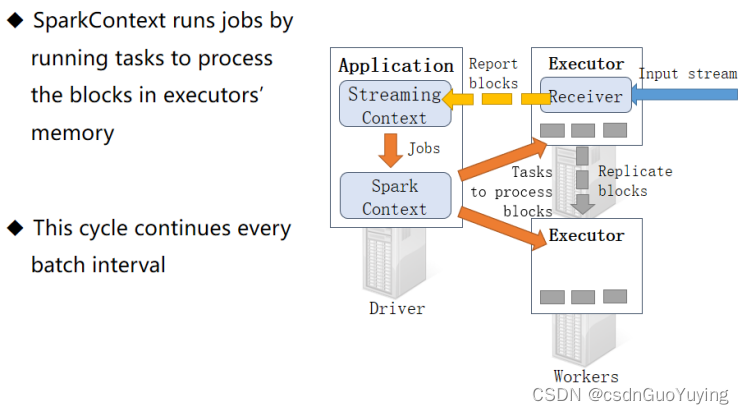
Streaming 工作原理总述
整个Streaming运行过程中,涉及到两个时间间隔:
- 批次时间间隔:BatchInterval
- 每批次数据的时间间隔,每隔多久加载一个Job;
- Block时间间隔:BlockInterval
- 接收器划分流式数据的时间间隔,可以调整大小哦,官方建议最小值不能小于50ms;
- 默认值为200ms,属性:spark.streaming.blockInterval,调整设置
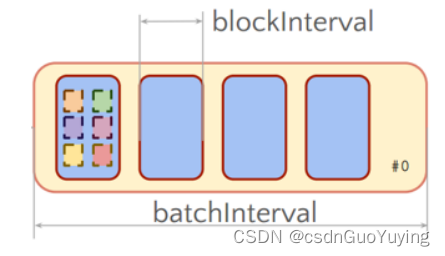
官方案例:
BatchInterval: 1s = 1000ms = 5 * BlockInterval
每批次RDD数据中,有5个Block,每个Block就是RDD一个分区数据
从代码层面结合实际数据处理层面来看,Streaming处理原理如下,左边为代码逻辑,右边为实际每批次数据处理过程。
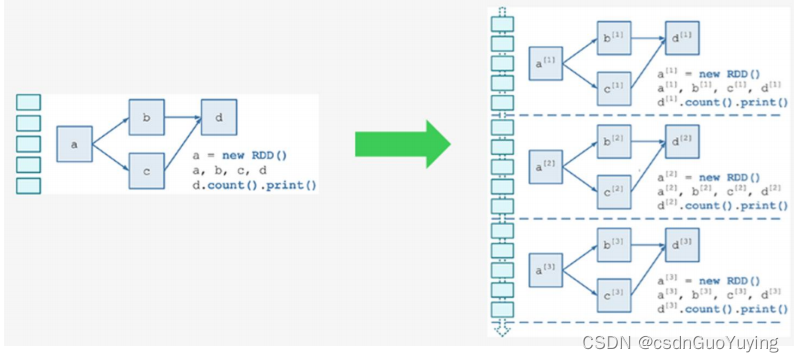
具体运行数据时,每批次数据依据代码逻辑执行。
// TODO: 3. 对每批次的数据进行词频统计
val resultDStream: DStream[(String, Int)] = inputDStream
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
// TODO: 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.print(10)
流式数据流图如下:
相关文章:
【Spark分布式内存计算框架——Spark Streaming】4.入门案例(下)Streaming 工作原理
2.3 Streaming 工作原理 SparkStreaming处理流式数据时,按照时间间隔划分数据为微批次(Micro-Batch),每批次数据当做RDD,再进行处理分析。 以上述词频统计WordCount程序为例,讲解Streaming工作原理。 创…...
2、算法先导---思维能力与工具
题目 碎纸片的拼接复原(2013B) 内容 破碎文件的拼接在司法物证复原、历史文献修复以及军事情报获取等领域都有着重要的应用。传统上,拼接复原工作需由人工完成,准确率较高,但效率很低。特别是当碎片数量巨大,人工拼接很难在短时…...

WordPress 函数:add_theme_support() 开启主题自定义功能(全面)
add_theme_support() 用于在我们的当前使用的主题添加一些特殊的功能,函数一般写在主题的functions.php文件中,当然也可以再插件中使用钩子来调用该函数,如果是挂在钩子上,那他必须挂在after_setup_theme钩子上,因为 i…...

Winform控件开发(16)——Timer(史上最全)
前言: Timer控件的作用是按用户定义的时间间隔引发事件的计时器,说的直白点就是,他就像一个定时炸弹一样到了一定时间就爆炸一次,区别在于定时炸弹炸完了就不会再次爆炸了,但是Timer这个计时器到了下一个固定时间还会触发一次,上面那张图片就是一个典型的计时器,该定时器…...

游戏高度可配置化:通用数据引擎(data-e)及其在模块化游戏开发中的应用构想图解
游戏高度可配置化:通数据引擎在模块化游戏开发中的应用构想图解 ygluu 码客 卢益贵 目录 一、前言 二、模块化与插件 1、常规模块化 2、插件式模块化(插件开发) 三、通用数据引擎理论与构成 1、名字系统(数据类型…...
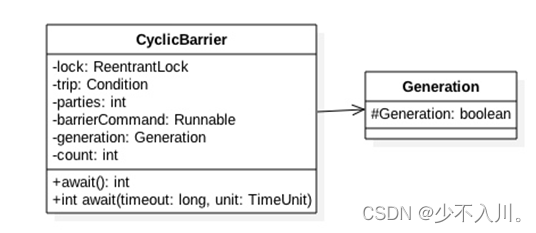
CountDownLatch与CyclicBarrier原理剖析
1.CountDownLatch 1.1 什么是CountDownLatch CountDownLatch是一个同步工具类,用来协调多个线程之间的同步,或者说起到线程之间的通信(而不是用作互斥的作用)。 CountDownLatch能够使一个线程在等待另外一些线程完成各自工作之…...
NLP中的对话机器人——预训练基准模型
引言 本文是七月在线《NLP中的对话机器人》的视频笔记,主要介绍FAQ问答型聊天机器人的实现。 场景二 上篇文章中我们解决了给定一个问题和一些回答,从中找到最佳回答的任务。 在场景二中,我们来实现: 给定新问题,从…...

C语言学习及复习笔记-【14】C文件读写
14 C文件读写 14.1打开文件 您可以使用 fopen( ) 函数来创建一个新的文件或者打开一个已有的文件,这个调用会初始化类型 FILE 的一个对象,类型 FILE包含了所有用来控制流的必要的信息。下面是这个函数调用的原型: FILE *fopen( const char…...

模拟退火算法优化灰色
clc; clear; close all; warning off; %% tic T01000; % 初始温度 Tend1e-3; % 终止温度 L200; % 各温度下的迭代次数(链长) q0.9; %降温速率 X[16.4700 96.1000 16.4700 94.4400 20.0900 92.5400 22.3900 93.3700 25.…...
Pandas怎么添加数据列删除列
Pandas怎么添加数据列 1、直接赋值 # 1、直接赋值df.loc[:, "最高气温"] df["最高气温"].str.replace("℃", "").astype("int32")df.loc[:, "最低气温"] df["最低气温"].str.replace("℃"…...

C++类和对象:构造函数和析构函数
目录 一. 类的六个默认成员函数 二. 构造函数 2.1 什么是构造函数 2.2 编译器自动生成的默认构造函数 2.3 构造函数的特性总结 三. 析构函数 3.1 什么是析构函数 3.2 编译器自动生成的析构函数 3.3 析构函数的特性总结 一. 类的六个默认成员函数 对于任意一个C类&…...
【Stata】从入门到精通.零基础小白必学的教程,一学就fei
视频教程移步:https://www.bilibili.com/video/BV1hK4y1d714/?p4&spm_id_frompageDriver&vd_sourcecc8074e9c81a225f214226065db53d32P3 第二讲 Stata处理数据全流程(上) P3 - 01:37内置数据 file example datasets使用…...

【RuoYi优化】调整JVM启动内存
📔 笔记介绍 大家好,千寻简笔记是一套全部开源的企业开发问题记录,毫无保留给个人及企业免费使用,我是作者星辰,笔记内容整理并发布,内容有误请指出,笔记源码已开源,前往Gitee搜索《chihiro-notes》,感谢您的阅读和关注。 作者各大平台直链: GitHub | Gitee | CSD…...

[架构模型]MVC模型详细介绍,并应用到unity中
简介: MVC模式是一种软件架构模式,它将应用程序分为三个主要部分:模型(Model)、视图(View)和控制器(Controller)。MVC模式的目标是实现应用程序的松耦合,以便…...

?? JavaScript 双问号(空值合并运算符)
?? JavaScript 双问号(空值合并运算符) 一、简述 在网上浏览 JavaScript 代码时或者学习其他代码时,可能会发现有的表达式用了两个问号(??)如下所示: let username; console.log(username ?? "Guest"…...
作业2.25----通过操作Cortex-A7核,串口输入相应的命令,控制LED灯进行工作
1.通过操作Cortex-A7核,串口输入相应的命令,控制LED灯进行工作 例如在串口输入led1on,开饭led1灯点亮 2.例如在串口输入led1off,开饭led1灯熄灭 3.例如在串口输入led2on,开饭led2灯点亮 4.例如在串口输入led2off,开饭led2灯熄灭 5.例如在串口输入led…...

0101基础概念-图-数据结构和算法(Java)
文章目录1 图1.1 定义1.2 4种图模型2 无向图2.1 定义2.2 术语后记1 图 1.1 定义 图是一种非线性的数据结构,表示多对多的关系。 图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V, E)…...

Linux基础命令和工具使用详解
Linux基础命令和工具使用详解一、grep搜索字符二、find查找文件三、ls 显示文件四、wc命令计算字数五、uptime机器启动时间负载六、ulimit用户资源七、curl http八、scp远程拷贝九、dos2unix和unix2dos十、sed 行处理10.1、简单模式10.2、替换模式十一、awk 列处理11.1、打印某…...

一个好的python文件可以有几种用途?
大家好鸭!我是小熊猫~ 这次来带大家浅浅回顾一点python小知识~ 源码资料电子书:点击此处跳转文末名片获取 python文件总共有两种用途: 一种是执行文件另一种是被当做模块导入 编写好的一个python文件可以有两种用途: 1. 脚本,…...

HDFS优化
单节点多块磁盘数据均衡 生成HDFS块均衡计划 hdfs diskbalancer -plan node1 执行均衡计划,node1.plan.json均衡计划文件 hdfs diskbalancer -execute node1.plan.json 查看当前均衡任务的执行情况 hdfs diskbalancer -query node1 取消均衡任务hdfs diskbalancer -cancel nod…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...