自己动手实现一个深度学习算法——三、神经网络的学习
文章目录
- 1.从数据中学习
- 1)数据驱动
- 2)训练数据和测试数据
- 2.损失函数
- 1)均方误差
- 2)交叉熵误差
- 3)mini-batch学习
- 3.数值微分
- 1)概念
- 2)数值微分实现
- 4.梯度
- 1)实现
- 2)梯度法
- 3)梯度法实现
- 4)神经网络的梯度
- 5)实现神经网络的梯度
- 5.学习算法的实现
- 1)神经网络的学习步骤
- 2)两层神经网络的类实现
- 3)mini-batch的实现
- 4)小结
这里所说的“学习”是指从训练数据中自动获取最优权重参数的过程。为了使神经网络能进行学习,将导入 损失函数这一指标。而学习的目的就是以该损失函数为基准,找出能使它的值达到最小的权重参数。为了找出尽可能小的损失函数的值,利用了 函数斜率的梯度法。
本章内容:
• 机器学习中使用的数据集分为训练数据和测试数据。
• 神经网络用训练数据进行学习,并用测试数据评价学习到的模型的泛化能力。
• 神经网络的学习以损失函数为指标,更新权重参数,以使损失函数的值减小。
• 利用某个给定的微小值的差分求导数的过程,称为数值微分。
• 利用数值微分,可以计算权重参数的梯度。
• 数值微分虽然费时间,但是实现起来很简单。下一章中要实现的稍微复杂一些的误差反向传播法可以高速地计算梯度。
1.从数据中学习
神经网络的特征就是可以从数据中学习。所谓“从数据中学习”,是指可以由数据自动决定权重参数的值。
1)数据驱动
数据是机器学习的命根子。
比如识别5。一种方案是,先从图像中提取特征量,再用机器学习技术学习这些特征量的模式。这里所说的“特征量”是指可以从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器。
图像的特征量通常表示为向量的形式。在计算机视觉领域,常用的特征量包括SIFT、SURF 和 HOG 等。使用这些特征量将图像数据转换为向量,然后对转换后的向量使用机器学习中的SVM、KNN等分类器进行学习。
机器学习的方法中,由机器从收集到的数据中找出规律性。与从零开始想出算法相比,这种方法可以更高效地解决问题,也能减轻人的负担。但是需要注意的是,将图像转换为向量时使用的特征量仍是由人设计的。
神经网络直接学习图像本身。该方法不存在人为介入。图像中包含的重要特征量都是由机器来学习的。
三种方案比较

神经网络的优点是对所有的问题都可以用同样的流程来解决。比如,不管要求解的问题是识别5,还是识别狗,抑或是识别人脸,神经网络都是通过不断地学习所提供的数据,尝试发现待求解的问题的模式。也就是说,与待处理的问题无关,神经网络可以将数据直接作为原始数据,进行“端对端”的学习。
2)训练数据和测试数据
机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和实验等**。首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试数据评价训练得到的模型的实际能力。**另外,训练数据也可以称为监督数据。
泛化能力是指处理未被观察过的数据(不包含在训练数据中的数据)的能力。获得泛化能力是机器学习的最终目标。
因此,仅仅用一个数据集去学习和评价参数,是无法进行正确评价的。这样会导致可以顺利地处理某个数据集,但无法处理其他数据集的情况。顺便说一下,只对某个数据集过度拟合的状态称为过拟合(over fitting)。避免过拟合也是机器学习的一个重要课题。
2.损失函数
神经网络的学习通过某个指标表示现在的状 k 3 k^3 k3态。然后,以这个指标为基准,寻找最优权重参数。神经网络的学习中所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数,但一般用均方误差和交叉熵误差等。
损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。“使性能的恶劣程度达到最小”和“使性能的优良程度达到最大”是等价的,y^2
1)均方误差
可以用作损失函数的函数有很多,其中最有名的是均方误差(mean squared error)。均方误差如下式所示。

这里,y k {_k} k是表示神经网络的输出, t k t_k tk表示监督数据,k表示数据的维数。
2)交叉熵误差
除了均方误差之外,交叉熵误差(cross entropy error)也经常被用作损失函数。交叉熵误差如下式所示。

这里,log表示以e为底数的自然对数(loge)。 y k y_k yk是神经网络的输出, t k t_k tk是正确解标签。并且, t k t_k tk中只有正确解标签的索引为1,其他均为0(one-hot表示)。
因此,实际上只计算对应正确解标签的输出的自然对数。
3)mini-batch学习
机器学习使用训练数据进行学习。使用训练数据进行学习,严格来说,就是针对训练数据计算损失函数的值,找出使该值尽可能小的参数。因此,计算损失函数时必须将所有的训练数据作为对象。也就是说,如果训练数据有100个的话,我们就要把这100个损失函数的总和作为学习的指标。前面介绍的损失函数的例子中考虑的都是针对单个数据的损失函数。如果要求所有训练数据的损失函数的总和,以交叉熵误差为例,可以写成下面的式

这里,假设数据有N个, t n k t_{nk} tnk表示第n个数据的第k个元素的值( y n k y_{nk} ynk是神经网络的输出, t n k t_{nk} tnk是监督数据)。式子虽然看起来有一些复杂,其实只是把求单个数据的损失函数的式扩大到了N份数据,不过最后还要除以N进行正规化。通过除以N,可以求单个数据的“平均损失函数”。通过这样的平均化,可以获得和训练数据的数量无关的统一指标。比如,即便训练数据有1000个或10000个,也可以求得单个数据的平均损失函数。
3.数值微分
所谓数值微分就是用数值方法近似求解函数的导数的过程。
1)概念
计算函数f在(x + h)和(x−h) 之间的差分。因为这种计算方法以 x 为中心,计算它左右两边的差分,所以也称为中心差分(而(x + h)和x之间的差分称为前向差分)。
利用微小的差分求导数的过程称为数值微分。基于数学式的推导求导数的过程,则用“解析性”(analytic)一词,称为“解析性求解”或者“解析性求导”。
2)数值微分实现
# coding: utf-8
import numpy as np
import matplotlib.pylab as pltdef numerical_diff(f, x):#差分h = 1e-4 # 0.0001return (f(x+h) - f(x-h)) / (2*h)def function_1(x):return 0.01*x**2 + 0.1*x def tangent_line(f, x):d = numerical_diff(f, x)print(d)y = f(x) - d*xreturn lambda t: d*t + yx = np.arange(0.0, 20.0, 0.1)
y = function_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
#求function_1函数在x=5的表达式,即为切线
tf = tangent_line(function_1, 5)
y2 = tf(x)plt.plot(x, y)
plt.plot(x, y2)
plt.show()
4.梯度
由全部变量的偏导数汇总而成的向量称为梯度(gradient)。梯度指示的方向是各点处的函数值减小最多的方向
1)实现
# coding: utf-8
# cf.http://d.hatena.ne.jp/white_wheels/20100327/p3
import numpy as np
import matplotlib.pylab as plt
from mpl_toolkits.mplot3d import Axes3Ddef _numerical_gradient_no_batch(f, x):h = 1e-4 # 0.0001grad = np.zeros_like(x)for idx in range(x.size):tmp_val = x[idx]x[idx] = float(tmp_val) + hfxh1 = f(x) # f(x+h)x[idx] = tmp_val - h fxh2 = f(x) # f(x-h)grad[idx] = (fxh1 - fxh2) / (2*h)x[idx] = tmp_val # 还原值return graddef numerical_gradient(f, X):if X.ndim == 1:return _numerical_gradient_no_batch(f, X)else:grad = np.zeros_like(X)for idx, x in enumerate(X):grad[idx] = _numerical_gradient_no_batch(f, x)return graddef function_2(x):if x.ndim == 1:return np.sum(x**2)else:return np.sum(x**2, axis=1)def tangent_line(f, x):d = numerical_gradient(f, x)print(d)y = f(x) - d*xreturn lambda t: d*t + yif __name__ == '__main__':x0 = np.arange(-2, 2.5, 0.25)x1 = np.arange(-2, 2.5, 0.25)X, Y = np.meshgrid(x0, x1)X = X.flatten()Y = Y.flatten()grad = numerical_gradient(function_2, np.array([X, Y]) )plt.figure()plt.quiver(X, Y, -grad[0], -grad[1], angles="xy",color="#666666")#,headwidth=10,scale=40,color="#444444")plt.xlim([-2, 2])plt.ylim([-2, 2])plt.xlabel('x0')plt.ylabel('x1')# plt.grid()# plt.legend()plt.draw()plt.show()
运行结果:

结果表明梯度指向函数f(x0,x1) 的“最低处”(最小值),离“最低处”越远,箭头越大。
实际上,梯度会指向各点处的函数值降低的方向。更严格地讲,梯度指示的方向是各点处的函数值减小最多的方向。
quiver方法说明
作用:绘制向量场
quiver([X, Y], U, V, [C], **kw)
其中 X, Y 定义了箭头的位置, U, V 定义了箭头的方向, C 作为可选参数用来设置颜色。
下面是几个常见的参数:
units: 此参数指示了除箭头长度外,其他尺寸的变化趋势,以该单位的倍数测量。可取值为 {‘width’, ‘height’, ‘dots’, ‘inches’, ‘x’, ‘y’ ‘xy’}, 默认是 ‘width’。需要配合 scale 参数使用。
scale: float, optional。此参数是每个箭头长度单位的数据单位数,通常该值越小,意味着箭头越长,默认为 None ,此时系统会采用自动缩放算法。箭头长度单位由 scale_units 参数指定。
scale_units: 此参数是可选参数,其中包含以下值:{‘width’, ‘height’, ‘dots’, ‘inches’, ‘x’, ‘y’, ‘xy’}, 一般当 scale=None 时该选项指示长度单位,默认为 None。
angles: 此参数指定了确定箭头角度的方法,可以取 {‘uv’, ‘xy’} 或者 array-like, 默认是 ‘uv’ 。 设计原因是 因为图的宽和高可能不同,所以 x 方向的单位长度和 y 方向的单位长度可能不同,这时我们需要做出选择,一是不管长度对不对,角度一定要对,此时 angles=‘uv’,二是不管角度了,只要长度对就可以了,此时 angles=‘xy’。当该值为一个 array 的时候,该数组应该是以度数为单位的数组,表示了每一个箭头的方向,如下所示:
2)梯度法
机器学习的主要任务是在学习时寻找最优参数。
同样地,神经网络也必须在学习时找到最优参数(权重和偏置)。这里所说的最优参数是指损失函数取最小值时的参数。但是,一般而言,损失函数很复杂,参数空间庞大,我们不知道它在何处能取得最小值。而通过巧妙地使用梯度来寻找函数最小值(或者尽可能小的值)的方法就是梯度法。
函数的极小值、最小值以及被称为鞍点(saddle point)的地方,梯度为0。极小值是局部最小值,也就是限定在某个范围内的最小值。鞍点是从某个方向上看是极大值,从另一个方向上看则是极小值的点。虽然梯度法是要寻找梯度为0的地方,但是那个地方不一定就是最小值(也有可能是极小值或者鞍点)。此外,当函数很复杂且呈扁平状时,学习可能会进入一个(几乎)平坦的地区,陷入被称为“学习高原”的无法前进的停滞期。
在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进,如此反复,不断地沿梯度方向前进。像这样,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法(gradient method)。梯度法是解决机器学习中最优化问题的常用方法,特别是在神经网络的学习中经常被使用。
η表示更新量,在神经网络的学习中,称为学习率。学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。

上述式子是表示更新一次的式子,这个步骤会反复执行。
学习率需要事先确定为某个值,比如0.01或0.001。一般而言,这个值过大或过小,都无法抵达一个“好的位置”。在神经网络的学习中,一般会一边改变学习率的值,一边确认学习是否正确进行了。
3)梯度法实现
# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
from gradient_2d import numerical_gradient#参数f是要进行最优化的函数,init_x是初始值,lr是学习率learning rate,step_num 是梯度法的重复次数。
#使用这个函数可以求函数的极小值,顺利的话,还可以求函数的最小值。
def gradient_descent(f, init_x, lr=0.01, step_num=100):x = init_xx_history = []for i in range(step_num):x_history.append( x.copy() )#numerical_gradient(f,x) 会求函数的梯度,用该梯度乘以学习率得到的值进行更新操作,由step_num指定重复的次数。grad = numerical_gradient(f, x)x -= lr * gradreturn x, np.array(x_history)def function_2(x):return x[0]**2 + x[1]**2init_x = np.array([-3.0, 4.0]) lr = 0.1
step_num = 20
x, x_history = gradient_descent(function_2, init_x, lr=lr, step_num=step_num)plt.plot( [-5, 5], [0,0], '--b')
plt.plot( [0,0], [-5, 5], '--b')
plt.plot(x_history[:,0], x_history[:,1], 'o')plt.xlim(-3.5, 3.5)
plt.ylim(-4.5, 4.5)
plt.xlabel("X0")
plt.ylabel("X1")
plt.show()实验结果表明,学习率过大的话,会发散成一个很大的值;反过来,学习率过小的话,基本上没怎么更新就结束了。也就是说,设定合适的学习率是一个很重要的问题。
像学习率这样的参数称为超参数。这是一种和神经网络的参数(权重和偏置)性质不同的参数。相对于神经网络的权重参数是通过训练数据和学习算法自动获得的,学习率这样的超参数则是人工设定的。一般来说,超参数需要尝试多个值,以便找到一种可以使学习顺利进行的设定。
4)神经网络的梯度
这里所说的梯度是指损失函数关于权重参数的梯度。比如,有一个只有一个形状为2×3 的权重 W 的神经网络,损失函数用L表示。此时,梯度可以用 表示。用数学式表示的话,如下所示。

5)实现神经网络的梯度
根据梯度法,更新权重参数
# coding: utf-8
# 导入sys和os模块,sys模块提供了一些变量和函数,os模块提供了一些与操作系统交互的功能
import sys, os
#为了导入父目录中的文件而进行的设定
sys.path.append(os.pardir) # 为了导入父目录中的文件而进行的设定
import numpy as np
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient"""
simple Net类只有一个实例变量,即形状为2×3的权重参数。它有两个方法,一个是用于预测的predict(x),另一个是用于求损失函数值的loss(x,t)。这里参数x接收输入数据,t接收正确解标签。
"""
class simpleNet:def __init__(self):# 用高斯分布进行初始化self.W = np.random.randn(2,3)
#用于预测def predict(self, x):return np.dot(x, self.W)def loss(self, x, t):# 计算预测结果z z = self.predict(x)y = softmax(z)# 计算交叉熵误差作为损失函数值 loss = cross_entropy_error(y, t)# 返回损失函数值return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])net = simpleNet()
f = lambda w: net.loss(x, t)
dW = numerical_gradient(f, net.W)
#打印梯度dW
print(dW)
5.学习算法的实现
求出神经网络的梯度后,接下来只需根据梯度法,更新权重参数即可。
1)神经网络的学习步骤
前提
神经网络存在合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为“学习”。神经网络的学习分成下面4个步骤。
步骤1(mini-batch)
从训练数据中随机选出一部分数据,这部分数据称为mini-batch。我们的目标是减小mini-batch的损失函数的值。
步骤2(计算梯度)
为了减小mini-batch的损失函数的值,需要求出各个权重参数的梯度。梯度表示损失函数的值减小最多的方向。
步骤3(更新参数)
将权重参数沿梯度方向进行微小更新。
步骤4(重复)
重复步骤1、步骤2、步骤3。
这个方法通过梯度下降法更新参数,不过因为这里使用的数据是随机选择的mini batch数据,所以又称为随机梯度下降法(stochastic gradient descent)。“随机”指的是“随机选择的”的意思,因此,随机梯度下降法是“对随机选择的数据进行的梯度下降法”。深度学习的很多框架中,随机梯度下降法一般由一个名为SGD的函数来实现。SGD 来源于随机梯度下降法的英文名称的首字母。
2)两层神经网络的类实现
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
from common.functions import *
from common.gradient import numerical_gradientclass TwoLayerNet:#进行初始化。参数从头开始依次表示输入层的神经元数、隐藏层的神经元数、输出层的神经元数def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):# 初始化权重#保存神经网络的参数的字典型变量(实例变量)。#params['W1'] 是第 1 层的权重,params['b1'] 是第 1 层的偏置。#params['W2'] 是第 2 层的权重,params['b2'] 是第 2 层的偏置self.params = {}self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)self.params['b1'] = np.zeros(hidden_size)self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)self.params['b2'] = np.zeros(output_size)#进行识别(推理)。参数x是图像数据def predict(self, x):W1, W2 = self.params['W1'], self.params['W2']b1, b2 = self.params['b1'], self.params['b2']a1 = np.dot(x, W1) + b1z1 = sigmoid(a1)a2 = np.dot(z1, W2) + b2y = softmax(a2)return y# x:输入数据, t:监督数据#计算损失函数的值。参数x是图像数据,t是正确解标签(后面3个方法的参数也一样)def loss(self, x, t):y = self.predict(x)return cross_entropy_error(y, t)#计算识别精度def accuracy(self, x, t):y = self.predict(x)y = np.argmax(y, axis=1)t = np.argmax(t, axis=1)accuracy = np.sum(y == t) / float(x.shape[0])return accuracy#计算权重参数的梯度# x:输入数据, t:监督数据def numerical_gradient(self, x, t):loss_W = lambda W: self.loss(x, t)grads = {}grads['W1'] = numerical_gradient(loss_W, self.params['W1'])grads['b1'] = numerical_gradient(loss_W, self.params['b1'])grads['W2'] = numerical_gradient(loss_W, self.params['W2'])grads['b2'] = numerical_gradient(loss_W, self.params['b2'])return grads#计算权重参数的梯度。def gradient(self, x, t):W1, W2 = self.params['W1'], self.params['W2']b1, b2 = self.params['b1'], self.params['b2']#保存梯度的字典型变量(numerical_gradient() 方法的返回值)。#grads['W1'] 是第 1 层权重的梯度,grads['b1'] 是第 1 层偏置的梯度。#grads['W2'] 是第 2 层权重的梯度,grads['b2'] 是第 2 层偏置的梯度grads = {}batch_num = x.shape[0]# forwarda1 = np.dot(x, W1) + b1z1 = sigmoid(a1)a2 = np.dot(z1, W2) + b2y = softmax(a2)# backwarddy = (y - t) / batch_numgrads['W2'] = np.dot(z1.T, dy)grads['b2'] = np.sum(dy, axis=0)da1 = np.dot(dy, W2.T)dz1 = sigmoid_grad(a1) * da1grads['W1'] = np.dot(x.T, dz1)grads['b1'] = np.sum(dz1, axis=0)return grads
初始化方法会对权重参数进行初始化。如何设置权重参数的初始值这个问题是关系到神经网络能否成功学习的重要问题。这里权重使用符合高斯分布的随机数进行初始化,偏置使用 0 进行初始化。
3)mini-batch的实现
mini-batch 学习,就是从训练数据中随机选择一部分数据(称为 mini-batch),再以这些mini-batch为对象,使用梯度法更新参数的过程。
完整代码实现如下:
train_neuralnet.py文件,训练并测试二层神经网络TwoLayerNet
# coding: utf-8
import sys, ossys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000 # 适当设定循环的次数
# 获取训练集的大小
train_size = x_train.shape[0]
# mini-batch的大小为100,需要每次从60000个训练数据中随机取出100个数据(图像数据和正确解标签数据)。
batch_size = 100
# 设定学习率为0.1。
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 计算每个epoch的迭代次数,至少为1。
iter_per_epoch = max(train_size / batch_size, 1)
# 对循环迭代次数进行计数。
for i in range(iters_num):batch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask]t_batch = t_train[batch_mask]# 计算梯度# 使用网络计算梯度。# 对这个包含100笔数据的mini-batch求梯度,使用随机梯度下降法(SGD)更新参数。# grad = network.numerical_gradient(x_batch, t_batch)grad = network.gradient(x_batch, t_batch) # 快速版# 对网络中的参数进行更新。for key in ('W1', 'b1', 'W2', 'b2'):network.params[key] -= learning_rate * grad[key]# 计算当前批次的损失。loss = network.loss(x_batch, t_batch)# 将损失添加到列表中。train_loss_list.append(loss)if i % iter_per_epoch == 0:# 计算训练集上的准确度。train_acc = network.accuracy(x_train, t_train)# 计算测试集上的准确度。test_acc = network.accuracy(x_test, t_test)# 将训练准确度添加到列表中。train_acc_list.append(train_acc)#将测试准确度添加到列表中。test_acc_list.append(test_acc)# 打印训练和测试准确度。print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))# 绘制图形
# 定义用于绘图的标记类型。
markers = {'train': 'o', 'test': 's'}
# 创建x轴的坐标值,从0到列表的
x = np.arange(len(train_acc_list))
plt.subplot(2,1,1)
# 绘制训练准确度曲线
plt.plot(x, train_acc_list, label='train acc')
# 绘制测试准确度曲线
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
# 绘制训练损失曲线
plt.subplot(2,1,2)
xx=np.arange(len(train_loss_list))
plt.plot(xx, train_loss_list, label='train loss')
plt.ylabel("loss")
plt.legend(loc='upper right')
# 显示图像
plt.show()
mnist.py,获取手写数据
# coding: utf-8
try:import urllib.request
except ImportError:raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickle
import os
import numpy as npurl_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {'train_img':'train-images-idx3-ubyte.gz','train_label':'train-labels-idx1-ubyte.gz','test_img':'t10k-images-idx3-ubyte.gz','test_label':'t10k-labels-idx1-ubyte.gz'
}dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784def _download(file_name):file_path = dataset_dir + "/" + file_nameif os.path.exists(file_path):returnprint("Downloading " + file_name + " ... ")urllib.request.urlretrieve(url_base + file_name, file_path)print("Done")def download_mnist():for v in key_file.values():_download(v)def _load_label(file_name):file_path = dataset_dir + "/" + file_nameprint("Converting " + file_name + " to NumPy Array ...")with gzip.open(file_path, 'rb') as f:labels = np.frombuffer(f.read(), np.uint8, offset=8)print("Done")return labelsdef _load_img(file_name):file_path = dataset_dir + "/" + file_nameprint("Converting " + file_name + " to NumPy Array ...") with gzip.open(file_path, 'rb') as f:data = np.frombuffer(f.read(), np.uint8, offset=16)data = data.reshape(-1, img_size)print("Done")return datadef _convert_numpy():dataset = {}dataset['train_img'] = _load_img(key_file['train_img'])dataset['train_label'] = _load_label(key_file['train_label']) dataset['test_img'] = _load_img(key_file['test_img'])dataset['test_label'] = _load_label(key_file['test_label'])return datasetdef init_mnist():download_mnist()dataset = _convert_numpy()print("Creating pickle file ...")with open(save_file, 'wb') as f:pickle.dump(dataset, f, -1)print("Done!")def _change_one_hot_label(X):T = np.zeros((X.size, 10))for idx, row in enumerate(T):row[X[idx]] = 1return Tdef load_mnist(normalize=True, flatten=True, one_hot_label=False):"""读入MNIST数据集Parameters----------normalize : 将图像的像素值正规化为0.0~1.0one_hot_label : one_hot_label为True的情况下,标签作为one-hot数组返回one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组flatten : 是否将图像展开为一维数组Returns-------(训练图像, 训练标签), (测试图像, 测试标签)"""if not os.path.exists(save_file):init_mnist()with open(save_file, 'rb') as f:dataset = pickle.load(f)if normalize:for key in ('train_img', 'test_img'):dataset[key] = dataset[key].astype(np.float32)dataset[key] /= 255.0if one_hot_label:dataset['train_label'] = _change_one_hot_label(dataset['train_label'])dataset['test_label'] = _change_one_hot_label(dataset['test_label'])if not flatten:for key in ('train_img', 'test_img'):dataset[key] = dataset[key].reshape(-1, 1, 28, 28)return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label']) if __name__ == '__main__':init_mnist()gradient.py文件,梯度计算
# coding: utf-8
import numpy as np"""计算函数f在给定输入点x处的数值梯度
"""
def numerical_gradient(f, x):"""定义一个函数numerical_gradient,它接受两个参数:函数f和输入点x """#设置步长h,即梯度下降法中的学习率,这里取值为0.0001。h = 1e-4 # 0.0001#初始化一个与输入点x形状和大小相同的零向量grad,用于存储计算得到的梯度。grad = np.zeros_like(x)#使用np.nditer来遍历输入点x的所有元素,flags=['multi_index']表示返回多个索引,op_flags=['readwrite']表示读写操作。it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])#while循环条件是当迭代器it未完成时继续循环。while not it.finished:idx = it.multi_indextmp_val = x[idx]x[idx] = float(tmp_val) + hfxh1 = f(x) # f(x+h)x[idx] = tmp_val - hfxh2 = f(x) # f(x-h)grad[idx] = (fxh1 - fxh2) / (2*h)x[idx] = tmp_val # 还原值it.iternext() return grad
运行结果:

随着epoch的前进(学习的进行),发现使用训练数据和测试数据评价的识别精度都提高了,并且,这两个识别精度基本上没有差异(两条线基本重叠在一起)。因此,可以说这次的学习中没有发生过拟合的现象。随着学习的进行,损失函数的值在不断减小。这是学习正常进行的信号,表示神经网络的权重参数在逐渐拟合数据。也就是说,神经网络的确在学习!通过反复地向它浇灌(输入)数据,神经网络正在逐渐向最优参数靠近。
epoch 是一个单位。一个epoch表示学习中所有训练数据均被使用过一次时的更新次数。比如,对于10000笔训练数据,用大小为100笔数据的mini-batch进行学习时,重复随机梯度下降法100次,所有的训练数据就都被“看过”了
一般做法是事先将所有训练数据随机打乱,然后按指定的批次大小,按序生成 mini-batch。这样每个mini-batch均有一个索引号,比如此例可以是0, 1, 2,. . ., 99,然后用索引号可以遍历所有的mini-batch。遍历一次所有数据,就称为一个epoch。
4)小结
为了能顺利进行神经网络的学习,我们导入了损失函数这个指标。以这个损失函数为基准,找出使它的值达到最小的权重参数,就是神经网络学习的目标。为了找到尽可能小的损失函数值,我们介绍了使用函数斜率的梯度法。
相关文章:
自己动手实现一个深度学习算法——三、神经网络的学习
文章目录 1.从数据中学习1)数据驱动2)训练数据和测试数据 2.损失函数1)均方误差2)交叉熵误差3)mini-batch学习 3.数值微分1)概念2)数值微分实现 4.梯度1)实现2)梯度法3)梯度法实现4)…...

C++中使用复制构造函数确保深复制
C中使用复制构造函数确保深复制 复制构造函数是一个重载的构造函数,由编写类的程序员提供。每当对象被复制时,编译器都将调用复制构造函数。 为 MyString 类声明复制构造函数的语法如下: class MyString {MyString(const MyString& cop…...
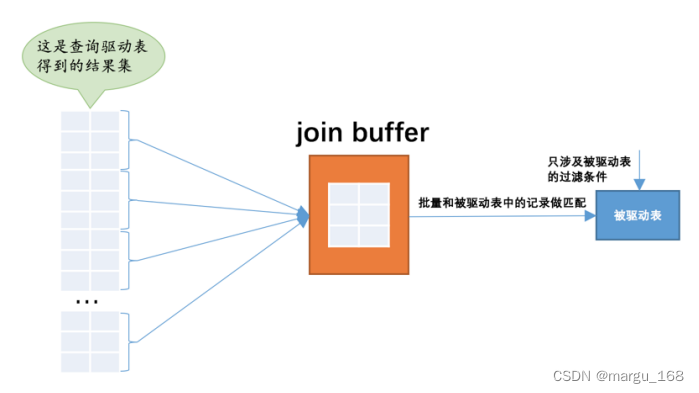
【Mysql】Mysql中表连接的原理
连接简介 在实际工作中,我们需要查询的数据很可能不是放在一张表中,而是需要同时从多张表中获取。下面我们以简单的两张表为例来进行说明。 连接的本质 为方便测试说明,,先创建两个简单的表并给它们填充一点数据: …...

Java配置47-Spring Eureka 未授权访问漏洞修复
文章目录 1. 背景2. 方法2.1 Eureka Server 添加安全组件2.2 Eureka Server 添加参数2.3 重启 Eureka Server2.4 Eureka Server 升级版本2.5 Eureka Client 配置2.6 Eureka Server 添加代码2.7 其他问题 1. 背景 项目组使用的 Spring Boot 比较老,是 1.5.4.RELEASE…...

6.Spark共享变量
概述 共享变量 共享变量的工作原理Broadcast VariableAccumulator 共享变量 共享变量的工作原理 通常,当给 Spark 操作的函数(如 mpa 或 reduce) 在 Spark 集群上执行时,函数中的变量单独的拷贝到各个节点上,函数执行时,使用…...

FaceChain开源虚拟试衣功能,打造更便捷高效的试衣新体验
简介 虚拟试衣这个话题由来已久,电商行业兴起后,就有相关的研发讨论。由其所见即所得的属性,它可以进一步提升用户服装购买体验。它既可以为商家做商品展示服务,也可以为买家做上身体验服务,这让同时具备了 B 和 C 的两…...

java的几种对象: PO,VO,DAO,BO,POJO
概述 对象释意使用备注PO(persistant object)持久对象可以看成是与数据库中的表相映射的Java对象,最简单的PO就是对应数据库中某个表中的一条记录。PO中应该不包含任何对数据库的操作VO(view object)表现层对象主要对…...
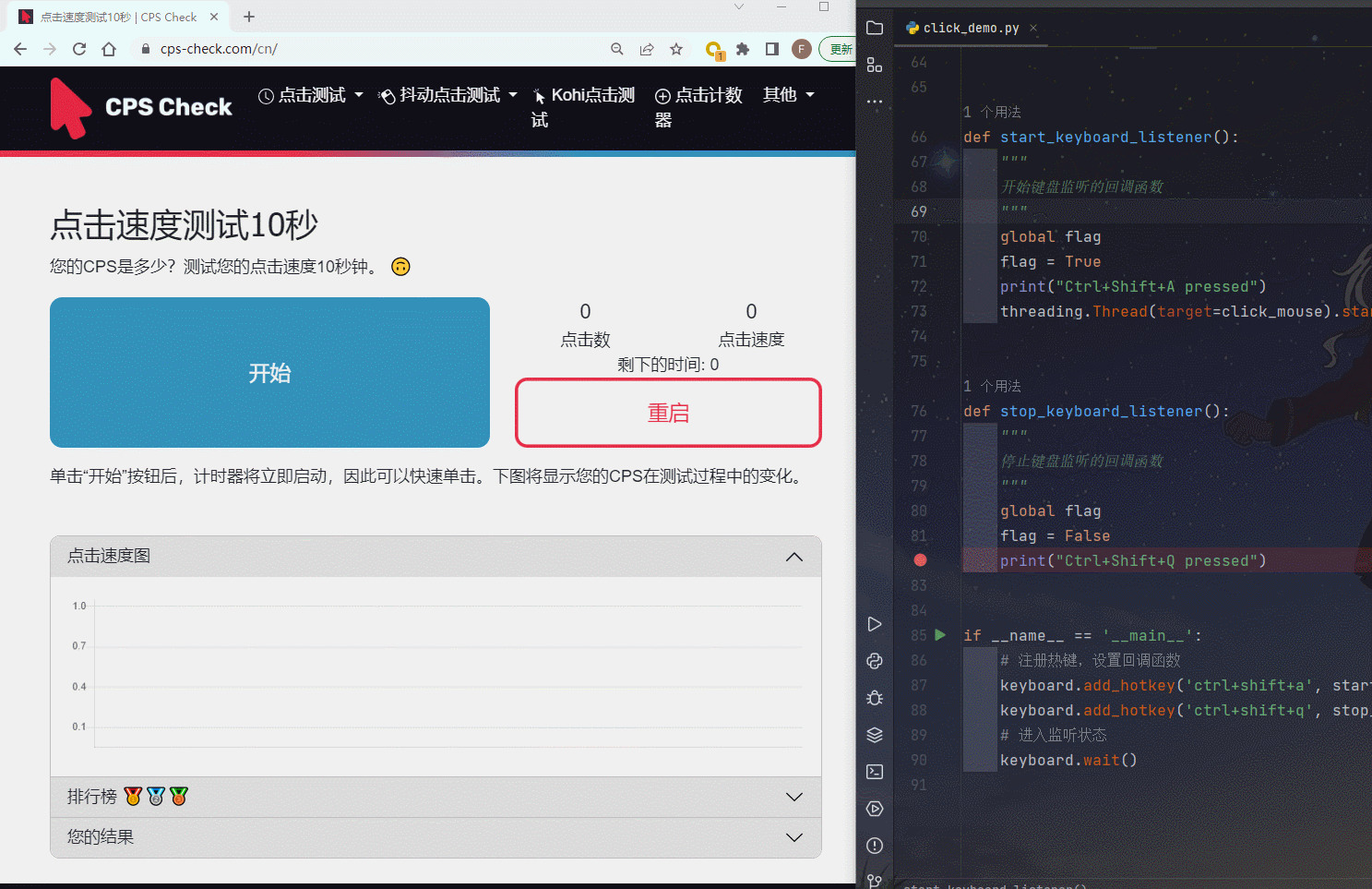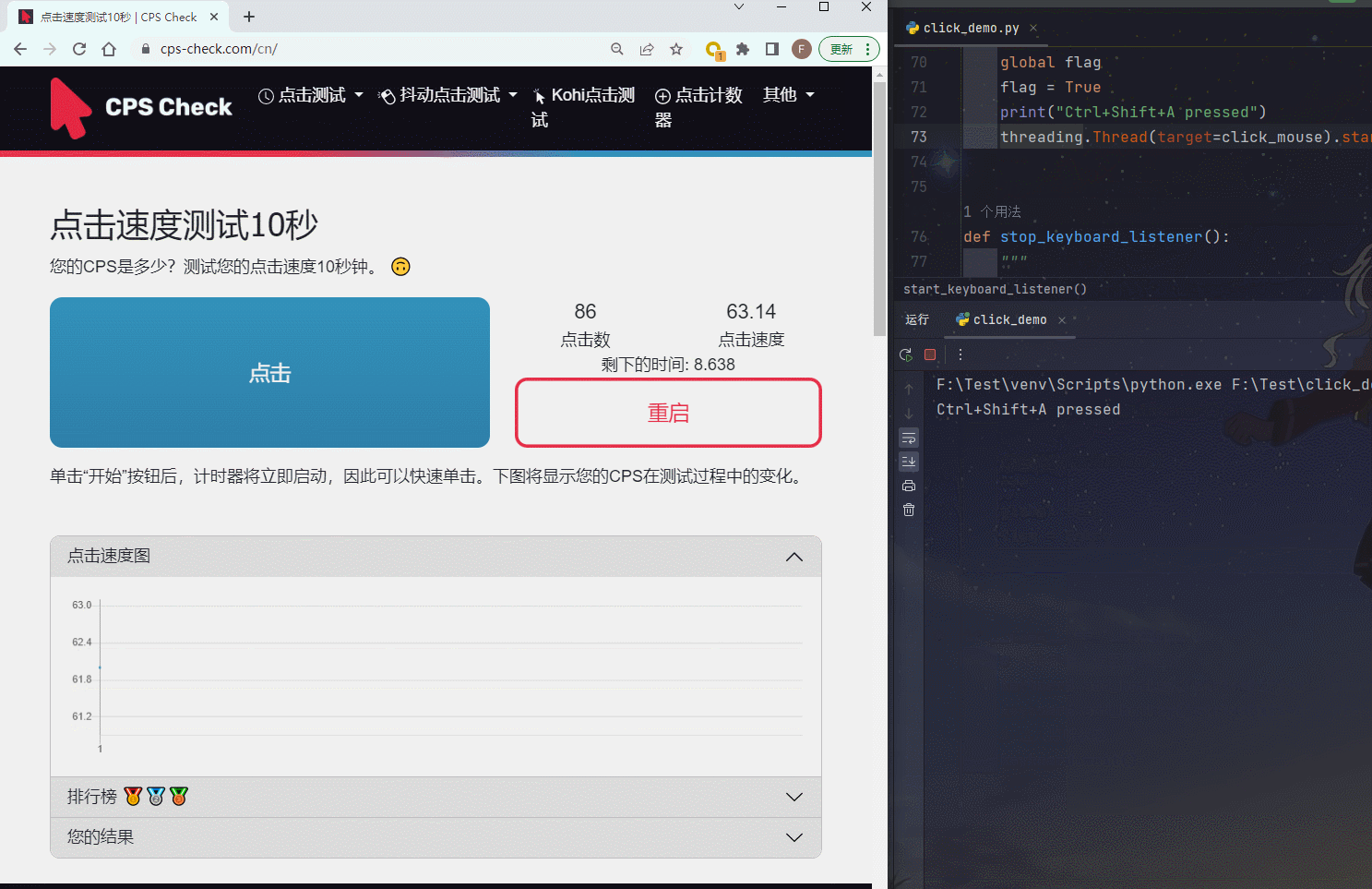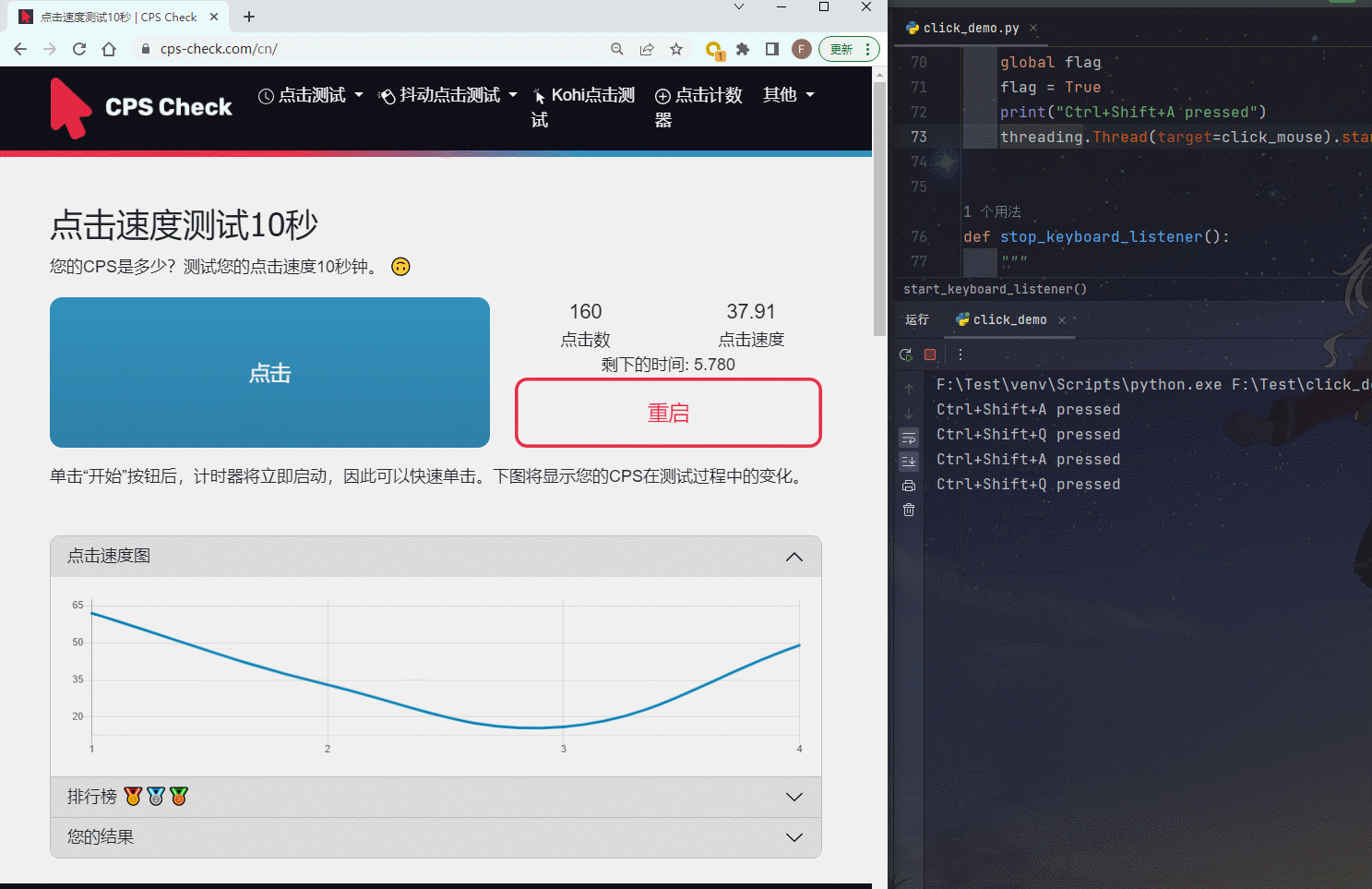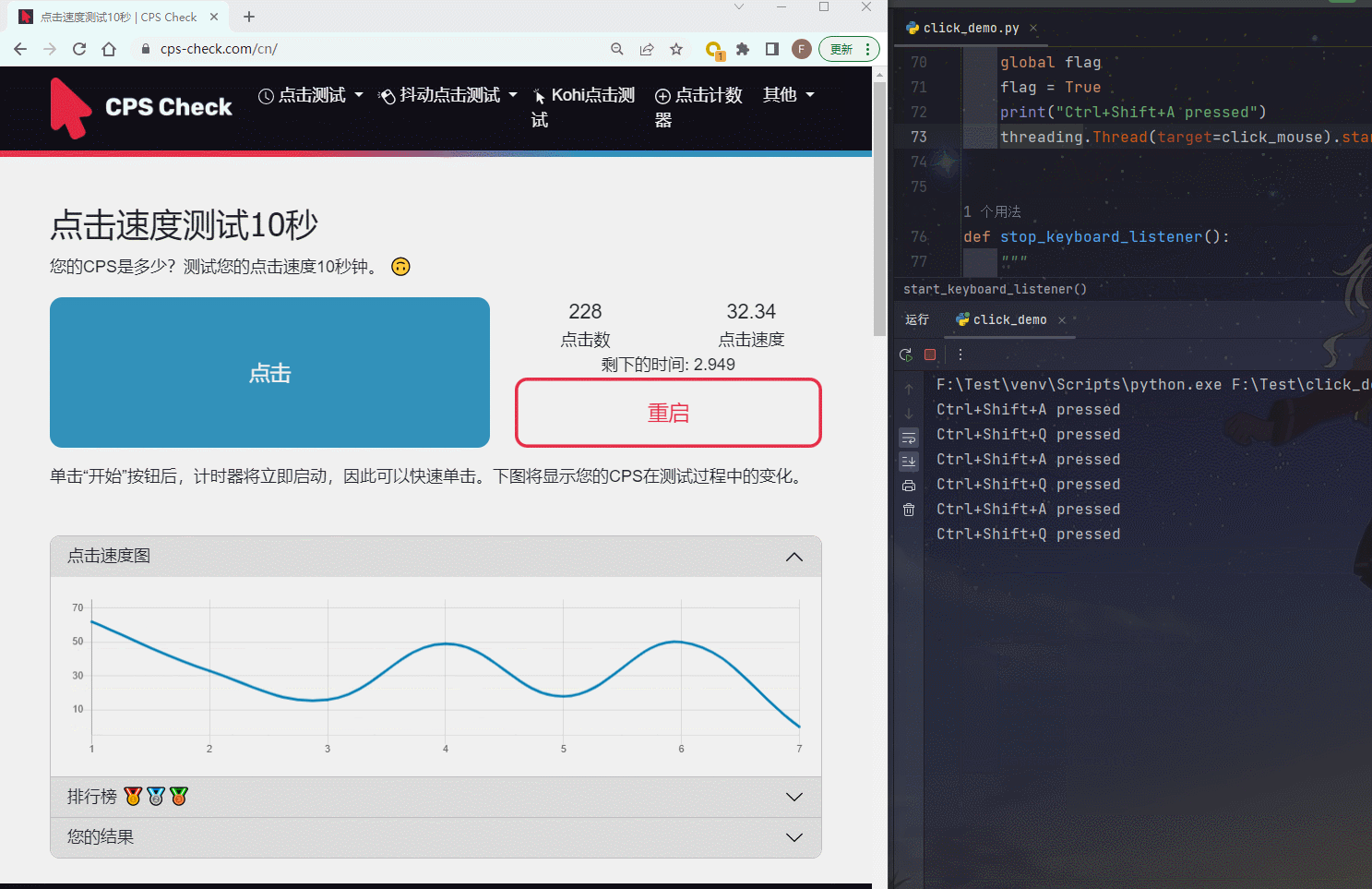
【使用Python编写游戏辅助工具】第三篇:鼠标连击器的实现
前言 这里是【使用Python编写游戏辅助工具】的第三篇:鼠标连击器的实现。本文主要介绍使用Python来实现鼠标连击功能。 鼠标连击是指在很短的时间内多次点击鼠标按钮,通常是鼠标左键。当触发鼠标连击时,鼠标按钮会迅速按下和释放多次…...

C++二分查找算法的应用:最小好进制
本文涉及的基础知识点 二分查找 题目 以字符串的形式给出 n , 以字符串的形式返回 n 的最小 好进制 。 如果 n 的 k(k>2) 进制数的所有数位全为1,则称 k(k>2) 是 n 的一个 好进制 。 示例 1: 输入:n “13” 输出:“3” …...
2022年12月 Python(三级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python等级考试(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 列表L1中全是整数,小明想将其中所有奇数都增加1,偶数不变,于是编写了如下图所示的代…...

行业安卓主板-基于RK3568/3288/3588的AI视觉秤/云相框/点餐机/明厨亮灶行业解决方案(一)
AI视觉秤 单屏Al秤集成独立NPU,可达0.8Tops算力,令AI运算效率大幅提升,以实现生鲜商品快速准确识别,快速称重打印标签,降低生鲜门店运营成本,缓解高峰期称重排队拥堵的现象,提高称重效率&#…...

fo-dicom缺少DicomJpegLsLosslessCodec
VS2019,fo-dicom v4.0.8 using Dicom.Imaging.Codec; ... DicomJpegLsLosslessCodec //CS0103 当前上下文中不存在名称“DicomJpegLsLosslessCodec” 但官方文档的确存在该类的说明DicomJpegLsLosslessCodec 尝试:安装包fo-dicom.Codecs,注…...

跳跳狗小游戏
欢迎来到程序小院 跳跳狗 玩法:一直弹跳的狗狗,鼠标点击屏幕左右方向键进行弹跳,弹到不同物品会有不同的分数减扣,规定的时间3分钟内完成狗狗弹跳,快去跳跳狗吧^^。开始游戏https://www.ormcc.com/play/gameStart/198…...
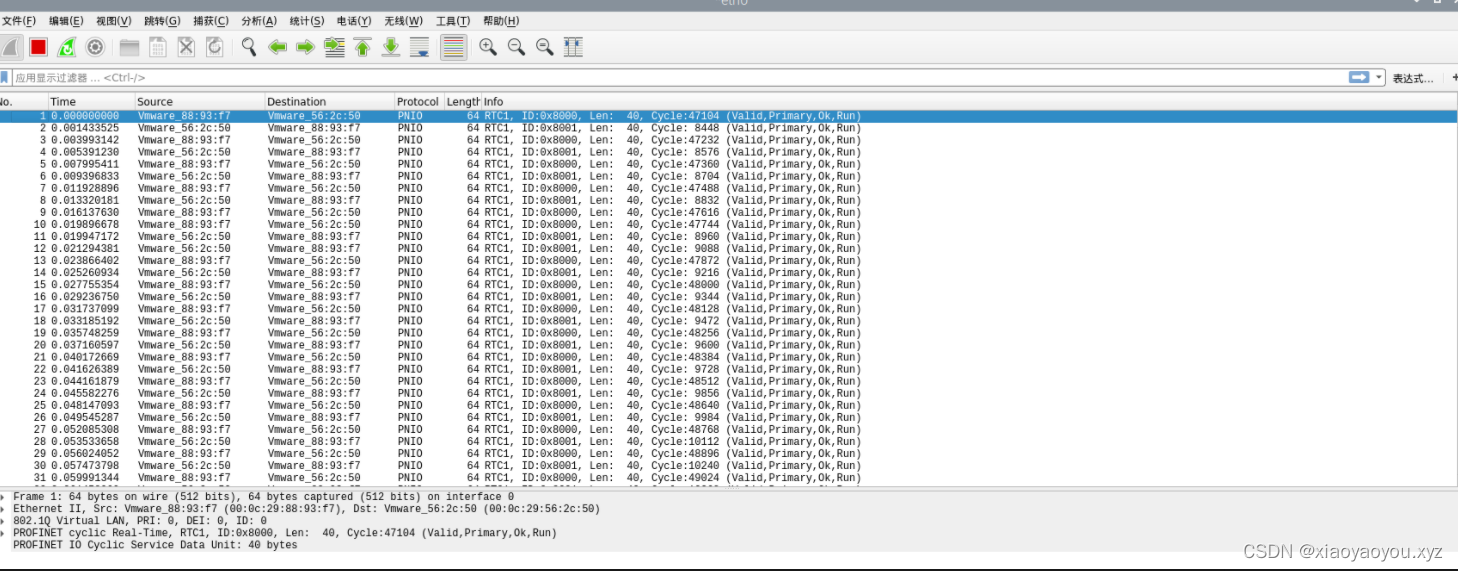
CoDeSys系列-4、基于Ubuntu的codesys运行时扩展包搭建Profinet主从环境
CoDeSys系列-4、基于Ubuntu的codesys运行时扩展包搭建Profinet主从环境 文章目录 CoDeSys系列-4、基于Ubuntu的codesys运行时扩展包搭建Profinet主从环境一、前言二、资料收集三、Ubuntu18.04从安装到更换实时内核1、下载安装Ubuntu18.042、下载安装实时内核,解决编…...

shell_70.Linux调整谦让度
调整谦让度 1.nice 命令 (1)nice 命令允许在启动命令时设置其调度优先级。要想让命令以更低的优先级运行,只需用nice 命令的-n 选项指定新的优先级即可: $ nice -n 10 ./jobcontrol.sh > jobcontrol.out & [2] 16462 $ $ ps -p 16462 -o pid,…...
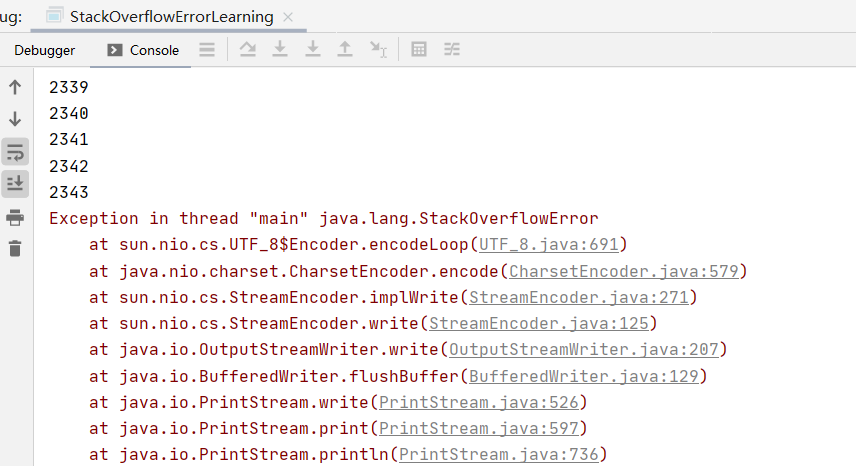
【jvm】虚拟机栈
目录 一、背景二、栈与堆三、声明周期四、作用五、特点(优点)六、可能出现的异常七、设置栈内存大小八、栈的存储单位九、栈运行原理十、栈帧的内部结构10.1 说明10.2 局部变量表10.3 操作数栈10.4 动态链接10.5 方法返回地址10.6 一些附加信息 十一、代…...

Flink SQL Over 聚合详解
Over 聚合定义(⽀持 Batch\Streaming):**特殊的滑动窗⼝聚合函数,拿 Over 聚合 与 窗⼝聚合 做对⽐。 窗⼝聚合:不在 group by 中的字段,不能直接在 select 中拿到 Over 聚合:能够保留原始字段…...

【鸿蒙软件开发】ArkUI之容器组件Counter(计数器组件)、Flex(弹性布局)
文章目录 前言一、Counter1.1 子组件1.2 接口1.3 属性1.4 事件 1.5 示例代码二、Flex弹性布局到底是什么意思? 2.1 权限列表2.2 子组件2.3 接口参数 2.4 示例代码示例代码1示例代码2 总结 前言 Counter容器组件:计数器组件,提供相应的增加或…...
:神经网络-线性层及其他层介绍)
PyTorch入门学习(十一):神经网络-线性层及其他层介绍
目录 一、简介 二、PyTorch 中的线性层 三、示例:使用线性层构建神经网络 四、常见的其他层 一、简介 神经网络是由多个层组成的,每一层都包含了一组权重和一个激活函数。每层的作用是将输入数据进行变换,从而最终生成输出。线性层是神经…...
农业水土环境与面源污染建模及对农业措施响应
目录 专题一 农业水土环境建模概述 专题二 ArcGIS入门 专题三 农业水土环境建模流程 专题四 DEM数据制备流程 专题五 土地利用数据制备流程 专题六 土壤数据制备流程 专题七 气象数据制备流程 专题八 农业措施数据制备流程 专题九 参数率定与结果验证 专题十 模型结…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...

云安全与网络安全:核心区别与协同作用解析
在数字化转型的浪潮中,云安全与网络安全作为信息安全的两大支柱,常被混淆但本质不同。本文将从概念、责任分工、技术手段、威胁类型等维度深入解析两者的差异,并探讨它们的协同作用。 一、核心区别 定义与范围 网络安全:聚焦于保…...

Linux安全加固:从攻防视角构建系统免疫
Linux安全加固:从攻防视角构建系统免疫 构建坚不可摧的数字堡垒 引言:攻防对抗的新纪元 在日益复杂的网络威胁环境中,Linux系统安全已从被动防御转向主动免疫。2023年全球网络安全报告显示,高级持续性威胁(APT)攻击同比增长65%,平均入侵停留时间缩短至48小时。本章将从…...

2025年- H71-Lc179--39.组合总和(回溯,组合)--Java版
1.题目描述 2.思路 当前的元素可以重复使用。 (1)确定回溯算法函数的参数和返回值(一般是void类型) (2)因为是用递归实现的,所以我们要确定终止条件 (3)单层搜索逻辑 二…...

2025年全国I卷数学压轴题解答
第19题第3问: b b b 使得存在 t t t, 对于任意的 x x x, 5 cos x − cos ( 5 x t ) < b 5\cos x-\cos(5xt)<b 5cosx−cos(5xt)<b, 求 b b b 的最小值. 解: b b b 的最小值 b m i n min t max x g ( x , t ) b_{min}\min_{t} \max_{x} g(x,t) bmi…...