【3D图像分割】基于 Pytorch 的 VNet 3D 图像分割3(3D UNet 模型篇)
在本文中,主要是对3D UNet 进行一个学习和梳理。对于3D UNet 网上的资料和GitHub直接获取的代码很多,不需要自己从0开始。那么本文的目的是啥呢?
本文就是想拆解下其中的结构,看看对于一个3D的UNet,和2D的UNet,究竟有什么不同?如果是你自己构建,有什么样的经验和技巧可以学习。
3D的UNet的论文地址:3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation
对于2D的UNet感兴趣的小伙伴,可以先跳转去这里:【BraTS】Brain Tumor Segmentation 脑部肿瘤分割2(UNet的复现);相信阅读完,你会对这个模型,心中已经有了结构。
对本系列的其他篇章,点击下面👇链接:
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割1(综述篇)
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割2(基础数据流篇)
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割6(数据预处理)
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割7(数据预处理)
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割8(CT肺实质分割)
- 【3D 图像分割】基于 Pytorch 的 VNet 3D 图像分割9(patch 的 crop 和 merge 操作)
一、 3D UNet 结构剖析
unet无论是2D,还是3D,从整体结构上进行划分,大体可以分位以下两个阶段:
- 下采样的阶段,也就是U的左边(
encoder),负责对特征提取; - 上采样的阶段,也就是U的右边(
decoder),负责对预测恢复。
如下图展示的这样:

其中:
- 蓝色框表示的是特征图;
- 绿色长箭头,是
concat操作; - 橘色三角,是
conv+bn+relu的组合; - 红色的向下箭头,是
max pool; - 黄色的向上箭头,是
up conv; - 最后的紫色三角,是
conv,恢复了最终的输出特征图;
对于模型构建这块,可以在论文中,看看作者是如何描述网络结构的:
Like the standard u-net, it has an analysis and a synthesis path each with four resolution steps.In the analysis path, each layer contains two 3 × 3 × 3 convolutions each followed by a rectified linear unit (ReLu), and then a 2 × 2 × 2 max pooling with strides of two in each dimension.In the synthesis path, each layer consists of an upconvolution of 2 × 2 × 2 by strides of two in each dimension, followed by two 3 × 3 × 3 convolutions each followed by a ReLu.Shortcut connections from layers of equal resolution in the analysis path provide the essential high-resolution features to the synthesis path.In the last layer a 1×1×1 convolution reduces the number of output channels to the number of labels which is 3 in our case.
从论文中的网络结构示意图也可以发现:
- 水平看,每一个小块,基本都是三个特征图,最后一层除外;
- 水平看,每个特征图之间,都是橘色三角,是
conv+bn+relu的组合,最后一层除外; encoder阶段,连接各个水平块的,是下采样;decoder阶段,连接各个水平块的,是反卷积(upconvolution);- 还有就是绿色长箭头的
concat,和最后的conv输出特征图。
二、 3D UNet 复现
复线在3D UNet前,可以先参照下相对简单,且很深渊源的2D UNet结构。其中被多次使用的一个水平块中,也是两个conv+bn+relu的组合,2D UNet的构建如下所示:
class ConvBlock2d(nn.Module):def __init__(self, in_ch, out_ch):super(ConvBlock2d, self).__init__()# 第1个3*3的卷积层self.conv1 = nn.Sequential(nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(out_ch),nn.ReLU(inplace=True),)# 第2个3*3的卷积层self.conv2 = nn.Sequential(nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(out_ch),nn.ReLU(inplace=True),)# 定义数据前向流动形式def forward(self, x):x = self.conv1(x)x = self.conv2(x)return x
而在3D UNet的一个水平块中,同样是两个conv+bn+relu的组合,如下所示:
is_elu = False
def activateELU(is_elu, nchan):if is_elu:return nn.ELU(inplace=True)else:return nn.PReLU(nchan)def ConvBnActivate(in_channels, middle_channels, out_channels):# This is a block with 2 convolutions# The first convolution goes from in_channels to middle_channels feature maps# The second convolution goes from middle_channels to out_channels feature mapsconv = nn.Sequential(nn.Conv3d(in_channels, middle_channels, stride=1, kernel_size=3, padding=1),nn.BatchNorm3d(middle_channels),activateELU(is_elu, middle_channels),nn.Conv3d(middle_channels, out_channels, stride=1, kernel_size=3, padding=1),nn.BatchNorm3d(out_channels),activateELU(is_elu, out_channels),)return conv
2.1、模块搭建
可以发现,nn.Conv2d变成了nn.Conv3d,nn.BatchNorm2d变成了nn.BatchNorm3d。遵照这个规则,构建下采样MaxPool3d、上采样反卷积ConvTranspose3d,以及最后紫色一层卷积,输出特征层FinalConvolution,如下:
def DownSample():# It halves the spatial dimensions on every axes (x,y,z)return nn.MaxPool3d(kernel_size=2, stride=2)def UpSample(in_channels, out_channels):# It doubles the spatial dimensions on every axes (x,y,z)return nn.ConvTranspose3d(in_channels, out_channels, kernel_size=2, stride=2)def FinalConvolution(in_channels, out_channels):return nn.Conv3d(in_channels, out_channels, kernel_size=1)
除此之外,绿色长箭头,concat操作,是在水平方向上,也就是列上进行组合,如下所示:
def CatBlock(x1, x2):return torch.cat((x1, x2), 1)
至此,构建模型所需要的各个组块,都准备完毕了。接下来就是构建模型,将各个组块搭起来。其中有个规律:
- 除
encoder中第一conv+bn+relu外,每一次前都需要下采样; decoder中,每一个conv+bn+relu前,都需要上采样;- 并且,
decoder中第一个conv操作,需要进行concat操作; DownSample的channel不变,特征图尺寸变小;UpSample的channel不变,特征图尺寸变大;
那就把这些规则,根据图示给加上,组合后的一个类,就如下所示:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass UNet3D(nn.Module):def __init__(self, num_out_classes=2, input_channels=1, init_feat_channels=32):super().__init__()# Encoder layers definitionsself.down_sample = DownSample()self.init_conv = ConvBnActivate(input_channels, init_feat_channels, init_feat_channels*2)self.down_conv1 = ConvBnActivate(init_feat_channels*2, init_feat_channels*2, init_feat_channels*4)self.down_conv2 = ConvBnActivate(init_feat_channels*4, init_feat_channels*4, init_feat_channels*8)self.down_conv3 = ConvBnActivate(init_feat_channels*8, init_feat_channels*8, init_feat_channels*16)# Decoder layers definitionsself.up_sample1 = UpSample(init_feat_channels*16, init_feat_channels*16)self.up_conv1 = ConvBnActivate(init_feat_channels*(16+8), init_feat_channels*8, init_feat_channels*8)self.up_sample2 = UpSample(init_feat_channels*8, init_feat_channels*8)self.up_conv2 = ConvBnActivate(init_feat_channels*(8+4), init_feat_channels*4, init_feat_channels*4)self.up_sample3 = UpSample(init_feat_channels*4, init_feat_channels*4)self.up_conv3 = ConvBnActivate(init_feat_channels*(4+2), init_feat_channels*2, init_feat_channels*2)self.final_conv = FinalConvolution(init_feat_channels*2, num_out_classes)# Softmaxself.softmax = F.softmaxdef forward(self, image):# Encoder Part ## B x 1 x Z x Y x Xlayer_init = self.init_conv(image)# B x 64 x Z x Y x Xmax_pool1 = self.down_sample(layer_init)# B x 64 x Z//2 x Y//2 x X//2layer_down2 = self.down_conv1(max_pool1)# B x 128 x Z//2 x Y//2 x X//2max_pool2 = self.down_sample(layer_down2)# B x 128 x Z//4 x Y//4 x X//4layer_down3 = self.down_conv2(max_pool2)# B x 256 x Z//4 x Y//4 x X//4max_pool_3 = self.down_sample(layer_down3)# B x 256 x Z//8 x Y//8 x X//8layer_down4 = self.down_conv3(max_pool_3)# B x 512 x Z//8 x Y//8 x X//8# Decoder part #layer_up1 = self.up_sample1(layer_down4)# B x 512 x Z//4 x Y//4 x X//4cat_block1 = CatBlock(layer_down3, layer_up1)# B x (256+512) x Z//4 x Y//4 x X//4layer_conv_up1 = self.up_conv1(cat_block1)# B x 256 x Z//4 x Y//4 x X//4layer_up2 = self.up_sample2(layer_conv_up1)# B x 256 x Z//2 x Y//2 x X//2cat_block2 = CatBlock(layer_down2, layer_up2)# B x (128+256) x Z//2 x Y//2 x X//2layer_conv_up2 = self.up_conv2(cat_block2)# B x 128 x Z//2 x Y//2 x X//2layer_up3 = self.up_sample3(layer_conv_up2)# B x 128 x Z x Y x Xcat_block3 = CatBlock(layer_init, layer_up3)# B x (64+128) x Z x Y x Xlayer_conv_up3 = self.up_conv3(cat_block3)# B x 64 x Z x Y x Xfinal_layer = self.final_conv(layer_conv_up3)# B x 2 x Z x Y x Xreturn self.softmax(final_layer, dim=1)
2.2、模型初测
定义好了模型还不算完,分阶段测试下构建的网络是不是和我们所预想的一样。我们给他一个输入,测试下是否与我们最初的想法是一致的,是否报错等等问题,如下这样:
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 没gpu就用cpu
print(DEVICE)# Tensors for 3D Image Processing in PyTorch
# Batch x Channel x Z x Y x X
# Batch size BY x Number of channels x (BY Z dim) x (BY Y dim) x (BY X dim)if __name__ == '__main__':from torchsummary import summarymodel = UNet3D(num_out_classes=3, input_channels=3, init_feat_channels=32)# print(model)summary(model, input_size=(3, 128, 128, 64), batch_size=-1, device='cpu')
打印的内容如下:
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv3d-1 [-1, 32, 128, 128, 64] 2,624BatchNorm3d-2 [-1, 32, 128, 128, 64] 64PReLU-3 [-1, 32, 128, 128, 64] 32Conv3d-4 [-1, 64, 128, 128, 64] 55,360BatchNorm3d-5 [-1, 64, 128, 128, 64] 128PReLU-6 [-1, 64, 128, 128, 64] 64MaxPool3d-7 [-1, 64, 64, 64, 32] 0Conv3d-8 [-1, 64, 64, 64, 32] 110,656BatchNorm3d-9 [-1, 64, 64, 64, 32] 128PReLU-10 [-1, 64, 64, 64, 32] 64Conv3d-11 [-1, 128, 64, 64, 32] 221,312BatchNorm3d-12 [-1, 128, 64, 64, 32] 256PReLU-13 [-1, 128, 64, 64, 32] 128MaxPool3d-14 [-1, 128, 32, 32, 16] 0Conv3d-15 [-1, 128, 32, 32, 16] 442,496BatchNorm3d-16 [-1, 128, 32, 32, 16] 256PReLU-17 [-1, 128, 32, 32, 16] 128Conv3d-18 [-1, 256, 32, 32, 16] 884,992BatchNorm3d-19 [-1, 256, 32, 32, 16] 512PReLU-20 [-1, 256, 32, 32, 16] 256MaxPool3d-21 [-1, 256, 16, 16, 8] 0Conv3d-22 [-1, 256, 16, 16, 8] 1,769,728BatchNorm3d-23 [-1, 256, 16, 16, 8] 512PReLU-24 [-1, 256, 16, 16, 8] 256Conv3d-25 [-1, 512, 16, 16, 8] 3,539,456BatchNorm3d-26 [-1, 512, 16, 16, 8] 1,024PReLU-27 [-1, 512, 16, 16, 8] 512ConvTranspose3d-28 [-1, 512, 32, 32, 16] 2,097,664Conv3d-29 [-1, 256, 32, 32, 16] 5,308,672BatchNorm3d-30 [-1, 256, 32, 32, 16] 512PReLU-31 [-1, 256, 32, 32, 16] 256Conv3d-32 [-1, 256, 32, 32, 16] 1,769,728BatchNorm3d-33 [-1, 256, 32, 32, 16] 512PReLU-34 [-1, 256, 32, 32, 16] 256ConvTranspose3d-35 [-1, 256, 64, 64, 32] 524,544Conv3d-36 [-1, 128, 64, 64, 32] 1,327,232BatchNorm3d-37 [-1, 128, 64, 64, 32] 256PReLU-38 [-1, 128, 64, 64, 32] 128Conv3d-39 [-1, 128, 64, 64, 32] 442,496BatchNorm3d-40 [-1, 128, 64, 64, 32] 256PReLU-41 [-1, 128, 64, 64, 32] 128ConvTranspose3d-42 [-1, 128, 128, 128, 64] 131,200Conv3d-43 [-1, 64, 128, 128, 64] 331,840BatchNorm3d-44 [-1, 64, 128, 128, 64] 128PReLU-45 [-1, 64, 128, 128, 64] 64Conv3d-46 [-1, 64, 128, 128, 64] 110,656BatchNorm3d-47 [-1, 64, 128, 128, 64] 128PReLU-48 [-1, 64, 128, 128, 64] 64Conv3d-49 [-1, 3, 128, 128, 64] 195
================================================================
Total params: 19,077,859
Trainable params: 19,077,859
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 12.00
Forward/backward pass size (MB): 8544.00
Params size (MB): 72.78
Estimated Total Size (MB): 8628.78
----------------------------------------------------------------
其中,我们测试的参数量是19,077,859,论文中说的参数量:The architecture has 19069955 parameters in total. 有略微的差别。
后面再调用模型,进行一次前向传播,loss运算和反向回归。如果这里都通过了,那么后面构建训练代码,就更简单了很多。如下:
if __name__ == '__main__':input_channels = 3num_out_classes = 2init_feat_channels = 32batch_size = 4model = UNet3D(num_out_classes=num_out_classes, input_channels=input_channels, init_feat_channels=init_feat_channels)# B x C x Z x Y x X# 4 x 1 x 64 x 64 x 64input_batch_size = (batch_size, input_channels, 128, 128, 64)input_example = torch.rand(input_batch_size)unet = model.to(DEVICE)input_example = input_example.to(DEVICE)output = unet(input_example)# output = output.cpu().detach().numpy()# Expected output shape# B x N x Z x Y x X# 4 x 2 x 64 x 64 x 64expected_output_shape = (batch_size, num_out_classes, 128, 128, 64)print("Output shape = {}".format(output.shape))assert output.shape == expected_output_shape, "Unexpected output shape, check the architecture!"expected_gt_shape = (batch_size, 128, 128, 64)ground_truth = torch.ones(expected_gt_shape)ground_truth = ground_truth.long().to(DEVICE)# Defining loss fnce_layer = torch.nn.CrossEntropyLoss()# Calculating lossce_loss = ce_layer(output, ground_truth)print("CE Loss = {}".format(ce_loss))# Back propagationce_loss.backward()
输出内容如下:
Output shape = torch.Size([4, 2, 128, 128, 64])
CE Loss = 0.6823387145996094
2.3、疑问汇总
在GitHub上,一篇关于3D UNet的仓库,获得了1.6k 星星。链接地址在这里:pytorch-3dunet
在这个GitHub里面,增加了很多的注释,也带来了一些心中的疑惑。
2.3.1、什么时候使用softmax?什么时候使用sigmoid?
选择使用softmax或sigmoid作为输出层的依据取决于您的任务类型和具体情况。
-
如果您的任务是对每个像素进行多类别分类(语义分割),例如图像分割任务,那么您可以使用
softmax作为输出层。softmax将为每个像素分配一个概率分布,表示该像素属于每个类别的概率,这样可以确保每个像素的预测结果归一化,并且所有通道的概率之和为1。这种方法通常用于分割器官或病变等结构。 -
如果您的任务是对每个像素进行二元分类,例如肿瘤检测任务,那么您可以使用
sigmoid作为输出层。sigmoid将为每个像素分配一个0到1之间的值,表示该像素属于正类的概率。这种方法通常用于检测二元结构,如肿瘤。但是,二元分类任务,使用softmax也是可以的。
总之,选择哪种输出层取决于您的任务类型和具体情况。
2.3.2、训练阶段是不需要softmax/sigmoid?只在推理阶段使用呢?
if True applies the final normalization layer (sigmoid or softmax), otherwise the networks returns the output from the final convolution layer; use False for regression problems, e.g. de-noising
-
在训练阶段,输出层的特征图通常不需要经过
sigmoid或softmax函数处理,因为在计算损失函数时,通常会使用原始的特征图和标签图进行比较。 -
在推理阶段,输出层的特征图需要经过
sigmoid或softmax函数处理,以将特征图转换为像素级别的预测结果。对于分割一个类别的任务,您可以使用sigmoid函数将特征图转换为像素级别的二进制掩码,表示每个像素属于结节的概率。对于分割多个类别的任务,您可以使用softmax函数将特征图转换为像素级别的类别标签。
因此,在推理阶段,您需要将输出层的特征图通过sigmoid或softmax函数进行处理,以获得像素级别的预测结果。
在上面的GitHub有个训练的提示,如下这样:
-
Training loss shape of target
- When training with binary-based losses, i.e.: BCEWithLogitsLoss, DiceLoss, BCEDiceLoss, GeneralizedDiceLoss: The
target data has to be 4D(one target binary mask per channel). - When training with WeightedCrossEntropyLoss, CrossEntropyLoss, PixelWiseCrossEntropyLoss the
target dataset has to be 3D, see also pytorch documentation for CE loss: https://pytorch.org/docs/master/generated/torch.nn.CrossEntropyLoss.html
- When training with binary-based losses, i.e.: BCEWithLogitsLoss, DiceLoss, BCEDiceLoss, GeneralizedDiceLoss: The
-
final_sigmoid in the model config section applies only to the inference time (validation, test):
- When training with
BCEWithLogitsLoss, DiceLoss, BCEDiceLoss, GeneralizedDiceLosssetfinal_sigmoid=True; - When training with cross entropy based losses (
WeightedCrossEntropyLoss, CrossEntropyLoss, PixelWiseCrossEntropyLoss) setfinal_sigmoid=False,so that Softmax normalization is applied to the output.
- When training with
2.3.3、在训练阶段,真的不可以加入sigmoid或softmax吗?
万事没有一个太绝对了。在训练阶段使用了sigmoid或softmax也是可以的,以获得类似于推理阶段的预测结果。这种方法称为“软标签”,可以帮助模型更好地学习特征和提高分割结果的质量。(因为sigmoid或softmax类似于一个规范化层,可以降低提高收敛效率)
使用软标签时,您需要将每个像素的标签从硬标签(0或1)转换为概率分布。对于分割一个类别的任务,您可以使用sigmoid函数将标签转换为0到1之间的值,表示该像素属于结节的概率。对于分割多个类别的任务,您可以使用softmax函数将标签转换为每个类别的概率分布。
请注意,使用软标签会增加模型的训练难度和计算复杂度。因此,
- 如果您的数据集足够大且质量良好,您可以不使用软标签来训练模型,也就是训练阶段不使用
sigmoid或softmax; - 但是如果您的数据集较小或存在噪声数据,使用软标签可能会提高模型的性能和分割结果的质量。也就是训练阶段使用
sigmoid或softmax。
在论文:3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation,论文中第3.2章节介绍了如何使用软标签。

2.3.4、out_channels 的数量,要不要加背景层?
out_channels (int): number of output segmentation masks; Note that the of out_channels might correspond to either different semantic classes or to different binary segmentation mask.
It’s up to the user of the class to interpret the out_channels and use the proper loss criterion during training (i.e. CrossEntropyLoss (multi-class) or BCEWithLogitsLoss (two-class) respectively)
我的理解是,有多少个目标类,out_channels 就是多少,不需要加背景类。但是,我也看到就只有一个类别,但是做了加1操作的。这点我再了解下。如果你有什么心得,欢迎评论区交流。
三、总结
UNet网络的结构,无论是二维的,还是三维的,都是比较容易理解的,这可能也是为什么那么受欢迎的原因之一吧。如果你看过之前那篇关于2D UNet的过程,再看本篇应该就简单的很多。觉得本篇更简单一些呢。
我觉得本篇最大的价值,就是:
- 逐模块的分析了结构;
- 对后续的模型构建提供了思路;
- 构建完模型需要先预测试,两种方式可选;
- 对模型的优势和劣势,分析。
如果你阅读的过程中,发现了问题和疑问,欢迎评论区交流。
相关文章:
【3D图像分割】基于 Pytorch 的 VNet 3D 图像分割3(3D UNet 模型篇)
在本文中,主要是对3D UNet 进行一个学习和梳理。对于3D UNet 网上的资料和GitHub直接获取的代码很多,不需要自己从0开始。那么本文的目的是啥呢? 本文就是想拆解下其中的结构,看看对于一个3D的UNet,和2D的UNet&#x…...
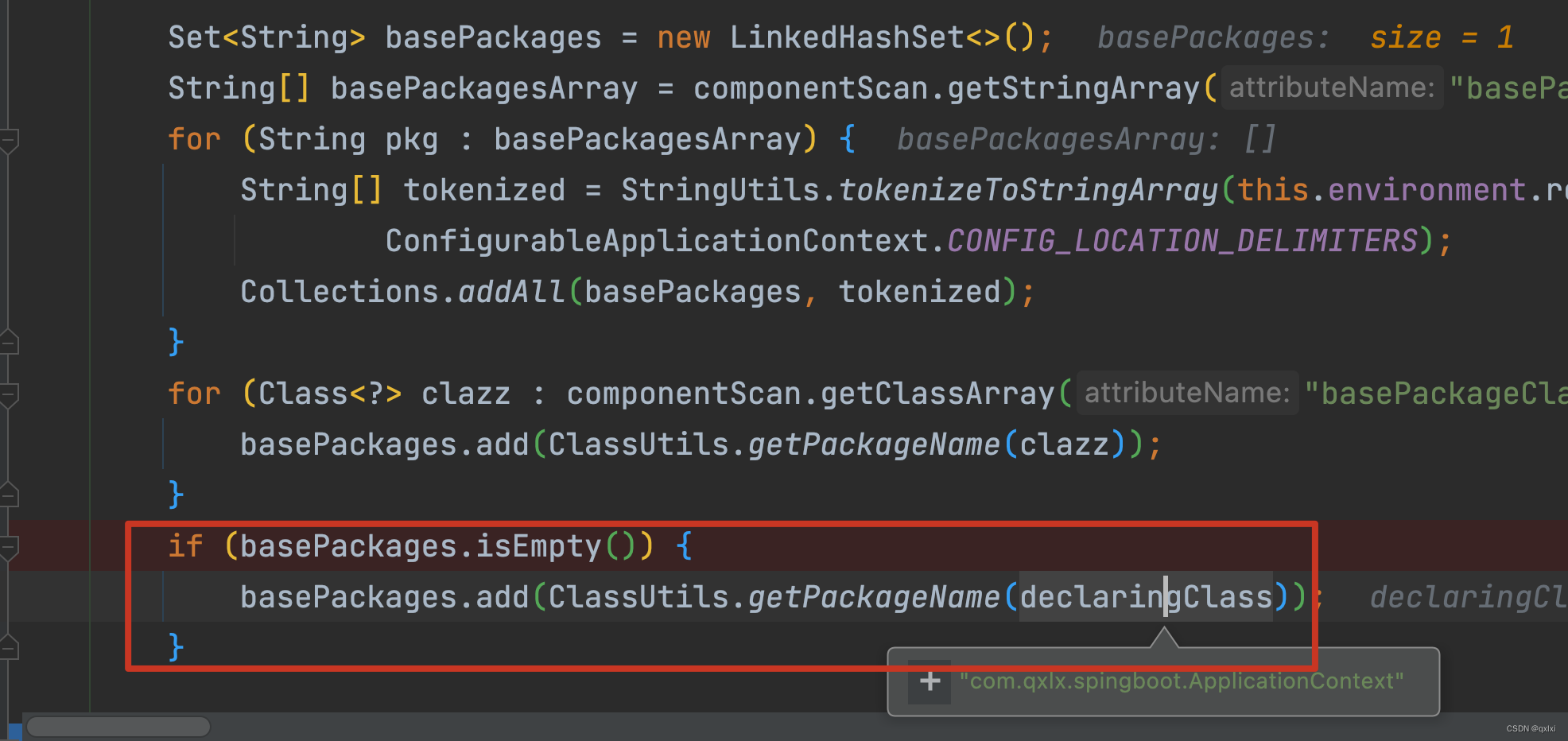
【源码解析】Spring Bean定义常见错误
案例1 隐式扫描不到Bean的定义 RestController public class HelloWorldController {RequestMapping(path "/hiii",method RequestMethod.GET)public String hi() {return "hi hellowrd";}}SpringBootApplication RestController public class Applicati…...

由于找不到vcruntime140.dll无法继续执行代码
在计算机使用过程中,我们可能会遇到一些错误提示,其中之一就是“vcruntime140.dll丢失”。这个错误通常发生在运行某些程序或游戏时,它会导致程序无法正常运行。那么,如何解决vcruntime140.dll丢失的问题呢?本文将介绍…...
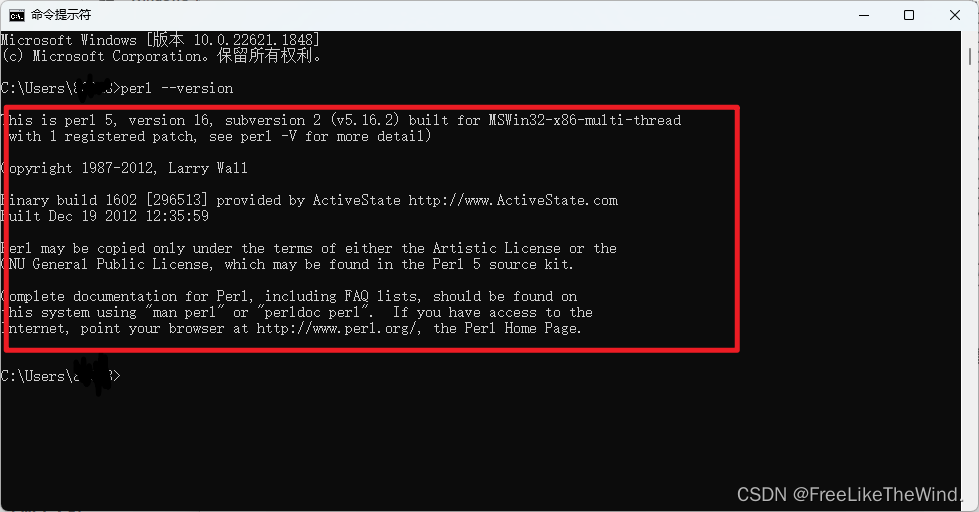
Perl安装教程
1. perl简介 Perl 是 Practical Extraction and Report Language 的缩写,可翻译为 “实用报表提取语言”。Perl 是高级、通用、直译式、动态的程序语言。Perl 最初的设计者为拉里沃尔(Larry Wall),于1987年12月18日发表。Perl 借…...

Docker数据卷使用过程中想到的几个问题
1.已经创建的容器如何挂载数据卷? 答:已经创建的容器我的理解是不能改变改变数据卷挂载的。 但有一种方法可以将数据卷挂载记录到文件里,通过修改文件而改变数据卷挂载,就是通过使用docker compose,这样每次只要修改在…...

Angular 中的路由
1 使用 routerLink 指令 路由跳转 命令创建项目: ng new ng-demo创建需要的组件: ng g component components/home ng g component components/news ng g component components/produect找到 app-routing.module.ts 配置路由: 引入组件: import { Ho…...
【市场分析】Temu数据采集销售额商品量占比分析数据分析接口Api
引言 temu电商平台是一个充满活力的电商平台,拥有多种商品类别和数万家店铺。在这个项目中我的任务是采集平台上的大量公开数据信息。通过数据采集,我旨在深入了解temu电商平台的产品分布、销售趋势和文本描述,以揭示有趣的见解。 数据采集…...
Python笔记——linux/ubuntu下安装mamba,安装bob.learn库
Python笔记——linux/ubuntu下安装mamba,安装bob.learn库 一、安装/卸载anaconda二、安装mamba1. 命令行安装(大坑,不推荐)2. 命令行下载guihub上的安装包并安装(推荐)3. 网站下载安装包并安装(…...

Redis之Java操作Redis的使用
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是君易--鑨,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的博客专栏《Redis实战开发》。🎯🎯 …...
《网络协议》01. 基本概念
title: 《网络协议》01. 基本概念 date: 2022-08-30 09:50:52 updated: 2023-11-05 15:28:52 categories: 学习记录:网络协议 excerpt: 互联网、网络互连模型(OSI,TCP/IP)、计算机通信基础、MAC 地址、ARP & ICMP、IP & 子…...

设置Ubuntu网络代理
设置Ubuntu网络代理 1 编写set_proxy.sh 在/home/xxx新建文件set_proxy.sh,添加如下代码: #!/bin/sh hostip$(cat /etc/resolv.conf | grep nameserver | awk { print $2 }) wslip$(hostname -I | awk {print $1}) port10809PROXY_HTTP"http://$…...

LeetCode----23. 合并 K 个升序链表
题目 给你一个链表数组,每个链表都已经按升序排列。 请你将所有链表合并到一个升序链表中,返回合并后的链表。 示例 1: 输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [ 1->4->5, 1->3->4, 2->6 ] 将它们合并到…...
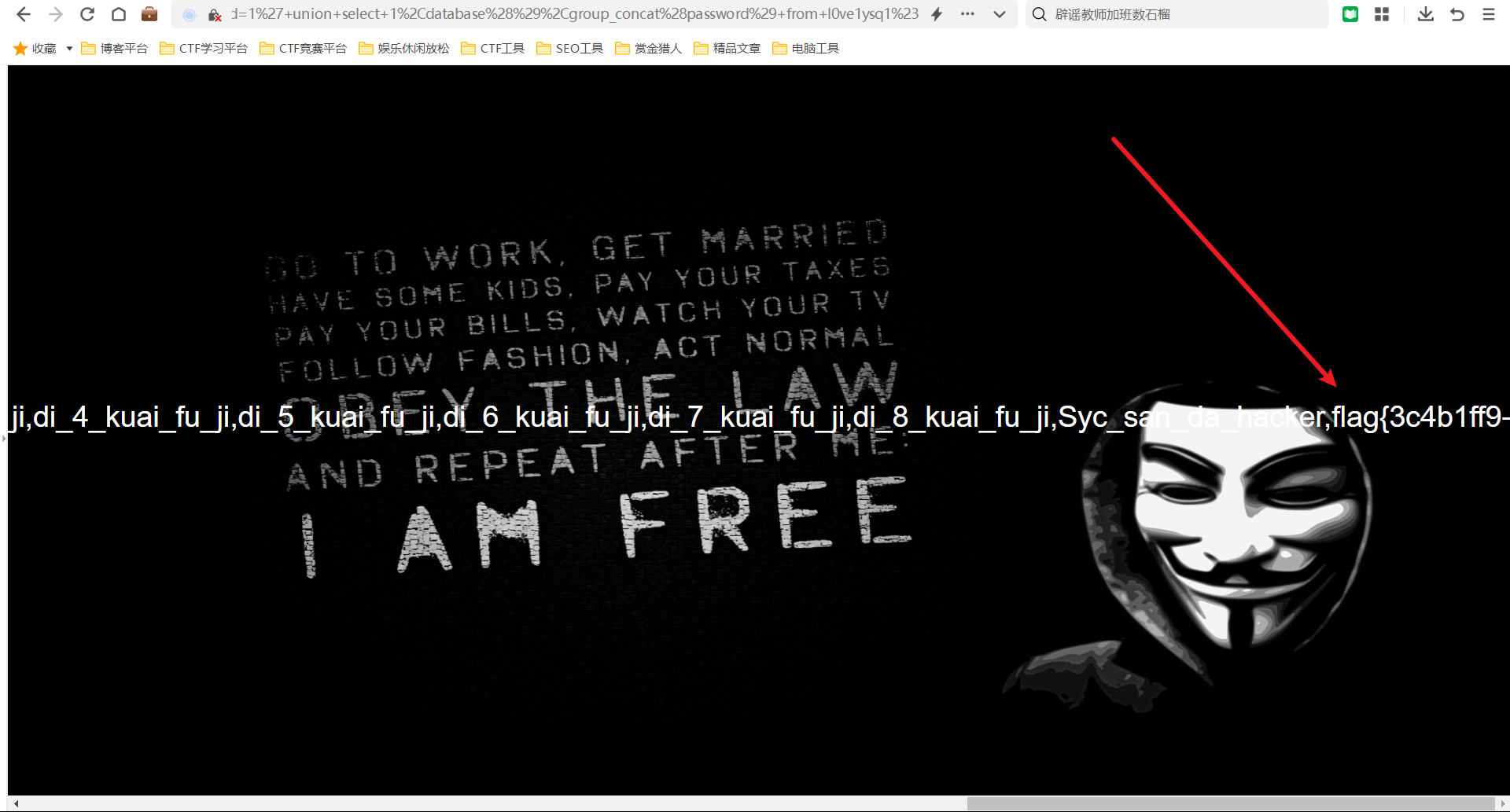
[极客大挑战 2019]LoveSQL 1
题目环境:判断注入类型是否为数字型注入 admin 1 回显结果 否 是否为字符型注入 admin 1 回显结果 是 判断注入手法类型 使用堆叠注入 采用密码参数进行注入 爆数据库1; show database();#回显结果 这里猜测注入语句某字段被过滤,或者是’;被过滤导致不能…...
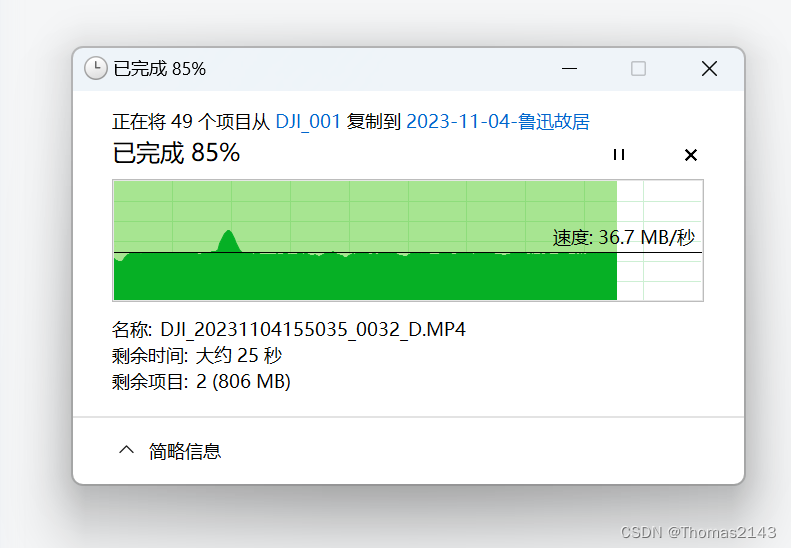
dji mini4pro 图片拷贝到电脑速度
环境 win电脑 amd3600 m.2固态硬盘 dp快充数据线 直接主机使用dp线连接无人机 9成是raw格式图片 一小部分是视频和全景图 TF卡信息: 闪迪 128GB 129元 闪迪 128GB TF(MicroSD) 存储卡U3 C10 V30 A2 4K 至尊超极速移动版 "TF卡至尊超极速" 理论读取200MB/s …...

基于深度学习的目标检测算法 计算机竞赛
文章目录 1 简介2 目标检测概念3 目标分类、定位、检测示例4 传统目标检测5 两类目标检测算法5.1 相关研究5.1.1 选择性搜索5.1.2 OverFeat 5.2 基于区域提名的方法5.2.1 R-CNN5.2.2 SPP-net5.2.3 Fast R-CNN 5.3 端到端的方法YOLOSSD 6 人体检测结果7 最后 1 简介 ǵ…...
前端面试题之CSS篇
1、css选择器及其优先级 标签选择器: 1类选择器、属性选择器、伪类选择器:10id选择器:100内联选择器(style“”):1000!important:10000 2、display的属性值及其作用 属性值作用none元素不显示,…...

【SQL相关实操记录】
一. 两张表的联合查询 task表中含 id(任务的序列号), action(任务内容), owner(任务分配的对象), target_date(目标完成日期), status(任务的完成状态),mmid(对应meeting的序列号--表示在该meeting中所对应布置的任务). meeting表中含id(meeting的序列号), status(meeting记…...
Python爬虫实战-批量爬取下载网易云音乐
大家好,我是python222小锋老师。前段时间卷了一套 Python3零基础7天入门实战https://blog.csdn.net/caoli201314/article/details/1328828131小时掌握Python操作Mysql数据库之pymysql模块技术https://blog.csdn.net/caoli201314/article/details/133199207一天掌握p…...

LeetCode 面试题 16.14. 最佳直线
文章目录 一、题目二、C# 题解 一、题目 给定一个二维平面及平面上的 N 个点列表 Points,其中第 i 个点的坐标为 Points[i][Xi,Yi]。请找出一条直线,其通过的点的数目最多。 设穿过最多点的直线所穿过的全部点编号从小到大排序的列表为 S,你仅…...

Spring Boot创建多模块项目
创建一个普通的Spring Boot项目, 然后只留下 pom.xml 剩下的都删掉 删除多余标签 标识当前为父模块 创建子模块 删除子模块中多余标签 声明父模块 在父模块中声明子模块...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...
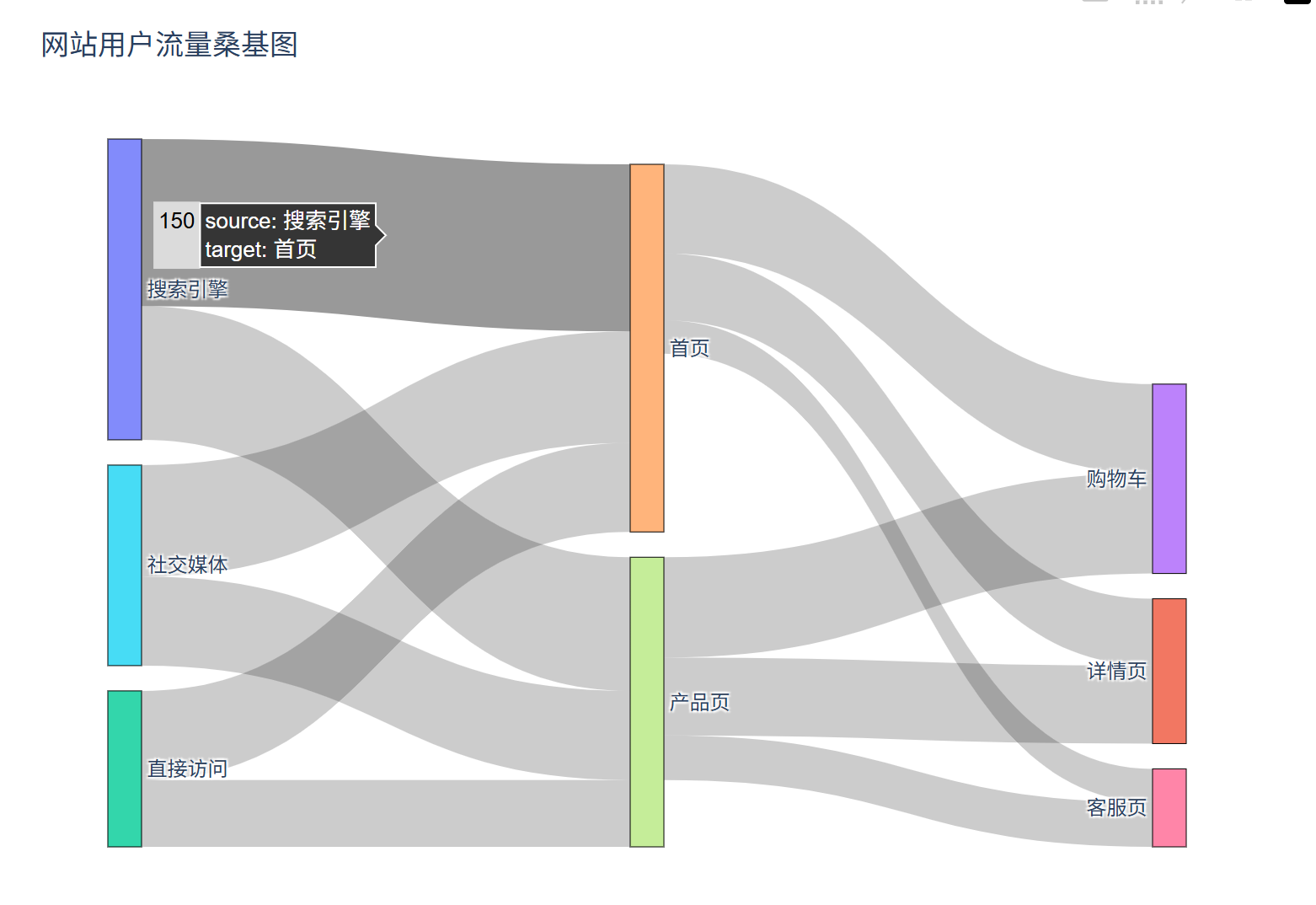
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...