redis教程 二 redis客户端Jedis使用
文章目录
- Redis的Java客户端-Jedis
- Jedis快速入门
- 创建工程:
- 引入依赖:
- 建立连接
- 测试:
- 释放资源
- Jedis连接池
- 创建Jedis的连接池
- 改造原始代码
- Redis的Java客户端-SpringDataRedis
- 快速入门
- 导入pom坐标
- 配置文件
- 测试代码
- 数据序列化器
- StringRedisTemplate
- Hash结构操作
- 项目仓库
Redis的Java客户端-Jedis
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/docs/clients/
其中Java客户端也包含很多但在开发中用的最多的还是Jedis,接下来就让我们以Jedis开始我们的快速实战。
Jedis快速入门
入门案例详细步骤
案例分析:
创建工程:
创建一个maven管理的java项目
引入依赖:
在pom.xml文件下添加以下依赖
<dependencies><!--jedis--><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>4.4.3</version></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>RELEASE</version><scope>test</scope></dependency>
</dependencies>
建立连接
新建一个单元测试类,内容如下:
private Jedis jedis;@BeforeEach
void setUp() {// 1.建立连接jedis = new Jedis("192.168.218.134", 6379);// jedis = JedisConnectionFactory.getJedis();// 2.设置密码jedis.auth("123456");// 3.选择库jedis.select(0);
}
测试:
@Test
void testString() {// 存入数据String result = jedis.set("name", "onenewcode");System.out.println("result = " + result);// 获取数据String name = jedis.get("name");System.out.println("name = " + name);
}@Test
void testHash() {// 插入hash数据jedis.hset("user:1", "name", "Jack");jedis.hset("user:1", "age", "21");// 获取Map<String, String> map = jedis.hgetAll("user:1");System.out.println(map);
}
释放资源
@AfterEach
void tearDown() {if (jedis != null) {jedis.close();}
}
Jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式
有关池化思想,并不仅仅是这里会使用,很多地方都有,比如说我们的数据库连接池,比如我们tomcat中的线程池,这些都是池化思想的体现。
创建Jedis的连接池
public class JedisConnectionFacotry {private static final JedisPool jedisPool;static {//配置连接池JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxTotal(8);poolConfig.setMaxIdle(8);poolConfig.setMinIdle(0);poolConfig.setMaxWaitMillis(1000);//创建连接池对象jedisPool = new JedisPool(poolConfig,"192.168.218.134",6379,1000,"123456");}public static Jedis getJedis(){return jedisPool.getResource();}
}
代码说明:
-
1) JedisConnectionFacotry:工厂设计模式是实际开发中非常常用的一种设计模式,我们可以使用工厂,去降低代的耦合,比如Spring中的Bean的创建,就用到了工厂设计模式
-
2)静态代码块:随着类的加载而加载,确保只能执行一次,我们在加载当前工厂类的时候,就可以执行static的操作完成对 连接池的初始化
-
3)最后提供返回连接池中连接的方法.
改造原始代码
代码说明:
1.在我们完成了使用工厂设计模式来完成代码的编写之后,我们在获得连接时,就可以通过工厂来获得。
,而不用直接去new对象,降低耦合,并且使用的还是连接池对象。
2.当我们使用了连接池后,当我们关闭连接其实并不是关闭,而是将Jedis还回连接池的。
@BeforeEachvoid setUp(){//建立连接/*jedis = new Jedis("127.0.0.1",6379);*/jedis = JedisConnectionFacotry.getJedis();//选择库jedis.select(0);}@AfterEachvoid tearDown() {if (jedis != null) {jedis.close();}}
Redis的Java客户端-SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK.JSON.字符串.Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
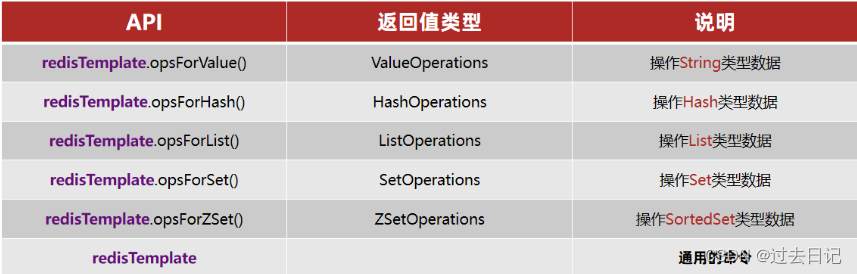
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:
快速入门
SpringBoot已经提供了对SpringDataRedis的支持,使用非常简,首先创建一个spring boot项目
导入pom坐标
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.onenewcode</groupId><artifactId>MyRedis</artifactId><version>0.0.1-SNAPSHOT</version><name>MyRedis</name><description>MyRedis</description><properties><java.version>17</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>3.0.2</spring-boot.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!--redis依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!--common-pool--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency><!--Jackson依赖--><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>17</source><target>17</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring-boot.version}</version><configuration><mainClass>com.onenewcode.myredis.MyRedisApplication</mainClass><skip>true</skip></configuration><executions><execution><id>repackage</id><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build></project>配置文件
在application.yml文件下添加以下内容
spring:data:redis:host: 192.168.218.134port: 6379password: 123456lettuce:pool:max-active: 8 #最大连接max-idle: 8 #最大空闲连接min-idle: 0 #最小空闲连接max-wait: 100ms #连接等待时间测试代码
@SpringBootTest
class MyRedisApplicationTests {@Resourceprivate RedisTemplate<String, Object> redisTemplate;@Testvoid testString() {// 写入一条String数据redisTemplate.opsForValue().set("name", "onenewcode");// 获取string数据Object name = redisTemplate.opsForValue().get("name");System.out.println("name = " + name);}
}贴心小提示:SpringDataJpa使用起来非常简单,记住如下几个步骤即可
SpringDataRedis的使用步骤:
- 引入spring-boot-starter-data-redis依赖
- 在application.yml配置Redis信息
- 注入RedisTemplate
目录结构
数据序列化器
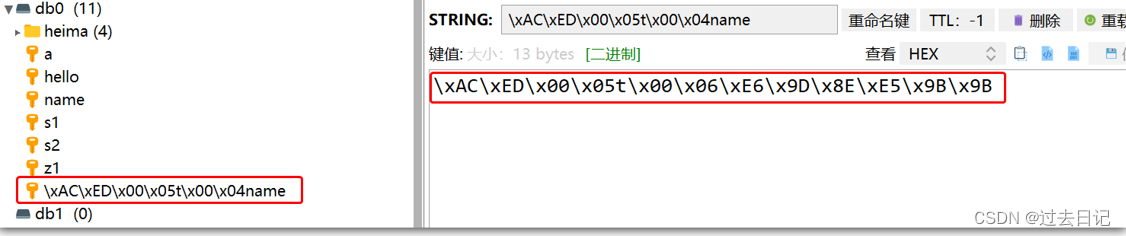
RedisTemplate可以接收任意Object作为值写入Redis,只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:
缺点:
- 可读性差
- 内存占用较大
我们可以自定义RedisTemplate的序列化方式,代码如下:
@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){// 创建RedisTemplate对象RedisTemplate<String, Object> template = new RedisTemplate<>();// 设置连接工厂template.setConnectionFactory(connectionFactory);// 创建JSON序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// 设置Key的序列化template.setKeySerializer(RedisSerializer.string());template.setHashKeySerializer(RedisSerializer.string());// 设置Value的序列化template.setValueSerializer(jsonRedisSerializer);template.setHashValueSerializer(jsonRedisSerializer);// 返回return template;}
}
这里采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图:
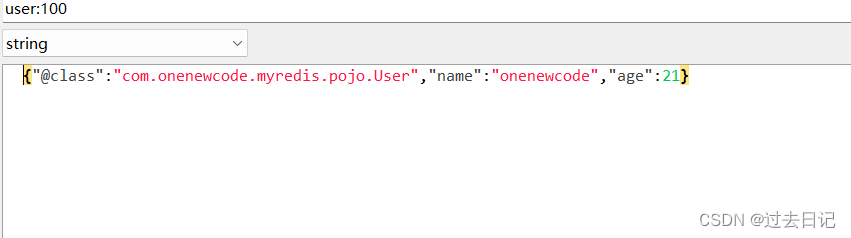
整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
StringRedisTemplate
尽管JSON的序列化方式可以满足我们的需求,但依然存在一些问题,自动进行序列化时会负载多余的信息。
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
为了减少内存的消耗,我们可以采用手动序列化的方式,换句话说,就是不借助默认的序列化器,而是我们自己来控制序列化的动作,同时,我们只采用String的序列化器,这样,在存储value时,我们就不需要在内存中就不用多存储数据,从而节约我们的内存空间
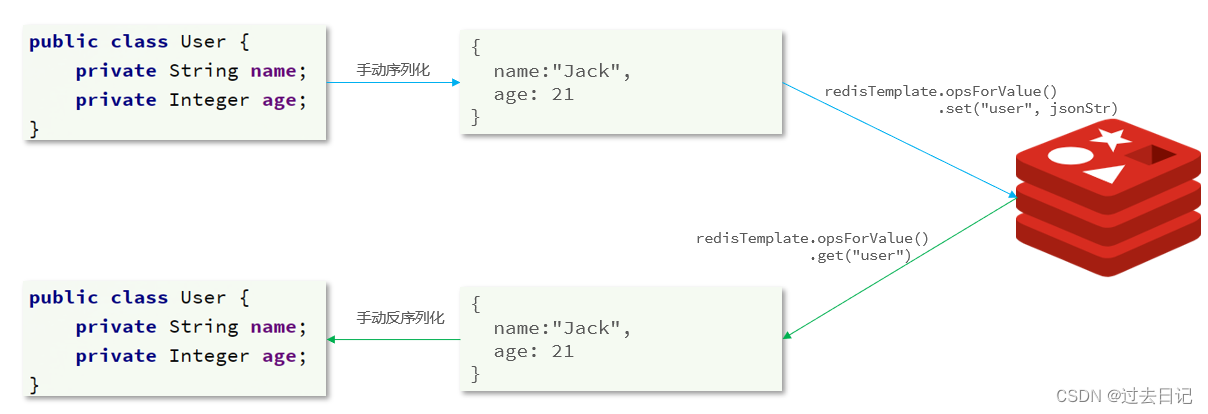
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用:
@SpringBootTest
class MyRedisApplicationTests {@Resourceprivate RedisTemplate<String, Object> redisTemplate;@Autowiredprivate StringRedisTemplate stringRedisTemplate;// JSON工具private static final ObjectMapper mapper = new ObjectMapper();@Testvoid testString() {// 写入一条String数据redisTemplate.opsForValue().set("1", "onenewcode");// 获取string数据Object name = redisTemplate.opsForValue().get("name");System.out.println("name = " + name);}@Testvoid testSaveUser() throws JsonProcessingException {// 创建对象User user = new User("onenewcode", 21);// 手动序列化String json = mapper.writeValueAsString(user);// 写入数据stringRedisTemplate.opsForValue().set("user:200", json);// 获取数据String jsonUser = stringRedisTemplate.opsForValue().get("user:200");// 手动反序列化User user1 = mapper.readValue(jsonUser, User.class);System.out.println("user1 = " + user1);}
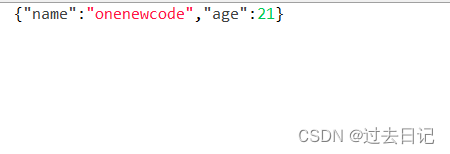
}此时我们再来看一看存储的数据,小伙伴们就会发现那个class数据已经不在了,节约了我们的空间~
最后小总结:
RedisTemplate的两种序列化实践方案:
-
方案一:
- 自定义RedisTemplate
- 修改RedisTemplate的序列化器为GenericJackson2JsonRedisSerializer
-
方案二:
- 使用StringRedisTemplate
- 写入Redis时,手动把对象序列化为JSON
- 读取Redis时,手动把读取到的JSON反序列化为对象
Hash结构操作
在基础篇的最后,咱们对Hash结构操作一下,收一个小尾巴,这个代码咱们就不再解释啦
马上就开始新的篇章~~~进入到我们的Redis实战篇
@SpringBootTest
class RedisStringTests {···@Testvoid testHash() {stringRedisTemplate.opsForHash().put("user:400", "name", "onenewcode");stringRedisTemplate.opsForHash().put("user:400", "age", "21");Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:400");System.out.println("entries = " + entries);}
}
项目仓库
https://github.com/onenewcode/MyRedis.git
相关文章:
redis教程 二 redis客户端Jedis使用
文章目录 Redis的Java客户端-JedisJedis快速入门创建工程:引入依赖:建立连接测试:释放资源Jedis连接池创建Jedis的连接池改造原始代码 Redis的Java客户端-SpringDataRedis快速入门导入pom坐标配置文件测试代码 数据序列化器StringRedisTempla…...
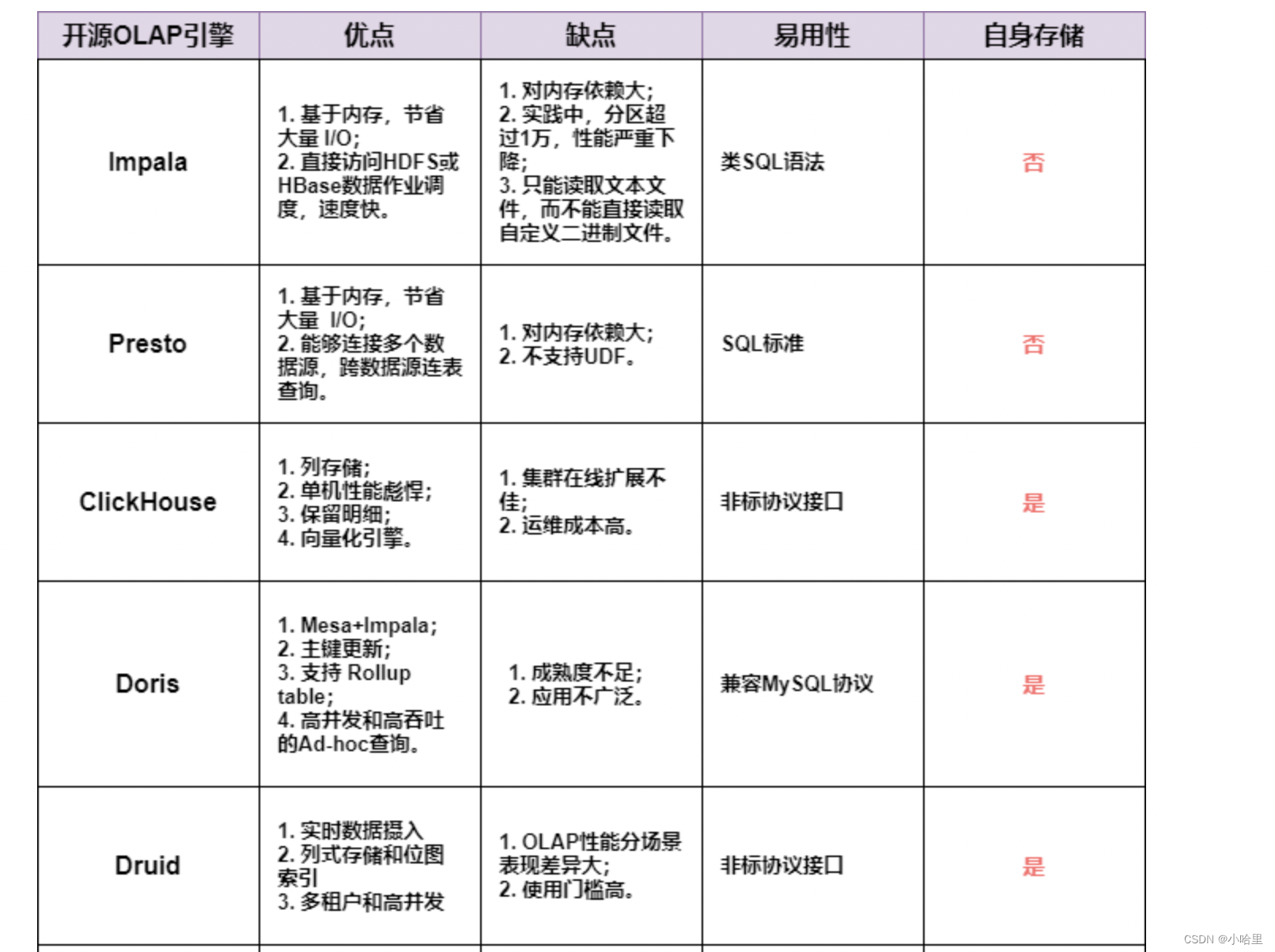
【数据开发】大数据平台架构,Hive / THive介绍
1、大数据引擎 大数据引擎是用于处理大规模数据的软件系统, 常用的大数据引擎包括Hadoop、Spark、Hive、Pig、Flink、Storm等。 其中,Hive是一种基于Hadoop的数据仓库工具,可以将结构化的数据映射到Hadoop的分布式文件系统上,并提…...
)
SOEM源码解析——ecx_init_context(初始化句柄)
0 工具准备 1.SOEM-master-1.4.0源码1 ecx_init_context函数总览 /*** @brief 初始化句柄* @param context 句柄*/ void ecx_init_context(ecx_contextt *context) {int lp;*(context->slavecount) = 0;/* clean ec_slave array */...

11.Z-Stack协议栈使用
f8wConfig.cfg文件 选择信道、设置PAN ID 选择信道 #define DEFAULT_CHANLIST 0x00000800 DEFAULT_CHANLIST 表明Zigbee模块要工作的网络,当有多个信道参数值进行或操作之后,把结果作为 DEFAULT_CHANLIST值 对于路由器、终端、协调器的意义࿱…...
设计模式—结构型模式之适配器模式
设计模式—结构型模式之适配器模式 将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,适配器模式分为类结构型模式(继承)和对象结构型模式(组合)两种,前者&a…...

【LeetCode】187. 重复的DNA序列
187. 重复的DNA序列 难度:中等 题目 DNA序列 由一系列核苷酸组成,缩写为 A, C, G 和 T.。 例如,"ACGAATTCCG" 是一个 DNA序列 。 在研究 DNA 时,识别 DNA 中的重复序列非常有用。 给定一个表示 DNA序列 的字符串 …...

C++17中std::any的使用
类sdk:any提供类型安全的容器来存储任何类型的单个值。通俗地说,std::any是一个容器,可以在其中存储任何值(或用户数据),而无需担心类型安全。void*的功能有限,仅存储指针类型,被视为不安全模式。std::any可以被视为vo…...

携手ChainGPT 人工智能基础设施 波场TRON革新 Web3 版图
近日,波场TRON与 Web3 人工智能基础设施服务商 ChainGPT 正式达成合作。通过本次合作,双方将进一步推动人工智能和区块链技术的融合,在实现优势互补的同时,真正惠及日常生活。 作为一站式的加密AI中心,ChainGPT 的人工智能工具需要进行大量计算,能耗高,而波场TRON采用的创新型…...

pdfH5实现pdf预览功能
1.引入 npm install pdfh5 2.使用 <view id"pdfBox" class""></view> showPdf(url) {this.pdfh5 new Pdfh5("", {URIenable: false,zoomEnanle: true,maxZoom: 2,pdfurl: url})this.pdfh5.on("complete", function(st…...

Redis的持久化机制
多级缓存使用到了一个装饰设计模式:相当于我不影响我之前缓存本身的代码,但是我可以对我的缓存去做增强,因此多级缓存就是采用装饰模式去实现的~! 多级缓存可以采用装饰模式去重构~! Redis当中的持久化机制ÿ…...
mac装不了python3.7.6
今天发现一个很奇怪的问题 但是我一换成 conda create -n DCA python3.8.12就是成功的 这个就很奇怪...

仿写知乎日报第三周
新学到的 本周新学习了FMDB数据库,并对Masonry的使用有了更近一步的了解,还了解了cell的自适应高度 FMDB数据库的介绍和使用:iOS——FMDB的介绍与使用 cell自适应高度和Mansonry自动布局 本周写了评论区,在写评论区的时候&…...

Godot Best practices
Get Forward Vector transform.x # 等价手算 var rad node.rotation var forward Vector2(cos(rad), sin(rad))Await and Unity Style Coroutine func coroutine(on_update: Callable, duration: float 1):var elapse_time 0while elapse_time < 1:elapse_time get_p…...

win10 + cmake3.17 编译 giflib5.2.1
所有源文件已经打包上传csdn,大家可自行下载。 1. 下载giflib5.2.1,解压。 下载地址:GIFLIB - Browse Files at SourceForge.net 2. 下载CMakeLists.txt 及其他依赖的文件 从github上的osg-3rdparty-cmake项目: https://github.…...

【rust/esp32】初识slint ui框架并在st7789 lcd上显示
文章目录 说在前面关于slint关于no-std关于dma准备工作相关依赖代码结果参考 说在前面 esp32版本:s3运行环境:no-std开发环境:wsl2LCD模块:ST7789V2 240*280 LCDSlint版本:master分支github地址:这里 关于s…...
-http工作机制、指令和内置变量)
精通Nginx(05)-http工作机制、指令和内置变量
http服务是Nginx最原始的服务,搞清楚其工作机制非常有利于弄懂nginx是如何工作的。 Nginx核心模块为ngx_http_core_module。 目录 http工作机制 配置结构 工作机制 http常用指令 http server listen server_name location 优先级 "/"的特殊用法 root/a…...
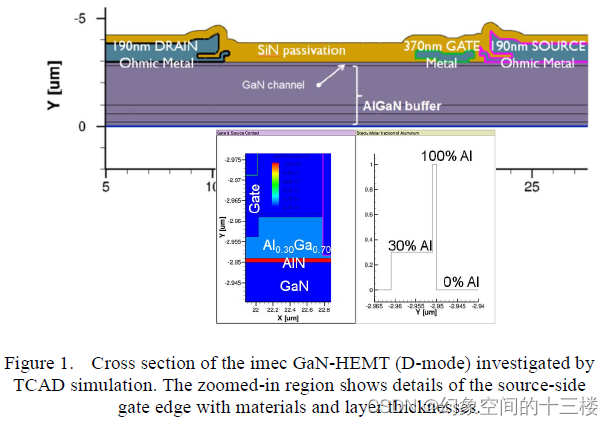
用于 GaN-HEMT 功率器件仿真的 TCAD 方法论
目录 标题:TCAD Methodology for Simulation of GaN-HEMT Power Devices来源:Proceedings of the 26th International Symposium on Power Semiconductor Devices & ICs(14年 ISPSD)GaN-HEMT仿真面临的挑战文章研究了什么文章的创新点文章的研究方法…...
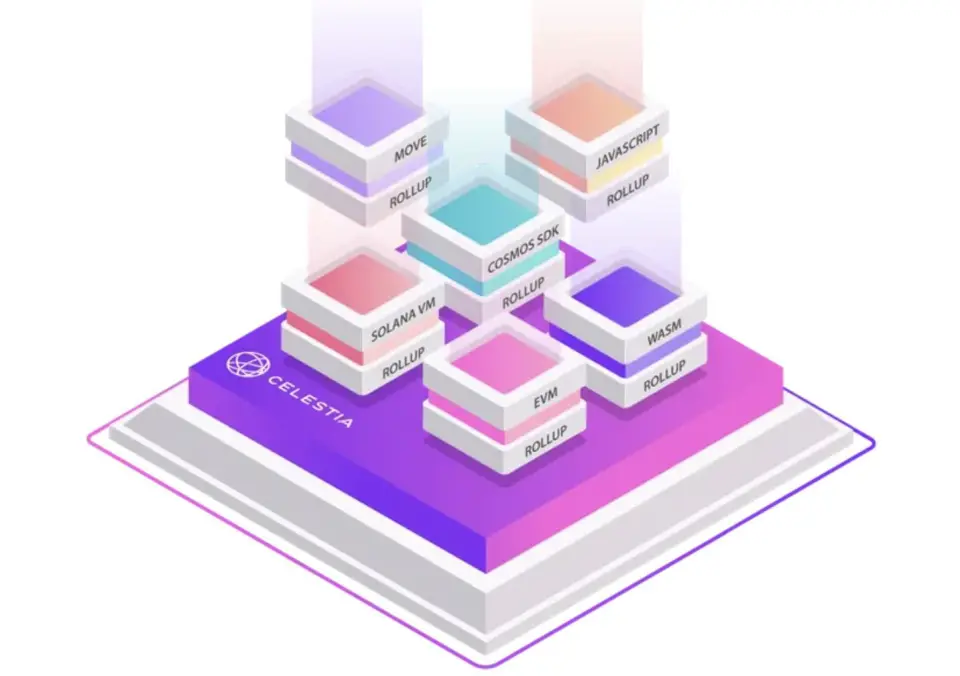
Web3公链之Cosmos生态的项目Celestia
文章目录 Web3公链之Cosmos生态的项目:模块化区块链Celestia什么是CelestiaCelestia网络架构数据可用性问题有哪些可用的解决方案? 发展历史运行节点参考 Web3公链之Cosmos生态的项目:模块化区块链Celestia 什么是Celestia 官网:…...

vue+prismjs 网页代码高亮插件
最近在使用wangEditor的过程中发现编辑器中代码块展示没有问题,但是预览编辑器中的内容样式丢失,看过wangEditor的文档后发现用到了Prism.js,现将使用的经验分享。 使用步骤 1、安装prismjs插件 // 1. 安装prismjs 插件 npm install prismj…...
【软件测试】其实远远不止需求文档这么简单
我们都知道,软件测试是一门依赖性很强的综合技术,软件测试工程师在施行自己的工作时,总是要依赖其他团队的产出。 比如,我们要依赖着需求团队给出的需求分析说明书来确定测试的方向,又要依赖开发团队产出的实际代码产品…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...