@Slf4j将日志记录到磁盘和数据库
文章目录
- 1、背景介绍
- 2、存本地
- 2.1、配置文件
- 2.2、使用
- 3、存数据库
- 3.1、配置文件改造
- 3.2、过滤器编写
- 3.3、表准备
- 3.4、添加依赖
- 3.5、测试
- 4、优化
- 4.1、日志定期删除
1、背景介绍
现在我一个SpringBoot项目想记录日志,大概可以分为下面这几种:
- 用户操作日志:作用是记录什么用户在什么时间点访问了什么接口做了什么操作,相当于对用户在系统中的一举一动做了一个监控;
- 登录登出日志:就是将所有用户登录系统和登出系统记录到数据库,比如时间、IP、IP归属地等做一个记录,这个简单,就不过多赘述了
- 开发调试日志:就是我们常用的log.info(“xxxxx”);记录一些日志信息到磁盘中,方便上生产后,出现Bug时,可以多一些日志信息帮助我们尽快定位问题的
今天我们主要来好好聊一下开发调试日志
2、存本地
我们先来介绍一下,开发调试日志如何存本地磁盘
2.1、配置文件
首先我们需要在SpringBoot工程的resources下新建一个名叫【logback-spring.xml】的文件,内容如下:
<!-- 级别从高到低 OFF 、 FATAL 、 ERROR 、 WARN 、 INFO 、 DEBUG 、 TRACE 、 ALL -->
<!-- 日志输出规则 根据当前ROOT 级别,日志输出时,级别高于root默认的级别时 会输出 -->
<!-- 以下 每个配置的 filter 是过滤掉输出文件里面,会出现高级别文件,依然出现低级别的日志信息,通过filter 过滤只记录本级别的日志 -->
<!-- scan 当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true。 -->
<!-- scanPeriod 设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug 当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="60 seconds" debug="false"><!-- 动态日志级别 --><jmxConfigurator /><property name="charset" value="UTF-8"/><!-- 定义日志文件 输出位置 --><property name="log_dir" value="C:/LOGS/EasyJavaSE" /><!-- 日志最大的历史 30天 --><property name="maxHistory" value="30" /><!-- 单个日志文件的最大大小 --><property name="maxFileSize" value="5MB" /><!--格式化输出:%d表示日期,%t:表示线程名,%-5level:级别从左显示5个字符宽度,%c:类全路径,%msg:日志消息,%M:方法名,%L:日志所属行号,%n:换行符(Windows平台为"\r\n",Unix平台为"\n") --><property name="FORMAT" value="[%X{TRACE_ID}] - %-5level %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %c.%M:%L:%msg%n"/><!-- ConsoleAppender 控制台输出日志 --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern><!-- 设置日志输出格式 -->${FORMAT}</pattern></encoder></appender><!-- ERROR级别日志 --><!-- 滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 RollingFileAppender --><appender name="ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 过滤器,只记录WARN级别的日志 --><!-- 果日志级别等于配置级别,过滤器会根据onMath 和 onMismatch接收或拒绝日志。 --><filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 设置过滤级别 --><level>ERROR</level><!-- 用于配置符合过滤条件的操作 --><onMatch>ACCEPT</onMatch><!-- 用于配置不符合过滤条件的操作 --><onMismatch>DENY</onMismatch></filter><!-- 最常用的滚动策略,它根据时间来制定滚动策略.既负责滚动也负责出发滚动 --><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!--滚动时产生的文件的存放位置及文件名称 %d{yyyy-MM-dd}:按天进行日志滚动%i:当文件大小超过maxFileSize时,按照i进行文件滚动,i的值从0开始递增--><fileNamePattern>${log_dir}/error/%d{yyyy-MM-dd}/error-%i.log</fileNamePattern><!-- 可选节点,控制保留的归档文件的最大数量,超出数量就删除旧文件假设设置每个月滚动,且<maxHistory>是6, 则只保存最近6个月的文件,删除之前的旧文件。注意,删除旧文件是,那些为了归档而创建的目录也会被删除 --><maxHistory>${maxHistory}</maxHistory><!-- 日志文件的最大大小 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>${maxFileSize}</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><encoder><pattern><!-- 设置日志输出格式 -->${FORMAT}</pattern></encoder></appender><!-- WARN级别日志 appender --><appender name="WARN" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 过滤器,只记录WARN级别的日志 --><!-- 果日志级别等于配置级别,过滤器会根据onMath 和 onMismatch接收或拒绝日志。 --><filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 设置过滤级别 --><level>WARN</level><!-- 用于配置符合过滤条件的操作 --><onMatch>ACCEPT</onMatch><!-- 用于配置不符合过滤条件的操作 --><onMismatch>DENY</onMismatch></filter><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${log_dir}/warn/%d{yyyy-MM-dd}/warn-%i.log</fileNamePattern><maxHistory>${maxHistory}</maxHistory><!-- 日志文件的最大大小 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>${maxFileSize}</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><encoder><pattern>${FORMAT}</pattern></encoder></appender><!-- INFO级别日志 appender --><appender name="INFO" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>INFO</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${log_dir}/info/%d{yyyy-MM-dd}/info-%i.log</fileNamePattern><maxHistory>${maxHistory}</maxHistory><!-- 日志文件的最大大小 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>${maxFileSize}</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><encoder><pattern>${FORMAT}</pattern></encoder></appender><!-- DEBUG级别日志 appender --><appender name="DEBUG" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>DEBUG</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${log_dir}/debug/%d{yyyy-MM-dd}/debug-%i.log</fileNamePattern><maxHistory>${maxHistory}</maxHistory><!-- 日志文件的最大大小 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>${maxFileSize}</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><encoder><pattern>${FORMAT}</pattern></encoder></appender><!-- root级别 --><root><!-- 只有该级别日志及以上级别日志才会输出到指定渠道 --><!-- 测试:debug。上生产环境时,需要改成info或error --><level value="info" /><!-- 控制台输出渠道 --><appender-ref ref="console" /><!-- 文件输出渠道 --><appender-ref ref="ERROR" /><appender-ref ref="INFO" /><appender-ref ref="WARN" /><appender-ref ref="DEBUG" /></root>
</configuration>2.2、使用
要想要使用也非常简单,只需要先在pom.xml中导入下面依赖:
<!--lombok-->
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency>然后在需要记录日志的类上打一个下面的注解:
@Slf4j
public class TestController{//........
}然后就可以直接使用了,像这样:
@Slf4j
@RestController
@RequestMapping("/test")
public class TestController{@GetMapping("/test002/{name}")public JSONResult test002(@PathVariable("name") String name){log.info("这是 info 级别日志");log.warn("这是 warn 级别日志");log.error("这是 error 级别日志");log.debug("这是 debug 级别日志");return JSONResult.success(name);}
}项目启动,浏览器访问:http😕/localhost:8008/test/test002/tom,然后你去看磁盘对应目录中,就会记录日志成功了
3、存数据库
上面方式虽然可以记录开发调试日志到磁盘,但是有个问题是,每次要看日志的时候,都需要连接生产环境的Linux服务器,然后拉取日志文件到本地了再分析,这样比较耗时,所以我们可以优化一下,将这些日志信息存到数据库中,然后搞一个管理页面直接展示,这样查看生产环境日志就简单多了,改造步骤如下:
3.1、配置文件改造
【logback-spring.xml】配置文件改成下面这样:
<!-- 级别从高到低 OFF 、 FATAL 、 ERROR 、 WARN 、 INFO 、 DEBUG 、 TRACE 、 ALL -->
<!-- 日志输出规则 根据当前ROOT 级别,日志输出时,级别高于root默认的级别时 会输出 -->
<!-- 以下 每个配置的 filter 是过滤掉输出文件里面,会出现高级别文件,依然出现低级别的日志信息,通过filter 过滤只记录本级别的日志 -->
<!-- scan 当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true。 -->
<!-- scanPeriod 设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug 当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="60 seconds" debug="false"><!-- 动态日志级别 --><jmxConfigurator /><property name="charset" value="UTF-8"/><!-- 定义日志文件 输出位置 --><property name="log_dir" value="C:/LOGS/EasyJavaSE" /><!-- 日志最大的历史 30天 --><property name="maxHistory" value="30" /><!-- 单个日志文件的最大大小 --><property name="maxFileSize" value="5MB" /><!--格式化输出:%d表示日期,%t:表示线程名,%-5level:级别从左显示5个字符宽度,%c:类全路径,%msg:日志消息,%M:方法名,%L:日志所属行号,%n:换行符(Windows平台为"\r\n",Unix平台为"\n") --><property name="FORMAT" value="[%X{TRACE_ID}] - %-5level %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %c.%M:%L:%msg%n"/><!-- ConsoleAppender 控制台输出日志 --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern><!-- 设置日志输出格式 -->${FORMAT}</pattern></encoder></appender><!-- ERROR级别日志 --><!-- 滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 RollingFileAppender --><appender name="ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 过滤器,只记录WARN级别的日志 --><!-- 果日志级别等于配置级别,过滤器会根据onMath 和 onMismatch接收或拒绝日志。 --><filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 设置过滤级别 --><level>ERROR</level><!-- 用于配置符合过滤条件的操作 --><onMatch>ACCEPT</onMatch><!-- 用于配置不符合过滤条件的操作 --><onMismatch>DENY</onMismatch></filter><!-- 最常用的滚动策略,它根据时间来制定滚动策略.既负责滚动也负责出发滚动 --><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!--滚动时产生的文件的存放位置及文件名称 %d{yyyy-MM-dd}:按天进行日志滚动%i:当文件大小超过maxFileSize时,按照i进行文件滚动,i的值从0开始递增--><fileNamePattern>${log_dir}/error/%d{yyyy-MM-dd}/error-%i.log</fileNamePattern><!-- 可选节点,控制保留的归档文件的最大数量,超出数量就删除旧文件假设设置每个月滚动,且<maxHistory>是6, 则只保存最近6个月的文件,删除之前的旧文件。注意,删除旧文件是,那些为了归档而创建的目录也会被删除 --><maxHistory>${maxHistory}</maxHistory><!-- 日志文件的最大大小 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>${maxFileSize}</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><encoder><pattern><!-- 设置日志输出格式 -->${FORMAT}</pattern></encoder></appender><!-- WARN级别日志 appender --><appender name="WARN" class="ch.qos.logback.core.rolling.RollingFileAppender"><!-- 过滤器,只记录WARN级别的日志 --><!-- 果日志级别等于配置级别,过滤器会根据onMath 和 onMismatch接收或拒绝日志。 --><filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 设置过滤级别 --><level>WARN</level><!-- 用于配置符合过滤条件的操作 --><onMatch>ACCEPT</onMatch><!-- 用于配置不符合过滤条件的操作 --><onMismatch>DENY</onMismatch></filter><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${log_dir}/warn/%d{yyyy-MM-dd}/warn-%i.log</fileNamePattern><maxHistory>${maxHistory}</maxHistory><!-- 日志文件的最大大小 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>${maxFileSize}</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><encoder><pattern>${FORMAT}</pattern></encoder></appender><!-- INFO级别日志 appender --><appender name="INFO" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>INFO</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${log_dir}/info/%d{yyyy-MM-dd}/info-%i.log</fileNamePattern><maxHistory>${maxHistory}</maxHistory><!-- 日志文件的最大大小 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>${maxFileSize}</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><encoder><pattern>${FORMAT}</pattern></encoder></appender><!-- DEBUG级别日志 appender --><appender name="DEBUG" class="ch.qos.logback.core.rolling.RollingFileAppender"><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>DEBUG</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${log_dir}/debug/%d{yyyy-MM-dd}/debug-%i.log</fileNamePattern><maxHistory>${maxHistory}</maxHistory><!-- 日志文件的最大大小 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>${maxFileSize}</maxFileSize></timeBasedFileNamingAndTriggeringPolicy></rollingPolicy><encoder><pattern>${FORMAT}</pattern></encoder></appender><!-- 将日志写入数据库 --><appender name="DB" class="ch.qos.logback.classic.db.DBAppender"><connectionSource class="ch.qos.logback.core.db.DriverManagerConnectionSource"><driverClass>com.mysql.cj.jdbc.Driver</driverClass><url>jdbc:mysql://127.0.0.1:3306/easyjavase?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC</url><user>root</user><password>123456</password></connectionSource><!--自定义过滤器--><filter class="cn.wujiangbo.filter.LogFilter"></filter></appender><!-- root级别 --><root><!-- 只有该级别日志及以上级别日志才会输出到指定渠道 --><!-- 测试:debug。上生产环境时,需要改成info或error --><level value="info" /><!-- 控制台输出渠道 --><appender-ref ref="console" /><!-- 文件输出渠道 --><appender-ref ref="ERROR" /><appender-ref ref="INFO" /><appender-ref ref="WARN" /><appender-ref ref="DEBUG" /><appender-ref ref="DB" /></root>
</configuration>3.2、过滤器编写
新建一个过滤器,处理日志,哪些需要入库,哪些不需要入库,都在这个过滤器中指定,代码如下:
package cn.wujiangbo.filter;import ch.qos.logback.classic.spi.LoggingEvent;
import ch.qos.logback.core.filter.Filter;
import ch.qos.logback.core.spi.FilterReply;
import cn.hutool.extra.spring.SpringUtil;
import cn.wujiangbo.domain.system.EasySlf4jLogging;
import cn.wujiangbo.service.system.EasySlf4jLoggingService;
import cn.wujiangbo.utils.DateUtils;/*** <p>Slf4j日志入库-过滤器</p>** @author 波波老师(微信:javabobo0513)*/
public class LogFilter extends Filter<LoggingEvent> {public EasySlf4jLoggingService easySlf4jLoggingService = null;@Overridepublic FilterReply decide(LoggingEvent event) {String loggerName = event.getLoggerName();if(loggerName.startsWith("cn.wujiangbo")){//项目本身的日志才会入库EasySlf4jLogging log = new EasySlf4jLogging();log.setLogTime(DateUtils.getCurrentLocalDateTime());log.setLogThread(event.getThreadName());log.setLogClass(loggerName);log.setLogLevel(event.getLevel().levelStr);log.setTrackId(event.getMDCPropertyMap().get("TRACE_ID"));log.setLogContent(event.getFormattedMessage());//日志内容easySlf4jLoggingService = SpringUtil.getBean(EasySlf4jLoggingService.class);//日志入库easySlf4jLoggingService.asyncSave(log);return FilterReply.ACCEPT;}else{//非项目本身的日志不会入库return FilterReply.DENY;}}
}3.3、表准备
数据库准备一张表存开发日志信息,建表语句如下:
DROP TABLE IF EXISTS `easy_slf4j_logging`;
CREATE TABLE `easy_slf4j_logging` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',`log_level` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '日志级别',`log_content` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT '日志内容',`log_time` datetime NULL DEFAULT NULL COMMENT '日志时间',`log_class` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '日志类路径',`log_thread` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '日志线程',`track_id` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '全局跟踪ID',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = 'Slf4j日志表' ROW_FORMAT = Compact;3.4、添加依赖
pom.xml中需要添加下面依赖:
<!--slf4j日志写入数据库的依赖-->
<dependency><groupId>ch.qos.logback</groupId><artifactId>logback-core</artifactId><version>1.2.7</version>
</dependency>3.5、测试
启动项目,浏览器访问:http://localhost:8008/test/test002/tom,然后表中就有数据了,如下:

管理页面就可以直接查到了,如下:

nice
4、优化
4.1、日志定期删除
系统中会有各种各样的日志,防止数据过大,我们可以只保留最近6个月的数据,6个月以前的日志信息将其删除掉,可以搞一个定时任务,每天晚上11:30执行一次,当然,什么时候执行,大家根据自己实际情况修改,我这里定时任务代码如下:
package cn.wujiangbo.task;import cn.wujiangbo.mapper.system.EasySlf4jLoggingMapper;
import cn.wujiangbo.utils.DateUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;/*** <p>定时任务类</p>** @author 波波老师(微信 : javabobo0513)*/
@Component
@Slf4j
public class CommonTask {@Resourcepublic EasySlf4jLoggingMapper easySlf4jLoggingMapper;/*** 删除日志表数据*/@Scheduled(cron = "0 30 23 ? * *")//每天晚上11:30触发public void task001() {log.info("--------【定时任务:删除数据库日志-每晚11:30触发一次】-------------执行开始,时间:{}", DateUtils.getCurrentDateString());easySlf4jLoggingMapper.deleteLog();log.info("--------【定时任务:删除数据库日志-每晚11:30触发一次】-------------执行结束,时间:{}", DateUtils.getCurrentDateString());}
}SQL语句如下:
delete from easy_slf4j_logging where log_time <= DATE_SUB(CURDATE(), INTERVAL 6 MONTH)相关文章:
@Slf4j将日志记录到磁盘和数据库
文章目录 1、背景介绍2、存本地2.1、配置文件2.2、使用 3、存数据库3.1、配置文件改造3.2、过滤器编写3.3、表准备3.4、添加依赖3.5、测试 4、优化4.1、日志定期删除 1、背景介绍 现在我一个SpringBoot项目想记录日志,大概可以分为下面这几种: 用户操作…...
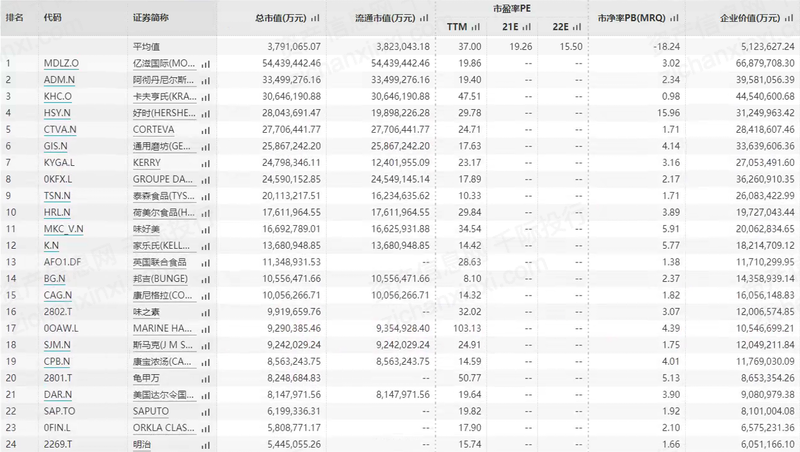
2023年中国制糖行业研究报告
第一章 行业概况 1.1 定义 制糖行业是指以甘蔗、甜菜等为主要原料,通过一系列的工艺流程,生产糖以及相关副产品的产业。它是食品工业的重要组成部分,为人们日常生活中的甜蜜体验提供了必不可少的物质基础。 主要原料: 制糖行业…...

从使用的角度看 ByConity 和 ClickHouse 的差异
自 ClickHouse Inc 宣布其重要新功能仅在 ClickHouse Cloud 上开放以来,一些关注 ByConity 开源的社区小伙伴也来询问 ByConity 后续开源规划。为回答社区疑问,我们将之前分享的关于 ByConity 与 ClickHouse 相关功能对比的 webinar 整理为文章ÿ…...

Eureka处理流程
1、Eureka Server服务端会做什么 1、服务注册 Client服务提供者可以向Server注册服务,并且内部有二层缓存机制来维护整个注册表,注册表是Eureka Client的服务提供者注册进来的。 2、提供注册表 服务消费者用来获取注册表 3、同步状态 通过注册、心跳机制…...

排序算法
文章目录 P1271 【深基9.例1】选举学生会选择排序、冒泡排序、插入排序快速排序排序算法的应用[NOIP2006 普及组] 明明的随机数[NOIP2007 普及组] 奖学金P1781 宇宙总统 #mermaid-svg-Zo8AMme5IW1JlT6K {font-family:"trebuchet ms",verdana,arial,sans-serif;font-s…...

华为政企光传输网络产品集
产品类型产品型号产品说明 maintainProductEA5800-X15 典型配置 上行160G 下行64口GPON 16口XGS PONEA5800系列多业务接入设备定位为面向NG-PON的下一代OLT,基于分布式架构,运用虚拟接入技术,为用户提供宽带、无线、视频回传等多业务统一承…...

四路IC卡读卡器通信协议
1、摘要 Sle4442卡为256字节加密卡,存在读数据、写数据、保护数据以及密码操作。该卡在密码验证之前数据为只读状态,需要写入数据必须先进行密码验证,密码为3个字节,新卡初始密码为0xff,0xff,0xff。该读卡器…...

JavaFX作业
前言: 在写这个作业之前,尝试在JavaFX中添加全局快捷键,测试了大概5个小时,到处找教程换版本,结果最后还是没找到支持Java8以上的(也有可能是我自己的问题),最后只能退而求其次&…...

【使用Python编写游戏辅助工具】第五篇:打造交互式游戏工具界面:PySide6/PyQT高效构建GUI工具
前言 这里是【使用Python编写游戏辅助工具】的第五篇:打造交互式游戏工具界面:PySide6/PyQT高效构建GUI工具。本文主要介绍使用PySide6来实现构建GUI工具。 在前面,我们实现了两个实用的游戏辅助功能: 由键盘监听事件触发的鼠标连…...
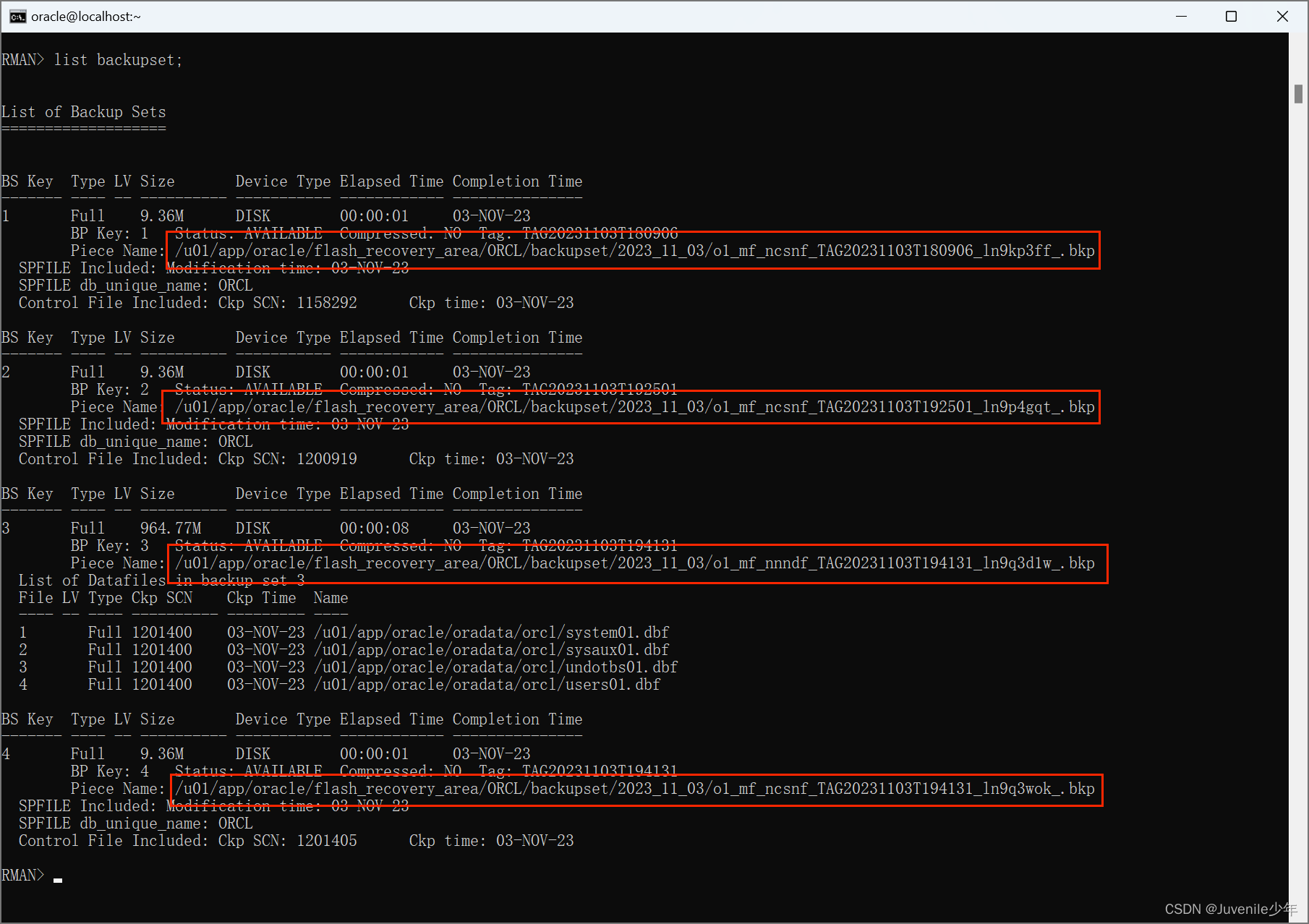
06.Oracle数据备份与恢复
Oracle数据备份与恢复 一、通过RMAN方式备份二、使用emp/imp和expdb/impdb工具进行备份和恢复三、使用Data guard进行备份与恢复 一、通过RMAN方式备份 通过 RMAN(Oracle 数据库备份和恢复管理器)方式备份 Oracle 数据库,可以使用以下步骤&a…...

大航海时代Ⅳ 威力加强版套装 HD Version (WinMac)中文免安装版
《大航海时代》系列的人气SRPG《大航海时代IV》以HD的新面貌再次登场!本作品以16世纪的欧洲“大航海时代”为舞台,玩家将以探险家、商人、军人等不同身份与全世界形形色色的人们一起上演出跌宕起伏的海洋冒险。游戏中玩家的目的是在不同的海域中掌握霸权…...
微信小程序 uCharts的使用方法
一、背景 微信小程序项目需要渲染一个柱状图,使用uCharts组件完成 uCharts官网指引👉:uCharts官网 - 秋云uCharts跨平台图表库 二、实现效果 三、具体使用 进入官网查看指南,有两种方式进行使用:分别是原生方式与组…...
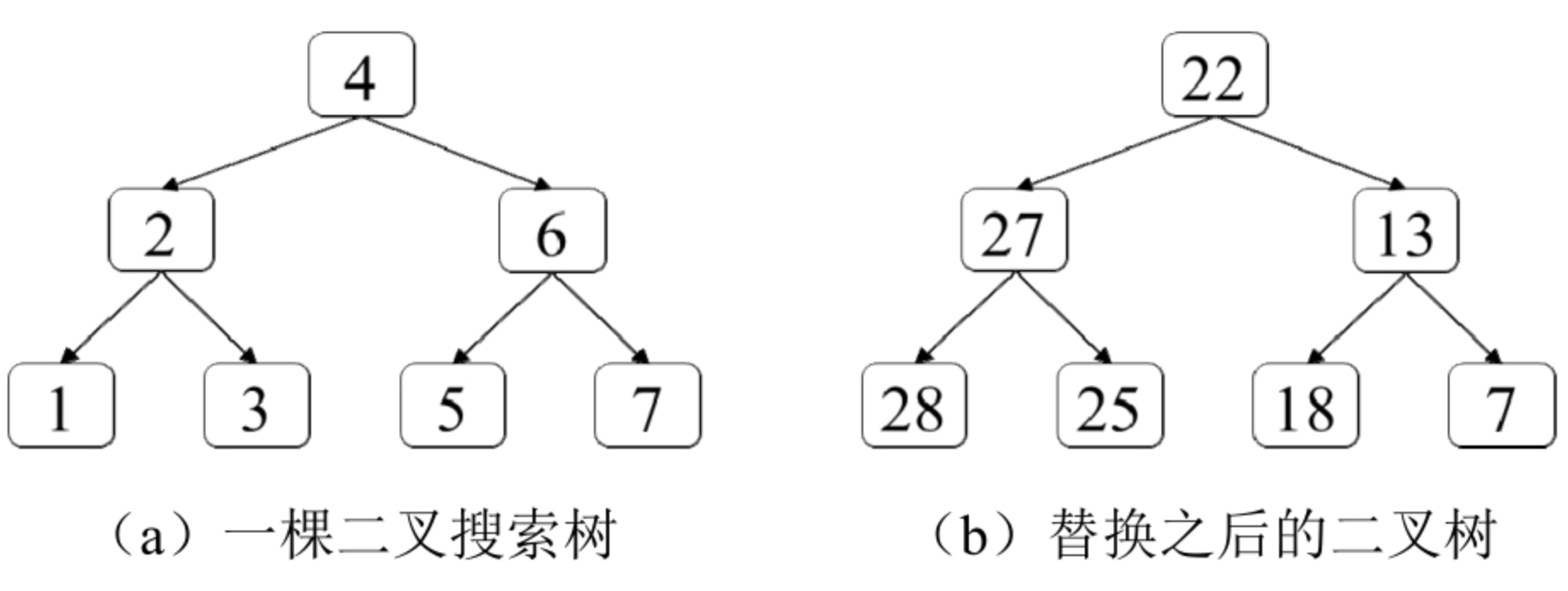
面试算法54:所有大于或等于节点的值之和
题目 给定一棵二叉搜索树,请将它的每个节点的值替换成树中大于或等于该节点值的所有节点值之和。假设二叉搜索树中节点的值唯一。例如,输入如图8.10(a)所示的二叉搜索树,由于有两个节点的值大于或等于6(即…...

七月论文审稿GPT第二版:从Meta Nougat、GPT4审稿到LongLora版LLaMA、Mistral
前言 如此前这篇文章《学术论文GPT的源码解读与微调:从chatpaper、gpt_academic到七月论文审稿GPT》中的第三部分所述,对于论文的摘要/总结、对话、翻译、语法检查而言,市面上的学术论文GPT的效果虽暂未有多好,可至少还过得去&am…...
:神经网络-搭建小实战和Sequential的使用)
PyTorch入门学习(十二):神经网络-搭建小实战和Sequential的使用
目录 一、介绍 二、先决条件 三、代码解释 一、介绍 在深度学习领域,构建复杂的神经网络模型可能是一项艰巨的任务,尤其是当您有许多层和操作需要组织时。幸运的是,PyTorch提供了一个方便的工具,称为Sequential API,…...

Linux shell编程学习笔记20:case ... esac、continue 和break语句
一、case ... esac语句说明 在实际编程中,我们有时会请到多条件多分支选择的情况,用if…else语句来嵌套处理不烦琐,于是JavaScript等语言提供了多选择语句switch ... case。与此类似,Linux Shell脚本编程中提供了case...in...esa…...

树莓派4无法进入桌面模式(启动后出现彩色画面,然后一直黑屏,但是可以正常启动和ssh)
本文记录了这段比较坎坷的探索之路,由于你的问题不一定是我最终解决方案的,可能是前面探索路上试过的,所以建议按顺序看排除前置问题。 双十一又买了个树莓派 4B,插上之前树莓派 4B 的 TF 卡直接就能使用(毕竟是一样规…...

花草世界生存技能
多菌灵 杀菌常用 阿维菌素 杀虫常用 除蚜虫 吡虫啉 有毒性 内吸性(植物吸收) 苦参碱 无毒,中药提取 内吸性药 吡虫啉,噻虫嗪、啶虫脒、苦参碱 栀子花 春秋花后修剪 牡丹 秋冬种植; 洛阳产地; 肥料 …...
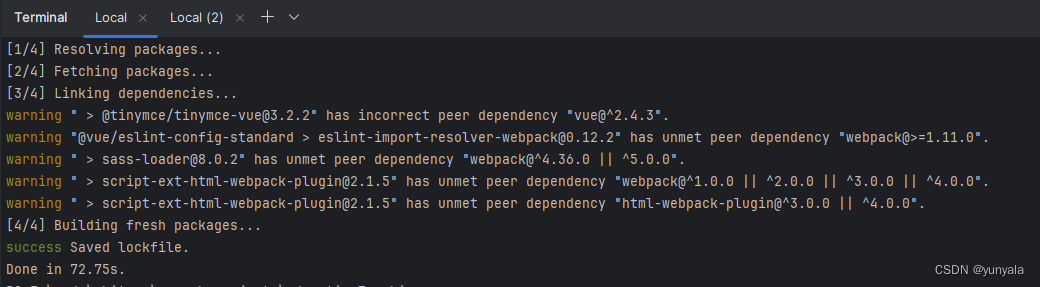
执行npm install时老是安装不成功node-sass的原因和解决方案
相信你安装前端项目所需要的依赖包(npm install 或 yarn install)时,有可能会出现如下报错: D:\code\**project > yarn install ... [4/4] Building fresh packages... [-/6] ⠁ waiting... [-/6] ⠂ waiting... [-/6] ⠂ wai…...

【MongoDB】集群搭建实战 | 副本集 Replica-Set | 分片集群 Shard-Cluster | 安全认证
文章目录 MongoDB 集群架构副本集主节点选举原则搭建副本集主节点从节点仲裁节点 连接节点添加副本从节点添加仲裁者节点删除节点 副本集读写操作副本集中的方法 分片集群分片集群架构目标第一个副本集第二个副本集配置集初始化副本集路由集添加分片开启分片集合分片删除分片 安…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...