基于新一代kaldi项目的语音识别应用实例
本文是由郭理勇在第二届SH语音技术研讨会和第七届Kaldi技术交流会上对新一代kaldi项目在学术及“部署”两个方面报告的内容上的整理。如果有误,欢迎指正。
文字整理丨李泱泽
编辑丨语音小管家
喜报:新一代Kaldi团队三篇论文均被语音顶会ICASSP-2023接收
论文链接:
-
Fast and parallel decoding for transducer
https://arxiv.org/abs/2211.00484
-
Delay-penalized transducer for low-latency streaming ASR
https://arxiv.org/abs/2211.00490
-
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
https://arxiv.org/abs/2211.00508

感谢各位对新一代Kaldi社区的关注。今天我主要介绍新一代Kaldi在学术及“部署”两个方面应用实例。“部署”在这里打了引号,是因为部署是一个复杂的系统,25分钟无法很好地描述它。因此今天只有一两页PPT会涉及到它,更多介绍在学术方面的应用。

今天的演讲主要包含以下几个环节,首先是我们项目以及团队的介绍。第二个环节是关于k2的学术应用,第三个环节是模型部署和sherpa子项目的介绍。由于只有25分钟时间,后面Q&A的时间可能不是特别充足,欢迎大家关注我们的公众号,扫码进入交流群。公众号每周五会推送一篇k2的文章,会介绍我们近期的工作和k2论文核心算法的实现。我们非常用心地去准备并且写得非常详细,强烈推荐对新一代Kaldi应用以及核心算法感兴趣的朋友关注我们公众号。

我们团队在小米有一个7人小组,同时也有很多来自开源社区广大工程师的支持。另外 Daniel Povey 教授领衔开发了k2 Lhotse 和 Icefall 项目,数据处理项目是以 Piotr 博士领衔开发。再次感谢广大开源社区工程师的支持。

今天的演讲主要涉及k2项目,熟悉新一代Kaldi项目的同学知道它包含很多子项目(而第一代Kaldi是一个单独的项目)。新一代Kaldi采用项目群的方式有利有弊。先说弊端,有的刚接触的朋友可能会说这项目哪是哪,我怎么一键跑不起来,一会儿要装这个一会儿要装那个。然后好处呢,如果朋友们听完今天的分享,可能会意识到为什么要拆成一个一个子项目,以及拆成子项目的好处。

新一代Kaldi是一个项目群,所以现代Kaldi项目并不完全等同于k2。k2只是其中一个子项目。今天我们主要涉及k2的学术应用。这个截图是k2 官网上截的一个介绍,当时 Dan 哥在写这个介绍时,我其实没有太看懂什么意思,今天我把这个重点标出来。第一段讲的是无缝融合,k2与Pytorch以及状态求导转换机的无缝结合。结合的目的在于可以很容易地修改结合各种不同的损失函数,像这里写到的交叉熵损失函数、CTC损失函数。第二个重点在于Compose函数,如何把一个神经网络的 embedding 转成状态机,转成状态机后,它就可以与很多传统的状态机的状态图去结合计算。我们今天主要针对这两段展开介绍。

这一页ppt是将k2官网首页的愿景翻译成中文。第一个就是Pytorch的无缝融合。既然说到k2 与 Pytorch是无缝融合。我们先来看看原来的缝在哪里。在没有k2的时候,也有很多把状态图的算法实现出来给Pytorch打补丁。早期的时候,我们有一个用pybind11给Kaldi 打包的项目(注:第一代Kaldi 项目中的pybind11分支),它和Pytorch有那么一点点的缝,不像k2那么无缝结合。它的缝在于底层内存分配没有用 torch的Allocator。k2 消除的另一缝在于它关键数据结构和算法都继承了 torch.autograd.Function。熟悉 Pytorch 的朋友可能知道,一旦继承了这个 function 之后,相当于就被 Pytorch 的 outograd graph 图追踪。所以k2的这些函数和Pytorch的自动求到就无缝结合上了。
在无缝结合的基础上,k2另一个愿景是实现很多FSA和FST算法,并且这些算法实现可以高效地运行于显卡之上。整个k2的运算不是在 tensor 维度,而是在 FST 维度。在k2里面有一个函数,它可以把Pytorch的tensor embedding转换为FSA。随后整个计算就转为了一个FSA/FST的操作,一个神经网络的embedding转化为FST/FSA的效果如上页ppt右图所示。这个示意图画的是,如果我有两个时刻,每个时刻有8帧的概率,那么这个 T x C = 2 x 8的这么一个矩阵,它转成FST/FSA后大概就长这个样子。这个也很容易理解,现在就2帧,第一个时刻和第二个时刻之间可以随意跳,第零个时刻和第一个时刻之间也可以随意跳,跳转概率就是每个token自己神经网络对应的概率。
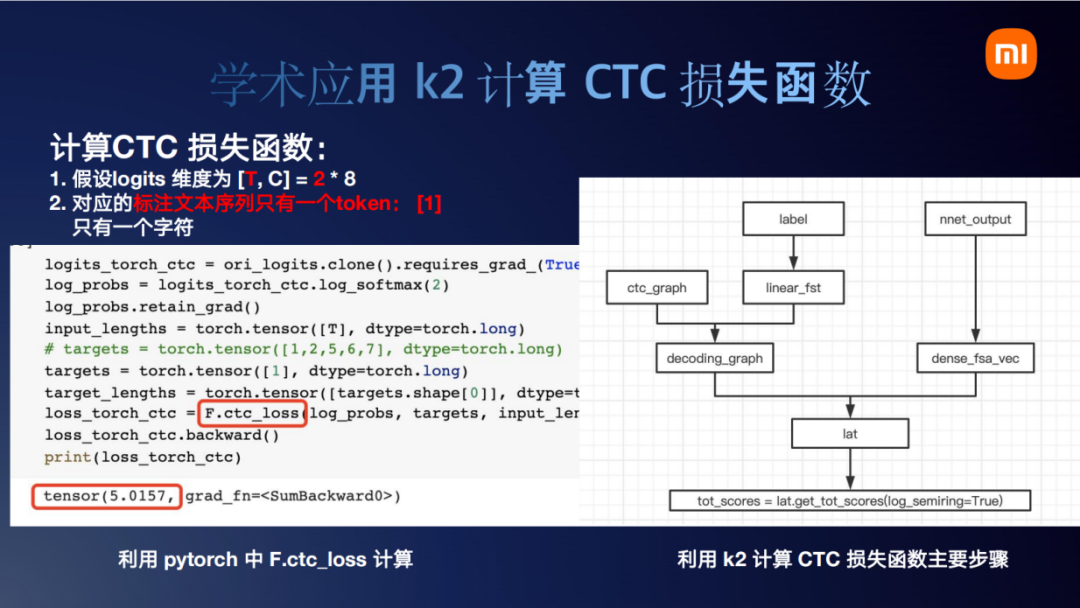
k2要将所有的东西都转换为FST/FSA。接下来我们分析一个应用:k2是如何计算CTC损失函数的。现在假设 logits 也就是神经网络的输出为 2 x 8,标注文本只有一个token。即:两个时刻个logits, 一个tokenn。如果用Pytorch去计算的话,就是左边这个真实的代码,只需要调用 torch.Function.ctc_loss,一行就出来了(结果是5.0157)。如果用k2去实现的话,整个流程大概如右图所示。我们刚才说,k2把所有的概念所有的变量都转换为了FST/FSA。那么看到这个右边,k2计算CTC loss整体分为两大块。首先是左边,左边先处理文本信息label,然后和ctc_graph compose得到decoding_graph(注:逻辑上可以通过compose实现,在实际生产环节,会直接采用更为高效的k2.ctc_graph,“跳过”compose过程)。右边是处理神经网络的输出nnet_output,将它转为dense_fsa_vec,就是我们前一页看的那个图。然后decoding_graph和dense_fsa_vec compose后去做一个lattice,最后lattice再最大score。
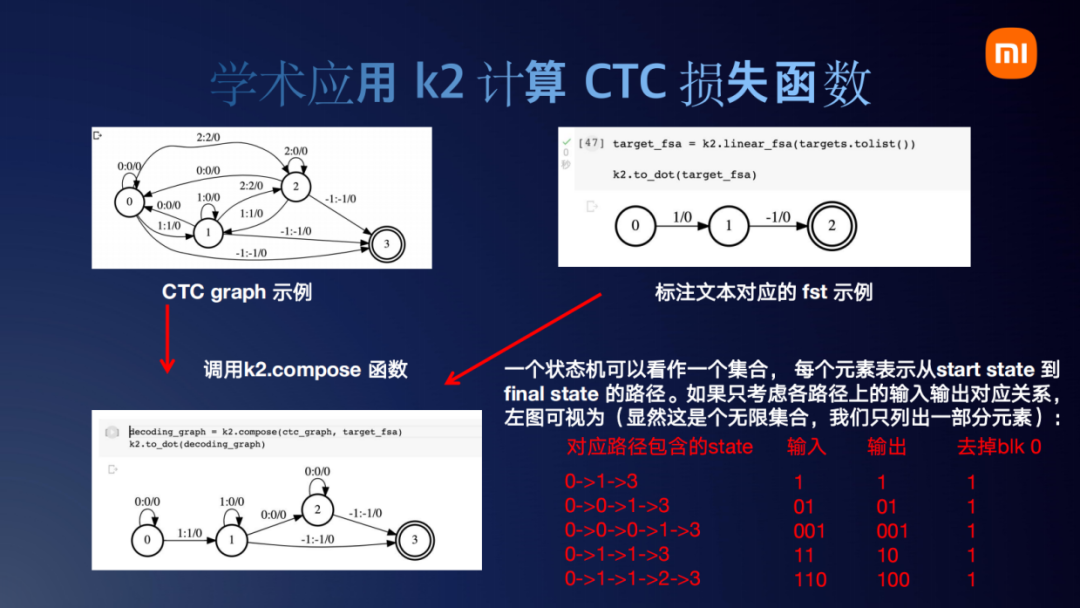
token也就是右上角这个文本对应的fst也很好理解,token就是1,跳一步生成一个1。最后这个-1到0的边,是k2里自定义的一个特殊要求,每一个fst必须以-1结尾,这个不影响我们的理解,所以这个-1我们可以暂时忽略。左边的CTC graph,熟悉CTC的朋友可能知道,一般我们在论文里面画CTC gragh也都是这样画。现在把CTC graph和文本对应的线性序列去做compose的话,它会得到左下角这个图。左下角这个图其实就是表示怎样生成一个token 1。我们解释一下这个图,一个状态机可以看作一个集合,它的每一个状态就是一个路径。首先这个路径无法穷举,因为含有自环。我们就列出来几个,可以看出,无论左下角这个图怎么走,它最后输出的token都是1。所以这页PPT 展示了如果文本标注是一个token 1,它所对应的fst图结构会如左下角所示。
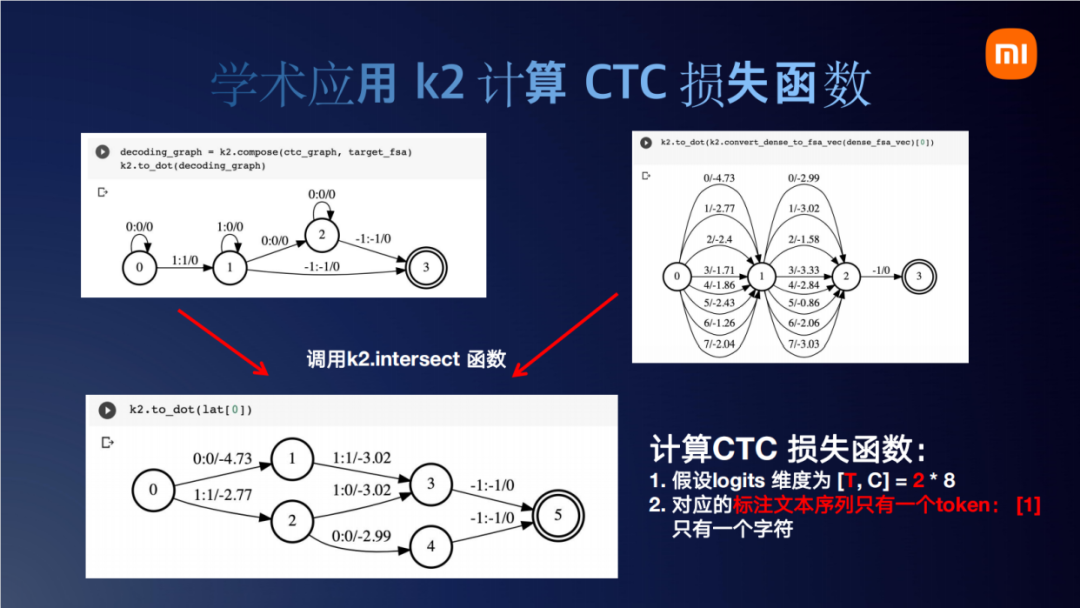
刚才我们将文本处理完了,现在处理神经网络。神经网络会转成这么一个dense_fsa,它和文本token对应的图结构(左上)去做intersect之后,输出左下角这个图。我们大概走一下这个图,比如0到1、1到3,它输出0 1,那么0是一个blank我们不要,相当于输出一个token 1。边上的概率就是从神经网络里拿到的,此时得到这个lattice,可以看到确实只有两个时刻(最后-1对应的边可以忽略)。各个边上的概率就是从神经网络上获取的概率,然后输出的label刚好就是我们文本要求的一个1。

那再对这个lattice做一个tot_score,得到5.0157。这个基于k2的CTC的损失函数结果有三个注意的点,首先它也等于5.0157(和前面torch.Function.ctc_loss结果完全一致)。第二点是,它是一个torch的tensor,这个的意义在于,神经网络的tensor转换为fsa/fst后经过k2的一番操作它还是一个tensor。从这个角度上我们可以说k2和Pytorch是无缝融合的。第三个点在于它有一个grad_fn,如果熟悉Pytorch就知道任何一个tensor只要它有grad_fn,它就可以做backward。
目前位置,我们以基于k2的CTC损失函数为例,解释了一下什么是Pytorch与k2的无缝融合。

明明Pytorch一行就能实现的东西,k2搞得这么复杂化简为繁是不是吃饱了没事干。其实不是,前面的几页PPT都是为接下来的两篇论文做铺垫。

首先我们分享一下英伟达的论文。如同刚开始宝秋总分享的那样,k2项目不只是小米一个团队开源出来的,还有很多开源社区的朋友一起贡献代码。不只是我们的工作值得关注,那些用k2来做研发的很好的一些点也值得大家关注。今天我们分享特意选了两篇不是我们团队的论文,避免大家说我们“王婆卖瓜,自卖自夸”。第一篇是英伟达最近被Interspeech接收的一篇论文。

我们回顾一下,这个就是刚才说的k2计算CTC的主要步骤。这篇论文主要修改了绿色这个点,也就是ctc_graph这一块儿。

看一下论文中的截图,常见的ctc_graph图是图a,论文里提出将这个图改为更简单一点的c、d。总体上来说,改了之后别的流程都不需要动,只需要把绿色这块儿的结构改了,就可以调用k2完成后续的计算。
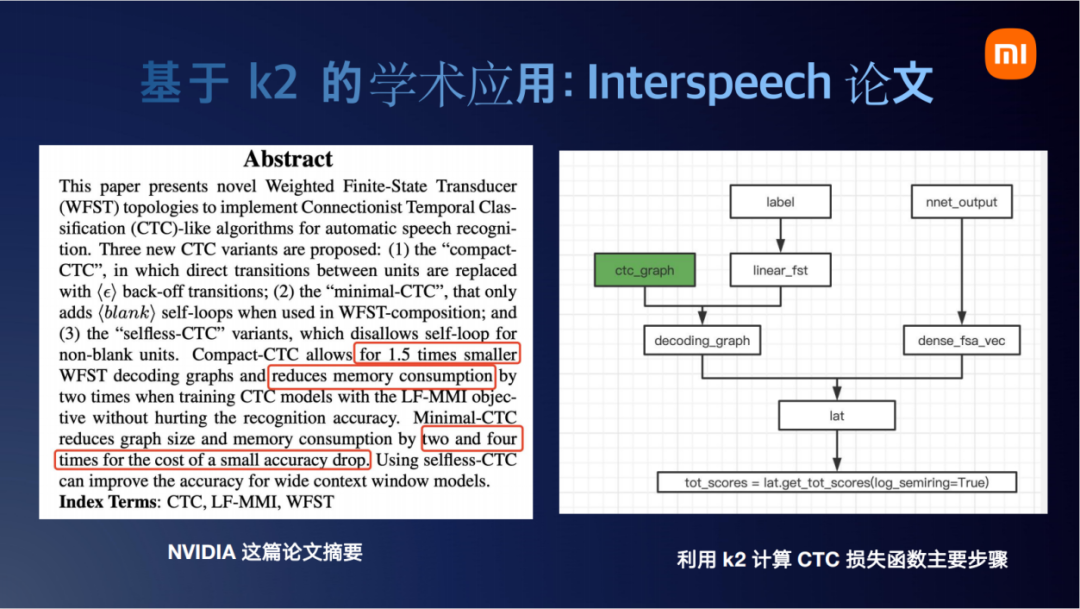
它最终获得的效果是,如果去裁剪一下这个图,不按标准做法去做,去画一个特别小的图,准确率会有一定的损失,但是图的大小和内存占用可以小2到4倍。看到这里,我们就想这篇论文的工作,没有k2也是可以实现的。但是肯定会复杂一点,而且Pytorch CTC也不支持这样的操作。那k2究竟为这项工作带来多大的便利性呢。

我们看一下它的代码实现。这个代码是真实的代码,我直接从英伟达开源项目NVIDIA NeMo里截取出来的。看一下它是如何实现的,为什么说使用k2会给这个论文带来极大的便利性。他们最核心的函数就是我画红框和绿框的这两个,它调用的接口是k2.Fsa.from_str。我们只需要把边的信息写成一行一行的文本文件或者写成string类型。它前面这个构图实际上就写了一个for循环,构建了一个Python的代码。然后再写一个字符串的处理函数,就把这个图构出来了。构出来以后呢,直接就使用k2.Fsa.from_str导入进来。右边这个也是写一个字符串的处理函数去构一个图。构图之后,用k2.Fsa.from_str就把这个图导进来了。导进来之后,对k2来说,无论是标准的CTC拓扑图,还是改进后的拓扑图,或者还是你自己特地设计出来的别的图,只要合法,都能用k2.Fsa.from_str导进来,后续都可以用compose、intersect操作计算出来损失函数。所以说k2的便利性做的特别好。总体上来讲,用户只需要用python 字符串处理程序生成图,后续的操作都可以交给k2来探索不同结构的fst 的效果。

第二篇我们分享北京大学和腾讯基于k2的ICASSP论文,最近被ICASSP接受了。
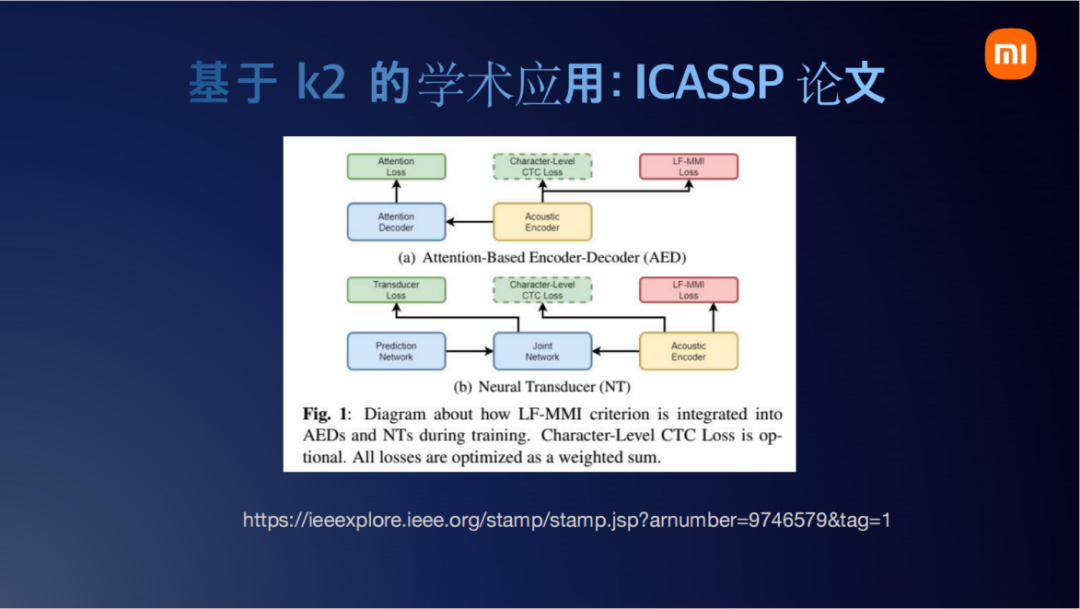
它的工作是在经典的端到端训练框架上加了两个loss。一个是Character-Level CTC Loss,一个是LF-MMI Loss。结合上面那个例子,使用k2来实现这个的话就是天衣无缝了。我们只需要把图导进来,LF-MMI也是一个分子图一个分母图。把图做进来后,剩下的compose和intersect操作k2都是无缝支持的。

他们这里面也提到引入图操作的损失函数,准确率会获得大约4.1%到4.4%的提升。他们这个工作也是基于k2来实现的,也开源了,感兴趣的朋友可以关注一下。

这两篇是友商基于k2实现的论文,可以看一下他们用了大概哪些接口。第一个接口就是k2.Fsa.from_str,我个人感觉,翻译成·白话就是只要你会用Python处理字符串,你就可以构建Fsa的图,导进来后和pytorch无缝结合。from_str()还有一个接口是openfst=True。如果你现在已经有了一个由openfst构建的图,转成字符串后k2也可以识别,可以非常丝滑得导入。k2的图也可以非常丝滑地转成openfst的图。另一个我个人非常推荐的就是k2.to_dot,之前PPT里的都不是我特意去找什么画图工具画的,就是使用的k2.to_dot。可以看到截图里还有代码,调用k2.to_dot(fsa)。如果你在k2里做了一个字符串,想看看画的图对不对,直接就可以所见即所得,所得即所见,非常方便。还有一个函数就是k2.convert_dense_to_fsa_vec,如果想把一个torch的tensor转成fsa,只需要调用这个函数,接下整个fsa操作完成后返回的仍然是torch的tensor。tensor转成fsa之后,剩下的可以调用一系列k2里的工具,你可以用compose、intersect等各种各样的工具去处理它,处理完后返回的tensor与Pytorch无缝衔接,并且可导。
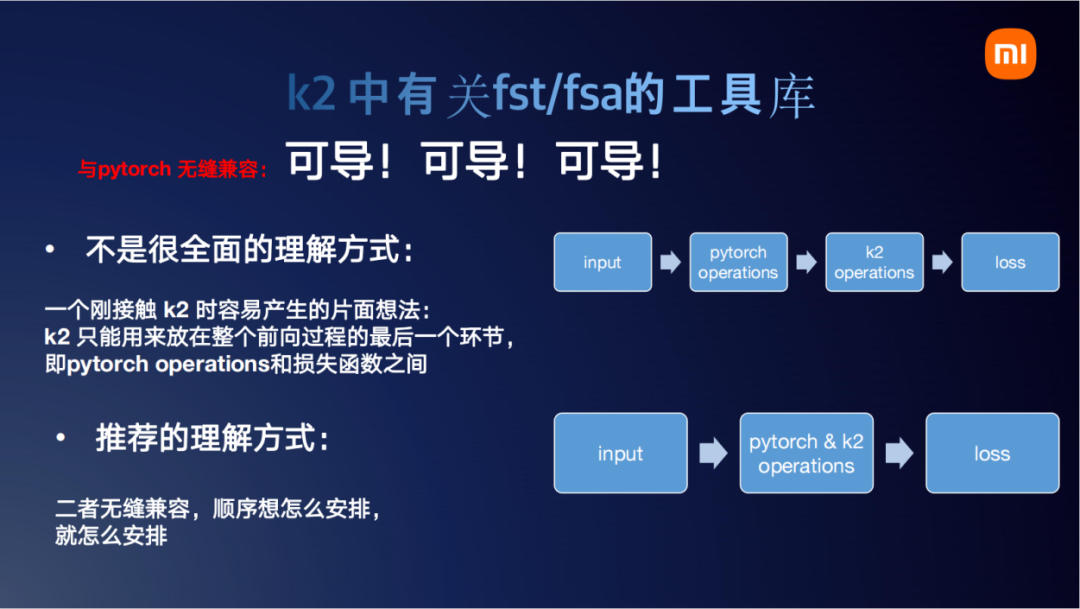
我们继续讲一下Pytorch这个可导该怎么理解。一种我个人感觉不是很全面的理解方式,可能受我们早期kaldi-pybind11的影响,总是觉得k2的函数是不是只能到最后计算损失函数的时候稍微用一下。以前把Pytorch和LF-MMI损失函数结合起来的时候,要把kaldi的LF-MMI函数打包成一个Python的接口。这样的话这个接口只能实现LF-MMI这个函数,别的什么都实现不了。从那个时代过来的朋友可能会有一个误区,觉得k2是不是也这样。input音频,经过Pytorch的transformer、Linear或是什么一大段处理,处理完后再送给k2的一个操作,返回一个loss。事实上这个理解是对的,刚才那两篇论文里也是这么实现的,但不是特别全面。因为我们说Pytorch与k2是完全无缝兼容的,两者的操作完全可以穿插着来。比如我现在有10个函数,第一个函数是Pytorch的函数。那现在我处理完后,我感觉到现在这个环节我需要一个k2的函数把它处理一下,比如k2的regular_tensor之类的去处理一下。那你第二个环节可以去插入一个k2的操作,k2的操作返回一个Pytorch的tensor。那你紧接着由可以在第三个环节插入一个Pytorch,在第四个环节插入一个k2。像三明治一样,一层加一层。我觉得这个可能是Pytorch与k2无缝理解的一种方式。包括我们最近在实现的MWER这样一种损失函数就是穿插着来的,先对神经网络的tensor做一个Pytorch的操作,然后做k2的操作,然后又是Pytorch的操作.....所以说完全无缝兼容。
结合起来,我们回答一个问题,k2是什么或者说k2能用来做什么。我个人感觉是k2提供了各种各样丰富的工具。这个工具究竟有什么用,我们写的时候也不知道这个工具能发挥到多大的威力。比如英伟达那篇论文,看完之后我也感觉很巧妙。当初在设计k2里的那些接口的时候,也没有想到会这么用。但是英伟达他们团队就用很巧妙的思维,找的点非常好,再加上辛苦的实验,做出来这么好的结果。做一个类比的话,k2里的工具就像是乐高的积木。那能用积木块搭成什么样子完全取决于社区广大工程师的思维探索。k2的工具并不会限制我们的能力,不像原来那种对kaldi工具打个包,那你只能用原有的版本,干不了别的。k2的工具是非常丰富的,你想怎么组装就怎么组装,实现什么功能能限制的就只有我们自己的思维了,k2这个工具其实已经完全做好了。再举一个类比的例子,这有点像torch的Linear和Conformer、Transformer之间的关系。像Linear这个结构,一个线性的变化Y = w * X,这个接口很早就出来了。后面就出来很聪明的人,把LInear去搭建这种attetion的qkv结构。这个例子就类似与k2,k2提供了很多的小工具接口,这些接口怎么搭建起来去做实验的一个功能,这个可能就需要一些思维火花。所以我个人建议,有发论文的这种要求的朋友们可以去研究一下k2。把奇思妙想和k2这些现有的工具结合起来,然后为我们学术领域做贡献。

前面pr了一堆友商的论文,我们也介绍一下我们自己的论文。前面有朋友问有没有论文链接,这边也给了链接。第一个就是Puned RNN-T的函数,我个人觉得不那么谦虚地讲可能是地球上最快的RNN-T损失计算方法。第二个就是RNN-T高速并行的解码方法,它可以实现基于CUDA加速,可以多个音频同时解码,并且集成了基于FST的解码图。第三个工作是label delay的控制方法,我们这个方法不仅可以用在RNN-T上也可用在CTC上。第四个引入的Training overhead几乎可以忽略不计的新型蒸馏框架,Dan哥前面有介绍,这边都给出了论文链接。

接下来介绍k2工程部署的工作sherpa。这个图可能画的不是特别的全,因为sherpa这个项目正在不断地发展。但是我们还是希望以这个图尽量把sherpa项目的思想和大概设计展示给大家。第一是我们把这个项目以sherpa为核心分为前端和后端。后端支持k2的解码,包括各种各样的MACE、NCNN、ONNX这些神经网络的引擎。这些引擎驱动的模型或者来自于我们Icefall的训练,或者来自于WeNet的训练,甚至来自于Torchaudio和Espnet的训练。一旦能导成ONNX或者Torchscript的模型,就可以使用sherpa来驱动。Sherpa建立好语音服务的后端引擎后,你可以通过websocket或者HTTP,以及python的前端或者C++前端或者Javascript前端完全无缝地结合起来。解释到这里我还想解释一下为什么新一代kaldi选择用项目组的方式来组建这个项目而不是像kaldi一样单个项目。结合刚才我们两个工作,比如像英伟达和腾讯他们开源的项目都用了k2。从他们论文需求上讲,他们可能只是需要fst或者fsa的操作,他们只需要把k2的子项目去集成到他们整个语音项目里,不需要用我们sherpa、lhotest。另外一块比如说现在有一些公司或者团队他们想用sherpa项目,他们模型的工具可能是他们自己自研的一套。但是不影响,使用sherpa项目只需要把训练的流程转成ONNX或者任意一种sherpa支持的格式,那你就可以用sherpa驱动起来。我觉得这个也可以大概显示出来我们使用项目组,把各个子项目进行解耦管理的优势。

正如Dan哥所说,现场放demo总是可能有风险,再加上时间有限。对我们工作感兴趣的朋友,可以扫码关注一下公众号,也可以加入我们的群。我们尽量做到每周更新。朋友们对新一代kaldi有问题可以在群里面问,我们会写文章去回答,如果这个问题特别好的话。

总结一下今天我们简要的分享主要是分享了两个问题。一个是现代kaldi项目包含很多子项目,k2是其中一个主要用于实现fst和fsa算法的子项目。另一个是我们当前主力研发的sherpa子项目,它是用于部署我们训练所得的模型。

最后热烈欢迎朋友们来关注公众号。
相关文章:
基于新一代kaldi项目的语音识别应用实例
本文是由郭理勇在第二届SH语音技术研讨会和第七届Kaldi技术交流会上对新一代kaldi项目在学术及“部署”两个方面报告的内容上的整理。如果有误,欢迎指正。 文字整理丨李泱泽 编辑丨语音小管家 喜报:新一代Kaldi团队三篇论文均被语音顶会ICASSP-2023接…...
【GO】31.grpc 客户端负载均衡源码分析
这篇文章是记录自己查看客户端grpc负载均衡源码的过程,并没有太详细的讲解,参考价值不大,可以直接跳过,主要给自己看的。一.主要接口:Balancer Resolver1.Balancer定义Resolver定义具体位置为1.grpc源码对解析器(resol…...

PTA L1-058 6翻了(详解)
前言:内容包括:题目,代码实现,大致思路,代码解读 题目: “666”是一种网络用语,大概是表示某人很厉害、我们很佩服的意思。最近又衍生出另一个数字“9”,意思是“6翻了”࿰…...

【Origin科研绘图】如何快速绘制一个折线图 ||【前端特效】爱心篇 之 幸好有你 || 泰坦尼克号——乘客生存与否 预测 || PyCharm使用介绍
🎯作者主页:追光者♂ 🌸个人简介:在读计算机专业硕士研究生、CSDN-人工智能领域新星创作者🏆、2022年CSDN博客之星人工智能领域TOP4🌟、阿里云社区专家博主🏅 【无限进步,一起追光!】 🍎欢迎点赞👍 收藏⭐ 留言📝 🌿本篇,首先是:基于科研绘图工具O…...

一文解读电压放大器(电压放大器原理)
关于电压放大器的科普知识,之前讲过很多,今天为大家汇总一篇文章来详细的讲解电压放大器,希望大家对于电压放大器能有更清晰的认识。电压放大器是什么:电压放大器是一种常用的电子器件,它的主要作用是把输入信号的振幅…...
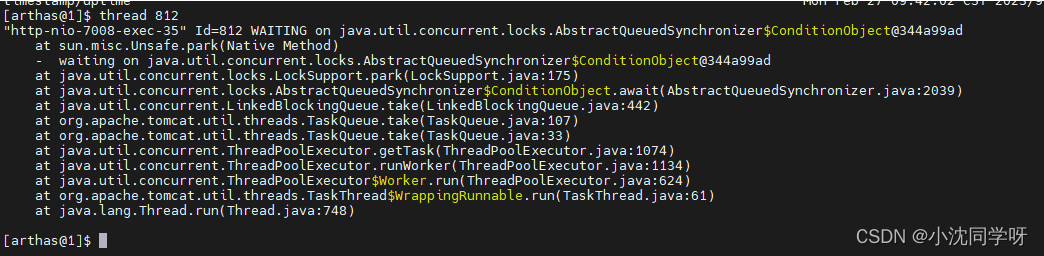
线上监控诊断神器arthas
目录 什么是arthas 常用命令列表 1、dashboard仪表盘 2、heapdump dumpJAVA堆栈快照 3、jvm 4、thread 5、memory 官方文档 安装使用 1、云安装arthas 2、获取需要监控进程ID 3、运行arthas 4、进入仪表盘 5、其他命令使用查看官方文档 什么是arthas arthas是阿…...

@Import注解的原理
此注解是springboot自动注入的关键注解,所以拿出来单独分析一下。 启动类的run方法跟进去最终找到refresh方法; 这里直接看这个org.springframework.context.support.AbstractApplicationContext#refresh方法即可,它下面有一个方法 invoke…...
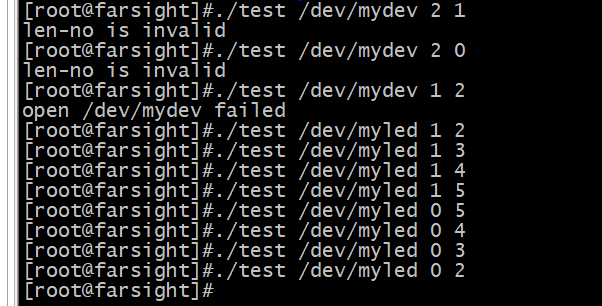
平台总线开发(id和设备树匹配)
目录 一、ID匹配之框架代码 二、ID匹配之led驱动 三、设备树匹配 四、设备树匹配之led驱动 五、一个编写驱动用的宏 一、ID匹配之框架代码 id匹配(可想象成八字匹配):一个驱动可以对应多个设备 ------优先级次低 注意事项…...

TS泛型,原来就这?
一、泛型是什么?有什么作用? 当我们定义一个变量不确定类型的时候有两种解决方式: 使用any 使用any定义时存在的问题:虽然知道传入值的类型但是无法获取函数返回值的类型;另外也失去了ts类型保护的优势 使用泛型 泛型…...
关于算法学习和刷题的建议
大家好,我是方圆。最近花时间学了学算法,应该算是我接触Java以来第一次真正的学习它,这篇帖子我会说一些我对算法学习的理解,当然这仅仅是浅浅的入算法的门,如果想深挖或者是有基础的人想提升自己,我觉得这…...
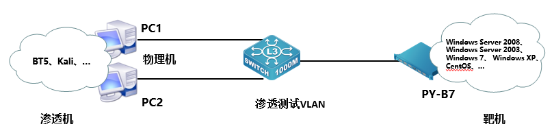
2023年“网络安全”赛项浙江省金华市选拔赛 任务书
2023年“网络安全”赛项浙江省金华市选拔赛 任务书 任务书 一、竞赛时间 共计3小时。 二、竞赛阶段 竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 第一阶段单兵模式系统渗透测试 任务一 Windows操作系统渗透测试 任务二 Linux操作系统渗透测试 任务三 网页渗透 任务四 Linux系统…...

http协议简介
http 1.简介 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。1960年美国人Ted Nelson构思了一种通过计算机处…...

CSDN 第三十一期竞赛题解
第二次参加 总分77.5,主要是在最后一题数据有误,花费了巨量时间… 参加的另一次比赛最后一道题目也出现了一点问题,有点遗憾。 题解 T1:最优利润值 你在读的经营课程上,老师布置了一道作业。在一家公司的日常运营中&…...
)
EM_ASM系列宏定义(emscripten)
2.5 EM_ASM系列宏很多编译器支持在C/C代码直接嵌入汇编代码,Emscripten采用类似的方式,提供了一组以“EM_ASM”为前缀的宏,用于以内联的方式在C/C代码中直接嵌入JavaScript代码。2.5.1 EM_ASMEM_ASM使用很简单,只需要将欲执行的Ja…...

Batchnorm和Layernorm的区别
在深度学习训练中,我们经常会遇到这两个归一化操作,他们之间有什么区别呢?我们来简单介绍一下: BatchNorm: 在深度学习训练的时候我们的数据如果没有经过预处理,有可能会出现梯度消失或者梯度爆炸的情况&…...

高级前端面试题汇总
iframe 有那些优点和缺点? iframe 元素会创建包含另外一个文档的内联框架(即行内框架)。 优点: 用来加载速度较慢的内容(如广告)可以使脚本可以并行下载可以实现跨子域通信 缺点: iframe 会…...
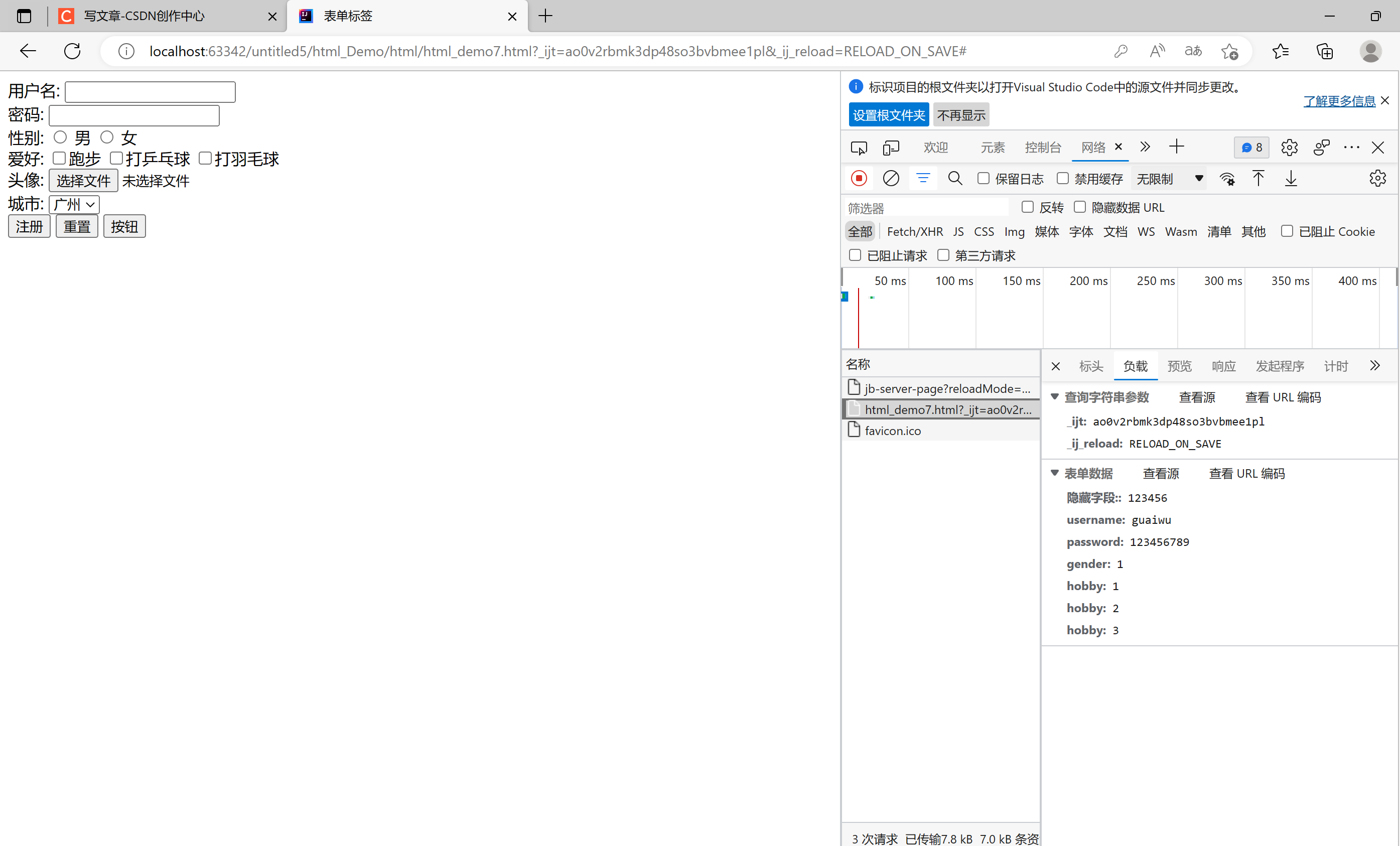
HTML#5表单标签
一. 表单标签介绍表单: 在网页中主要负责数据采集功能,使用<form>标签定义表单表单项: 不同类型的input元素, 下拉列表, 文本域<form> 定义表单<input> 定义表单项,通过typr属性控制输入形式<label> 为表单项定义标注<select> 定义下拉列表<o…...

ONNX可视化与编辑工具
ONNX可视化与编辑工具netrononnx-modifier在模型部署的过程中,需要使用到ONNX模型,下面给大家推荐两个ONNX可视化与编辑工具,其中,netron仅支持模型的可视化,onnx-modifier支持ONNX的可视化与编辑。 netron Netron是…...
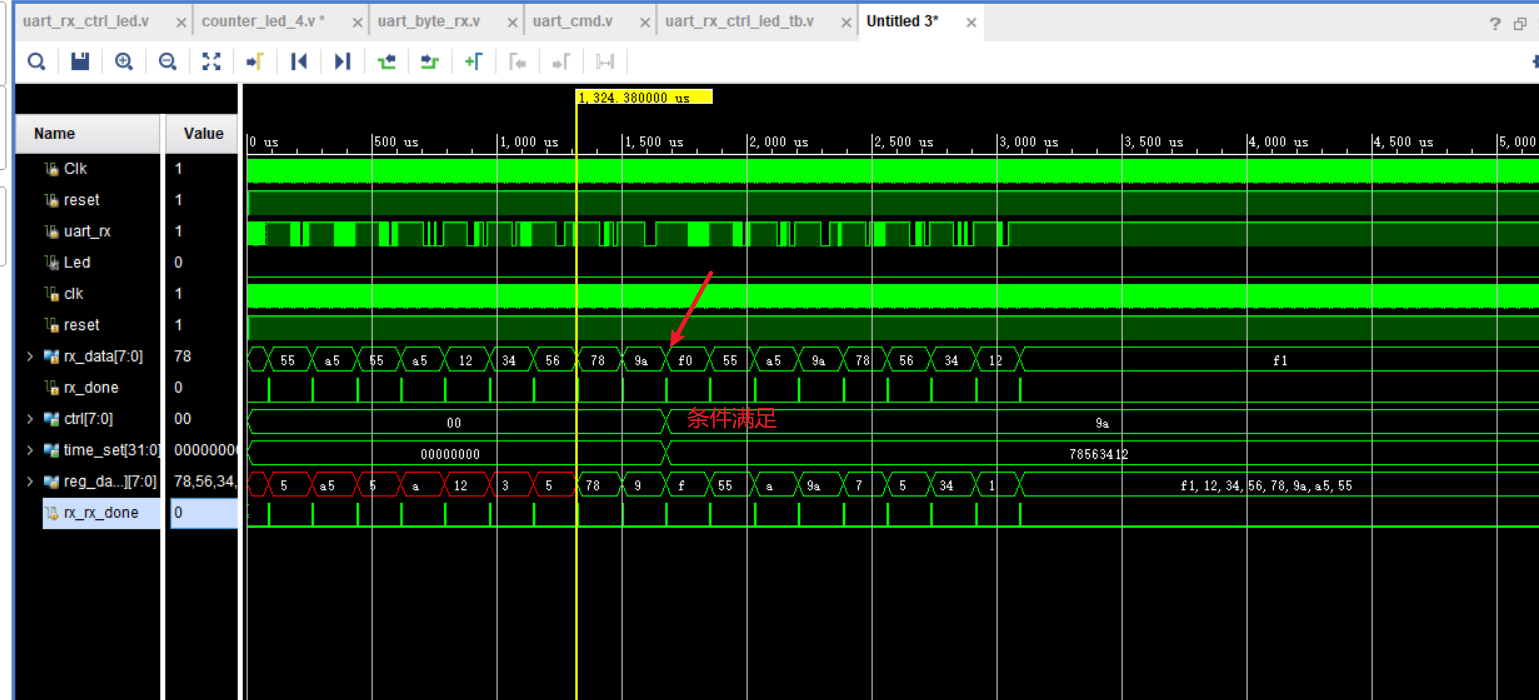
Verilog 学习第五节(串口接收部分)
小梅哥串口部分学习part2 串口通信接收原理串口通信接收程序设计与调试巧用位操作优化串口接收逻辑设计串口接收模块的项目应用案例串口通信接收原理 在采样的时候没有必要一直判断一个clk内全部都是高/低电平,如果采用直接对中间点进行判断的话,很有可能…...
)
AIX系统常见漏洞修复(exec、rlogin、rsh、ftp、telnet远端服务运行中)
漏洞:1.1 SSH 服务支持弱加密算法 1. 使用telnet 登录2.vi /etc/ssh/sshd_config 最后添加一下内容(去掉 arcfour、arcfour128、arcfour256 等弱加密算法) Ciphers aes128-ctr,aes192-ctr,aes256-ctr,aes128-cbc,3des-cbc,blowfish-cbc,cast…...

7个AI论文降重工具实测,改写效果与适用场景解析
AIGC检测功能展示 降AIGC效果 必知!7个AI降重排名,助论文通过 还在为论文查重率发愁?随着学术规范日益严格,查重和AIGC检测成为论文通过的硬性门槛。别担心,AI降重工具来拯救你!经过实测对比,…...

零人类公司编排框架Paperclip的安装
简介 Paperclip 是一个开源的 AI 智能体编排系统,专门用于构建「零人工公司」。它由 Node.js 服务器和 React UI 组成,可以协调多个 AI 智能体(Agent)来运行你的业务。你可以带入自己的 AI 代理,分配目标,并…...

卸灰阀、星型卸料阀、旋转卸料阀cad总装配图纸
卸灰阀、星型卸料阀与旋转卸料阀作为气力输送系统中的核心组件,其设计逻辑与功能定位直接决定了物料的输送效率与系统稳定性。卸灰阀通常安装于储料仓底部,通过阀体开合控制物料下落,其核心作用在于防止仓内气体逆流,避免粉尘外泄…...

DNS解析 HTTP TCP/IP ICMP/NAT/NAPT相关知识点
DNS解析 HTTP TCP/IP ICMP/NAT/NAPT 文章目录DNS解析 HTTP TCP/IP ICMP/NAT/NAPT📌 一、DNS相关面试题答案1. DNS解析过程是怎样的?2. DNS使用的是TCP还是UDP?为什么?3. 什么是DNS缓存污染?如何防止?4. DNS…...

Memos 备忘录的Markdown语法介绍
了解如何使用 Markdown 来格式化你的备忘录,Memos 支持遵循 CommonMark 和 GitHub Flavored Markdown (GFM) 规范的 Markdown 格式。本指南涵盖了最常用的语法。可作为日常速查表文本格式**粗体文本** *斜体文本* ~~删除线~~ 行内代码 结果:粗体文本、斜…...

【AI应用出海】
AI应用出海 商品出海的成功案例通常涉及多方面的策略和技术支持。以下是一些典型案例: 案例1:跨境电商平台 某电商平台利用AI技术优化商品推荐和定价策略,通过分析海外用户行为数据,实现精准营销。该平台在东南亚市场增长迅速&…...

AI写论文宝藏推荐,4款AI论文写作工具让写职称论文如行云流水!
科研人员的AI论文写作利器推荐 对于很多科研人员来说,撰写期刊论文是一件让人十分棘手的事情。面对海量的信息和繁琐的格式要求,加上不断的修改和编辑工作,很多学者常常感到手足无措,效率低下。因此,借助一些AI论文写…...

UG NX 曲率梳分析精要
UG NX 曲率梳分析精要 曲率梳通过梳状图形直观显示曲线上的曲率变化(方向与半径),是分析曲线连续性的核心工具。用户可单选或多选曲线进行分析。 通过曲率梳可判定曲线的四种连续类型: 1. G0(位置连续) 定义…...

Qwen3-VL:30B保姆级教程:星图平台创建实例→Ollama验证→Clawdbot安装→飞书对接全链路
Qwen3-VL:30B保姆级教程:星图平台创建实例→Ollama验证→Clawdbot安装→飞书对接全链路 1. 引言:打造你的专属多模态AI助手 想象一下,你的团队群里发来一张复杂的业务图表,或者一张新产品的设计草图,大家正在热烈讨论…...

AI 人工智能领域主动学习的航空航天应用案例
当AI学会"主动提问":航空航天领域的主动学习实践启示 关键词 主动学习(Active Learning)、航空航天AI、数据稀缺性、查询策略、专家标注、故障诊断、卫星遥感 摘要 在航空航天这样高风险、高精度的领域,AI模型往往面临&…...