JPA 注解及主键生成策略使用指南
JPA 注解
Entity 常用注解
参考:JPA & Spring Data JPA学习与使用小记
指定对象与数据库字段映射时注解的位置:如@Id、@Column等注解指定Entity的字段与数据库字段对应关系时,注解的位置可以在Field(属性)或Property(属性的get方法上),两者统一用其中一种,不能两者均有。推荐用前者。
@Entity、@Table
@Entity(必需)
标注在实体类上。
映射实体类。指出该 Java 类为实体类,将映射到指定的关系数据库表。
应用了此注解后,将会自动将类名映射作为数据库表名、将类内的字段名映射为数据库表的列名。映射策略默认是按驼峰命名法拆分将类名或字段名拆分成多部分,然后以下划线连接,如StudentEntity -> student_entity、studentName -> student_name。若不按默认映射,则可通过@Table、@Column 指定,见下面。
@Table(可选)
标注在实体类上。
映射数据库表名。当实体类与其映射的数据库表名不同名时需要使用 @Table 标注说明,该标注与 @Entity 标注并列使用
- schema属性:指定数据库名
- name属性:指定表名,不指定时默认按驼峰命名法拆分将类名,并以下划线连接
@DynamicInsert、@DynamicUpdate
@DynamicInsert(可选)
标注在实体类上。
设置为 true,表示 insert 对象的时候,生成动态的 insert 语句,如果这个字段的值是 null 就不会加入到 insert 语句中,默认 false
@DynamicUpdate(可选)
标注在实体类上。
-
设置为 true,表示执行 update 对象时,在生成动态的 update 语句前,会先查询该表在数据库中的字段值,并对比更新使用的对象中的字段值与数据库中的字段值是否相同,若相同(即该值没有修改),则该字段就不会被加入到 update 语句中。
-
默认 false,表示无论更新使用实体类中的字段值与数据库中的字段值是否一致,都加入到 update 语句中,即都使用对象中所有字段的值覆盖数据库中的字段值。
比如只想更新某个属性,但是却把整个属性都更改了,这并不是希望的结果,希望的结果是:更改了哪写字段,只要更新修改的字段就够了。
所以 jpa 更新数据库字段值,无论是否有 @DynamicUpdate 注解,均需要手动先 select 对象,然后通过 set 更新对象的属性值,然后再 save 对象,实现更新操作
注意:
-
@DynamicUpdate 的动态更新的含义是,比较更新要使用的实体类中的所有字段值与从数据库中查询出来的所有字段值,判断其是否有修改,不同则加入到update语句中更新字段值。
例如:数据库中 id=1 的记录所有字段都是非空的,但是实体类中只有 name 有值,也就是所有字段都变了,只是其他字段被更新为了新的空值。
@Id、@GeneratedValue
@Id(必需)
标注在实体类成员变量或 getter 方法之上。
映射生成主键。用于声明一个实体类的属性映射为数据库的一个主键列。
若同时指定了下面的 @GeneratedValue 则存储时会自动生成主键值,否则在存入前用户需要手动为实体赋一个主键值。
主键值类型可以是:
-
Primitive types:
boolean, byte, short, char, int, long, float, double
-
Equivalent wrapper classes from package java.lang:
Byte,Short, Character, Integer, Long, Float, Double
-
java.math.BigInteger, java.math.BigDecimal
-
java.lang.String
-
java.util.Date, java.sql.Date, java.sql.Time, java.sql.Timestamp
-
Any enum type
-
Reference to an entity object
-
composite of several keys above
指定联合主键,有 @IdClass、@EmbeddedId 两种方法。
@GeneratedValue
@GeneratedValue 用于标注主键的生成策略,通过 strategy 属性指定。
默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:SqlServer 对应 identity,MySQL 对应 auto increment
-
AUTO: JPA自动选择合适的策略,是默认选项
-
IDENTITY:采用数据库 ID自增长的方式来自增主键字段,Oracle 不支持这种方式
-
TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。
-
SEQUENCE:通过序列产生主键,通过 @SequenceGenerator 注解指定序列名,MySql 不支持这种方式
@Column、@Basic、@Transient
@Column(可选)
标注在实体类成员变量或 getter 方法之上。
映射表格列。当实体的属性与其映射的数据库表的列不同名时需要使用 @Column 标注说明。
类的字段名在数据库中对应的字段名可以通过此注解的name属性指定,不指定则默认为将属性名按驼峰命名法拆分并以下划线连接,如 createTime 对应 create_time。
**注意:**即使name的值中包含大写字母,对应到db后也会转成小写,如@ Column(name="create_Time") 在数据库中字段名仍为create_time。可通过SpringBoot配置参数【spring.jpa.hibernate.naming.physical-strategy】配置对应策略,如指定name值是什么,数据库中就对应什么名字的列名。默认值为:【org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy】
@Column注解一共有10个属性,这10个属性均为可选属性,各属性含义分别如下:
-
name:定义了被标注字段在数据库表中所对应字段的名称。
-
unique:该字段是否为唯一标识,默认为false。也可以使用@Table标记中的@UniqueConstraint。
-
nullable:该字段是否可以为null值,默认为true。
-
length:字段的长度,当字段的类型为varchar时,该属性才有效,默认为255个字符。
-
insertable:在使用“INSERT”脚本插入数据时,是否插入该字段的值。默认为true。
-
updatable:在使用“UPDATE”脚本插入数据时,是否更新该字段的值。默认为true。
insertable = false 和updatable = false 一般多用于只读的属性,例如主键和外键等。这些字段的值通常是自动生成的。
-
columnDefinition:建表时创建该字段的DDL语句,一般用于通过Entity生成表定义时使用。
(如果DB中表已经建好,该属性没有必要使用)
-
precision和scale:表示精度,当字段类型为double时,precision表示数值的总长度,scale表示小数点所占的位数。
-
table:定义了包含当前字段的表名。
@Basic(可选)
表示一个简单的属性到数据表的字段的映射,对于没有任何标注的属性或getter方法,默认标注为 @Basic
-
fetch 表示属性的读取策略,有 EAGER 和 LAZY 两种,分别为立即加载和延迟加载
-
optional 表示该属性是否允许为 null,默认为 true
@Transient:忽略属性
定义暂态属性。表示该属性并非一个到数据库表的字段的映射,ORM 框架将忽略该属性。
如果一个属性并非数据库表的字段映射,就必须将其标识为 @Transient,否则ORM 框架默认为其注解 @Basic,例如工具方法不需要映射。
@Temporal:时间日期精度
标注在实体类成员变量或getter方法之上。可选。
在 JavaAPI 中没有定义 Date 类型的精度,而在数据库中表示 Date 类型的数据类型有 Date(年月日),Time(时分秒),TimeStamp(年月日时分秒) 三种精度,进行属性映射的时候可以使用 @Temporal 注解调整精度。
目前此注解只能用于修饰JavaAPI中的【java.util.Date】、【java.util.Calendar】类型的变量,TemporalType 取 DATE、TIME、TIMESTAMP 时在MySQL中分别对应的 DATE、TIME、DATETIME 类型。
示例:
@Temporal(TemporalType.TIMESTAMP)@CreationTimestamp //org.hibernate.annotations.CreationTimestamp,用于在JPA执行insert操作时自动更新该字段值@Column(name = "create_time", updatable=false ) //为防止手动set,可设false以免该字段被更新private Date createTime;@Temporal(TemporalType.TIMESTAMP)@UpdateTimestamp //org.hibernate.annotations.UpdateTimestamp,用于在JPA执行update操作时自动更新该字段值private Date updateTime;
时间日期自动更新:
1、Hibernate 的注解:
@CreationTimestamp(创建时间)、@UpdateTimestamp(更新时间)
用法:在时间日期类型属性上加上注解即可
2、SpringDataJPA 的注解:(可参阅https://blog.csdn.net/tianyaleixiaowu/article/details/77931903)
@CreatedDate(创建时间)、@LastModifiedDate(更新时间)、@CreatedBy、@LastModifiedBy
用法:
- 在实体类加上注解 @EntityListeners(AuditingEntityListener.class)
- 在启动类上加上注解 @EnableJpaAuditing
- 在实体类中属性中加上面四种注解
示例:
@Data
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
public abstract class BaseEntity {@Id@GeneratedValue(strategy = GenerationType.AUTO)protected Integer id;// 创建时间@CreatedDate@Column(name = "create_time", updatable=false ) //为防止手动set,可设false以免该字段被更新private Long createTime;// 更新时间@LastModifiedDate@Column(name = "update_time")private Long updateTime;
}
其他注解
@MappedSuperClass:共有字段超类
标注在实体类上。
共有字段超类中声明了各 Entity 共有的字段,即数据库中多表中共有的字段,如 create_time、update_time、id 等。
标注为 @MappedSuperclass 的类将不是一个完整的实体类,将不会映射到数据库表,但是其属性都将映射到其子类的数据库字段中。
标注为 @MappedSuperclass 的类不能再标注 @Entity 或 @Table 注解,也无需实现序列化接口。
允许多级继承
注解的类继承另一个实体类或标注 @MappedSuperclass 类,可以使用 @AttributeOverride 或 @AttributeOverrides 注解重定义其父类属性映射到数据库表中字段。
@IdClass:指定联合主键类
标注在实体类上。
指定联合主键类。如:@IdClass(StudentExperimentEntityPK.class)
主键类 StudentExperimentEntityPK 需要满足:
- 实现 Serializable 接口
- 有默认的 public 无参数的构造方法
- 重写 equals 和 hashCode 方法。equal s方法用于判断两个对象是否相同,EntityManger 通过 find 方法来查找 Entity 时,是根据 equals 的返回值来判断的。hashCode 方法返回当前对象的哈希码
- 它的类型和名称必须与使用 @Id 进行标注的实体主键字段的类型和名称一致。
示例:
/** * 实体类*/
@Data
@Entity
@Table(name = "customer_course")
@IdClass(CustomerCourseEntityPK.class) // 指定联合主键类
public class CustomerCourseEntity {@Id@Column(name = "customer_id", length = ColumnLengthConstrain.LEN_ID_MAX)private String customerId;@Id@Column(name = "course_id", length = ColumnLengthConstrain.LEN_ID_MAX)private String courseId;@Column(name = "max_number")private Integer maxNumber;@ManyToOne@JoinColumn(name = "course_id", referencedColumnName = "id", nullable = false, insertable = false, updatable = false)private CourseEntity courseByCourseId;
}
/** * 联合主键类*/
@Data
public class CustomerCourseEntityPK implements Serializable {private static final long serialVersionUID = 1L;private String customerId;private String courseId;
}
@EmbeddedId:联合主键
标注在实体类成员变量或 getter 方法上。
功能与 @IdClass 一样用于指定联合主键。不同的是其标注在实体内的主键类变量上,且主键类应该标注 @Embeddable 注解。
此外在主键类内指定的字段在实体类内可以不再指定,若再指定则需为 @Column 加上 insertable = false, updatable = false 属性
示例:
@Data
@Entity
@Table(name = "customer_course")
@IdClass(CustomerCourseEntityPK.class) // 指定联合主键类
public class CustomerCourseEntity {@EmbeddedIdprivate CustomerCourseEntityPK id;@Column(name = "max_number")private Integer maxNumber;
}
/** * 联合主键类*/
@Data
@Embeddable
public class CustomerCourseEntityPK implements Serializable {private static final long serialVersionUID = 1L;@Column(name = "customer_id", length = ColumnLengthConstrain.LEN_ID_MAX)private String customerId;@Column(name = "course_id", length = ColumnLengthConstrain.LEN_ID_MAX)private String courseId;
}
@Inheritance:表结构复用
标注在实体类上。
用于表结构复用。指定被该注解修饰的类被子类继承后子类和父类的表结构的关系。
通过 strategy 属性指定关系,有三种策略:
-
SINGLE_TABLE:适用于共同字段多独有字段少的关联关系定义。
子类和父类对应同一个表且所有字段在一个表中,还会自动生成(也可通过 @DiscriminatorColumn 指定)一个字段
varchar 'dtype'用来表示一条数据是属于哪个实体的。为默认值。未使用 @Inheritance 或使用了但没指定 strategy 属性时默认采用此策略。
-
JOINED:子类和父类对应不同表,父类属性对应的列(除了主键)不会且无法再出现在子表中。子表自动产生与父表主键对应的外键与父表关联。同样地也可通过 @DiscriminatorColumn 为父类指定一个字段用于标识一条记录属于哪个子类。
-
TABLE_PER_CLASS:子类和父类对应不同表且各类自己的所有字段(包括继承的)分别都出现在各自的表中;表间没有任何外键关联。此策略最终效果与 @MappedSuperClass 等同。
@Inheritance 与 @MappedSuperclass 的区别:
- @MappedSuperclass 子类与父类没有外键关系、不会对应同一个表
- @Inheritance 适用于表关联后者适用于定义公共字段
- 两者是可以混合使用
@Inheritance、@MappedSuperClass 可用于定义 Inheritance 关系。这些方式的一个缺点是子类中无法覆盖从父类继承的字段的定义(如父类中 name 是 not null,但子类中允许为 null)。
除了 @Inheritance、@MappedSuperClass 外,还有一种 Inheritance 方法(此法可解决上述不足):先定义一个 Java POJO(干净的 POJO,没有任何对该类使用任何的 ORM 注解),然后不同子类继承该父类,并分别在不同子类中进行 ORM 定义即可。此法下不同子类拥有父类的公共字段且该字段在不同子类中对应的数据库列定义可不同。
@Embedded、@Embeddable
当一个实体类要在多个不同的实体类中进行使用,而其不需要生成数据库表
- @Embeddable:标注在类上,表示此类是可以被其他类嵌套
- @Embedded:标注在属性上,表示嵌套被@Embeddable注解的同类型类
@Enumerated:映射枚举
使用此注解映射枚举字段,以String类型存入数据库
注入数据库的类型有两种:EnumType.ORDINAL(Interger)、EnumType.STRING(String)
@TableGenerator:主键值生成器
TableGenerator定义一个主键值生成器,在 @GeneratedValue的属性strategy = GenerationType.TABLE时,generator属性中可以使用生成器的名字。生成器可以在类、方法或者属性上定义。
生成器是为多个实体类提供连续的ID值的表,每一行为一个类提供ID值,ID值通常是整数。
属性说明:
- name:生成器的唯一名字,可以被Id元数据使用。
- table:生成器用来存储id值的Table定义。
- pkColumnName:生成器表里用来保存主键名字的字段
- valueColumnName:生成器表里用来保存主键值的字段
- pkColumnValue:生成器表里用来保存主键名字的字段的值
- initialValue:id值的初始值。
- allocationSize:id值的增量
示例:
@Entity
public class Employee {@Id@Column(name = "id")@TableGenerator(name = "hf_opert_id_gen", // 此处的名字要和下面generator属性值一致table = "mcs_hibernate_seq", // 主键保存到数据库的表名pkColumnName = "sequence_name", // 表里用来保存主键名字的字段valueColumnName = "sequence_next_hi_value", // 表里用来保存主键值的字段pkColumnValue = "user_id", // 表里名字字段对应的值allocationSize = 1) // 自动增长,设置为1@GeneratedValue(strategy = GenerationType.TABLE, generator = "hf_opert_id_gen")private Integer id;}
@JoinColumn、@JoinColumns
@JoinColumn:指定外键
如果在实体类的某个属性上定义了联表关系(OneToOne或OneTOMany等),则使用@JoinColumn注解来定义关系的属性。JoinColumn的大部分属性和Column类似。
属性说明:
- name:主表的列名。若不指定,默认为 关联表的名称 + “_” + 关联表主键的字段名,例如 address_id
- referencedColumnName:关联表作为外键的列名。若不指定,默认为关联表的主键作为外键。
- unique:是否唯一 ,默认false
- nullable:是否允许为空,默认true
- insertable:是否允许插入,默认true
- updatable:是否允许更新,默认true
- columnDefinition:定义建表时创建此列的DDL
- secondaryTable:从表名。如果此列不建在主表上(默认建在主表),该属性定义该列所在从表的名字。
- foreignKey():外键。默认@ForeignKey(ConstraintMode.PROVIDER_DEFAULT);
@Data
@Entity
public class Person {...// Person和Address是一对一关系。Address表中名为id_address的列作为外键指向Person表中名为address_id的列@OneToOne@JoinColumn(name="address_id", referencedColumnName="id_address", unique=true)private Address address;
}@Data
@Entity
public class Address {@Id@column(name ="id_address")private Integer idAddress;
}
@JoinColumns
如果在实体类的某个属性上定义了联表关系(OneToOne或OneTOMany等),并且关系存在多个JoinColumn,则使用@JoinColumns注解定义多个JoinColumn的属性。
属性说明:
- value:定义JoinColumn数组,指定每个JoinColumn的属性
@Data
@Entity
public class Custom {// Custom和Order是一对一关系。Order表中一个名为CUST_ID的列作为外键指向Custom对应表中名为ID_CUST的列,另一名为CUST_NAME的列作为外键指向Custom对应表中名为NAME_CUST的列@OneToOne@JoinColumns({@JoinColumn(name="CUST_ID", referencedColumnName="ID_CUST"),@JoinColumn(name="CUST_NAME", referencedColumnName="NAME_CUST")})private Order order;
}
@OneToOne、@OneToMany
@OneToOne
描述一个 一对一的关联
属性说明:
- fetch:表示抓取策略,默认为FetchType.LAZY
- cascade:表示级联操作策略。CascadeType.ALL,当前类增删改查改变之后,关联类跟着增删改查。
@Data
@Entity
public class Person {...// Person和Address是一对一关系。Address表中名为id_address的列作为外键指向Person表中名为address_id的列@OneToOne@JoinColumn(name="address_id", referencedColumnName="id_address", unique=true)private Address address;
}
@OneToMany
描述一个 一对多的关联,该属性应该为集体类型,在数据库中并没有实际字段。
属性说明:
- fetch:表示抓取策略,默认为FetchType.LAZY,因为关联的多个对象通常不必从数据库预先读取到内存
- cascade:表示级联操作策略,对于OneToMany类型的关联非常重要,通常该实体更新或删除时,其关联的实体也应当被更新或删除
例如:实体User和Order是OneToMany的关系,则实体User被删除时,其关联的实体Order也应该被全部删除
@ManyToOne、@ManyToMany
@ManyToOne
表示一个多对一的映射,该注解标注的属性通常是数据库表的外键
属性说明:
- optional:是否允许该字段为null,该属性应该根据数据库表的外键约束来确定,默认为true
- fetch:表示抓取策略,默认为FetchType.EAGER
- cascade:表示默认的级联操作策略,可以指定为ALL,PERSIST,MERGE,REFRESH和REMOVE中的若干组合,默认为无级联操作
- targetEntity:表示该属性关联的实体类型。该属性通常不必指定,ORM框架根据属性类型自动判断 targetEntity
@ManyToMany
描述一个多对多的关联。多对多关联上是两个一对多关联,但是在ManyToMany描述中,中间表是由ORM框架自动处理
属性说明:
- targetEntity:表示多对多关联的另一个实体类的全名,例如:package.Book.class
- mappedBy:表示多对多关联的另一个实体类的对应集合属性名称
两个实体间相互关联的属性必须标记为@ManyToMany,并相互指定targetEntity属性, 需要注意的是,有且只有一个实体的@ManyToMany注解需要指定mappedBy属性,指向targetEntity的集合属性名称,利用ORM工具自动生成的表除了User和Book表外,还自动生成了一个User_Book表,用于实现多对多关联
@NamedStoredProcedureQuery
定义在一个实体上面声明存储过程。有多个存储过程,可以用@NamedStoredProcedureQueries。
- name:自定义存储过程在java中的唯一别名,调用时使用;
- procedureName:数据库中的存储过程名;
- parameters:存储过程的参数
- @StoredProcedureParameter:定义存储过程的参数属性
- name:参数名。和数据库里的参数名字一样
- mode:参数模式。ParameterMode.IN、OUT、INOUT、REF_CURSOR
- type:参数数据类型。String.class、Integer.class,Long.class等
- @StoredProcedureParameter:定义存储过程的参数属性
@JsonFormat、@DateTimeFormat
@JsonFormat
后端到前端的时间格式的转换。注意:该注解并非 JPA 注解。
// 出参时间格式化
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date createTime;
也可以在配置文件中配置进行时间戳统一转换:
spring.jackson.date-format=yyyy-MM-dd HH:mm:ss
spring.jackson.time-zone=GMT+8
@DateTimeFormat
前端到后端的时间格式的转换。注意:该注解并非 JPA 注解。
// 入参出参时间格式化。请求报文只需要传入"yyyy-MM-dd HH:mm:ss"格式字符串进来,则自动转换为Date类型数据
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm")
private Date createTime;
主键生成策略
通用策略
@GeneratedValue 注解介绍
参考:JPA注解之“@GeneratedValue”详解
-
通过 annotation 来映射 hibernate 实体,基于 annotation 的 hibernate 主键标识 @Id,由 @GeneratedValue 设定其生成规则。
-
@GeneratedValue 注解用于标注主键的生成策略,通过 strategy 属性指定。
默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:
- SqlServer 对应 identity
- MySQL 对应 auto increment 。
源码定义:
@Target({METHOD,FIELD})
@Retention(RUNTIME)
public @interface GeneratedValue{ GenerationType strategy() default AUTO; String generator() default "";
}
其中GenerationType:
public enum GenerationType{ TABLE, SEQUENCE, IDENTITY, AUTO
}
JPA 提供的四种标准用法为:
-
AUTO:JPA 自动选择合适的策略,是默认选项
-
IDENTITY:采用数据库ID自增长的方式来自增主键字段。Oracle 不支持这种方式
-
TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植
-
SEQUENCE:通过序列产生主键,通过@SequenceGenerator 注解指定序列名。MySql不支持这种方式
AUTO、IDENTITY、SEQUENCE 策略
-
AUTO 策略
用法:
// 指定主键 @Id // 指定主键生成策略,默认为 AUTO @GeneratedValue(strategy = GenerationType.AUTO) -
IDENTITY 策略
用法:
@Id @GeneratedValue(strategy = GenerationType.IDENTITY) -
SEQUENCE 策略
用法:
// 使用示例 @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator="aaa") @SequenceGenerator(name="aaa", sequenceName="seq_payment")@SequenceGenerator 源码定义:
@Target({TYPE, METHOD, FIELD}) @Retention(RUNTIME) public @interface SequenceGenerator { String name(); String sequenceName() default ""; int initialValue() default 0; int allocationSize() default 50; }以上属性说明如下:
-
name 表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的“generator”值中
-
sequenceName :表示生成策略用到的数据库序列名称
-
initialValue 表示主键初识值,默认为0
-
allocationSize 表示每次主键值增加的大小。例如设置成1,则表示每次创建新记录后自动加1,默认为50
-
TABLE 策略
-
用法示例:
@Id @GeneratedValue(strategy = GenerationType.TABLE, generator="pk_gen") @TableGenerator(name = "pk_gen", table="tb_generator", pkColumnName="gen_name", valueColumnName="gen_value", pkColumnValue="PAYABLEMOENY_PK", allocationSize=1 )-
在主键生成后,这条纪录的 value 值,按 allocationSize 递增。
-
使用此策略需要数据库存在相应的表
-- 定义应用表 tb_generator CREATE TABLE tb_generator ( id NUMBER NOT NULL, gen_name VARCHAR2(255) NOT NULL, gen_value NUMBER NOT NULL, PRIMARY KEY(id) ) -- 插入纪录,供生成主键使用 INSERT INTO tb_generator(id, gen_name, gen_value) VALUES (1,PAYABLEMOENY_PK', 1);
-
-
@TableGenerator 的源码定义
@Target({TYPE, METHOD, FIELD}) @Retention(RUNTIME) public @interface TableGenerator { String name(); String table() default ""; String catalog() default ""; String schema() default ""; String pkColumnName() default ""; String valueColumnName() default ""; String pkColumnValue() default ""; int initialValue() default 0; int allocationSize() default 50; UniqueConstraint[] uniqueConstraints() default {}; }以上属性说明如下:
-
name 表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的“generator”值中;
-
table 表示表生成策略所持久化的表名,例如,这里表使用的是数据库中的“tb_generator”;
-
catalog 属性和 schema属性具体指定表所在的目录名或是数据库模式名;
-
pkColumnName :属性的值表示在持久化表中,该主键生成策略所对应键值的名称。
例如在“tb_generator”中将“gen_name”作为数据库表中主键的键值对的名称;
-
valueColumnName 属性的值表示在持久化表中,该主键当前所生成的值,它的值将会随着每次创建累加。
例如,在“tb_generator”中将“gen_value”作为数据库表中主键的键值对的键值;
-
pkColumnValue 属性的值表示在持久化表中,该生成策略所对应的主键。例如在“tb_generator”表中,将“gen_name”的值为“CUSTOMER_PK”;
-
initialValue 表示主键初始值,默认为0;
-
allocationSize 表示每次主键值增加的大小。例如设置成1,则表示每次创建新记录后自动加1,默认为50;
-
UniqueConstraint 与@Table标记中的用法类似;
-
hibernate 策略
hibernate 提供多种主键生成策略,有点是类似于 JPA,基于 Annotation 的方式通过 @GenericGenerator 注解实现。
@GenericGenerator 注解介绍
源码定义:
@Target({PACKAGE, TYPE, METHOD, FIELD})
@Retention(RUNTIME)
public @interface GenericGenerator { String name(); String strategy(); Parameter[] parameters() default {};
}
以上属性说明如下:
- name 属性指定生成器名称;
- strategy 属性指定具体生成器的类名;
- parameters 得到strategy指定的具体生成器所用到的参数;
hibernate 特有策略
-
native:将主键的生成工作交由数据库完成,hibernate 不管(常用)
对于 oracle 采用 Sequence 方式,对于 MySQL 和 SQL Server 采用 identity(自增主键生成机制)
-
uuid:采用 128 位的 uuid 算法生成主键,uuid 被编码为一个 32 位 16 进制数字的字符串,占用空间大(字符串类型)
-
hilo:使用 hilo 生成策略,要在数据库中建立一张额外的表,默认表名为 hibernate_unique_key,默认字段为 integer 类型,名称是 next_hi(比较少用)
-
assigned:在插入数据的时候主键由程序处理(很常用),这是
<generator>元素没有指定时的默认生成策略。等同于 JPA 中的 AUTO
-
identity:使用 SQL Server 和 MySQL 的自增字段
注意:这个方法不能放到 Oracle 中,Oracle 不支持自增字段,要设定sequence(MySQL 和 SQL Server 中很常用)
等同于 JPA 中的 INDENTITY
-
increment:插入数据的时候 hibernate 会给主键添加一个自增的主键,但是一个 hibernate 实例就维护一个计数器,所以在多个实例运行的时候不能使用这个方法
-
select:使用触发器生成主键(主要用于早期的数据库主键生成机制,少用)
-
sequence:调用底层数据库的序列来生成主键,要设定序列名,不然hibernate无法找到
-
seqhilo:通过 hilo 算法实现,但是主键历史保存在 Sequence 中
适用于支持 Sequence 的数据库,如 Oracle(比较少用)
-
foreign:使用另外一个相关联的对象的主键,通常和
<one-to-one>联合起来使用 -
guid:采用数据库底层的 guid 算法机制
对应 MYSQL 的 uuid() 函数,SQL Server 的 newid() 函数,ORACLE 的rawtohex(sys_guid()) 函数等
-
uuid.hex:看 uuid,建议用 uuid 替换;
-
sequence-identity:sequence 策略的扩展,采用立即检索策略来获取 sequence 值
注意:需要 JDBC3.0 和 JDK4 以上(含1.4)版本
使用示例:
// uuid
@GeneratedValue(generator = "paymentableGenerator")
@GenericGenerator(name = "paymentableGenerator", strategy = "uuid")
// 除以下所列特殊适配格式外,其他策略均采用上面第一种格式
// select
@GeneratedValue(generator = "paymentableGenerator")
@GenericGenerator(name="select", strategy="select", parameters = { @Parameter(name = "key", value = "idstoerung") })
// sequence
@GeneratedValue(generator = "paymentableGenerator")
@GenericGenerator(name = "paymentableGenerator", strategy = "sequence", parameters = { @Parameter(name = "sequence", value = "seq_payablemoney") })
// seqhilo
@GeneratedValue(generator = "paymentableGenerator")
@GenericGenerator(name = "paymentableGenerator", strategy = "seqhilo", parameters = { @Parameter(name = "max_lo", value = "5") })
// foreign
@GeneratedValue(generator = "idGenerator")
@GenericGenerator(name = "idGenerator", strategy = "foreign", parameters = { @Parameter(name = "property", value = "employee") })
// sequence-identity
@GeneratedValue(generator = "paymentableGenerator")
@GenericGenerator(name = "paymentableGenerator", strategy = "sequence-identity",parameters = { @Parameter(name = "sequence", value = "seq_payablemoney") })
对于这些 hibernate 主键生成策略和各自的具体生成器之间的关系,在 org.hibernate.id.IdentifierGeneratorFactory 中指定了:
static { GENERATORS.put("uuid", UUIDHexGenerator.class); GENERATORS.put("hilo", TableHiLoGenerator.class); GENERATORS.put("assigned", Assigned.class); GENERATORS.put("identity", IdentityGenerator.class); GENERATORS.put("select", SelectGenerator.class); GENERATORS.put("sequence", SequenceGenerator.class); GENERATORS.put("seqhilo", SequenceHiLoGenerator.class); GENERATORS.put("increment", IncrementGenerator.class); GENERATORS.put("foreign", ForeignGenerator.class); GENERATORS.put("guid", GUIDGenerator.class); GENERATORS.put("uuid.hex", UUIDHexGenerator.class); //uuid.hex is deprecated GENERATORS.put("sequence-identity", SequenceIdentityGenerator.class);
}
// 上面十二种策略,加上native,hibernate一共默认支持十三种生成策略。
自定义策略
hibernate 每种主键生成策略提供接口 org.hibernate.id.IdentifierGenerator 的实现类,如果要实现自定义的主键生成策略也必须实现此接口。
IdentifierGenerator 提供一个 generate 方法,generate 方法返回产生的主键。
// 源码展示
public interface IdentifierGenerator { public static final String ENTITY_NAME = "entity_name"; public Serializable generate(SessionImplementor session, Object object) throws HibernateException;
}
自定义主键生成策略
-
方式1:自定义类实现 IdentifierGenerator 接口
-
方式2:自定义类继承 hibernate 的主键生成器类(间接实现了 IdentifierGenerator 接口)
示例:
import org.hibernate.HibernateException; import org.hibernate.MappingException; import org.hibernate.engine.spi.SharedSessionContractImplementor; import org.hibernate.id.UUIDHexGenerator; import org.hibernate.service.ServiceRegistry; import org.hibernate.type.Type; import java.io.Serializable; import java.util.Properties;/*** 自定义主键生成策略。实现自己设置ID,同时保留原来的主键生成策略(32位UUID)不变。* 调用的保存方法需为Repository.save()或EntityManager.merge()* 若调用的保存方法为EntityManager.persist(),且传入对象有id值时,仍会报错!*/ public class CustomUUIDGenerator extends UUIDHexGenerator {private String entityName;@Overridepublic void configure(Type type, Properties params, ServiceRegistry serviceRegistry) throws MappingException {entityName = params.getProperty(ENTITY_NAME);if (entityName == null) {throw new MappingException("no entity name");}super.configure(type, params, serviceRegistry);}@Overridepublic Serializable generate(SharedSessionContractImplementor session, Object object) throws HibernateException {Serializable id = session.getEntityPersister(entityName, object).getIdentifier(object, session);if (id != null) {return id;}return super.generate(session, object);} }Entity 实体类中使用
@GeneratedValue(generator = "paymentableGenerator") @GenericGenerator(name = "paymentableGenerator", strategy = "{自定义主键生成策略的全限定类名}") private String id;
Repository 相关注解
Repository 相关注解主要在 SpringDataJpa 的 Repository 中使用。
-
@Query:自定义 JPQL 或原生 Sql 查询,摆脱命名查询的约束
@Query("select u from User u where u.firstname = :firstname") // JPQL User findByLastnameOrFirstname(@Param("lastname") String lastname);@Query(value = "SELECT * FROM USERS WHERE X = ?1", nativeQuery = true) // 原生sql User findByEmailAddress(String X);关于 @**Query **中参数的占位符:
-
方式1:标识符
:参数名可以定义好参数名,赋值时采用 @Param(“参数名”),而不用管顺序。
-
方式2:使用索引下标
?索引值索引值从 1 开始,查询中 ”?X” 个数需要与方法定义的参数个数相一致,并且顺序也要一致。
-
-
@Modifying:DELETE 和 UPDATE 操作必须加上 @modifying 注解,以通知 Spring Data 这是一个 DELETE 或 UPDATE 操作
-
@Transactional:UPDATE 或者 DELETE 操作需要使用事务
-
@Async:异步操作
-
@NoRepositoryBean:避免 Spring 容器为此接口创建实例。
不被Service层直接用到的Repository(如base repository)均应加此声明
可用于定义公共 Repository,并将业务中用到的公共方法抽离到公共Repository中
@NoRepositoryBean public interface BaseRepository<T, ID> {@Modifying@Query("update #{#entityName} set isDelete='N' where id in ?1 ")Integer myUpdateAsNotDeleted(Collection<String> ids); }
相关文章:

JPA 注解及主键生成策略使用指南
JPA 注解 Entity 常用注解 参考:JPA & Spring Data JPA学习与使用小记 指定对象与数据库字段映射时注解的位置:如Id、Column等注解指定Entity的字段与数据库字段对应关系时,注解的位置可以在Field(属性)或Prope…...
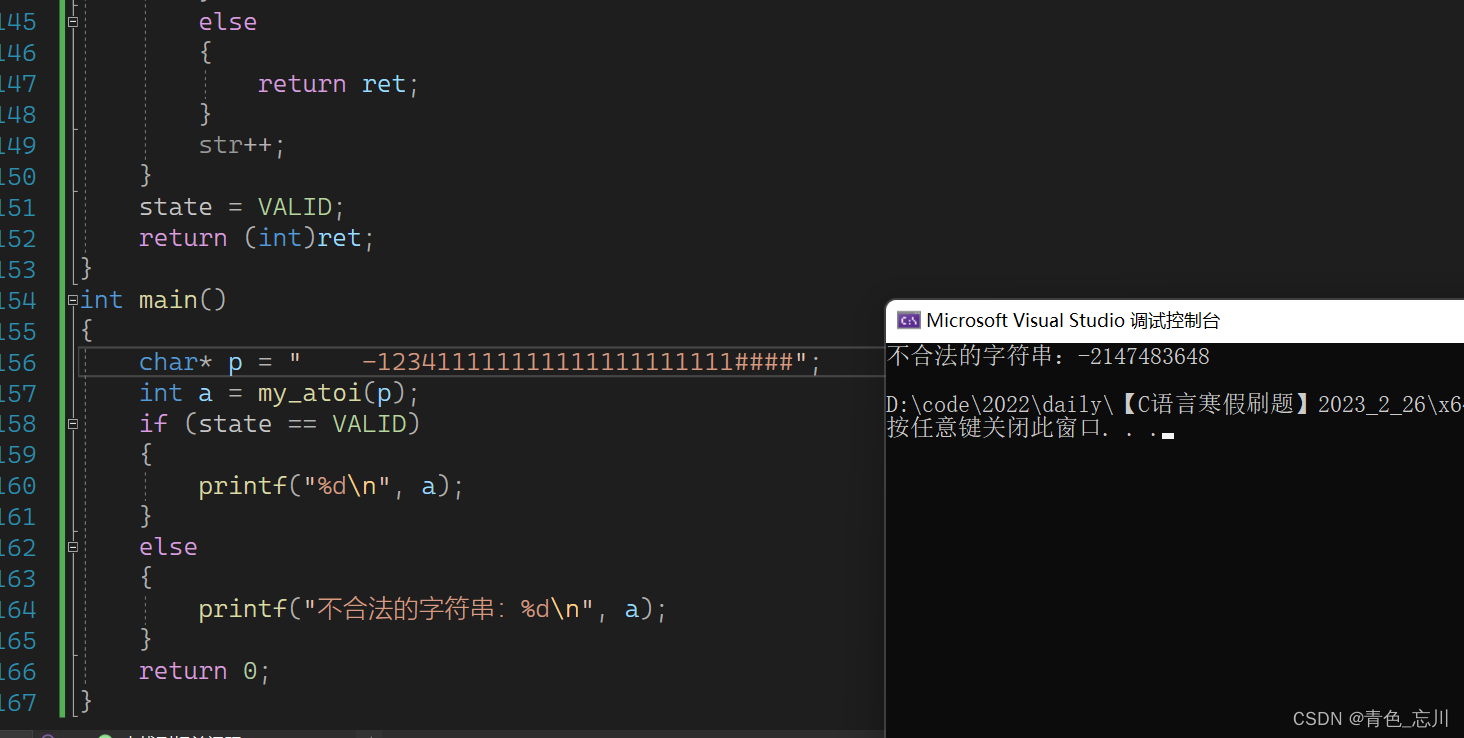
【C语言刷题】找单身狗、模拟实现atoi
目录 一、找单身狗 1.暴力循环法 2.分组异或法 二、模拟实现atoi 1.atoi函数的功能 2.模拟实现atoi 一、找单身狗 题目描述:给定一个数组中只有两个数字是出现一次,其他所有数字都出现了两次。 编写一个函数找出这两个只出现一次的数字。 比如&…...

前端必会面试题指南
计算属性和watch有什么区别?以及它们的运用场景? // 区别computed 计算属性:依赖其它属性值,并且computed的值有缓存,只有它依赖的属性值发生改变,下一次获取computed的值时才会重新计算computed的值。watch 侦听器:…...

C 语言—— 数组
【C 语言】数组1. 概念2. 声明3. 分类4. 初始化5. 赋值6. 附加语法7. VLA 的一些补充1. 概念 数组是存放一组 相同类型 的 有序 数据的一段 连续 空间。 2. 声明 TYPE identifier[static(optional) qualifiers(optional) expression(optional)] TYPE identifier[qualifiers(o…...
Oracle-RAC集群主机重启问题分析
问题背景: 在对一套两节点Oracle RAC19.18集群进行部署时,出现启动数据库实例就会出现主机出现重启的情况,检查发现主机重启是由于节点集群被驱逐导致。 问题: 两节点Oracle RAC19.18集群,启动数据库实例会导致主机出现重启。 问题分析: 主机多次出现…...
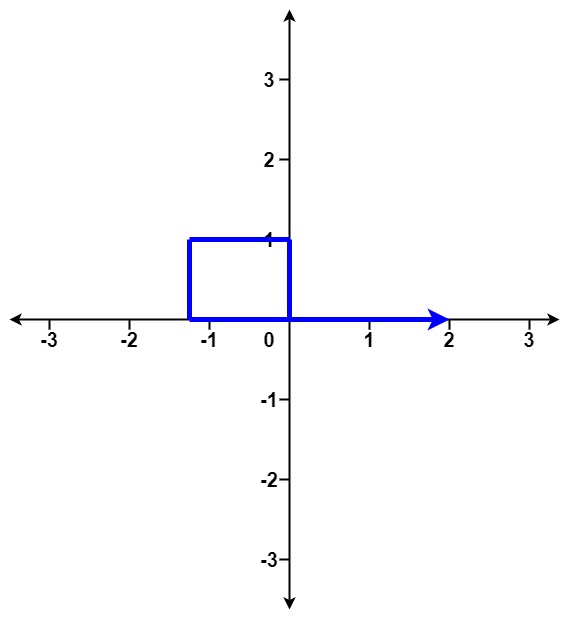
Python每日一练(20230227)
目录 1. 路径交叉 ★★★ 2. 缺失的第一个正数 ★★★ 3. 寻找两个正序数组的中位数 ★★★ 附录 散列表 基本概念 常用方法 1. 路径交叉 给你一个整数数组 distance 。 从 X-Y 平面上的点 (0,0) 开始,先向北移动 distance[0] 米,然后向西移…...

Scratch少儿编程案例-算法练习-存款收益计算
专栏分享 点击跳转=>Unity3D特效百例点击跳转=>案例项目实战源码点击跳转=>游戏脚本-辅助自动化点击跳转=>Android控件全解手册点击跳转=>Scratch编程案例👉关于作者...

【Linux驱动开发100问】Linux驱动开发工程师在面试中常被问到的问题汇总
🥇今日学习目标:什么是Kconfig?如何使用Kconfig? 🤵♂️ 创作者:JamesBin ⏰预计时间:10分钟 🎉个人主页:嵌入式悦翔园个人主页 🍁专栏介绍:Lin…...

每日学术速递2.27
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.CL 1.FiTs: Fine-grained Two-stage Training for Knowledge-aware Question Answering 标题:FiTs:用于知识感知问答的细粒度两阶段训练 作者:Qichen…...

【数据库系统概论】基础知识总结
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...
)
简单移动平均在量化中的应用(附Python实战代码)
在大多数金融产品的投资过程中,均线系统都是很重要的投资参考。一般来说,均线可以近似理解为某段时间内成交筹码的均价,它往往能帮助我们找到合适的支撑位和压力位。随着各种技术流派以及统计学的发展,从简单移动平均中逐渐衍生出了更多的均线计算方式,比如指数移动平均、…...
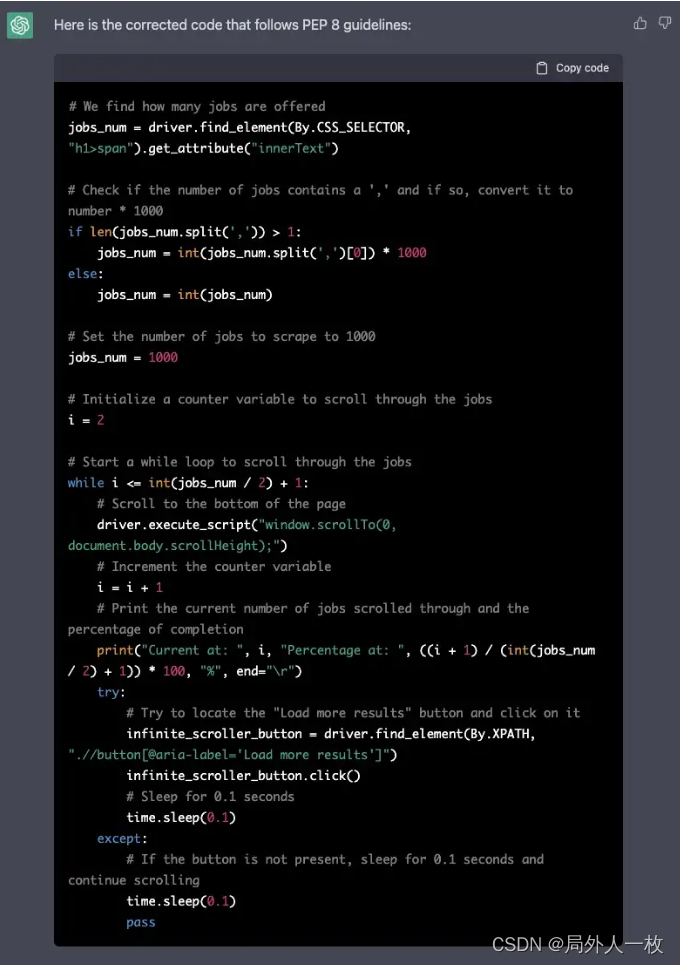
ChatGPT提高你日常工作的五个特点,以及如何使用它来提高代码质量
ChatGPT已经完全改变了代码开发模式。然而,大多数软件开发者和数据专家们仍然不使用ChatGPT来完善——并简化他们的工作。 这就是我们在这里列出提升日常工作效率和质量的5个不同的特点的原因。 让我们一起来看看在日常工作中如何使用他们。 警告:不要…...

spark datasourceV1和v2
datasourceV2 一文理解 Apache Spark DataSource V2 诞生背景及入门实战 https://zhuanlan.zhihu.com/p/83006243 2.3 Data source API v2 https://issues.apache.org/jira/browse/SPARK-15689 Because of the above limitations/issues, the built-in data source impleme…...
10种聚类算法的完整python操作示例
大家好,聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系…...

构建合作伙伴生态系统刻不容缓
合作伙伴关系管理(PRM)系统是否已死?向合作伙伴生态系统的转变将如何改变我们未来管理合作伙伴计划的方式? 自PC革命以来,间接销售和渠道营销一直普遍存在于技术领域,通过其他公司的销售团队和人脉来增加销售,是一种明…...
)
剑指 Offer 55 - I. 二叉树的深度(java解题)
剑指 Offer 55 - I. 二叉树的深度(java解题)1. 题目2. 解题思路3. 数据类型功能函数总结4. java代码1. 题目 输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径&a…...
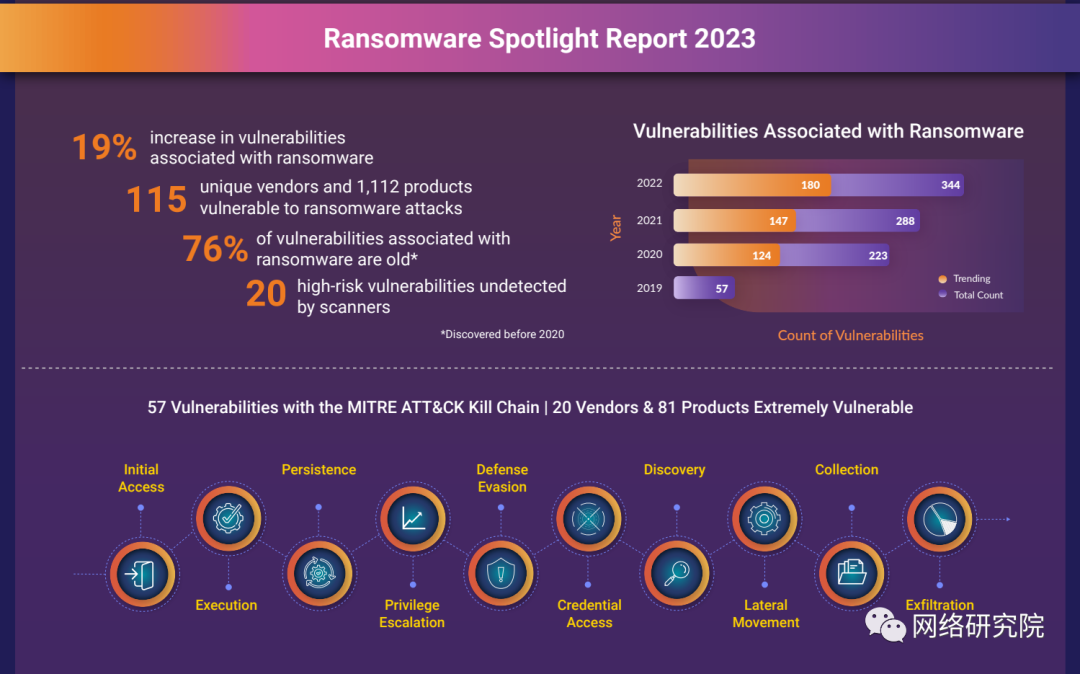
威胁行为者将旧漏洞武器化以发起勒索软件攻击
勒索软件运营商比以往任何时候都更加依赖未打补丁的系统来获得对受害者网络的初始访问权限。 一份新报告显示,攻击者正在互联网和暗网中积极搜索可用于勒索软件攻击的旧漏洞和已知漏洞。 其中许多缺陷已存在多年,对尚未修补或更新易受攻击系统的组织构…...

2023北京健博会/第十届中国国际大健康产博览会
China-DJK北京健博会,立足北京打造国内外大健康产业快速融合发展平台; 大健康时代:20年前没有健康产业,如今健康产业成了全球经济中唯“不缩水”的行业,早已被国际经济学界确定为“无限广阔的兆亿产业”。据机构数据&…...
Python学习笔记之环境搭建
Python学习笔记之环境搭建1. 下载Python2. Windows 安装最新Python3. Linux 安装最新PythonPython是一种编程语言,可以让您更快地工作并更有效地集成系统。 您可以学习使用Python,并立即看到生产力的提高和维护成本的降低。 Python是荷兰程序员吉多范罗苏…...

死锁的总结
哲学家死锁造成的原因:我有你需要的,但你已经有了 饥饿与死锁的区别 死锁一旦发生一定又饥饿现象,但是饥饿现象产生不一定是死锁 历史上对于死锁的声音 死锁的方案 前面两个都是不允许死锁出现 前面都是概念性的东西 后面我们研究如何破坏…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

【Ftrace 专栏】Ftrace 参考博文
ftrace、perf、bcc、bpftrace、ply、simple_perf的使用Ftrace 基本用法Linux 利用 ftrace 分析内核调用如何利用ftrace精确跟踪特定进程调度信息使用 ftrace 进行追踪延迟Linux-培训笔记-ftracehttps://www.kernel.org/doc/html/v4.18/trace/events.htmlhttps://blog.csdn.net/…...
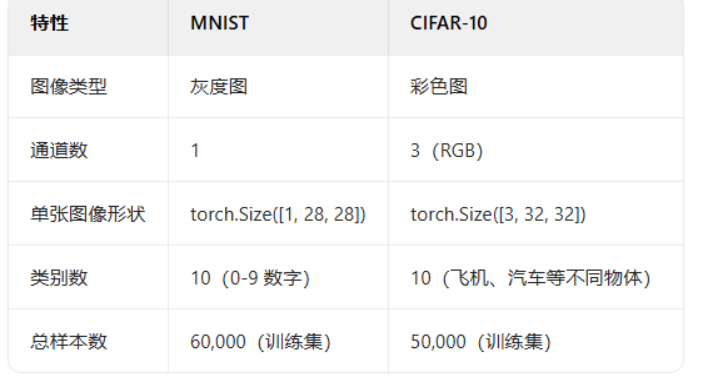
python学习day39
图像数据与显存 知识点回顾 1.图像数据的格式:灰度和彩色数据 2.模型的定义 3.显存占用的4种地方 a.模型参数梯度参数 b.优化器参数 c.数据批量所占显存 d.神经元输出中间状态 4.batchisize和训练的关系 import torch import torchvision import torch.nn as nn imp…...