强化学习RL 01~ 数学基础
目录
RL理解要点
1. RL数学基础
1.1 Random Variable 随机变量
1.2 概率密度函数 Probability Density Function(PDF)
1.3 期望 Expectation
1.4 随机抽样 Random Sampling
2. RL术语 Terminologies
2.1 agent、state 和 action
2.2 策略 policy π
2.3 奖励 reward
2.4 状态转移 state transition
2.5 agent environment interaction 环境交互
2.6 强化学习中的随机性 Randomness in Reinforcement Learning
2.7 play the game using AI
2.8 rewards、returns
2.8.1 Discounted return Ut 折扣回报
2.8.2 Random in Returns
2.9 value function 价值函数
2.9.1 Action-value function Qπ(s, a)
2.9.2 Optimal action-value function Q*
2.9.3 State-value function Vπ
3. How does AI control the agent?
3.1 policy function π
3.2 Q*(s, a)函数
3.3 Open AI gym
参考
RL理解要点
- RL学什么呢?就是要学习policy策略函数
1. RL数学基础
1.1 Random Variable 随机变量
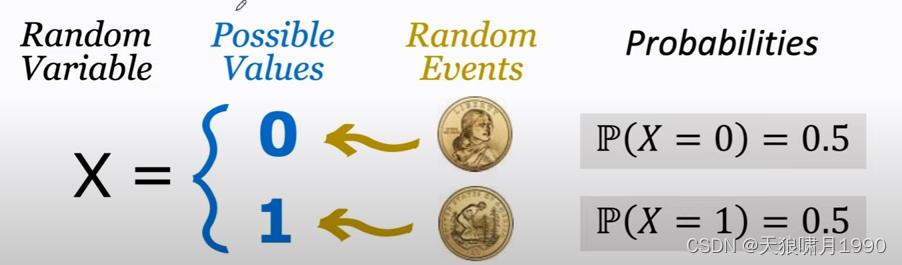
Random Variable: a variable whose values depend on outcomes of a random event. 随机变量是一个未知的量,它的值取决于随机事件的结果。
用大写字母表示随机变量 random variable,用小写字母表示随机变量观测值 observed value。
1.2 概率密度函数 Probability Density Function(PDF)
本质:就是一个概率分布(0.2, 0.3, 0.5)。
PDF provides a relative likelihood that the value of the random variable would equal that sample.
e.g. Gaussian distribution
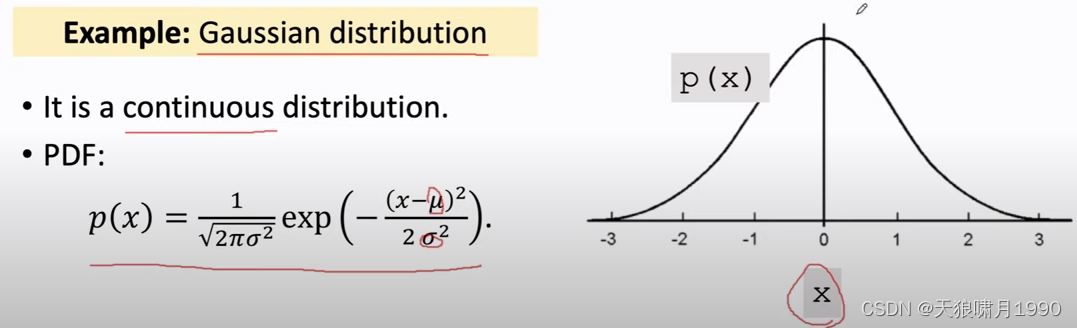
连续分布、离散分布。用表示其定义域domain

1.3 期望 Expectation
本质:是平均值,是预估结果。

1.4 随机抽样 Random Sampling

2. RL术语 Terminologies
2.1 agent、state 和 action
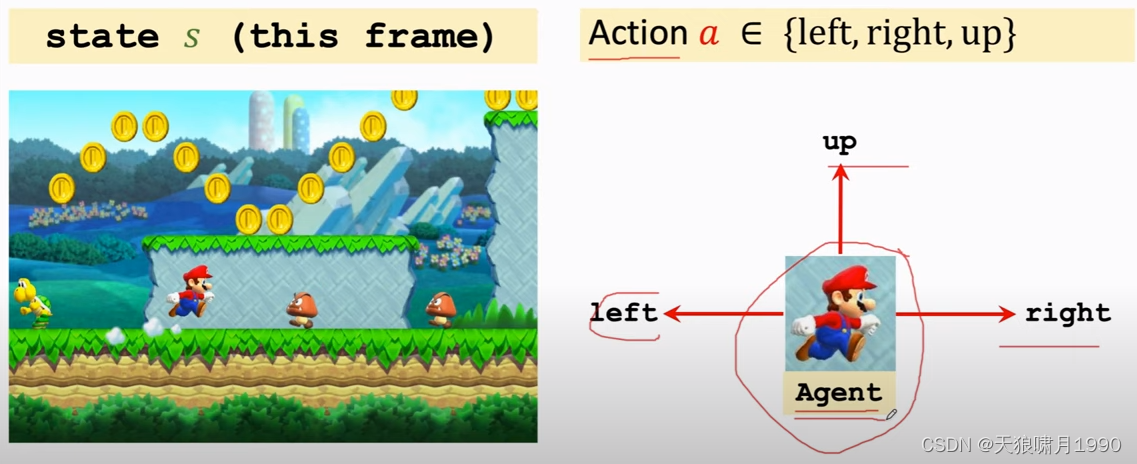
- 可以近似理解当前图片frame就是state
- agent,翻译为“智能体”
- 当前state,agent可以做的动作叫action,包括{'left', 'right', 'up'}
2.2 策略 policy π
本质:policy策略是一个概率密度函数,就是根据state生成一个动作action概率分布。
policy根绝观测到状态state,做出决策,然后控制agent运动。
Note that policy函数是随机的。

2.3 奖励 reward
agent做出一个动作,游戏就会给出一个奖励reward
奖励定义的好坏,非常影响强化学习的结果。

2.4 状态转移 state transition
agent做出一个动作,游戏就会给出一个新的状态state,这个过程就叫state transition。
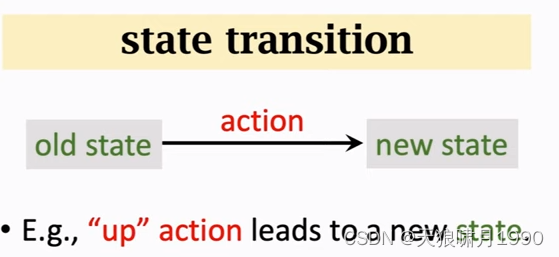
- state transition can be random.
- randomness is from the environment. 状态转移的随机性是从环境中来的,这里的环境是游戏的程序。
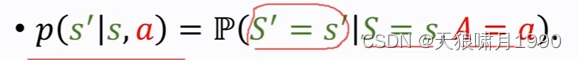
可以把状态转移用p函数来表示,这是个条件概率密度函数,意思是如果观测到当前状态s和动作a ,p函数就表示s prime的概率。
2.5 agent environment interaction 环境交互

agent和environment,agent看到状态st之后,要做出一个动作at,agent做出动作at后,环境environment会更新状态、把状态变成st+1,同时environment还会给agent一个奖励rt。
2.6 强化学习中的随机性 Randomness in Reinforcement Learning
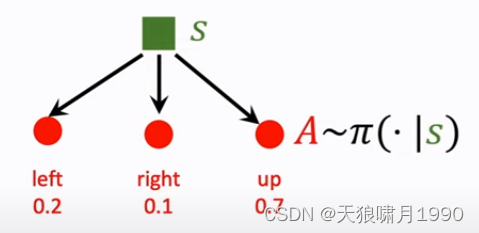
- Actions have randomness. actions是根据policy函数随机抽样得到的,我们用policy函数来控制agent,给定当前状态s,agent输出的动作a是根据策略函数policy输出的概率分布来随机抽样。
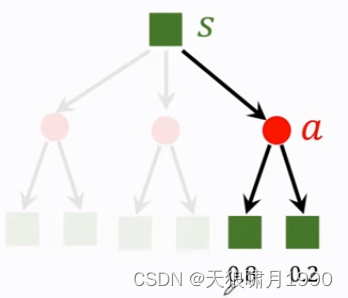
- state transitions have randomness. 假定agent做出了up action,环境environment就要生成下一个状态s',这个状态s'具有随机性,environment用状态概率转移函数p算出概率,然后用概率来随机抽样得到下一个状态s',
2.7 play the game using AI
通过强化学习学出policy function π,AI就是用policy函数来控制agent。

游戏当前状态s1,AI用policy函数来算一个概率,然后随机抽样得到动作a1,然后环境会生成下一个状态s2,并且给agent一个奖励r1,然后环境会拿新的状态s2作为输入,并用policy function来算概率,然后随机抽样得到新的动作a2,然后这样一直循环下去,直到打赢游戏或game over。
得到一个轨迹(state, action, reward)trajectory:s1,a1,r1,s2,a2,r2,...,st,at,rt。
2.8 rewards、returns
Return翻译为“回报”,也称作cumulative future reward,“未来的累积奖励”。
把t时刻的return记作Ut,就是把从t时刻开始的reward全都加起来,一直加到游戏结束时的最后一个奖励。
Question: Are Rt and Rt+1 equally important?
Future reward is less valuable than present reward.
Rt+1 should be given less weight than Rt. --> Discounted return
2.8.1 Discounted return Ut 折扣回报
γ,折扣率 discount rate gamma(tuning hyper-parameter),介于[0, 1]。

折扣率是个超参数,需要我们自己来调,折扣率的设置对强化学习的效果有一定的影响。
2.8.2 Random in Returns
Return Ut的随机性。假如游戏已经结束了,所有的奖励已经观测到了,那么奖励是数值,用rt表示;如果在t时刻游戏还没结束,那么奖励还是随机变量,还没被观测到,用Rt表示。

随机性有两个来源:一是action a是从policy概率分布中随机抽样得到的;二是下一状态new state,状态转移函数p输出一个概率分布,environment从中随机抽样得到一个新的状态s'。
- For any i ≥ t, the reward Ri depends on Si and Ai. 当前agent处在的状态s和做出的动作a,就决定了奖励Ri是什么。
- 回报Ut是Rt、Rt+1等等的加权求和,而Ri是由Si和Ai决定的,所以给定st,Ut跟t时刻开始所有的动作At,At+1,At+2,..和状态St+1,St+2,...都有关了。
2.9 value function 价值函数
2.9.1 Action-value function Qπ(s, a)

在t时刻,你并不知道Ut是什么。Ut是个随机变量,它依赖于未来所有的动作At,At+1,At+2,...和未来所有的状态St,St+1,St+2,...
Ut未知,那我该怎么评估当前的形势呢?
对Ut求期望,把里面的随机性都用积分积掉,得到一个实数。
把Ut当作未来所有动作Ai和所有状态Si的一个函数,未来的动作和状态都有随机性,动作Ai的概率密度函数是policy function π,状态Si的概率密度函数是状态转移函数p,期望就是针对未来Si和Ai求得,出了St和At,其余的随机变量都是积分积掉,被积掉的是At+1,At+2等动作、St+1,St+2等动作,求期望得到的动作价值函数Qπ,其只跟当前动作at、状态st有关。
函数Qπ还与policy function π有关,因为积分时会用到policy函数,π函数不一样,Qπ就会不一样。
Qπ的直观意义:如果用状态价值函数Qπ,那么在当前状态st下做动作at是好还是坏。
已知policy函数π,那么Qπ就会给当前状态下所有动作A打分,然后就知道哪个动作好、哪个动作不好。
2.9.2 Optimal action-value function Q*
如何把action-value function中的π去掉呢?
可以对Qπ关于π求最大化。意思是我们有无数种policy函数π,但我们应该使用最好的那一种!
最好的policy函数就是让Qπ最大化的那个π,得到函数Q*称为optimal action-value function。

Q*跟π无关,它的直观意义:Q*可以用来对当前动作at做评价--分数,比如下围棋是,你把棋子放在这个位置胜算有多大,你把棋子放在那个位置胜算有多大。
Q*非常有用,agent可以根据Q*对actions的评价来做决策。
2.9.3 State-value function Vπ

状态价值函数Vπ,它是action-value function动作价值函数Qπ的期望。
Qπ与状态st、动作A有关,可以把A当作随机变量,求期望把它消掉,这样Vπ只跟st和π有关。
Vπ直观意义:Vπ可以告诉我们当前局势好不好,比如下围棋,Vπ可以告诉我们当前胜算有多大,是快赢了还是快输了。
![]()
这里的期望是根据A求得,A的概率密度函数是policy function π。根据期望定义,可以把期望写成连加或积分的形式。
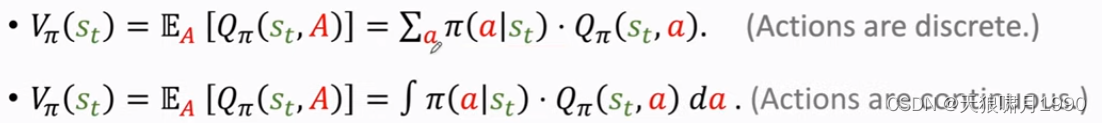
For fixed policy π, Vπ(s) evaluates how good the situation is in state s.
Es[Vπ(S)] evaluates how good the policy π is.
3. How does AI control the agent?
3.1 policy function π
一种方法是学一个策略函数policy π
有了policy 函数π,就可以用来控制agent来做动作。

3.2 Q*(s, a)函数
另一种方法是学习optimal action-value function Q*(s, a)函数,它是value based model
假如有了Q*函数,agent可以根据Q*函数来做动作了。
如果处在状态s,那么做动作a是好还是坏。没观测到一个状态st,就把st作为Q*函数的输入,让Q*函数对每一个函数做一个评价,假如up move的q值最大,因为q值是对未来奖励reward总和的期望,所以选up获取以期在未来获得更多奖励。

3.3 Open AI gym
- 经典控制问题
- atari game
- 连续控制问题 continuous control tasks


参考
1. 王树森~强化学习 Reinforcement Learning
2. https://www.cnblogs.com/pinard/category/1254674.html
相关文章:
强化学习RL 01~ 数学基础
目录 RL理解要点 1. RL数学基础 1.1 Random Variable 随机变量 1.2 概率密度函数 Probability Density Function(PDF) 1.3 期望 Expectation 1.4 随机抽样 Random Sampling 2. RL术语 Terminologies 2.1 agent、state 和 action 2.2 策略 policy π 2.3 奖励 reward …...
Java的运算符
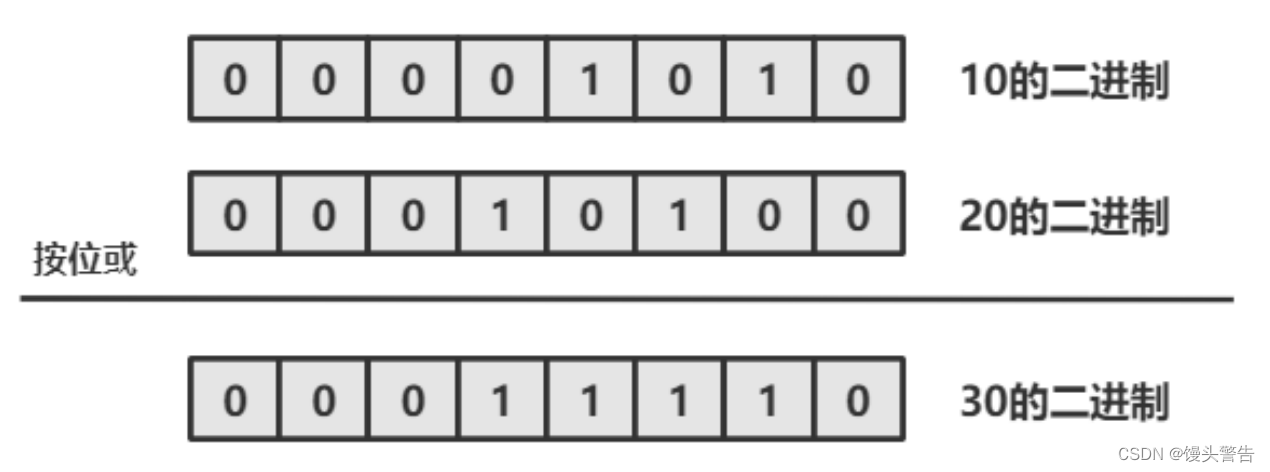
目录 一、什么是运算符 二、算术运算符 1. 基本四则运算符:加减乘除模( - * / %) 2、增量运算符 - * % 3. 自增/自减运算符 -- 三、关系运算符 四、 逻辑运算符(重点) 1. 逻辑与 && 2. 逻辑或 || 3. 逻辑非 ! 4. 短路求值…...

扫地机器人(蓝桥杯C/C++)
题目描述 小明公司的办公区有一条长长的走廊,由 NN 个方格区域组成,如下图所示。 走廊内部署了 KK 台扫地机器人,其中第 ii 台在第 A_iAi 个方格区域中。已知扫地机器人每分钟可以移动到左右相邻的方格中,并将该区域清扫干净。…...
如何理解API?API 是如何工作的?(5分钟诠释)
大家可能最近经常听到 API 这个概念,那什么是API,它又有什么特点和好处呢? wiki 百科镇楼 …[APIs are] a set of subroutine definitions, protocols, and tools for building application software. In general terms, it’s a set of cle…...

PAT--1111 对称日
央视新闻发了一条微博,指出 2020 年有个罕见的“对称日”,即 2020 年 2 月 2 日,按照 年年年年月月日日 格式组成的字符串 20200202 是完全对称的。 给定任意一个日期,本题就请你写程序判断一下,这是不是一个对称日&a…...

前端纯函数和副作用概念,且在react上的体现详解
什么是纯函数 纯函数是这样一种函数,即相同的输入,永远会得到相同的输出的函数,而且没有任何可观察的副作用。 什么是副作用 副作用是在计算结果的过程中,系统状态的一种变化,或者与外部世界进行的可观察的交互。 个…...

转行软件测试3年了,听前辈说测试前途是IT里最low的,我慌了......
互联网行业的技术岗位一般分为研发、测试和运维,虽然前些年测试一直都不如研发岗位那么吃香。但现在随着国内对软件测试的重视,我国互联网企业对软件测试的需求在未来还将继续增大。听起来软件测试的就业形势一片大好,那么到底软件测试的发展…...
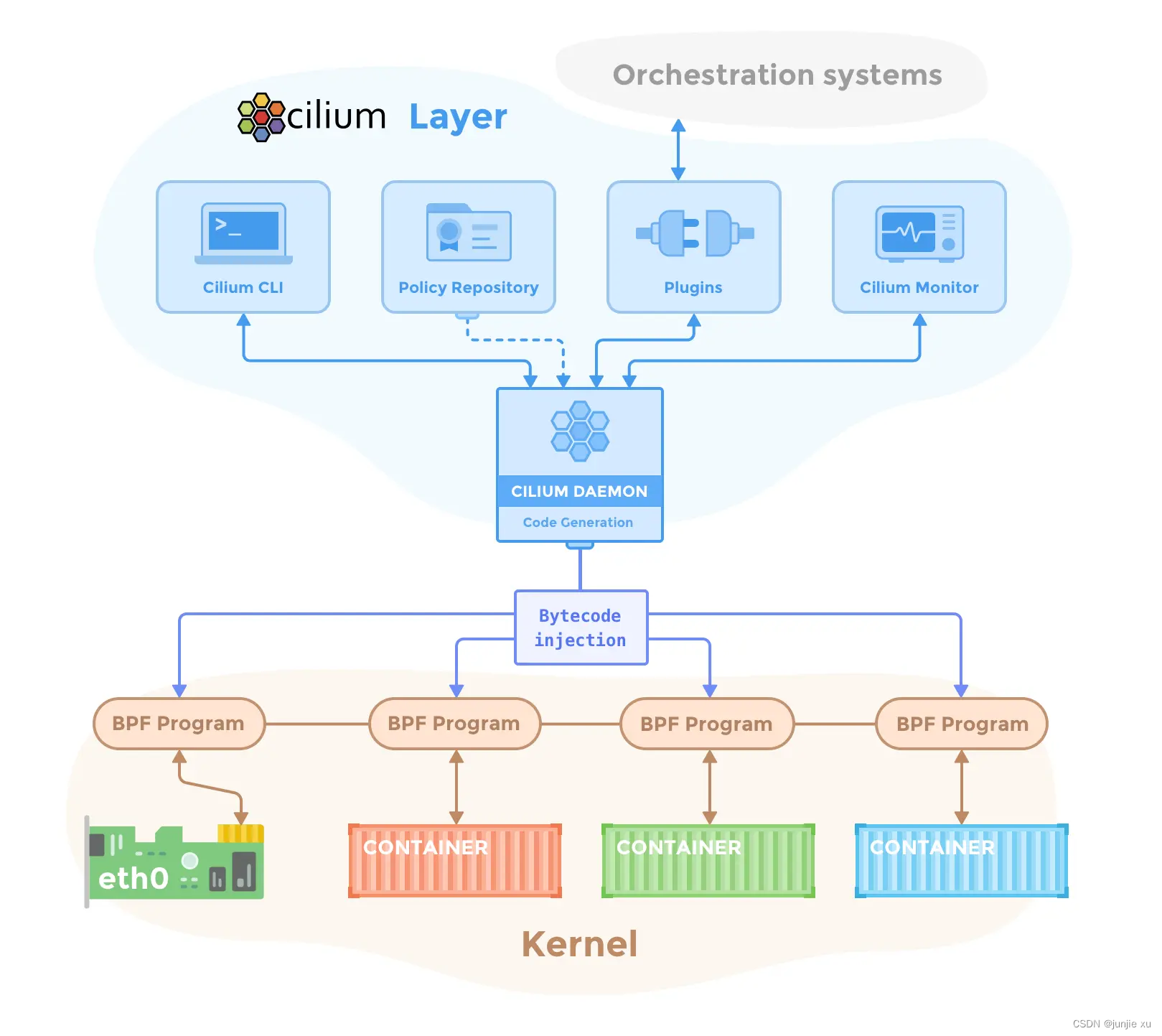
CNI 网络流量 5.1 Cilium 介绍和原理
文章目录简介安装组件和原理Cilium-agent初始化IPAMCNICilium cli 的使用bpfMap 的操作Cilium-agentEbpf简介 Cilium 是一个用于容器网络领域的开源项目,主要是面向容器而使用,用于提供并透明地保护应用程序工作负载(如应用程序容器或进程&a…...
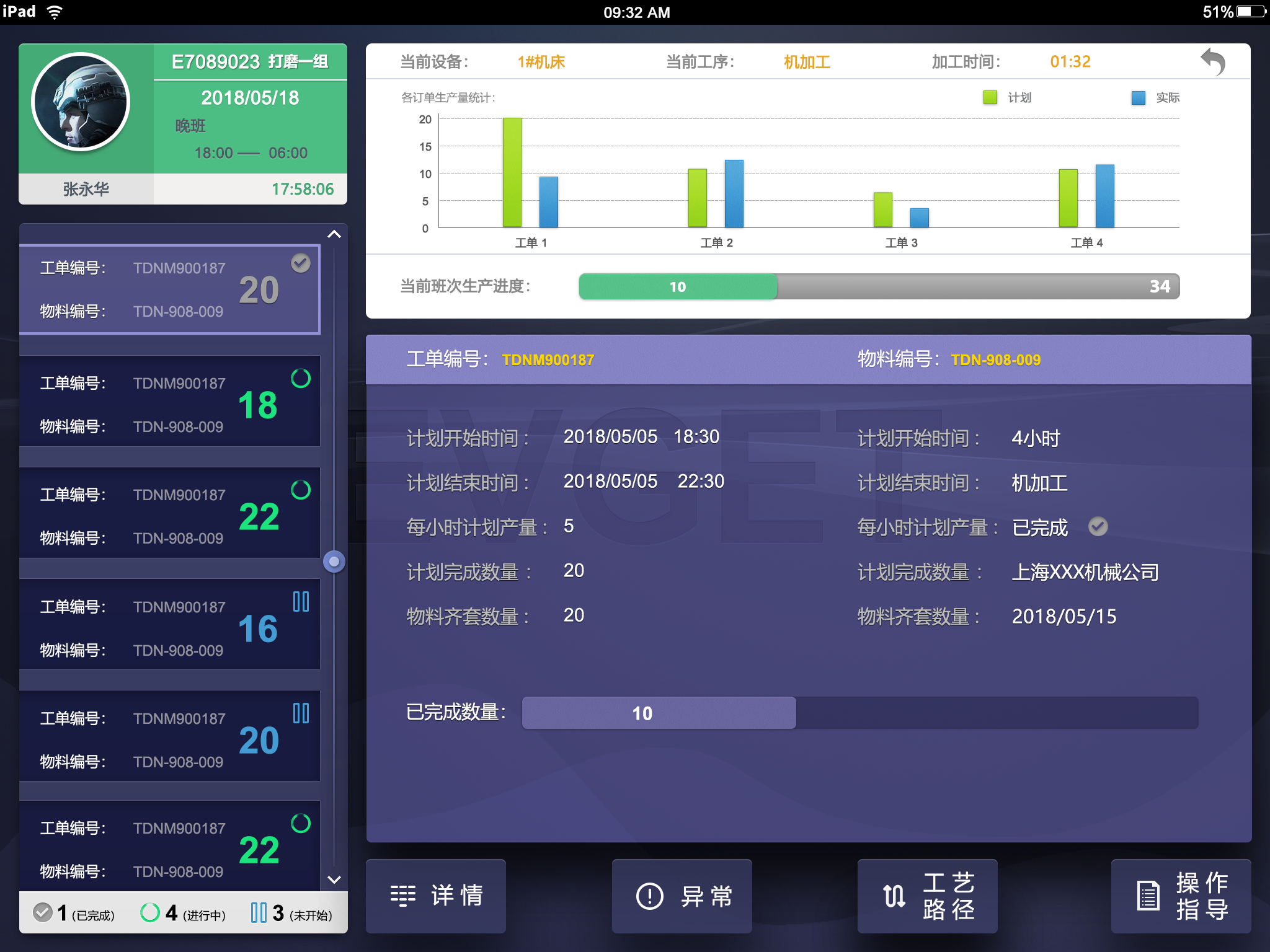
机加行业MES解决方案,助力企业打造数字化透明车间
机械加工行业的主要原材料占整个生产物料成本的95%~99%,以挖掘机为例,原材料有各种规格的钢板、焊丝、焊条、油漆以及各种气体等,其中主要原材料是钢板,占原材料比率的98%以上。 因此机械加工mes的原材料管理是机械加工行业信息化…...
C/C++每日一练(20230227)
目录 1. 按要求排序数组 ★ 2. Z 字形变换 ★★ 3. 下一个排列 ★★ 1. 按要求排序数组 给你一个整数数组 arr 。请你将数组中的元素按照其二进制表示中,数字 1 的数目升序排序。 如果存在多个数字二进制中 1 的数目相同,则必须将它们按照数值大小…...

总结SpringBoot1.x迁移到2.x需要注意的问题
SpringBoot1.x和SpringBoot2.x版本差异化还是比较大的,有些三方依赖组件有些是基于2.0版本为标准升级的,当我们将项目由1.0升级到2.0时会出现依赖的方法不存在或方法错误,需要逐个去调整,下面总结了我们升级实践过程中遇到的一些问…...

Api接口小知识
应用程序接口API(Application Programming Interface),是提供特定业务输出能力、连接不同系统的一种约定。这里包括外部系统与提供服务的系统(中控系统)或者后台不同的系统之间的交互点。包括外部接口、内部接口、内部接口有包括&…...

「JVM 高效并发」Java 协程
Java 语言抽象和隐藏了各种操作系统线程差异性的接口,这曾经是它区别于其他编程语言的一大优势,但在某些场景下,却已经出现了疲态; 文章目录1. 内核线程的局限2. 协程的复苏3. Java 的解决方案1. 内核线程的局限 在微服务架构中&…...

Web Spider案例 网洛者 第一题 JS混淆加密 - 反hook操作 练习(五)
文章目录一、资源推荐二、第一题 JS混淆加密 - 反hook操作2.1 过控制台反调试(debugger)2.2 开始逆向分析三、python具体实现代码四、记录一下,execjs调用混淆JS报错的问题总结提示:以下是本篇文章正文内容,下面案例可供参考 一、资源推荐 …...
前端基础之CSS扫盲
文章目录一. CSS基本规范1. 基本语法格式2. 在HTML引入CSS3. 选择器分类二. CSS常用属性1. 文本属性2. 文本格式3. 背景属性4. 圆角矩形和圆5. 元素的显示模式6. CSS盒子模型7. 弹性布局光使用HTML来写一个前端页面的话其实只是写了一个大体的框架, 整体的页面并不工整美观, 而…...

mysql组复制、mysql路由器、mysql的MHA高可用
文章目录前言一、mysql组复制1.实验机配置2.测试二、mysql路由器三、mysql之MHA高可用1.MHA概念1.创建一主两从集群2.MHA部署3.故障切换前言 一、mysql组复制 1.实验机配置 server1配置 首先停止数据库 [rootserver1 mysql]# /etc/init.d/mysqld stop Shutting down MySQL..…...

一篇搞懂springboot多数据源
好文推荐 https://zhuanlan.zhihu.com/p/563949762 mybatis 配置多数据源 参考文章 https://blog.csdn.net/qq_38353700/article/details/118583828 使用mybatis配置多数据源我接触过的有两种方式,一种是通过java config的方式手动配置两个数据源,…...
Verilog 数据类型和数组简介
在这篇文章将讨论 verilog 中最常用的数据类型,包括对数据表示,线网类型、变量类型,向量类型和数组的讨论。尽管 verilog 被认为是一种弱类型语言(loosely typed),但设计者仍必须在 Verilog 设计中为每个端…...

【数据结构】时间复杂度和空间复杂度以及相关OJ题的详解分析
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:数据结构 🎯长路漫漫浩浩,万事皆有期待 文章目录1.算法效率1.1 如何衡…...

31--Vue-前端开发-Vue语法
一、前端-Vue介绍 1.前端介绍 1、HTML(5)、CSS(3)、JavaScript(ES5、ES6):编写一个个的页面 ----> 给后端(PHP、Python、Go、Java) ----> 后端嵌入模板语法 ----> 后端渲染完数据 ----> 返回数据给前端 ----> 在浏览器中查看 2、Ajax的出现 -> 后台发送异…...

3小时掌握拼多多数据采集:Scrapy框架实战指南
3小时掌握拼多多数据采集:Scrapy框架实战指南 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 对于电商数据分析和市场研究从业者而言,获…...

如何用赛博朋克2077存档编辑器重塑你的夜之城体验
如何用赛博朋克2077存档编辑器重塑你的夜之城体验 【免费下载链接】CyberpunkSaveEditor A tool to edit Cyberpunk 2077 sav.dat files 项目地址: https://gitcode.com/gh_mirrors/cy/CyberpunkSaveEditor 在夜之城的霓虹灯下,你是否曾因错误的属性点分配而…...

EF Core 拦截器实战:SaveChangesInterceptor、CommandInterceptor 与审计落地
一、背景与问题缘起 MySQL 5.6.51 版本下 2000 万行核心业务表开展新增字段操作,需求为新增BIGINT(19) NOT NULL DEFAULT 0 COMMENT 注释(因业务实际需要存储大数值关联字段)。 表的核心特性为Java 多线程密集读写,业务请求持续高…...

5个核心操作完成HMCL启动器数据无缝迁移:告别重装烦恼
5个核心操作完成HMCL启动器数据无缝迁移:告别重装烦恼 【免费下载链接】HMCL A Minecraft Launcher which is multi-functional, cross-platform and popular 项目地址: https://gitcode.com/gh_mirrors/hm/HMCL 当你的Minecraft世界从一个设备转移到另一个设…...
)
避开PLC烧毁陷阱:FX3S晶体管输出必须知道的7个细节(含虚设电阻计算)
避开PLC烧毁陷阱:FX3S晶体管输出必须知道的7个细节(含虚设电阻计算) 在工业自动化现场,FX3S系列PLC的晶体管输出模块烧毁问题堪称"隐形杀手"。去年某汽车生产线因一个0.5A保险丝选型错误导致全线停产8小时,损…...
)
告别重复输入密码!手把手教你为GitLab配置SSH密钥(Windows/Mac通用)
告别重复输入密码!手把手教你为GitLab配置SSH密钥(Windows/Mac通用) 每次提交代码都要输入密码?GitLab频繁的身份验证是否让你感到烦躁?作为开发者,我们每天要与版本控制系统打交道数十次,重复的…...

高性能队列Disruptor:从原理到实战的完整指南
高性能队列Disruptor:从原理到实战的完整指南 【免费下载链接】blog_demos CSDN博客专家程序员欣宸的github,这里有六百多篇原创文章的详细分类和汇总,以及对应的源码,内容涉及Java、Docker、Kubernetes、DevOPS等方面 项目地址…...

OpenClaw配置备份指南:gemma-3-12b-it模型迁移与快速恢复
OpenClaw配置备份指南:gemma-3-12b-it模型迁移与快速恢复 1. 为什么需要备份OpenClaw配置? 上周我的主力开发机突然硬盘故障,导致精心调校的OpenClaw配置全部丢失。整整两天时间,我都在重新配置模型参数、飞书通道和自定义技能—…...
)
从相似度矩阵到业务落地:AdaFace模型测试结果全解读(含自研推理代码分享)
从相似度矩阵到业务落地:AdaFace模型测试结果全解读(含自研推理代码分享) 当开发者完成AdaFace模型训练后,如何准确评估模型效果并实现业务落地成为关键挑战。相似度矩阵作为人脸识别系统的核心输出,其解读直接影响身份…...
)
YOLOv5与DeepSort结合优化:如何调整参数让目标跟踪更精准(附代码对比)
YOLOv5与DeepSort参数调优实战:提升目标跟踪精度的关键策略 在计算机视觉领域,目标跟踪技术正从实验室快速走向工业应用。当基础功能实现后,如何让系统在实际场景中表现更稳定、更精准,成为开发者面临的核心挑战。本文将深入剖析Y…...