chinese_llama_aplaca训练和代码分析
训练细节 · ymcui/Chinese-LLaMA-Alpaca Wiki · GitHub中文LLaMA&Alpaca大语言模型+本地CPU/GPU训练部署 (Chinese LLaMA & Alpaca LLMs) - 训练细节 · ymcui/Chinese-LLaMA-Alpaca Wiki![]() https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E8%AE%AD%E7%BB%83%E7%BB%86%E8%8A%82中文LLaMA&Alpaca大语言模型词表扩充+预训练+指令精调 - 知乎在 大模型词表扩充必备工具SentencePiece一文中,我们提到了在目前开源大模型中,LLaMA无疑是最闪亮的星。但是,与 ChatGLM-6B 和 Bloom 原生支持中文不同。 LLaMA 原生仅支持 Latin 或 Cyrillic 语系,对于中文支…
https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E8%AE%AD%E7%BB%83%E7%BB%86%E8%8A%82中文LLaMA&Alpaca大语言模型词表扩充+预训练+指令精调 - 知乎在 大模型词表扩充必备工具SentencePiece一文中,我们提到了在目前开源大模型中,LLaMA无疑是最闪亮的星。但是,与 ChatGLM-6B 和 Bloom 原生支持中文不同。 LLaMA 原生仅支持 Latin 或 Cyrillic 语系,对于中文支…![]() https://zhuanlan.zhihu.com/p/631360711GitHub - liguodongiot/llm-action: 本项目旨在分享大模型相关技术原理以及实战经验。本项目旨在分享大模型相关技术原理以及实战经验。. Contribute to liguodongiot/llm-action development by creating an account on GitHub.
https://zhuanlan.zhihu.com/p/631360711GitHub - liguodongiot/llm-action: 本项目旨在分享大模型相关技术原理以及实战经验。本项目旨在分享大模型相关技术原理以及实战经验。. Contribute to liguodongiot/llm-action development by creating an account on GitHub.![]() https://github.com/liguodongiot/llm-action大模型词表扩充必备工具SentencePiece - 知乎背景随着ChatGPT迅速出圈,最近几个月开源的大模型也是遍地开花。目前,开源的大语言模型主要有三大类:ChatGLM衍生的大模型(wenda、 ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera…
https://github.com/liguodongiot/llm-action大模型词表扩充必备工具SentencePiece - 知乎背景随着ChatGPT迅速出圈,最近几个月开源的大模型也是遍地开花。目前,开源的大语言模型主要有三大类:ChatGLM衍生的大模型(wenda、 ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera…![]() https://zhuanlan.zhihu.com/p/630696264经过了一次预训练和一次指令精调,预训练使用扩充后的tokenizer,精调使用chinese_llama_aplaca的tokenizer。
https://zhuanlan.zhihu.com/p/630696264经过了一次预训练和一次指令精调,预训练使用扩充后的tokenizer,精调使用chinese_llama_aplaca的tokenizer。
1.词表扩充
为什么要扩充词表?直接在原版llama上用中文预训练不行吗?
原版LLaMA模型的词表大小是32K,其主要针对英语进行训练(具体详见LLaMA论文),对多语种支持不是特别理想(可以对比一下多语言经典模型XLM-R的词表大小为250K)。通过初步统计发现,LLaMA词表中仅包含很少的中文字符,所以在切词时会把中文切地更碎,需要多个byte token才能拼成一个完整的汉字,进而导致信息密度降低。比如,在扩展词表后的模型中,单个汉字倾向于被切成1个token,而在原版LLaMA中可能就需要2-3个才能组合成一个汉字,显著降低编解码的效率。
Chinese-LLaMA-Alpaca是在通用中文语料上训练了基于 sentencepiece 的20K中文词表并与原版LLaMA模型的32K词表进行合并,排除重复的token后,得到的最终中文LLaMA词表大小为49953。在模型精调(fine-tune)阶段 Alpaca 比 LLaMA 多一个 pad token,所以中文Alpaca的词表大小为49954。合并中文扩充词表并与原版LLaMA模型的32K词表,这里直接使用官方训练好的词表chinese_sp.model。
1.1 sentencepiece训练:
spm_train --input=/workspace/data/book/hongluomeng_clean.txt --model_prefix=/workspace/model/book/hongluomeng-tokenizer --vocab_size=4000 --character_coverage=0.9995 --model_type=bpe
- --input: 训练语料文件,可以传递以逗号分隔的文件列表。文件格式为每行一个句子。 无需运行tokenizer、normalizer或preprocessor。 默认情况下,SentencePiece 使用 Unicode NFKC 规范化输入。
- --model_prefix:输出模型名称前缀。 训练完成后将生成 <model_name>.model 和 <model_name>.vocab 文件。
- --vocab_size:训练后的词表大小,例如:8000、16000 或 32000
- --character_coverage:模型覆盖的字符数量,对于字符集丰富的语言(如日语或中文)推荐默认值为 0.9995,对于其他字符集较小的语言推荐默认值为 1.0。
- --model_type:模型类型。 可选值:unigram(默认)、bpe、char 或 word 。 使用word类型时,必须对输入句子进行pretokenized。
1.2 训练得到的model和原词表进行合并
转换格式
```
python convert_llama_weights_to_hf.py --input_dir /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base/ --model_size 7B --output_dir /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/
```词表合并
```
python merge_tokenizers.py --llama_tokenizer_dir /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/ --chinese_sp_model_file /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/scripts/merge_tokenizer/chinese_sp.model
```
merged_tokenizer_sp:为训练好的词表模型
merged_tokenizer_hf:HF格式训练好的词表模型
2.训练:
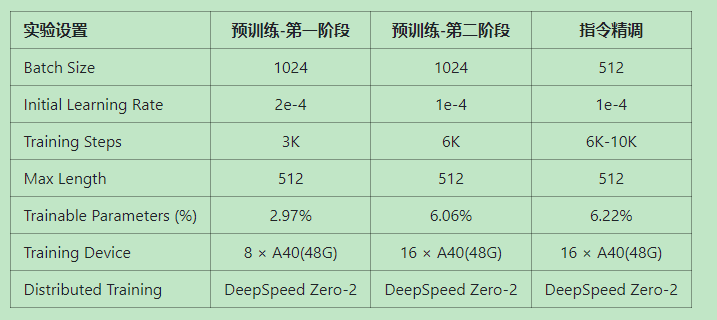
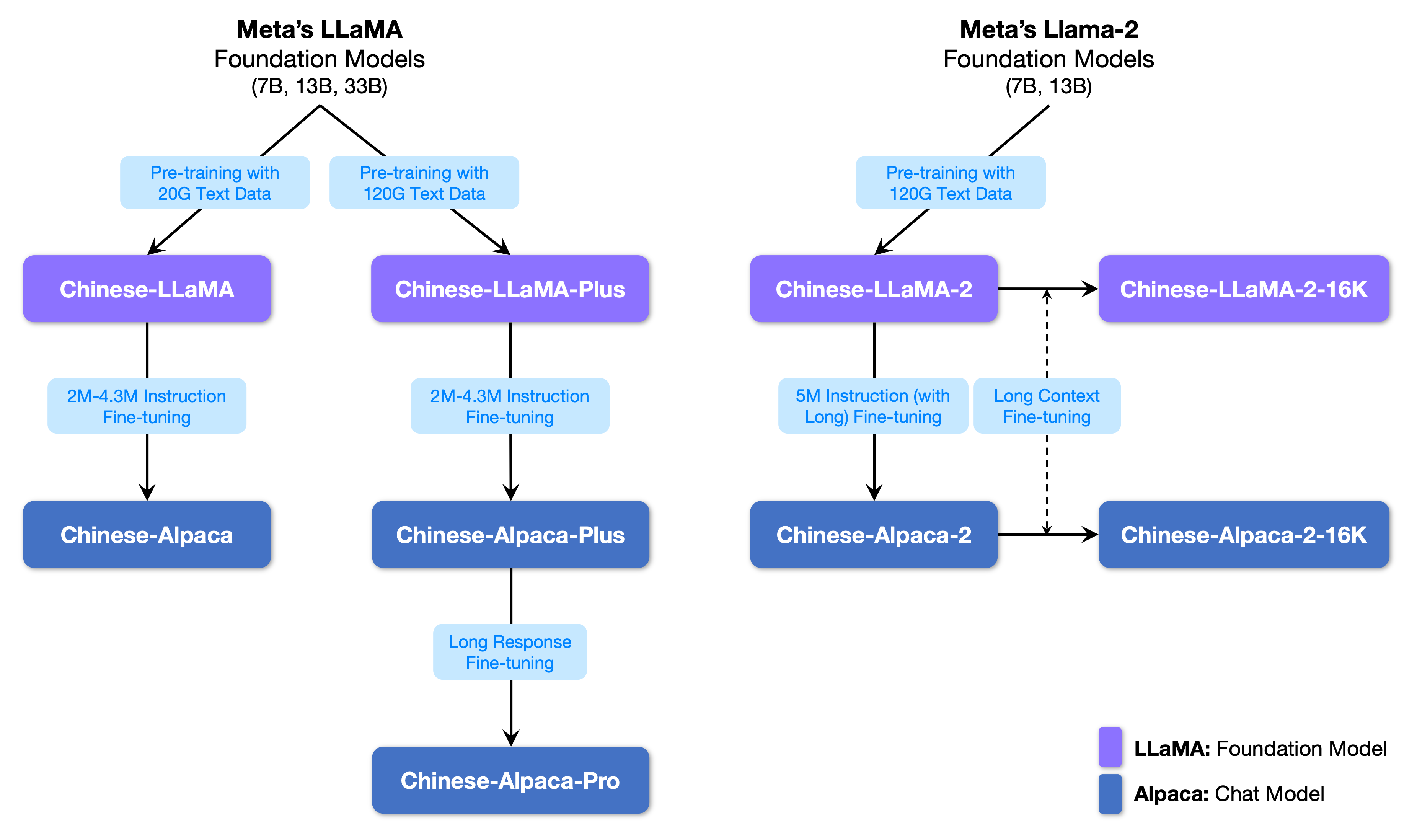
训练分三个阶段,第一和第二阶段属于预训练阶段,第三阶段属于指令精调。
2.1 第一阶段
冻结transformer参数,仅训练embedding,在尽量不干扰元模型的情况下适配新增的中文词向量。收敛速度较慢,如果不是有特别充裕的时间和计算资源,官方建议跳过该阶段,同时,官网并没有提供该阶段的代码,如果需要进行该阶段预训练,需要自行修改。
第一步:在训练之前,将除了Embedding之外的层设置为param.requires_grad = False,如下所示:
for name, param in model.named_parameters():if "model.embed_tokens" not in name:param.requires_grad = False
第二步:在训练的时候,在优化器中添加过滤器filter把requires_grad = False的参数过滤掉,这样在训练的时候,不会更新这些参数,如下所示:
optimizer = AdamW(filter(lambda p: p.requires_grad, model.parameters()))2.2 第二阶段
使用lora,为模型添加lora权重,训练embedding的同时更新lora权重
lr=2e-4
lora_rank=8
lora_alpha=32
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05pretrained_model=/home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/
chinese_tokenizer_path=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/scripts/merge_tokenizer/merged_tokenizer_hf/
dataset_dir=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/data/
data_cache=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/data_cache/
per_device_train_batch_size=1
per_device_eval_batch_size=1
gradient_accumulation_steps=1
training_step=100
output_dir=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/deepspeed_config_file=ds_zero2_no_offload.jsontorchrun --nnodes 1 --nproc_per_node 3 run_clm_pt_with_peft.py \--deepspeed ${deepspeed_config_file} \--model_name_or_path ${pretrained_model} \--tokenizer_name_or_path ${chinese_tokenizer_path} \--dataset_dir ${dataset_dir} \--data_cache_dir ${data_cache} \--validation_split_percentage 0.001 \--per_device_train_batch_size ${per_device_train_batch_size} \--per_device_eval_batch_size ${per_device_eval_batch_size} \--do_train \--seed $RANDOM \--fp16 \--num_train_epochs 1 \--lr_scheduler_type cosine \--learning_rate ${lr} \--warmup_ratio 0.05 \--weight_decay 0.01 \--logging_strategy steps \--logging_steps 10 \--save_strategy steps \--save_total_limit 3 \--save_steps 200 \--gradient_accumulation_steps ${gradient_accumulation_steps} \--preprocessing_num_workers 8 \--block_size 512 \--output_dir ${output_dir} \--overwrite_output_dir \--ddp_timeout 30000 \--logging_first_step True \--lora_rank ${lora_rank} \--lora_alpha ${lora_alpha} \--trainable ${lora_trainable} \--modules_to_save ${modules_to_save} \--lora_dropout ${lora_dropout} \--torch_dtype float16 \--gradient_checkpointing \--ddp_find_unused_parameters False
2.3 将lora模型合并到基础模型中
python merge_llama_with_chinese_lora.py --base_model /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/ --lora_model /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/pt_lora_model/ --output_type huggingface --output_dir /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/2.4 第三阶段:指令精调
训练数据是alpaca_data_zh_51k.json,词表扩充阶段得到的词表是49953,但是sft阶段,alpaca的词表比llama多一个pad token,所以是49954,注意这个chinese_llama_alpaca的词表直接从作者的项目中拉取。
lr=1e-4
lora_rank=8
lora_alpha=32
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05pretrained_model=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/
chinese_tokenizer_path=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/chinese_alpaca_tokenizer/
dataset_dir=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/data/
per_device_train_batch_size=1
per_device_eval_batch_size=1
gradient_accumulation_steps=8
output_dir=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_sft/
#peft_model=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_sft/
validation_file=/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/data/alpaca_valid.jsondeepspeed_config_file=ds_zero2_no_offload.jsontorchrun --nnodes 1 --nproc_per_node 3 run_clm_sft_with_peft.py \--deepspeed ${deepspeed_config_file} \--model_name_or_path ${pretrained_model} \--tokenizer_name_or_path ${chinese_tokenizer_path} \--dataset_dir ${dataset_dir} \--validation_split_percentage 0.001 \--per_device_train_batch_size ${per_device_train_batch_size} \--per_device_eval_batch_size ${per_device_eval_batch_size} \--do_train \--do_eval \--seed $RANDOM \--fp16 \--num_train_epochs 1 \--lr_scheduler_type cosine \--learning_rate ${lr} \--warmup_ratio 0.03 \--weight_decay 0 \--logging_strategy steps \--logging_steps 10 \--save_strategy steps \--save_total_limit 3 \--evaluation_strategy steps \--eval_steps 100 \--save_steps 2000 \--gradient_accumulation_steps ${gradient_accumulation_steps} \--preprocessing_num_workers 8 \--max_seq_length 512 \--output_dir ${output_dir} \--overwrite_output_dir \--ddp_timeout 30000 \--logging_first_step True \--lora_rank ${lora_rank} \--lora_alpha ${lora_alpha} \--trainable ${lora_trainable} \--modules_to_save ${modules_to_save} \--lora_dropout ${lora_dropout} \--torch_dtype float16 \--validation_file ${validation_file} \--gradient_checkpointing \--ddp_find_unused_parameters False
# --peft_path ${peft_model} 
2.5 将预训练权重lora和精调lora合并到基础模型上
python merge_llama_with_chinese_lora.py --base_model /home/image_team/image_team_docker_home/lgd/e_commerce_llm/weights/LLaMA-7B-Base-hf/ --lora_model /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir/pt_lora_model/,"/home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_sft/sft_lora_model/" --output_type huggingface --output_dir /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_all/2.6 前向推理
python inference_hf.py --base_model /home/image_team/image_team_docker_home/lgd/common/Chinese-LLaMA-Alpaca-main/output_dir_all/ --with_prompt --interactivetransformer==4.31.0
3.代码分析
3.1 预训练代码
parser = HfArgumentParser((ModelArgument,DataTrainArguments,MyTrainingArgument))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()set_seed(training_args.seed)
config = AutoConfig.from_pretrained(model_args.model_name_or_path,...)
tokenizer = LlamaTokenizer.from_pretrained(model_args.tokenizer_name_or_path,...)block_size = tokenizer.model_max_lengthwith training_args.main_process_first():files = [file.name for file in path.glob("*.txt")]for idx,file in enumerate(files):raw_dataset = load_dataset("text",data_file,cache_dir,keep_in_memory=False)tokenized_dataset = raw_dataset.map(tokenize_function,...)grouped_dataset = tokenized_dataset.map(group_texts,...)
- tokenize_function->output = tokenizer(examples["text"])processed_dataset.save_to_disk(cache_path)lm_datasets = concatenate_datasets([lm_datasets,processed_dataset['train']])lm_datasets = lm_datasets.train_test_split(data_args.validation_split_percentage) train_dataset = lm_datasets['train']
model = LlamaForCausalLM.from_pretrained(model_args.model_name_or_path,..)
model_vocab_size = model.get_output_embeddings().weight.size(0)
model.resize_token_embeddings(len(tokenizer))target_modules = training_args.trainable.split(',')
modules_to_save = training_args.module_to_save
lora_rank = training_args.lora_rank
lora_dropout = training_args.lora_dropout
lora_alpha = training_args.lora_alpha
peft_config = LoraConfig(TasskType.CAUSAL_LM,target_modules,lora_rank,lora_alpha,lora_dropout,lora_dropout,modules_to_save)
model = get_peft_model(model,peft_config)
old_state_dict = model.state_dict()
model.state_dict = (lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())
).__get__(model, type(model))trainer = Trainer(model,training_args,train_dataset,eval_dataset,tokenizer,fault_tolerance_data_collator,compute_metrics,preprocess_logits_for_metrics)
trainer.add_callback(SavePeftModelCallback)checkpoint = training_args.resume_from_checkpoint
train_result = trainer.train(checkpoint)
metrics = train_result.metrics
trainer.log_metrics("train",metrics)
trainer.save_metrics("train",metrics)
trainer.save_state()3.2 指令精调代码
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, MyTrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()set_seed(training_args.seed)
config = AutoConfig.from_pretrained(model_args.model_name_or_path,...)
tokenizer = LlamaTokenizer.from_pretrained(model_args.tokenizer_name_or_path,...)tokenizer.add_special_tokens(dict(pad_token="[PAD]"))
data_collator = DataCollatorForSupervisedDataset(tokenizer)
- input_ids,labels = tuple([instance[key] for instance in instances] for key in ("input_ids","labels"))
- input_ids = torch.nn.utils.rnn.pad_sequence(input_ids,batch_first=True,padding_value=self.tokenizer.pad_token_id)
- labels = torch.nn.utils.rnn.pad_sequence(labels,batch_first=True,padding_values=-100)with training_args.main_process_first():files = [os.path.join(path,filename) for file in path.glob("*.json")]train_dataset = build_instruction_dataset(files,tokenizer,data,max_seq_length,...)
- for file in data_path:raw_dataset = load_dataset("json",data_file=file,..)tokenized_dataset = raw_dataset.map(tokenization,...)
-- for instruction,input,output in zip(examples['instruction'],examples['input'],examples['output']):if input is not None and input != "":instruction = instruction+"\n"+inputsource = prompt.format_map({'instruction':instruction})target = f"{output}{tokenizer.eos_token}"tokenized_sources = tokenizer(sources,return_attention_mask=False)tokenized_targets = tokenizer(targets,return_attention_mask=False,add_special_tokens=False)for s,t in zip(tokenized_sources['input_ids'],tokenized_targets['input_ids']):input_ids = torch.LongTensor(s+t)[:max_seq_length]labels = torch.LongTensor([IGNORE_INDEX]*len(s) + t)[:max_seq_length]return results = {'input_ids':all_input_ids,'labels':all_labels}model = LlamaForCausalLM.from_pretrained(model_args.model_name_or_path,config,...)
embedding_size = model.get_input_embeddings().weight.shape[0]
model.resize_token_embeddings(len(tokenizers))target_modules = training_args.trainable.split(',')
modules_to_save = training_args.modules_to_save
if modules_to_save is not None:modules_to_save = modules_to_save.split(',')
lora_rank = training_args.lora_rank
lora_dropout = training_args.lora_dropout
lora_alpha = training_args.lora_alpha
peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules=target_modules,inference_mode=False,r=lora_rank, lora_alpha=lora_alpha,lora_dropout=lora_dropout,modules_to_save=modules_to_save)
model = get_peft_model(model, peft_config)old_state_dict = model.state_dict
model.state_dict = (lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())).__get__(model, type(model))
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,tokenizer=tokenizer,data_collator=data_collator,)
trainer.add_callback(SavePeftModelCallback) train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()3.3 推理代码
apply_attention_patch(use_memory_efficient_attention=True)
apply_ntk_scaling_path(args.alpha)generation_config = dict(
temperature=0.2,
topk=40,
top_p=0.9,
do_sample=True,
num_beams=1,
repetition_penalty=1.1,
max_new_tokens=400)tokenizer = LlamaTokenizer.from_pretrained(args.tokenizer_path)
base_model = LlamaForCausalLM.from_pretrained(args.base_model,load_in_8bit,torch.float16,low_cpu_mem_usage=True)
model_vocab_size = base_model.get_input_embeddings().weight.size(0)
base_model.resize_token_embeddings(tokenzier_vocab_size)
model = base_model
model.eval()with torch.no_grad():while True:raw_input_text = input("Input:")input_text = generate_prompt(instruction=raw_input_text)inputs = tokenizer(input_text,return_tensors="pt")generation_output = model.generate(input_ids=inputs["input_ids"].to(device),attention_mask=inputs['attention_mask'].to(device),eos_token_id=tokenizer.eos_token_id,pad_token_id=tokenizer.pad_token_id,**generation_config)s = generate_output[0]output = tokenizer.decode(s,skip_special_tokens=True)response = output.split("### Response:")[1].strip()
相关文章:
chinese_llama_aplaca训练和代码分析
训练细节 ymcui/Chinese-LLaMA-Alpaca Wiki GitHub中文LLaMA&Alpaca大语言模型本地CPU/GPU训练部署 (Chinese LLaMA & Alpaca LLMs) - 训练细节 ymcui/Chinese-LLaMA-Alpaca Wikihttps://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E8%AE%AD%E7%BB%83%E7%BB%86%E…...

大数据Doris(十七):关于 Partition 和 Bucket 的数量和数据量的建议
文章目录 关于 Partition 和 Bucket 的数量和数据量的建议 关于 Partition 和 Bucket 的数量和数据量的建议 一个表的 Tablet 总数量等于 (Partition num * Bucket num)。一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。单个 Tablet 的数据量理论…...

进击的巨人 完结篇 后篇-中文下载
话不多说,直接上链接 【简中】[BeanSub][Shingeki_n…1080P][x264_AAC].mp4 https://www.aliyundrive.com/s/7V4jaN6s6rY 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放…...

力扣刷题-二叉树-二叉树的非递归遍历
参考:https://www.programmercarl.com/%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E8%BF%AD%E4%BB%A3%E9%81%8D%E5%8E%86.html#%E6%80%9D%E8%B7%AF 思路 为什么可以用迭代法(非递归的方式)来实现二叉树的前后中序遍历呢? 我们在栈与…...

react_15
动态菜单 图标要独立安装依赖 npm install ant-design/icons 图标组件,用来将字符串图标转换为标签图标 import * as icons from "ant-design/icons"; interface Module {[p: string]: any; } const all: Module icons; export default function Ico…...

关于ROS的网络通讯方式TCP/UDP
一、TCP与UDP TCP/IP协议族为传输层指明了两个协议:TCP和UDP,它们都是作为应同程序和网络操作的中介物。 **TCP(Transmission Control Protocol)协议全称是传输控制协议,是一种面向连接的、可靠的、基于字节流的传输…...
Leetcode—421.数组中两个数的最大异或值【中等】明天写一下字典树做法!!!
2023每日刷题(十九) Leetcode—421.数组中两个数的最大异或值 算法思想 参考自灵茶山艾府 实现代码 class Solution { public:int findMaximumXOR(vector<int>& nums) {int maxValue *max_element(nums.begin(), nums.end());int highId…...

数智赋能!麒麟信安参展全球智慧城市大会
10月31日至11月2日,为期三天的2023全球智慧城市大会长沙在湖南国际会展中心举办,大会已连续举办12届,是目前全球规模最大、专注于城市和社会智慧化发展及转型的主题展会。长沙市委常委、常务副市长彭华松宣布开幕,全球智慧城市大会…...
基础课21——知识库管理
1.知识库的概念、特点与功能 智能客服中的知识库是一个以知识为基础的系统,可以明确地表达与实际问题相对应的知识,并构成相对独立的程序行为主体,有利于有效、准确地解决实际问题。它储存着机器人对所有信息的认知概念和理解,这…...
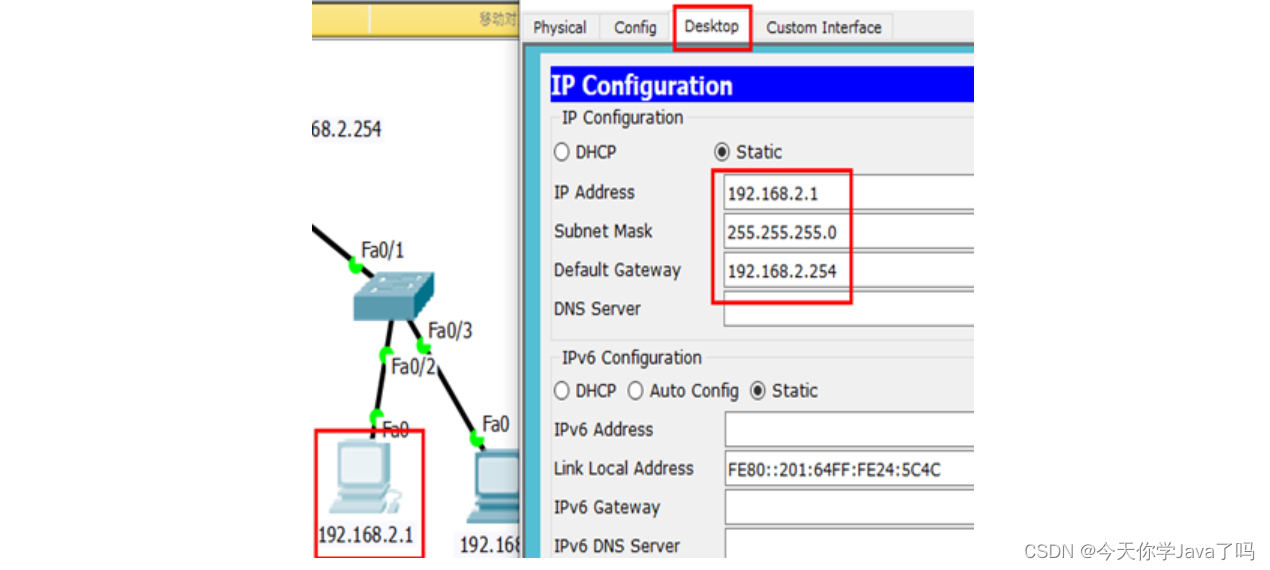
网络运维Day01
文章目录 环境准备OSI七层参考模型什么是协议?协议数据单元(PDU)设备与层的对应关系什么是IP地址?IP地址分类IP的网络位和主机位IP地址默认网络位与主机位子网掩码默认子网掩码查看IP地址安装CISCO汉化CISCO(可选操作) CISCO之PC机器验证通信 CISCSO之交…...
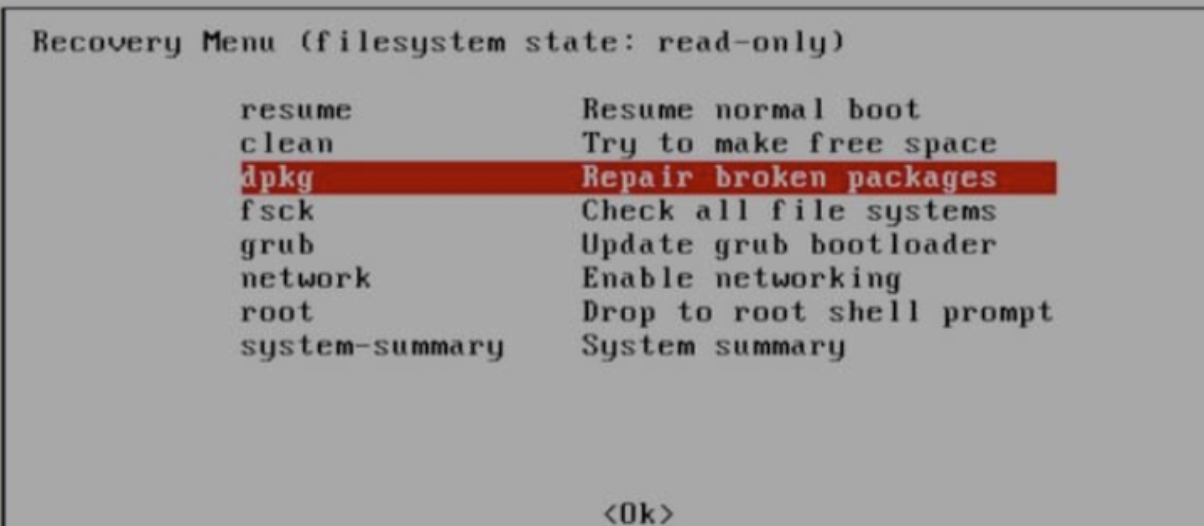
从零配置一台linux主机
1. Linux软件安装方式 软件安装教程 设置国内源 因为 linux 本身自带的下载源资源有限,所以在使用 apt 命令下载的时候,有些包可能找不到,所以要添加国内源。方法如下: 打开文件 /etc/apt/sources.list sudo gedit /etc/apt/s…...
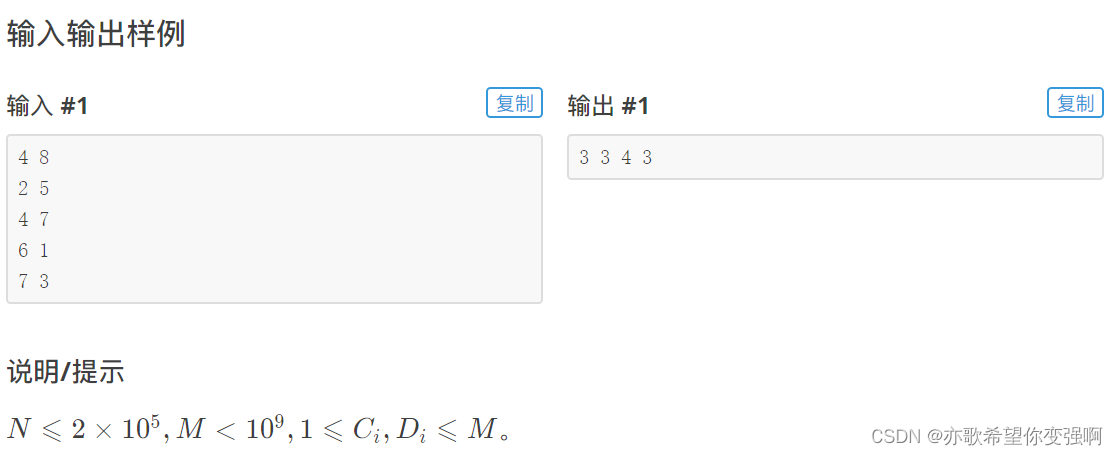
【蓝桥每日一题]-倍增(保姆级教程 篇1)
今天讲一下倍增 目录 题目:忠诚 思路: 题目:国旗计划 思路: 查询迭代类倍增: 本质是一个一个选区间使总长度达到 M,类似凑一个数。而我们会经常用不大于它最大的二的次幂,减去之后,再重复这…...
、RNN(循环神经网络)和GCN(图卷积神经网络))
CNN(卷积神经网络)、RNN(循环神经网络)和GCN(图卷积神经网络)
CNN(卷积神经网络): 区别:CNN主要适用于处理网格状数据,如图像或其他二维数据。它通过卷积层、池化层和全连接层来提取和学习输入数据的特征。卷积层使用卷积操作来捕捉局部的空间结构,池化层用于降低特征图…...
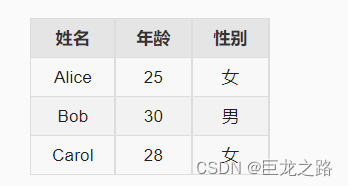
在markdown中怎么画表格
2023年11月5日,周日上午 下面是一种常用的方式来编写表格: | 列1标题 | 列2标题 | 列3标题 | |:------:|:------:|:------:| | 内容 | 内容 | 内容 | | 内容 | 内容 | 内容 |在这个示例中,第一行用于定义表格的列标…...

每天五分钟计算机视觉:搭建手写字体识别的卷积神经网络
本文重点 我们学习了卷积神经网络中的卷积层和池化层,这二者都是卷积神经网络中不可缺少的元素,本例中我们将搭建一个卷积神经网络完成手写字体识别。 卷积和池化的直观体现 手写字体识别 手写字体的图片大小是32*32*3的,它是一张 RGB 模式的图片,现在我们想识别它是从 …...
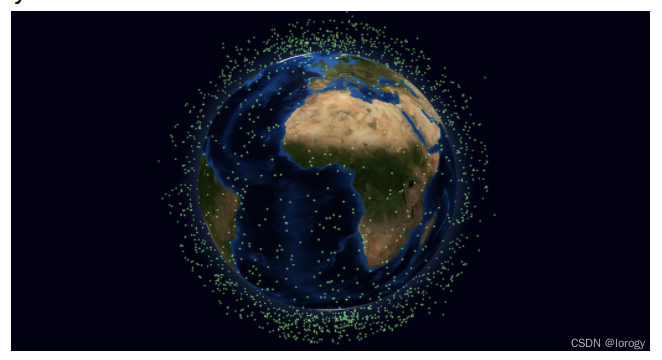
【React】【react-globe.gl】3D Objects效果
目录 想要实现的效果实现过程踩坑安装依赖引入页面 想要实现的效果 示例地址 实现过程 踩坑 示例是通过script引入的依赖,但本人需要在react项目中实现该效果。按照react-globe.gl官方方法引入总是报错 Cant import the named export AmbientLight from non EcmaS…...
)
目标检测YOLO系列从入门到精通技术详解100篇-【目标检测】SLAM(补充篇)
目录 前言 知识储备 SLAM基础知识 算法原理 什么是SLAM SLAM算法框架...

Pytorch 缓解过拟合和网络退化
一 添加BN模块 BN模块应该添加 激活层前面 在模型实例化后,我们需要对BN层进行初始化。PyTorch中的BN层是通过nn.BatchNorm1d或nn.BatchNorm2d类来实现的。 bn nn.BatchNorm1d(20) # 对于1D输入数据,使用nn.BatchNorm1d;对于2D输入数据&am…...
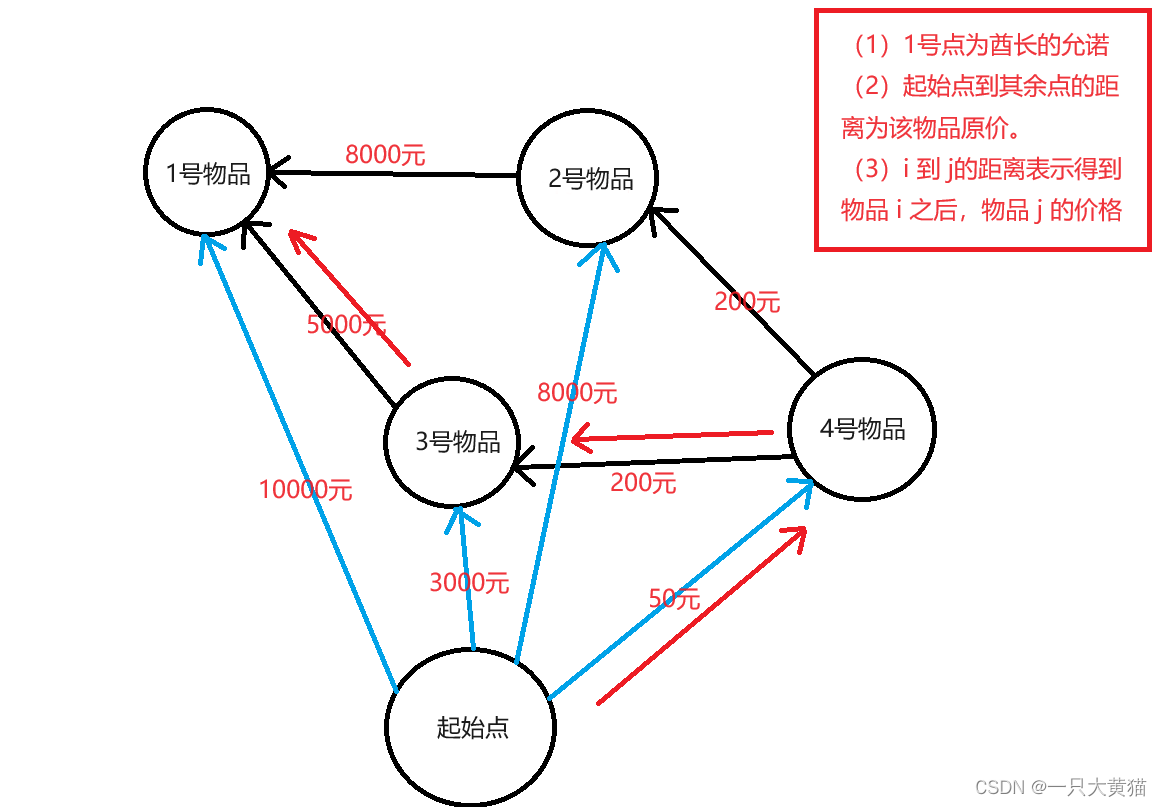
【算法】昂贵的聘礼(dijkstra算法)
题目 年轻的探险家来到了一个印第安部落里。 在那里他和酋长的女儿相爱了,于是便向酋长去求亲。 酋长要他用 10000 个金币作为聘礼才答应把女儿嫁给他。 探险家拿不出这么多金币,便请求酋长降低要求。 酋长说:”嗯,如果你能够替我…...
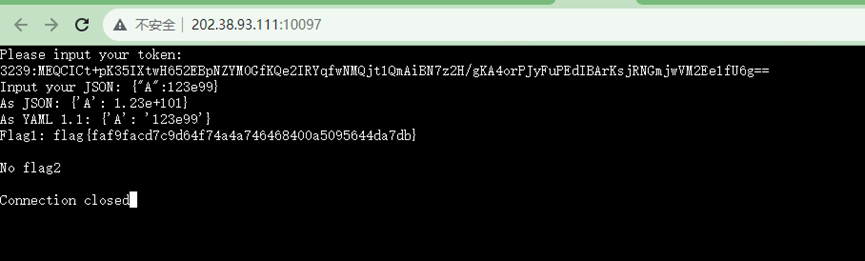
hackergame2023菜菜WP
文章目录 总结Hackergame2023更深更暗组委会模拟器猫咪小测标题HTTP集邮册Docker for everyone惜字如金 2.0Git? Git!高频率星球低带宽星球小型大语言模型星球旅行日记3.0JSON ⊂ YAML? 总结 最近看到科大在举办CTF比赛,刚好我学校也有可以参加,就玩了…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...