高级前端面试题汇总
iframe 有那些优点和缺点?
iframe 元素会创建包含另外一个文档的内联框架(即行内框架)。
优点:
- 用来加载速度较慢的内容(如广告)
- 可以使脚本可以并行下载
- 可以实现跨子域通信
缺点:
- iframe 会阻塞主页面的 onload 事件
- 无法被一些搜索引擎索识别
- 会产生很多页面,不容易管理
代码输出结果
function Foo(){Foo.a = function(){console.log(1);}this.a = function(){console.log(2)}
}Foo.prototype.a = function(){console.log(3);
}Foo.a = function(){console.log(4);
}Foo.a();
let obj = new Foo();
obj.a();
Foo.a();输出结果:4 2 1
解析:
- Foo.a() 这个是调用 Foo 函数的静态方法 a,虽然 Foo 中有优先级更高的属性方法 a,但 Foo 此时没有被调用,所以此时输出 Foo 的静态方法 a 的结果:4
- let obj = new Foo(); 使用了 new 方法调用了函数,返回了函数实例对象,此时 Foo 函数内部的属性方法初始化,原型链建立。
- obj.a() ; 调用 obj 实例上的方法 a,该实例上目前有两个 a 方法:一个是内部属性方法,另一个是原型上的方法。当这两者都存在时,首先查找 ownProperty ,如果没有才去原型链上找,所以调用实例上的 a 输出:2
- Foo.a() ; 根据第2步可知 Foo 函数内部的属性方法已初始化,覆盖了同名的静态方法,所以输出:1
你在工作终于到那些问题,解决方法是什么
经常遇到的问题就是Cannot read property ‘prototype’ of undefined
解决办法通过浏览器报错提示代码定位问题,解决问题Vue项目中遇到视图不更新,方法不执行,埋点不触发等问题
一般解决方案查看浏览器报错,查看代码运行到那个阶段未之行结束,阅读源码以及相关文档等
然后举出来最近开发的项目中遇到的算是两个比较大的问题。代码输出结果
async function async1 () {console.log('async1 start');await new Promise(resolve => {console.log('promise1')})console.log('async1 success');return 'async1 end'
}
console.log('srcipt start')
async1().then(res => console.log(res))
console.log('srcipt end')输出结果如下:
script start
async1 start
promise1
script end这里需要注意的是在async1中await后面的Promise是没有返回值的,也就是它的状态始终是pending状态,所以在await之后的内容是不会执行的,包括async1后面的 .then。
如何解决跨越问题
(1)CORS
下面是MDN对于CORS的定义:
跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头来告诉浏览器 让运行在一个 origin (domain)上的Web应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域HTTP 请求。
CORS需要浏览器和服务器同时支持,整个CORS过程都是浏览器完成的,无需用户参与。因此实现CORS的关键就是服务器,只要服务器实现了CORS请求,就可以跨源通信了。
浏览器将CORS分为简单请求和非简单请求:
简单请求不会触发CORS预检请求。若该请求满足以下两个条件,就可以看作是简单请求:
1)请求方法是以下三种方法之一:
- HEAD
- GET
- POST
2)HTTP的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
若不满足以上条件,就属于非简单请求了。
(1)简单请求过程:
对于简单请求,浏览器会直接发出CORS请求,它会在请求的头信息中增加一个Orign字段,该字段用来说明本次请求来自哪个源(协议+端口+域名),服务器会根据这个值来决定是否同意这次请求。如果Orign指定的域名在许可范围之内,服务器返回的响应就会多出以下信息头:
Access-Control-Allow-Origin: http://api.bob.com // 和Orign一直
Access-Control-Allow-Credentials: true // 表示是否允许发送Cookie
Access-Control-Expose-Headers: FooBar // 指定返回其他字段的值
Content-Type: text/html; charset=utf-8 // 表示文档类型如果Orign指定的域名不在许可范围之内,服务器会返回一个正常的HTTP回应,浏览器发现没有上面的Access-Control-Allow-Origin头部信息,就知道出错了。这个错误无法通过状态码识别,因为返回的状态码可能是200。
在简单请求中,在服务器内,至少需要设置字段:Access-Control-Allow-Origin
(2)非简单请求过程
非简单请求是对服务器有特殊要求的请求,比如请求方法为DELETE或者PUT等。非简单请求的CORS请求会在正式通信之前进行一次HTTP查询请求,称为预检请求。
浏览器会询问服务器,当前所在的网页是否在服务器允许访问的范围内,以及可以使用哪些HTTP请求方式和头信息字段,只有得到肯定的回复,才会进行正式的HTTP请求,否则就会报错。
预检请求使用的请求方法是OPTIONS,表示这个请求是来询问的。他的头信息中的关键字段是Orign,表示请求来自哪个源。除此之外,头信息中还包括两个字段:
- Access-Control-Request-Method:该字段是必须的,用来列出浏览器的CORS请求会用到哪些HTTP方法。
- Access-Control-Request-Headers: 该字段是一个逗号分隔的字符串,指定浏览器CORS请求会额外发送的头信息字段。
服务器在收到浏览器的预检请求之后,会根据头信息的三个字段来进行判断,如果返回的头信息在中有Access-Control-Allow-Origin这个字段就是允许跨域请求,如果没有,就是不同意这个预检请求,就会报错。
服务器回应的CORS的字段如下:
Access-Control-Allow-Origin: http://api.bob.com // 允许跨域的源地址
Access-Control-Allow-Methods: GET, POST, PUT // 服务器支持的所有跨域请求的方法
Access-Control-Allow-Headers: X-Custom-Header // 服务器支持的所有头信息字段
Access-Control-Allow-Credentials: true // 表示是否允许发送Cookie
Access-Control-Max-Age: 1728000 // 用来指定本次预检请求的有效期,单位为秒只要服务器通过了预检请求,在以后每次的CORS请求都会自带一个Origin头信息字段。服务器的回应,也都会有一个Access-Control-Allow-Origin头信息字段。
在非简单请求中,至少需要设置以下字段:
'Access-Control-Allow-Origin'
'Access-Control-Allow-Methods'
'Access-Control-Allow-Headers'减少OPTIONS请求次数:
OPTIONS请求次数过多就会损耗页面加载的性能,降低用户体验度。所以尽量要减少OPTIONS请求次数,可以后端在请求的返回头部添加:Access-Control-Max-Age:number。它表示预检请求的返回结果可以被缓存多久,单位是秒。该字段只对完全一样的URL的缓存设置生效,所以设置了缓存时间,在这个时间范围内,再次发送请求就不需要进行预检请求了。
CORS中Cookie相关问题:
在CORS请求中,如果想要传递Cookie,就要满足以下三个条件:
- 在请求中设置
withCredentials
默认情况下在跨域请求,浏览器是不带 cookie 的。但是我们可以通过设置 withCredentials 来进行传递 cookie.
// 原生 xml 的设置方式
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
// axios 设置方式
axios.defaults.withCredentials = true;- Access-Control-Allow-Credentials 设置为 true
- Access-Control-Allow-Origin 设置为非
*
(2)JSONP
jsonp的原理就是利用<script>标签没有跨域限制,通过<script>标签src属性,发送带有callback参数的GET请求,服务端将接口返回数据拼凑到callback函数中,返回给浏览器,浏览器解析执行,从而前端拿到callback函数返回的数据。
1)原生JS实现:
<script>var script = document.createElement('script');script.type = 'text/javascript';// 传参一个回调函数名给后端,方便后端返回时执行这个在前端定义的回调函数script.src = 'http://www.domain2.com:8080/login?user=admin&callback=handleCallback';document.head.appendChild(script);// 回调执行函数function handleCallback(res) {alert(JSON.stringify(res));}</script>服务端返回如下(返回时即执行全局函数):
handleCallback({"success": true, "user": "admin"})2)Vue axios实现:
this.$http = axios;
this.$http.jsonp('http://www.domain2.com:8080/login', {params: {},jsonp: 'handleCallback'
}).then((res) => {console.log(res);
})后端node.js代码:
var querystring = require('querystring');
var http = require('http');
var server = http.createServer();
server.on('request', function(req, res) {var params = querystring.parse(req.url.split('?')[1]);var fn = params.callback;// jsonp返回设置res.writeHead(200, { 'Content-Type': 'text/javascript' });res.write(fn + '(' + JSON.stringify(params) + ')');res.end();
});
server.listen('8080');
console.log('Server is running at port 8080...');JSONP的缺点:
- 具有局限性, 仅支持get方法
- 不安全,可能会遭受XSS攻击
(3)postMessage 跨域
postMessage是HTML5 XMLHttpRequest Level 2中的API,且是为数不多可以跨域操作的window属性之一,它可用于解决以下方面的问题:
- 页面和其打开的新窗口的数据传递
- 多窗口之间消息传递
- 页面与嵌套的iframe消息传递
- 上面三个场景的跨域数据传递
用法:postMessage(data,origin)方法接受两个参数:
- data: html5规范支持任意基本类型或可复制的对象,但部分浏览器只支持字符串,所以传参时最好用JSON.stringify()序列化。
- origin: 协议+主机+端口号,也可以设置为"*“,表示可以传递给任意窗口,如果要指定和当前窗口同源的话设置为”/"。
1)a.html:(domain1.com/a.html)
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display:none;"></iframe>
<script> var iframe = document.getElementById('iframe'); iframe.onload = function() { var data = { name: 'aym'}; // 向domain2传送跨域数据iframe.contentWindow.postMessage(JSON.stringify(data), 'http://www.domain2.com'); }; // 接受domain2返回数据window.addEventListener('message', function(e) { alert('data from domain2 ---> ' + e.data); }, false);
</script>2)b.html:(domain2.com/b.html)
<script>// 接收domain1的数据window.addEventListener('message', function(e) {alert('data from domain1 ---> ' + e.data);var data = JSON.parse(e.data);if (data) {data.number = 16;// 处理后再发回domain1window.parent.postMessage(JSON.stringify(data), 'http://www.domain1.com');}}, false);
</script>(4)nginx代理跨域
nginx代理跨域,实质和CORS跨域原理一样,通过配置文件设置请求响应头Access-Control-Allow-Origin…等字段。
1)nginx配置解决iconfont跨域
浏览器跨域访问js、css、img等常规静态资源被同源策略许可,但iconfont字体文件(eot|otf|ttf|woff|svg)例外,此时可在nginx的静态资源服务器中加入以下配置。
location / {add_header Access-Control-Allow-Origin *;
}2)nginx反向代理接口跨域
跨域问题:同源策略仅是针对浏览器的安全策略。服务器端调用HTTP接口只是使用HTTP协议,不需要同源策略,也就不存在跨域问题。
实现思路:通过Nginx配置一个代理服务器域名与domain1相同,端口不同)做跳板机,反向代理访问domain2接口,并且可以顺便修改cookie中domain信息,方便当前域cookie写入,实现跨域访问。
nginx具体配置:
#proxy服务器
server {listen 81;server_name www.domain1.com;location / {proxy_pass http://www.domain2.com:8080; #反向代理proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie里域名index index.html index.htm;# 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用add_header Access-Control-Allow-Origin http://www.domain1.com; #当前端只跨域不带cookie时,可为*add_header Access-Control-Allow-Credentials true;}
}(5)nodejs 中间件代理跨域
node中间件实现跨域代理,原理大致与nginx相同,都是通过启一个代理服务器,实现数据的转发,也可以通过设置cookieDomainRewrite参数修改响应头中cookie中域名,实现当前域的cookie写入,方便接口登录认证。
1)非vue框架的跨域 使用node + express + http-proxy-middleware搭建一个proxy服务器。
- 前端代码:
var xhr = new XMLHttpRequest();
// 前端开关:浏览器是否读写cookie
xhr.withCredentials = true;
// 访问http-proxy-middleware代理服务器
xhr.open('get', 'http://www.domain1.com:3000/login?user=admin', true);
xhr.send();- 中间件服务器代码:
var express = require('express');
var proxy = require('http-proxy-middleware');
var app = express();
app.use('/', proxy({// 代理跨域目标接口target: 'http://www.domain2.com:8080',changeOrigin: true,// 修改响应头信息,实现跨域并允许带cookieonProxyRes: function(proxyRes, req, res) {res.header('Access-Control-Allow-Origin', 'http://www.domain1.com');res.header('Access-Control-Allow-Credentials', 'true');},// 修改响应信息中的cookie域名cookieDomainRewrite: 'www.domain1.com' // 可以为false,表示不修改
}));
app.listen(3000);
console.log('Proxy server is listen at port 3000...');2)vue框架的跨域
node + vue + webpack + webpack-dev-server搭建的项目,跨域请求接口,直接修改webpack.config.js配置。开发环境下,vue渲染服务和接口代理服务都是webpack-dev-server同一个,所以页面与代理接口之间不再跨域。
webpack.config.js部分配置:
module.exports = {entry: {},module: {},...devServer: {historyApiFallback: true,proxy: [{context: '/login',target: 'http://www.domain2.com:8080', // 代理跨域目标接口changeOrigin: true,secure: false, // 当代理某些https服务报错时用cookieDomainRewrite: 'www.domain1.com' // 可以为false,表示不修改}],noInfo: true}
}(6)document.domain + iframe跨域
此方案仅限主域相同,子域不同的跨域应用场景。实现原理:两个页面都通过js强制设置document.domain为基础主域,就实现了同域。
1)父窗口:(domain.com/a.html)
<iframe id="iframe" src="http://child.domain.com/b.html"></iframe>
<script>document.domain = 'domain.com'; var user = 'admin';
</script>1)子窗口:(child.domain.com/a.html)
<script>document.domain = 'domain.com';// 获取父窗口中变量console.log('get js data from parent ---> ' + window.parent.user);
</script>(7)location.hash + iframe跨域
实现原理:a欲与b跨域相互通信,通过中间页c来实现。 三个页面,不同域之间利用iframe的location.hash传值,相同域之间直接js访问来通信。
具体实现:A域:a.html -> B域:b.html -> A域:c.html,a与b不同域只能通过hash值单向通信,b与c也不同域也只能单向通信,但c与a同域,所以c可通过parent.parent访问a页面所有对象。
1)a.html:(domain1.com/a.html)
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display:none;"></iframe>
<script>var iframe = document.getElementById('iframe'); // 向b.html传hash值setTimeout(function() { iframe.src = iframe.src + '#user=admin'; }, 1000); // 开放给同域c.html的回调方法function onCallback(res) { alert('data from c.html ---> ' + res); }
</script>2)b.html:(.domain2.com/b.html)
<iframe id="iframe" src="http://www.domain1.com/c.html" style="display:none;"></iframe>
<script>var iframe = document.getElementById('iframe');// 监听a.html传来的hash值,再传给c.htmlwindow.onhashchange = function () {iframe.src = iframe.src + location.hash;};
</script><script>// 监听b.html传来的hash值window.onhashchange = function () {// 再通过操作同域a.html的js回调,将结果传回window.parent.parent.onCallback('hello: ' + location.hash.replace('#user=', ''));};
</script>(8)window.name + iframe跨域
window.name属性的独特之处:name值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
1)a.html:(domain1.com/a.html)
var proxy = function(url, callback) {var state = 0;var iframe = document.createElement('iframe');// 加载跨域页面iframe.src = url;// onload事件会触发2次,第1次加载跨域页,并留存数据于window.nameiframe.onload = function() {if (state === 1) {// 第2次onload(同域proxy页)成功后,读取同域window.name中数据callback(iframe.contentWindow.name);destoryFrame();} else if (state === 0) {// 第1次onload(跨域页)成功后,切换到同域代理页面iframe.contentWindow.location = 'http://www.domain1.com/proxy.html';state = 1;}};document.body.appendChild(iframe);// 获取数据以后销毁这个iframe,释放内存;这也保证了安全(不被其他域frame js访问)function destoryFrame() {iframe.contentWindow.document.write('');iframe.contentWindow.close();document.body.removeChild(iframe);}
};
// 请求跨域b页面数据
proxy('http://www.domain2.com/b.html', function(data){alert(data);
});2)proxy.html:(domain1.com/proxy.html)
中间代理页,与a.html同域,内容为空即可。
3)b.html:(domain2.com/b.html)
<script> window.name = 'This is domain2 data!';
</script>通过iframe的src属性由外域转向本地域,跨域数据即由iframe的window.name从外域传递到本地域。这个就巧妙地绕过了浏览器的跨域访问限制,但同时它又是安全操作。
(9)WebSocket协议跨域
WebSocket protocol是HTML5一种新的协议。它实现了浏览器与服务器全双工通信,同时允许跨域通讯,是server push技术的一种很好的实现。
原生WebSocket API使用起来不太方便,我们使用Socket.io,它很好地封装了webSocket接口,提供了更简单、灵活的接口,也对不支持webSocket的浏览器提供了向下兼容。
1)前端代码:
<div>user input:<input type="text"></div>
<script src="https://cdn.bootcss.com/socket.io/2.2.0/socket.io.js"></script>
<script>
var socket = io('http://www.domain2.com:8080');
// 连接成功处理
socket.on('connect', function() { // 监听服务端消息socket.on('message', function(msg) { console.log('data from server: ---> ' + msg); }); // 监听服务端关闭socket.on('disconnect', function() { console.log('Server socket has closed.'); });});
document.getElementsByTagName('input')[0].onblur = function() { socket.send(this.value);};
</script>2)Nodejs socket后台:
var http = require('http');
var socket = require('socket.io');
// 启http服务
var server = http.createServer(function(req, res) {res.writeHead(200, {'Content-type': 'text/html'});res.end();
});
server.listen('8080');
console.log('Server is running at port 8080...');
// 监听socket连接
socket.listen(server).on('connection', function(client) {// 接收信息client.on('message', function(msg) {client.send('hello:' + msg);console.log('data from client: ---> ' + msg);});// 断开处理client.on('disconnect', function() {console.log('Client socket has closed.'); });
});代码输出结果
function runAsync (x) {const p = new Promise(r => setTimeout(() => r(x, console.log(x)), 1000))return p
}
Promise.race([runAsync(1), runAsync(2), runAsync(3)]).then(res => console.log('result: ', res)).catch(err => console.log(err))输出结果如下:
1
'result: ' 1
2
3then只会捕获第一个成功的方法,其他的函数虽然还会继续执行,但是不是被then捕获了。
参考 前端进阶面试题详细解答
代码输出问题
function fun(n, o) {console.log(o)return {fun: function(m){return fun(m, n);}};
}
var a = fun(0); a.fun(1); a.fun(2); a.fun(3);
var b = fun(0).fun(1).fun(2).fun(3);
var c = fun(0).fun(1); c.fun(2); c.fun(3);输出结果:
undefined 0 0 0
undefined 0 1 2
undefined 0 1 1这是一道关于闭包的题目,对于fun方法,调用之后返回的是一个对象。我们知道,当调用函数的时候传入的实参比函数声明时指定的形参个数要少,剩下的形参都将设置为undefined值。所以 console.log(o); 会输出undefined。而a就是是fun(0)返回的那个对象。也就是说,函数fun中参数 n 的值是0,而返回的那个对象中,需要一个参数n,而这个对象的作用域中没有n,它就继续沿着作用域向上一级的作用域中寻找n,最后在函数fun中找到了n,n的值是0。了解了这一点,其他运算就很简单了,以此类推。
HTTP 1.0 和 HTTP 1.1 之间有哪些区别?
HTTP 1.0和 HTTP 1.1 有以下区别:
- 连接方面,http1.0 默认使用非持久连接,而 http1.1 默认使用持久连接。http1.1 通过使用持久连接来使多个 http 请求复用同一个 TCP 连接,以此来避免使用非持久连接时每次需要建立连接的时延。
- 资源请求方面,在 http1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,http1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- 缓存方面,在 http1.0 中主要使用 header 里的 If-Modified-Since、Expires 来做为缓存判断的标准,http1.1 则引入了更多的缓存控制策略,例如 Etag、If-Unmodified-Since、If-Match、If-None-Match 等更多可供选择的缓存头来控制缓存策略。
- http1.1 中新增了 host 字段,用来指定服务器的域名。http1.0 中认为每台服务器都绑定一个唯一的 IP 地址,因此,请求消息中的 URL 并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机,并且它们共享一个IP地址。因此有了 host 字段,这样就可以将请求发往到同一台服务器上的不同网站。
- http1.1 相对于 http1.0 还新增了很多请求方法,如 PUT、HEAD、OPTIONS 等。
如何防御 XSS 攻击?
可以看到XSS危害如此之大, 那么在开发网站时就要做好防御措施,具体措施如下:
- 可以从浏览器的执行来进行预防,一种是使用纯前端的方式,不用服务器端拼接后返回(不使用服务端渲染)。另一种是对需要插入到 HTML 中的代码做好充分的转义。对于 DOM 型的攻击,主要是前端脚本的不可靠而造成的,对于数据获取渲染和字符串拼接的时候应该对可能出现的恶意代码情况进行判断。
- 使用 CSP ,CSP 的本质是建立一个白名单,告诉浏览器哪些外部资源可以加载和执行,从而防止恶意代码的注入攻击。
- CSP 指的是内容安全策略,它的本质是建立一个白名单,告诉浏览器哪些外部资源可以加载和执行。我们只需要配置规则,如何拦截由浏览器自己来实现。
- 通常有两种方式来开启 CSP,一种是设置 HTTP 首部中的 Content-Security-Policy,一种是设置 meta 标签的方式
- 对一些敏感信息进行保护,比如 cookie 使用 http-only,使得脚本无法获取。也可以使用验证码,避免脚本伪装成用户执行一些操作。
documentFragment 是什么?用它跟直接操作 DOM 的区别是什么?
MDN中对documentFragment的解释:
DocumentFragment,文档片段接口,一个没有父对象的最小文档对象。它被作为一个轻量版的 Document使用,就像标准的document一样,存储由节点(nodes)组成的文档结构。与document相比,最大的区别是DocumentFragment不是真实 DOM 树的一部分,它的变化不会触发 DOM 树的重新渲染,且不会导致性能等问题。
当我们把一个 DocumentFragment 节点插入文档树时,插入的不是 DocumentFragment 自身,而是它的所有子孙节点。在频繁的DOM操作时,我们就可以将DOM元素插入DocumentFragment,之后一次性的将所有的子孙节点插入文档中。和直接操作DOM相比,将DocumentFragment 节点插入DOM树时,不会触发页面的重绘,这样就大大提高了页面的性能。
对 CSSSprites 的理解
CSSSprites(精灵图),将一个页面涉及到的所有图片都包含到一张大图中去,然后利用CSS的 background-image,background-repeat,background-position属性的组合进行背景定位。
优点:
- 利用
CSS Sprites能很好地减少网页的http请求,从而大大提高了页面的性能,这是CSS Sprites最大的优点; CSS Sprites能减少图片的字节,把3张图片合并成1张图片的字节总是小于这3张图片的字节总和。
缺点:
- 在图片合并时,要把多张图片有序的、合理的合并成一张图片,还要留好足够的空间,防止板块内出现不必要的背景。在宽屏及高分辨率下的自适应页面,如果背景不够宽,很容易出现背景断裂;
CSSSprites在开发的时候相对来说有点麻烦,需要借助photoshop或其他工具来对每个背景单元测量其准确的位置。- 维护方面:
CSS Sprites在维护的时候比较麻烦,页面背景有少许改动时,就要改这张合并的图片,无需改的地方尽量不要动,这样避免改动更多的CSS,如果在原来的地方放不下,又只能(最好)往下加图片,这样图片的字节就增加了,还要改动CSS。
对事件委托的理解
(1)事件委托的概念
事件委托本质上是利用了浏览器事件冒泡的机制。因为事件在冒泡过程中会上传到父节点,父节点可以通过事件对象获取到目标节点,因此可以把子节点的监听函数定义在父节点上,由父节点的监听函数统一处理多个子元素的事件,这种方式称为事件委托(事件代理)。
使用事件委托可以不必要为每一个子元素都绑定一个监听事件,这样减少了内存上的消耗。并且使用事件代理还可以实现事件的动态绑定,比如说新增了一个子节点,并不需要单独地为它添加一个监听事件,它绑定的事件会交给父元素中的监听函数来处理。
(2)事件委托的特点
- 减少内存消耗
如果有一个列表,列表之中有大量的列表项,需要在点击列表项的时候响应一个事件:
<ul id="list"><li>item 1</li><li>item 2</li><li>item 3</li>......<li>item n</li>
</ul>如果给每个列表项一一都绑定一个函数,那对于内存消耗是非常大的,效率上需要消耗很多性能。因此,比较好的方法就是把这个点击事件绑定到他的父层,也就是 ul 上,然后在执行事件时再去匹配判断目标元素,所以事件委托可以减少大量的内存消耗,节约效率。
- 动态绑定事件
给上述的例子中每个列表项都绑定事件,在很多时候,需要通过 AJAX 或者用户操作动态的增加或者去除列表项元素,那么在每一次改变的时候都需要重新给新增的元素绑定事件,给即将删去的元素解绑事件;如果用了事件委托就没有这种麻烦了,因为事件是绑定在父层的,和目标元素的增减是没有关系的,执行到目标元素是在真正响应执行事件函数的过程中去匹配的,所以使用事件在动态绑定事件的情况下是可以减少很多重复工作的。
// 来实现把 #list 下的 li 元素的事件代理委托到它的父层元素也就是 #list 上:
// 给父层元素绑定事件
document.getElementById('list').addEventListener('click', function (e) {// 兼容性处理var event = e || window.event;var target = event.target || event.srcElement;// 判断是否匹配目标元素if (target.nodeName.toLocaleLowerCase === 'li') {console.log('the content is: ', target.innerHTML);}
});在上述代码中, target 元素则是在 #list 元素之下具体被点击的元素,然后通过判断 target 的一些属性(比如:nodeName,id 等等)可以更精确地匹配到某一类 #list li 元素之上;
(3)局限性
当然,事件委托也是有局限的。比如 focus、blur 之类的事件没有事件冒泡机制,所以无法实现事件委托;mousemove、mouseout 这样的事件,虽然有事件冒泡,但是只能不断通过位置去计算定位,对性能消耗高,因此也是不适合于事件委托的。
当然事件委托不是只有优点,它也是有缺点的,事件委托会影响页面性能,主要影响因素有:
- 元素中,绑定事件委托的次数;
- 点击的最底层元素,到绑定事件元素之间的
DOM层数;
在必须使用事件委托的地方,可以进行如下的处理:
- 只在必须的地方,使用事件委托,比如:
ajax的局部刷新区域 - 尽量的减少绑定的层级,不在
body元素上,进行绑定 - 减少绑定的次数,如果可以,那么把多个事件的绑定,合并到一次事件委托中去,由这个事件委托的回调,来进行分发。
vue-router
mode
hashhistory
跳转
this.$router.push()<router-link to=""></router-link>
占位
<router-view></router-view>
vue-router源码实现
- 作为一个插件存在:实现
VueRouter类和install方法 - 实现两个全局组件:
router-view用于显示匹配组件内容,router-link用于跳转 - 监控
url变化:监听hashchange或popstate事件 - 响应最新
url:创建一个响应式的属性current,当它改变时获取对应组件并显示
// 我们的插件:
// 1.实现一个Router类并挂载期实例
// 2.实现两个全局组件router-link和router-view
let Vue;class VueRouter {// 核心任务:// 1.监听url变化constructor(options) {this.$options = options;// 缓存path和route映射关系// 这样找组件更快this.routeMap = {}this.$options.routes.forEach(route => {this.routeMap[route.path] = route})// 数据响应式// 定义一个响应式的current,则如果他变了,那么使用它的组件会rerenderVue.util.defineReactive(this, 'current', '')// 请确保onHashChange中this指向当前实例window.addEventListener('hashchange', this.onHashChange.bind(this))window.addEventListener('load', this.onHashChange.bind(this))}onHashChange() {// console.log(window.location.hash);this.current = window.location.hash.slice(1) || '/'}
}// 插件需要实现install方法
// 接收一个参数,Vue构造函数,主要用于数据响应式
VueRouter.install = function (_Vue) {// 保存Vue构造函数在VueRouter中使用Vue = _Vue// 任务1:使用混入来做router挂载这件事情Vue.mixin({beforeCreate() {// 只有根实例才有router选项if (this.$options.router) {Vue.prototype.$router = this.$options.router}}})// 任务2:实现两个全局组件// router-link: 生成一个a标签,在url后面添 // <router-link to="/about">aaa</router-link>Vue.component('router-link', {props: {to: {type: String,required: true},},render(h) {// h(tag, props, children)return h('a',{ attrs: { href: '#' + this.to } },this.$slots.default)// 使用jsx// return <a href={'#'+this.to}>{this.$slots.default}</a>}})Vue.component('router-view', {render(h) {// 根据current获取组件并render// current怎么获取?// console.log('render',this.$router.current);// 获取要渲染的组件let component = nullconst { routeMap, current } = this.$routerif (routeMap[current]) {component = routeMap[current].component}return h(component)}})
}export default VueRouter
进程之前的通信方式
(1)管道通信
管道是一种最基本的进程间通信机制。管道就是操作系统在内核中开辟的一段缓冲区,进程1可以将需要交互的数据拷贝到这段缓冲区,进程2就可以读取了。
管道的特点:
- 只能单向通信
- 只能血缘关系的进程进行通信
- 依赖于文件系统
- 生命周期随进程
- 面向字节流的服务
- 管道内部提供了同步机制
(2)消息队列通信
消息队列就是一个消息的列表。用户可以在消息队列中添加消息、读取消息等。消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法。 每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构。可以通过发送消息来避免命名管道的同步和阻塞问题。但是消息队列与命名管道一样,每个数据块都有一个最大长度的限制。
使用消息队列进行进程间通信,可能会收到数据块最大长度的限制约束等,这也是这种通信方式的缺点。如果频繁的发生进程间的通信行为,那么进程需要频繁地读取队列中的数据到内存,相当于间接地从一个进程拷贝到另一个进程,这需要花费时间。
(3)信号量通信
共享内存最大的问题就是多进程竞争内存的问题,就像类似于线程安全问题。我们可以使用信号量来解决这个问题。信号量的本质就是一个计数器,用来实现进程之间的互斥与同步。例如信号量的初始值是 1,然后 a 进程来访问内存1的时候,我们就把信号量的值设为 0,然后进程b 也要来访问内存1的时候,看到信号量的值为 0 就知道已经有进程在访问内存1了,这个时候进程 b 就会访问不了内存1。所以说,信号量也是进程之间的一种通信方式。
(4)信号通信
信号(Signals )是Unix系统中使用的最古老的进程间通信的方法之一。操作系统通过信号来通知进程系统中发生了某种预先规定好的事件(一组事件中的一个),它也是用户进程之间通信和同步的一种原始机制。
(5)共享内存通信
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问(使多个进程可以访问同一块内存空间)。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
(6)套接字通信
上面说的共享内存、管道、信号量、消息队列,他们都是多个进程在一台主机之间的通信,那两个相隔几千里的进程能够进行通信吗?答是必须的,这个时候 Socket 这家伙就派上用场了,例如我们平时通过浏览器发起一个 http 请求,然后服务器给你返回对应的数据,这种就是采用 Socket 的通信方式了。
代码输出结果
function runAsync (x) {const p = new Promise(r => setTimeout(() => r(x, console.log(x)), 1000))return p
}
function runReject (x) {const p = new Promise((res, rej) => setTimeout(() => rej(`Error: ${x}`, console.log(x)), 1000 * x))return p
}
Promise.all([runAsync(1), runReject(4), runAsync(3), runReject(2)]).then(res => console.log(res)).catch(err => console.log(err))输出结果如下:
// 1s后输出
1
3
// 2s后输出
2
Error: 2
// 4s后输出
4可以看到。catch捕获到了第一个错误,在这道题目中最先的错误就是runReject(2)的结果。如果一组异步操作中有一个异常都不会进入.then()的第一个回调函数参数中。会被.then()的第二个回调函数捕获。
从输入URL到页面展示过程

1. DNS域名解析
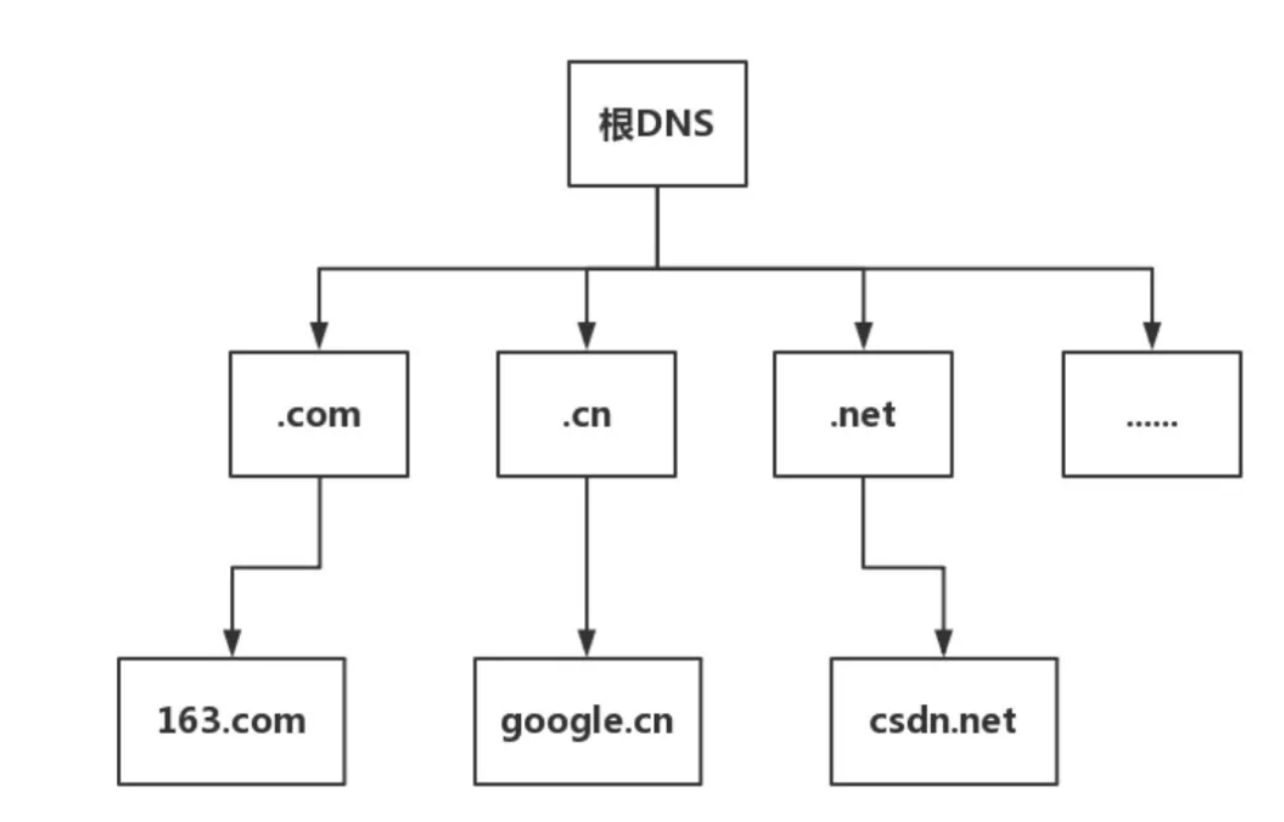
- 根 DNS 服务器 :返回顶级域 DNS 服务器的 IP 地址
- 顶级域 DNS 服务器:返回权威 DNS 服务器的 IP 地址
- 权威 DNS 服务器 :返回相应主机的 IP 地址
DNS的域名查找,在客户端和浏览器,本地DNS之间的查询方式是递归查询;在本地DNS服务器与根域及其子域之间的查询方式是迭代查询;

在客户端输入 URL 后,会有一个递归查找的过程,从浏览器缓存中查找->本地的hosts文件查找->找本地DNS解析器缓存查找->本地DNS服务器查找,这个过程中任何一步找到了都会结束查找流程。
如果本地DNS服务器无法查询到,则根据本地DNS服务器设置的转发器进行查询。若未用转发模式,则迭代查找过程如下图:

结合起来的过程,可以用一个图表示:

在查找过程中,有以下优化点:
- DNS存在着多级缓存,从离浏览器的距离排序的话,有以下几种:
浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。 - 在域名和 IP 的映射过程中,给了应用基于域名做负载均衡的机会,可以是简单的负载均衡,也可以根据地址和运营商做全局的负载均衡。
2. 建立TCP连接
首先,判断是不是https的,如果是,则HTTPS其实是HTTP + SSL / TLS 两部分组成,也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据
进行三次握手,建立TCP连接。
- 第一次握手:建立连接。客户端发送连接请求报文段
- 第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认
- 第三次握手:客户端收到服务器的SYN+ACK报文段,向服务器发送ACK报文段
SSL握手过程
- 第一阶段 建立安全能力 包括协议版本 会话Id 密码构件 压缩方法和初始随机数
- 第二阶段 服务器发送证书 密钥交换数据和证书请求,最后发送请求-相应阶段的结束信号
- 第三阶段 如果有证书请求客户端发送此证书 之后客户端发送密钥交换数据 也可以发送证书验证消息
- 第四阶段 变更密码构件和结束握手协议
完成了之后,客户端和服务器端就可以开始传送数据
发送HTTP请求,服务器处理请求,返回响应结果
TCP连接建立后,浏览器就可以利用
HTTP/HTTPS协议向服务器发送请求了。服务器接受到请求,就解析请求头,如果头部有缓存相关信息如if-none-match与if-modified-since,则验证缓存是否有效,若有效则返回状态码为304,若无效则重新返回资源,状态码为200
这里有发生的一个过程是HTTP缓存,是一个常考的考点,大致过程如图:

3. 关闭TCP连接
4. 浏览器渲染
按照渲染的时间顺序,流水线可分为如下几个子阶段:构建 DOM 树、样式计算、布局阶段、分层、栅格化和显示。如图:
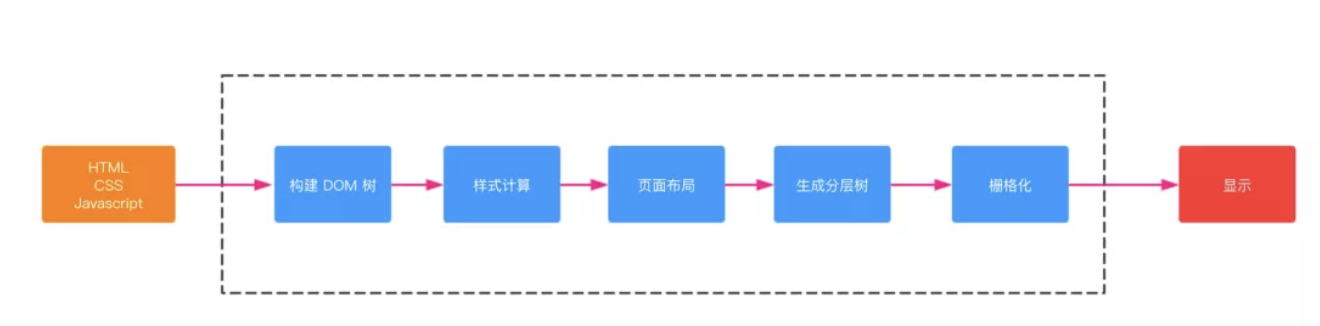
- 渲染进程将 HTML 内容转换为能够读懂DOM 树结构。
- 渲染引擎将 CSS 样式表转化为浏览器可以理解的
styleSheets,计算出DOM节点的样式。 - 创建布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树。
- 为每个图层生成绘制列表,并将其提交到合成线程。合成线程将图层分图块,并栅格化将图块转换成位图。
- 合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上。
构建 DOM 树

- 转码(Bytes -> Characters)—— 读取接收到的 HTML 二进制数据,按指定编码格式将字节转换为 HTML 字符串
- Tokens 化(Characters -> Tokens)—— 解析 HTML,将 HTML 字符串转换为结构清晰的 Tokens,每个 Token 都有特殊的含义同时有自己的一套规则
- 构建 Nodes(Tokens -> Nodes)—— 每个 Node 都添加特定的属性(或属性访问器),通过指针能够确定 Node 的父、子、兄弟关系和所属 treeScope(例如:iframe 的 treeScope 与外层页面的 treeScope 不同)
- 构建 DOM 树(Nodes -> DOM Tree)—— 最重要的工作是建立起每个结点的父子兄弟关系
样式计算
渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式。
CSS 样式来源主要有 3 种,分别是通过 link 引用的外部 CSS 文件、style标签内的 CSS、元素的 style 属性内嵌的 CSS。
页面布局
布局过程,即
排除 script、meta 等功能化、非视觉节点,排除display: none的节点,计算元素的位置信息,确定元素的位置,构建一棵只包含可见元素布局树。如图:

其中,这个过程需要注意的是回流和重绘
生成分层树
页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)
栅格化
合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图

通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)。在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
显示
最后,合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上,渲染过程完成。
如何避免回流与重绘?
减少回流与重绘的措施:
- 操作DOM时,尽量在低层级的DOM节点进行操作
- 不要使用
table布局, 一个小的改动可能会使整个table进行重新布局 - 使用CSS的表达式
- 不要频繁操作元素的样式,对于静态页面,可以修改类名,而不是样式。
- 使用absolute或者fixed,使元素脱离文档流,这样他们发生变化就不会影响其他元素
- 避免频繁操作DOM,可以创建一个文档片段
documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中 - 将元素先设置
display: none,操作结束后再把它显示出来。因为在display属性为none的元素上进行的DOM操作不会引发回流和重绘。 - 将DOM的多个读操作(或者写操作)放在一起,而不是读写操作穿插着写。这得益于浏览器的渲染队列机制。
浏览器针对页面的回流与重绘,进行了自身的优化——渲染队列
浏览器会将所有的回流、重绘的操作放在一个队列中,当队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会对队列进行批处理。这样就会让多次的回流、重绘变成一次回流重绘。
上面,将多个读操作(或者写操作)放在一起,就会等所有的读操作进入队列之后执行,这样,原本应该是触发多次回流,变成了只触发一次回流。
Virtual Dom 的优势在哪里?
Virtual Dom 的优势」其实这道题目面试官更想听到的答案不是上来就说「直接操作/频繁操作 DOM 的性能差」,如果 DOM 操作的性能如此不堪,那么 jQuery 也不至于活到今天。所以面试官更想听到 VDOM 想解决的问题以及为什么频繁的 DOM 操作会性能差。
首先我们需要知道:
DOM 引擎、JS 引擎 相互独立,但又工作在同一线程(主线程) JS 代码调用 DOM API 必须 挂起 JS 引擎、转换传入参数数据、激活 DOM 引擎,DOM 重绘后再转换可能有的返回值,最后激活 JS 引擎并继续执行若有频繁的 DOM API 调用,且浏览器厂商不做“批量处理”优化, 引擎间切换的单位代价将迅速积累若其中有强制重绘的 DOM API 调用,重新计算布局、重新绘制图像会引起更大的性能消耗。
其次是 VDOM 和真实 DOM 的区别和优化:
- 虚拟 DOM 不会立马进行排版与重绘操作
- 虚拟 DOM 进行频繁修改,然后一次性比较并修改真实 DOM 中需要改的部分,最后在真实 DOM 中进行排版与重绘,减少过多DOM节点排版与重绘损耗
- 虚拟 DOM 有效降低大面积真实 DOM 的重绘与排版,因为最终与真实 DOM 比较差异,可以只渲染局部
代码输出结果
async function async1 () {console.log('async1 start');await new Promise(resolve => {console.log('promise1')resolve('promise1 resolve')}).then(res => console.log(res))console.log('async1 success');return 'async1 end'
}
console.log('srcipt start')
async1().then(res => console.log(res))
console.log('srcipt end')这里是对上面一题进行了改造,加上了resolve。
输出结果如下:
script start
async1 start
promise1
script end
promise1 resolve
async1 success
async1 endHTTPS是如何保证安全的?
先理解两个概念:
- 对称加密:即通信的双⽅都使⽤同⼀个秘钥进⾏加解密,对称加密虽然很简单性能也好,但是⽆法解决⾸次把秘钥发给对⽅的问题,很容易被⿊客拦截秘钥。
- ⾮对称加密:
- 私钥 + 公钥= 密钥对
- 即⽤私钥加密的数据,只有对应的公钥才能解密,⽤公钥加密的数据,只有对应的私钥才能解密
- 因为通信双⽅的⼿⾥都有⼀套⾃⼰的密钥对,通信之前双⽅会先把⾃⼰的公钥都先发给对⽅
- 然后对⽅再拿着这个公钥来加密数据响应给对⽅,等到到了对⽅那⾥,对⽅再⽤⾃⼰的私钥进⾏解密
⾮对称加密虽然安全性更⾼,但是带来的问题就是速度很慢,影响性能。
解决⽅案:
结合两种加密⽅式,将对称加密的密钥使⽤⾮对称加密的公钥进⾏加密,然后发送出去,接收⽅使⽤私钥进⾏解密得到对称加密的密钥,然后双⽅可以使⽤对称加密来进⾏沟通。
此时⼜带来⼀个问题,中间⼈问题:
如果此时在客户端和服务器之间存在⼀个中间⼈,这个中间⼈只需要把原本双⽅通信互发的公钥,换成⾃⼰的公钥,这样中间⼈就可以轻松解密通信双⽅所发送的所有数据。
所以这个时候需要⼀个安全的第三⽅颁发证书(CA),证明身份的身份,防⽌被中间⼈攻击。 证书中包括:签发者、证书⽤途、使⽤者公钥、使⽤者私钥、使⽤者的HASH算法、证书到期时间等。
但是问题来了,如果中间⼈篡改了证书,那么身份证明是不是就⽆效了?这个证明就⽩买了,这个时候需要⼀个新的技术,数字签名。
数字签名就是⽤CA⾃带的HASH算法对证书的内容进⾏HASH得到⼀个摘要,再⽤CA的私钥加密,最终组成数字签名。当别⼈把他的证书发过来的时候,我再⽤同样的Hash算法,再次⽣成消息摘要,然后⽤CA的公钥对数字签名解密,得到CA创建的消息摘要,两者⼀⽐,就知道中间有没有被⼈篡改了。这个时候就能最⼤程度保证通信的安全了。
相关文章:
高级前端面试题汇总
iframe 有那些优点和缺点? iframe 元素会创建包含另外一个文档的内联框架(即行内框架)。 优点: 用来加载速度较慢的内容(如广告)可以使脚本可以并行下载可以实现跨子域通信 缺点: iframe 会…...
HTML#5表单标签
一. 表单标签介绍表单: 在网页中主要负责数据采集功能,使用<form>标签定义表单表单项: 不同类型的input元素, 下拉列表, 文本域<form> 定义表单<input> 定义表单项,通过typr属性控制输入形式<label> 为表单项定义标注<select> 定义下拉列表<o…...

ONNX可视化与编辑工具
ONNX可视化与编辑工具netrononnx-modifier在模型部署的过程中,需要使用到ONNX模型,下面给大家推荐两个ONNX可视化与编辑工具,其中,netron仅支持模型的可视化,onnx-modifier支持ONNX的可视化与编辑。 netron Netron是…...
Verilog 学习第五节(串口接收部分)
小梅哥串口部分学习part2 串口通信接收原理串口通信接收程序设计与调试巧用位操作优化串口接收逻辑设计串口接收模块的项目应用案例串口通信接收原理 在采样的时候没有必要一直判断一个clk内全部都是高/低电平,如果采用直接对中间点进行判断的话,很有可能…...
)
AIX系统常见漏洞修复(exec、rlogin、rsh、ftp、telnet远端服务运行中)
漏洞:1.1 SSH 服务支持弱加密算法 1. 使用telnet 登录2.vi /etc/ssh/sshd_config 最后添加一下内容(去掉 arcfour、arcfour128、arcfour256 等弱加密算法) Ciphers aes128-ctr,aes192-ctr,aes256-ctr,aes128-cbc,3des-cbc,blowfish-cbc,cast…...
IEEE SLT 2022论文丨如何利用x-vectors提升语音鉴伪系统性能?
分享一篇IEEE SLT 2022收录的声纹识别方向的论文,《HOW TO BOOST ANTI-SPOOFING WITH X-VECTORS》由AuroraLab(极光实验室)发表。 来源丨AuroraLab AuroraLab源自清华大学电子工程系与新疆大学信息科学与工程学院,以说话人识别和…...
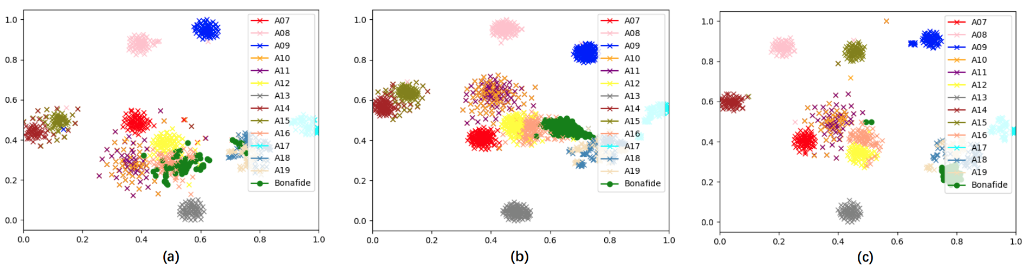
设计模式(十三)----结构型模式之桥接模式
1 概述 现在有一个需求,需要创建不同的图形,并且每个图形都有可能会有不同的颜色。我们可以利用继承的方式来设计类的关系: 我们可以发现有很多的类,假如我们再增加一个形状或再增加一种颜色,就需要创建更多的类。 试…...

倾向得分匹配案例分析
一、倾向得分匹配法说明 倾向得分匹配模型是由Rosenbaum和Rubin在1983年提出的,首次运用在生物医药领域,后来被广泛运用在药物治疗、计量研究、政策实施评价等领域。倾向得分匹配模型主要用来解决非处理因素(干扰因素)的偏差。 …...

基于SpringCloud的可靠消息最终一致性04:项目基础代码
上一节给出了项目需求和骨架代码,这一节来接着看基础代码。骨架代码和基础代码最主要的区别是:骨架代码都是数据库脚本、POM依赖文件、配置文件内容、运维脚本等,而基础代码则是和业务有关联,但并非关键代码的部分。 这些代码不用一个个地看,主要是看看结构就行。 图二十五…...

操作系统权限提升(十八)之Linux提权-内核提权
Linux 内核提权 Linux 内核提权原理 内核提权是利用Linux内核的漏洞进行提权的,内核漏洞进行提权一般包括三个环节: 1、对目标系统进行信息收集,获取到系统内核信息及版本信息; 2、根据内核版本获取其对应的漏洞以及EXP 3、使…...

华为OD机试真题Java实现【快递运输】真题+解题思路+代码(20222023
快递运输 题目 一辆运送快递的货车,运送的快递均放在大小不等的长方体快递盒中,为了能够装载更多的快递,同时不能让货车超载,需要计算最多能装多少个快递。 注:快递的体积不受限制,快递数最多1000个,货车载重最大50000。 🔥🔥🔥🔥🔥👉👉👉👉👉�…...

java面试题-JVM问题排查
1.常见的Linux定位问题的工具?常见的 Linux 定位问题的命令可以分为以下几类:系统状态命令:包括 top、uptime、vmstat、sar 等命令,用于查看系统整体的状态,如 CPU 使用率、内存使用率、磁盘 I/O 等。进程状态命令&…...
市场上有很多低代码开发平台,不懂编程的人可以用哪些?
市场上有很多低代码开发平台,不懂编程的人可以用哪些?这个问题一看就是外行问的啦,低代码平台主打的就是一个“全民开发”,而且现在很多低代码平台都发展为零代码了,不懂编程也完全可以使用! 所谓低代码开…...

Tina_Linux打包流程说明指南_new
OpenRemoved_Tina_Linux_打包流程_说明指南_new 1 概述 1.1 编写目的 介绍Allwinner 平台上打包流程。 1.2 适用范围 Allwinner 软件平台Tina v3.0 版本以上。 1.3 相关人员 适用Tina 平台的广大客户,想了解Tina 打包流程的开发人员。 2 固件打包简介 固件…...

JVM面试题
JVM 1.jvm的组成部分 类加载器:将javac编译的class文件加载到内存中 运行时数据区:将内存划分成若干个不同的区域。 执行引擎:负责解析命令,提交操作系统执行。 本地接口:融合不同的语言为java所用 2.运行时数据区 方法区&…...

@FeignClient注解
1.在启动类上开启Feign功能 不开会提示找不到所需要的bean Consider defining a bean of type in your configuration SpringBootApplication EnableFeignClients public class AuthApplication {public static void main(String[] args) {SpringApplication.run(AuthApplic…...
一文搞懂如何在 React 中使用 防抖(Debounce)和 节流(Throttle)
在前端的日常开发中,经常会使用到两个函数防抖(Debounce)和节流(Throttle),防抖函数可以有效控制在一段时间内只执行最后一次请求,例如搜索框输入时,只在输入完成后才进行请求接口。…...

Airbyte API
Airbyte API涵盖了Airbyte功能的方方面面,主要分类:Source_definition:来源定义,实现了来源的增删改查功能。Destination_definition:目标定义,实现了目标的增删改查功能。Workspace:工作区管理…...

vue项目使用Electron开发桌面应用
添加npm配置避免安装Electron错误 请确保您的 node 版本大于等于 18. cmd运行: npm config edit 该命令会打开npm的配置文件,请在空白处添加: electron_builder_binaries_mirrorhttps://npmmirror.com/mirrors/electron-builder-binaries/ e…...

std::chrono笔记
文章目录1. radio原型作用示例2. duration原型:作用示例3. time_point原型作用示例4. clockssystem_clock示例steady_clock示例high_resolution_clock先说感觉,这个库真恶心,刚接触感觉跟shi一样,特别是那个命名空间,太…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...
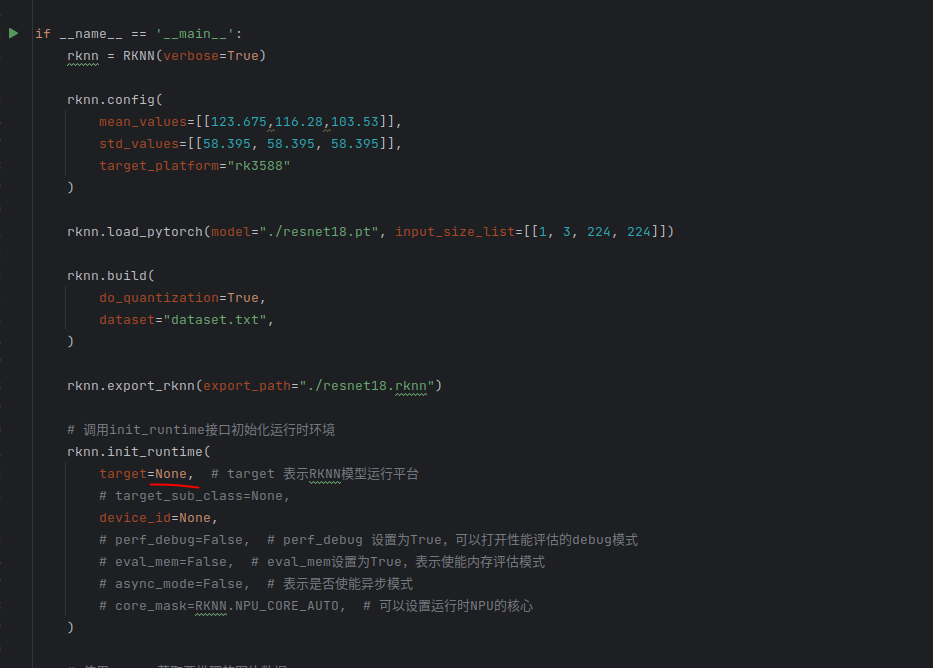
rknn toolkit2搭建和推理
安装Miniconda Miniconda - Anaconda Miniconda 选择一个 新的 版本 ,不用和RKNN的python版本保持一致 使用 ./xxx.sh进行安装 下面配置一下载源 # 清华大学源(最常用) conda config --add channels https://mirrors.tuna.tsinghua.edu.cn…...
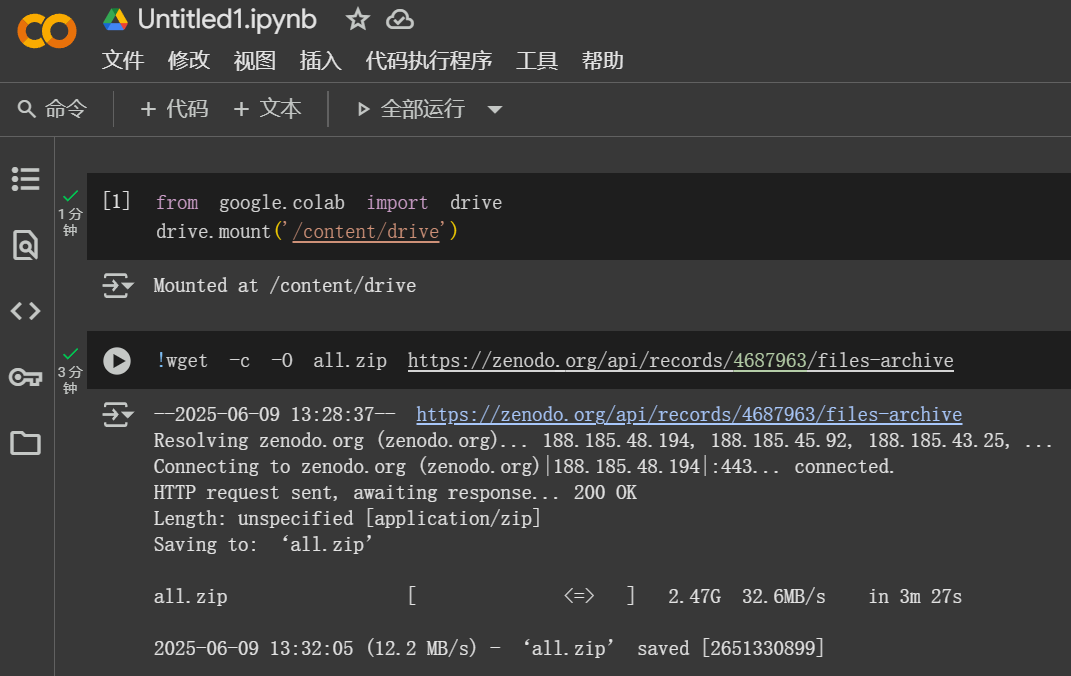
在Zenodo下载文件 用到googlecolab googledrive
方法:Figshare/Zenodo上的数据/文件下载不下来?尝试利用Google Colab :https://zhuanlan.zhihu.com/p/1898503078782674027 参考: 通过Colab&谷歌云下载Figshare数据,超级实用!!࿰…...
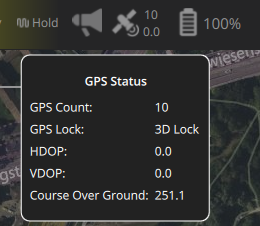
【PX4飞控】mavros gps相关话题分析,经纬度海拔获取方法,卫星数锁定状态获取方法
使用 ROS1-Noetic 和 mavros v1.20.1, 携带经纬度海拔的话题主要有三个: /mavros/global_position/raw/fix/mavros/gpsstatus/gps1/raw/mavros/global_position/global 查看 mavros 源码,来分析他们的发布过程。发现前两个话题都对应了同一…...

FTXUI::Dom 模块
DOM 模块定义了分层的 FTXUI::Element 树,可用于构建复杂的终端界面,支持响应终端尺寸变化。 namespace ftxui {...// 定义文档 定义布局盒子 Element document vbox({// 设置文本 设置加粗 设置文本颜色text("The window") | bold | color(…...