用Python制作邮件检测器
github地址:
https://github.com/CaLlMeErIC/MailDetective
因为需求需要写一个简单的邮件检测系统的框架,这里记录下思路
首先第一反应,这个检测系统不应该是各个邮件收件系统都有自带的吗,于是搜索了下是否有相关的邮件检测开源软件,发现有两个比较靠谱的:
1.spamassassin
https://spamassassin.apache.org/
2.mmpi
https://github.com/a232319779/mmpi
3.其他一大堆使用机器学习的nlp方法,论文保存在git的misc文件下了
发现实际mmpi比较符合我的需求,但是看了下感觉规则有点少了而且是几年前的,
spamassassin规则很丰富,而且一直在更新,但是也有问题:它的规则很大一部分是根据英文关键词和域名设计的,如果是中文的话需要再做适配,还有就是他的很多规则需要联网或者自定义黑白名单,我的想法是尽量做一个离线也能使用的脚本框架,于是借鉴
spamassassin的方式,把它的正则表达式规则移植过来。它的中心思想是,如果邮件命中了规则的话就给邮件加上对应的报警分数,当分数达到一定阈值的时候就报警。
我是尝试使用了python自带的email包来读取邮件,然后把各个字段以字典的形式保存下来,到时候对应的检测的时候直接检测对应字段即可
import email.header
import os
from email.parser import Parser
import json
import re
from OSutils import loadJsonclass MailReader(object):"""用于读取eml文件,并把各个字段保存下来使用python3.7内置的email包"""def __init__(self, eml_path="", debug=False):"""初始化属性"""self.raw_email = Noneself.email_content = Noneself.process_log = ""self.debug = debugself.attribute_dict = {}self.mail_text = ""self.all_links = []self.urls = []self.tag = set()self.flag = set()if eml_path:self.__MailReader(eml_path)@staticmethoddef decodeHeader(header_str):"""输入需要解码的header字符串,返回解码结果"""temp = email.header.decode_header(header_str)result = email.header.make_header(temp)return resultdef addTag(self, tag):"""给邮件添加标签,以字符串的形式存放在列表中"""self.tag.add(tag)return self.tagdef addFlag(self, flag):"""给邮件添加自定义的检测标记tag用于输出,flag用于规则检测"""self.flag.add(flag)return self.flagdef toString(self):"""打印整个邮件以及日志"""print("email内容:", self.email_content)if self.debug:print("process_log:", self.process_log)return self.email_contentdef toDict(self):"""把header转换为字典形式,From,To,Subject需要单独解码字典的键统一小写"""each_key: strall_str = []if self.attribute_dict != {}:return self.attribute_dictfor each_key in set(self.email_content.keys()):self.attribute_dict.update({each_key.lower(): self.email_content.get_all(each_key)})all_str += self.email_content.get_all(each_key)for each_key in ["From", "To", "Subject"]:temp = []if each_key not in self.attribute_dict:continuefor each_str in self.attribute_dict.get(each_key):each_str = str(self.decodeHeader(each_str))temp.append(each_str)self.attribute_dict.update({each_key.lower(): temp})self.attribute_dict.update({'body': self.getContent()})self.attribute_dict.update({'url': self.getUrls()})self.attribute_dict.update({'all': all_str})return self.attribute_dictdef toJson(self):"""把字典转换为json格式"""if self.attribute_dict == {}:self.attribute_dict = self.toDict()return json.dumps(self.attribute_dict)def __MailReader(self, eml_path):"""读取邮件,有些邮件开头会混入无用字符,需要去除才能提取信息"""try:if os.path.exists(eml_path):with open(eml_path, encoding='utf-8', errors='ignore') as fp:self.raw_email = fp.read()cut_len = 0for each_line in self.raw_email.split('\n'):if ':' not in each_line:cut_len += len(each_line) + 1else:breakif cut_len:self.raw_email = self.raw_email[cut_len:]self.email_content = Parser().parsestr(self.raw_email)except Exception as e:self.process_log += "读取邮件失败:" + str(e)self.toString()return selfdef parseMail(self, eml_path):"""输入邮件路径,用email库整理邮件"""self.attribute_dict = {}return self.__MailReader(eml_path)def getContent(self):"""循环遍历数据块并尝试解码,暂时只处理text数据"""all_content = []for par in self.email_content.walk():if not par.is_multipart(): # 这里要判断是否是multipart,是的话,里面的数据是无用的str_charset = par.get_content_charset(failobj=None) # 当前数据块的编码信息if str_charset is None:self.addTag("没有获取到部分内容的charset")self.addFlag("NO_CHARSET")continuestr_content_type = par.get_content_type()if str_content_type in ('text/plain', 'text/html'):try:content = par.get_payload(decode=True)all_content.append(content.decode(str_charset))except Exception as e:print(e)self.mail_text = all_contentreturn all_contentdef getUrls(self):"""获取所有的url链接,与getLinks不一样的是,getUrls的返回值是一个字符串列表"""if self.urls:return self.urlsself.getLinks()return self.urlsdef getLinks(self):"""通过正则表达式,匹配超链接以及显示的属性内容,格式如下[('https://rashangharper.com/wp-admin/user/welllz/display/login.html', 'wellsfargo.com')]"""if self.all_links:return self.all_linksall_links = []self.urls = []if self.mail_text == "":self.getContent()pattern = '<a.*?href="(.+)".*?>(.*?)</a>'for part in self.mail_text:links = re.findall(pattern, part, re.IGNORECASE)all_links += linksself.all_links = all_linksfor each_link in all_links:self.urls += list(each_link)return all_linksif __name__ == '__main__':a = MailReader("fakeherf.eml").toDict().get('date')[0]
然后是规则设计部分,也是参考spamassassin的规则, 分为简单规则和复杂规则,简单规则,直接用正则表达式检查邮件对应的部分即可

复杂规则的话,我是写成了python类的形式,然后在运行的时候动态加载,放在metarules文件夹里,类似于下面这样的:
class CheckMail(object):"""检查邮件中,From是否和存在的真实发件源不一样"""def __init__(self, input_mail):self.reader = input_mailself.score = 2.5self.description = "检查邮件中,From和存在的真实发件源不一样"@staticmethoddef list2str(data_list):"""把字符串列表转换成字符串"""if isinstance(data_list, list):result = ""for each_str in data_list:result += each_str + " "return result[:-1]return data_listdef getReport(self):"""检测邮件的From字段,option_sender中是几种可能的真实发件人字段"""header_dict = self.reader.toDict()if header_dict.get('from'):mail_from = self.list2str(header_dict.get('from'))else:self.reader.addTag("发件人缺失")return True, [self.score, "未检测到发件人字段"]for option_sender in ["x-mail-from", "return-path", "x-qq-orgsender", "sender"]:if option_sender in header_dict:for each_option_sender in header_dict.get(option_sender):if each_option_sender not in mail_from:self.reader.addTag("疑似伪造的发件人")return True, [self.score, self.description]return False, []
其他内容及readme详见github
相关文章:
用Python制作邮件检测器
github地址: https://github.com/CaLlMeErIC/MailDetective 因为需求需要写一个简单的邮件检测系统的框架,这里记录下思路 首先第一反应,这个检测系统不应该是各个邮件收件系统都有自带的吗,于是搜索了下是否有相关的邮件检测开源软件&#…...

K8S---pod基础概念
目录 一、资源限制 二、Pod 的两种使用方式 三、Pod 资源共享 四、底层容器Pause 1、Pause共享资源 1.1 网络 1.2 存储 1.3 小结 2、Pause主要功能 3、Pod 与 Pause 结构的设计初衷 五、Pod容器的分类 1、基础容器(infrastructure container)…...

激活函数入门学习
本篇文章从外行工科的角度尽量详细剖析激活函数,希望不吝指教! 学习过程如下,先知道这个东西是什么,有什么用处,以及怎么使用它: 1. 为什么使用激活函数 2. 激活函数总类及优缺点 3. 如何选择激活函数 …...

小文智能结合ChatGPT的产业未来
最近几个月,由人工智能实验室OpenAI发布的对话式大型语言模型ChatGPT在国内外各大平台掀起了一阵AI狂潮。短短几天时间,其用户量就突破了百万大关,注册用户之多一度导致服务器爆满。 继AI画图之后,ChatGPT成为了新的顶流…...
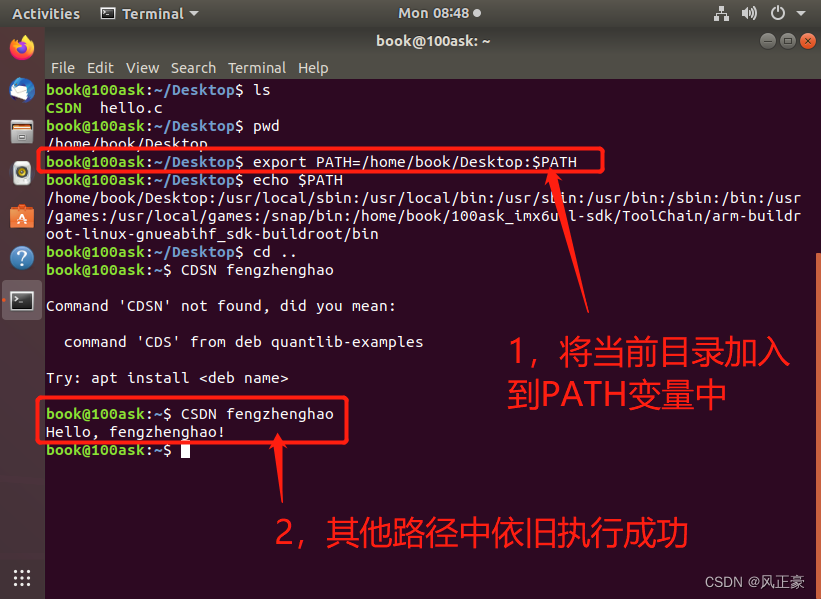
Linux-编写一个自己的命令
前言(1)在Linux中,我们对文件路径进行操作都需要输入命令。那么,有人可能就会有疑惑了,命令是什么东西?我们是否也可以创造出自己的命令呢?答案是可以的。命令本身其实就是可执行文件。但是与普…...

Nacos架构篇 - Distro协议
Distro 它是 Nacos 社区自研的一种 AP 分布式协议(也是最终一致性协议)。它面向临时实例,保证了在某些 Nacos 节点宕机后,整个临时实例处理系统依旧可以正常工作。作为一种有状态的中间件应用的内嵌协议,Distro 保证了…...

和月薪3W的聊过后,才知道自己一直在打杂...
前几天和一个朋友聊面试,他说上个月同时拿到了腾讯和阿里的offer,最后选择了阿里。 我了解了下他的面试过程,就一点,不管是阿里还是腾讯的面试,这个级别的程序员,都会考察项目管理能力,并且权重…...

关于Ubuntu18.04 root账户登录的问题
关于Ubuntu18.04 root账户登录的问题一、 Ubuntu 18.04添加root用户登录1. 设置root用户2. 修改/root/.profile3. 修改/etc/pam.d目录下的gdm-autologin和gdm-password4. 修改50-ubuntu.conf5. 登录root账户二、Ubuntu18.04不能远程使用root账户登录的问题1. 修改sshd_config2.…...
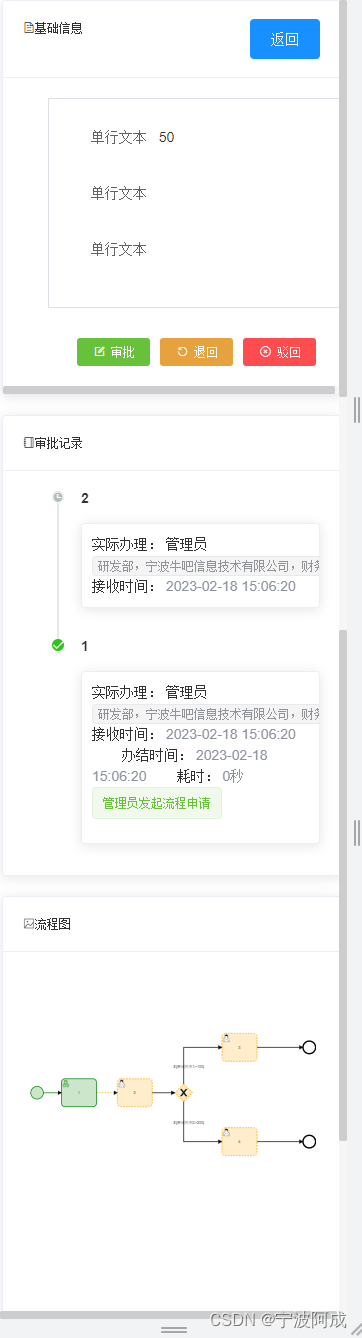
基于jeecgboot的flowable的H5版本在演示系统发布
目前在NBCIO 亿事达企业管理平台上发布了H5的在线演示系统,欢迎大家批评指正。 在nbcio-vue nbcio-vue: NBCIO 亿事达企业管理平台前端代码,基于ant-design-vue-jeecg的前端版本: 3.0.0代码和和flowable6.7.2,初步完成了集流程设…...

【代码训练营】day44 | 完全背包理论 518. 零钱兑换 II 377. 组合总和 Ⅳ
所用代码 java 完全背包 01背包物品只能使用一次 – 倒序遍历 for(i 0; i < weight.length; i){ 物品for (j bagWeight; j > weight[i]; j--){ 背包dp[j] max(dp[j], dp[j-weight[i]] value[i])} }完全背包物品可以使用无限次 – 正序遍历 for(i 0; i < weigh…...
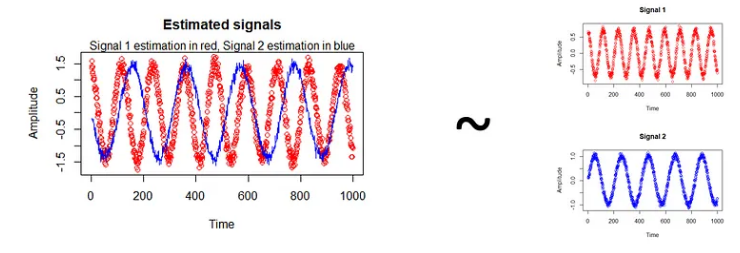
ICA简介:独立成分分析
1. 简介 您是否曾经遇到过这样一种情况:您试图分析一个复杂且高度相关的数据集,却对信息量感到不知所措?这就是独立成分分析 (ICA) 的用武之地。ICA 是数据分析领域的一项强大技术,可让您分离和识别多元数据集中的底层独立来源。 …...

②【Java 组】蓝桥杯省赛真题解析 [振兴中华] [三部排序] 持续更新中...
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ 蓝桥杯真题--持续更新中...一、振兴中华二、三…...

PostgreSql 视图
一、概述 视图(View)本质上是一个存储在数据库中的查询语句。视图本身不包含数据,也被称为虚拟表。 我们在创建视图时给它指定了一个名称,然后可以像表一样对其进行查询。 优势: 不保存数据,节省空间。减少…...
)
【PAT甲级题解记录】1150 Travelling Salesman Problem (25 分)
【PAT甲级题解记录】1150 Travelling Salesman Problem (25 分) 前言 Problem:1150 Travelling Salesman Problem (25 分) Tags:模拟 图的遍历 旅行商问题 Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1150 Travell…...
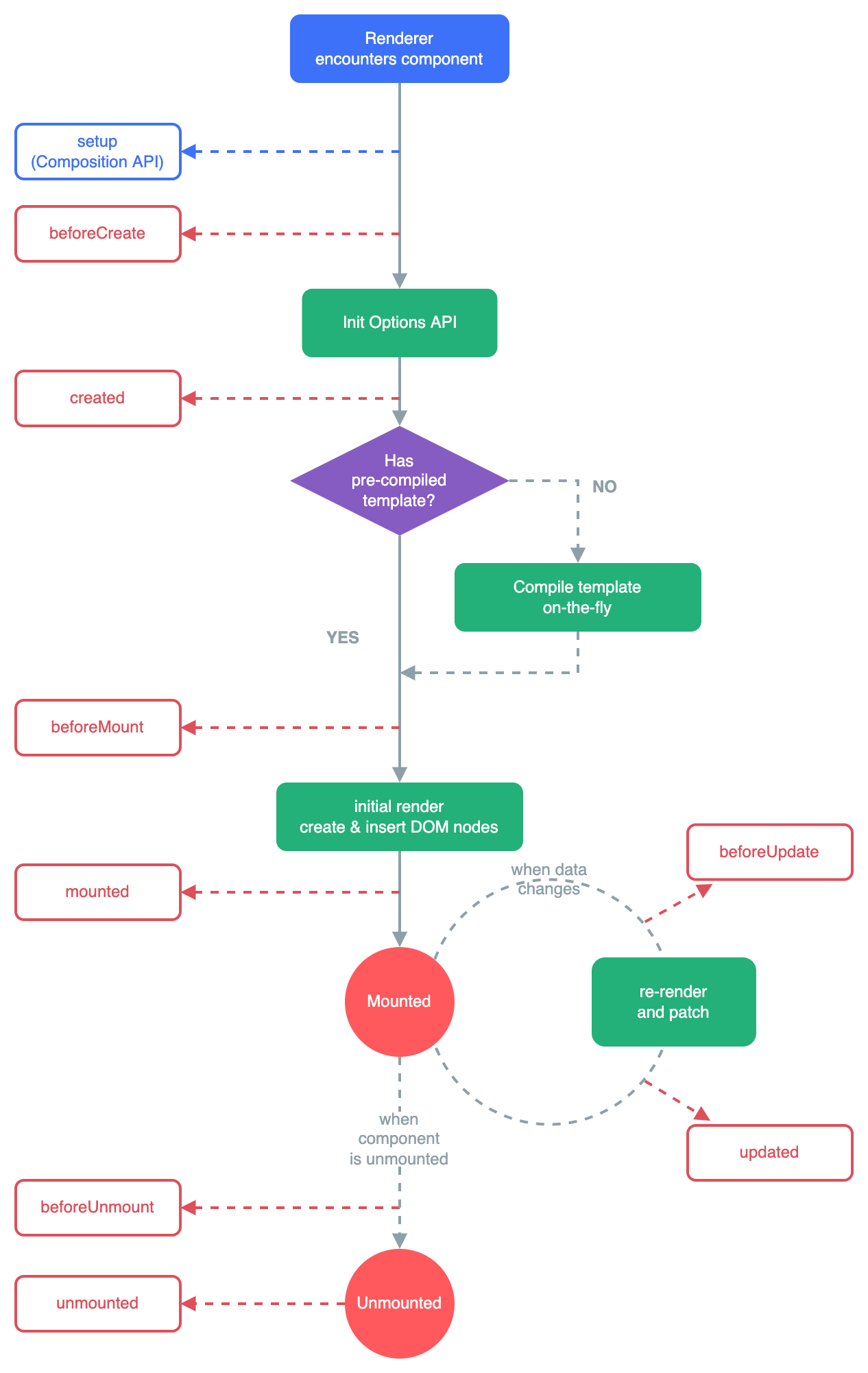
vue生命周期
vue生命周期是什么?Vue生命周期是指vue实例对象从创建之初到销毁的过程,vue所有功能的实现都是围绕其生命周期进行的,在生命周期的不同阶段调用对应的钩子函数可以实现组件数据管理和DOM渲染两大重要功能。我们来看一下官网给的vue生命周期的…...

排查解决Java进程占用内存过高
排查解决Java进程占用内存过高1 在项目部署运行之前1 检查JVM参数设置2 检查代码逻辑3 使用内存分析工具4 检查线程5 调整应用程序的设计7 调整硬件资源2 在项目部署运行之后1 在项目部署运行之前 1 检查JVM参数设置 检查JVM的启动参数设置,包括-Xmx和-Xms参数&am…...
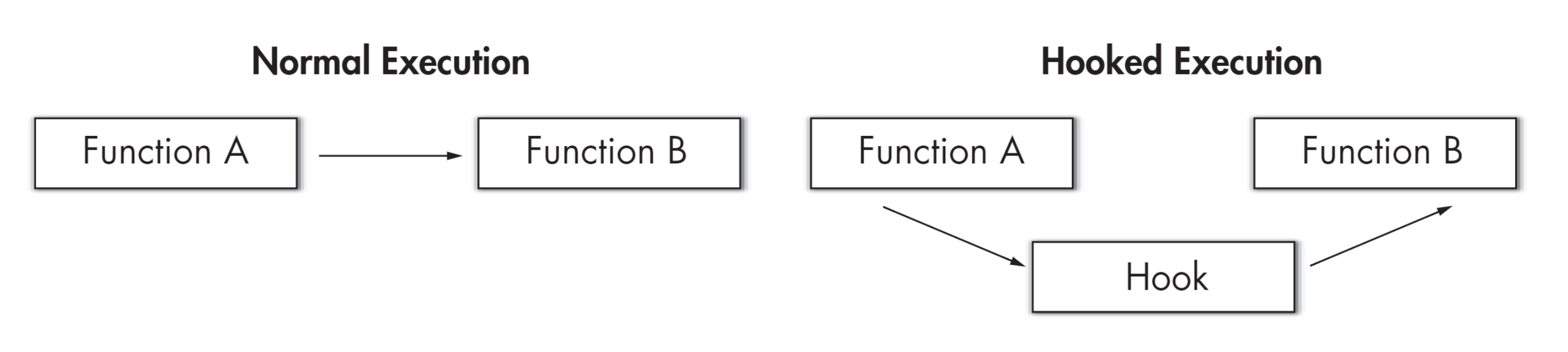
一个基于 LKM 的 Linux 内核级 rootkit 的实现
博客已迁移至:https://gls.show/ GitHub链接 演示Slides overview rootkit是一种恶意软件,攻击者可以在获得 root 或管理员权限后安装它,从而隐藏入侵并保持root权限访问。rootkit可以是用户级的,也可以是内核级的。关于rootk…...

CAN工具 - ValueCAN - 基础介绍(续)
VSpy3(Vehicle Spy 3的简写),作为一个常用的车载总线仿真工具,在车载网络领域也是有非常大的市场,前面也简单介绍过一些简单的功能,今天就再次介绍一些。什么是VSpy3?VSpy3是美国英特佩斯公司下…...
一个Laravel+vue免费开源的基于RABC控制的博客系统
项目介绍 CCENOTE 是一个使用 Vue3 Laravel8 开发的前后端分离的基于RABC权限控制管理的内容管理系统,由于作者本人比较喜欢写作的原因,因此开发了这个项目,后端使用的PHP的Laravel框架,并且整理了数据层与业务层,相…...
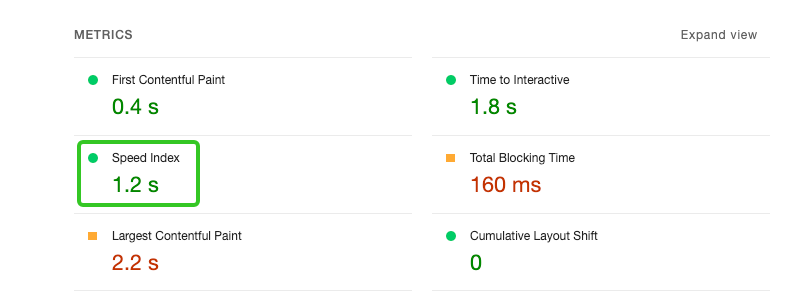
从 B 站出发,用 Chrome devTools performance 分析页面如何渲染
页面是如何渲染的?通常会得到“解析 HTML、css 合成 Render Tree,就可以渲染了”的回答。但是具体都做了些什么,却很少有人细说,我们今天就从 Chrome 的性能工具开始,具体看看一个页面是如何进行渲染的,以及…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...

国产大模型新王登基?Qwen3.7-Max全球第五、编程Agent登顶,千问APP免费体验全攻略
AI前线观察 | 2026.05.25 就在刚刚过去的阿里云峰会上,通义千问甩出了一张“王炸”。万亿参数MoE架构的旗舰模型Qwen3.7-Max正式接入千问APP、PC端及网页端。这不仅仅是一次版本更新,更是国产大模型在权威第三方榜单中首次稳居全球前五、国产第一的里程碑…...
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南
3步高效解决TranslucentTB任务栏透明化难题:完整配置指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否厌倦了Window…...