为机器学习算法准备数据(Machine Learning 研习之八)
本文还是同样建立在前两篇的基础之上的!
属性组合实验
希望前面的部分能让您了解探索数据并获得洞察力的几种方法。您发现了一些数据怪癖,您可能希望在将数据提供给机器学习算法之前对其进行清理,并且发现了属性之间有趣的相关性,特别是与目标属性
之间的相关性。您还注意到一些属性具有向右倾斜的分布,因此您可能需要转换它们(例如,通过计算它们的对数或平方根)。当然,你的里程会因每个项目而有很大的不同,但大致的想法是相似的。
在为机器学习算法准备数据之前,您可能需要做的最后一件事是尝试各种属性组合。例如,如果你不知道一个地区有多少住户,那么这个地区的房间总数就不是很有用。你真正想要的是每个家庭的房间数量。同样,卧室总数本身也不是很有用:你可能想对比一下房间的数量。每个家庭的人口似乎也是一个有趣的属性组合。创建这些新属性如下:
housing["rooms_per_house"] = housing["total_rooms"] / housing["households"]
housing["bedrooms_ratio"] = housing["total_bedrooms"] / housing["total_rooms"]
housing["people_per_house"] = housing["population"] / housing["households"]
然后你再看一遍相关矩阵:

!新的bedrooms_ratio属性与房屋中值的相关性要比与房间或卧室总数的相关性大得多。显然,卧室/房间比率较低的房子往往更贵。每个家庭的房间数量也比一个地区的房间总数更能说明问题-很明显,房
子越大,就越贵。
这一轮的探索不需要绝对彻底;关键是从正确的角度出发,并迅速获得见解,这将帮助您获得第一个相当好的原型。但是这是一个迭代的过程:一旦你建立并运行了一个原型,你就可以分析它的输出以获得更多的见解,然后再回到这个探索步骤。
为机器学习算法准备数据
是时候为您的机器学习算法准备数据了。你应该为此编写函数,而不是手工操作,这有几个很好的理由:
- 这将允许您在任何数据集上轻松重现这些转换(例如,下次获得新数据集时)。
- 您将逐步构建一个转换函数库,以便在未来的项目中重用。
- 您可以在实时系统中使用这些函数来转换新数据,然后再将其输入到您的算法中。
- 这将使您能够轻松地尝试各种转换,并查看哪种转换组合效果最好。
但首先,恢复到一个干净的训练集(通过再次复制strat_train_set)。您还应该将预测变量和标签分开,因为您不一定希望对预测变量和目标值应用相同的转换(请注意,drop()创建数据的副本,并且不影响strat_train_set):
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
清除数据
大多数机器学习算法无法处理缺失的功能,因此您需要处理这些功能。例如,您之前注意到total_bedrooms属性有一些缺失值。你有三个选项可以解决这个问题:
- 去掉相应的区。
- 去掉整个属性。
- 将缺失值设置为某个值(零、均值、中位数等)。这就是所谓的归罪。
您可以使用PandasDataFrame的dropna () 、drop () 和fillna ()方法轻松完成这些任务:
housing.dropna(subset=["total_bedrooms"], inplace=True) # option 1
housing.drop("total_bedrooms", axis=1) # option 2
median = housing["total_bedrooms"].median() # option 3
housing["total_bedrooms"].fillna(median, inplace=True)
您决定使用选项3,因为它的破坏性最小,但是您将使用一个方便的Scikit-Learn类:Simplelmputer,而不是前面的代码。这样做的好处是,它将存储每个特征的中值:这将使得它不仅可以估算训练集上的缺失值,还可以估算验证集、测试集和输入到模型的任何新数据上的缺失值。要使用它,首先需要创建一个Simplelmputer实例,指定要将每个属性的缺失值替换为该属性的中位数:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
由于中位数只能在数值属性上计算,因此您需要创建一个仅具有数值属性的数据副本(这将排除文本属性ocean_proximity):
housing_num = housing.select_dtypes(include=[np.number])
现在,您可以使用fit()方法将补缺器实例拟合到训练数据:
imputer.fit(housing_num)
估算器只是计算每个属性的中位数,并将结果存储在它的statistics_instance变量中。只有total_bedrooms属性有缺失值,但您无法确定系统上线后的新数据中不会有任何缺失值,因此更安全的做法是将补缺器应用于所有数值属性:

现在,您可以使用这个"训练过的"估算器通过用学习到的中位数替换缺失值来转换训练集:
X = imputer.transform(housing_num)
缺失的值也可以替换为平均值(strategy=“mean”),或替换为最频繁的值(strategy=“most_frequent”),或替换为常值(strategy=“constant”, fill_value=…)。后两种策略支持非数值数据。
sklear.impute软件包中还有更强大的imputer(都仅用于数值特性):
- KNNImputer将每个缺失值替换为该功能的k-近邻值的平均
值。距离是基于所有可用的功能。- Iterativelmputer为每个特征训练回归模型,以根据所有其他可用
特征预测缺失值。然后,它会根据更新的数据再次训练模型,并
多次重复该过程,在每次迭代时改进模型和替换值。
Scikit-Learn转换器输出NumPy数组(或有时SciPy稀疏矩阵),即使它们被输入熊猫数据帧。“因此,inputer.Transform(Home_Num)的输出是NumPy数组:X既没有列名,也没有索引。幸运的是,在DataFrame中包装X并从宿主num中恢复列名和索引并不难:
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing_num.index)
处理文本和分类属性
到目前为止,我们只处理了数字属性,但您的数据也可能包含文本属性。在这个数据集中,只有一个:ocean_proximity属性。让我们看看它的值的前几个实例:

它不是任意的文本:有有限数量的可能值,每个值代表一个类别。所以这个属性是一个分类属性。大多数机器学习算法更喜欢与数字打交道,所以让我们将这些类别从文本转换为数字。为此,我们可以使用Scikit-Learn的OrdinalEncoder类:
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoded中的前几个编码值是这样的:

您可以使用categories_instance变量获取类别列表。它是一个列表,包含每个分类属性的一维类别数组(在本例中,列表包含单个数组,因为只有一个分类属性):

这种表示法的一个问题是,ML算法将假设两个附近的值比两个遥远的值更相似。这在某些情况下可能是没有问题的(例如,对于已排序的类别(如“坏”、“平均”、“好”和“优秀”),但显然海洋邻近栏的情况并非如此(例如,类别0和4显然比类别0和1更相似)。要解决这个问题,一个常见的解决方案是为每个类别创建一个二进制属性:一个属性在类别为“<1H海洋”时等于1(否则为0),另一个属性在“内陆”时等于1(否则为0),依此类推。这称为单热编码,因为只有一个属性将等于1(热),而其他属性将等于0(冷)。新属性有时被称为伪属性。Scikit-Learn提供了一个OneHotEncoder类来将分类值转换为单热向量:
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
默认情况下,OneHotEncoder的输出是SciPy稀疏矩阵,而不是NumPyarray:

稀疏矩阵是大多数包含零的矩阵的一种非常有效的表示形式。实际上,它内部只存储非零值及其位置。当一个分类属性有数百或数千个类别时,单热编码会产生一个非常大的矩阵,其中除了每行只有一个1之外,其余都是0。在这种情况下,稀疏矩阵正是您所需要的:它将节省大量内存并加快计算速度。你可以使用一个稀疏矩阵,就像一个普通的2D数组,12但是如果你想把它转换成一个(密集的)NumPy数组,只需要调用toarray()方法:

或者,您可以在创建OneHotEncoder时设置sparse=False,在这种情况下,transform()方法将直接返回一个常规(密集)NumPy数组。
与OrdinalEncoder一样,您可以使用编码器的categories_instance变量获取类别列表:

Pandas有一个名为get_dummies()的函数,它也将每个分类特征转换为单热点表示,
每个类别有一个二进制特征:

它看起来很好很简单,那么为什么不使用它来代替OneHotEncoder呢?OneHotEncoder的优点是它能记住训练的类别。这一点非常重要,因为一旦您的模型投入生产,就应该提供与训练期间完全相同的功能:不多也不少。看看我们的训练好的cat_encoder在转换相同的df_test时输出(使用transform(),而不是fit_transform ()):

看到区别了吗get_dummies()只看到两个类别,所以它输出两列,而OneHotEncoder按照正确的顺序为每个学习到的类别输出一列。而且,如果您给get_dummies()提供一个包含未知类别DataFrame(例如,“《2HOPEN”),那么它将很高兴地为其生成一列:

但OneHotEncoder更聪明:它将检测未知类别并引发异常。如果你愿意,你可以将handle_unknown超参数设置为"ignore",在这种情况下,它将用零表示未知类别:

使用DataFrame拟合任何Scikit-Learn估计器时,估计器将列名存储在feature_names_in_attribute中。Scikit-Learn然后确保任何DataFrame在此之后被馈送到该估算器(例如要转换()或预测())具有相同的列名。Transformers还提供get_feature_names_out ()方法,您可以使用该方法围绕Transformers的输出构建DataFrame:

相关文章:
为机器学习算法准备数据(Machine Learning 研习之八)
本文还是同样建立在前两篇的基础之上的! 属性组合实验 希望前面的部分能让您了解探索数据并获得洞察力的几种方法。您发现了一些数据怪癖,您可能希望在将数据提供给机器学习算法之前对其进行清理,并且发现了属性之间有趣的相关性,…...

基于Python OpenCV的金铲铲自动进游戏、D牌...
基于Python OpenCV的金铲铲自动进游戏、D牌... 1. 自动点击进入游戏1.1 环境准备1.2 功能实现2. 自动D牌3. 游戏结束自动退1. 自动点击进入游戏 PS: 本测试只用于交流学习OpenCV的相关知识,不能用于商业用途,后果自负。 1.1 环境准备 需要金铲铲在win10的模拟器,我们这里选…...

c++中httplib使用
httplib文件链接:百度网盘 请输入提取码 提取码:kgnq json解析库:百度网盘 请输入提取码 提取码:oug0 一、获取token 打开postman, 在body这个参数中点击raw,输入用户名和密码 然后需要获取到域名和地址。 c++代码如下: #include "httplib.h" #in…...
Vite 的基本原理,和 webpack 在开发阶段的比较
目录 1,webpack 的流程2,Vite 的流程简单编译 3,总结 主要对比开发阶段。 1,webpack 的流程 开发阶段大致流程:指定一个入口文件,对相关的模块(js css img 等)先进行打包࿰…...
[开源]免费开源MES系统/可视化数字大屏/自动排班系统
开源系统概述: 万界星空科技免费MES、开源MES、商业开源MES、市面上最好的开源MES、MES源代码、免费MES、免费智能制造系统、免费排产系统、免费排班系统、免费质检系统、免费生产计划系统。 万界星空开源MES制造执行系统的Java开源版本。开源mes系统包括系统管理…...

python如何使用gspread读取google在线excel数据?
一、背景 公司使用google在线excel管理测试用例,为了方便把手工测试用到的测试数据用来做自动化用例测试数据,所以就想使用python读取在线excel数据,通过数据驱动方式,完成自动化回归测试,提升手动复制,粘…...
线程同步——互斥量解锁、解锁
类似与进程间通信信号量的加锁解锁。 对互斥量进行加锁后,任何其他试图在此对互斥量加锁的线程都会被阻塞,直到当前线程释放该互斥锁。如果释放互斥锁时有多个线程被阻塞,所有在该互斥锁上的阻塞线程都会变成可运行状态,第一个变…...

数据结构(c语言版) 顺序表
代码 #include <stdio.h> #include <stdlib.h>typedef int E; //这里我们的元素类型就用int为例吧,先起个别名//定义结构体 struct List{E * array;int capacity; //数组的容量int size; };//给结构体指针起别名 typedef struct List * ArrayLis…...
)
Springboot 集成 RocketMq(入门)
1.RocketMq安装部署 Linux 安装 RocketMq-CSDN博客 2.添加依赖包 <dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.2.3</version> </dependency> 3.配…...
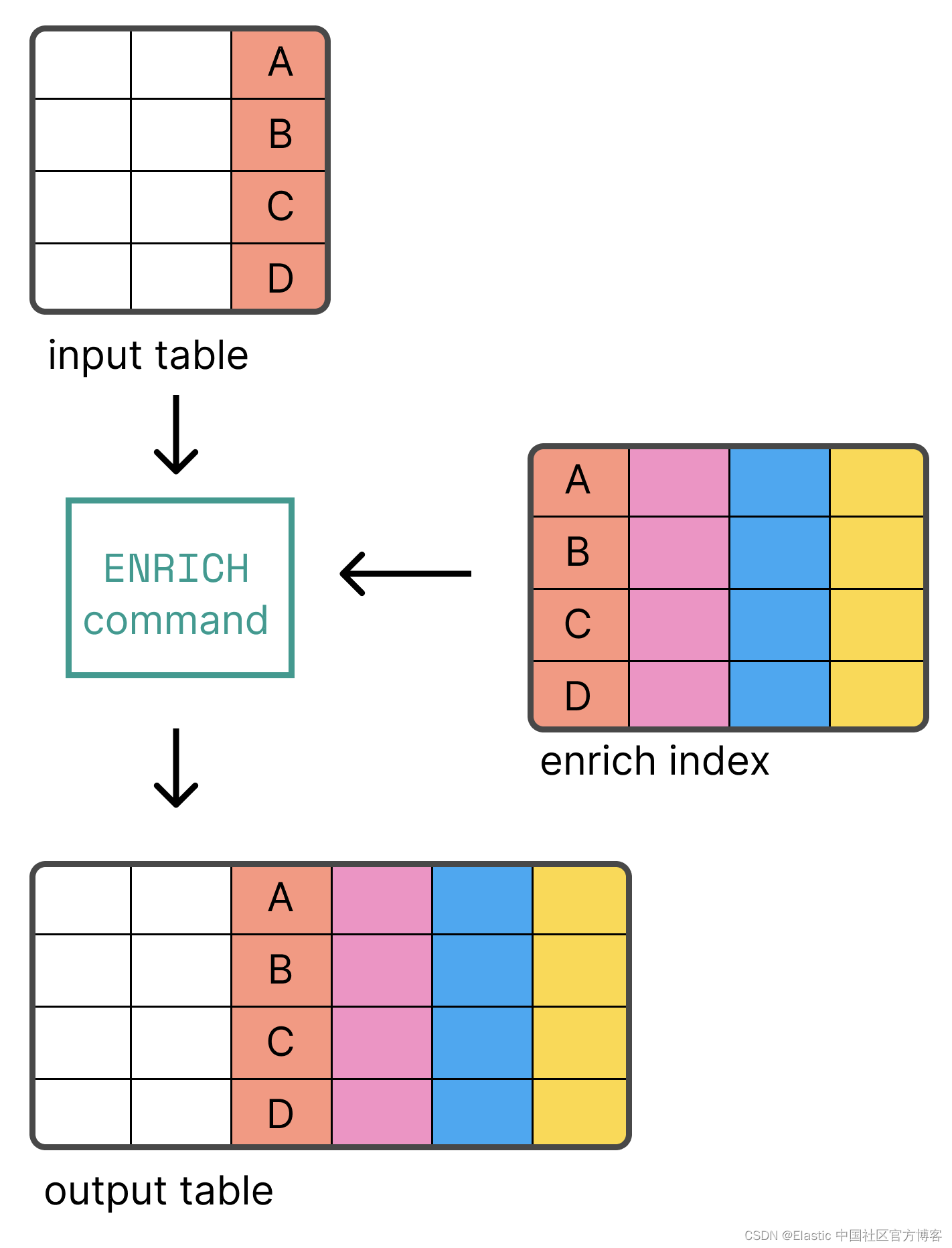
Elasticsearch:ES|QL 中的数据丰富
在之前的文章 “Elasticsearch:ES|QL 查询语言简介”,我有介绍 ES|QL 的 ENRICH 处理命令。ES|QL ENRICH 处理命令在查询时将来自一个或多个源索引的数据与 Elasticsearch 丰富索引中找到的字段值组合相结合。这个有点类似于关系数据库查询中所使用的 jo…...

【linux编程】linux文件IO高级I/O函数介绍和代码示例
Linux文件IO高级I/O函数用法是指如何使用这些函数来实现高效和灵活的文件读写操作,它们包括以下几类: 分散读和集中写:readv和writev函数可以一次性地从一个文件描述符读取或写入多个缓冲区,而不需要多次调用read或write函数。这样可以减少系统调用的开销,提高I/O效率。存…...

jQuery获取地址栏GET参数值
jQuery获取地址栏GET参数值 封装方法: window.location 是获取当前页面地址 // 获取地址栏参数 function GetUrlString(name){var reg new RegExp("(^|&)" name "([^&]*)(&|$)");var r window.location.search.substr(1).match…...

JAVA应用中线程池设置多少合适?
目录 1、机器配置: 2、核心线程数 3、最大线程数多少合适? 4、理论基础 5、测试验证 一个线程跑满一个核心的利用率 6个线程 12 个线程:所有核的cpu利用率都跑满 有io操作 6、计算公式 7、决定最大线程数的流程: 1、机器…...

.Net Core 3.1 解决数据大小限制
微软官网文档上对.NET Core3.1解决数据大小限制有详细的介绍。下面是根据自己的情况进行的总结,我们可以把.Core项目部署在IIS上,也可以利用Kestrel进行部署。这两种方式处理数据大小限制的方式不一样,具体如下: 一、部署在IIS上…...

【音视频 | opus】opus编码的Ogg封装文件详解
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...
)
【微信小程序】自定义组件(一)
自定义组件 组件的创建与引用1、创建组件2、引用组件3、全局引用VS局部引用4、组件和页面的区别 样式1、组件样式隔离2、组件样式隔离的注意点3、stylelsolation的可选值 数据、方法和属性1、data数据2、methods方法3、properties4、data和properties区别5、使用setData修改pr…...

如何通过一条数字人三维动画宣传片,打造出数字文旅
越来越多虚拟人,以文化挖掘者的身份通过数字人三维动画宣传片,打通次元壁,助力文化传播形式创造性转化、创新性表达,赋予文化发展新动能。 如南方都市报民间博物馆文化探寻者“岭梅香”,由一艘在南宋时期失事的沉船“南…...
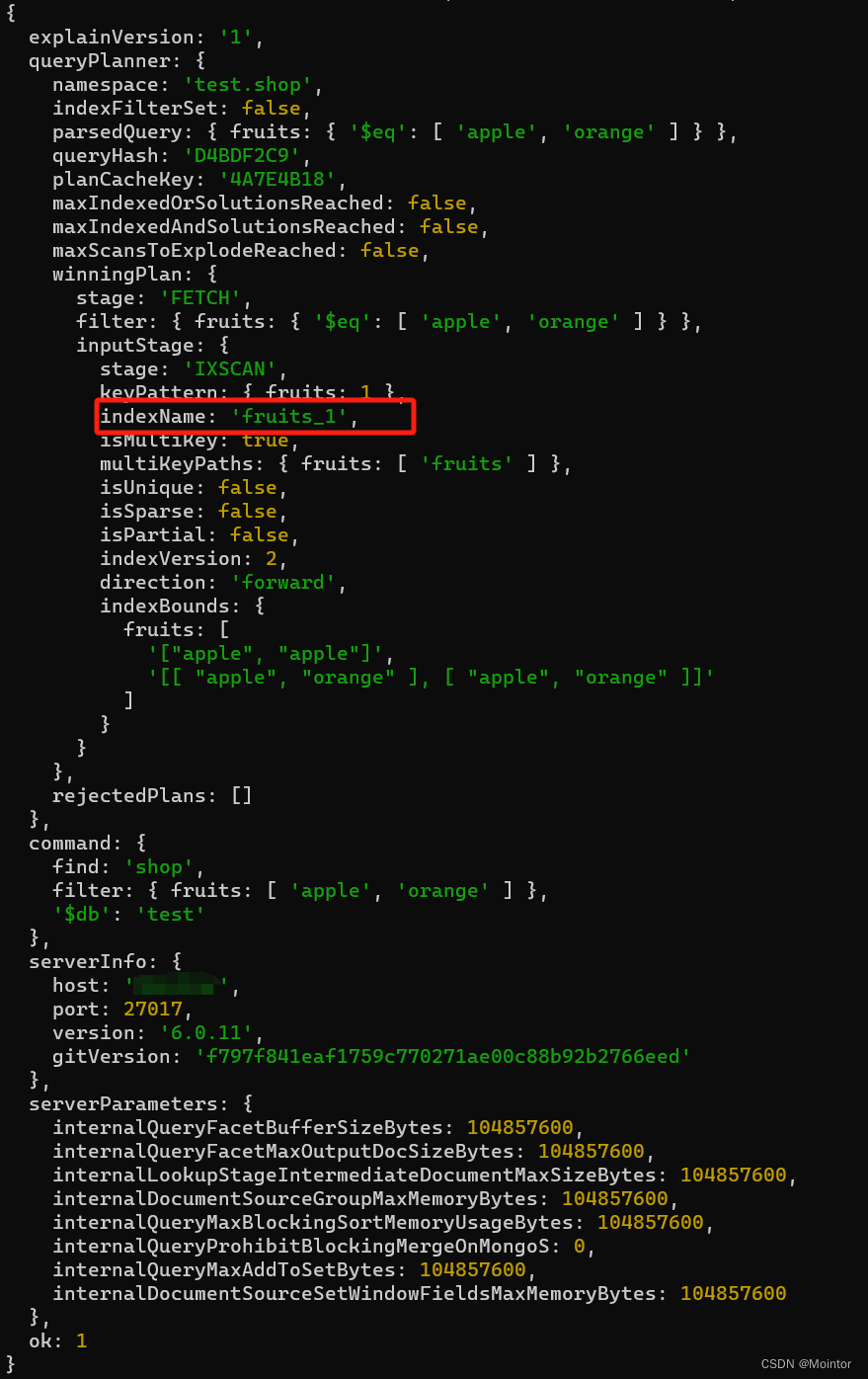
【MongoDB】索引 - 数组字段的多键索引
数组字段创建索引时,MongoDB会为数组中的每个元素创建索引键(多键索引),多键索引支持数组字段的高效查询。 一、准备工作 这里准备一些数据 db.shop.insertMany([{_id: 1, name: "水果店1", fruits: ["apple&qu…...
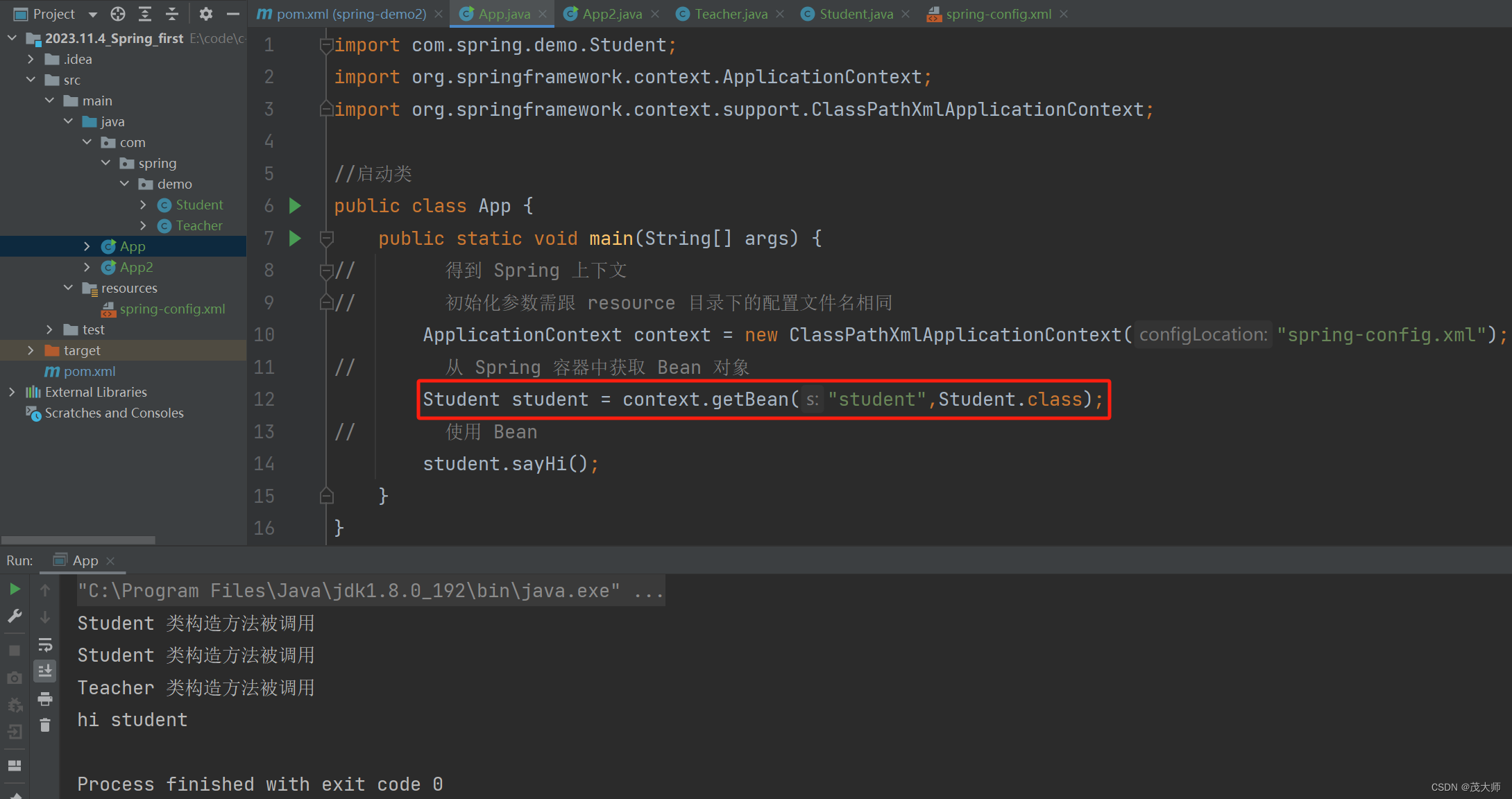
2023.11.5 关于 Spring 创建 和 使用
目录 创建 Spring 项目 1.创建 Maven 项目 2.添加 Spring 依赖 将 Bean 对象存储到 Spring 容器中 创建 Bean 存储 Bean ApplicationContext 获取 Bean BeanFactory 获取 Bean ApplicationContext 和 BeanFactory 的区别 获取 Bean 的三种方式 根据 Bean id 获取…...
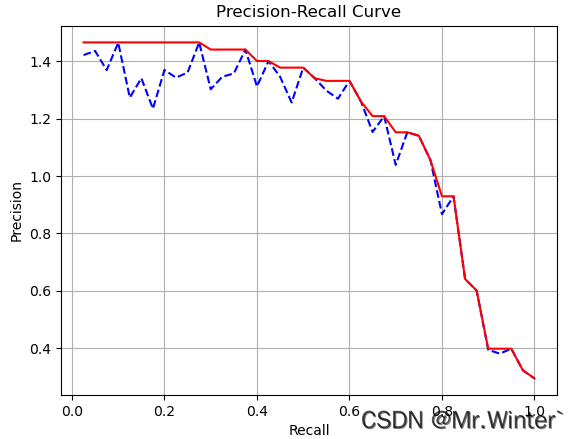
3D目标检测实战 | 图解KITTI数据集评价指标AP R40(附Python实现)
目录 1 准确率和召回率2 P-R曲线的绘制3 AP R11与AP R40标准4 实际案例 1 准确率和召回率 首先给出 T P TP TP、 F P FP FP、 F N FN FN、 T N TN TN的概念 真阳性 True Positive T P TP TP 预测为正(某类)且真值也为正(某类)的样本数,可视为 I o U > I o U t…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

ubuntu22.04 安装docker 和docker-compose
首先你要确保没有docker环境或者使用命令删掉docker sudo apt-get remove docker docker-engine docker.io containerd runc安装docker 更新软件环境 sudo apt update sudo apt upgrade下载docker依赖和GPG 密钥 # 依赖 apt-get install ca-certificates curl gnupg lsb-rel…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...

绕过 Xcode?使用 Appuploader和主流工具实现 iOS 上架自动化
iOS 应用的发布流程一直是开发链路中最“苹果味”的环节:强依赖 Xcode、必须使用 macOS、各种证书和描述文件配置……对很多跨平台开发者来说,这一套流程并不友好。 特别是当你的项目主要在 Windows 或 Linux 下开发(例如 Flutter、React Na…...