【深度学习实验】网络优化与正则化(七):超参数优化方法——网格搜索、随机搜索、贝叶斯优化、动态资源分配、神经架构搜索
文章目录
- 一、实验介绍
- 二、实验环境
- 1. 配置虚拟环境
- 2. 库版本介绍
- 三、优化算法
- 0. 导入必要的库
- 1. 随机梯度下降SGD算法
- a. PyTorch中的SGD优化器
- b. 使用SGD优化器的前馈神经网络
- 2.随机梯度下降的改进方法
- a. 学习率调整
- b. 梯度估计修正
- 3. 梯度估计修正:动量法Momentum
- 4. 自适应学习率
- 5. Adam算法
- 四、参数初始化
- 五、数据预处理
- 六、逐层归一化
- 七、超参数优化
- 0. 前期准备
- a. 神经网络模型
- b. 训练和评估函数
- c. 分类数据
- 1. 网格搜索
- a. 基本步骤
- b. 代码实现
- 2. 随机搜索
- a. 基本步骤
- b. 优缺点
- c. 代码实现
- 3. 贝叶斯优化
- a.基本步骤
- b. 代码实现
- 4. 动态资源分配
- 5. 神经架构搜索
一、实验介绍
深度神经网络在机器学习中应用时面临两类主要问题:优化问题和泛化问题。
-
优化问题:深度神经网络的优化具有挑战性。
- 神经网络的损失函数通常是非凸函数,因此找到全局最优解往往困难。
- 深度神经网络的参数通常非常多,而训练数据也很大,因此使用计算代价较高的二阶优化方法不太可行,而一阶优化方法的训练效率通常较低。
- 深度神经网络存在梯度消失或梯度爆炸问题,导致基于梯度的优化方法经常失效。
-
泛化问题:由于深度神经网络的复杂度较高且具有强大的拟合能力,很容易在训练集上产生过拟合现象。因此,在训练深度神经网络时需要采用一定的正则化方法来提高网络的泛化能力。
目前,研究人员通过大量实践总结了一些经验方法,以在神经网络的表示能力、复杂度、学习效率和泛化能力之间取得良好的平衡,从而得到良好的网络模型。本系列文章将从网络优化和网络正则化两个方面来介绍如下方法:
- 在网络优化方面,常用的方法包括优化算法的选择、参数初始化方法、数据预处理方法、逐层归一化方法和超参数优化方法。
- 在网络正则化方面,一些提高网络泛化能力的方法包括ℓ1和ℓ2正则化、权重衰减、提前停止、丢弃法、数据增强和标签平滑等。
本文将介绍神经网络优化的逐层归一化方法,包括批量归一化、层归一化、权重归一化(略)、局部响应归一化(略)等
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7
conda activate DL
pip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib
conda install scikit-learn
2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
|---|---|---|
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、优化算法
神经网络的参数学习是一个非凸优化问题.当使用梯度下降法来进行优化网络参数时,参数初始值的选取十分关键,关系到网络的优化效率和泛化能力.参数初始化的方式通常有以下三种:
0. 导入必要的库
from torch import nn
1. 随机梯度下降SGD算法
随机梯度下降(Stochastic Gradient Descent,SGD)是一种常用的优化算法,用于训练深度神经网络。在每次迭代中,SGD通过随机均匀采样一个数据样本的索引,并计算该样本的梯度来更新网络参数。具体而言,SGD的更新步骤如下:
- 从训练数据中随机选择一个样本的索引。
- 使用选择的样本计算损失函数对于网络参数的梯度。
- 根据计算得到的梯度更新网络参数。
- 重复以上步骤,直到达到停止条件(如达到固定的迭代次数或损失函数收敛)。
a. PyTorch中的SGD优化器
Pytorch官方教程
optimizer = torch.optim.SGD(model.parameters(), lr=0.2)
b. 使用SGD优化器的前馈神经网络
【深度学习实验】前馈神经网络(final):自定义鸢尾花分类前馈神经网络模型并进行训练及评价
2.随机梯度下降的改进方法
传统的SGD在某些情况下可能存在一些问题,例如学习率选择困难和梯度的不稳定性。为了改进这些问题,提出了一些随机梯度下降的改进方法,其中包括学习率的调整和梯度的优化。
a. 学习率调整
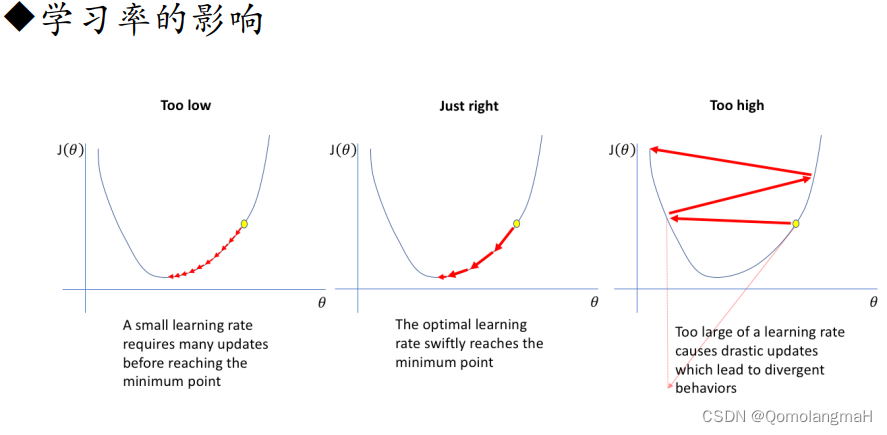
- 学习率衰减(Learning Rate Decay):随着训练的进行,逐渐降低学习率。常见的学习率衰减方法有固定衰减、按照指数衰减、按照时间表衰减等。
- Adagrad:自适应地调整学习率。Adagrad根据参数在训练过程中的历史梯度进行调整,对于稀疏梯度较大的参数,降低学习率;对于稀疏梯度较小的参数,增加学习率。这样可以在不同参数上采用不同的学习率,提高收敛速度。
- Adadelta:与Adagrad类似,但进一步解决了Adagrad学习率递减过快的问题。Adadelta不仅考虑了历史梯度,还引入了一个累积的平方梯度的衰减平均,以动态调整学习率。
- RMSprop:也是一种自适应学习率的方法,通过使用梯度的指数加权移动平均来调整学习率。RMSprop结合了Adagrad的思想,但使用了衰减平均来减缓学习率的累积效果,从而更加稳定。
b. 梯度估计修正
- Momentum:使用梯度的“加权移动平均”作为参数的更新方向。Momentum方法引入了一个动量项,用于加速梯度下降的过程。通过积累之前的梯度信息,可以在更新参数时保持一定的惯性,有助于跳出局部最优解、加快收敛速度。
- Nesterov accelerated gradient:Nesterov加速梯度(NAG)是Momentum的一种变体。与Momentum不同的是,NAG会先根据当前的梯度估计出一个未来位置,然后在该位置计算梯度。这样可以更准确地估计当前位置的梯度,并且在参数更新时更加稳定。
- 梯度截断(Gradient Clipping):为了应对梯度爆炸或梯度消失的问题,梯度截断的方法被提出。梯度截断通过限制梯度的范围,将梯度控制在一个合理的范围内。常见的梯度截断方法有阈值截断和梯度缩放。
3. 梯度估计修正:动量法Momentum
【深度学习实验】网络优化与正则化(一):优化算法:使用动量优化的随机梯度下降算法(Stochastic Gradient Descent with Momentum)
4. 自适应学习率
【深度学习实验】网络优化与正则化(二):基于自适应学习率的优化算法详解:Adagrad、Adadelta、RMSprop
5. Adam算法
Adam算法(Adaptive Moment Estimation Algorithm)[Kingma et al., 2015]可以看作动量法和 RMSprop 算法的结合,不但使用动量作为参数更新方向,而且可以自适应调整学习率。
【深度学习实验】网络优化与正则化(三):随机梯度下降的改进——Adam算法详解(Adam≈梯度方向优化Momentum+自适应学习率RMSprop)~入选综合热榜
四、参数初始化
【深度学习实验】网络优化与正则化(四):参数初始化及其Pytorch实现——基于固定方差的初始化(高斯、均匀分布),基于方差缩放的初始化(Xavier、He),正交初始化
五、数据预处理
【深度学习实验】网络优化与正则化(五):数据预处理详解——标准化、归一化、白化、去除异常值、处理缺失值~入选综合热榜
六、逐层归一化
【深度学习实验】网络优化与正则化(六):逐层归一化方法——批量归一化、层归一化、权重归一化、局部响应归一化
七、超参数优化
0. 前期准备
a. 神经网络模型
class SimpleNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, output_size)self.softmax = nn.Softmax(dim=1)def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.fc2(x)x = self.softmax(x)return x
b. 训练和评估函数
def train_and_evaluate(model, X_train, y_train, X_val, y_val, criterion, optimizer, epochs=10):for epoch in range(epochs):model.train()optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()model.eval()val_outputs = model(X_val)_, predictions = torch.max(val_outputs, 1)val_accuracy = accuracy_score(y_val.numpy(), predictions.numpy())return val_accuracy
c. 分类数据
在这里插入代码片
1. 网格搜索
网格搜索(Grid Search)是一种穷举搜索方法,它尝试在预定义的超参数空间中的所有可能组合中找到最佳配置。具体来说,如果总共有 K K K个超参数,每个超参数可以取 m k m_k mk 个不同的值,那么网格搜索将尝试 m 1 × m 2 × . . . × m K m_1 × m_2 × ... × m_K m1×m2×...×mK 个不同的超参数组合。
在网格搜索中,如果某些超参数是连续的,而不是离散的,可以将其离散化为几个"经验"值。这样做的目的是为了限制搜索空间,以便更有效地寻找最佳配置。虽然这种方法可能会在某些情况下忽略超参数的细微变化,但在实践中,它可以帮助减少搜索的复杂性。
网格搜索是一种简单但有效的方法,特别适用于超参数空间较小的情况。然而,对于超参数空间较大或高维的情况,随机搜索、贝叶斯优化或演化算法等方法可能更具优势,它们可以更灵活地探索超参数空间,而不会受到穷举搜索的限制。
a. 基本步骤
- 定义超参数空间: 首先,需要明确定义每个超参数的可能取值。这可以通过指定每个超参数的候选值范围来完成。
- 创建参数网格: 对于每个超参数,选择一组候选值。将这些候选值组合成一个网格,即每个超参数的所有可能组合。如果超参数的取值空间是离散的,那么可以使用所有可能的离散值;如果是连续的,可以选择一些合适的离散化值。
- 设置评估指标: 定义一个评估指标,用于度量每个超参数组合的性能。这通常是在验证集或开发集上的性能表现,如准确率、误差率等。目标是最小化或最大化该指标,具体取决于任务类型。
- 训练和评估模型: 对于每个超参数组合,在训练集上训练模型,并在验证集上评估性能。使用定义的评估指标来度量每个模型的性能。
- 选择最佳超参数组合: 通过比较所有超参数组合的性能,选择具有最佳性能的超参数组合。
- 可视化和分析: 可以通过可视化方法,如学习曲线或热力图,来进一步分析超参数的影响。这有助于了解模型在超参数空间中的表现。
- 验证和测试: 最终,使用选定的最佳超参数组合在测试集上验证模型的性能,确保所选超参数对未见数据的泛化效果。
b. 代码实现
hidden_sizes = [64, 128, 256]
learning_rates = [0.001, 0.01, 0.1]best_accuracy = 0
best_params = {}for hidden_size in hidden_sizes:for learning_rate in learning_rates:model = SimpleNN(input_size=20, hidden_size=hidden_size, output_size=2)optimizer = SGD(model.parameters(), lr=learning_rate)criterion = nn.CrossEntropyLoss()accuracy = train_and_evaluate(model, torch.FloatTensor(X_train), torch.LongTensor(y_train),torch.FloatTensor(X_test), torch.LongTensor(y_test), criterion, optimizer)if accuracy > best_accuracy:best_accuracy = accuracybest_params = {'hidden_size': hidden_size, 'learning_rate': learning_rate}print("Grid Search - Best Parameters:", best_params)
print("Grid Search - Best Accuracy:", best_accuracy)
2. 随机搜索
随机搜索是一种更灵活的超参数优化方法,相较于网格搜索,它不受先验定义的超参数网格的限制。通过在超参数空间中进行随机采样,随机搜索能够更有效地探索可能的超参数组合,特别是当某些超参数对模型性能的影响相对较小或难以预测时。
随机搜索的主要优势在于它避免了网格搜索中的过度尝试不重要的超参数组合。对于那些对性能有较大影响的超参数,随机搜索有更大的可能性在更早的阶段找到优秀的配置,而不受网格搜索的较粗略采样的限制。
a. 基本步骤
- 定义超参数空间: 确定每个超参数的可能取值范围。这可以是一个离散的集合,也可以是一个连续的区间。
- 选择随机超参数组合: 对于每次迭代,从超参数空间中随机选择一个超参数组合。这可以通过在每个超参数的取值范围内进行均匀或非均匀的随机采样来完成。
- 训练和评估模型: 使用所选的超参数组合,在训练集上训练模型,并在验证集或开发集上评估性能。这通常涉及训练模型直到收敛或达到预定义的迭代次数。
- 更新最佳配置: 比较当前超参数组合的性能与已知的最佳性能,如果性能更好,则更新最佳配置。
- 重复迭代: 重复以上步骤,直到达到预定的迭代次数或计算资源限制。
b. 优缺点
-
相对于网格搜索,随机搜索的主要优点在于:
- 灵活性: 不受先验定义的网格限制,能够在超参数空间中更灵活地进行探索。
- 高效性: 特别适用于超参数空间较大的情况,避免了网格搜索中不必要的尝试。
-
然而,随机搜索也有一些局限性:
- 不保证最优解: 由于是随机选择,不保证找到全局最优的超参数配置。
- 不充分利用超参数之间的相关性: 与贝叶斯优化等方法相比,随机搜索不利用不同超参数之间的相关性,可能在搜索过程中浪费一些资源。
c. 代码实现
num_trials = 10best_accuracy = 0
best_params = {}for _ in range(num_trials):hidden_size = random.choice([64, 128, 256])learning_rate = random.choice([0.001, 0.01, 0.1])model = SimpleNN(input_size=20, hidden_size=hidden_size, output_size=2)optimizer = SGD(model.parameters(), lr=learning_rate)criterion = nn.CrossEntropyLoss()accuracy = train_and_evaluate(model, torch.FloatTensor(X_train), torch.LongTensor(y_train),torch.FloatTensor(X_test), torch.LongTensor(y_test), criterion, optimizer)if accuracy > best_accuracy:best_accuracy = accuracybest_params = {'hidden_size': hidden_size, 'learning_rate': learning_rate}print("Random Search - Best Parameters:", best_params)
print("Random Search - Best Accuracy:", best_accuracy)
3. 贝叶斯优化
贝叶斯优化是一种基于贝叶斯统计的自适应超参数优化方法,它通过在搜索空间中建立一个目标函数的概率模型,来智能地选择下一组待试验的超参数。这种方法相对于随机搜索和网格搜索更加高效,特别适用于计算资源受限的情况下。
a.基本步骤
- 定义超参数空间: 和其他优化方法一样,首先需要定义每个超参数的可能取值范围。
- 选择初始样本点: 选择一组初始的超参数样本点,通常是通过随机选择或者根据先验知识选择的。
- 建立概率模型: 使用已有的样本点,建立一个对目标函数的概率模型。常用的模型包括高斯过程(Gaussian Process)和随机森林。
- 选择下一个样本点: 基于当前的概率模型,选择下一个超参数样本点,这个选择通常是基于对目标函数的不确定性的评估。一种常见的策略是使用“概率提升(Probability of Improvement)”或“置信区间(Expected Improvement)”等指标来评估每个点的潜在收益。
- 采样和评估: 在选择的超参数点处进行模型的训练和评估,得到目标函数的值。
- 更新概率模型: 将新的样本点加入已有的样本,然后更新概率模型,以更准确地表示目标函数。
- 重复迭代: 重复上述步骤,直到达到预定的迭代次数或满足其他停止准则。
贝叶斯优化的优势在于它能够根据已有样本来预测目标函数的形状,从而更聪明地选择下一个样本点,尤其在高维空间和计算资源有限的情况下表现得更为明显。时序模型优化(Sequential Model-Based Optimization,SMBO)是一种基于序列的贝叶斯优化方法,其中的“时序”指的是通过不断地迭代来逐步改善模型。
b. 代码实现
def objective(trial):hidden_size = trial.suggest_categorical('hidden_size', [64, 128, 256])learning_rate = trial.suggest_loguniform('learning_rate', 0.001, 0.1)model = SimpleNN(input_size=20, hidden_size=hidden_size, output_size=2)optimizer = SGD(model.parameters(), lr=learning_rate)criterion = nn.CrossEntropyLoss()accuracy = train_and_evaluate(model, torch.FloatTensor(X_train), torch.LongTensor(y_train),torch.FloatTensor(X_test), torch.LongTensor(y_test), criterion, optimizer)return -accuracy # Optuna minimizes the objective function, so we use negative accuracy.sampler = TPESampler(seed=42)
study = optuna.create_study(sampler=sampler)
study.optimize(objective, n_trials=10)print("Bayesian Optimization - Best Parameters:", study.best_params)
print("Bayesian Optimization - Best Accuracy:", -study.best_value) # Convert back to positive accuracy
4. 动态资源分配
动态资源分配是一种在超参数优化中更加智能地分配有限资源的方法。它的核心思想是通过早期停止和逐次减半等策略,在训练过程中识别哪些超参数组合可能不会带来较好的性能,从而及时中止这些配置的评估,将资源更多地留给其他有潜力的配置。以下是动态资源分配的一般步骤,特别是逐次减半方法:
- 定义超参数空间和总资源预算: 和其他超参数优化方法一样,首先需要定义每个超参数的可能取值范围,并确定可用的总资源预算(例如,摇臂的次数)。
- 初始化超参数配置: 随机选择一组初始的超参数配置,并开始评估它们的性能。
- 逐次减半: 将总资源预算分配给一组超参数配置,并在每一轮中选择性能较好的一半进行下一轮的评估。这个过程会重复进行,逐次减半资源分配,直到达到预定的轮数或资源用尽。
- 早期停止策略: 对于正在评估的每个超参数配置,可以通过监测学习曲线的形状,比如早期停止来判断是否中止当前训练。如果学习曲线不收敛或者收敛较差,可以中止当前训练,将资源留给其他配置。
- 选择最佳超参数配置: 根据逐次减半的过程,选择性能最好的超参数配置作为最终的结果。
逐次减半方法通过在每一轮中聚焦于性能较好的超参数配置,更有可能找到全局最优或局部最优的配置。这种方法尤其适用于计算资源受限的情况,可以在较短时间内找到性能较好的超参数配置。

5. 神经架构搜索
神经架构搜索(Neural Architecture Search,NAS)是一种探索神经网络结构的自动化方法。与传统的由人类专家手动设计神经网络结构不同,NAS旨在通过使用机器学习技术来搜索神经网络的结构,以提高性能。基本上,神经架构搜索的目标是找到一个最优的神经网络结构,使得在给定任务上的性能达到最佳。这可以通过定义一个搜索空间,其中包含各种可能的网络结构来实现。每个网络结构都可以用一个参数化的描述来表示,通常是一个变长的字符串。这个描述包含了网络的层次结构、每一层的类型、连接方式等信息。
神经架构搜索通常采用元学习的思想。这意味着有一个控制器,负责生成神经网络结构的描述。这个控制器本身可以是一个循环神经网络(RNN),它学会生成有效的网络结构描述。控制器的训练过程通常使用强化学习来完成。奖励信号一般是由生成的子网络在开发集或验证集上的性能,例如准确率。整个神经架构搜索的流程如下:
- 定义搜索空间: 确定神经网络结构的参数化表示,并定义一个搜索空间,包含各种可能的网络结构。
- 设计控制器: 创建一个控制器,通常是一个循环神经网络(RNN),负责生成神经网络结构的描述。
- 初始化控制器: 初始化控制器的参数。
- 强化学习训练: 通过强化学习算法,如REINFORCE,训练控制器。在每一轮训练中,生成一个网络结构描述,训练该结构的子网络,然后使用性能作为奖励信号来更新控制器的参数。
- 搜索过程: 通过不断迭代上述过程,搜索最佳的神经网络结构描述。
- 评估最优结构: 使用测试集评估最终选择的最优神经网络结构的性能。
神经架构搜索的优势在于它可以自动发现复杂的网络结构,而不需要人类专家的介入。这使得神经网络设计更具有普适性和适应性,能够更好地适应不同的任务和数据。然而,NAS也面临着计算资源消耗大、搜索空间巨大等挑战。近年来,许多改进的方法和算法被提出,以提高神经架构搜索的效率。
相关文章:
【深度学习实验】网络优化与正则化(七):超参数优化方法——网格搜索、随机搜索、贝叶斯优化、动态资源分配、神经架构搜索
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、优化算法0. 导入必要的库1. 随机梯度下降SGD算法a. PyTorch中的SGD优化器b. 使用SGD优化器的前馈神经网络 2.随机梯度下降的改进方法a. 学习率调整b. 梯度估计修正 3. 梯度估计修正:动量法Momen…...
简单漂亮的首页
效果图 说明 这个首页我也是构思了很久,才想出这个界面,大家喜欢的话,可以拿走去使用 技术的话,采用的就是vue的语法,但是不影响,很多样式我都是直接手敲出来的 代码实现 标语 <!-- 标语 start-->&…...
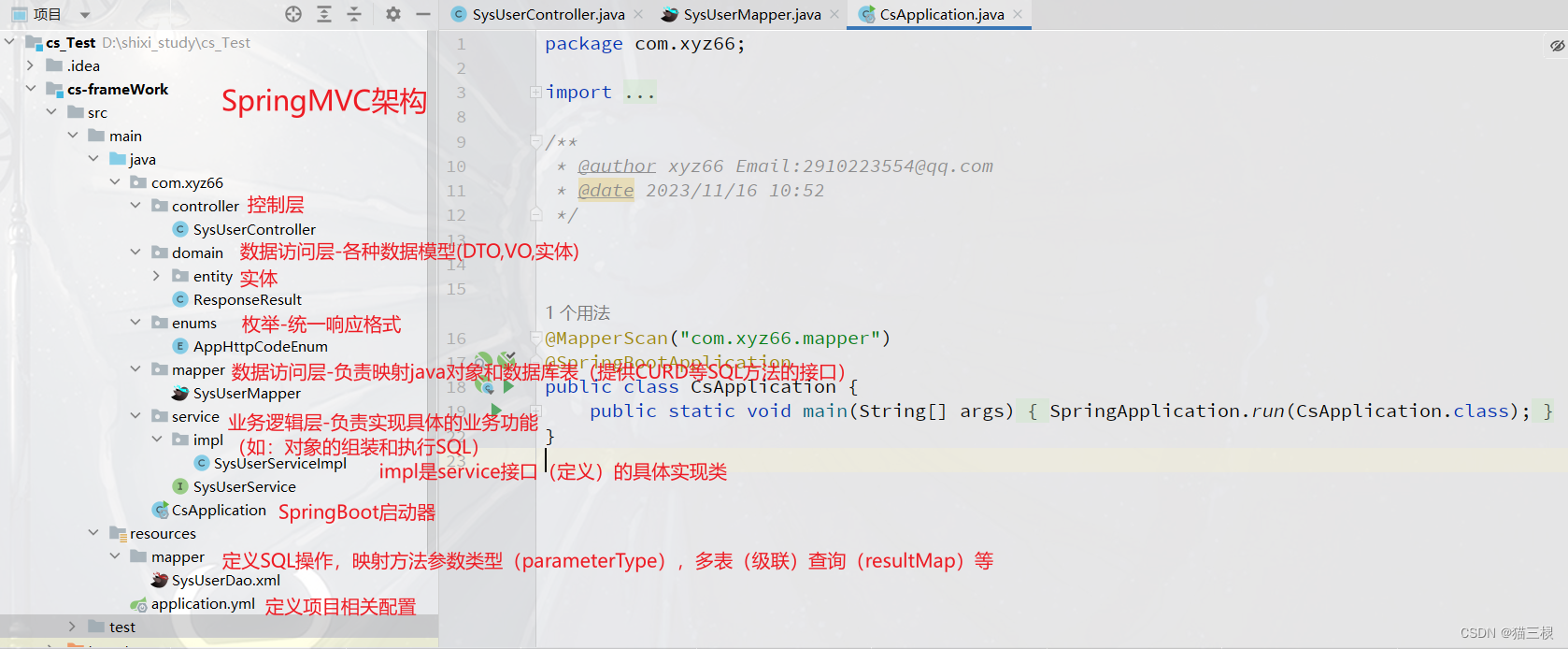
SSM项目初始化流程与操作概念解释-SpringBoot简化版
文章目录 1.引入概念2.导入依赖3.项目配置4.依照SpringMVC框架构建项目 1.引入概念 例如某一个XX系统,该系统存在前台页面(给用户直观看或使用),和后台页面(给管理人员调整数据和权限)。 这二个页面都通过…...
)
Angular 路由无缝导航的实现与应用(六)
Angular 是一种流行的前端开发框架,它提供了强大的路由功能,用于构建单页应用程序(SPA)。本文将介绍 Angular 路由的基本概念和使用方法,并通过具体的代码实例演示如何利用路由实现无缝的页面导航。 什么是 Angular 路…...

quickapp_快应用_tabBar
tabBar 配置项中配置tabBar(版本兼容)使用tabs组件配置tabBar语法示例问题-切换tab没有反应问题-数据渲染问题解决优化 问题-tab的动态配置 第三方组件tabbar 一般首页都会显示几个tab用于进行页面切换,以下是几种tab配置方式。 配置项中配置tabBar(版本兼容) 在m…...
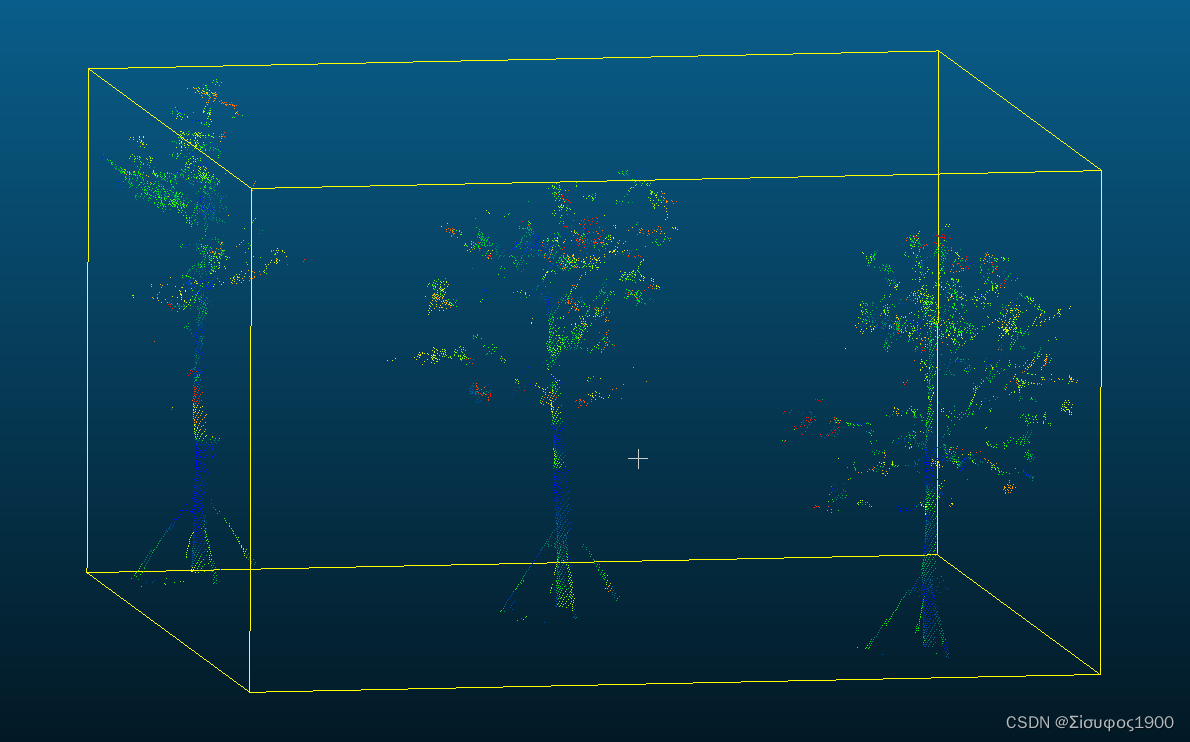
PCL_点云分割_基于法线微分分割
一、概述 PCL_点云分割_基于法线微分分割_点云法向量微分-CSDN博客 利用不同的半径(大的半径、小半径)来计算同一个点的法向量差值P。判断P的范围,从而进行分割。 看图理解: 二、计算流程 1、计算P点小半径的法向量Ns 2、计…...

计算机毕业论文内容参考|基于深度学习的交通标识智能识别系统的设计与维护
文章目录 导文摘要前言绪论1课题背景2国内外现状与趋势3课题内容相关技术与方法介绍系统分析总结与展望导文 基于深度学习的交通标识智能识别系统是一种利用深度学习模型对交通标识进行识别和解析的系统。它可以帮助驾驶员更好地理解交通规则和安全提示,同时也可以提高道路交通…...
)
SELinux零知识学习十六、SELinux策略语言之类型强制(1)
接前一篇文章:SELinux零知识学习十五、SELinux策略语言之客体类别和许可(9) 二、SELinux策略语言之类型强制 SELinux策略大部分内容都是由多条类型强制规则构成的,这些规则控制被允许的使用权,大多数默认转换标志、审…...
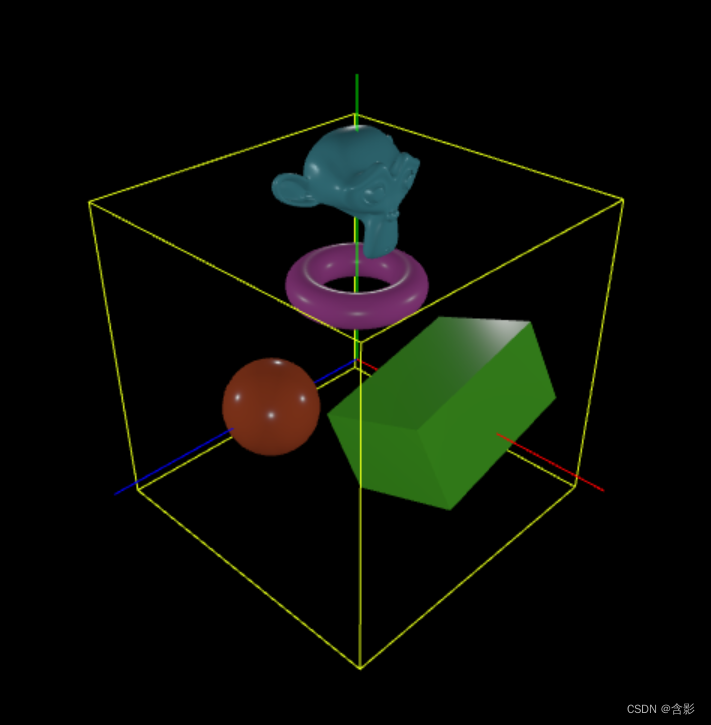
轻量封装WebGPU渲染系统示例<34>-数据驱动之Json构建场景
场景和数据之间的互通: 场景数据化或者数据化场景,是当前的主流场景数据构成方式。方便传输方便交换甚至是交互。 内置数据互通机制更有利于用户在各种应用场合下实现具体的3D相关的应用需求。用户只需要关心标准的或者约定好的数据定义及操作方式就能方…...

全局异常拦截和Spring Security认证异常的拦截的顺序
📑前言 本文主要全局异常拦截和Spring Security认证异常的顺序,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是青衿🥇 ☁️博客首页:CSDN主页放风讲故事 🌄每日…...
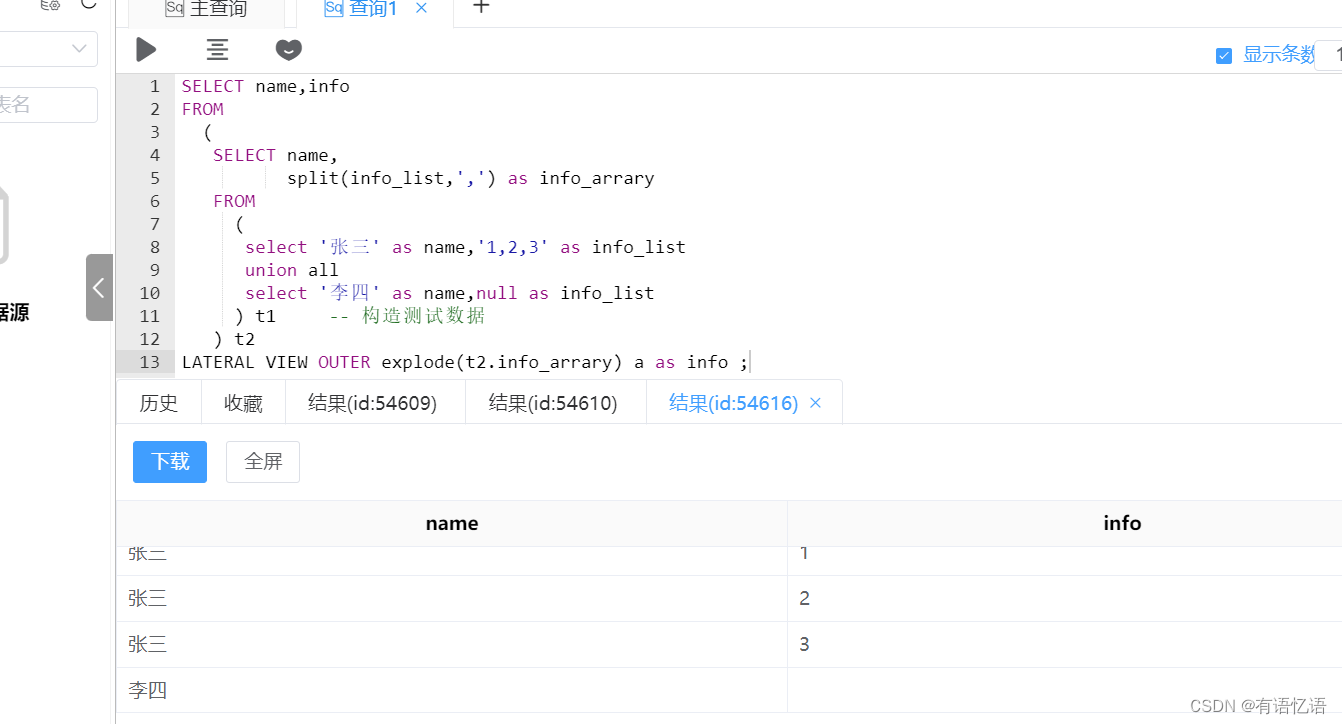
Hive Lateral View explode列为空时导致数据异常丢失
一、问题描述 日常工作中我们经常会遇到一些非结构化数据,因此常常会将Lateral View 结合explode使用,达到将非结构化数据转化成结构化数据的目的,但是该方法对应explode的内容是有非null限制的,否则就有可能造成数据缺失。 SE…...
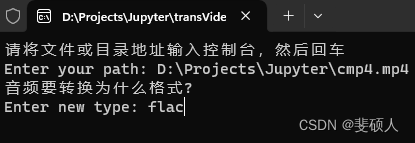
音频类型转换工具-可执行文件exe/dmg制作
朋友车载音乐需要MP3格式,想要个批量转换工具 准备工作 brew install ffmpeg --HEAD或者官网下载安装ffmpeg并配置环境conda install ffmpeg 或者pip install ffmpeg-python 音频类型转换程序.py文件 exe文件在windows下打包,dmg在macos下打包&#…...
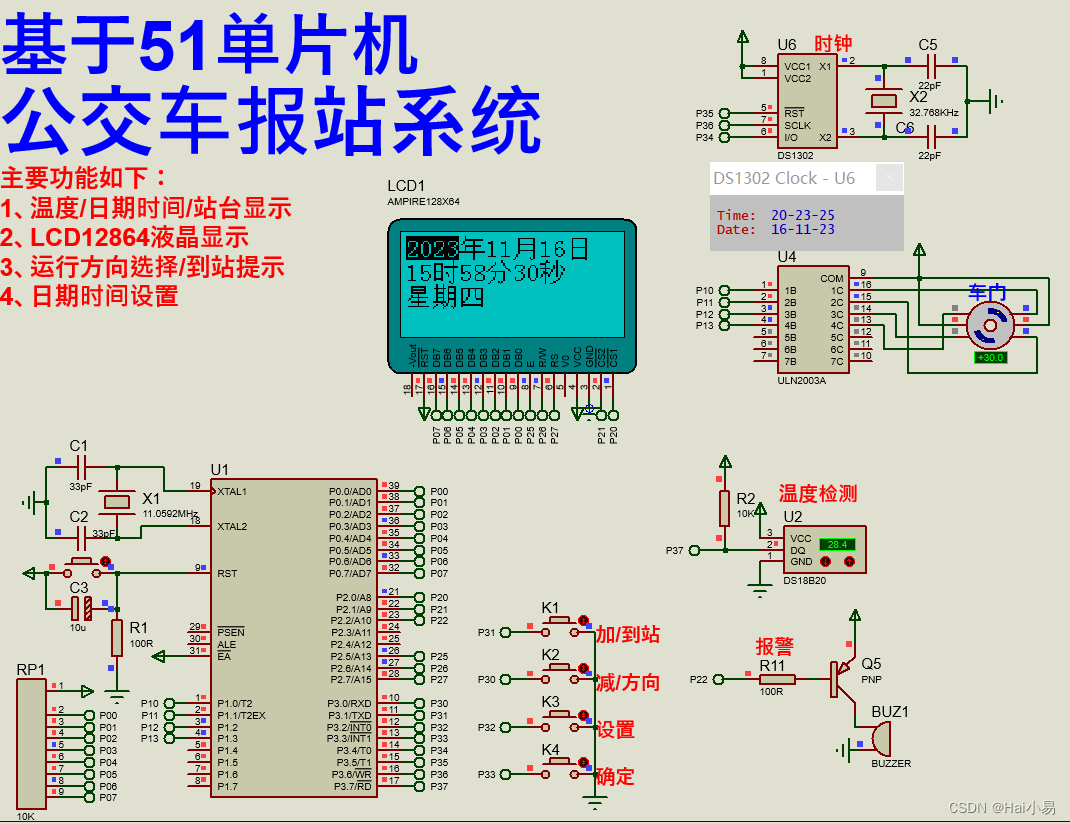
【Proteus仿真】【51单片机】公交车报站系统
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真51单片机控制器,使用LCD12864显示模块、DS18B20温度传感器、DS1302时钟模块、按键、LED蜂鸣器、ULN2003、28BYJ48步进电机模块等。 主要功能: 系统运行后&…...
C++--STL总结
参考教程:黑马程序员匠心之作|C教程从0到1入门编程,学习编程不再难_哔哩哔哩_bilibili 软件界一直希望建立一种可重复利用的东西,C的面向对象和泛型编程思想,目的就是复用性的提升。 大多情况下,数据结构和算法都未能有一套标准,…...
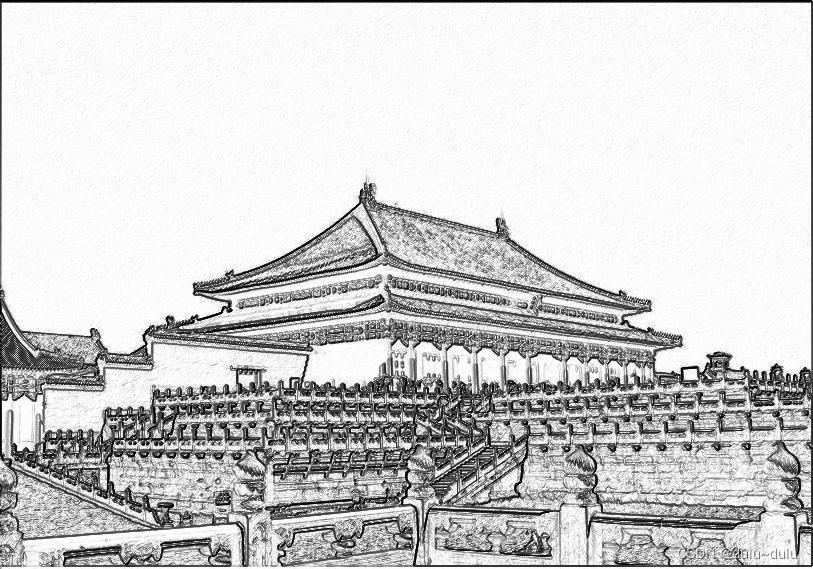
Python----图像的手绘效果
图像的数组表示 图像是有规则的二维数据,可以用numpy 库将图像转换成数组对象 : from PIL import Image import numpy as np imnp.array(Image.open("D://np.jpg")) print(im.shape,im.dtype)结果: 图像转换对应的ndarray 类型是3 维数据&am…...

Android13集成paho.mqtt.android启动异常
项目中原依赖是: implementation(org.eclipse.paho:org.eclipse.paho.android.service:1.1.1) {exclude module: support-v4transitive true } implementation org.eclipse.paho:org.eclipse.paho.client.mqttv3:1.2.5在Android10系统运行正常,能够连接…...

STM框架之按键扫描新思路
STM框架之按键扫描新思路 引入代码展示思路分析 我们学习了定时器实现毫秒级/秒级任务框架,这期我们基于任务框架学习按键扫描新思路。 引入 在按键扫描的过程中,最重要的一步就是按键消抖,解决的方法最简单粗暴的就是先扫描一次按键状态&am…...
)
Linux服务器挂载另一台服务器的文件夹(mount)
我们实际应用中,会常遇到多个Linux服务器之间需要频繁共享文件,或者是一台服务器需要使用另一台服务器的闲置磁盘空间。最方便的方法就是挂载另一台linux文件夹(文件服务器),通俗理解为:当前服务器远程连接…...
剑指offer --- 用两个栈实现队列的先进先出特性
目录 前言 一、读懂题目 二、思路分析 三、代码呈现 总结 前言 当我们需要实现队列的先进先出特性时,可以使用栈来模拟队列的行为。本文将介绍如何使用两个栈来实现队列,并给出具体的思路和代码实现。 一、读懂题目 题目:用两个栈实现一…...
流媒体协议
◆ RTP(Real-time Transport Protocol),实时传输协议。 ◆ RTCP(Real-time Transport Control Protocol),实时传输控制协议。 ◆ RTSP(Real Time Streaming Protocol),实时流协议。 ◆ RTMP(Real Time Messaging Protocol),实时…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...