Hadoop环境搭建及Demo
参考博客
Windows 10安装Hadoop 3.3.0教程 (kontext.tech)
Hadoop入门篇——伪分布模式安装 & WordCount词频统计 | Liu Baoshuai’s Blog
Hadoop安装教程 Linux版_linux和hadoop的安装_lnlnldczxy的博客-CSDN博客
hadoop启动出错 The value of property bind.address must not be null
Hadoop:MapReduce之倒排索引(Combiner和Partitioner的使用)
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.
使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)
环境配置
WSL-Linux
Win商店下载Ubuntu,使用VS Code 连接到WSL,终端–>新建终断,在终端中进行配置。
配置 Java
先在终端输入java -version 查看是否已安装 java,有的话删掉再去Oracle官网下JDK1.8版本,若没有也去官网下JDK1.8版本。(hadoop 貌似最大仅支持 JDK11)
# 先更新一下
sudo apt-get updateflyboy@flyboy:~$ java -version
Command 'java' not found, but can be installed with:
sudo apt install openjdk-11-jre-headless # version 11.0.18+10-0ubuntu1~22.04, or
sudo apt install openjdk-8-jre-headless # version 8u362-ga-0ubuntu1~22.04
...........
下载后,终端执行cd /mnt/d/Download 进入到压缩包下载位置,再执行如下命令将其移到WSL里:
cd /mnt/d/Download
sudo mv jdk-8u391-linux-x64.tar.gz /home/EnvironmentSetting/Java/
# 此处会涉及到权限问题,后面会有介绍:设定flyboy相关文件操作权限
# 此处暂时用 sudo mkdir -p /home/EnvironmentSetting/Java 创建指定文件夹
然后cd /home/EnvironmentSetting/Java/ 再执行如下命令进行解压并将其移到/usr/local/java:
sudo tar -zxvf jdk-8u391-linux-x64.tar.gz
sudo mv jdk1.8.0_391/ /usr/local/java
之后,设置 JAVA_HOME 环境变量,以便在终端中运行 Java 程序:在终端中输入如下命令(该命令设置系统环境变量,.bashrc 为设置用户环境变量),按 i 进入编辑模式:
sudo vi /etc/profile
将如下 Java 的系统环境变量设置复制到最后:
JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
按 esc 退出编辑,输入 :wq 保存并退出。在 终端中输入 source /etc/profile,使配置生效。
若想很方便的通过 VS Code 修改 WSL-Linux 文件,可执行如下命令赋予当前用户相关操作权限:
# sudo chown -R myuser /path/to/folder
# myuser: 当前用户名, /path/to/folder:需要操作的文件夹路径
sudo chown -R flyboy /home
然后,通过 VS Code 打开 flyboy/.bashrc,将 java 的用户环境变量设置复制到最后即可:
# jdk环境
export JAVA_HOME=/usr/local/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=${JAVA_HOME}/bin:$PATH
在 终端中输入 source ~/.bashrc,使配置生效。输入如下命令验证 java 是否安装成功:
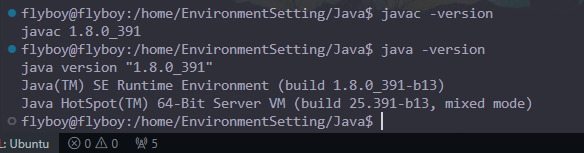
配置 Hadoop
设置 ssh 免密登录
Hadoop 是分布式平台,需多机间协作,设置 ssh 免密登录可减少每次登陆主机输密码的繁琐流程。
-
安装 SSH:Ubuntu 默认已安装了 SSH client,此外还需安装 SSH server。
sudo apt-get install openssh-server -
设置免密登录:终端输入
ssh-keygen -t rsa以生成密钥对,回车到底,将公钥的内容写入到 authorized_keys 文件中:ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
-
免密登录:终端输入
ssh localhost,若能免密登录,即设置成功。ssh localhost -
可能会报错:
ssh: connect to host localhost port 22: Connection refused。
错误信息解决
重新下载,确认都已下载完毕:
sudo apt-get purge openssh-server # purge 是卸载并删除配置文件
sudo apt-get install openssh-server openssh-client
尝试启动 ssh 服务,依据上述步骤再次生成密钥:
sudo service ssh start
结果可能报错 sshd: no hostkeys available – exiting。依次输入如下命令可解决该错误:
ssh-keygen -A
/etc/init.d/ssh start
然后重启:sudo service ssh restart ,再关闭防火墙设置,重新ssh localhost :
flyboy@flyboy:~$ sudo service ssh restart* Restarting OpenBSD Secure Shell server sshd [ OK ]
flyboy@flyboy:~$ sudo ufw disable
Firewall stopped and disabled on system startup
flyboy@flyboy:~$ ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ED25519 key fingerprint is SHA256:U/ETlYH9JEAIQ+9SR5vnQCdKxEgN/MX1JxLvN5rJlAE.
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])?
输入 no,然后输入如下命令:
chmod 777 /etc/ssh/ssh_config
sudo vi /etc/ssh/ssh_config
然后在这个文件的最后加上如下内容:
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
flyboy@flyboy:~$ ssh localhost
Warning: Permanently added 'localhost' (ED25519) to the list of known hosts.
Welcome to Ubuntu 22.04.2 LTS (GNU/Linux 5.10.102.1-microsoft-standard-WSL2 x86_64)
警告信息的消除办法:创建~/.ssh/config 文件
vim ~/.ssh/config
在文件中输入如下内容再登录即可:
UserKnownHostsFile ~/.ssh/known_hosts
运行 ps -e | grep ssh,查看是否有sshd进程:
flyboy@flyboy:~$ ps -e | grep ssh1344 pts/9 00:00:00 ssh1345 ? 00:00:00 sshd1369 ? 00:00:00 sshd
...........................
hadoop 下载与配置
官网下载 Hadoop ,然后将下载的压缩包文件移动后并解压到 /usr/local/hadoop 文件夹下:
cd /mnt/d/Download
# sudo mkdir -p /home/EnvironmentSetting/Temp
sudo mv hadoop-3.3.6.tar.gz /home/EnvironmentSetting/Temp/
cd /home/EnvironmentSetting/Temp
sudo tar -zxvf hadoop-3.3.6.tar.gz
sudo mv hadoop-3.3.6 /usr/local/hadoop
在 终端中输入 sudo vi /etc/profile ,按 i 进入编辑模式:
HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native
按 esc 退出编辑,输入 :wq 保存并退出。再输入source /etc/profile ,使配置的环境变量生效。
然后输入如下命令以通过 VS Code 修改 /usr/local/hadoop 下的所有文件:
# sudo chown -R 用户名 Hadoop安装目录
sudo chown -R flyboy /usr/local/hadoop
然后通过 VS Code 打开 /usr/local/hadoop/etc/hadoop/ 文件夹:
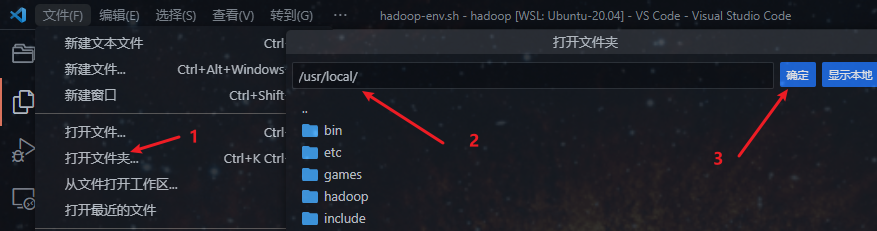
打开配置 hadoop-env.sh 文件:
# 显式声明java路径
export JAVA_HOME=/usr/local/java
source ./hadoop-env.sh
然后,输入hadoop version 已验证是否安装成功:

伪分布式配置
配置 core-site.xml 文件
sudo vi /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><!-- 指定hadoop运行时产生文件的存储路径 --><property><name>hadoop.tmp.dir</name><!-- 配置到hadoop目录下temp文件夹 --><value>file:/usr/local/hadoop/tmp</value></property>
</configuration>
配置 hdfs-site.xml 文件
sudo vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration><property><!--指定hdfs保存数据副本的数量,包括自己,默认为3--><!--伪分布式模式,此值必须为1--><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><!-- name node 存放 name table 的目录 --><value>file:/usr/local/hadoop/tmp/hdfs/name</value></property><property><name>dfs.datanode.data.dir</name><!-- data node 存放数据 block 的目录 --><value>file:/usr/local/hadoop/tmp/hdfs/data</value></property><property><name>dfs.namenode.http-address</name><value>localhost:50070</value></property><property><name>dfs.secondary.http.address</name><value>localhost:50090</value></property>
</configuration>
配置 mapred-site.xml 文件
sudo vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration><property><!--指定mapreduce运行在yarn上--><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
配置 yarn-site.xml 文件
sudo vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>localhost:9000</value></property>
</configuration>
启动 hadoop
初始化
在 终端中输入如下命令进行初始化操作(只初次启动需要):
hdfs namenode -format
启动 hadoop 集群
在 终端中输入start-all.sh(或分别输入 start-dfs.sh 和 start-yarn.sh):
start-all.sh
hadoop fs -ls /
使用 jps (JavaVirtualMachineProcessStatus) 命令查看 hadoop 是否已启动,运行的 java 进程中应包含以下几种:
4050 Jps
3956 NodeManager
3653 SecondaryNameNode
3414 NameNode
3852 ResourceManager
3518 DataNode
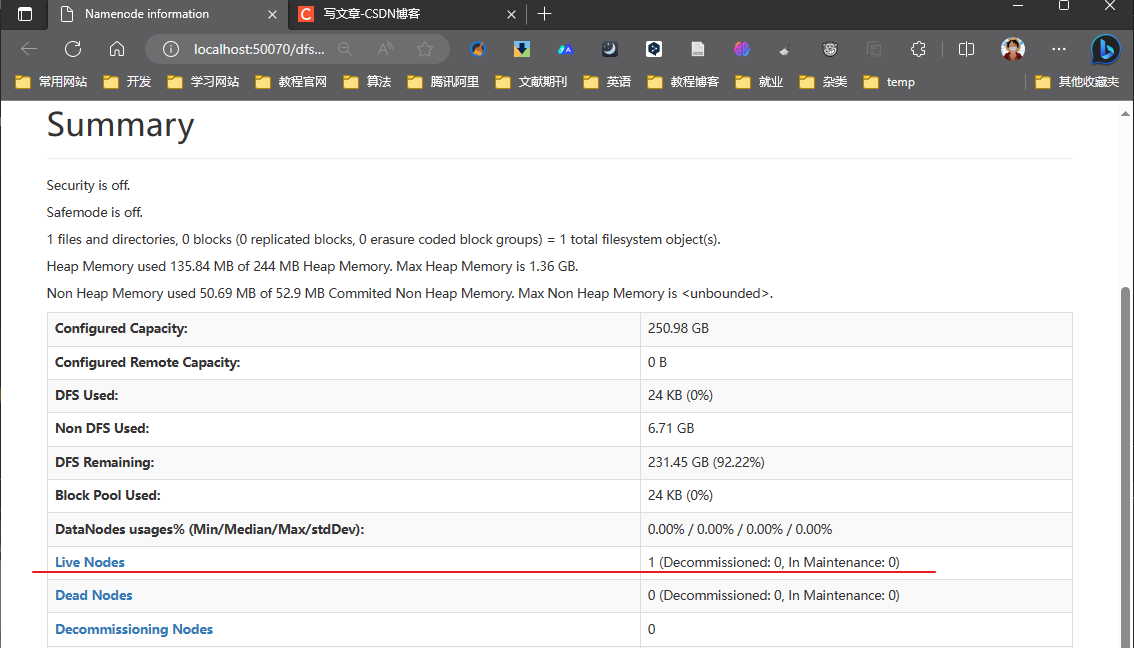
查看 NameNode 和 Yarn
访问 http://localhost:50070/dfshealth.html#tab-overview
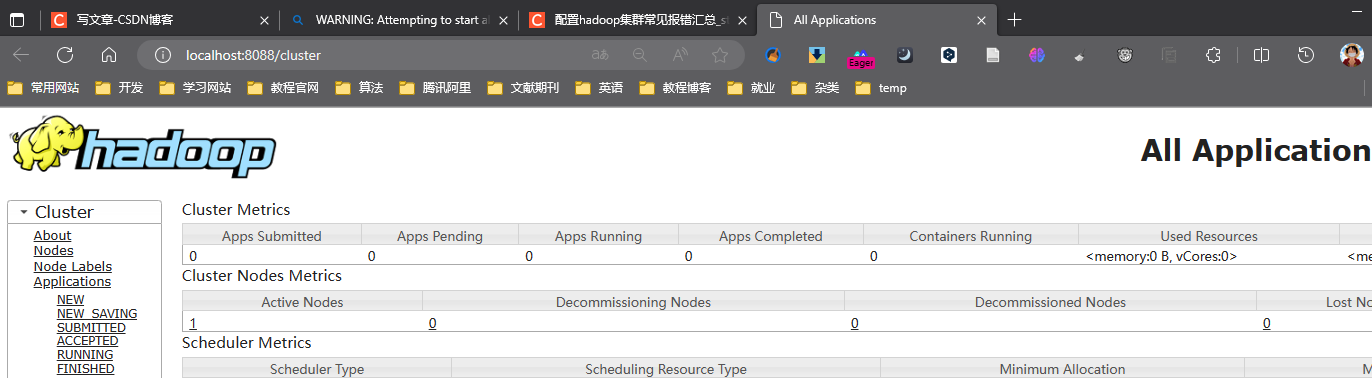
访问 http://localhost:8088/cluster
关闭 hadoop 集群
在 终端中输入 stop-all.sh (或 stop-yarn.sh + stop-dfs.sh):
stop-all.sh
错误解决
值得注意的是:必须消除ssh localhost带来的警告信息,否则会一直出现如下错误:
hdfs namenode -format:21/02/03 03:58:54 ERROR namenode.NameNode: Failed to start namenode.
jps后仅启动如下服务:(ResourceManager未启动,所以8088端口访问失败)
flyboy@flyboy:/usr/local/hadoop$ jps
13569 Jps
12289 NameNode
12441 DataNode
12972 NodeManager
8685 SecondaryNameNode
Hadoop伪分布式无法启动ResourceManager问题解决办法
查阅logs下有关ResourceManager的日志信息发现报错如下:
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.net.BindException: Problem binding to [localhost:9000] java.net.BindException: Address already in use; For more details see: http://wiki.apache.org/hadoop/BindException
修改 yarn-site.xml 内容:
<configuration>
<!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
停止服务后删除 hadoop/tmp 文件夹重新格式化启动:
stop-all.sh
sudo rm -r ./tmp
hdfs namenode -format
start-all.sh
hadoop fs -ls /
jps
jps后服务均启动:
17392 DataNode
17604 SecondaryNameNode
17974 NodeManager
18486 Jps
17837 ResourceManager
17231 NameNode
倒排索引
案例设定
-
实现效果:统计各文档中出现的每个单词在各文档中出现的次数。
-
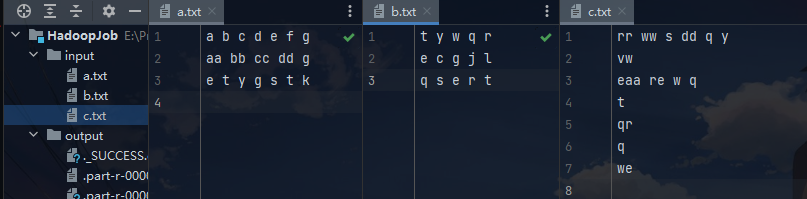
输入:例如 a.txt,b.txt,c.txt…。每个文档的内容为若干行单词,单词间用空格分开;例如a.txt的内容如下:
a b c d e f g aa bb cc dd g e t y g s t k -
分区要求:以 a-m 字母开头(不区分大小写)的单词出现在 0 区;以 n-z 字母开头的单词出现在 1 区;其余开头的单词出现在 2 区;
-
单词的输出形式:c a.txt->1,b.txt->1,其中 c 是单词(亦为key),”a.txt->1,b.txt->1” 表示输出的 value,即 c 在 a.txt 文档中出现1次,在 b.txt 文档中出现1次;
-
案例说明:
-
Mapper:统计各文档中不同单词的出现次数;例如,如果输入文本是"Hello world, hello Java"且文件名为"example.txt",则映射器会生成以下键值对:
- 键:“Hello->example.txt”, 值:“1”
- 键:“world,->example.txt”,值:“1”
- 键:“hello->example.txt”, 值:“1”
- 键:“Java->example.txt”, 值:“1”
-
Reducer,将以上结果作为输入,将相同的键进行聚合(在reducer前可以进行组合归约以及分区归约以加速reducer归约速度),将相同键的所有值拼接为一个字符串,处理后输出倒排索引;输出结果(K,V)的形式为:
hello a.txt->2,b.txt->1。 -
注:根据 context 获取文件名方法:
FileSplit inputSplit = (FileSplit)context.getInputSplit(); Path path = inputSplit.getPath(); String filename = path.getName();
-
实现过程
IntelliJ IDEA 创建 Maven 工程
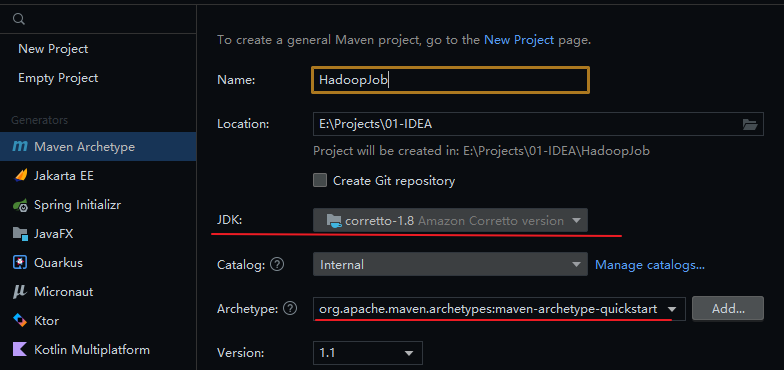
项目层次结构如图:
pom.xml
<properties><hadoop.version>3.3.6</hadoop.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>3.8.1</version><scope>test</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency>
</dependencies>
完整代码
ReversedIndexMain.java
package org.team.ReversedIndex;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;// 创建倒排索引的主类
public class ReversedIndexMain{public static void main(String[] args) throws Exception {Job job = Job.getInstance(new Configuration()); // 创建Job类的新实例,并配置必要的设置job.setJarByClass(ReversedIndexMain.class); // 指定作业的主类job.setMapperClass(ReversedMapper.class); // 设置 mapper 类job.setMapOutputKeyClass(Text.class); // 指定 mapper 输出的键值类型job.setMapOutputValueClass(Text.class);job.setReducerClass(ReversedReducer.class); // 设置 reducer 类job.setOutputKeyClass(Text.class); // 指定 reducer 输出的键值类型job.setOutputValueClass(Text.class);// 设置组合器类:可选的优化步骤,在将数据发送给reducer之前执行本地归约操作job.setCombinerClass(ReversedCombiner.class);job.setPartitionerClass(ReversedPartitioner.class); // 设置自定义分区器类job.setNumReduceTasks(3); // 设置归约任务的数量,以指定所需的 reducer 数量// 设置输入,输出路径.输入路径是包含输入文件的目录,输出路径是存储输出的目录FileInputFormat.setInputPaths(job,args[0]);FileOutputFormat.setOutputPath(job,new Path(args[1]));// 提交作业以执行,并等待其完成boolean result = job.waitForCompletion(true);//判断作业是否完成控制程序结束System.exit(result?0:1);}
}
ReversedMapper.java
package org.team.ReversedIndex;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;// 倒排mapper类实现:扫描每个文档里的数据,不论重复,出现就标1
public class ReversedMapper extends Mapper<LongWritable, Text,Text,Text> {private Text outKey = new Text();private Text outValue = new Text("1"); // 默认值 1@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 获取输入片段的文件名,然后使用split(" ")将文本数据拆分为单词数组FileSplit inputSplit = (FileSplit)context.getInputSplit();String fileName = inputSplit.getPath().getName();String[] words = value.toString().split(" ");for (String word : words) {outKey.set(word+"->"+fileName); // 将单词和文件名以箭头连接起来作为输出键context.write(outKey,outValue); // 将输出键值对写入上下文(Context)中}}
}
ReversedCombiner.java
package org.team.ReversedIndex;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;// 倒排组合器实现:接收来自mapper的部分键值对数据,并在本地对相同的键进行聚合,计算各个值的总和
public class ReversedCombiner extends Reducer<Text,Text,Text, Text> {private Text outKey = new Text();private Text outValue = new Text();@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {// 迭代values参数,可获取与当前键相关联的所有值.将每个值解析为整数并累加到count变量中.// 然后,使用key参数获取当前键的字符串表示,并使用split("->")方法将其拆分为单词和文件名.// 将单词设置为outKey,并将文件名和计数以"fileName->count"的形式设置为outValue.int count = 0;for (Text value : values) {count+=Integer.parseInt(value.toString());}String[] words = key.toString().split("->");outKey.set(words[0]);outValue.set(words[1]+"->"+count);context.write(outKey,outValue);}
}
ReversedPartitioner.java
package org.team.ReversedIndex;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
// 倒排分区器实现:根据键的首字母将键值对分配到不同的分区中
public class ReversedPartitioner extends Partitioner<Text,Text> {@Overridepublic int getPartition(Text text, Text text2, int i) {// 将文本类型的键转换为字符串,并获取该字符串的第一个字符(以小写形式).然后,使用字符的ASCII码进行判断,将键分配到不同的分区.// 如此操作可以将具有相似首字母的键分配到同一分区中,从而提高 Reduce 阶段的效率char head = Character.toLowerCase(text.toString().charAt(0));if(head>='a'&& head<='m')return 0;else if(head>'m'&& head<='z')return 1;elsereturn 2;}
}
ReversedReducer.java
package org.team.ReversedIndex;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
// 归约类实现:接收来自映射器的键值对数据,并将相同的键进行聚合,将相同键的所有值拼接为一个字符串
public class ReversedReducer extends Reducer<Text,Text, Text,Text> {private Text outValue = new Text();@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {// 迭代values参数,以获取与当前键相关联的所有值.使用StringBuilder对象将这些值逐个添加到字符串中,并使用逗号分隔,// 最后,通过 substring() 方法去除字符串末尾的逗号,并将结果设置为 outValue的值// 然后,使用 context.write()方法将输出键值对写入上下文(Context)中StringBuilder stringBuilder = new StringBuilder();for (Text value : values) {stringBuilder.append(value.toString()).append(",");}String outStr = stringBuilder.substring(0,stringBuilder.length()-1);outValue.set(outStr);context.write(key,outValue);}
}
IDEA测试
注:本地测试也需要配置 hadoop 的 windows 环境,与上述配置 Linux 的类似。
数据集:
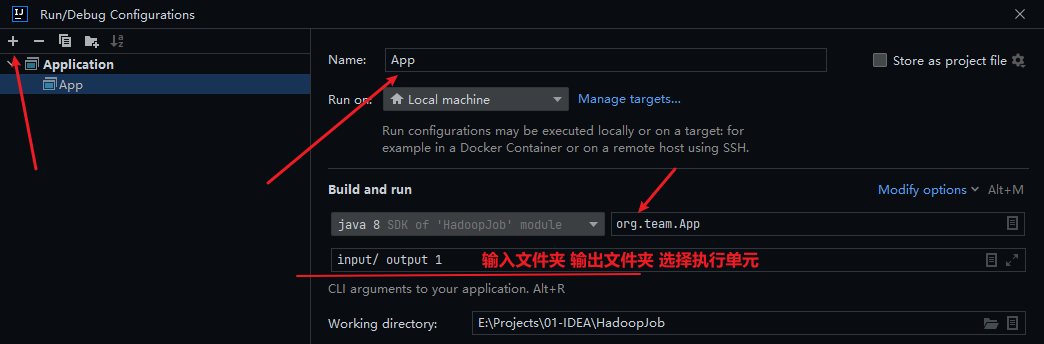
配置运行参数:(下次运行需手动删除 output 文件夹,否则报错)
测试结果:
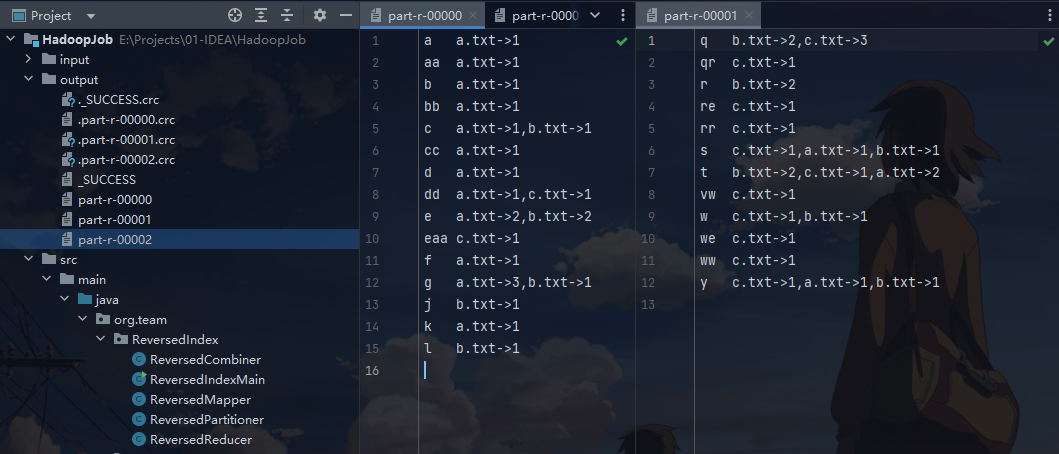
Maven 打包
如图所示,在右侧点击 Maven 的package进行打包,打包结果会在项目的target文件夹中输出。最终需要的只是Jar包。
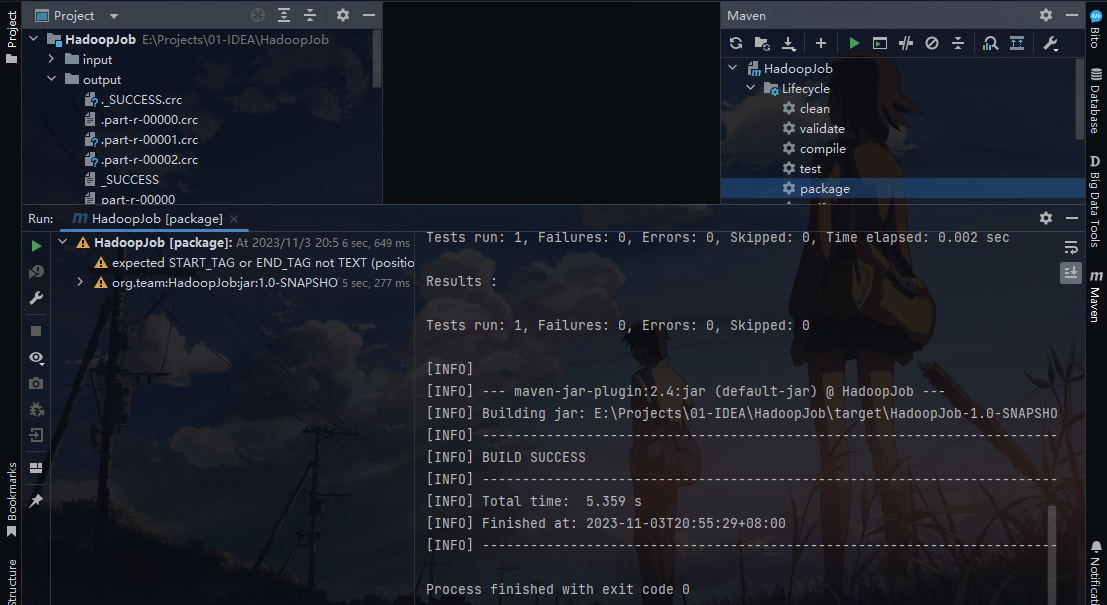
Hadoop 集群运行
将Windows里用IDEA生成的Jar包copy到Linux用户目录下:/home/flyboy/。然后将本地文件上传至dfs文件系统中:将Windows里用IDEA跑的数据集也copy到/home/flyboy/下,然后在dfs系统中新建一个名为 local 的文件夹,将当前目录切换到 hadoop 安装目录下,使用如下命令:
cd /usr/local/hadoop
hdfs dfs -mkdir /local
hadoop fs -ls / # 查看是否创建成功
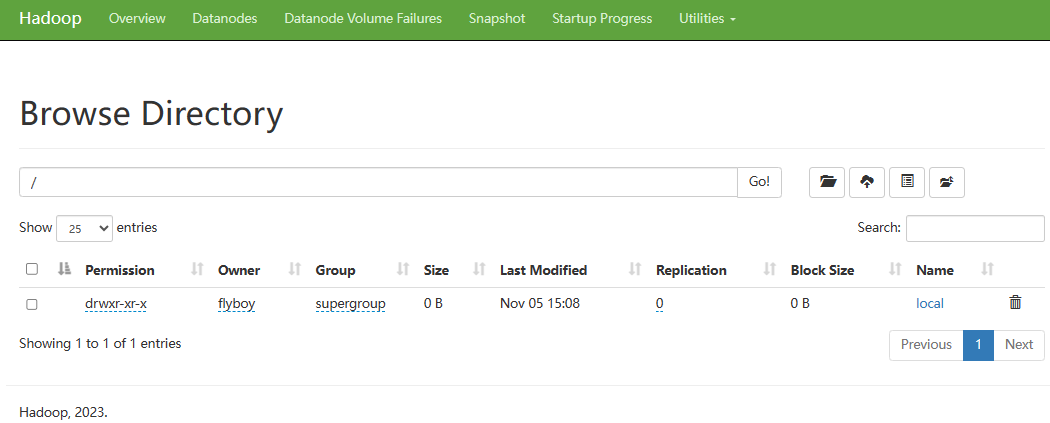
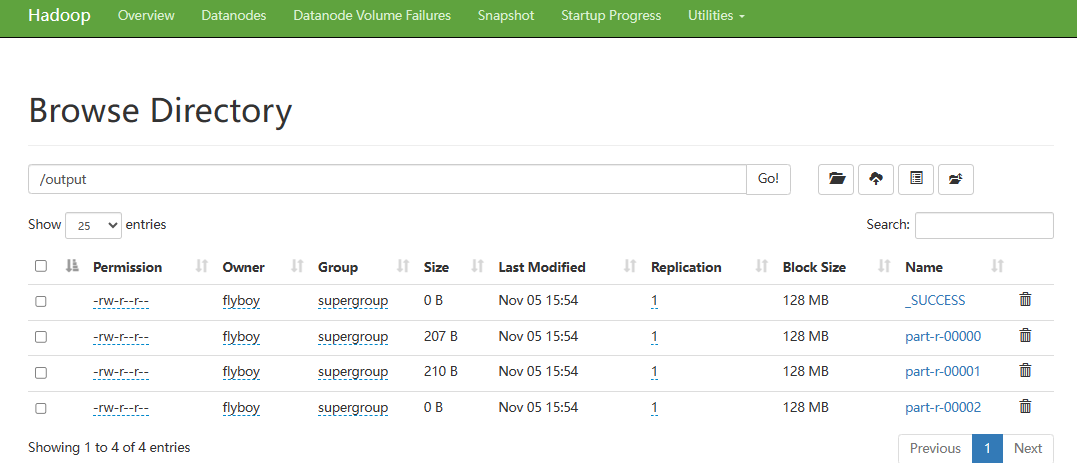
访问 http://localhost:50070/dfshealth.html#tab-overview ,点击“Utilities --> Browse the file system“,在地址栏上输入“/”,则在dfs系统上的所有文件夹及文件都会显示,如下图:
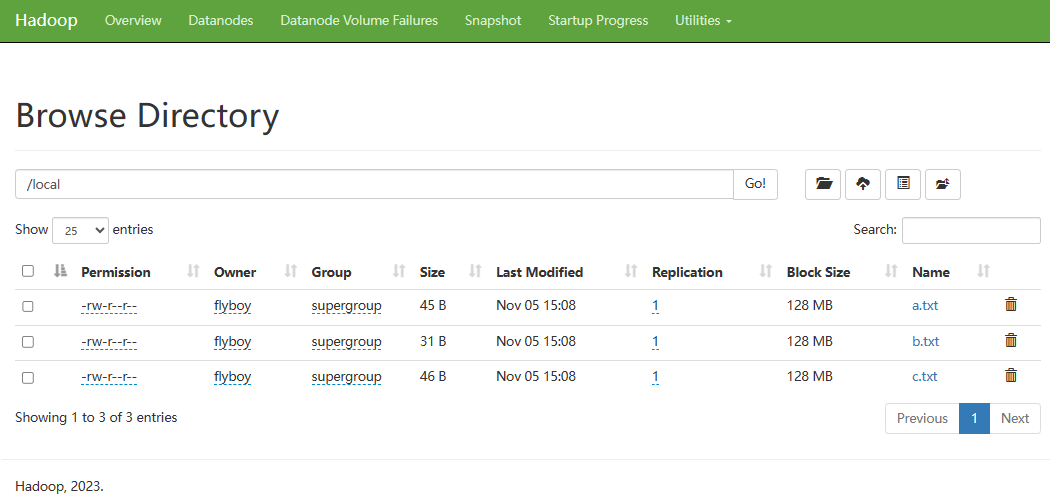
使用如下命令将数据集上传至 local 目录下:
hdfs dfs -put /home/flyboy/input/*.txt /local/
上传完毕,在上图页面上点击Name下的local链接,打开如下页面,发现数据集在列表中,点击a.txt链接,会弹出a.txt的详细信息。
使用如下命令将当前目录切换到根目录:
cd /
hadoop jar /home/flyboy/HadoopJob-1.0-SNAPSHOT.jar org/team/App /local/*.txt /output 1
其中,/home/flyboy/HadoopJob-1.0-SNAPSHOT.jar 是 jar 包所在目录,org.team/App 是因为 main 程序是放在org.team 包下的App.java下,/local/*.txt 是 dfs 文件系统下的输入文件,/output 是设定的输出目录。1 表示执行倒排索引。执行完毕,在浏览器中可以看到多了一个output的文件夹,其内容和IDEA测试一致。
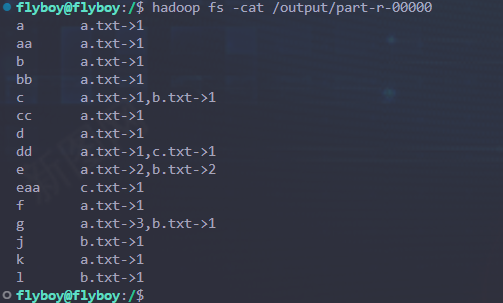
# 查看测试结果
hadoop fs -cat /output/part-r-00000
遇到的错误
在服务器上运行 jar 包报错:
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your <HADOOP_HOME>/etc/hadoop/mapred-site.xml contains the below configuration:
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
根据错误日志,修改 mapred-site-xml 文件,在其中插入以下代码:(随后停止服务删除tmp重新格式化)
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
相关文章:
Hadoop环境搭建及Demo
参考博客 Windows 10安装Hadoop 3.3.0教程 (kontext.tech) Hadoop入门篇——伪分布模式安装 & WordCount词频统计 | Liu Baoshuai’s Blog Hadoop安装教程 Linux版_linux和hadoop的安装_lnlnldczxy的博客-CSDN博客 hadoop启动出错 The value of property bind.address …...
更新一下数据集
UCI Machine Learning Repository UCI的数据集还是挺老牌的,最近换了地址,我就再记录一下。 左边是比较常见的数据集,比如Iris很经典,Heart Disease这也是,包括Wine,通常对于初学者学习比较好,…...

web3之跨链预言机SupraOracles:什么是Supra
文章目录 web3之跨链预言机SupraOracles什么是Supra什么是DORA(分布式Oracle协议)使用场景web3之跨链预言机SupraOracles 什么是Supra 官网:https://supraoracles.com/ 预言机的核心价值就在于数据传输,数据传输的速度、准确性、安全性更是重中之重。Supra Oracles 就是这…...

关系型数据库 期末复习(未完
关系型数据库 绪论概念间的关系数据库的历史信息和数据数据模型 关系模型数据结构关系完整性关系操作语言 关系代数语言 绪论 概念间的关系 数据->数据库->数据库管理系统->数据库系统 数据库的历史 人工管理阶段 -> 文件系统阶段 -> 数据库系统阶段 数据库…...

【学习笔记】CF1895G Two Characters, Two Colors
感谢grass8sheep提供的思路。 首先,我们可以用 D P DP DP解决这个问题。 设 f i , j f_{i,j} fi,j表示前 i i i个数中有 j j j个为 1 1 1的位置为红色的最大价值。则转移如下: f i , j ← f i − 1 , j b i f_{i,j}\gets f_{i-1,j}b_i fi,j←fi−…...
GZ035 5G组网与运维赛题第10套
2023年全国职业院校技能大赛 GZ035 5G组网与运维赛项(高职组) 赛题第10套 一、竞赛须知 1.竞赛内容分布 竞赛模块1--5G公共网络规划部署与开通(35分) 子任务1:5G公共网络部署与调试(15分) 子…...

基于SSM的教学管理系统(有报告)。Javaee项目。
演示视频: 基于SSM的教学管理系统(有报告)。Javaee项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构,通过Spring SpringMvc My…...
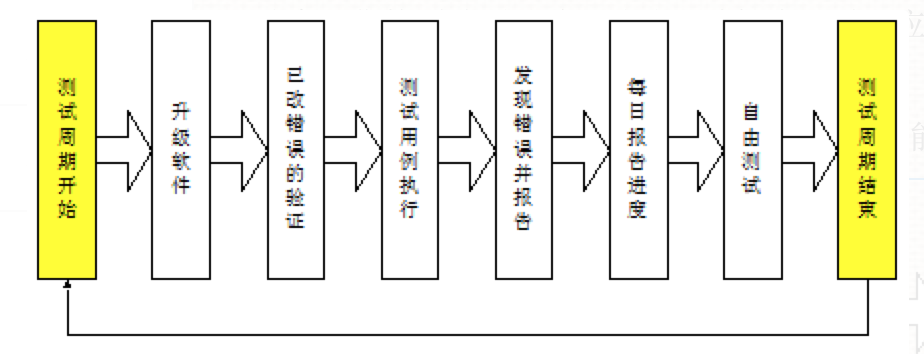
软件测试工作流程
流程体系介绍 在以往的项目工作中,我参与过,需求评审、测试计划制定、测试用例编写、测试用例执行、测试脚本编写、测试脚本的执行,进行回归测试、验收测试、编写阶段性测试报告等工作 需求分析,需求评审(RPD、产品原…...
高级文本编辑软件 UltraEdit mac中文版介绍说明
UltraEdit mac是一款在Windows系统中非常出名的文本编辑器, UltraEdit for mac对于IT程序猿来说,更是必不可少,可以使用UltraEdit编辑配置文件、查看16进制文件、代码高亮显示等,虽然Mac上已经有了很多优秀的文本编辑器࿰…...

python模块的介绍和导入
python模块的介绍和导入 概念 在Python中,每个Python代码文件都是一个模块。写程序时,我们可以将代码分散在不同的模块(文件)中,然后在一个模块中引用另一个模块的内容。 导入格式 1、在一个模块中引用(导入)另一个模块可以使用import语句…...
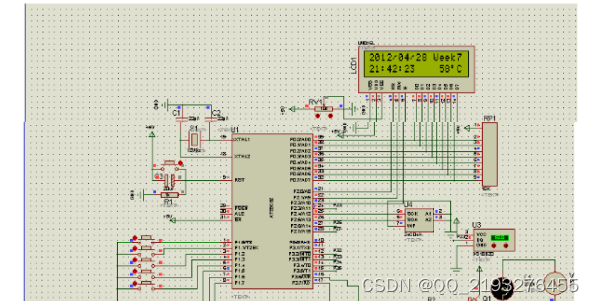
基于单片机的智能饮水机系统
收藏和点赞,您的关注是我创作的动力 文章目录 概要 一、系统设计方案分析2.1 设计功能及性能分析2.2设计方案分析 二、系统的硬件设计3.1 系统设计框图系统软件设计4.1 总体介绍原理图 四、 结论 概要 现在很多学校以及家庭使用的饮水机的功能都是比较单一的&#…...
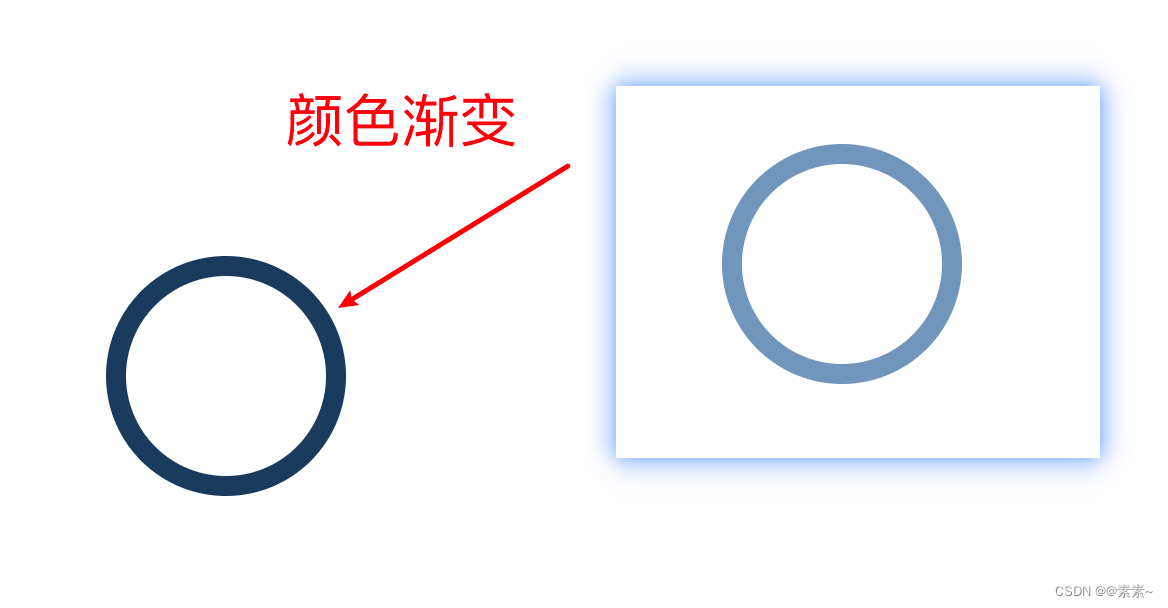
CSS画圆以及CSS实现动态圆
CSS画圆以及CSS实现动态圆 1. 先看基础(静态圆)1.1 效果如下:1.2 代码如下: 2. 动态圆2.1 一个动态圆2.1.1 让圆渐变2.1.2 圆渐变8秒后消失2.1.3 转动的圆(单个圆) 2.2 多个动态圆 1. 先看基础(…...
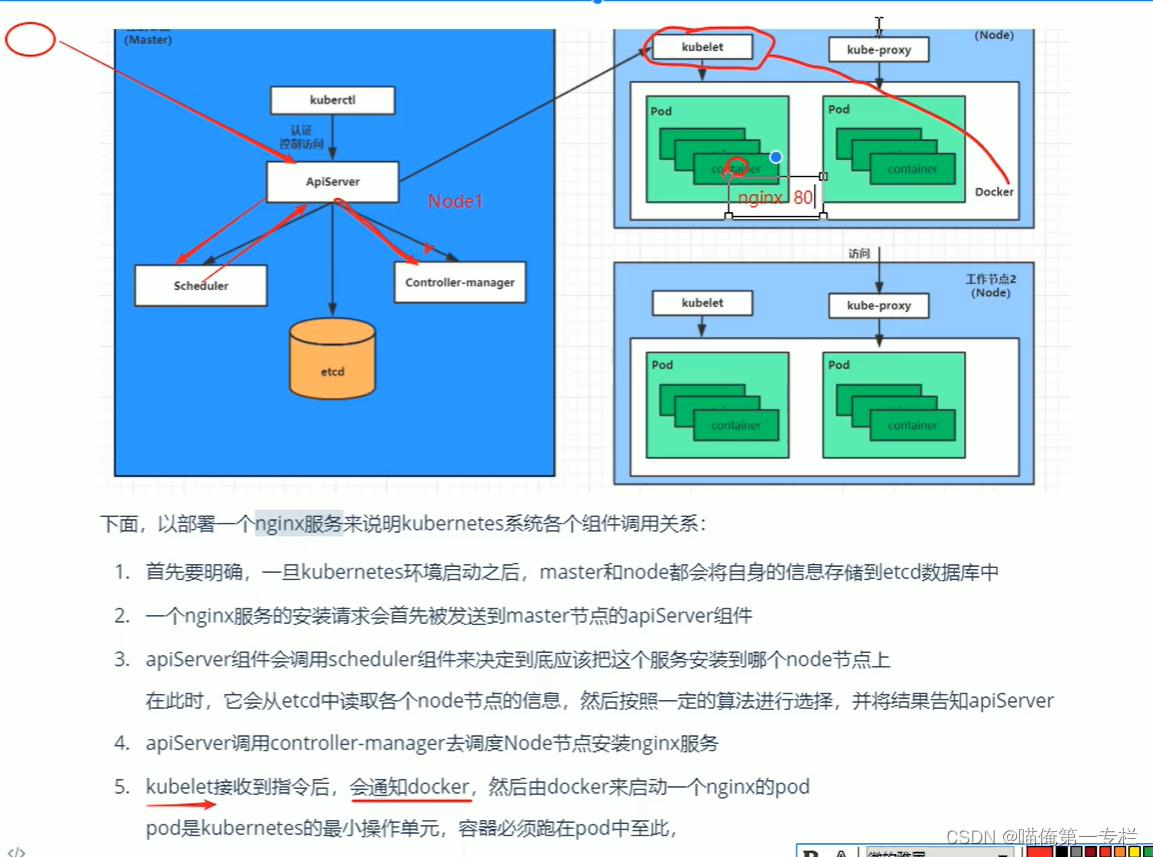
K8S知识点(一)
(1)应用部署方式转变 (2)K8S介绍 容器部署容易出现编排问题,为了解决就出现了大量的编排软件,这里将的是K8S编排问题的解决佼佼者 弹性伸缩:当流量从1000变为1200可以,自动开启一个…...
人工智能师求职面试笔试题及答案汇总
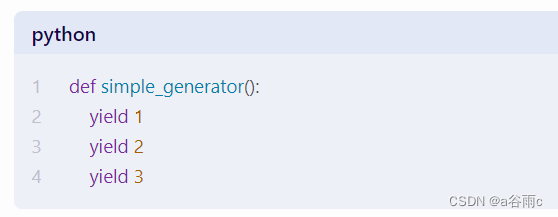
人工智能师求职面试笔试题及答案汇总 1.如何在Python中实现一个生成器? 答:在Python中,生成器是一种特殊类型的迭代器。生成器允许你在需要时才生成值,从而节省内存。生成器函数在Python中是通过关键字yield来实现的。例如&…...

【Windows-软件-FFmpeg】(01)通过CMD运行FFmpeg进行操作,快速上手
前言 通过"cmd"运行"ffmpeg"进行操作,快速上手; 实操 【实操一】 说明 使用"ffmpeg"来合并音频文件和视频文件 ; 环境 Windows 11 专业版(22621.2428); 代码 …...

Spring Data Redis + RabbitMQ - 基于 string 实现缓存、计数功能(同步数据)
目录 一、Spring Data Redis 1.1、缓存功能 1.1.1、分析 1.1.2、案例实现 1.1.3、效果演示 1.2、计数功能(Redis RabbitMQ) 1.2.1、分析 1.2.2、案例实现 一、Spring Data Redis 1.1、缓存功能 1.1.1、分析 使用 redis 作为缓存, M…...

Facebook Developer 的 HashCode
在 Android 中,您可以使用 Facebook SDK 提供的工具来生成您的应用程序的哈希码(hash code),以便在 Facebook 开发者帐户中配置您的应用程序。 要生成哈希码,您可以使用以下步骤: 打开终端或命令提示符&am…...

下载使用 ant design Pro 中遇到的一些问题
文章目录 npm 版本问题在idea终端输入命令报错:error:0308010C:digital envelope routines::unsupported npm 版本问题 npm v9.6.3 is known not to run on Node.js v19.9.0. This version of npm supports the following node versions: ^14.17.0 || ^16.13.0 || …...
「Java开发指南」如何用MyEclipse搭建Spring MVC应用程序?(一)
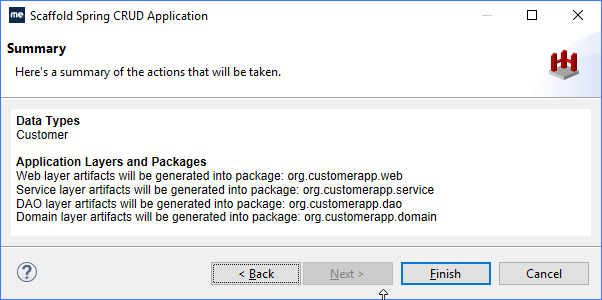
本教程将指导开发者如何生成一个可运行的Spring MVC客户应用程序,该应用程序实现域模型的CRUD应用程序模式。在本教程中,您将学习如何: 从数据库表的Scaffold到现有项目部署搭建的应用程序 使用Spring MVC搭建需要MyEclipse Spring或Bling授…...
[动态规划] (七) 路径问题:LCR 166.剑指offer 47. 珠宝的最高价值
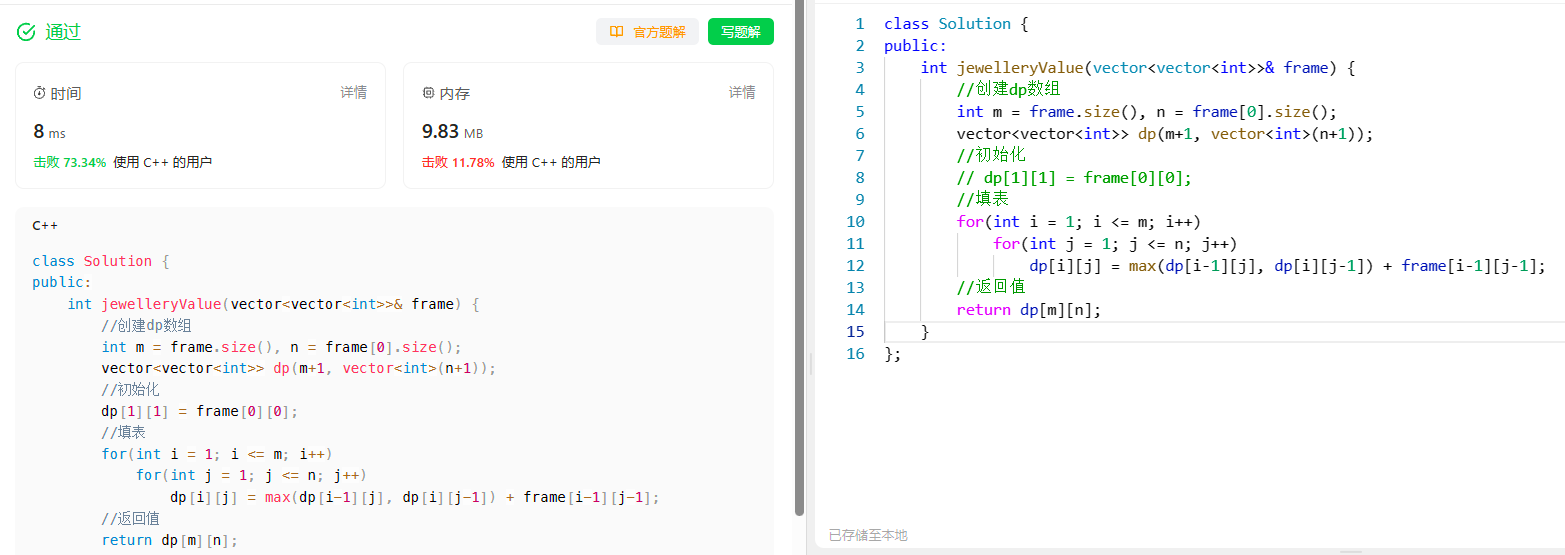
[动态规划] (七) 路径问题:LCR 166./剑指offer 47. 珠宝的最高价值 文章目录 [动态规划] (七) 路径问题:LCR 166./剑指offer 47. 珠宝的最高价值题目解析解题思路状态表示状态转移方程初始化和填表顺序 返回值代码实现总结 LCR 166. 珠宝的最高价值 题目…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...