数据的存储--MongoDB文档存储
MongoDB文档存储
NoSQL,全称为Not Only SQL,意为不仅仅是SQL,泛指非关系型数据库。NoSQL是基于键值对的,而且不需要经过SQL层的解析,数据之间没有耦合性,性能非常高。
非关系行数据库又可细分如下。
- 键值存储数据库:代表有Redis、Voldemort和Oracle BDB等。
- 列存储数据库:代表有Cassandra、HBase和Riak等。
- 文档型数据库:代表有CouchDB和MongoDB等。
- 图形数据库:代表有Neo4J、InfoGrid和Infinite Graph等。
MongoDB是由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容的存储形式类似JSON对象。它的字段值可以包含其他文档、数组及文档数组,非常灵活。
1. 准备工作
首先确保已经安装好了MongoDB并启动了其服务,还需要安装好Python的PyMongo库,可以使用pip3来安装:
pip3 install pymongo
2.连接MongoDB
连接MongoDB时,需要使用PyMongo库里面的MongoClient方法,一般而言,传入MongoDB的IP及端口即可。MongoClient方法的第一个参数为地址host,第二个参数为端口port(如果不传入此参数,默认取值为27017):
import pymongo
client = pymongo.MongoClient(host='localhost', port=27017)
这样就创建MongoDB第连接对象了。
另外,还可以直接给MongoClient的第一个参数host传入MongoDB的连接字符串,它以mongoldb开头,例如:
client = MongoClient('mongodb://localhost:27017/')
这样可以达到同样的连接效果。
3.指定数据库
在MongoDB中,可以建立多个数据库,所以我们需要指定操作哪个数据库。这里我们以指定test数据库为例来说明:
db = client.test
这里调用client的test属性即可返回test数据库。当然,也可以这样指定:
db = client['test']
4.指定集合
MongoDB的每个数据库又都包含许多集合(collection),这些集合类似于关系型数据库中的表。下一步需要指定要操作哪些集合,这里指定一个集合,名称为students。与指定数据库类似,指定集合也有两种方式:
collection = db.students
或
collection = db['students']
这样我们便声明了一个集合对象。
5.插入数据
接下来,便可以插入数据了。在students这个集合中,新建一条学生数据,这条数据以字典形式表示:
student = {'id':'20170101','name': 'Jordan','age': 20,'gender': 'male'
}
这里指定了学生的学号、姓名、年龄和性别。然后直接调用collection类的insert方法即可插入数据,代码如下:
result = collection.insert_one(student)
print(result)
在MongoDB中,每条数据都有一个_id属性作为唯一标识。如果没有显式指明该属性,那么MongoDB会自动产生一个ObjectId类型的_ _id属性,insert方法会在执行后返回_id值。
运行结果如下:
6554af645035eca6670c261f
当然,也可以同时插入多条数据,只需要以列表形式传递即可,实例如下:
student1 = {'id': '20170103','name': 'Bob','age': 28,'gender': 'male'
}student2 = {'id': '20170204','name': 'Mike','age':32,'gender': 'male'
}result = collection.insert_many([student1, student2])
print(result)
print(result.inserted_ids)
返回结果是对应的_id的集合:
[ObjectId('6554b13f43d77fb882124952'), ObjectId('6554b13f43d77fb882124953')]
6.查询
插入数据后, 我们可以利用find_one或find方法进行查询,用前者查询得到的是单个结果,后者则会返回一个生成器对象。实例代码如下:
import pymongoclient = pymongo.MongoClient(host='localhost', port=27017)db = client.test
collection = db.studentsresult = collection.find_one({'name': 'Mike'})
print(result)
print(type(result))
这里我们查询name值为Mike的数据,运行结果如下:
{'_id': ObjectId('65548291f1761603ce61adad'), 'id': '20170102', 'name': 'Mike', 'age': 21, 'gender': 'male'}
<class 'dict'>
可以发现,结果是字典类型,它多了_id属性,这就是MongoDB在插入数据过程中自动添加的。此外,我们也可以根据ObjectId来查询数据,此时需要使用bson库里面的objectid:
from bson.objectid import ObjectIdresult = collection.find_one({'_id': ObjectId('6554b13f43d77fb882124952')})
print(result)
其查询结果依然是字典类型,具体如下:
{'_id': ObjectId('6554b13f43d77fb882124952'), 'id': '20170103', 'name': 'Bob', 'age': 28, 'gender': 'male'}
当然, 如果查询结果不存在,则会返回None。
若要查询多条数据,可以使用find方法。例如,查找age为20的数据,实例代码如下:
results = collection.find({'age': 20})
print(results)
for result in results:print(result)
运行结果如下:
<pymongo.cursor.Cursor object at 0x108fdbc10>
{'_id': ObjectId('65548291f1761603ce61adad'), 'id': '20170102', 'name': 'Mike', 'age': 20, 'gender': 'male'}
{'_id': ObjectId('6554af645035eca6670c261f'), 'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male'}
{'_id': ObjectId('6554b13f43d77fb882124952'), 'id': '20170103', 'name': 'Bob', 'age': 20, 'gender': 'male'}
返回结果是Cursor类型,相当于一个生成器,通过遍历能够获取所有的结果,其中每个结果都是字典类型。
如果要查询age大于20的数据,则写法如下:
results = collection.find({'age': {'$gt':20}})
print(results[0])
这里查询条件中的键值已经不是单纯的数字了,而是一个字典,其键名为比较符号$gt,意思是大于;键值为20。
这里将比较符号归纳为表如下:
#### 比较符号
| 符 号 | 含 义 | 实 例 |
|---|---|---|
| $lt | 小于 | {‘age’: {‘$lt’: 20}} |
| $gt | 大于 | {‘age’: {‘$gt’: 20}} |
| $lte | 小于等于 | {‘age’: {‘$lte’: 20}} |
| $gte | 大于等于 | {‘age’: {‘$gte’: 20}} |
| $ne | 不等于 | {‘age’: {‘$ne’: 20}} |
| $in | 在范围内 | {‘age’: {‘$in’: [20, 23]}} |
| ¥nin | 不在范围内 | {‘age’: {‘nin’: [20, 23]}} |
另外,还可以进行正则匹配查询。例如,执行以下代码查询name以M开头的学生数据:
results = collection.find({'$regex': '^M.*'})
这里使用$regex来指定正则匹配,^M.*代表以M为开头的正则表达式。
下面将一些功能符号归类为下表:
功能符号
| 符 号 | 含 义 | 实 例 | 实例含义 |
|---|---|---|---|
| $regex | 匹配正则表达式 | {‘name’: {‘regex’: ‘^M.*’}} | name以M开头 |
| $exists | 属性是否存在 | {‘name’: {‘$exists’: True}} | 存在name属性 |
| $type | 类型判断 | {‘age’: {‘$type’: ‘int’}} | age的类型为int |
| $mod | 数字模操作 | {‘age’: {‘$mod’: {5, 0}}} | age模5余0 |
| $text | 文本查询 | {‘KaTeX parse error: Expected '}', got 'EOF' at end of input: text': {'search’: ‘Mike’}} | text类型的属性中包含Mike字符串 |
| $where | 高级条件查询 | {‘$where’: ‘obj.fans_count == obj.follows_count’} | 自身粉丝数等于关注数 |
7.计数
要统计查询结果包含多少条数据,可以调用count方法。例如统计所有数据条数,代码如下:
count = collection.find().count()
print(count)
统计符合某个条件的数据有多少条,代码如下:
count = collection.find({'age': 20}).count()
print(count)
运行结果是一个数值,即符合条件的数据条数。
8.排序
排序时,直接调用sort方法,并传入排序的字段及升降序标志即可。实例代码如下:
import pymongo
# 连接数据库
client = pymongo.MongoClient(host='localhost', port=27017)
# 指定数据库
db = client.test
# 指定集合
collection = db.students
# 调用sort方法
results = collection.find().sort('name', pymongo.ASCENDING)
print([result['name'] for result in results])
运行结果如下:
['Bob', 'Jordan', 'Mike', 'Nani']
这里我们调用pymongo.ASCENDING指定按生序排序。如果要降序,可以传入pymongo.DESCENDINg。
9.偏移
在某些情况下,可能只想取某几个元素,这时可以利用skip方法偏移几个位置,例如偏移2,即可忽略前两个元素,获取第三个及以后的元素:
import pymongoclient = pymongo.MongoClient(host='localhost', port=27017)db = client.testcollection = db.studentsresults = collection.find().sort('name', pymongo.ASCENDING).skip(2)
print([result['name'] for result in results])
运行结果如下:
['Mike', 'Nani']
另外,还可以使用limit方法指定要获取的结果个数,实例代码如下:
results = collection.find().sort('name', pymongo.ASCENDING).skip(1).limit(3)
print([result['name'] for result in results])
运行结果如下:
['Jordan', 'Mike', 'Nani']
值得注意的是, 在数据库中数据量非常庞大的时候(例如千万、亿级别),最好不要使用大偏移量来查询数据,因为这样很可能导致内存溢出。此时可以使用类似如下操作来查询:
from bson.objectid import ObjectId
collection.find({'_id': {'$gt': ObjectId('65548291f1761603ce61adad')}})
这里需要记录好上次查询的_id。
10.更新
对于数据更新,我们可以使用update_one方法,在其中指定更新的条件和更新后的数据即可。例如:
import pymongoclient = pymongo.MongoClient(host='localhost', port=27017)db = client.testcollection = db.studentscondition = {'name': 'Jordan'}
student = collection.find_one(condition)
student['age'] = 25
result = collection.update_one(condition, {'$set': student})
print(result)
print(result.matched_count, result.modified_count)
这里调用的是update_one方法,其第二个参数不能再直接传入修改后的字典,而是需要使用{‘$set’: student}这种形式的数据。然后分别调用matched_count和modified_count属性,可以获得匹配的数据条数和影响的数据条数。
运行结果如下:
<pymongo.results.UpdateResult object at 0x10ae5bbe0>
1 0
可以发现update_one 方法的返回结果是UpdateResult类型。我们再看一个例子:
condition = {'age': {'$gt': 20}}
result = collection.update_one(condition, {'$inc': {'age': 1}})
print(result)
print(result.matched_count, result.modified_
这里查询条件为age大于20,然后更新条件是{‘$inc’: {‘age’: 1}}, 也就是对age加1,因此执行update_one方法之后,会对第一条符合查询条件的学生数据的age加1。
运行结果如下:
<pymongo.results.UpdateResult object at 0x10aa59c70>
1 1
可以看到匹配条数为1条,影响条数也是1条。
但如果调用update_many方法,则会更新所有符合条件的数据,实例代码如下:
condition = {'age': {'$gt': 20}}
result = collection.update_many(condition, {'$inc': {'age': 1}})
print(result)
print(result.matched_count, result.modified_count)
运行结果如下:
<pymongo.results.UpdateResult object at 0x10dfd9c70>
2 2
11.删除
删除操作比较简单,直接调用delete_one方法和delete_many。delete_one删除第一条符合条件的数据,delete_many删除所有符合条件的数据均会被删除。实例代码如下:
import pymongoclient = pymongo.MongoClient(host='localhost', port=27017)db = client.testcollection = db.studentsresult = collection.delete_one({'name': '赵玲薇'})
print(result)
删除多条数符合条件的数据,实例代码如下:
result = collection.delete_many({'age': {'$gt': 19}})
print(result.deleted_count)
运行结果如下:
3
调用delete_count属性获取删除的数据条数。
12.其他操作
除了以后操作,PyMongo还提供了一些组合方法,例如find_one_and_delete、find_one_and_replace和find_one_and_update,分别是查找后删除、替换和更新操作,用法与上述方法基本一致。
相关文章:

数据的存储--MongoDB文档存储
MongoDB文档存储 NoSQL,全称为Not Only SQL,意为不仅仅是SQL,泛指非关系型数据库。NoSQL是基于键值对的,而且不需要经过SQL层的解析,数据之间没有耦合性,性能非常高。 非关系行数据库又可细分如下。 键值存…...

Notepad++ 通过HexEditor插件查看.hprof文件、heap dump文件的堆转储数据
文章目录 需求场景插件安装查看notepad的版本,看看是32位的还是64位的下载对应的版本解压导入插件打开notepad插件文件夹:Notepad安装目录新建一个HexEditor文件夹选中插件文件导入 重启notepad使用 需求场景 想要查看app内存的某个域的数据。 利用Andr…...
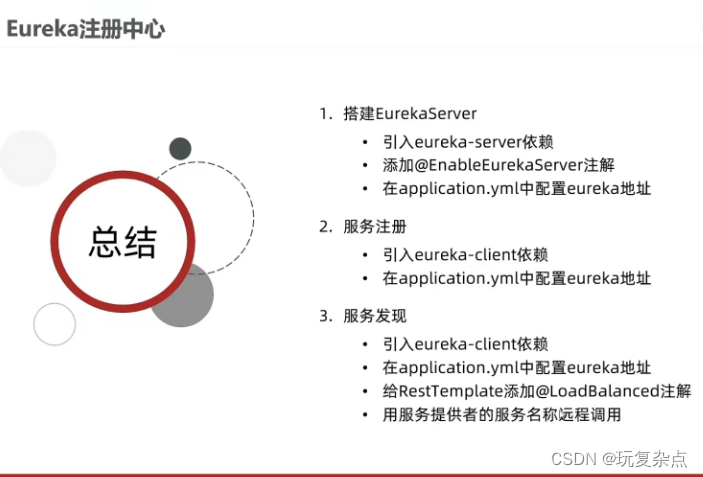
微服务学习 | Eureka注册中心
微服务远程调用 在order-service的OrderApplication中注册RestTemplate 在查询订单信息时,需要同时返回订单用户的信息,但是由于微服务的关系,用户信息需要在用户的微服务中去查询,故需要用到上面的RestTemplate来让订单的这个微…...

spring boot集成quartz
目录 1.定时任务实现 2.quartz说明 3.存储方式 4.示例 5.定时任务的重新定制,恢复,暂停及删除 1.定时任务实现 定时任务的实现方式有很多,如下: 1.启动类中添加EnableScheduling,开启定时任务功能,然…...

[Linux] yum仓库相关
一、yum仓库 1.1 yum简介 yum 是一种基于 RPM 软件包(Red-Hat Package Manager 的缩写)的软件更新机制,可自动解决软件包之间的依赖关系。这就解决了日常工作中花费大量时间寻找安装包的问题。 为什么会出现依赖 linux 本身就有简化系统的优…...
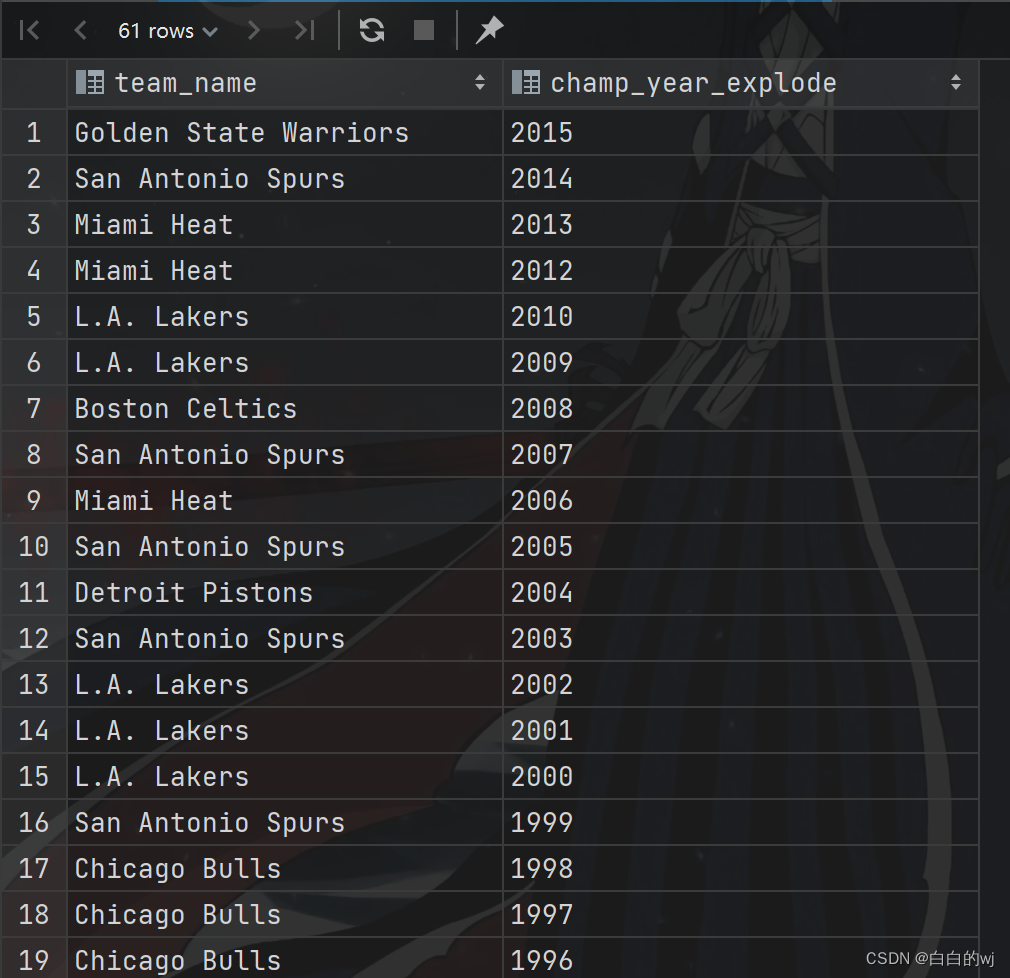
2023.11.15-hivesql之炸裂函数explode练习
把一个容器的多个数据炸裂出单独展示: explode(容器) 需求:将NBA总冠军球队数据使用explode进行拆分,并且根据夺冠年份进行倒序排序。 1.建表 --step1:建表 create table the_nba_championship(team_name string,champion_year array<string> ) row format…...

Linux - 内核 - 安全机制 - 内存页表安全
说明 内核页表安全的最终目标是:将内核使用到的内存页(内核与module占用)的属性(读/写/可执行)配置成安全的,即:代码段和rodata段只读,非代码段不能执行等,用来防御堆栈…...
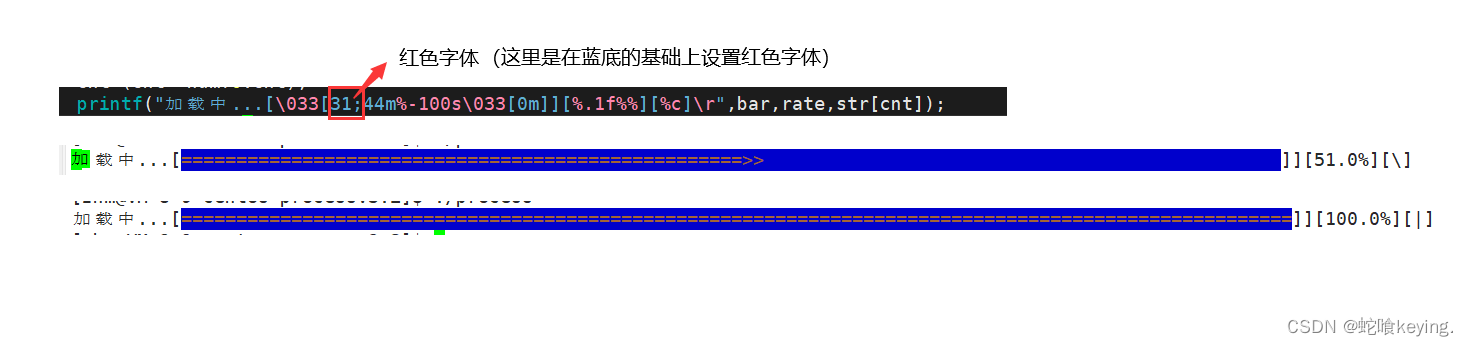
Linux---(七)Makefile写进度条(三个版本)
文章目录 一、前提引入🎗️下面的代码什么现象?🎗️下面的代码什么现象? 二、缓冲区三、回车换行🎗️注意🎗️图解🎗️老式回车键造型(意思是充当两个动作)🎗…...

数据库分页查询
数据库只所以要分页查询,其实是界面显示的需要,不是数据库的需要。 数据库本身查询是很快的。本文章是针对这种情况的。 如果数据库本身查询慢,那是优化查询语句的事情了。不在本文章范围内。 今天遇到了这个问题。 是个老项目。在原有的查询…...

如何选择合适的数据库管理工具?Navicat Or DBeaver
写在前面 在阅读本文之前,糖糖给大家准备了Navicat和DBeaver安装包,在公众号内回复“Navicat”或“DBeaver”或"数据库管理工具"来下载。 引言 对于测试而言,在实际工作中往往会用到数据库,那么选择使用哪种类型的数…...
Opencv!!在树莓派上安装Opencv!
一、更新树莓派系统 sudo apt-get update sudo apt-get upgrade二、安装python-opencv sudo apt-get install libopencv-dev sudo apt-get install python3-opencv三、查看是否安装成功 按以下命令顺序执行: python import cv2 cv2.__version__如果出现版本号&a…...
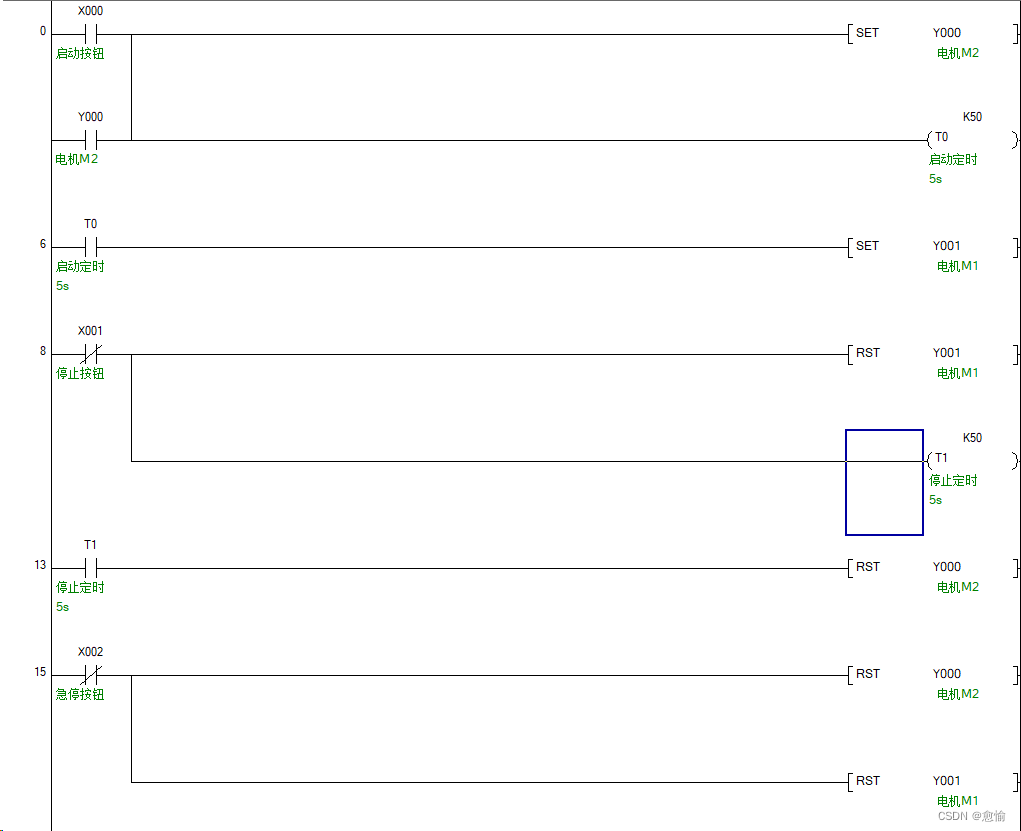
三菱FX3U小项目—传输带定分级控制
目录 一、项目描述 二、IO口分配 三、项目程序 四、总结 一、项目描述 两条运输带顺序相连,为了避免运送的物料在1号运输线上堆积,所以启动时,1号运输带开始运行,5S后2号运输带自动启动。停机时顺序与启动刚好相反,…...

实例解释遇到前端报错时如何排查问题
前端页面报错: 1、页面报错500,首先我们可以知道是服务端的问题,需要去看下服务端的报错信息: 2、首先我们查看下前端是否给后端传了id: 我们可以看到接口是把ID返回了,就需要再看下p_id是什么情况了。 3、我们再次请…...

微电影分销付费短剧小程序开发
微电影系统分销管理付费软件是一款面向微电影制作公司和影视产业的付费软件,它的出现旨在帮助微电影制作公司和影视产业实现分销管理,提高产业的效率和竞争力。本文将介绍微电影系统分销管理付费软件的背景、特点和开发方法。 一、背景 微电影作…...

时间序列预测中的4大类8种异常值检测方法(从根源上提高预测精度)
一、本文介绍 本文给大家带来的是时间序列预测中异常值检测,在我们的数据当中有一些异常值(Outliers)是指在数据集中与其他数据点显著不同的数据点。它们可能是一些极端值,与数据集中的大多数数据呈现明显的差异。异常值可能由于…...
Android---Gradle 构建问题解析
想必做 Android App 开发的对 Gradle 都不太陌生。因为有 Android Studio 的帮助,Android 工程师使用 Gradle 的门槛不算太高,基本的配置都大同小异。只要在 Android Studio 默认生成的 build.gradle 中稍加修改,就都能满足项目要求。但是&am…...

02-2解析JsonPath
一、jsonpath的安装及使用方式 pip安装 pip install jsonpathjsonpath的使用 obj json.load(open(json文件, r, encodingutf‐8)) ret jsonpath.jsonpath(obj, jsonpath语法)可以参考以下这篇博客进行jsonpath的简单入门JSONPath-简单入门...

Git拉取远程指定分支
git clone 指定分支-CSDN博客 即:git clone -b 分支名称 git地址 这种方法也是可以的。但是其实主分支也是拉取下来了,其他分支也拉取下来了,只不过所需分支也拉取下来并且对应当前工作区的代码。如果真的只拉取指定分支,可以用…...
使用Ant Design Pro开发时的一个快速开发接口请求的技巧
使用Ant Design Pro开发时的一个快速开发接口的技巧 当我们的后端在写好接口以后,我们通过swagger knife4j可以生成一个接口文档,后端启动以后,可以生成一个接口文档,当输入地址 localhost:8101/api/v3/api-docs (这…...

m1 rvm install 3.0.0 Error running ‘__rvm_make -j8‘
在使用M1 在安装cocopods 前时,安装 rvm install 3.0.0遇到 rvm install 3.0.0 Error running __rvm_make -j8 备注: 该图片是借用其他博客图片,因为我的环境解决完没有保留之前错误信息。 解决方法如下: 1. brew uninstall --ignore-depe…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...