7.spark sql编程
概述
spark 版本为
3.2.4,注意RDD转DataFrame的代码出现的问题及解决方案
本文目标如下:
RDD,Datasets,DataFrames之间的区别- 入门
- SparkSession
- 创建
DataFrames DataFrame操作- 编程方式运行
sql查询 - 创建
Datasets DataFrames与RDDs互相转换- 使用反射推断模式
- 编程指定
Schema
参考 Spark 官网
相关文章链接如下
| 文章 | 链接 |
|---|---|
| spark standalone环境安装 | 地址 |
| Spark的工作与架构原理 | 地址 |
| 使用spark开发第一个程序WordCount程序及多方式运行代码 | 地址 |
| RDD编程指南 | 地址 |
| RDD持久化 | 地址 |
RDD ,Datasets,DataFrames 之间的区别
Datasets , DataFrames和 RDD
Dataset 是一个分布式的数据集合,Dataset 是 Spark 1.6 中添加的一个新接口,它增益了 RDD (强类型,可以使用 lambda 函数的能力) 和 Spark sql 优化执行引擎的优势。Dataset 可以由JVM对象构建,然后使用函数转换(map、flatMap、filter等)进行操作。数据集API有Scala和Java版本。Python不支持数据集API。
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,DataFrame API在Scala、Java、Python和R中可用。在Scala API中,DataFrame只是Dataset[Row]的一个类型别名。而在Java API中,用户需要使用Dataset<Row>来表示DataFrame。
DataFrame=RDD+Schema,RDD可以认为是表中的数据,Schema是表结构信息。DataFrame可以通过很多来源进行构建,包括:结构化的数据文件,Hive中的表,外部的关系型数据库,以及RDD
入门
Spark SQL是一个用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了更多关于正在执行的数据结构信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。有几种方法可以与SparkSQL进行交互,包括SQL和 Dataset API。计算结果时,使用相同的执行引擎,与用于表示计算的API/语言无关。方便用户切换不同的方式进行操作
people.json
people.json文件准备
SparkSession
Spark sql 中所有功能入口点是 SparkSession类。创建一个基本的 SparkSession,只需使用 SparkSession.builder()
import org.apache.spark.sql.SparkSessionval spark = SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.option", "some-value").getOrCreate()
创建 DataFrames
使用 SparkSession,通过存在的RDD,hive 表,或其它的Spark data sources 程序创建 DataFrames
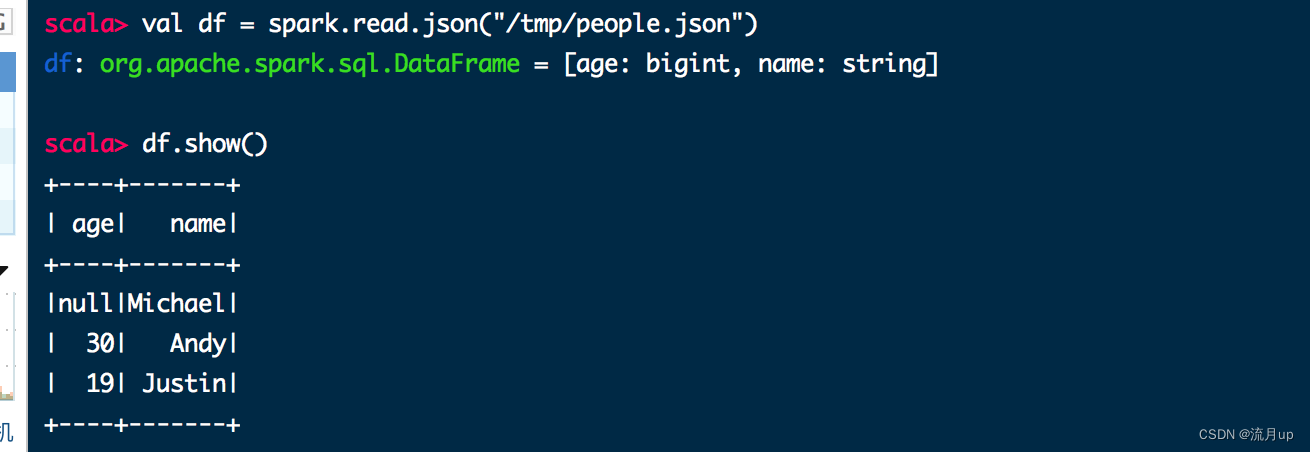
val df = spark.read.json("/tmp/people.json")
df.show()
执行如下图
DataFrame 操作
使用数据集进行结构化数据处理的基本示例如下
// 需要引入 spark.implicits._ 才可使用 $
// This import is needed to use the $-notation
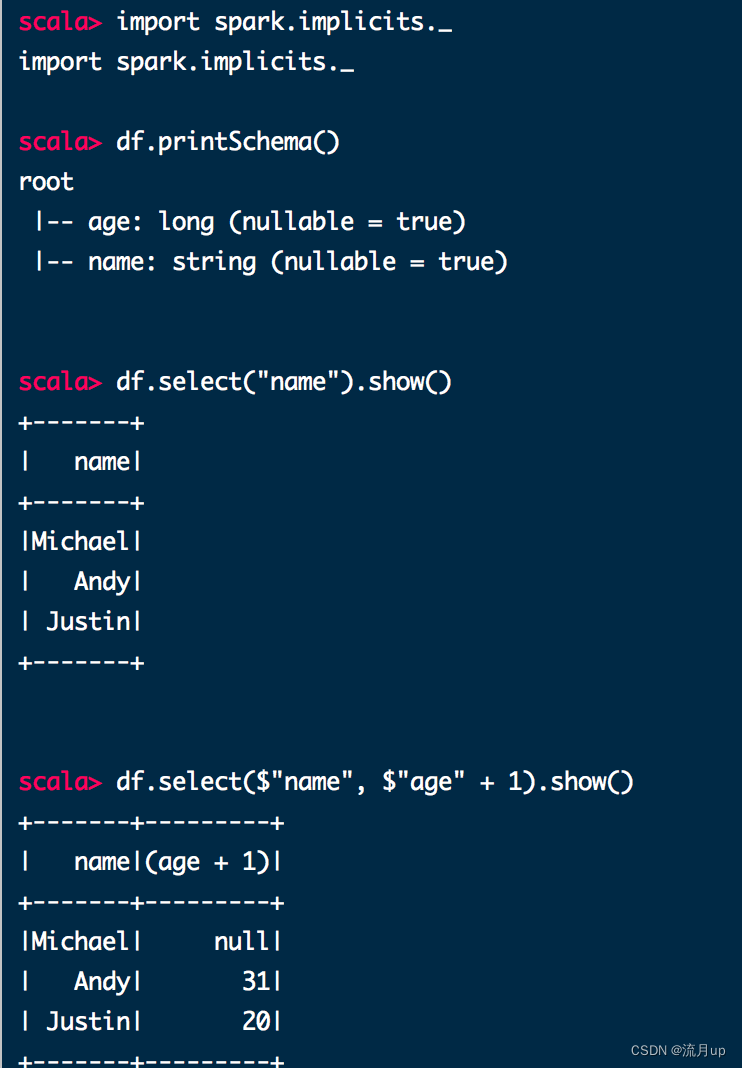
import spark.implicits._
// 打印schema 以树格式
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)// 仅显示 name 列
// Select only the "name" column
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// 显示所有,age 加1
// Select everybody, but increment the age by 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+// 过滤 人的 age 大于 21
// Select people older than 21
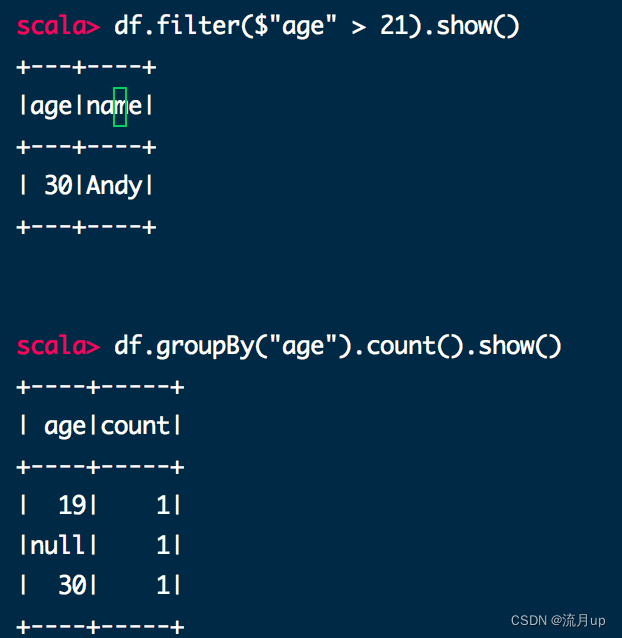
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+// 按 age 分组统计
// Count people by age
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
spark-shell 执行如下图
编程方式运行 sql 查询
df.createOrReplaceTempView("people")val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
执行如下:
scala> df.createOrReplaceTempView("people")scala> val sqlDF = spark.sql("SELECT * FROM people")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]scala> sqlDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
创建 Datasets
Datasets类似于RDD,不是使用Java序列化或Kryo,而是使用专门的编码器来序列化对象,以便通过网络进行处理或传输。使用的格式允许Spark执行许多操作,如过滤、排序和哈希,而无需将字节反序列化为对象。
case class Person(name: String, age: Long)// 为 case classes 创建编码器
// Encoders are created for case classes
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()// 为能用类型创建编码器,并提供 spark.implicits._ 引入
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)// 通过定义类,将按照名称映射,DataFrames 能被转成 Dataset
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "/tmp/people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
执行如下:
scala> case class Person(name: String, age: Long)
defined class Personscala> val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]scala> caseClassDS.show()
+----+---+
|name|age|
+----+---+
|Andy| 32|
+----+---+scala> val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS: org.apache.spark.sql.Dataset[Int] = [value: int]scala> primitiveDS.map(_ + 1).collect()
res1: Array[Int] = Array(2, 3, 4)scala> val path = "/tmp/people.json"
path: String = /tmp/people.jsonscala> val peopleDS = spark.read.json(path).as[Person]
peopleDS: org.apache.spark.sql.Dataset[Person] = [age: bigint, name: string]scala> peopleDS.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
DataFrames 与 RDDs 互相转换
Spark SQL支持两种不同的方法将现有RDD转换为Datasets。
- 第一种方法使用反射来推断包含特定类型对象的
RDD的模式。这种基于反射的方法可以生成更简洁的代码,当知道schema结构的时间,会有更好的效果。 - 第二种方法是通过编程接口,构造
schema,然后将其应用于现有的RDD。虽然此方法更详细,直至运行时,才能知道他们的字段和类型,用于构造Datasets。
使用反射推断模式
代码如下:
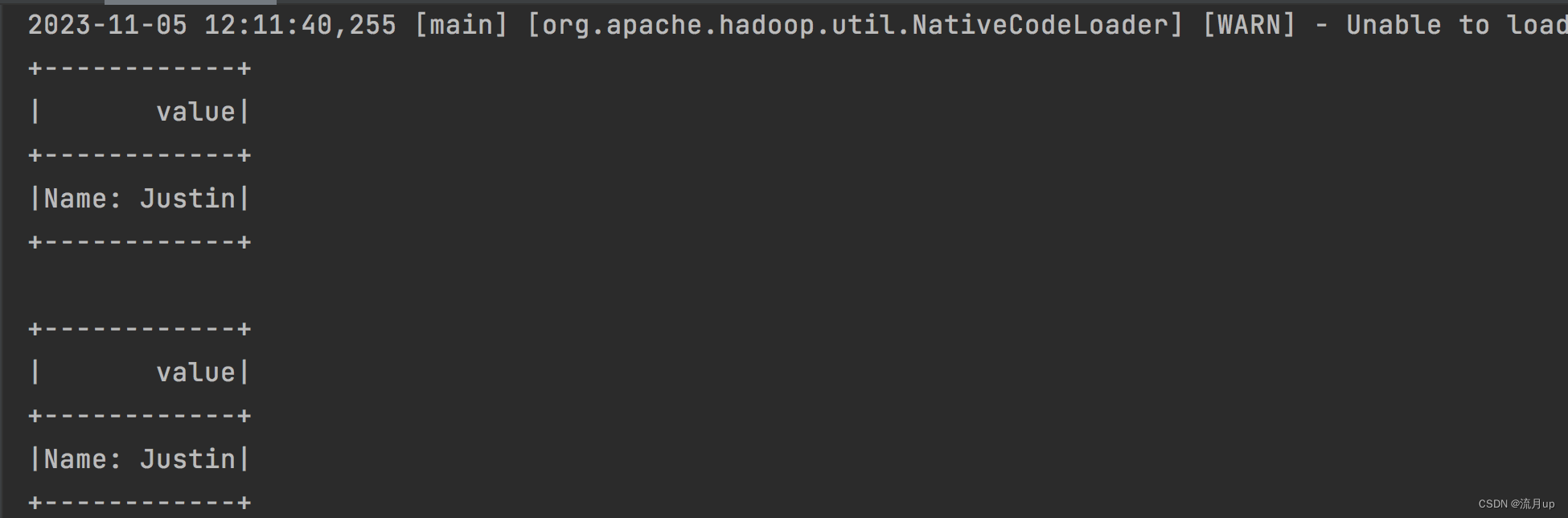
object RddToDataFrameByReflect {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("RddToDataFrameByReflect").master("local").getOrCreate()// 用于从RDD到DataFrames的隐式转换// For implicit conversions from RDDs to DataFramesimport spark.implicits._// Create an RDD of Person objects from a text file, convert it to a Dataframeval peopleDF = spark.sparkContext.textFile("/Users/hyl/Desktop/fun/sts/spark-demo/people.txt").map(_.split(",")).map(attributes => Person(attributes(0), attributes(1).trim.toInt)).toDF()// Register the DataFrame as a temporary viewpeopleDF.createOrReplaceTempView("people")// SQL statements can be run by using the sql methods provided by Sparkval teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")// The columns of a row in the result can be accessed by field indexteenagersDF.map(teenager => "Name: " + teenager(0)).show()// or by field nameteenagersDF.map(teenager => "Name: " + teenager.getAs[String]("name")).show()}case class Person(name: String, age: Long)
}
执行如下图:
编码问题
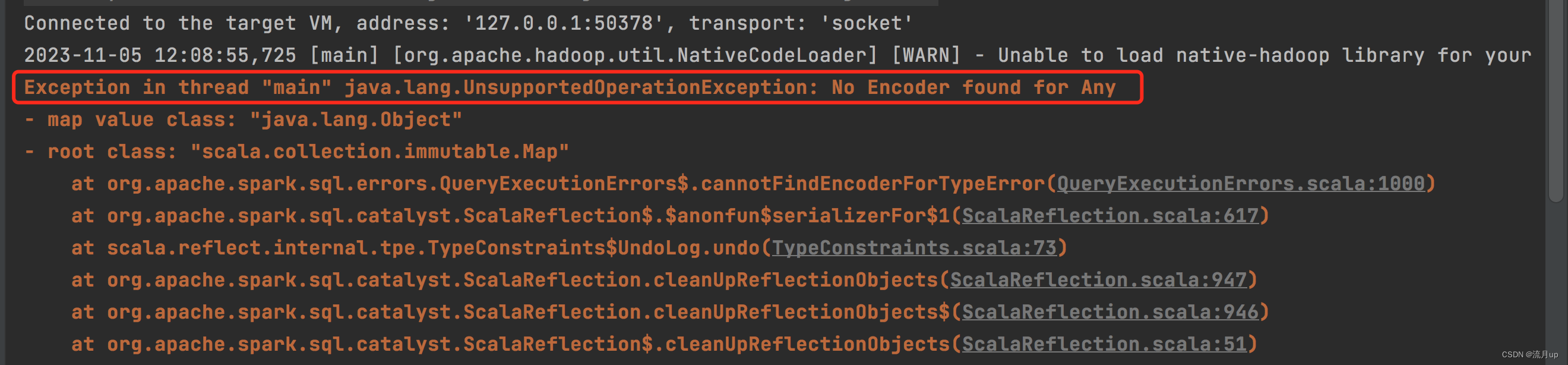
关于 Spark 官网 上复杂类型编码问题,直接加下面一句代码
teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect().foreach(println(_))
报以下图片错误
将原有代码改变如下:
// 没有为 Dataset[Map[K,V]] 预先定义编码器,需要自己定义// No pre-defined encoders for Dataset[Map[K,V]], define explicitlyimplicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]// 也可以如下操作// Primitive types and case classes can be also defined as// implicit val stringIntMapEncoder: Encoder[Map[String, Any]] = ExpressionEncoder()// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect().foreach(println(_))// Array(Map("name" -> "Justin", "age" -> 19))
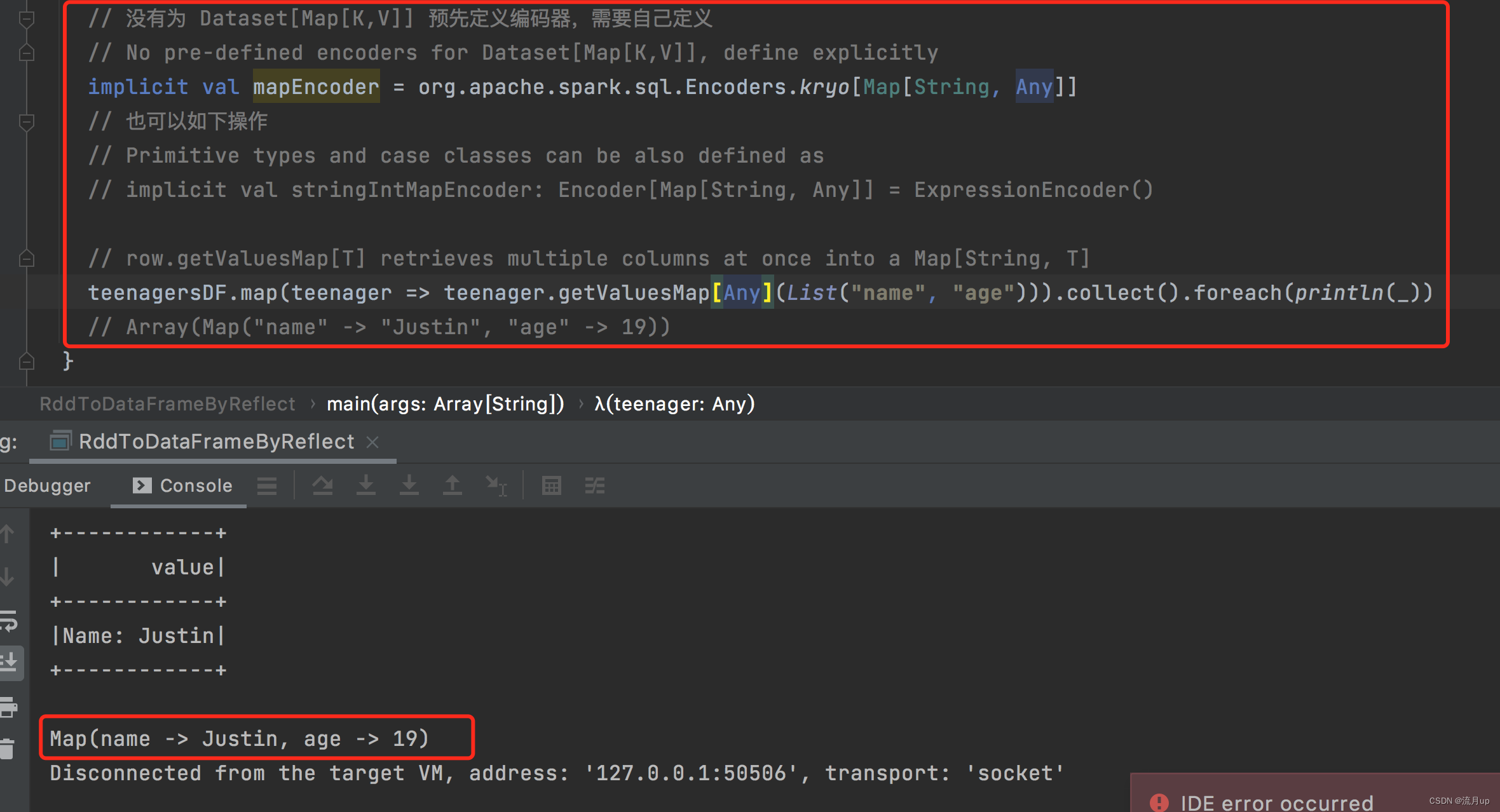
通过这一波操作,就可以理解什么情况下,需要编码器,以及编码器的作用
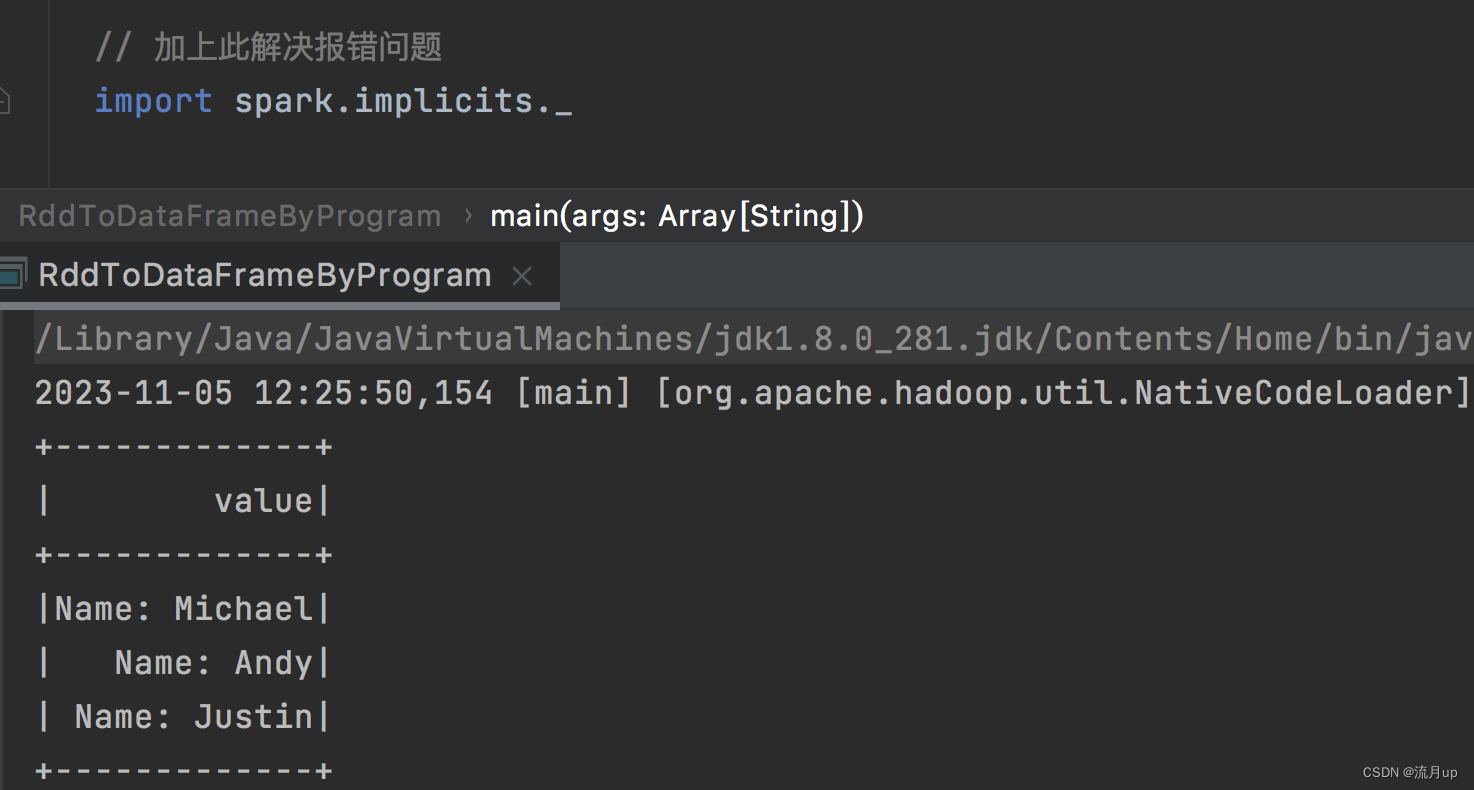
编程指定 Schema
代码如下:
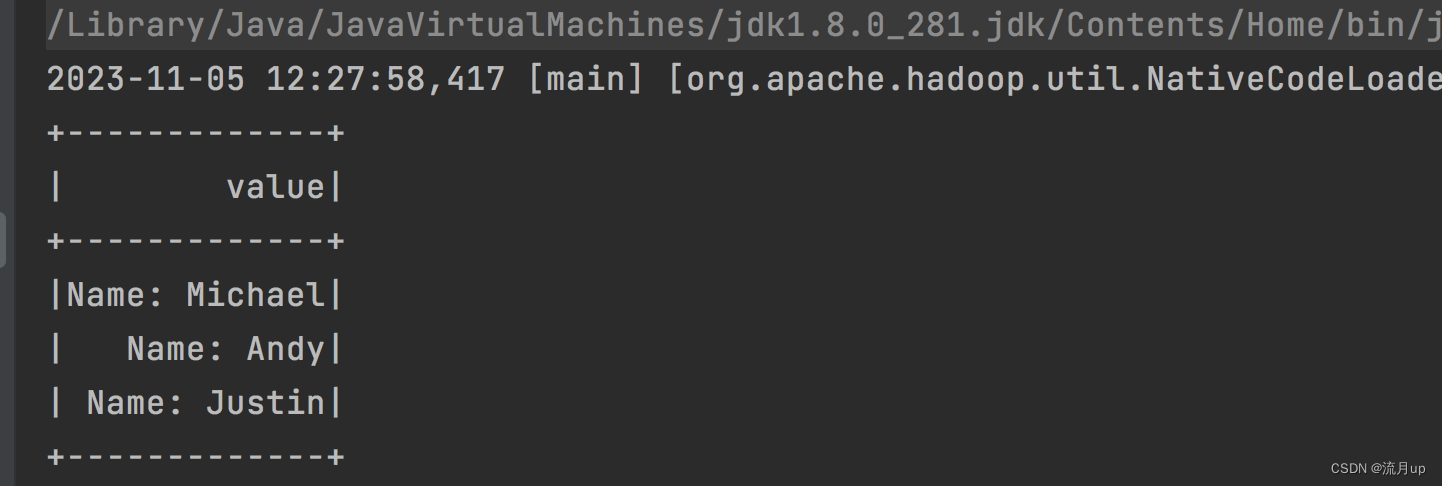
object RddToDataFrameByProgram {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local").getOrCreate()import org.apache.spark.sql.Rowimport org.apache.spark.sql.types._// 加上此解决报错问题import spark.implicits._// Create an RDDval peopleRDD = spark.sparkContext.textFile("/Users/hyl/Desktop/fun/sts/spark-demo/people.txt")// The schema is encoded in a stringval schemaString = "name age"// Generate the schema based on the string of schemaval fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))val schema = StructType(fields)// Convert records of the RDD (people) to Rowsval rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim))// Apply the schema to the RDDval peopleDF = spark.createDataFrame(rowRDD, schema)// Creates a temporary view using the DataFramepeopleDF.createOrReplaceTempView("people")// SQL can be run over a temporary view created using DataFramesval results = spark.sql("SELECT name FROM people")// The results of SQL queries are DataFrames and support all the normal RDD operations// The columns of a row in the result can be accessed by field index or by field nameresults.map(attributes => "Name: " + attributes(0)).show()}
}
执行如下图
官方文档的代码不全问题
Unable to find encoder for type String. An implicit Encoder[String] is needed to store String instances in a Dataset. Primitive types (Int, String, etc) and Product types (case classes) are supported by importing spark.implicits._ Support for serializing other types will be added in future releases.
results.map(attributes => "Name: " + attributes(0)).show()

加下以下代码
// 加上此解决报错问题
import spark.implicits._
如下图解决
结束
spark sql 至此结束,如有问题,欢迎评论区留言。
相关文章:
7.spark sql编程
概述 spark 版本为 3.2.4,注意 RDD 转 DataFrame 的代码出现的问题及解决方案 本文目标如下: RDD ,Datasets,DataFrames 之间的区别入门 SparkSession创建 DataFramesDataFrame 操作编程方式运行 sql 查询创建 DatasetsDataFrames 与 RDDs 互相转换 使用…...

【2023】COMAP美赛数模中的大型语言模型LLM和生成式人工智能工具的使用
COMAP比赛中的大型语言模型和生成式人工智能工具的使用 写在最前面GitHub Copilot工具 说明局限性 团队指南引文和引用说明人工智能使用报告 英文原版 Use of Large Language Models and Generative AI Tools in COMAP ContestslimitationsGuidance for teamsCitation and Refe…...

数据结构-顺序表学习资料
什么是顺序表? 顺序表是一种线性数据结构,它按照元素在内存中的物理顺序存储数据。顺序表可以通过数组实现,也可以通过链表和动态数组实现。 顺序表的特点 元素连续存储:顺序表中的元素在内存中是连续存储的,这样可…...

微信小程序获取剪切板的内容到输入框中
xml代码 <navigation-bar title"Weixin" back"{{false}}" color"black" background"#FFF"></navigation-bar> <view><input placeholder"请输入内容" name"content" type"text" …...

【年底不想背锅!网络工程师必收藏的排障命令大全】
网络故障排除工具是每个网络工程师的必需品。 为了提升我们的工作效率, 不浪费时间,工具的重要性显而易见 特别是每当添加新的设备或网络发生变更时,新的问题就会出现,而且很难快速确定问题出在哪里。每一位网络工程师或从事网…...

Windows服务器用PowerShell script判断服务器启动时间并做reboot动作
脚本如下,Windows 2019环境 60*119 是119分钟 $x(Get-Date) - (gcim Win32_OperatingSystem).LastBootUpTime echo $x.TotalSeconds " seconds passed" if($x.TotalSeconds -gt 60*119) {Invoke-Expression -Command "msg.exe * /TIME:20 reboot i…...
【HTML】播放器如何自动播放【已解决】
自动播放器策略 先了解浏览器的自动播放器策略 始终允许静音自动播放在以下情况,带声音的自动播放才会被允许 2.1 用户已经与当前域进行交互 2.2 在桌面上,用户的媒体参与指数阈值(MEI)已被越过,这意味着用户以前播放带有声音的视频。 2.3 …...

Go Gin中间件
Gin是一个用Go语言编写的Web框架,它提供了一种简单的方式来创建HTTP路由和处理HTTP请求。中间件是Gin框架中的一个重要概念,它可以用来处理HTTP请求和响应,或者在处理请求之前和之后执行一些操作。 以下是关于Gin中间件开发的一些基本信息&am…...

财务数字化转型的切入点是什么?_光点科技
随着科技的不断进步,数字化转型已经成为各个行业追求的目标,财务领域也不例外。那么,财务数字化转型的切入点在哪里呢?如何确保转型的成功进行? 数据整合与管理 财务数据的准确性与及时性是财务管理的基石。数字化转型…...
Langchain知识点(上)
输出格式 Pydantic (JSON) 解析器 # 创建模型实例 from langchain import OpenAI model OpenAI(model_nametext-davinci-003)# ------Part 2 # 创建一个空的DataFrame用于存储结果 import pandas as pd df pd.DataFrame(columns["flower_type", "price"…...
Tomcat安装配置教程
目录 1、安装tomcat1.1、查看JDK版本1.2、 匹配对应的JDK版本1.3、 下载Tomcat1.3.1、 安装包版(推荐,不用配环境)1.3.2、 压缩包版 2、 运行Tomcat3、 不能运行问题 1、安装tomcat 1.1、查看JDK版本 由于不同版本tomcat对于jdk的版本有要求…...
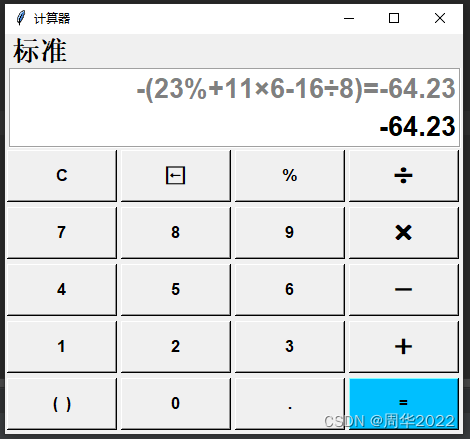
Python小试牛刀:GUI(图形界面)实现计算器UI界面(三)
上一篇:Python小试牛刀:GUI(图形界面)实现计算器UI界面(二)-CSDN博客 回顾前两篇文章,第一篇文章主要实现了计算器UI界面如何布局,以及简单概述Python常用的GUI库。第二篇文章主要实现了计算器UI界面按钮组…...

王道计算机网络
一、计算机网络概述 (一)计算机网络基本概念 计算机网络的定义、组成与功能 定义:以能够相互共享资源的方式互连起来的自治计算机系统的集合。 目的:资源共享, 组成单元:自治、互不影响的计算机 网络协议 从不同角度计算机网络…...
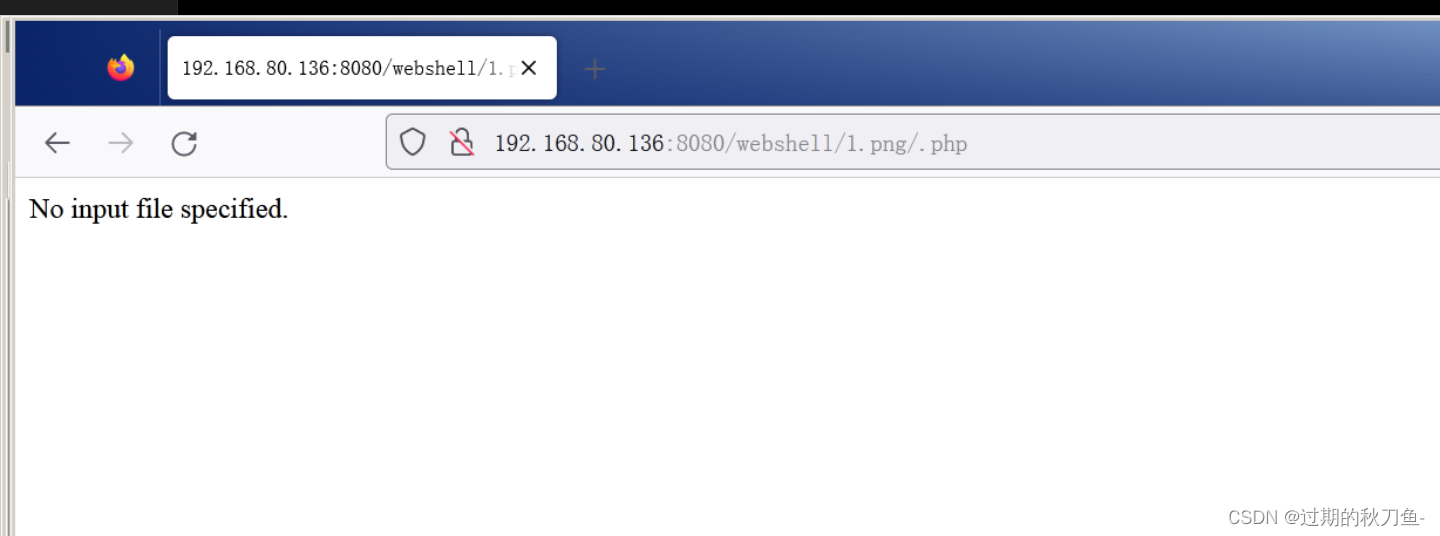
【漏洞复现】IIS_7.o7.5解析漏洞
感谢互联网提供分享知识与智慧,在法治的社会里,请遵守有关法律法规 文章目录 1.1、漏洞描述1.2、漏洞等级1.3、影响版本1.4、漏洞复现1、基础环境2、漏洞扫描3、漏洞验证 1.5、修复建议 1.1、漏洞描述 漏洞原理: cgi.fix_path1 1.png/.php该…...

Java 高效生成按指定间隔连续递增的列表(int,double)
简介 Java 按照指定间隔生成连续递增的List 列表(引入Stream 类和流操作来提高效率): 1. 生成递增的List< Integer> Testpublic void test009(){int start 1;int interval 2;int count 10;List<Integer> list IntStream.ite…...

C++ reference
cppreference.com 《现代C语言核心特性解析》 这是一本 C 进阶图书,全书分为 42 章,深入探讨了从 C11 到 C20 引入的核心特性。 本书不仅通过大量的实例代码讲解特性的概念和语法,还从编译器的角度分析特性的实现原理,让读者…...

关于网站安全的一些讨论
互联网的普及和发展为企业和个人提供了巨大的机会,但同时也伴随着网络安全威胁的增加。网站被攻击是一个常见的问题,可能导致数据泄露、服务中断和声誉受损。在本文中,我们将探讨与网络安全紧密相关的因素,分析为什么网站容易受到…...

unity 截图
unity 截图适用于各分辨率 float scr;void Start(){scr Screen.width /2160.00f;//2160是我做程序时的分辨率 Screen.width为打包后机器的分辨率}/// <summary>/// 区域截图/// </summary>/// <param name"rectT"></param>/// <param …...
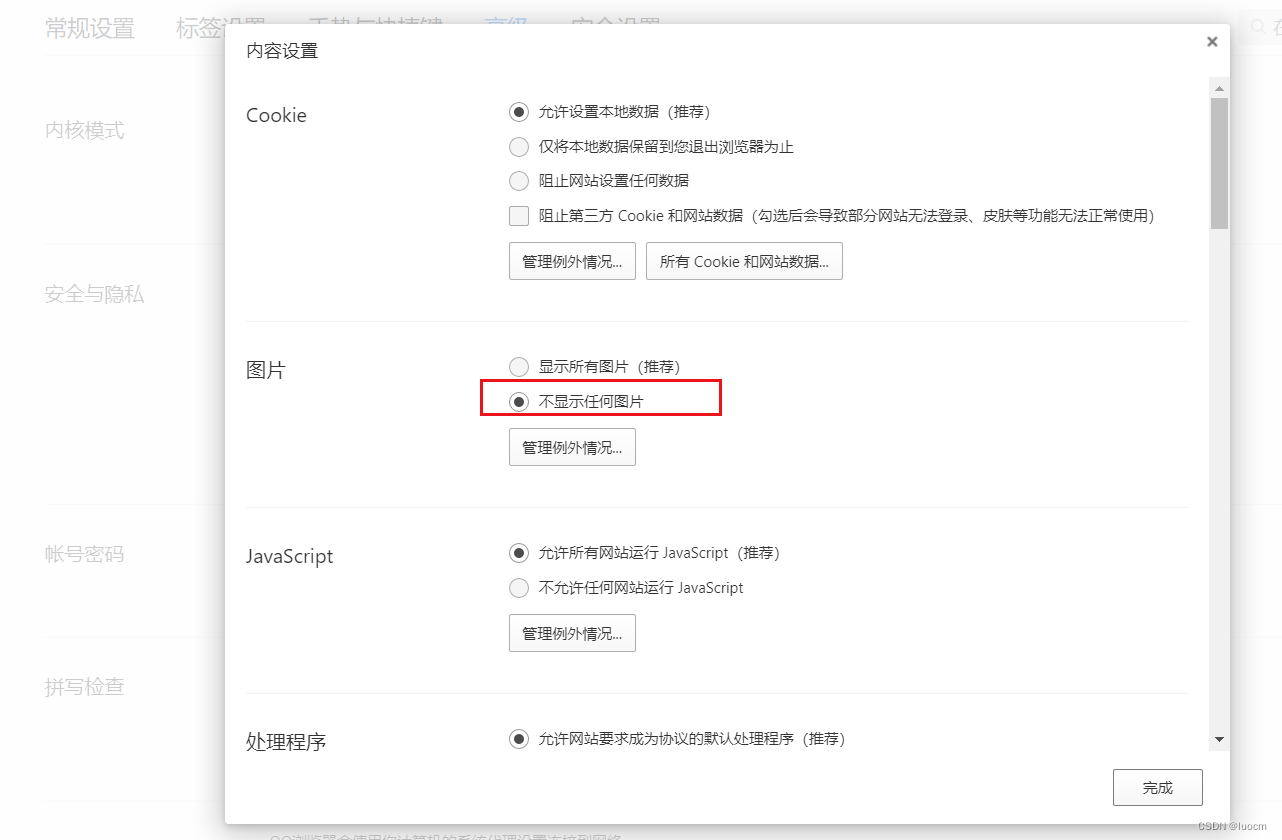
浏览器无图模式省流量经验
【备注】本文适合于那些用自购上网卡(非单位报销)、流量费花的心痛、平日里抠抠搜搜的diaosi人群!流量自由人群请关闭退出! 近日图年包流量费便宜,从某东平台上买了一个号称新款usb上网卡,只用了2天时间&a…...

【Hive】分区表和分桶表相关知识点介绍
Hive中的分区表和分桶表是两种用于优化数据查询和管理的技术。它们可以提高查询性能、减少数据扫描量并提供更精细的数据组织方式。 分区表(Partitioned Table) Hive的分区表将数据按照一个或多个列的值进行逻辑分区。每个分区都是一个独立的子目录,其中包含符合该分区条件…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...