Py之auto-gptq:auto-gptq的简介、安装、使用方法之详细攻略
Py之auto-gptq:auto-gptq的简介、安装、使用方法之详细攻略
目录
auto-gptq的简介
1、版本更新历史
2、性能对比
推理速度
困惑度(PPL)
3、支持的模型
3、支持的评估任务
auto-gptq的安装
auto-gptq的使用方法
1、基础用法
(1)、量化和推理
auto-gptq的简介
AutoGPTQ是一个易于使用的低延迟语言模型(LLM)量化软件包,具有用户友好的API,基于GPTQ算法。一个基于 GPTQ 算法,简单易用且拥有用户友好型接口的大语言模型量化工具包。
1、版本更新历史
2023-08-23 - (新闻) - ��� Transformers、optimum 和 peft 完成了对 auto-gptq 的集成,现在使用 GPTQ 模型进行推理和训练将变得更容易!阅读 这篇博客 和相关资源以了解更多细节!
2023-08-21 - (新闻) - 通义千问团队发布了基于 auto-gptq 的 Qwen-7B 4bit 量化版本模型,并提供了详尽的测评结果
2023-08-06 - (更新) - 支持 exllama 的 q4 CUDA 算子使得 int4 量化模型能够获得至少1.3倍的推理速度提升.
2023-08-04 - (更新) - 支持 RoCm 使得 AMD GPU 的用户能够使用 auto-gptq 的 CUDA 拓展.
2023-07-26 - (更新) - 一个优雅的 PPL 测评脚本以获得可以与诸如 llama.cpp 等代码库进行公平比较的结果。
2023-06-05 - (更新) - 集成 ��� peft 来使用 gptq 量化过的模型训练适应层,支持 LoRA,AdaLoRA,AdaptionPrompt 等。
2023-05-30 - (更新) - 支持从 ��� Hub 下载量化好的模型或上次量化好的模型到 ��� Hub。
2、性能对比
推理速度
以下结果通过这个脚本生成,文本输入的 batch size 为1,解码策略为 beam search 并且强制模型生成512个 token,速度的计量单位为 tokens/s(越大越好)。
量化模型通过能够最大化推理速度的方式加载。
| model | GPU | num_beams | fp16 | gptq-int4 |
|---|---|---|---|---|
| llama-7b | 1xA100-40G | 1 | 18.87 | 25.53 |
| llama-7b | 1xA100-40G | 4 | 68.79 | 91.30 |
| moss-moon 16b | 1xA100-40G | 1 | 12.48 | 15.25 |
| moss-moon 16b | 1xA100-40G | 4 | OOM | 42.67 |
| moss-moon 16b | 2xA100-40G | 1 | 06.83 | 06.78 |
| moss-moon 16b | 2xA100-40G | 4 | 13.10 | 10.80 |
| gpt-j 6b | 1xRTX3060-12G | 1 | OOM | 29.55 |
| gpt-j 6b | 1xRTX3060-12G | 4 | OOM | 47.36 |
困惑度(PPL)
对于困惑度的对比, 你可以参考 这里 和 这里
3、支持的模型
你可以使用 model.config.model_type 来对照下表以检查你正在使用的一个模型是否被 auto_gptq 所支持。
比如, WizardLM,vicuna 和 gpt4all 模型的 model_type 皆为 llama, 因此这些模型皆被 auto_gptq 所支持。
| model type | quantization | inference | peft-lora | peft-ada-lora | peft-adaption_prompt |
|---|---|---|---|---|---|
| bloom | ✅ | ✅ | ✅ | ✅ | |
| gpt2 | ✅ | ✅ | ✅ | ✅ | |
| gpt_neox | ✅ | ✅ | ✅ | ✅ | ✅要求该分支的 peft |
| gptj | ✅ | ✅ | ✅ | ✅ | ✅要求该分支的 peft |
| llama | ✅ | ✅ | ✅ | ✅ | ✅ |
| moss | ✅ | ✅ | ✅ | ✅ | ✅要求该分支的 peft |
| opt | ✅ | ✅ | ✅ | ✅ | |
| gpt_bigcode | ✅ | ✅ | ✅ | ✅ | |
| codegen | ✅ | ✅ | ✅ | ✅ | |
| falcon(RefinedWebModel/RefinedWeb) | ✅ | ✅ | ✅ | ✅ |
3、支持的评估任务
目前, auto_gptq 支持以下评估任务: 更多的评估任务即将到来!
LanguageModelingTask,
SequenceClassificationTask 和
TextSummarizationTask;auto-gptq的安装
你可以通过 pip 来安装与 PyTorch 2.0.1 相兼容的最新稳定版本的 AutoGPTQ 的预构建轮子文件:警告: 预构建的轮子文件不一定在 PyTorch 的 nightly 版本上有效。如果要使用 PyTorch 的 nightly 版本,请从源码安装 AutoGPTQ。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple auto-gptq对于 CUDA 11.7:
pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu117/对于 CUDA 11.8:
pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/对于 RoCm 5.4.2: pip install auto-gptq --extra-index-url https://huggingfac
e.github.io/autogptq-index/whl/rocm542/
auto-gptq的使用方法
1、基础用法
(1)、量化和推理
警告:这里仅是对 AutoGPTQ 中基本接口的用法展示,只使用了一条文本来量化一个特别小的模型,因此其结果的表现可能不如在大模型上执行量化后预期的那样好。以下展示了使用 auto_gptq 进行量化和推理的最简单用法:
from transformers import AutoTokenizer, TextGenerationPipeline
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfigpretrained_model_dir = "facebook/opt-125m"
quantized_model_dir = "opt-125m-4bit"tokenizer = AutoTokenizer.from_pretrained(pretrained_model_dir, use_fast=True)
examples = [tokenizer("auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm.")
]quantize_config = BaseQuantizeConfig(bits=4, # 将模型量化为 4-bit 数值类型group_size=128, # 一般推荐将此参数的值设置为 128desc_act=False, # 设为 False 可以显著提升推理速度,但是 ppl 可能会轻微地变差
)# 加载未量化的模型,默认情况下,模型总是会被加载到 CPU 内存中
model = AutoGPTQForCausalLM.from_pretrained(pretrained_model_dir, quantize_config)# 量化模型, 样本的数据类型应该为 List[Dict],其中字典的键有且仅有 input_ids 和 attention_mask
model.quantize(examples)# 保存量化好的模型
model.save_quantized(quantized_model_dir)# 使用 safetensors 保存量化好的模型
model.save_quantized(quantized_model_dir, use_safetensors=True)# 将量化好的模型直接上传至 Hugging Face Hub
# 当使用 use_auth_token=True 时, 确保你已经首先使用 huggingface-cli login 进行了登录
# 或者可以使用 use_auth_token="hf_xxxxxxx" 来显式地添加账户认证 token
# (取消下面三行代码的注释来使用该功能)
# repo_id = f"YourUserName/{quantized_model_dir}"
# commit_message = f"AutoGPTQ model for {pretrained_model_dir}: {quantize_config.bits}bits, gr{quantize_config.group_size}, desc_act={quantize_config.desc_act}"
# model.push_to_hub(repo_id, commit_message=commit_message, use_auth_token=True)# 或者你也可以同时将量化好的模型保存到本地并上传至 Hugging Face Hub
# (取消下面三行代码的注释来使用该功能)
# repo_id = f"YourUserName/{quantized_model_dir}"
# commit_message = f"AutoGPTQ model for {pretrained_model_dir}: {quantize_config.bits}bits, gr{quantize_config.group_size}, desc_act={quantize_config.desc_act}"
# model.push_to_hub(repo_id, save_dir=quantized_model_dir, use_safetensors=True, commit_message=commit_message, use_auth_token=True)# 加载量化好的模型到能被识别到的第一块显卡中
model = AutoGPTQForCausalLM.from_quantized(quantized_model_dir, device="cuda:0")# 从 Hugging Face Hub 下载量化好的模型并加载到能被识别到的第一块显卡中
# model = AutoGPTQForCausalLM.from_quantized(repo_id, device="cuda:0", use_safetensors=True, use_triton=False)# 使用 model.generate 执行推理
print(tokenizer.decode(model.generate(**tokenizer("auto_gptq is", return_tensors="pt").to(model.device))[0]))# 或者使用 TextGenerationPipeline
pipeline = TextGenerationPipeline(model=model, tokenizer=tokenizer)
print(pipeline("auto-gptq is")[0]["generated_text"])相关文章:
Py之auto-gptq:auto-gptq的简介、安装、使用方法之详细攻略
Py之auto-gptq:auto-gptq的简介、安装、使用方法之详细攻略 目录 auto-gptq的简介 1、版本更新历史 2、性能对比 推理速度 困惑度(PPL) 3、支持的模型 3、支持的评估任务 auto-gptq的安装 auto-gptq的使用方法 1、基础用法 (1)、量…...

【Linux】Linux+Nginx部署项目(负载均衡动静分离)
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于Linux的相关操作吧 目录 🥳🥳Welcome Huihuis Code World ! !🥳🥳 一.Nginx负载均衡 1.什么是负载均衡 2.实…...

C++笔记之vector的成员函数swap()和data()
C笔记之vector的成员函数swap()和data() 标准C中的std::vector类确实有swap()和data()这两个成员函数。下面是它们的简要描述: swap(): std::vector的swap()成员函数用于交换两个向量的内容,实现了高效的交换操作,不需要复制向量的元素。这…...

Linux centos环境 安装谷歌浏览器
教程 地址...
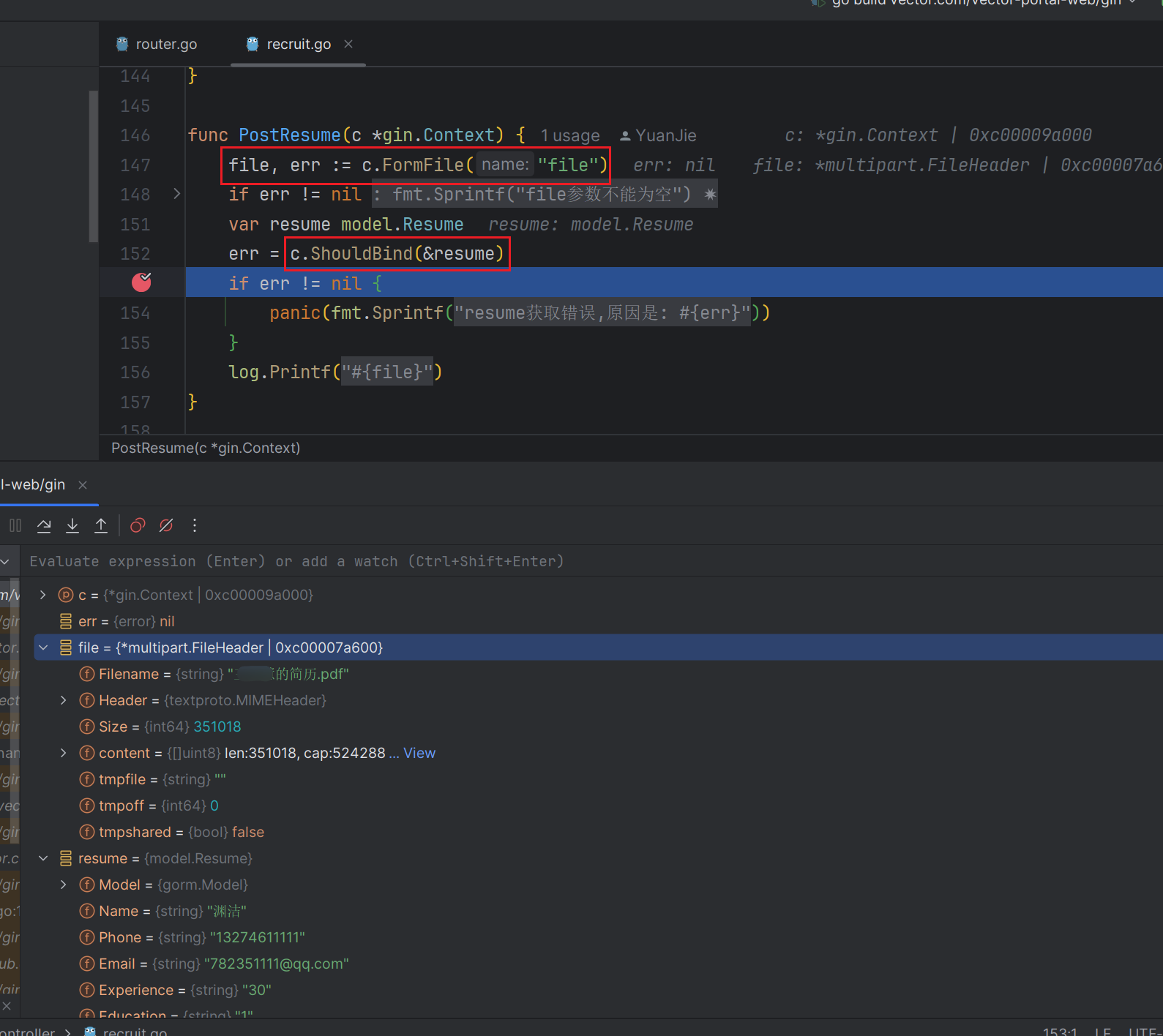
go-gin-vue3-elementPlus带参手动上传文件
文章目录 一. 总体代码流程1.1 全局Axios部分样例1.2 上传业务 二. 后端部分三. 测试样例 go的mvc层使用gin框架. 总的来说gin的formFile封装的不如springboot的好.获取值有很多的坑. 当然使用axios的formData也有不少坑.现给出较好的解决办法 以下部分仅贴出关键代码 一. 总…...

艺术的维度:洞察AI诈骗,优雅防范之艺术
当前,AI技术的广泛应用为社会公众提供了个性化智能化的信息服务,也给网络诈骗带来可乘之机,如不法分子通过面部替换语音合成等方式制作虚假图像、音频、视频仿冒他人身份实施诈骗、侵害消费者合法权益。 以下是一些常见的AI诈骗例子…...
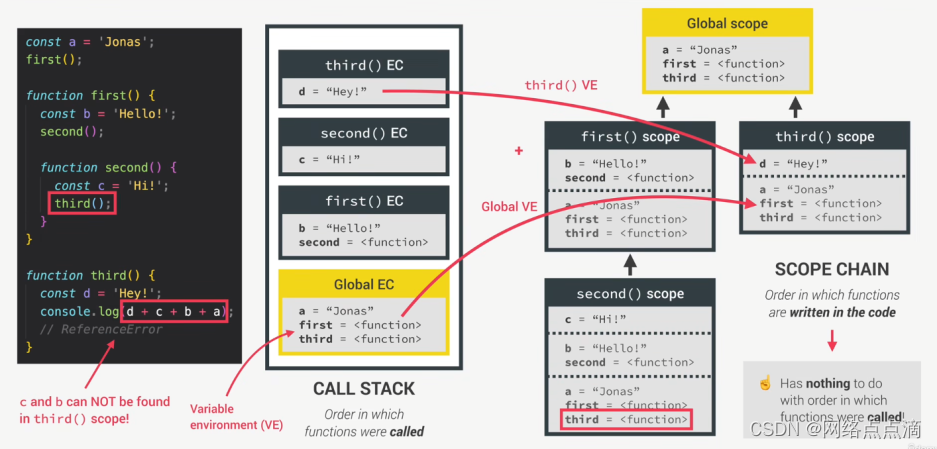
JavaScript的作用域和作用域链
作用域 ● 作用域(Scoping):我们程序中变量的组织和访问方式。"变量存在在哪里?“或者"我们可以在哪里访问某个变量,以及在哪里不能访问?” ● 词法作用域(Lexical scopingÿ…...
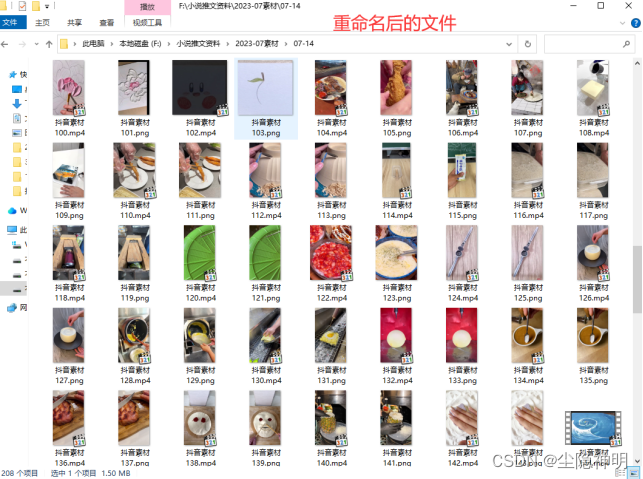
电脑文件批量重命名攻略:高效操作技巧助您轻松完成任务
在日常使用电脑时,我们经常需要对文件进行重命名。当文件数量众多时,手动重命名既耗时又容易出错。此时,借助一些实用技巧,我们可以轻松地完成电脑文件的批量重命名。本文将提供一份全面的电脑文件批量重命名攻略,帮助…...

四、三种基本程序结构
1、程序结构 (1)在C语言程序中,一共有三种程序结构:顺序结构、选择结构(分支结构)、循环结构。 顺序结构:按照事务本身特性,必须一个接着一个来完成。选择结构:到某个节点后,会根据一次判断结果来决定之后…...

深入理解元素的高度、行高、行盒和vertical-align
1.块级元素的高度 当没有设置高度时,高度由内容撑开,实际上是由行高撑开,当有多行时,高度为每行的行高高度之和。 行高为什么存在? 因为每行都由一个行盒包裹,行高实际上是行盒的高度。 2.什么是行盒&am…...

什么叫储能能量管理单元EMU?储能能量管理单元EMU功能?储能EMU是什么?储能能量管理系统如何实现一次调频AGC-AVC功能?
一:储能EMU是什么意思?什么叫储能能量管理单元EMU? EMU是能量管理单元的英文缩写 (Energy Management Unit, EMU) EmuPower3300能量管理单元EMU是由广州智昊电气研发配套EsccPower3300储能协调管理器组成对光伏电站的管理,控制,…...

机器学习之决策树
决策树: 是一种有监督学习方法,从一系列有特征和标签的数据中总结出决策规则,并采用树状图的结构来呈现规则,用来解决分类和回归问题。 节点:根节点:没有进边,有出边。包含最初的,针…...

聊聊logback的UNDEFINED_PROPERTY
序 本文主要研究一下logback的UNDEFINED_PROPERTY substVars ch/qos/logback/core/util/OptionHelper.java public static String substVars(String input, PropertyContainer pc0, PropertyContainer pc1) {try {return NodeToStringTransformer.substituteVariable(input,…...
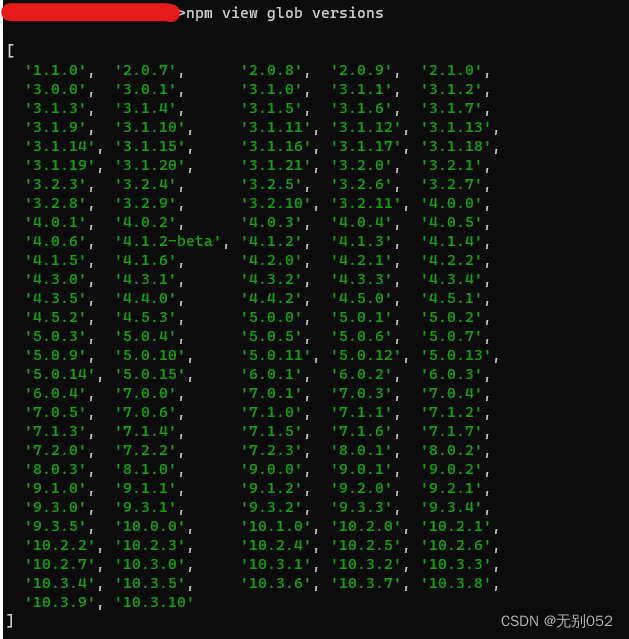
记一次pdjs时安装glob出现,npm ERR! code ETARGET和npm ERR! code ELIFECYCLE
如往常一样,我使用pdjs来编译proto文件,但出现了以下报错: 大致就是pdjs的util在尝试执行npm install glob^7.2.1 escodegen^1.13.0时出错了 尝试手动执行安装,escodegen被正确安装,但glob^7.2.1出错 npm ERR! code E…...
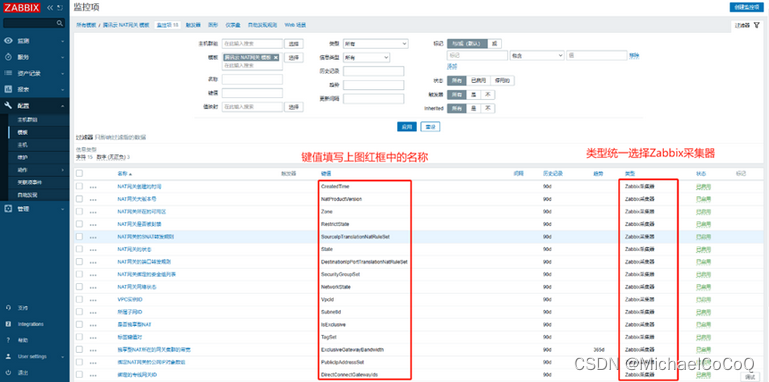
Zabbix如何监控腾讯云NAT网关
1、NAT网关介绍 NAT 网关(NAT Gateway)是一种支持 IP 地址转换服务,提供网络地址转换能力,主要包括SNAT(Source Network Address Translation,源网络地址转换)和DNAT(Destination N…...

SpringBoot案例(数据层、业务层、表现层)
1.创建项目 2.选择坐标 3.添加坐标 说明:为了便于开发,引入了lombak坐标。 <!--添加mybatis-plus坐标--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><ver…...

交叉编译程序:以 freetype 为例
1 程序运行的一些基础知识 1.1 编译程序时去哪找头文件? 系统目录:就是交叉编译工具链里的某个 include 目录;也可以自己指定:编译时用 “ -I dir ” 选项指定。 1.2 链接时去哪找库文件? 系统目录&#…...

spring-cloud-starter-dubbo不设置心跳间隔导致生产者重启no Provider问题记录
版本 spring-cloud-starter-dubbo-2.2.4.RELEASE 问题描述 生产者重启后,正常注册到注册中心,但是消费者调用接口是no provider,偶现,频繁出现 解决办法 先说原因和解决办法,有兴趣可以看下问题的排查过程。 原因…...

【数据结构】败者树的建树与比较过程
文章目录 前置知识归并段 建树过程比较过程疑问为什么比较次数减少了?如果某个归并段的元素一直获胜,没有元素了怎么办?处理方法 1处理方法 2 前置知识 归并段 外部排序算法通常用于处理大规模数据,其中数据量远超过计算机内存的…...

GlobalMapper---dem生成均匀分布的网格,或者均匀分布的点高程点
1打开DEM数据。点击工具栏上的Open Data File(s)按钮,打开DEM数据 2点击【Create Grid】按钮 3生成点 4导出格式xyz 5南方cass展点 6过滤抽稀...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...
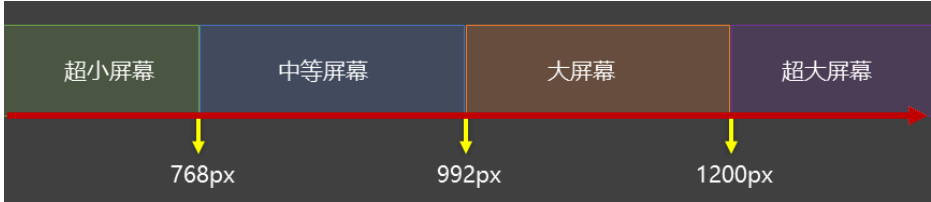
CSS3相关知识点
CSS3相关知识点 CSS3私有前缀私有前缀私有前缀存在的意义常见浏览器的私有前缀 CSS3基本语法CSS3 新增长度单位CSS3 新增颜色设置方式CSS3 新增选择器CSS3 新增盒模型相关属性box-sizing 怪异盒模型resize调整盒子大小box-shadow 盒子阴影opacity 不透明度 CSS3 新增背景属性ba…...