使用GPT-4训练数据微调GPT-3.5 RAG管道
原文:使用GPT-4训练数据微调GPT-3.5 RAG管道 - 知乎
OpenAI在2023年8月22日宣布,现在可以对GPT-3.5 Turbo进行微调了。也就是说,我们可以自定义自己的模型了。然后LlamaIndex就发布了0.8.7版本,集成了微调OpenAI gpt-3.5 turbo的功能
也就是说,我们现在可以使用GPT-4生成训练数据,然后用更便宜的API(gpt-3.5 turbo)来进行微调,从而获得更准确的模型,并且更便宜。所以在本文中,我们将使用NVIDIA的2022年SEC 10-K文件来仔细研究LlamaIndex中的这个新功能。并且将比较gpt-3.5 turbo和其他模型的性能。
RAG vs 微调
微调到底是什么?它和RAG有什么不同?什么时候应该使用RAG和微调?以下两张总结图:


这两个图像总结了它们基本的差别,为我们选择正确的工具提供了很好的指导。
但是,RAG和微调并不相互排斥。将两者以混合方式应用到同一个应用程序中是完全可行的。

RAG/微调混合方法
LlamaIndex提供了在RAG管道中微调OpenAI gpt-3.5 turbo的详细指南。从较高的层次来看,微调可以实现下图中描述的关键任务:

- 使用DatasetGenerator实现评估数据集和训练数据集的数据生成自动化。
- 在微调之前,使用第1步生成的Eval数据集对基本模型gpt-3.5-turbo进行Eval。
- 构建向量索引查询引擎,调用gpt-4根据训练数据集生成新的训练数据。
- 回调处理程序OpenAIFineTuningHandler收集发送到gpt-4的所有消息及其响应,并将这些消息保存为.jsonl (jsonline)格式,OpenAI API端点可以使用该格式进行微调。
- OpenAIFinetuneEngine是通过传入gpt-3.5-turbo和第4步生成的json文件来构造的,它向OpenAI发送一个微调调用,向OpenAI发起一个微调作业请求。
- OpenAI根据您的要求创建微调的gpt-3.5-turbo模型。
- 通过使用从第1步生成的Eval数据集来对模型进行微调。
简单的总结来说就是,这种集成使gpt-3.5 turbo能够对gpt-4训练的数据进行微调,并输出更好的响应。
步骤2和7是可选的,因为它们仅仅是评估基本模型与微调模型的性能。
我们下面将演示这个过程,在演示时,使用NVIDIA 2022年的SEC 10-K文件。
主要功能点
1、OpenAIFineTuningHandler
这是OpenAI微调的回调处理程序,用于收集发送到gpt-4的所有训练数据,以及它们的响应。将这些消息保存为.jsonl (jsonline)格式,OpenAI的API端点可以使用该格式进行微调。
2、OpenAIFinetuneEngine
微调集成的核心是OpenAIFinetuneEngine,它负责启动微调作业并获得一个微调模型,可以直接将其插件到LlamaIndex工作流程的其余部分。
使用OpenAIFinetuneEngine, LlamaIndex抽象了OpenAI api进行微调的所有实现细节。包括:
- 准备微调数据并将其转换为json格式。
- 使用OpenAI的文件上传微调数据。创建端点并从响应中获取文件id。
- 通过调用OpenAI的FineTuningJob创建一个新的微调作业。创建端点。
- 等待创建新的微调模型,然后使用新的微调模型。
我们可以使用OpenAIFinetuneEngine的gpt-4和OpenAIFineTuningHandler来收集我们想要训练的数据,也就是说我们使用gpt-4的输出来训练我们的自定义的gpt-3.5 turbo模型
from llama_index import ServiceContext
from llama_index.llms import OpenAI
from llama_index.callbacks import OpenAIFineTuningHandler
from llama_index.callbacks import CallbackManager # use GPT-4 and the OpenAIFineTuningHandler to collect data that we want to train on.
finetuning_handler = OpenAIFineTuningHandler()
callback_manager = CallbackManager([finetuning_handler]) gpt_4_context = ServiceContext.from_defaults( llm=OpenAI(model="gpt-4", temperature=0.3), context_window=2048, # limit the context window artifically to test refine process callback_manager=callback_manager,
) # load the training questions, auto generated by DatasetGenerator
questions = []
with open("train_questions.txt", "r") as f: for line in f: questions.append(line.strip()) from llama_index import VectorStoreIndex # create index, query engine, and run query for all questions
index = VectorStoreIndex.from_documents(documents, service_context=gpt_4_context)
query_engine = index.as_query_engine(similarity_top_k=2) for question in questions: response = query_engine.query(question) # save fine-tuning events to jsonl file
finetuning_handler.save_finetuning_events("finetuning_events.jsonl") from llama_index.finetuning import OpenAIFinetuneEngine # construct OpenAIFinetuneEngine
finetune_engine = OpenAIFinetuneEngine( "gpt-3.5-turbo", "finetuning_events.jsonl"
) # call finetune, which calls OpenAI API to fine-tune gpt-3.5-turbo based on training data in jsonl file.
finetune_engine.finetune() # check current job status
finetune_engine.get_current_job() # get fine-tuned model
ft_llm = finetune_engine.get_finetuned_model(temperature=0.3)需要注意的是,微调函数需要时间,对于我测试的169页PDF文档,从在finetune_engine上启动finetune到收到OpenAI的电子邮件通知我新的微调工作已经完成,这段时间大约花了10分钟。下面的电子邮件如下。

在收到该电子邮件之前,如果在finetune_engine上运行get_finetuned_model,会得到一个错误,提示微调作业还没有准备好。
3、ragas框架
ragas是RAG Assessment的缩写,它提供了基于最新研究的工具,使我们能够深入了解RAG管道。
ragas根据不同的维度来衡量管道的表现:忠实度、答案相关性、上下文相关性、上下文召回等。对于这个演示应用程序,我们将专注于衡量忠实度和答案相关性。
忠实度:衡量给定上下文下生成的答案的信息一致性。如果答案中有任何不能从上下文推断出来的主张,则会被扣分。
答案相关性:指回答直接针对给定问题或上下文的程度。这并不考虑答案的真实性,而是惩罚给出问题的冗余信息或不完整答案。
在RAG管道中应用ragas的详细步骤如下:
- 收集一组eval问题(最少20个,在我们的例子中是40个)来形成我们的测试数据集。
- 在微调之前和之后使用测试数据集运行管道。每次使用上下文和生成的输出记录提示。
- 对它们中的每一个运行ragas评估以生成评估分数。
比较分数就可以知道微调对性能的影响有多大。
代码如下:
contexts = []
answers = [] # loop through the questions, run query for each question
for question in questions: response = query_engine.query(question) contexts.append([x.node.get_content() for x in response.source_nodes]) answers.append(str(response)) from datasets import Dataset
from ragas import evaluate
from ragas.metrics import answer_relevancy, faithfulness ds = Dataset.from_dict( { "question": questions, "answer": answers, "contexts": contexts, }
) # call ragas evaluate by passing in dataset, and eval categories
result = evaluate(ds, [answer_relevancy, faithfulness])
print(result) import pandas as pd # print result in pandas dataframe so we can examine the question, answer, context, and ragas metrics
pd.set_option('display.max_colwidth', 200)
result.to_pandas()
评估结果 最后我们可以比较一下微调前后的eval结果。 基本gpt-3.5-turbo的评估请看下面的截图。answer_relevance的评分不错,但忠实度有点低。
经过微调,模型的性能在答案相关性中略有提高,从0.7475提高到0.7846,提高了4.96%。

使用gpt-4生成训练数据对gpt-3.5 turbo进行微调确实看到了改善。
一些有趣的发现
1、对小文档进行微调会导致性能下降
最初用一个小的10页PDF文件进行了实验,我发现eval结果与基本模型相比性能有所下降。然后又继续测试了两轮,结果如下:
第一轮基本模型:Ragas_score: 0.9122, answer_relevance: 0.9601, faithfulness: 0.8688
第一轮微调模型:Ragas_score: 0.8611, answer_relevance: 0.9380, faithfulness: 0.7958
第二轮基本模型:Ragas_score: 0.9170, answer_relevance: 0.9614, faithfulness: 0.8765
第二轮微调模型:Ragas_score: 0.8891, answer_relevance: 0.9557, faithfulness: 0.8313
所以换衣小文件可能是微调模型比基本模型表现更差的原因。所以使用了NVIDIA长达169页的SEC 10-K文件。对上面的结果做了一个很好的实验——经过微调的模型表现得更好,忠实度增加了4.96%。
2、微调模型的结果不一致
原因可能是数据的大小和评估问题的质量
尽管169页文档的微调模型获得了预期的评估结果,但我对相同的评估问题和相同的文档运行了第二轮测试,结果如下:
第二轮基本模型:Ragas_score: 0.8874, answer_relevance: 0.9623, faithfulness: 0.8233
第二轮微调模型:Ragas_score: 0.8218, answer_relevance: 0.9498, faithfulness: 0.7242
是什么导致了eval结果的不一致?
数据大小很可能是导致不一致的微调计算结果的根本原因之一。“至少需要1000个微调数据集的样本。”这个演示应用显然没有那么多的微调数据集。
另一个根本原因很可能在于数据质量,也就是eval问题的质量。我将eval结果打印到一个df中,列出了每个问题的问题、答案、上下文、answer_relevance和忠实度。
通过目测,有四个问题在忠实度中得分为0。而这些答案在文件中没有提供上下文。这四个问题质量很差,所以我从eval_questions.txt中删除了它们,重新运行了评估,得到了更好的结果:
基本模型eval:Ragas_score: 0.8947, answer_relevance: 0.9627, faithfulness: 0.8356

微调模型eval:Ragas_score: 0.9207, answer_relevance: 0.9596, faithfulness: 0.8847

可以看到在解决了这四个质量差的问题后,微调版的上升了5.9%。所以评估问题和训练数据需要更多的调整,以确保良好的数据质量。这确实是一个非常有趣的探索领域。
3、微调的成本
经过微调的gpt-3.5-turbo的价格高于基本模型的。我们来看看基本模型、微调模型和gpt-4之间的成本差异:
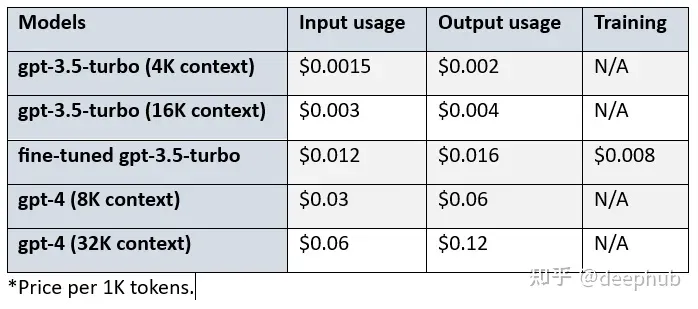
比较gpt-3.5-turbo (4K环境)、微调gpt-3.5-turbo和gpt-4 (8K环境),可以看到:
- 经过微调的gpt-3.5 turbo在输入和输出使用方面的成本是基本模型的8倍。
- 对于输入使用,Gpt-4的成本是微调模型的2.5倍,对于输出使用则是3.75倍。
- 对于输入使用,Gpt-4的成本是基本模型的20倍,对于输出使用情况是30倍。
- 另外使用微调模型会产生$0.008/1K 令牌的额外成本。
总结
本文探索了LlamaIndex对OpenAI gpt-3.5 turbo微调的新集成。我们通过NVIDIA SEC 10-K归档分析的RAG管道,测试基本模型性能,然后使用gpt-4收集训练数据,创建OpenAIFinetuneEngine,创建了一个新的微调模型,测试了它的性能,并将其与基本模型进行了比较。
可以看到,因为GPT4和gpt-3.5 turbo的巨大成本差异(20倍),在使用微调后,我们可以得到近似的效果,并且还能节省不少成本(2.5倍)
如果你对这个方法感兴趣,源代码在这里:
https://colab.research.google.com/github/wenqiglantz/nvidia-sec-finetuning/blob/main/nvidia_sec_finetuning.ipynb
作者:Wenqi Glantz
发布于 2023-09-06 10:09・IP 属地北京
相关文章:
使用GPT-4训练数据微调GPT-3.5 RAG管道
原文:使用GPT-4训练数据微调GPT-3.5 RAG管道 - 知乎 OpenAI在2023年8月22日宣布,现在可以对GPT-3.5 Turbo进行微调了。也就是说,我们可以自定义自己的模型了。然后LlamaIndex就发布了0.8.7版本,集成了微调OpenAI gpt-3.5 turbo的…...

二十三种设计模式全面解析-深入解析模板方法模式的奇妙世界
在软件设计的奇妙宇宙中,有一种设计模式如一颗流星般划过,留下绚丽的光芒,它就是——模板方法模式(Template Method Pattern)。这个模式不仅令代码更加灵活,而且蕴含了一种设计哲学,本文将深入研…...

【Spring】加载properties文件
文章目录 在Spring Context中加载properties文件测试总结 在Spring Context中加载properties文件 分为三步,如下图所示: 完整代码: <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.…...
react中间件的理解
一、是什么? 中间件(Middleware)在计算机中,是介于应用系统和系统软件之间的一类软件,它使用系统软件所提供的基础服务(功能),衔接网络应用上的各个部分或不同的应用,能…...
React函数组件状态Hook—useState《进阶-对象数组》
React函数组件状态-state 对象 state state 中可以保存任意类型的 JavaScript 值,包括对象。但是,你不应该直接修改存放在 React state 中的对象。相反,当你想要更新⼀个对象时,你需要创建⼀个新的对象(或者将其拷⻉⼀…...

linux 网络 cat /proc/net/dev 查看测试网络丢包情况
可以通过 cat /proc/net/dev 查看测试网络丢包情况,drop关键字,查看所有网卡的丢包情况 还可以看其他数据, /proc/net/下面有如下文件...

记录配置VS,使用opencv与Eigen
方法一: 1.下载VS 2.配置opencv,参考大佬博客,注意更改博客中版本的部分细节,比如opencv_world440d.lib换成自己下载的版本 3.配置Eigen,参考大佬博客 方法二:博客 本人第一次配置时候按照这篇内容配置的,但是不知道哪…...
uart控制led与beep
仲裁模块代码: // 外设控制模块,根据uart接收到的数据,控制led与beep的标志信号。 module arbit(input wire sys_clk ,input wire sys_rst_n ,input wire pi_flag …...

Linux修改root密码
如果知道当前的root密码,修改boot密码操作较简单。 步骤如下: # passwd --在root用户下执行passwd命令 Changing password for user root. New password: --此处输入新密码 BAD PASSWORD: The password is shorter than 8 characters Ret…...

C/C++模板类模板与函数模板区别,以及用法详解
类模板 类模板语法 类模板作用: 建立一个通用类,类中的成员 数据类型可以不具体制定,用一个虚拟的类型来代表。 语法: template<typename T> 类解释: template --- 声明创建模板 typename --- 表面其后面的…...
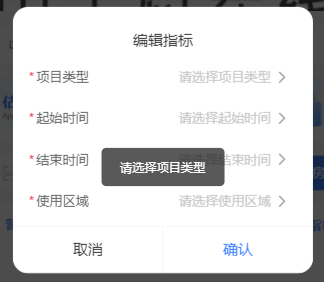
van-dialog弹窗异步关闭-校验表单
van-dialog弹窗异步关闭 有时候我们需要通过弹窗去处理表单数据,在原生微信小程序配合vant组件中有多种方式实现,其中UI美观度最高的就是通过van-dialog嵌套表单实现。 通常表单涉及到是否必填,在van-dialog的确认事件中直接return是无法阻止…...

Dynamic Wallpaper 16.7中文版
Macos动态壁纸推荐: Dynamic Wallpaper是一款Mac平台上的动态壁纸应用程序,它可以根据时间等因素动态切换壁纸,提供更加生动和多样化的桌面体验。 Dynamic Wallpaper包含了多个动态壁纸,用户可以根据自己的喜好选择和切换。这些…...
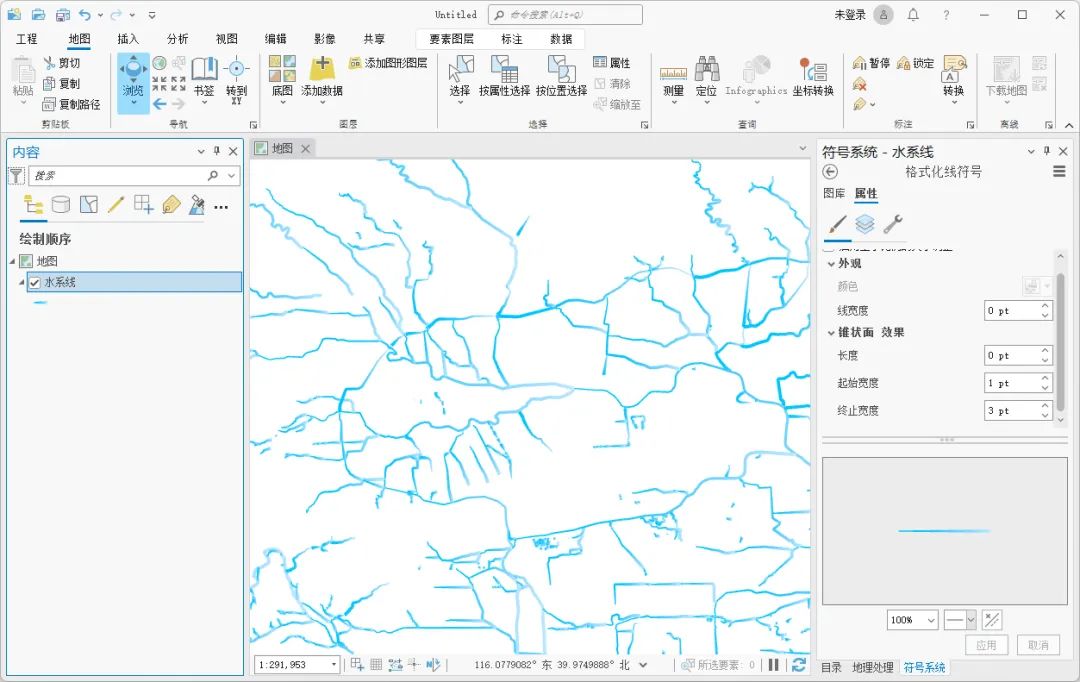
如何使用ArcGIS Pro制作渐变河流效果
对于面要素的河流水系,制作渐变效果方法比较简单,如果是线要素的河流有办法制作渐变效果吗,答案是肯定的,这里为大家介绍一下制作方法,希望能对你有所帮助。 数据来源 本教程所使用的数据是从水经微图中下载的水系数…...

《网络协议》06. HTTP 补充 · HTTPS · SSL/TLS
title: 《网络协议》06. HTTP 补充 HTTPS SSL/TLS date: 2022-10-06 18:09:55 updated: 2023-11-15 07:53:52 categories: 学习记录:网络协议 excerpt: HTTP/1.1 协议的不足、HTTP/2、HTTP/3、HTTP 协议的安全问题、SPDY、HTTPS、SSL/TLS、OpenSSL。 comments: fa…...
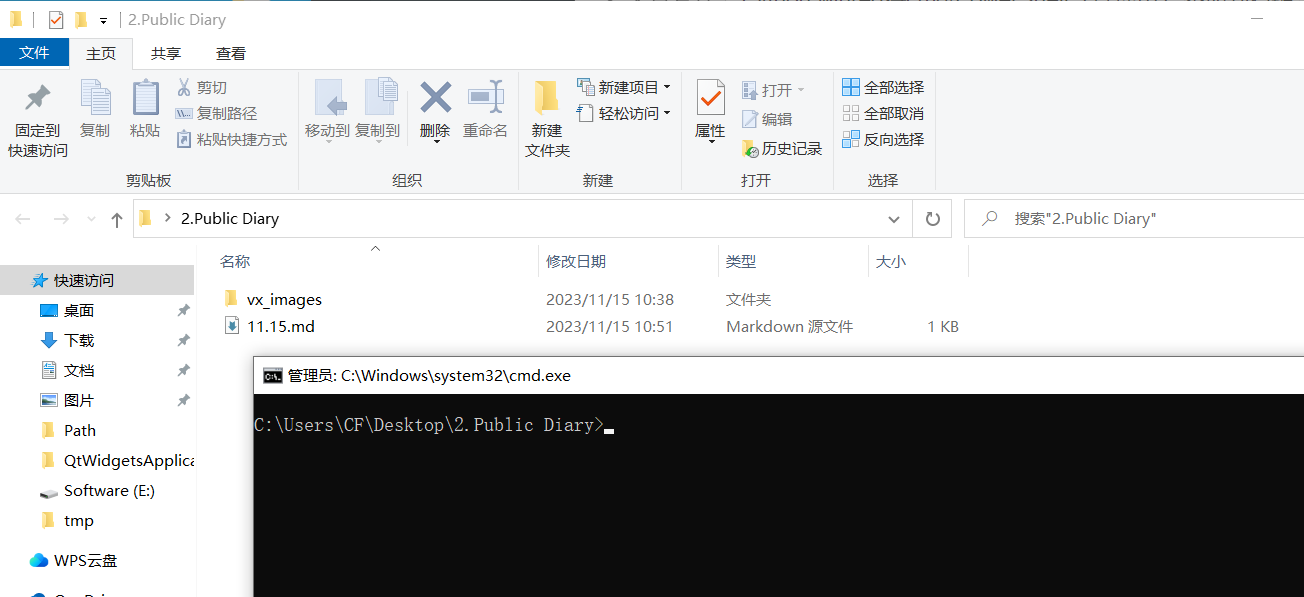
Python winreg将cmd/PowerShell(管理员)添加到右键菜单
效果 1. 脚本 用管理员权限运行,重复执行会起到覆盖效果(根据sub_key)。 icon自己设置。text可以自定义。sub_key可以改但不推荐(避免改成和系统已有项冲突的)。command不要改。 from winreg import *registry r&q…...
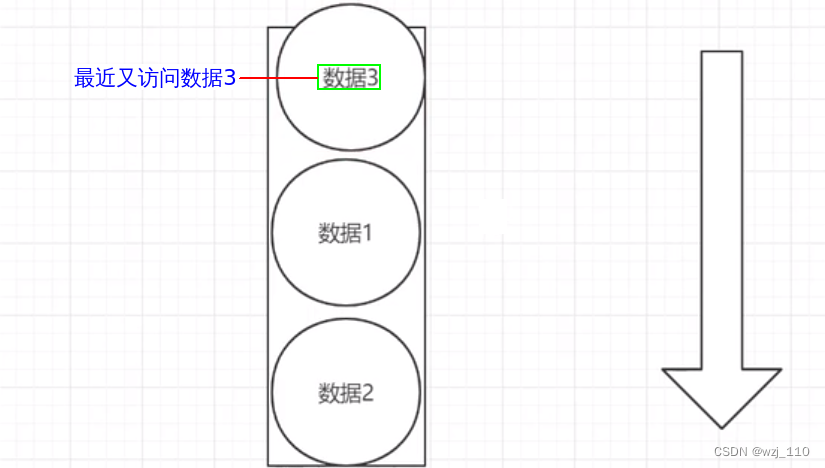
redis运维(九)字符串(二)字符串过期时间
一 字符串过期时间 细节点: 注意命令的入参和返回值 ① 再谈过期时间 说明: 设置key的同时并且设置过期时间,是一个原子操作 ② ttl 检查过期时间 ③ persist 删除过期时间 ④ redis 删除过期key的机制 ⑤ 惰性删除 惰性理解:让过期…...
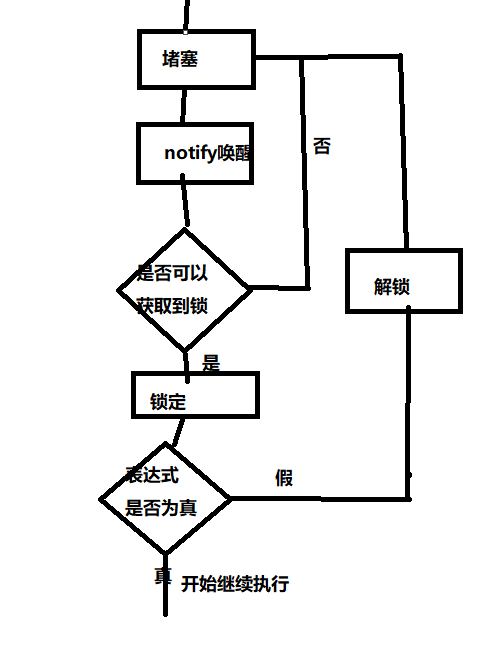
【C++】多线程的学习笔记(3)——白话文版(bushi
前言 好久没有继续写博客了,原因就是去沉淀了一下偷懒了一下 现在在学网络编程,c的多线程也还在学 这一变博客就讲讲c中的Condition Variable库吧 Condition Variable的简介 官方原文解释 翻译就是 条件变量是一个对象,它能够阻止调用…...

kotlin--3.集合操作
目录 一.list集合 二.Set集合 三.Map集合 迭代遍历Map集合: 8.hashMap 四.Stream流 1.map 2.filter 3.reduce 4.forEach 5.sorted 6.distinct 7.综合案例 一.list集合 在Kotlin中,常见的List集合类型有以下几种: listOf&…...
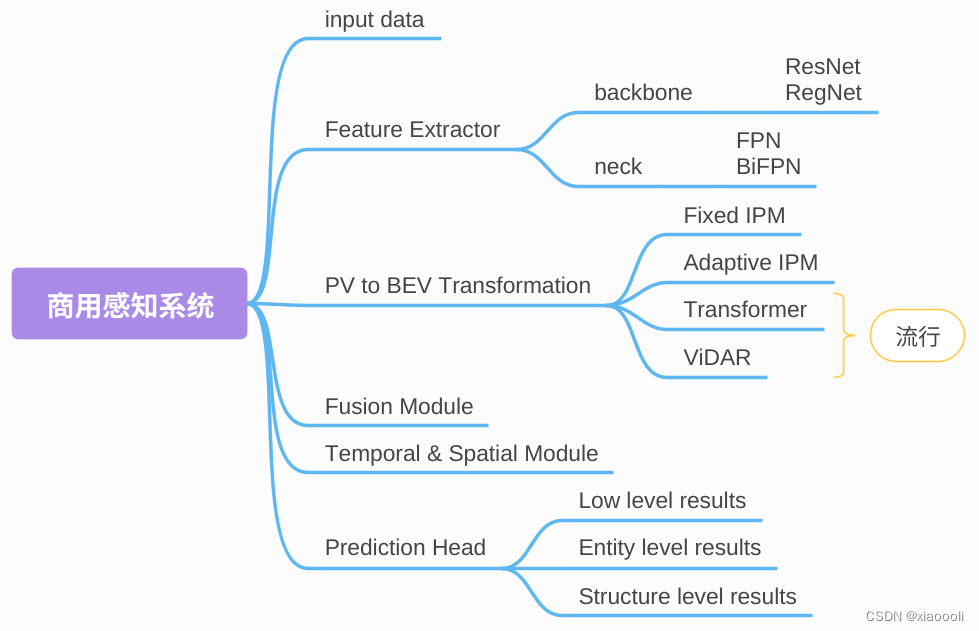
自动驾驶-BEV感知综述
BEV感知综述 随着自动驾驶传感器配置多模态化、多源化,将多源信息在unified View下表达变得更加关键。BEV视角下构建的local map对于多源信息融合及理解更加直观简洁,同时对于后续规划控制模块任务的开展也更为方便。BEV感知的核心问题是: …...
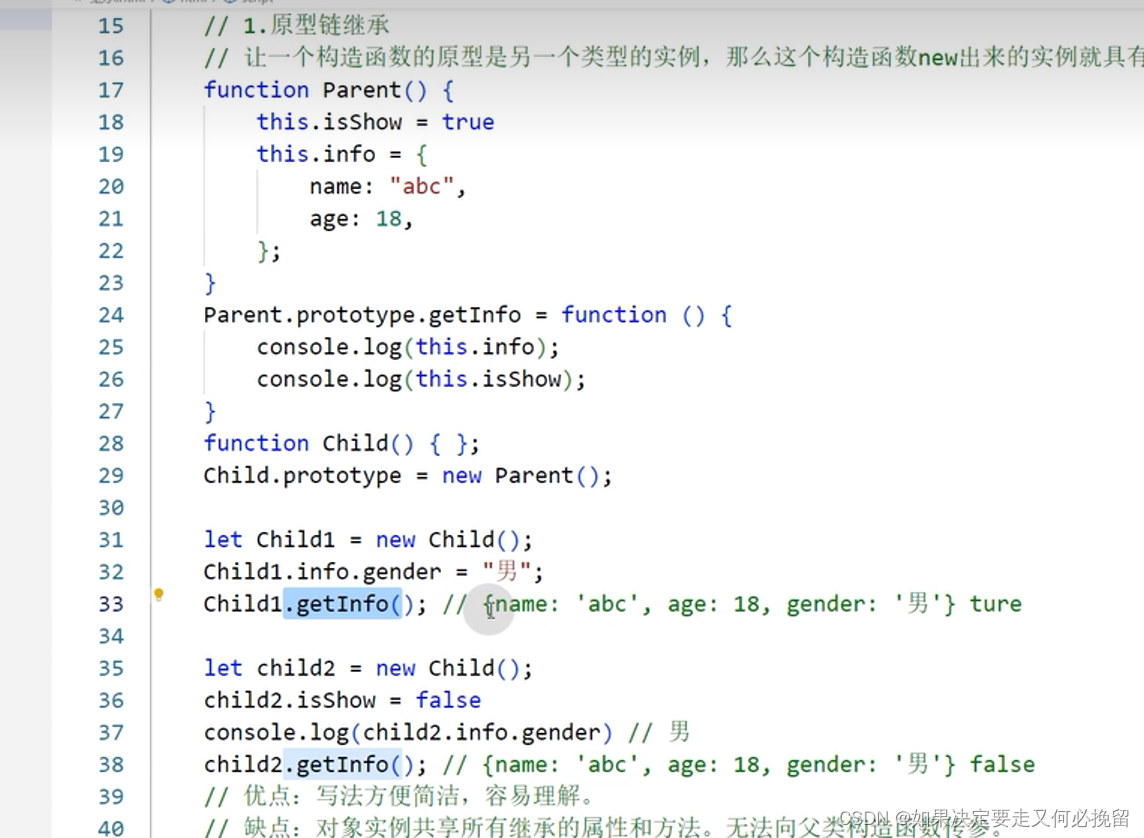
面试题-3
1.说一下原型链 原型就是一个普通对象,它是为构造函数实例共享属性和方法,所有实例中引用原型都是同一个对象 使用prototype可以把方法挂载在原型上,内存值保存一致 _proto_可以理解为指针,实例对象中的属性,指向了构造函数的原型(prototype) 2.new操…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...