Flink(五)【DataStream 转换算子(上)】
前言
这节注定是一个大的章节,我预估一下得两三天,涉及到的一些东西不懂就重新学,比如 Lambda 表达式,我只知道 Scala 中很方便,但在 Java 中有点发怵了;一个接口能不能 new 来构造对象? 答案是可以的,匿名内部类嘛。但这些好多都是不用不知道的事情。
不得不感慨还是学习爽啊,不懂就练,再不懂就问;辛苦自己倒也无妨,可是感情就不一样了,不懂就问?等到问的时候人家就要和你 say goodbye 了 。
1、基本转换算子(map/filter/flatMap)
1.1、map
map 已经是非常熟悉的算子了,在 Scala 中、在 Spark 中,map 的特点就是一进一出。
我们只需要基于 DataStream 调用 map()方法就可以进行转换处理。方法需要传入的参数是接口 MapFunction 的实现;返回值类型还是 DataStream,不过泛型(流中的元素类型)可能改变。
下面我们实现提取上一节的 POJO 类 WaterSensor 中 id 字段的功能。
package com.lyh.transform;import com.lyh.bean.WaterSensor;
import function.MyMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class MapDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> sensorDS = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3));// 三种实现方式:// 1. 匿名内部类 实现MapFunction<T,O>接口 T: 输入类型 O: 输出类型SingleOutputStreamOperator<String> map = sensorDS.map(new MapFunction<WaterSensor, String>() {@Overridepublic String map(WaterSensor waterSensor) throws Exception {return waterSensor.getId();}});// 2. lambda 表达式sensorDS.map(sensor -> sensor.getId()); // 如果是一行 可以省去大括号和returnsensorDS.map(sensor -> {return sensor.getId(); // 如果是多行 加个大括号 需要return});sensorDS.map(WaterSensor::getId); // 方法与构造函数引用 JDK8新特性// 3. 定义一个类来实现 MapFunctionsensorDS.map(new MyMapFunctionImpl());map.print();env.execute();}
}
匿名内部类和lambda表达式虽然简单快捷,但是实际开发中如果说我们的的这个类需要应用到多个场景中的话还是最好单独建个包(比如function),然后单独定义这个类:
package function;import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.functions.MapFunction;public class MyMapFunctionImpl implements MapFunction<WaterSensor,String> {@Overridepublic String map(WaterSensor waterSensor) throws Exception {return waterSensor.getId();}
}这么写是最规范的写法,也是良好的开发习惯。
1.2、filter
filter 转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉。
进行 filter 转换之后的新数据流的数据类型与原数据流是相同的。filter 转换需要传入的参数需要实现 FilterFunction 接口,而 FilterFunction 内要实现 filter()方法,就相当于一个返回布尔类型的条件表达式。

查看 FilterFunction 接口的源码,我们发现,这又是一个函数接口(只有一个抽象方法,且被@FunctionalInterface 标注),那么实现就很容易了,我们可以使用 lambda 表达式。
案例:过滤 Id 为 "s1" 的传感器。
package com.lyh.transform;import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class FilterDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> sensorDS = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3));// 过滤 "s1" 的三种实现方式:// 1. 匿名内部类 实现FilterFunction<T>接口 T: 要过滤的数据类型sensorDS.filter(new FilterFunction<WaterSensor>() {@Overridepublic boolean filter(WaterSensor waterSensor) throws Exception {return waterSensor.getId().equals("s1");}});// 2. lambda 表达式SingleOutputStreamOperator<WaterSensor> res = sensorDS.filter((waterSensor) -> waterSensor.getId().equals("s1"));// 3. 定义一个类来实现 FilterFunction// 这里省略res.print();env.execute();}
}
运行结果:
WaterSensor{id='s1', ts=1, vc=1}可以看到,id 为 s1 的传感器被过滤输出了。
1.3、flatMap
flatMap 操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生 0 到多个元素。flatMap 可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。
同 map 一样,flatMap 也可以使用 Lambda 表达式或者 FlatMapFunction 接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同。flatMap 操作会应用在每一个输入事件上面,FlatMapFunction 接口中定义了 flatMap 方法,用户可以重写这个方法,在这个方法中对输入数据进行处理,并决定是返回 0 个、1 个或多个结果数据。因此 flatMap 并没有直接定义返回值类型,而是通过一个“收集器”(Collector)来指定输出。希望输出结果时,只要调用收集器的.collect()方法就可以了;这个方法可以多次调用,也可以不调用。所以 flatMap 方法也可以实现 map 方法和 filter 方法的功能,当返回结果是 0 个的时候,就相当于对数据进行了过滤,当返回结果是 1 个的时候,相当于对数据进行了简单的转换操作。
案例 - 如果输入的数据是 sensor_1 ,只打印 vc ,如果输入的是 sensor_2, 既打印 ts 又打印 vc。
package com.lyh.transform;import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.scala.typeutils.Types;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;// 如果输入的数据是 sensor_1 ,只打印 vc ,如果输入的是 sensor_2, 既打印 ts 又打印 vc
public class FlatMapDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> sensorDS = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3));// 过滤 "s1" 的三种实现方式:// 1. 匿名内部类 实现FilterFunction<T>接口 T: 要过滤的数据类型sensorDS.flatMap(new FlatMapFunction<WaterSensor, String>() {@Overridepublic void flatMap(WaterSensor sensor, Collector<String> out) throws Exception {if (sensor.getId().equals("s1")){out.collect(sensor.getVc()+"");}else if (sensor.getId().equals("s2")){out.collect(sensor.getTs()+"\n"+sensor.getVc());}}});// 2. lambda 表达式SingleOutputStreamOperator<String> res = sensorDS.flatMap((WaterSensor sensor,Collector<String> out) -> {if (sensor.getId().equals("s1")) {out.collect(sensor.getVc() + "");} else if (sensor.getId().equals("s2")) {out.collect(sensor.getTs() + "\n" + sensor.getVc());}}).returns(Types.STRING()); // 需要注明返回类型// 3. 定义一个类来实现 FilterFunction// 这里省略res.print();env.execute();}
}
注意:这次需要对返回结果的类型进行声明,flatMap 和 map(一进一出)、filter(一进一出,因为返回的结果是一个 boolean 值) 是有点不一样的,因为 flatMap 是可以一进0出、一进一出甚至一进多出的。从上面的代码中我们可以看到, faltMap 方法中是通过采集器输出的,所以就可以通过判断语句实现不同数量的输出。
输出结果:
1
2
22、聚合算子(Aggregation)
直观上看,基本转换算子确实是在“转换”——因为它们都是基于当前数据,去做了处理和输出。而在实际应用中,我们往往需要对大量的数据进行统计或整合,从而提炼出更有用的信息。
聚合对应着我们 MapReduce 中的 reduce 这一步。
2.1、keyBy(按键分区)
我们对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在 Flink 中,要做聚合,需要先进行分区;这个操作就是通过 keyBy 来完成的。
keyBy 是聚合前必须要用到的一个算子。keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应着任务槽(task slot)。
基于不同的 key,流中的数据将被分配到不同的分区中去,这样一来,所有具有相同的 key 的数据,都将被发往同一个分区,那么下一步算子操作就将会在同一个 slot中进行处理了。
在内部,是通过计算 key 的哈希值(hash code),对分区数进行取模运算来实现的。所以这里 key 如果是 POJO 的话,必须要重写 hashCode()方法。keyBy()方法需要传入一个参数,这个参数指定了一个或一组 key。有很多不同的方法来指定 key:比如对于 Tuple 数据类型,可以指定字段的位置或者多个位置的组合;对于 POJO 类型,可以指定字段的名称(String);另外,还可以传入 Lambda 表达式或者实现一个键选择器(KeySelector),用于说明从数据中提取 key 的逻辑。
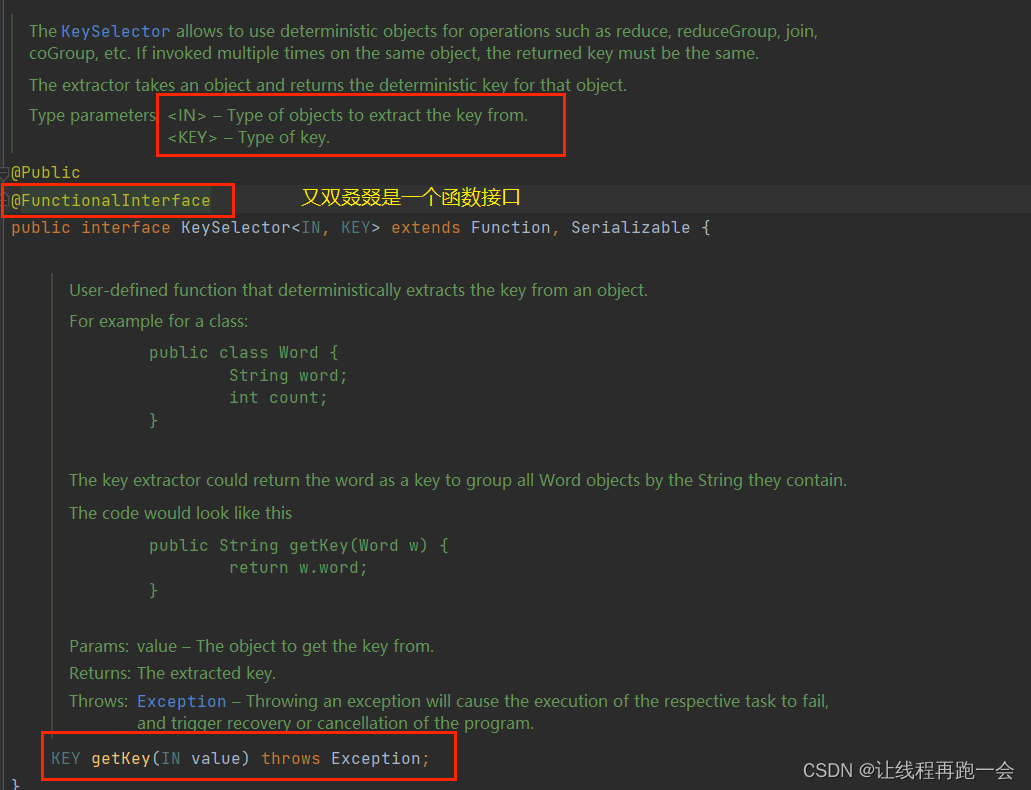
案例 - 根据 WaterSensor 的 id 进行分组(注意:这里是分组不是分区,一个分区可以存在多个组,因为 keyBy 只保证相同组在一个分区)。
package com.lyh.aggregation;import com.lyh.bean.WaterSensor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class KeyByDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStreamSource<WaterSensor> sensorDS = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3));/*** 按照 id 来进行分区* 因为KeyBy不是转换算子,所以它返回一个 键控流,仍然是一个数据流类型*/sensorDS.keyBy(new KeySelector<WaterSensor, String>() {@Overridepublic String getKey(WaterSensor sensor) throws Exception {return sensor.getId();}});// lambda 表达式KeyedStream<WaterSensor, String> keyedStream = sensorDS.keyBy((sensor) -> sensor.getId());keyedStream.print();env.execute();}
}
运行结果:
2> WaterSensor{id='s1', ts=1, vc=1}
1> WaterSensor{id='s2', ts=2, vc=2}
2> WaterSensor{id='s3', ts=3, vc=3}这次我们把并行度分为2,当我们调用 Sink 算子-print 的时候,它就会按照分区并行对数据进行输出,同时,它保证了相同 key 的数据在同一个分区中;当然,多个组也可以在同一个分区的,因为它只保证一个组的数据在同一个分区,没说不同组不可以在同一个分区;比如 hash值%分区数 结果相同的多个组也会被分到同一个组中。
2.2、sum/min/max/minBy/maxBy
有了按键分组的数据流 KeyedStream,我们就可以基于它进行聚合操作了。在 Flink 中,聚合算子和 keyBy 是成对出现的,因为把具有相同结构的数据放在一起(keyBy)再做聚合运算(聚合算子sum...)才是有意义的。就像我们 Hive 中经常把 groupBy 和 聚合函数放在一起。
- sum():在输入流上,对指定的字段做叠加求和的操作。
- min():在输入流上,对指定的字段求最小值。
- max():在输入流上,对指定的字段求最大值。
- minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包含字段最小值的整条数据。
- maxBy():与 max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
所以在 Flink 中,聚合算子是必须在 KeyBy 之后才能出现的,它做的是组内的聚合。
package com.lyh.aggregation;import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class SimpleAggregationDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> sensorDS = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 10L, 5),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3));KeyedStream<WaterSensor, String> keyedStream = sensorDS.keyBy((sensor) -> sensor.getId());/*** sum 的两种参数类型:* 1.按照位置进行聚合:* 之前我们对于元组类型Tuple2是直接可以使用位置来进行聚合的 但是POJO 类型是不允许的* 2.按照字段名进行聚合:* 对于 POJO 类型我们需要传入它的字段名*/
// keyedStream.sum("vc").print();
// keyedStream.min("vc").print();/*** max 与 maxBy 的区别* -max 只会取比较字段的最大值,非比较字段保留第一次的值* -maxBy 如果该数据对象的比较字段是新的最大值 直接取该数据对象*/keyedStream.max("vc").print();keyedStream.maxBy("vc").print();env.execute();}
}
这里要注意的就是 max/maxBy、min/minBy 的区别了。
输入数据:
WaterSensor{id='s1', ts=1, vc=1}
WaterSensor{id='s1', ts=10, vc=12}
WaterSensor{id='s2', ts=2, vc=2}
WaterSensor{id='s3', ts=3, vc=3}max("vc"):
WaterSensor{id='s1', ts=1, vc=1}
WaterSensor{id='s1', ts=1, vc=12} //这里只替换比较字段的值
WaterSensor{id='s2', ts=2, vc=2}
WaterSensor{id='s3', ts=3, vc=3}maxBy("vd"):
WaterSensor{id='s1', ts=1, vc=1}
WaterSensor{id='s1', ts=10, vc=12} //这里发现vc有新的最大值 直接替换整个对象
WaterSensor{id='s2', ts=2, vc=2}
WaterSensor{id='s3', ts=3, vc=3}2.3、reduce (规约聚合)
reduce 同样必须先 keyBy,再对相同组内的数据进行规约聚合,reduce 方法的特点是每个 key 的第一条数据来的时候不会立即执行 reduce 方法,而是存起来,直接输出;需要注意的是reduce的输出类型必须和输入类型一致。
reduce 方法需要传入一个实现 ReduceFunction 接口的对象,我们查看源码可以发现,这又双叒叕是一个函数接口,所以我们依然用lambda表达式这样最简洁。

我们用 reduce 实现 maxBy 的功能:
package com.lyh.aggregation;import com.lyh.bean.WaterSensor;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class ReduceDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> sensorDS = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s1", 10L, 5),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3));KeyedStream<WaterSensor, String> keyedStream = sensorDS.keyBy((sensor) -> sensor.getId());/*** reduce 同样必须在 keyBy 之后使用* 两两聚合 输入类型必须=输出类型*/SingleOutputStreamOperator<WaterSensor> reduce = keyedStream.reduce((sensor1, sensor2) -> new WaterSensor(sensor1.id, sensor2.ts, sensor1.getVc() + sensor2.getVc()));reduce.print();env.execute();}
}
输出结果:
WaterSensor{id='s1', ts=1, vc=1}
WaterSensor{id='s1', ts=10, vc=6}
WaterSensor{id='s2', ts=2, vc=2}
WaterSensor{id='s3', ts=3, vc=3}显然利用 reduce 算子我们可以更加灵活地对数据进行处理,比如我们修该上面的代码:
SingleOutputStreamOperator<WaterSensor> reduce = keyedStream.reduce((sensor1, sensor2) -> new WaterSensor(sensor1.id, sensor1.ts+sensor2.ts, sensor1.getVc() + sensor2.getVc()));这样我们就可以对来的数据的每个字段进行累加。
什么是有状态计算?
比如这里我们 reduce 会把每次处理的结果(状态)存下来,而且它自己会来维护,所以当相同 key 的数据再次来的时候,它才能对新旧数据再次进行聚合。
我们 reduce(value1,value2) 中,value1 指的就是之前的计算结果,也就是状态。而 value2 指的就是新来的数据。
3、用户自定义函数(UDF)
有点像我们 Hive 的 UDF ,更加灵活。
3.1、函数类
对于大部分操作而言,都需要传入一个用户自定义函数(UDF),实现相关操作的接口,来完成处理逻辑的定义。Flink 暴露了所有 UDF 函数的接口,具体实现方式为接口或者抽象类,例如 MapFunction、FilterFunction、ReduceFunction 等。
前面对于 POJO 类型的数据,我们用匿名内部类、lambda 和 单独一个实现类都实现过。
案例
这里我们再写一个简单的自定义函数 - FilterFuctionImpl ,我们希望可以通过自定义的字段名来对传进来的数据进行过滤(之前我们是写死只能过滤某个特定 id 的 WaterSensor 对象)。
package com.lyh.udf;import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.functions.FilterFunction;public class FilterFunctionImpl implements FilterFunction<WaterSensor> {public String sensor_id;public FilterFunctionImpl(String id) {this.sensor_id = id;}@Overridepublic boolean filter(WaterSensor sensor) throws Exception {return this.sensor_id.equals(sensor.getId());}
}
我们修改上面 1.2 中的 FilterDemo 代码:
SingleOutputStreamOperator<WaterSensor> res = sensorDS.filter(new FilterFunctionImpl("s2"));
运行结果:
WaterSensor{id='s2', ts=2, vc=2}3.2、富函数
“富函数类”也是 DataStream API 提供的一个函数类的接口,所有的 Flink 函数类都有其Rich 版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction 等。
既然“富”,那么它一定会比常规的函数类提供更多、更丰富的功能。与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
生命周期的概念在编程中其实非常重要,到处都有体现。例如:对于 C 语言来说,我们需要手动管理内存的分配和回收,也就是手动管理内存的生命周期。分配内存而不回收,会造成内存泄漏,回收没有分配过的内存,会造成空指针异常。而在 JVM 中,虚拟机会自动帮助我们管理对象的生命周期。对于前端来说,一个页面也会有生命周期。数据库连接、网络连接以及文件描述符的创建和关闭,也都形成了生命周期。所以生命周期的概念在编程中是无处不在的,需要我们多加注意。
Rich Function 有生命周期的概念。典型的生命周期方法有:
- open()方法,是 Rich Function 的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如 map()或者 filter()方法被调用之前,open()会首先被调用。所以像文件 IO 的创建,数据库连接的创建,配置文件的读取等等这样一次性的工作,都适合在 open()方法中完成。。
- close()方法,是生命周期中的最后一个调用的方法,类似于解构方法。一般用来做一些清理工作。
需要注意的是,这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如 RichMapFunction 中的 map(),在每条数据到来后都会触发一次调用。
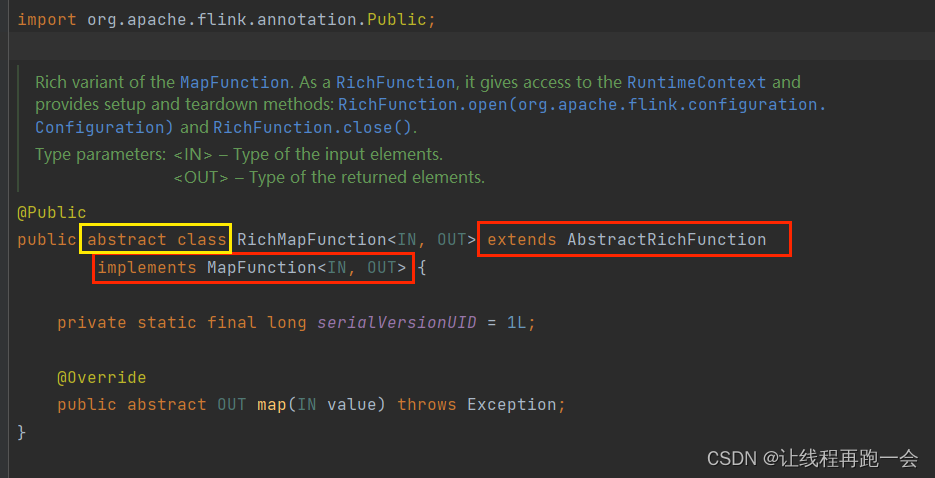
我们可以看到,RichMapFunction 是一个抽象类,它继承了 AbstractRichFunction 这个抽象类和 MapFunction 这个函数接口。
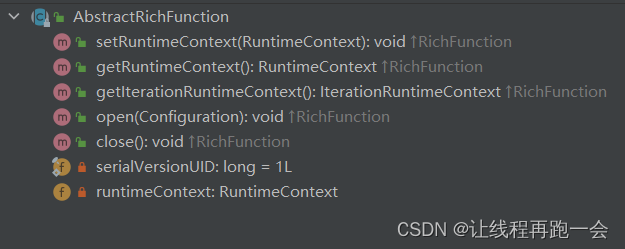
而 AbstractRichFunction 这个抽象类又为它提供了好多关于生命周期、上下文的管理方法。
案例
我们先用有界数据流来看一下这些方法是什么时候被调用的,这里先不去设置并行度(本地环境默认等于机器的cpu核数)。
package com.lyh.udf;import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class RichFunctionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<Integer> ds = env.fromElements(1, 2, 3, 4);SingleOutputStreamOperator<Integer> map = ds.map(new RichMapFunction<Integer, Integer>() {@Overridepublic Integer map(Integer value) throws Exception {return value + 1;}@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);RuntimeContext runtimeContext = getRuntimeContext(); // 上下文对象int indexOfThisSubtask = runtimeContext.getIndexOfThisSubtask(); // 子任务的编号(类似于我们线程的编号 从0开始)String taskNameWithSubtasks = runtimeContext.getTaskNameWithSubtasks();System.out.println("子任务线程编号: "+indexOfThisSubtask+" 启动, 子任务名称: "+taskNameWithSubtasks+"调用 open()");}@Overridepublic void close() throws Exception {super.close();RuntimeContext runtimeContext = getRuntimeContext(); // 上下文对象int indexOfThisSubtask = runtimeContext.getIndexOfThisSubtask(); // 子任务的编号(类似于我们线程的编号 从0开始)String taskNameWithSubtasks = runtimeContext.getTaskNameWithSubtasks();System.out.println("子任务线程编号: "+indexOfThisSubtask+" 启动, 子任务名称: "+taskNameWithSubtasks+"调用 close()");}});map.print();env.execute();}
}
运行结果:
子任务线程编号: 4 启动, 子任务名称: Map -> Sink: Print to Std. Out (5/16)#0调用 open()
子任务线程编号: 14 启动, 子任务名称: Map -> Sink: Print to Std. Out (15/16)#0调用 open()
子任务线程编号: 7 启动, 子任务名称: Map -> Sink: Print to Std. Out (8/16)#0调用 open()
子任务线程编号: 5 启动, 子任务名称: Map -> Sink: Print to Std. Out (6/16)#0调用 open()
子任务线程编号: 8 启动, 子任务名称: Map -> Sink: Print to Std. Out (9/16)#0调用 open()
子任务线程编号: 6 启动, 子任务名称: Map -> Sink: Print to Std. Out (7/16)#0调用 open()
子任务线程编号: 2 启动, 子任务名称: Map -> Sink: Print to Std. Out (3/16)#0调用 open()
子任务线程编号: 13 启动, 子任务名称: Map -> Sink: Print to Std. Out (14/16)#0调用 open()
子任务线程编号: 15 启动, 子任务名称: Map -> Sink: Print to Std. Out (16/16)#0调用 open()
子任务线程编号: 9 启动, 子任务名称: Map -> Sink: Print to Std. Out (10/16)#0调用 open()
子任务线程编号: 11 启动, 子任务名称: Map -> Sink: Print to Std. Out (12/16)#0调用 open()
子任务线程编号: 12 启动, 子任务名称: Map -> Sink: Print to Std. Out (13/16)#0调用 open()
子任务线程编号: 0 启动, 子任务名称: Map -> Sink: Print to Std. Out (1/16)#0调用 open()
子任务线程编号: 10 启动, 子任务名称: Map -> Sink: Print to Std. Out (11/16)#0调用 open()
子任务线程编号: 3 启动, 子任务名称: Map -> Sink: Print to Std. Out (4/16)#0调用 open()
子任务线程编号: 1 启动, 子任务名称: Map -> Sink: Print to Std. Out (2/16)#0调用 open()
12> 4
11> 3
10> 2
13> 5
子任务线程编号: 0 启动, 子任务名称: Map -> Sink: Print to Std. Out (1/16)#0调用 close()
子任务线程编号: 13 启动, 子任务名称: Map -> Sink: Print to Std. Out (14/16)#0调用 close()
子任务线程编号: 4 启动, 子任务名称: Map -> Sink: Print to Std. Out (5/16)#0调用 close()
子任务线程编号: 7 启动, 子任务名称: Map -> Sink: Print to Std. Out (8/16)#0调用 close()
子任务线程编号: 1 启动, 子任务名称: Map -> Sink: Print to Std. Out (2/16)#0调用 close()
子任务线程编号: 11 启动, 子任务名称: Map -> Sink: Print to Std. Out (12/16)#0调用 close()
子任务线程编号: 10 启动, 子任务名称: Map -> Sink: Print to Std. Out (11/16)#0调用 close()
子任务线程编号: 8 启动, 子任务名称: Map -> Sink: Print to Std. Out (9/16)#0调用 close()
子任务线程编号: 5 启动, 子任务名称: Map -> Sink: Print to Std. Out (6/16)#0调用 close()
子任务线程编号: 14 启动, 子任务名称: Map -> Sink: Print to Std. Out (15/16)#0调用 close()
子任务线程编号: 2 启动, 子任务名称: Map -> Sink: Print to Std. Out (3/16)#0调用 close()
子任务线程编号: 6 启动, 子任务名称: Map -> Sink: Print to Std. Out (7/16)#0调用 close()
子任务线程编号: 12 启动, 子任务名称: Map -> Sink: Print to Std. Out (13/16)#0调用 close()
子任务线程编号: 15 启动, 子任务名称: Map -> Sink: Print to Std. Out (16/16)#0调用 close()
子任务线程编号: 3 启动, 子任务名称: Map -> Sink: Print to Std. Out (4/16)#0调用 close()
子任务线程编号: 9 启动, 子任务名称: Map -> Sink: Print to Std. Out (10/16)#0调用 close()
我们再用无界数据流进行模拟,这次设置并行度为 2,修改上面的代码:
DataStreamSource<String> ds = env.socketTextStream("hadoop102",9999);SingleOutputStreamOperator<Integer> map = ds.map(new RichMapFunction<String, Integer>() {@Overridepublic Integer map(String value) throws Exception {return Integer.parseInt(value) + 1;}@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);System.out.println("子任务线程编号: "+getRuntimeContext().getIndexOfThisSubtask()+" 启动, 子任务名称: "+getRuntimeContext().getTaskNameWithSubtasks()+"调用 open()");}@Overridepublic void close() throws Exception {super.close();System.out.println("子任务线程编号: "+getRuntimeContext().getIndexOfThisSubtask()+" 启动, 子任务名称: "+getRuntimeContext().getTaskNameWithSubtasks()+"调用 close()");}});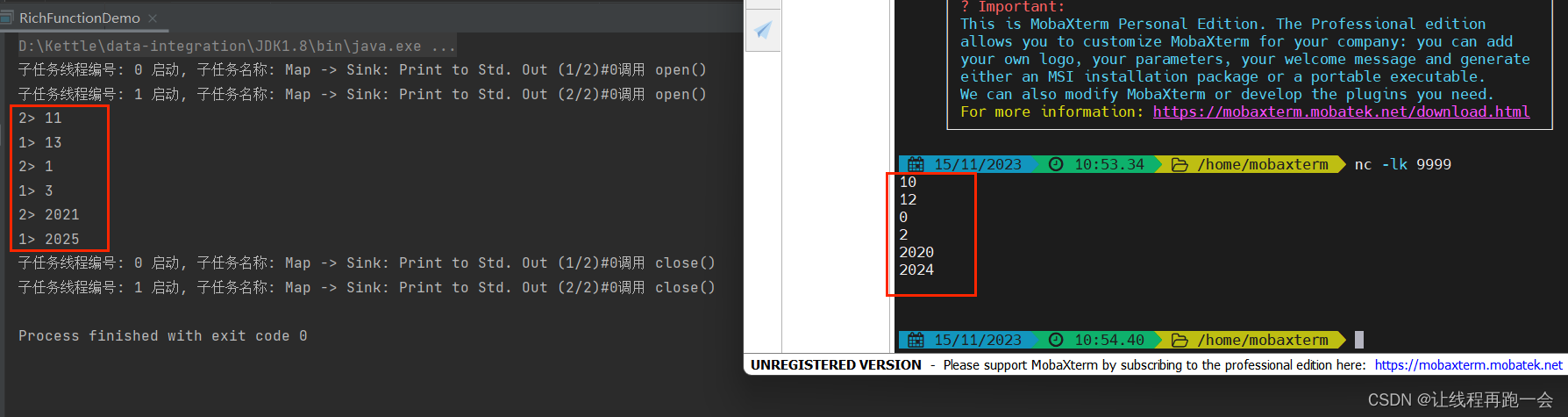
结论
RichXXXFunction:富函数
- 多了生命周期管理方法:
-
open():每个子任务,在启动时调用一次
-
close():每个子任务,在结束时调用一次
-
如果是flink程序异常挂掉,不会调用 close()
-
如果是正常调用 flink 的 cancel 命令或者web ui 端的 cancel ,可以 close()
-
-
- 多了运行时上下文
- 可以获取一些运行时的环境信息,比如 子任务编号、名称 ......
以后我们开发的时候,如果 Flink 程序启动时需要执行一次,关闭时需要执行一次的场景下就可以使用这些富函数了。
总结
剩下的部分下次完成。
相关文章:
Flink(五)【DataStream 转换算子(上)】
前言 这节注定是一个大的章节,我预估一下得两三天,涉及到的一些东西不懂就重新学,比如 Lambda 表达式,我只知道 Scala 中很方便,但在 Java 中有点发怵了;一个接口能不能 new 来构造对象? 答案是可以的&…...
【vitis】 AIE basic
AIE vs AIE-ML versal 期间分类 文件 操作 vitis -new -w . 安装...

微信抽奖活动怎么做
微信抽奖活动:打破传统,创新互动,带给你超乎想象的惊喜体验! 随着互联网的飞速发展,人们越来越热衷于参与各种线上活动。而微信,作为中国最大的社交平台之一,自然成为了各种活动的聚集地。今天…...

装机必备!这5款免费软件,你值得拥有!
目前win7渐渐退出视野,大部分人都开始使用win10了,笔者在日常的工作和使用中,为了能够让效率的大提升,下载了不少软件,以下的软件都是个人认为装机必备,而且都是可以免费下载。 1.屏幕亮度调节——Twin…...
华为eNSP综合实验考试
VLAN信息表 设备名称 端口 链路类型 VLAN 参数 HZ-HZCampus-Agg01-S5731 GE0/0/1 Trunk PVID:1 Allow-pass:10 20 Eth-trunk1(GE0/0/2,0/0/3,0/0/23) Trunk PVID:1 Allow-pass:10 20 GE0/0/24 Access PVID…...
OPPO Watch纯手机开启远程ADB调试
Wear OS手表中,我们可以直接在开发者设置中打开WiFi调试。但是这在OPPO等魔改Android系统中不再奏效。 需要什么?? 手表一台手机一个OTG转接头一个手表充电器一个 演示设备 手机: OPPO Find X手表: OPPO Watch 1代 …...
idea查看UML类图
idea查看UML类图 一、如何查看UML类图 1.1 选择需要查看的类或者包,鼠标右键,选择Diagrams->Show Diagram 1.2 对于UML类图中的包,选中后点击鼠标右键-> Expand Nodes(展开节点) 展开前 展开后 1.3 展开后分布比较凌乱ÿ…...
)
2736. 最大和查询 : 从一维限制到二维限制,逐步思考剖析本题(进阶一问)
题目描述 这是 LeetCode 上的 「2736. 最大和查询」 ,难度为 「困难」。 Tag : 「排序」、「离散化」、「树状数组」 给你两个长度为 n、下标从 0 开始的整数数组 nums1 和 nums2,另给你一个下标从 1 开始的二维数组 queries,其中 。 对于第…...

2023数维杯国际数学建模A题B题C题D题思路+模型+代码+完整论文
目录 1.数维杯各题思路模型:比赛开始后,第一时间更新,获取见文末名片 3 常见数模问题常见模型分类 3.1 分类问题 3.2 优化问题 详细思路见此名片,开赛第一时间更新 1.数维杯各题思路模型:9.7晚上比赛开始后&#x…...

java多个jar包编译生成.class文件
有时候需要通过多个jar包让java文件生成 .class字节码文件,这里主要记录一下格式问题 javac -cp a.jar;b.jar a.java...

小米手环8pro重新和手机配对解决办法
如果更换了手机,那么小米手环8pro是无法和新手机自动连接的。 但是在新手机上直接连接又连接不上,搜索蓝牙根本找不到手环的蓝牙。 解决办法就是: 把手环恢复出厂!!!!! 是的&…...
element-china-area-data插件vue3做省市区的下拉选择,用3个独立的el-select实现
第1版,选择下拉没有优化 第2版,选择下拉时,做了优化...

盘点十大免费低/无代码开发软件,数字化转型看这里
在数字化日益普及的当下,低代码开发技术逐渐受到大众的追捧。这种技术让缺乏编程经验的大众也能轻松创建应用程序和网站。通过直观的图形界面和拖拽功能,用户可以无需编写任何代码,轻松实现自己的开发需求。本文将为您介绍十大免费的低代码开…...
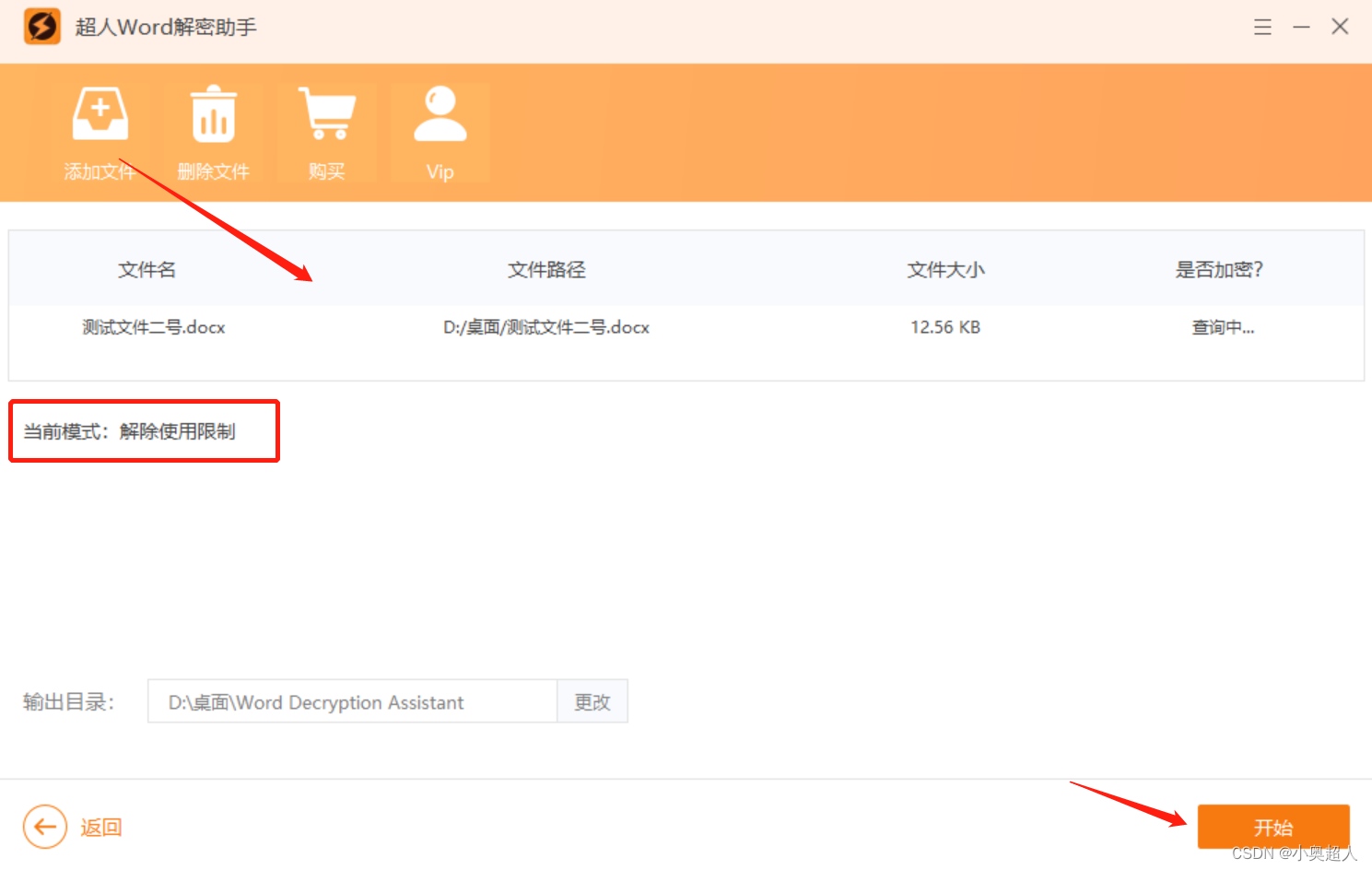
【word密码】word设置只读方式的四个方法
想要将word文档设置为只读模式,方法有很多,今天小奥超人介绍几个方法给大家。 方法一:文件属性 常见的、简单的设置方法,不用打开word文件,只需要右键选择文件,打开文件属性,勾选上【只读】选…...

正整数的阶乘
阶乘是基斯顿卡曼(Christian Kramp,1760~1826)于 1808 年发明的运算符号,是数学术语。 一个正整数的阶乘(factorial)是所有小于及等于该数的正整数的积,并且0的阶乘为1。自然数n的阶…...
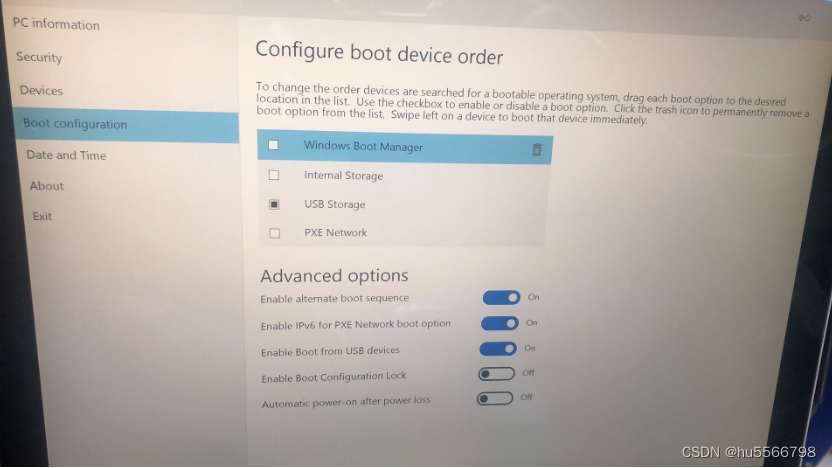
微软Surface/Surface pro笔记本电脑进入bios界面
微软Surface笔记本电脑进入bios界面 方法一推薦這種方法:Surface laptop 进BIOS步骤 开机后,不停按音量键进bios界面。 方法二:Surface Book、Surface Pro进bios步骤 1、关闭Surface,然后等待大约10秒钟以确保其处于关闭状态。…...

暂存2暂存2暂存2
暂存2暂存2暂存2...
深入理解TensorFlow:计算图的重要性与应用
TensorFlow是一个流行而强大的机器学习框架,其核心概念之一是计算图(computation graph)。计算图在TensorFlow中扮演着重要角色,作为一种数据流图表示形式,它能够将计算的过程可视化,同时方便优化、分布式计…...

20231114在HP笔记本的ubuntu20.04系统下向RealmeQ手机发送PDF文件
20231114在HP笔记本的ubuntu20.04系统下向RealmeQ手机发送PDF文件 2023/11/14 14:11 手机:Realme Q 笔记本电脑:HP https://item.jd.com/100012583174.html 惠普(HP)战66 三代AMD版 14英寸轻薄笔记本电脑(锐龙7nm 六核…...

【0234】PgBackendStatus 记录当前postgres进程的活动状态
1. 关于PgBackendStatus 每个存活的后端进场在共享内存中维护一个PgBackendStatus结构体,显示其当前活动状态。(结构体是根据BackendId分配的,但这并不重要。) 请注意: 进场状态收集器进程不参与、甚至不访问这些结构。 每个辅助进程还在共享内存中维护一个PgBackendStatu…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...
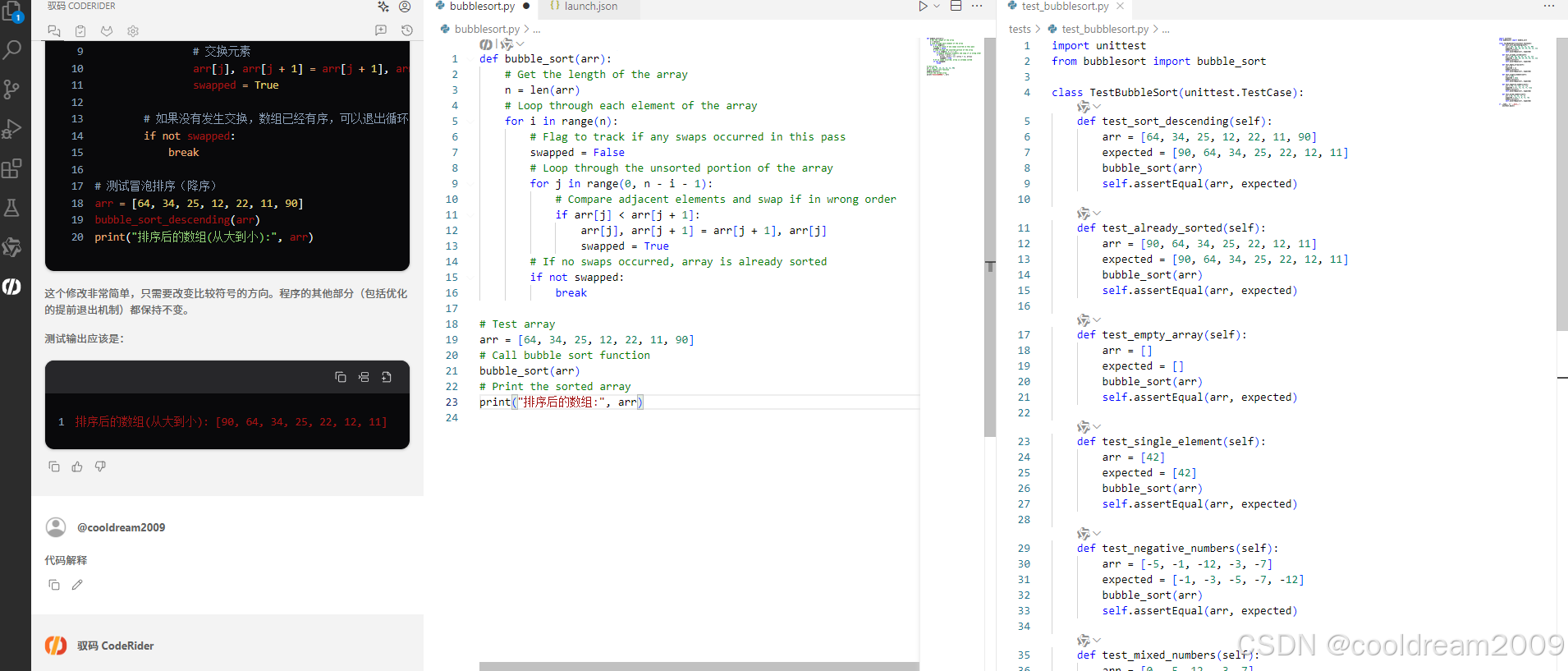
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...