Python编程-----并行处理应用程序
目录
一.进程
二.线程
三.Python标准库中并行处理的相关模块
Threading模块
(1)使用Thread对象创建线程
(2)自定义派生于Thread的对象
(3)线程加入join()
(4)用户线程和daemon线程
(5)Timer线程
线程同步
Lock/RLock对象:
Condition对象:
基于queue模块中队列的同步:
基于Event的同步和通信:
基于进程的并行计算:
一.进程
进程是操作系统中正在执行的应用程序的一个实例,每一个进程有自己的地址空间,一般包括文本区域、数据区域和堆栈区域。
•文本区域:处理器执行的代码
•数据区域:变量和进程执行期间使用的动态分配的内存
•堆栈区域:活动过程调用的指令和本地变量
二.线程
线程是进程中的一个实体,是CPU独立调度和分派处理器时间的基本单位。
线程由线程ID、当前指令指针、寄存器集合和堆栈组成,线程与同属一个进程的其他线程共享进程所拥有的全部资源。
线程使程序能够执行并发处理,例如:
•一个线程执行后台计算任务,另一线程监视输入
•高优先级线程管理关键任务
•服务器创建线程池,处理并发客户端请求
一个进程包含多个线程。多个线程相对独立,线程有自己的上下文,切换受系统控制。
三.Python标准库中并行处理的相关模块
- _thread和_dummy_thread模块:底层低级线程API。
- threading模块:线程及其同步处理。
- multiprocessing模块:多进程处理和进程池。
- concurrent.futures模块:启动并行任务。
- queue模块:线程安全队列,用于线程或进程间信息传递。
- asyncio模块:异步IO、事件循环和任务处理。
Threading模块
这里重点看threading模块:threading模块包括创建线程,启动线程和线程同步:
- threading.Thread对象实例化,可创建线程;
- Thread对象的start(),可启动线程。
- 创建Thread的派生类,重写run(),其对象实例也可创建线程。
- 设置线程对象的daemon属性,线程可设为用户线程或daemon线程
(1)使用Thread对象创建线程
threading模块封装了_thread模块,虽然可使用_thread模块中的start_new_thread()函数创建线程,但一般建议使用threading模块
Thread(target=None, name=None,args=(),kwargs={})
Thread是线程运行函数;
name是线程的名称;
args和kwargs是传递给target的参数元组和命名参数字典。
>>>t1 = threading.Thread(target=timer, args=(5,))
>>>t1.start() #启动线程
>>>t1.is_alive() #判断线程是否活动
>>>t1.name #属性,线程名
>>>t1.id #线程标识符
>>>threading.get_ident() #返回当前线程的标识符
>>>threading.current_thread() #返回当前线程
>>>threading.active_count() #返回活动的线程数目
>>>threading.enumerate() #返回线程的列表#创建和启动新线程
import threading, time, random
def timer(interval):for i in range(3):time.sleep(random.choice(range(interval))) #随机睡眠interval秒thread_id = threading.get_ident() #获取当前线程标识符print('Thread:{0} Time:{1}'.format(thread_id, time.ctime()))
if __name__=='__main__':t1 = threading.Thread(target=timer, args=(5,)) #创建线程t2 = threading.Thread(target=timer, args=(3,)) #创建线程t1.start(); t2.start() #启动线程
(2)自定义派生于Thread的对象
声明Thread的派生类,重写对象的run方法,创建对象实例,通过对象的start方法,可启动线程,并自动执行对象的run方法,例如如下操作:
import threading, time, random
class MyThread(threading.Thread): #继承threading.Threaddef __init__(self, interval): #构造函数threading.Thread.__init__(self) #调用父类构造函数self.interval = interval #对象属性def run(self): #定义run方法for i in range(3):time.sleep(random.choice(range(self.interval))) #随机睡眠interval秒thread_id = threading.get_ident() #获取当前线程标识符print(f'Thread:{thread_id}, time:{time.ctime()}')if __name__ == '__main__':t1 = MyThread(5) #创建对象t2 = MyThread(3)t1.start() #启动线程t2.start()
(3)线程加入join()
所谓线程加入t.join(),即让包含t.join()的线程(tc,即当前线程)“加入”到另外一个线程(t)的尾部。在线程(t)执行完毕之前,线程(tc)不能执行
join(timeout=None)
timeout是超时参数,单位为秒。如果指定了超时,则线程t执行完毕或者超时都可能使当前线程继续,此时可通过t.is_alive()来判断线程是否终止。
注意:线程不能加入自己,否则导致RuntimeError,因为这样将导致死锁。线程也不能加入未启动的线程,否则将导致RuntimeError。
import threading, time, random
class MyThread(threading.Thread): #继承threading.Threaddef __init__(self): #构造函数threading.Thread.__init__(self) #调用父类构造函数def run(self): #定义run方法for i in range(5):time.sleep(1) #睡眠1秒t = threading.current_thread() #获取当前线程print(f'{t.name} at {time.ctime()}')#打印线程名、当前时间print('线程t1结束')def test():t1 = MyThread() #创建线程对象t1.name = 't1' #设置线程名称t1.start() #启动线程print('主线程开始等待线程(t1)');t1.join(2) #主线程阻塞,等待t1结束或超时print('主线程等待线程(t1)2s结束')print('主线程开始等待线程结束');t1.join() #主线程阻塞,等待t1结束print('主线程结束')
if __name__=='__main__':test()
(4)用户线程和daemon线程
线程可以分为用户线程和daemon线程:
- 用户线程(非daemon线程)是通常意义的线程,应用程序运行即为主线程,在主线程中可以创建和启动新线程,默认为用户线程。只有当所有的非daemon的用户线程(包括主线程)结束后,应用程序终止。
- daemon线程,又称守护线程,其优先级最低,一般为其它的线程提供服务。通常,daemon线程是一个无限循环的程序。所有非daemon线程都结束了,则daemon线程自动终止。
- t.daemon = True
import threading, time
class MyThread(threading.Thread): #继承threading.Threaddef __init__(self, interval): #构造函数threading.Thread.__init__(self) #调用父类构造函数self.interval = interval #对象属性def run(self): #定义run方法t = threading.current_thread() #获取当前线程print('线程' + t.name + '开始')time.sleep(self.interval) #延迟self.interval秒print('线程' + t.name + '结束')
class MyThreadDaemon(threading.Thread): #继承threading.Threaddef __init__(self, interval): #构造函数threading.Thread.__init__(self) #调用父类构造函数self.interval = interval #对象属性def run(self): #定义run方法t = threading.current_thread() #获取当前线程print('线程' + t.name + '开始')while True:time.sleep(self.interval) #延迟self.interval秒print('daemon线程' + t.name + '正在运行')print('线程' + t.name + '结束')
def test():print('主线程开始') t1 = MyThread(5) #创建线程对象t2 = MyThreadDaemon(1) #创建线程对象t1.name = 't1'; t2.name = 't2' #设置线程名称t2.daemon = True #设置为daemont1.start() #启动线程t2.start()print('主线程结束')
if __name__=='__main__':test()
(5)Timer线程
在实际应用中,经常使用定时器触发一些事件,而 threading中的Timer线程(Thread的子类),可以很方便实现定时器功能。
Timer(interval,function,args=None,kwargs=None)
#构造函数,在指定时间interval后执行函数function
start() #启动线程,即启动计时器
cancel() #取消计时器
import threading
def f():print('Hello Timer!') #创建定时器,1秒后运行timer = threading.Timer(1, f)timer.start()
timer = threading.Timer(1, f) #创建定时器,1秒后运行
timer.start() 线程同步
当多个线程调用单个对象的属性和方法时,一个线程可能会中断另一个线程正在执行的任务,使该对象处于一种无效状态(被占用),因此必须针对这些调用进行同步处理
多种线程同步处理解决方案:Lock/RLock对象、Condition对象、Semaphore对象、Event对象
Lock/RLock对象:
- threading模块的Lock对象锁可实现线程简单同步。
- threading模块的RLock是可重入的同步锁。如果一个线程在持有锁的情况下再次调用acquire()方法,那么它将会被阻塞,因为锁已经被这个线程所持有,导致死锁的发生。可重入锁的特点是允许同一个线程多次调用acquire()来获取锁,而不会发生死锁。
注:每次调用acquire()都必须对应一次release()来释放锁,否则其他线程将无法再次获取该锁。
acquire() #获取锁,锁会被系统变为blocked状态
release()
#释放锁,锁进入unlocked状态,blocked状态的线程会受到一个通知,并有权利获得锁。多个线程处于blocked状态,系统会选择一个线程来获得锁(具体哪个线程获得与实现有关)
import threading
lock = threading.Lock()
lock.acquire()
#do something...
lock.release()Lock对象支持with语句
lock = threading.Lock()
with lock:#do something...
示例:
创建工作线程,模拟银行现金帐户取款。多个线程同时执行取款操作时,如果不使用同步处理,会造成账户余额混乱;尝试使用同步锁对象Lock,以保证多个线程同时执行取款操作时银行现金帐户取款的有效和一致
import threading, time, random
class Account(threading.Thread): #继承threading.Threadlock = threading.Lock() #创建锁def __init__(self, amount): #构造函数threading.Thread.__init__(self) #调用父类构造函数Account.amount = amount #账户金额,类变量def run(self): #定义run方法self.withdraw() #取款def withdraw(self):Account.lock.acquire() #获取锁。注释不使用同步处理t = threading.current_thread()a = random.choice(range(50,101))if Account.amount < a:print(f'{t.name}交易失败。取款前余额:{Account.amount},取款额:{a}')Account.lock.release() #释放锁return 0 #拒绝交易time.sleep(random.choice(range(5))) #随机睡眠[0-5)秒prev = Account.amountAccount.amount -= a #取款print(f'{t.name}取款前余额:{prev}, 取款额:{a}, 取款后额:{Account.amount}')Account.lock.release() #释放锁。注释不使用同步处理
def test():for i in range(5): #创建5个线程对象并启动Account(200).start()
if __name__=='__main__':test()Condition对象:
线程A获得同步锁lock,在执行同步代码时需要某资源,而该资源由线程B提供。线程B无法获取线程A占用的同步锁lock,故无法提供线程A资源,从而导致死锁。
- 解决死锁问题,可使用基于条件变量(condition)的线程间通信的通信机制
1.线程A获得同步锁lock,在执行同步代码时,需要等待线程B占用的资源,则可以调用wait()/wait(毫秒数)方法阻塞当前线程运行,并释放其占用的同步锁lock;
2.notify()方法,通知等待同步锁lock的线程B,线程B获取同步锁lock后执行资源生产或者释放资源操作,然后释放同步锁,并调用notify()通知线程A
3.线程A获取同步锁lock,继续执行
cv = threading.Condition(lock=None)
#条件变量对象关联一个锁lock。创建时可传入参数lock,没有传入则默认自动创建一个。
支持with语句,等价于cv.acquire()和cv.release()
with cv:
同步操作
wait()/wait(timeout) #释放锁,并阻塞当前线程,直到其他线程使用notify()和notifyAll()唤醒后重新获取锁
notify() #唤醒一个等待线程
notifyAll() #唤醒所有线程
import threading, time, random
class Container1(): #基于同步和通信def __init__(self): #构造函数self.contents = 0 #容器内容self.available = False #容器内容self.cv = threading.Condition() #条件变量def put(self, value): #生产函数with self.cv: #使用条件变量同步if self.available: #如果已经生产过,则等待self.cv.wait() #等待self.contents = value #生产,设置内容t = threading.current_thread()print(f'{t.name}生产{self.contents}')self.available = True #设置容器状态:已生产self.cv.notify() #通知等待的消费者def get(self): #消费函数with self.cv: #使用条件变量同步if not self.available: #如果未生产,则等待self.cv.wait() #等待t = threading.current_thread()print(f'{t.name}消费{self.contents}')self.available = False #设置容器状态:未生产self.cv.notify() #通知等待的生产者
class Container2(): #无同步和通信def __init__(self): #构造函数self.contents = 0 #容器内容self.available = False #容器内容def put(self, value): #生产函数if self.available: #如果已经生产passelse:self.contents = value #生产,设置内容t = threading.current_thread()print(f'{t.name}生产{self.contents}')self.available = True #设置容器状态:已生产def get(self): # 消费函数if not self.available: # 如果未生产,不操作passelse:t = threading.current_thread()print(f'{t.name}消费{self.contents}')self.available = False # 设置容器状态:未生产class Producer(threading.Thread): # 生产者类def __init__(self, container): # 构造函数threading.Thread.__init__(self) # 调用父类构造函数self.container = container # 容器def run(self): # 定义run方法for i in range(1, 6):time.sleep(random.choice(range(2))) # 随机睡眠[0-5)秒self.container.put(i) # 生产class Consumer(threading.Thread): #消费者类def __init__(self, container): #构造函数threading.Thread.__init__(self) #调用父类构造函数self.container = container #容器def run(self): #定义run方法for i in range(1,6):time.sleep(random.choice(range(2)))#随机睡眠[0-5)秒self.container.get() #消费def test1():print('基本同步和通信的生产者消费者模型:')container = Container1() #创建容器Producer(container).start() #创建消费者线程并启动Consumer(container).start() #创建消费者线程并启动
def test2():print('无同步和通信的生产者消费者模型:')container = Container2() #创建容器Producer (container).start() #创建消费者线程并启动Consumer(container).start() #创建消费者线程并启动
if __name__=='__main__':test1()
基于queue模块中队列的同步:
- 模块queue提供了适用于多线程编程的先进先出的数据结构(即队列),用来在生产者和消费者线程之间的信息传递。使用queue模块中的线程安全的队列,可以快捷实现生产者和消费者模型
- Queue模块中包含三种线程安全的队列:Queue、LifoQueue和PriorityQueue。以Queue为例,其主要方法包括:
(1)Queue(maxsize=0):构造函数,构造指定大小的队列。默认不限定大小
(2)put(item, block=True, timeout=None):向队列中添加一个项。默认阻塞,即队列满的时候,程序阻塞等待
(3)get(block=True, timeout=None):从队列中拿出一个项。默认阻塞,即队列为空的时候,程序阻塞等待
#基于queue.Queue的生产者和消费者案例
import time
import queue
import threading
q = queue.Queue(10) #创建一个大小为10的队列
def productor(i):while True:time.sleep(1) #休眠1秒钟,即每秒钟做一个包子q.put("厨师{}做的包子!".format(i)) #如果队列满,则等待
def consumer(j):while True:print("顾客{}吃了一个{}\n".format(j, q.get()),end=’’) #如果队列空,则等待time.sleep(1) #休眠1秒钟,即每秒钟吃一个包子
for i in range(3): #3个厨师不停做包子,t = threading.Thread(target=productor, args=(i,))t.start()
for k in range(10): #10个顾客等待吃包子v = threading.Thread(target=consumer, args=(k,))v.start()
基于Event的同步和通信:
- Event相当于红绿灯信号,可用于主线程控制其他线程的执行。当flag为False时,其他的线程调用e.wait()阻塞等待这个信号;当设置flag为True时,等待的线程解除阻塞继续执行。
- Event对象主要包括下列方法:
(1)wait([timeout]):阻塞等待,直到Event对象的flag为True或超时
(2)set():将flag设置为True
(3)clear():将flag设置为False
(4)isSet():判断flag是否为True
import threading
import random
def f(i, e):e.wait() #检测Event的标志,如果是False则阻塞print(f"线程{i}的随机结果为{random.randrange(1,100)}")
if __name__ == '__main__':event = threading.Event() #创建事件对象,默认标志为Falsefor i in range(3): #创建3个线程并运行,默认阻塞等待Eventt = threading.Thread(target=f, args=(i, event))t.start()ready = input('请输入1开始继续执行阻塞的线程:')if ready == "1":event.set() #设置Event的flag为True
基于进程的并行计算:
- multiprocessing模块提供了与进程相关的操作:创建进程、启动进程、进程同步等
- 模块multiprocessing还提供进程池和线程池
- multiprocessing模块的API与threading.Thread类似,大大减少其使用复杂度
注意:windows平台中所有与进程相关的代码必须放置在
if __name__ == ‘__main__’:之中
创建进程有两种方法,即创建Process的实例对象,创建Process的子类
Process(target=None, name=None,args=(),kwargs={})
target是进程运行的函数;
name是进程的名称;
args和kwargs是传递给target的参数元组和命名参数字典
t.start() #启动线程
t.is_alive() #判断线程是否活动
t.join() #进程加入
terminate() #终止进程
t.name #进程名
t.pid #进程id
t.daemon #设置进程为用户进程(False)或Daemon进程(True)
cpu_count() #可用的CPU核数
current_process() #返回当前进程
active_children() #活动的子进程
log_to_stderr() #设置输出日志信息到标准错误输出(控制台)
#使用Process对象创建和启动新进程
import time, random
import multiprocessing as mp
def timer(interval):for i in range(3):time.sleep(random.choice(range(interval))) #随机睡眠interval秒pid = mp.current_process().pid #获取当前进程IDprint('Process:{0} Time:{1}'.format(pid, time.ctime()))
if __name__=='__main__':p1 = mp.Process(target=timer, args=(5,)) #创建进程p2 = mp.Process(target=timer, args=(5,)) #创建进程p1.start() #启动线程p2.start()p1.join()p2.join() 模块multiprocessing为进程间提供了两种通信方法:Queue和Pipe
- 模块multiprocessing中的Queue类似于queue.Queue,为进程间通信提供了一个线程和进程安全的队列
- 模块multiprocessing中的Pipe()返回一个管道(包括两个连接对象),两个进程可以分别连接到不同的端的连接对象,然后通过其send()方法发送数据或者通过recv()方法接收数据。
基于Queue队列的生产者和消费者模型
import time
import multiprocessing as mp
def productor(i, q):while True:time.sleep(1) #休眠1秒钟,即每秒钟做一个包子q.put("厨师{}做的包子!".format(i)) #如果队列满,则等待
def consumer(j, q):while True:print("顾客{}吃了一个{}" .format(j, q.get())) #如果队列空,则等待time.sleep(1) #休眠1秒钟,即每秒钟吃一个包子
if __name__=='__main__':q = mp.Queue(10) #创建一个大小为10的队列for i in range(3): #3个厨师不停做包子,p = mp.Process(target=productor, args=(i,q))p.start()for k in range(10): #10个顾客等待吃包子p = mp.Process(target=consumer, args=(k,q))p.start()
基于Pipe的进程间通信
import multiprocessing as mp
import time, random, itertools
def consumer(conn):#从管道读取数据while True:try:item = conn.recv()time.sleep(random.randrange(2)) #随机休眠,代表处理过程print("consume:{}".format(item))except EOFError:break
def producer(conn):#生产项目并将其发送到连接的管道上for i in itertools.count(1): #从1开始无限循环time.sleep(random.randrange(2)) #随机休眠,代表处理过程conn.send(i)print("produce:{}".format(i))
if __name__=="__main__":# 创建管道,返回两个连接对象的元组conn_out, conn_in = mp.Pipe()# 创建并启动生产者进程,传入参数管道一端的连接对象p_producer = mp.Process(target=producer, args=(conn_out,))p_producer.start()# 创建并启动消费者进程,传入参数管道另一端的连接对象p_consumer = mp.Process(target=consumer, args=(conn_in,))p_consumer.start()#加入进程,等待完成p_producer.join(); p_consumer.join()
相关文章:

Python编程-----并行处理应用程序
目录 一.进程 二.线程 三.Python标准库中并行处理的相关模块 Threading模块 (1)使用Thread对象创建线程 (2)自定义派生于Thread的对象 (3)线程加入join() (4)用户线程和daemon线程 (5)Timer线程 线…...
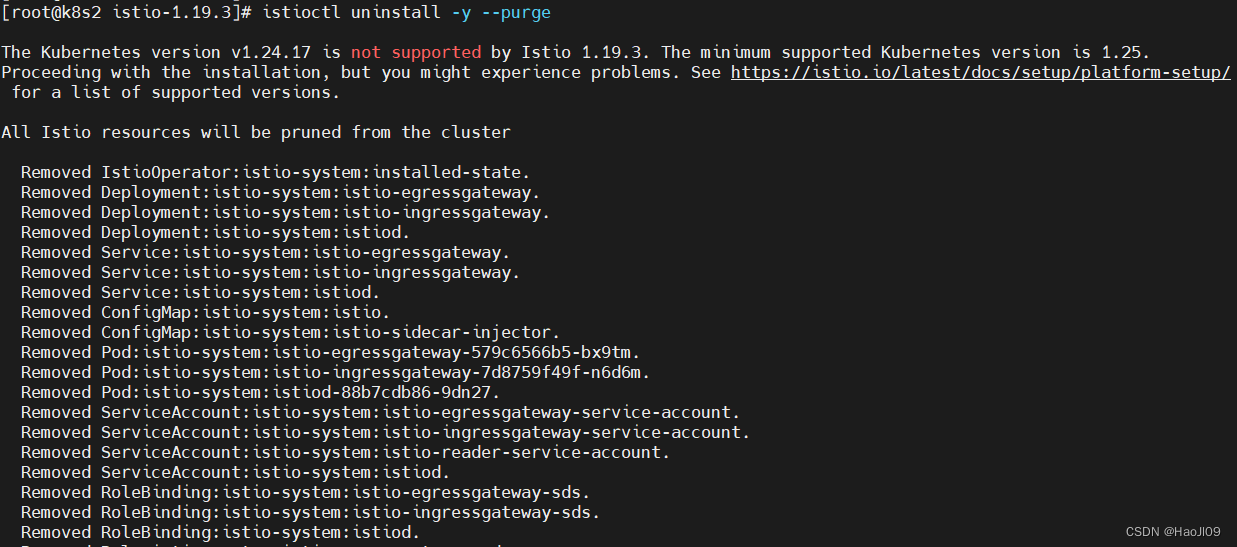
kubernetes集群编排——istio
官网:https://istio.io/latest/zh/about/service-mesh/ 部署 [rootk8s2 ~]# tar zxf istio-1.19.3-linux-amd64.tar.gz [rootk8s2 ~]# cd istio-1.19.3/[rootk8s2 istio-1.19.3]# export PATH$PWD/bin:$PATH demo专为测试准备的功能集合 [rootk8s2 istio-1.19.3]# i…...
mfc140u.dll丢失的解决方法,以及mfc140u.dll解决方法的优缺点
在使用电脑过程中,有时会遇到一些与动态链接库文件(DLL)相关的错误。其中,mfc140u.dll丢失的错误是较为常见的一种。当这个关键的mfc140u.dll文件丢失或损坏时,可能会导致某些应用程序无法正常运行。在本文中ÿ…...

2源码安装网络协议
2.2源码安装/网络协议 一、源码包应用场景 有时我们所用的内核版本太旧,系统自带的库(如libstdc.so.6)版本低或者依赖的其他软件版 本较低,导致无法安装目标软件。 软件/库其实是对机器汇编指令集的封装,在X86体系下…...
未来服务器操作系统的趋势与展望
摘要: 随着云计算、大数据和人工智能不断的发展,服务器操作系统也需要随之进行新一轮的升级。本文通过分析当前服务器操作系统的现状,探讨了未来服务器操作系统的趋势和展望,并针对一些关键问题提出了解决方案。 一、引言 服务器…...
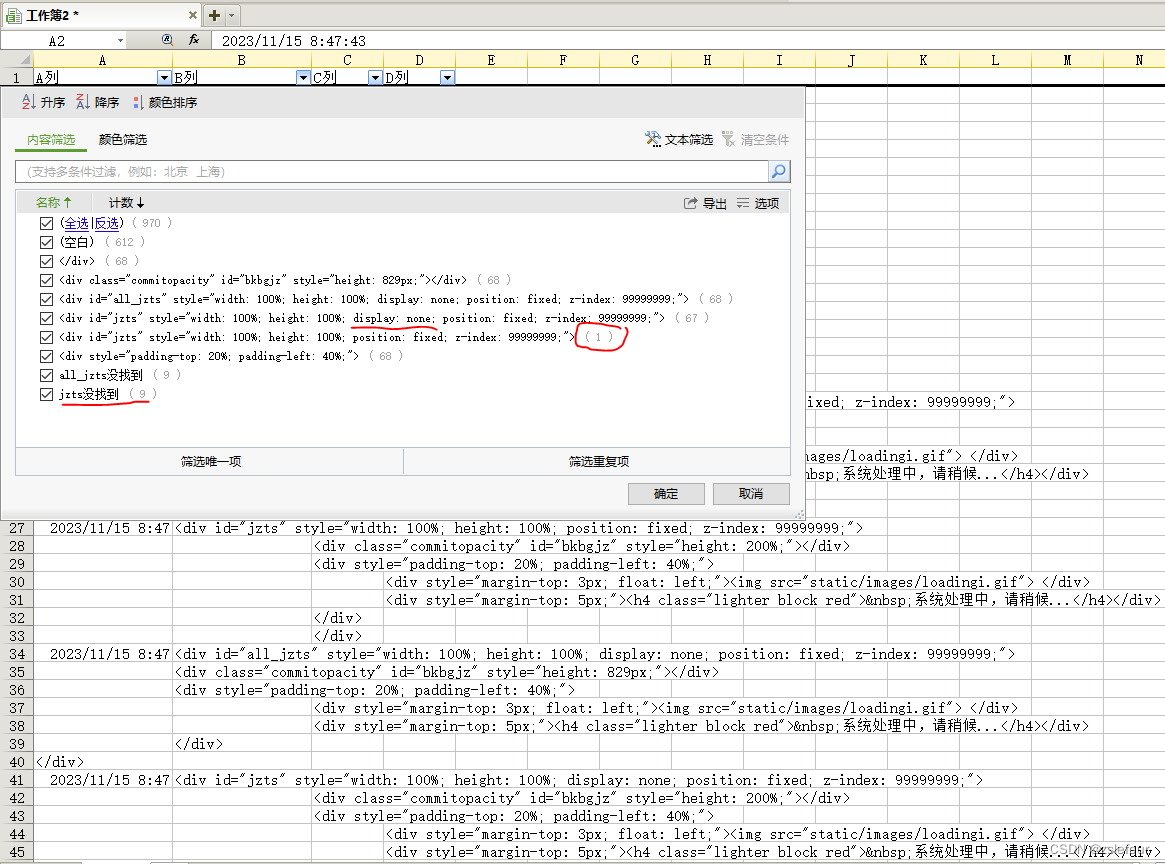
VB.net WebBrowser网页元素抓取分析方法
在用WebBrowser编程实现网页操作自动化时,常要分析网页Html,例如网页在加载数据时,常会显示“系统处理中,请稍候..”,我们需要在数据加载完成后才能继续下一步操作,如何抓取这个信息的网页html元素变化&…...
整体方案)
自建ES6.2.4切阿里云商业版ES(7.10)整体方案
一、切换目的&阿里云商业版ES版本选择 1.1 升级切换阿里云商业版7.10目的 自建的Elasticsearch服务运维难度高,操作复杂,需要手动调整资源,遇到性能瓶颈时优化难度相对云上Elasticsearch较大。使用阿里云提供的ES服务,提高系统稳定性使用云服务es,易于备份,数据恢复…...

Vue实现封装自定义指令
目录 一、什么是自定义指令? 二、自定义指令的使用 Vue中的自定义指令使用Vue.directive函数进行定义。该函数接受两个参数,第一个是指令名称,第二个是指令选项对象。 上述代码中,我们定义了一个名为my-directive的自定义指令…...
<MySQL> 查询数据进阶操作 -- 聚合查询
目录 一、聚合查询概述 二、聚合函数查询 2.1 常用函数 2.2 使用函数演示 2.3 聚合函数参数为*或列名的查询区别 2.4 字符串不能参与数学运算 2.5 具有误导性的结果集 三、分组查询 group by 四、分组后条件表达式查询 五、MySQL 中各个关键字的执行顺序 一、聚合查询…...

arm开发板
一个简单的hello world程序 minicom用来和开发板之间交互并且可以向开发板传输文件。打印hello world字符串。在linux虚拟机上编译我的代码,使用的交叉编译工具是arm-linux-gnueabihf-gcc (hard float) 可以使用 readelf -h libc.so.6 查看开发板是不是(…...
nodejs+vue教室管理系统的设计与实现-微信小程序-安卓-python-PHP-计算机毕业设计
用户 用户管理:查看,修改自己的个人信息 教室预约:可以预约今天明天的教室,按着时间段预约(可多选),如果当前时间超过预约时间段不能预约该时间段的教室 预约教室的时候要有个预约用途ÿ…...
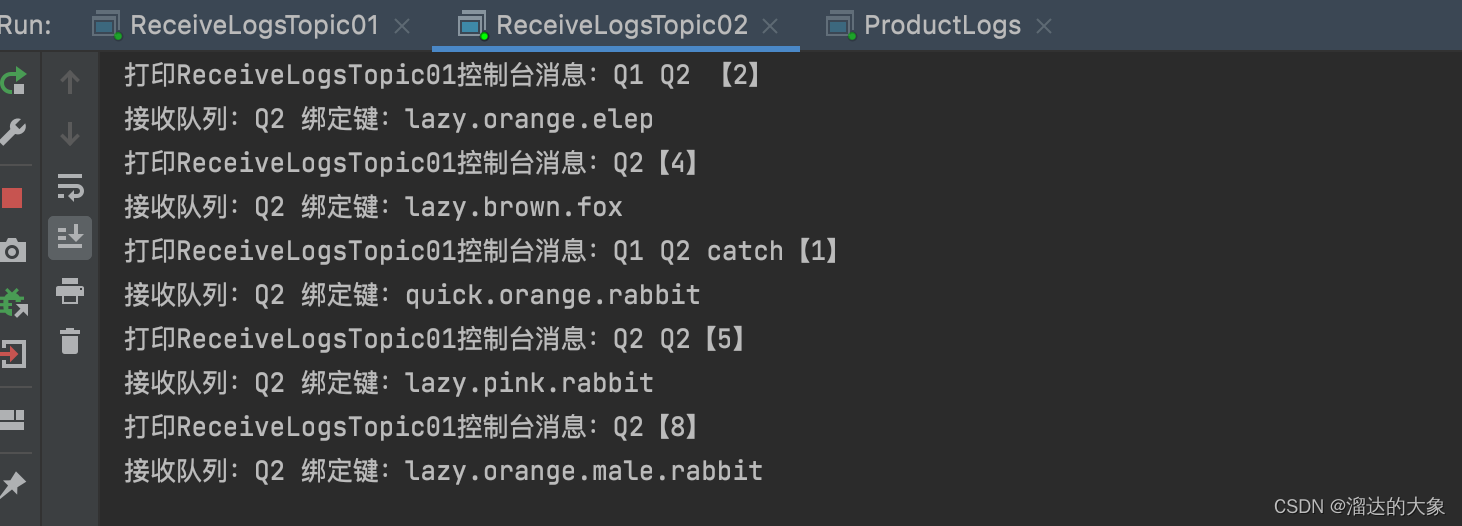
rabbitMQ的Topic模式的生产者与消费者使用案例
topic模式 RoutingKey 按照英文单词点号多拼接规则填充。其中消费者匹配规则时候 * 代表一个单词,#表示多个单词 消费者C1的RoutingKey 规则按照*.orange.* 匹配 绑定队列Q1 package com.esint.rabbitmq.work05;import com.esint.rabbitmq.RabbitMQUtils; import …...

【软考篇】中级软件设计师 第五部分
中级软件设计师 第五部分 三十六. 下午题变动题型参考答案例题一 如何保持数据流图平衡例题二 结构化语言例题三 关系模式例题四 用例关系内涵例题五 观察者模式 三十七:下午题第四题往年算法部分参考答案 读前须知: 【软考篇】中级软件设计师 学前须知 …...

论文阅读——RetNet
transformer的问题:计算量大,占用内存大,不好部署。 所以大家在找能解决办法,既能和transformer表现一样好,又能在推理阶段计算复杂度很低。 这些方法大概分类三类:一是代替transformer非线性注意力机制的…...
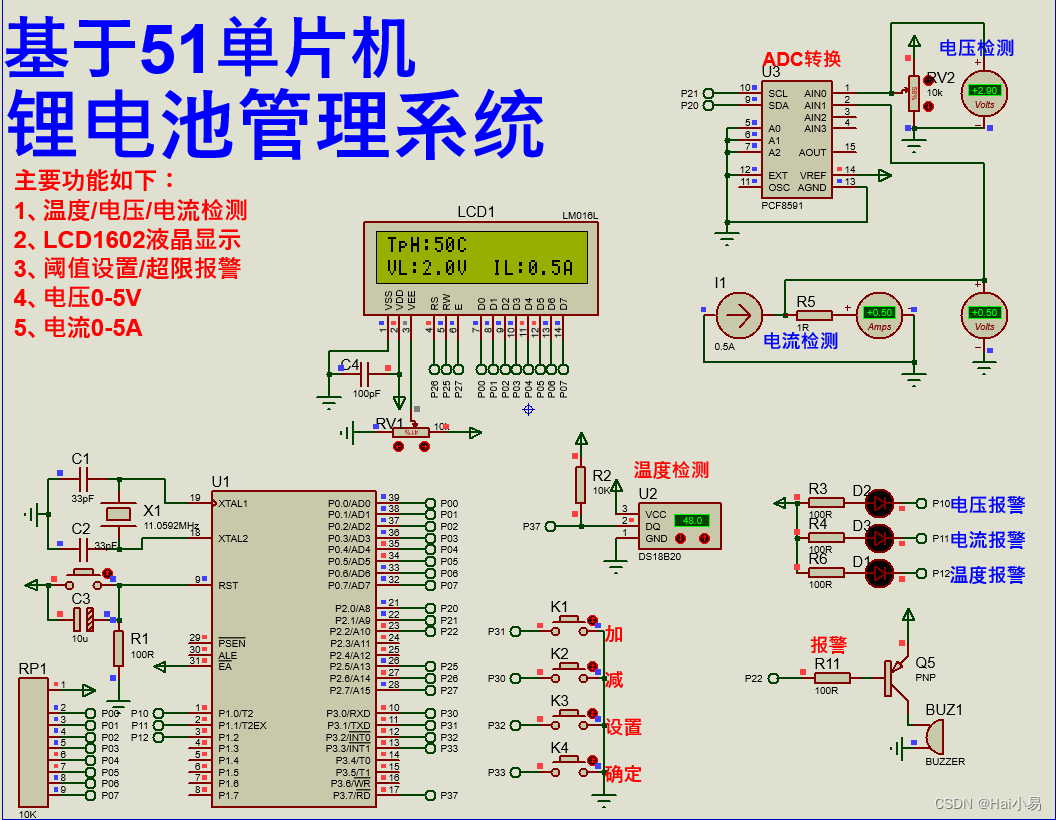
【Proteus仿真】【51单片机】锂电池管理系统
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真51单片机控制器,使用LCD1602显示模块、DS18B20温度传感器、PCF8691 ADC模块、按键、LED蜂鸣器模块等。 主要功能: 系统运行后,LCD1602显示温度…...

【工具使用-VScode】设置 VSCode 的自动保存功能
要设置 VSCode 的自动保存功能,请按照以下步骤进行操作: 打开 VSCode 编辑器。在顶部菜单中选择 “文件(File)”。选择 “首选项(Preferences)”。在下拉菜单中选择 “设置(Settings࿰…...

常用Git命令记录
持续补充… git add:提交到暂存区git remote add <remote_name> <remote_url> : 添加一个新的远程仓库。指定一个远程仓库的名称和 URL,将其添加到当前仓库中。git commit:暂存区提交到本地仓库;-m:添加日…...

Go语言常用库
Go语言常用库 文本主要介绍Go常用的一些系统库: sort、math、copy、strconv、crypto 1、sort package mainimport ("fmt""sort" )// sort // int排序 // sort.Ints([]int{}) // 字符串排序 // sort.Strings([]string{}) // 自定义排序 // s…...
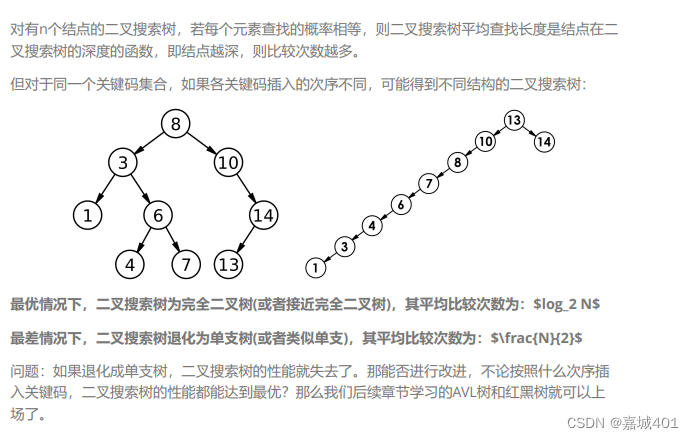
二叉树(进阶)
文章目录 1.内容安排说明2. 二叉搜索树2.1二叉搜索树的概念2.2二叉搜索树的实现2.3二叉树的性能: 搜索二叉树的应用k 模型kv模型 1.内容安排说明 二叉树在前面c数据结构阶段;已经讲过了;本节取名二叉树进阶的原因是: 1.map和set特…...

Flink之OperatorState
在Flink中状态主要分为三种: Operator State(算子状态)Keyed State(键控状态)Broadcast State(广播状态) 这里简单介绍一下Operator State的使用,说到使用State就必然要使用到Flink的容错机制也就是Checkpoint.具体内容见代码注解 数据源 这里选用Socket作为Source输入,便于…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...
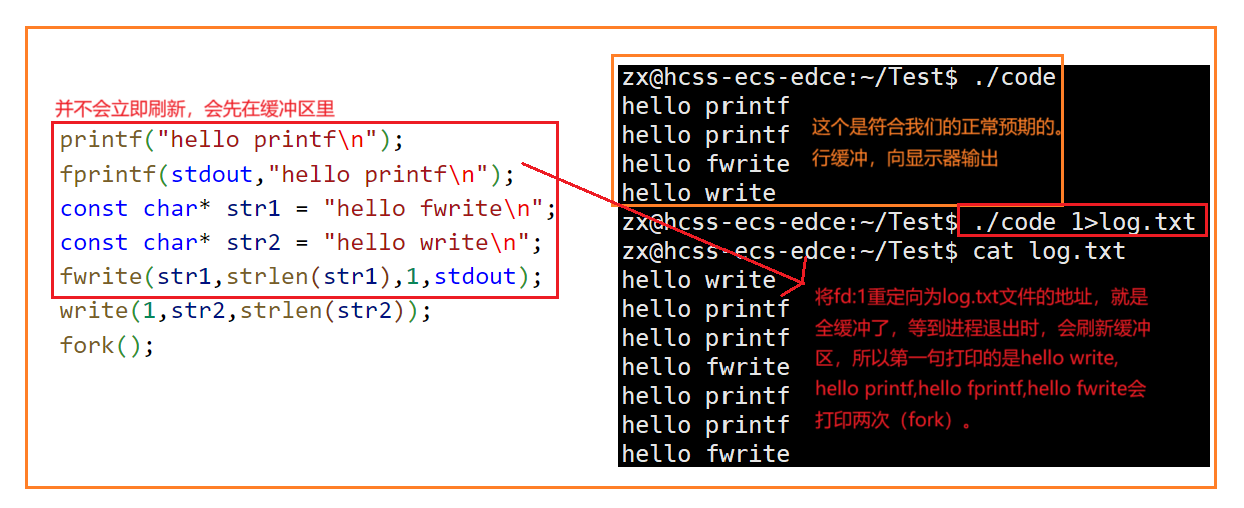
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...

Vue 3 + WebSocket 实战:公司通知实时推送功能详解
📢 Vue 3 WebSocket 实战:公司通知实时推送功能详解 📌 收藏 点赞 关注,项目中要用到推送功能时就不怕找不到了! 实时通知是企业系统中常见的功能,比如:管理员发布通知后,所有用户…...

PH热榜 | 2025-06-08
1. Thiings 标语:一套超过1900个免费AI生成的3D图标集合 介绍:Thiings是一个不断扩展的免费AI生成3D图标库,目前已有超过1900个图标。你可以按照主题浏览,生成自己的图标,或者下载整个图标集。所有图标都可以在个人或…...