【机器学习】 逻辑回归算法:原理、精确率、召回率、实例应用(癌症病例预测)
1. 概念理解
逻辑回归,简称LR,它的特点是能够将我们的特征输入集合转化为0和1这两类的概率。一般来说,回归不用在分类问题上,但逻辑回归却能在二分类(即分成两类问题)上表现很好。
逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层Sigmod函数映射,即先把特征线形求和,然后使用Sigmoid函数将最为假设函数来概率求解,再进行分类。
Sigmoid函数为:
sigmoid函数形如s曲线下侧无限接近0,上侧无限接近1
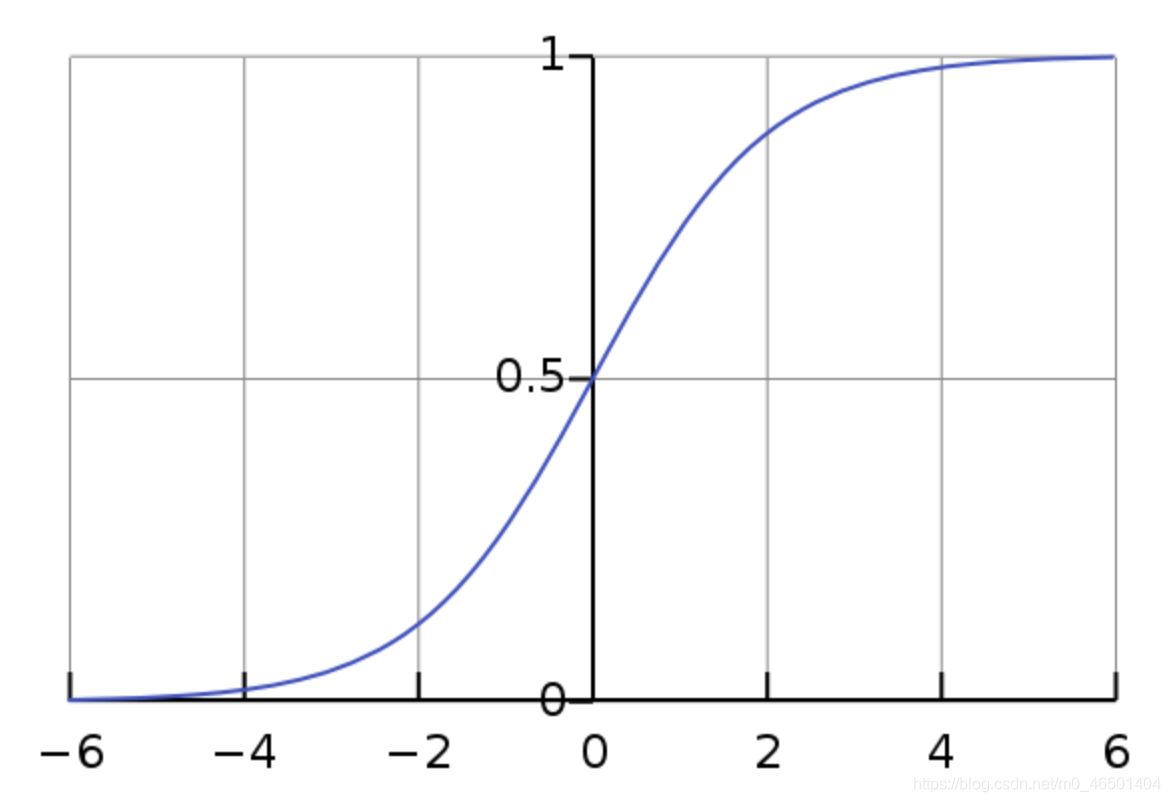
例如,在进行预测的过程中,预测结果大于0.5的认为是属于一类,小于0.5的我们认为是第二类,进而我们实现二分类。
优点: 适合需要得到一个分类概率的场景,简单,速度快
缺点: 只能用来处理二分类问题,不好处理多分类问题
应用: 是否患病、金融诈骗、是否虚假账号等
2. 精确率和召回率
如下表所示,如果我预测出一个人得了癌症,他的真实值也是得了癌症,那么这种情况称为TP真正例;如果我预测出一个人得了癌症,而他的真实值是没有得癌症,这种情况称为FN假反例。
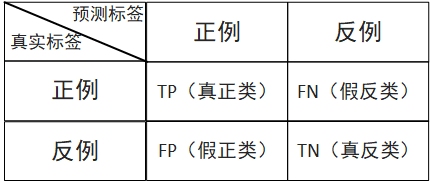
(1)精确率:预测结果为正例样本中真实为正例的比例(用于表示查得准不准)
公式为:
例:100个人中,我预测的结果是有20个人得了癌症。在这20个人中,真实得癌症的只有5个人,没得癌症的有15人。那么精确率为 P=5/(5+15)=0.25
(2)召回率:真实为正例的样本中预测结果为正例的比例(表示查的全,对正样本的区分能力)
公式为:
例:现在有20个人得了癌症,在这些人中我检测到有18个人得了癌症,还有2个人没有检测出来,召回率R=18/(18+2)
(3)综合指标:P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure。
公式为:
若F1较大的话,综合性能较好
导入方法: from sklearn.metrics import classification_report
classification_report() 函数参数
y_true:1维数组,或标签指示器数组/稀疏矩阵,真实值。
y_pred:1维数组,或标签指示器数组/稀疏矩阵,预测值
labels:列表,shape = [n_labels],报表中包含的标签索引的可选列表。
target_names:字符串列表,与标签匹配的可选显示名称(相同顺序)
sample_weight:类似于shape = [n_samples]的数组,可选项,样本权重
digits:int,输出浮点值的位数
3. 实例应用 -- 癌症病例预测
3.1 Sklearn 实现
逻辑回归方法导入: from sklearn.linear_model import LogisticRegression
参数设置: 参考博客 https://blog.csdn.net/jark_/article/details/78342644
penalty:惩罚项,str类型,可选参数为l1和l2,默认为l2。用于指定惩罚项中使用的规范。
L1规范假设的是模型的参数满足拉普拉斯分布,L2假设的模型参数满足高斯分布。所谓的范式就是加上对参数的约束,使得模型不会过拟合,加约束的情况下,理论上应该可以获得泛化能力更强的结果。
dual:对偶或原始方法,bool类型,默认为False。对偶方法只用在求解线性多核的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False。
tol:停止求解的标准,float类型,默认为1e-4。就是求解到多少的时停止,认为已经求出最优解。
C:正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数。像SVM一样,越小的数值表示越强的正则化。
fit_intercept:是否存在截距或偏差,bool类型,默认为True。
intercept_scaling:仅在正则化项为”liblinear”,且fit_intercept设置为True时有用。float类型,默认为1。
class_weight:用于标示分类模型中各种类型的权重,可以是一个字典或者’balanced’字符串,默认为不输入,也就是不考虑权重,即为None。
如果选择输入的话,可以选择balanced让类库自己计算类型权重,或者自己输入各个类型的权重。举个例子,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9,1:0.1},这样类型0的权重为90%,而类型1的权重为10%。如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。当class_weight为balanced时,类权重计算方法如下:n_samples / (n_classes * np.bincount(y))。n_samples为样本数,n_classes为类别数量,np.bincount(y)会输出每个类的样本数,例如y=[1,0,0,1,1],则np.bincount(y)=[2,3]。
random_state:随机数种子,int类型,可选参数,默认为无,仅在正则化优化算法为sag,liblinear时有用。
solver:优化算法选择参数,只有五个可选参数,即newton-cg, lbfgs, liblinear, sag, saga。默认为liblinear。
solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
newton-cg:牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
saga:线性收敛的随机优化算法的的变重。
verbose:日志冗长度,int类型。默认为0。就是不输出训练过程,1的时候偶尔输出结果,大于1,对于每个子模型都输出。
warm_start:热启动参数,bool类型。默认为False。如果为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)。
3.1 癌症预测
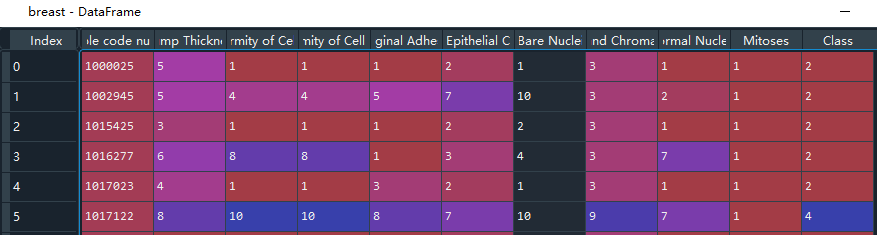
数据集包含10项特征值数据和1项目标数据,字符'?'代表缺失数据,目标中数字2代表癌症良性,4代表癌症恶性。
数据集下载地址:Index of /ml/machine-learning-databases/breast-cancer-wisconsin
names中存放的是每一项数据的列索引名称,pandas导入数据集时会默认将数据第一行当作数据索引名,而原数据没有列索引名,我们需要自定义列 pd.read_csv(文件路径,names=列名称)
#(1)数据获取
import pandas as pd
import numpy as np
# 癌症数据路径
filepath = 'C:\\Users\\admin\\.spyder-py3\\test\\文件处理\\癌症\\breast-cancer-wisconsin.data'
# 癌症的每一项特征名
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class']
# breast存放癌症数据,不默认将第一行作为列索引名,自定义列索引名
breast = pd.read_csv(filepath,names=names)
# 查看唯一值,Class这列代表的是否得癌症,使用.unique()函数查看该列有哪些互不相同的值
unique = breast['Class'].unique() #只有两种情况,是二分类问题,2代表良性,4代表恶性
3.2 数据处理
首先通过 .info() 函数查看数据中是否存在缺失数据nan和重复数据,本例子中没有。然后对字符'?'进行处理,先将'?'转换成nan值,再使用 .dropna() 函数将nan所在的行删除。完成以后划分特征值和目标值。再划分训练集和测试集,测试集取25%的数据。
#(2)数据处理
breast.info() #查看是否有缺失值、重复数据
# 该数据集存在字符串类型数据'?'
# 将'?'转换成nan
breast = breast.replace(to_replace='?',value=np.nan)
# 将nan所在的行删除
breast = breast.dropna()# 特征值是除了class列以外的所有数据
features = breast.drop('Class',axis=1)
# 目标值是class这一列
targets = breast['Class']#(3)划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(features,targets,test_size=0.25)
3.3 标准化处理
由于单位不一以及数据跨度过大等问题会影响模型准确度,因此对训练数据的和测试数据的特征值进行标准化处理。特征工程的具体方法会在后续章节中介绍,此处先做了解。
#(4)特征工程
# 导入标准化方法
from sklearn.preprocessing import StandardScaler
# 接收标准化方法
transfer = StandardScaler()
# 对训练的特征值x_train提取特征并标准化处理
x_train = transfer.fit_transform(x_train)
# 对测试的特征值x_test标准化处理
x_test = transfer.transform(x_test)
3.4 逻辑回归预测
由于癌症数据中结果只有2和4,良性和恶性,属于二分问题,可以使用逻辑回归方法来预测,此处,为方便各位理解,采用默认参数的逻辑回归方法。其中.fit()函数接收训练模型所需的特征值和目标值,预测函数.predict()接收的是预测所需的特征值,评分法.score()通过真实结果和预测结果计算准确率。计算得到的模型准确率为0.97
#(5)逻辑回归预测
# 导入逻辑回归方法
from sklearn.linear_model import LogisticRegression
# 接收逻辑回归方法
logist = LogisticRegression()
# penalty=l2正则化;tol=0.001损失函数小于多少时停止;C=1惩罚项,越小惩罚力度越小,是岭回归的乘法力度的分之一
# 训练
logist.fit(x_train,y_train)
# 预测
y_predict = logist.predict(x_test)
# 评分法计算准确率
accuracy = logist.score(x_test,y_test)3.5 准确率和召回率
#(6)准确率和召回率
# 导入
from sklearn.metrics import classification_report
# classification_report()
# 参数(真实值,预测值,labels=None,target_names=None)
# labels:class列中每一项,如该题的2和4,给它们取名字
# target_names:命名# 计算准确率和召回率
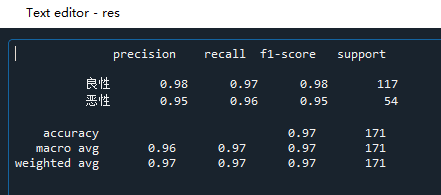
res = classification_report(y_test,y_predict,labels=[2,4],target_names=['良性','恶性'])
print(res)
precision表示准确率;recall表示召回率;f1-score表示综合指标;support表示预测的人数。本模型的召回率,良性达到0.97,恶性达到0.96;该例子是检测癌症,我们希望能找到所有得癌症的人,即使他不是癌症,也可以做进一步检查,因此我们需要一个召回率高的模型。
数据集获取:
Index of /ml/machine-learning-databases/breast-cancer-wisconsin
完整代码:
#(1)数据获取
import pandas as pd
import numpy as np
# 癌症数据路径
filepath = 'C:\\Users\\admin\\.spyder-py3\\test\\文件处理\\癌症\\breast-cancer-wisconsin.data'
# 癌症的每一项特征名
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class']
# breast存放癌症数据,不默认将第一行作为列索引名,自定义列索引名
breast = pd.read_csv(filepath,names=names)
# 查看唯一值,Class这列代表的是否得癌症,使用.unique()函数查看该列有哪些互不相同的值
unique = breast['Class'].unique() #只有两种情况,是二分类问题,2代表良性,4代表恶性#(2)数据处理
breast.info() #查看是否有缺失值、重复数据
# 该数据集存在字符串类型数据'?'
# 将'?'转换成nan
breast = breast.replace(to_replace='?',value=np.nan)
# 将nan所在的行删除
breast = breast.dropna()# 特征值是除了class列以外的所有数据
features = breast.drop('Class',axis=1)
# 目标值是class这一列
targets = breast['Class']#(3)划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(features,targets,test_size=0.25)#(4)特征工程
# 导入标准化方法
from sklearn.preprocessing import StandardScaler
# 接收标准化方法
transfer = StandardScaler()
# 对训练的特征值x_train提取特征并标准化处理
x_train = transfer.fit_transform(x_train)
# 对测试的特征值x_test标准化处理
x_test = transfer.transform(x_test)#(5)逻辑回归预测
# 导入逻辑回归方法
from sklearn.linear_model import LogisticRegression
# 接收逻辑回归方法
logist = LogisticRegression()
# penalty=l2正则化;tol=0.001损失函数小于多少时停止;C=1惩罚项,越小惩罚力度越小,是岭回归的乘法力度的分之一
# 训练
logist.fit(x_train,y_train)
# 预测
y_predict = logist.predict(x_test)
# 评分法计算准确率
accuracy = logist.score(x_test,y_test)#(6)准确率和召回率
# 导入
from sklearn.metrics import classification_report
# classification_report()
# 参数(真实值,预测值,labels=None,target_names=None)
# labels:class列中每一项,如该题的2和4,给它们取名字
# target_names:命名# 计算准确率和召回率
res = classification_report(y_test,y_predict,labels=[2,4],target_names=['良性','恶性'])
# precision准确率;recall召回率;综合指标F1-score;support:预测的人数
print(res)
相关文章:
【机器学习】 逻辑回归算法:原理、精确率、召回率、实例应用(癌症病例预测)
1. 概念理解 逻辑回归,简称LR,它的特点是能够将我们的特征输入集合转化为0和1这两类的概率。一般来说,回归不用在分类问题上,但逻辑回归却能在二分类(即分成两类问题)上表现很好。 逻辑回归本质上是线性回归,只是在特…...

算法萌新闯力扣:存在重复元素II
力扣题:存在重复元素II 开篇 这道题是217.存在重复元素的升级版,难度稍微提高。通过这道题,能加强对哈希表和滑动窗口的运用。 题目链接:219.存在重复元素II 题目描述 代码思路 1.利用哈希表,来保存数组元素及其索引位置 2.遍…...
《洛谷深入浅出基础篇》——P3405 citis and state ——哈希表
上链接:P3405 [USACO16DEC] Cities and States S - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)https://www.luogu.com.cn/problem/P3405 上题干: 题目描述 Farmer John 有若干头奶牛。为了训练奶牛们的智力,Farmer John 在谷仓的墙上放了一…...
在QGIS中加载显示3DTiles数据
“我们最近有机会在QGIS 3.34中实现一个非常令人兴奋的功能–能够以“Cesium 3D Tiles”格式加载和查看3D内容!” ——QGIS官方的 宣传介绍。 体验一下,感觉就是如芒刺背、如坐针毡、如鲠在喉。 除非我电脑硬件有问题,要么QGIS的3Dtiles是真…...

HBase学习笔记(3)—— HBase整合Phoenix
目录 Phoenix Shell 操作 Phoenix JDBC 操作 Phoenix 二级索引 HBase整合Phoenix Phoenix 简介 Phoenix 是 HBase 的开源 SQL 皮肤。可以使用标准 JDBC API 代替 HBase 客户端 API来创建表,插入数据和查询 HBase 数据 使用Phoenix的优点 在 Client 和 HBase …...

CentOS 7上生成HTTPS证书
在CentOS 7上生成HTTPS证书,可以使用OpenSSL工具。以下是在CentOS 7上生成自签名HTTPS证书的步骤: 安装OpenSSL: sudo yum install openssl生成证书和私钥: openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout ssl.…...

解决React遍历每次渲染多个根元素导致无法为元素赋值key的问题
遍历时,存在多个根标签,如果使用<></>无法正确赋值key,代码如下: function App() {const list [{ id:1, name:"小明" },{ id:2, name:"小田" },{ id:3, name:"小王" }]const listCon…...

2023年软件安装管家目录最新
软件目录 ①【电脑办公】电脑系统(直接安装)Win7Win8Win10OfficeOffice激活office2003office2007office2010office2013office2016office2019office365office2021wps2021Projectproject2007project2010project2016project2019project2013project2021Visio…...
mac苹果笔记本应用程序在哪?有什么快捷方式吗?
苹果笔记本电脑一直以来都被广泛使用,而苹果的操作系统 macOS 也非常受欢迎。一台好的笔记本电脑不仅仅依赖于硬件配置,还需要丰富多样的应用程序来满足用户的需求。苹果笔记本应用程序在哪,不少mac新手用户会有这个疑问。在这篇文章中&#…...

py 循环打开多个页面
在Python中,你可以使用selenium库来循环打开多个页面并进行场控。Selenium是一个用于网页自动化测试的工具,它能够模拟用户与网页交互的操作,如点击、输入等。 以下是一个基本的示例代码,演示如何使用Selenium循环打开多个页面并…...

AD教程 (十八)导入常见报错解决办法(unkonw pin及绿色报错等)
AD教程 (十八)导入常见报错解决办法(unkonw pin及绿色报错等) 常见报错解决办法 绿色报错 可以先按TM,复位错位标识绿色报错原因一般是由于规则冲突的原因,和规则冲突就会报错 点击工具,设计…...

ubuntu22.04下hadoop3.3.6+hbase2.5.6+phoenix5.1.3开发环境搭建
一、涉及软件包资源清单 1、java 这里使用的是openjdk 2、hadoop-3.3.6.tar.gz 3、hbase-2.5.6-hadoop3-bin.tar.gz 4、phoenix-hbase-2.5-5.13-bin.tar.gz 5、apache-zookeeper-3.8.3-bin.tar.gz 6、openssl-3.0.12.tar.gz 二、安装 1、操作系统环境准备 换源 sudo vim /et…...

【随手记】python语言的else语句在for、while等循环语句中的运用
在Python中,else语句可以与if语句一起使用,用于处理条件不成立时的情况。但是,else语句也可以与循环结构(如for循环、while循环)一起使用,用于处理循环正常结束时的情况,即循环没有被break语句中…...

RK3568 + YT 9215交换机芯片,MAC TO MAC 调试记录
前言 原来的方案是rk3568 gmac 直接接phy,phy 接 switch 芯片,只是把交换芯片当交换用,驱动方面基本不用开发,但是要做vlan 那么必须涉及交换芯片的开发。 选择裕太微有两个方面的原因:1.国产化替代2.可获得原厂技术支持3.目前已经完成 两个gmac 口交换芯片的配置,实现v…...
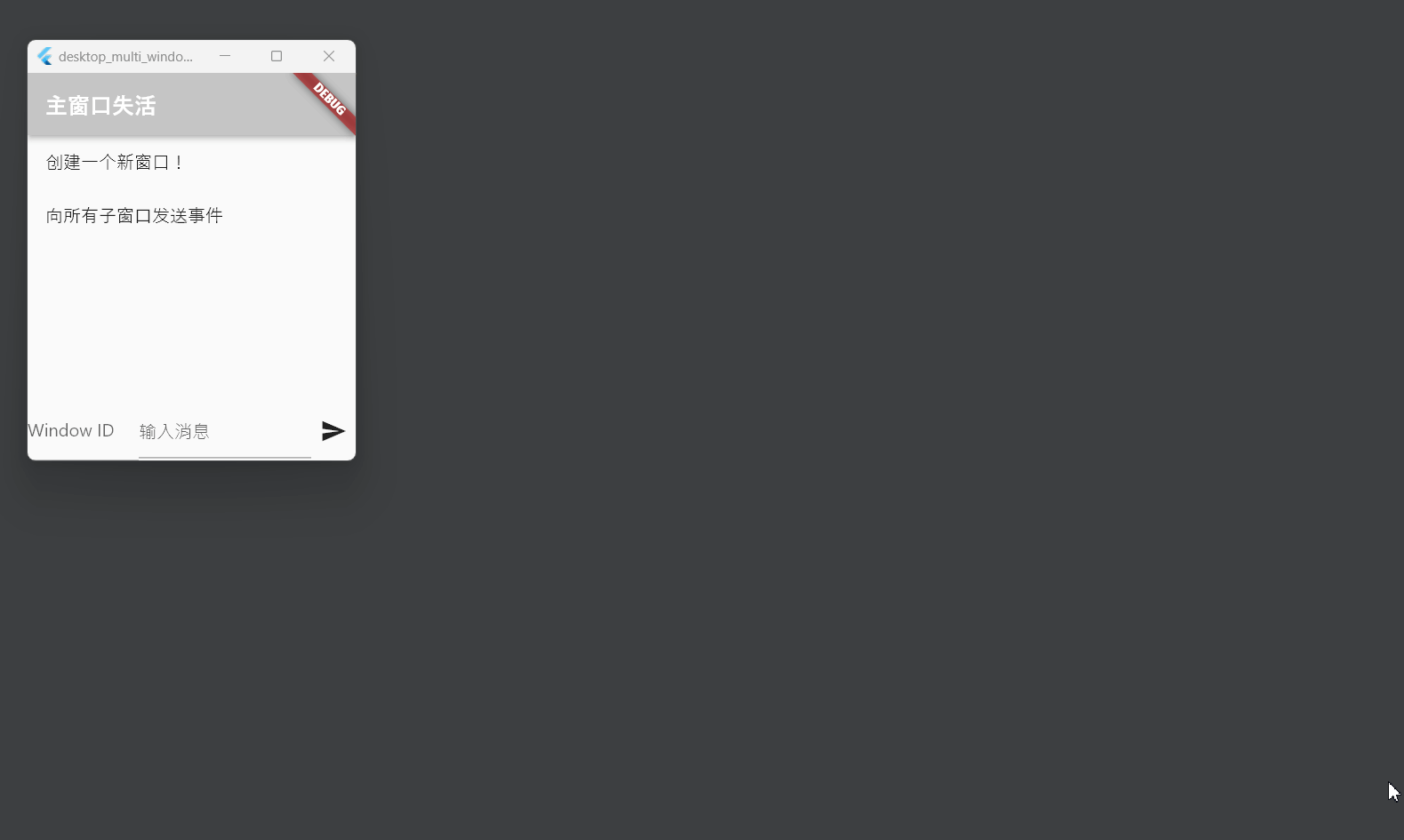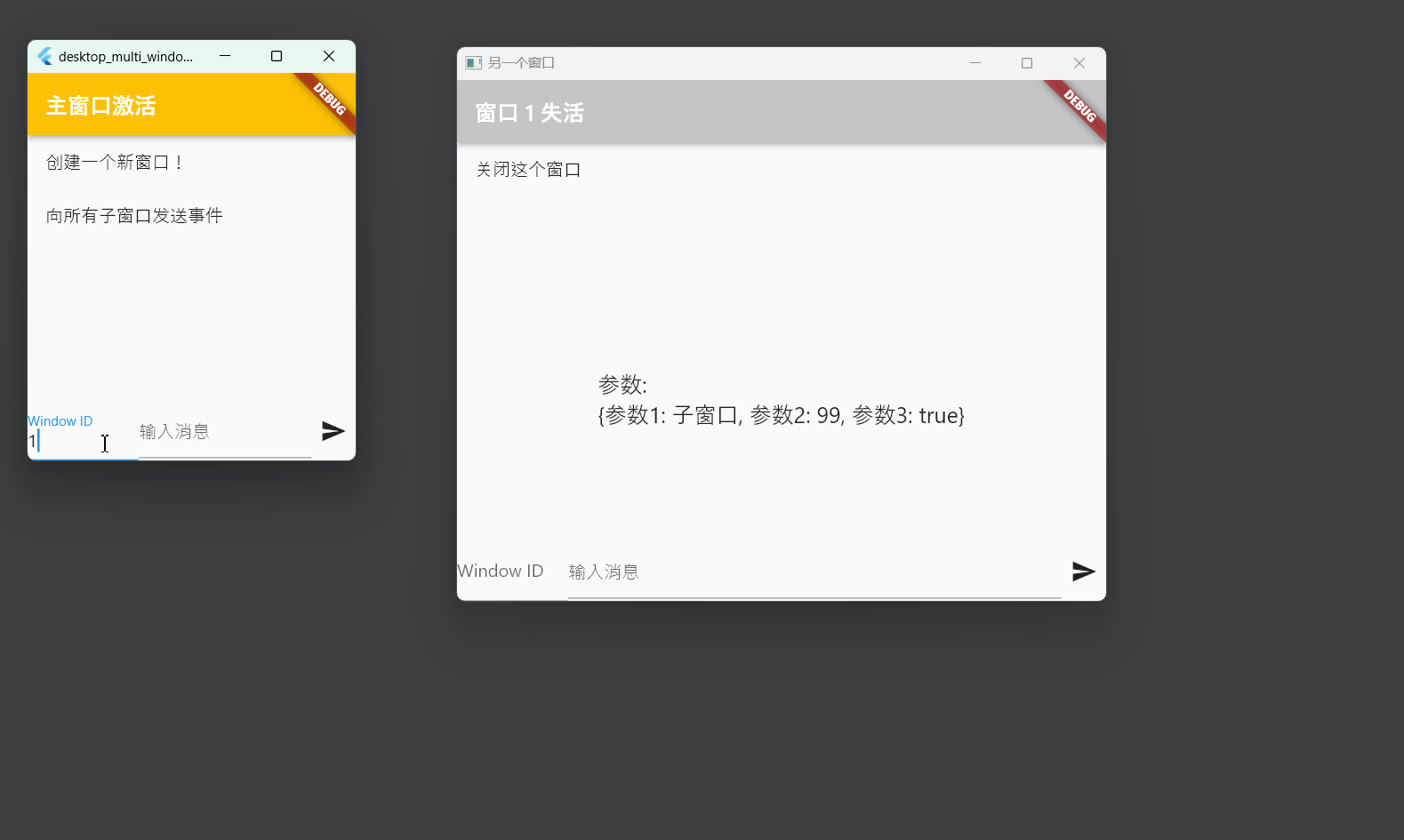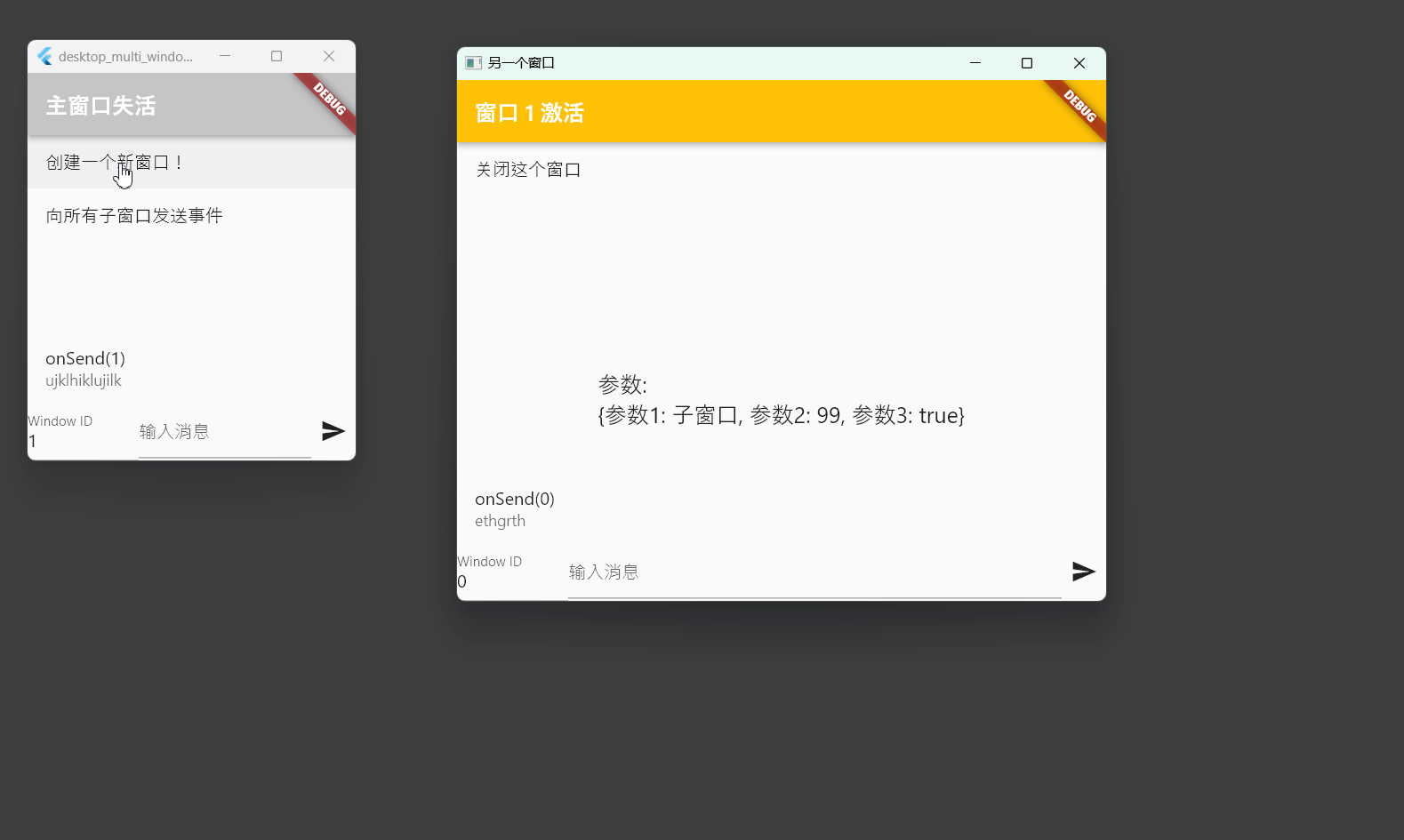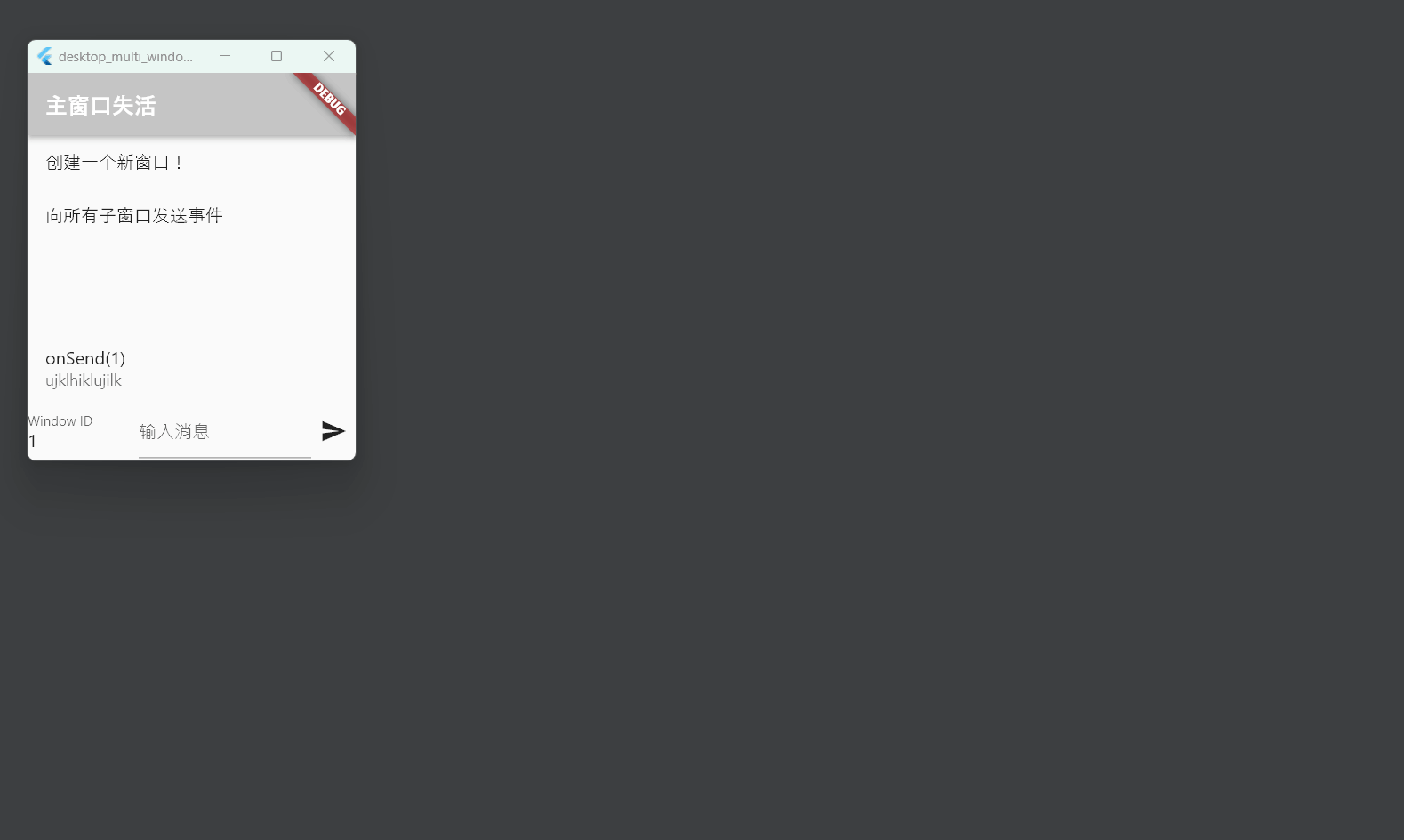
Flutter笔记:桌面端应用多窗口管理方案
Flutter笔记 桌面端应用多窗口管理方案 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/134468587 【简介…...
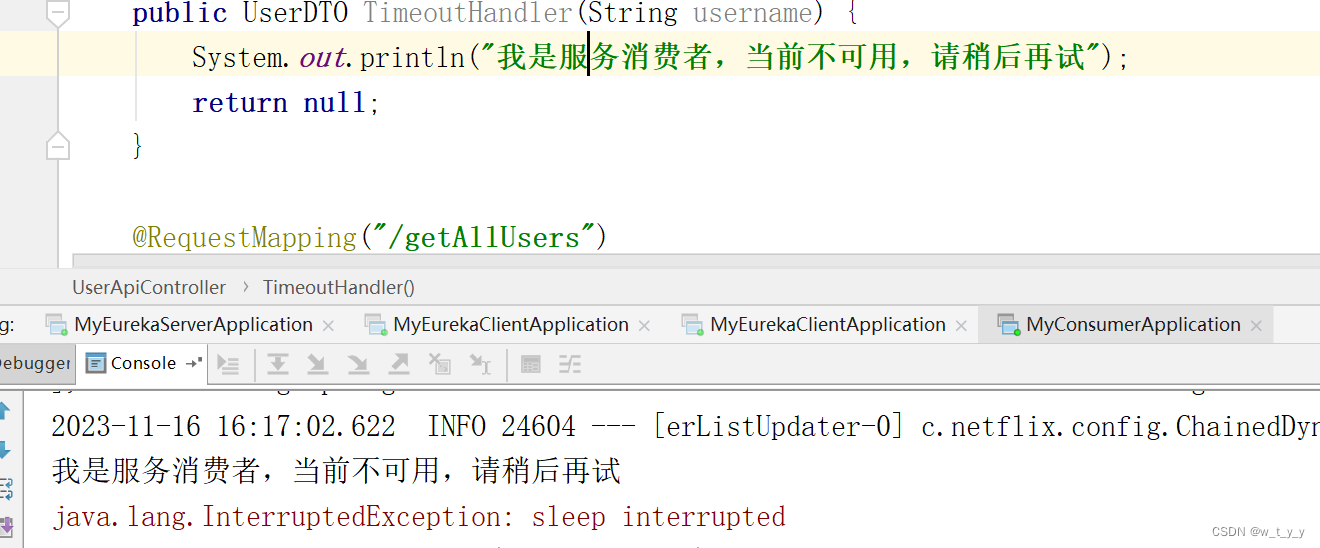
demo(三)eurekaribbonhystrix----服务降级熔断
一、介绍: 1、雪崩: 多个微服务之间调用的时候,假如微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的"扇出"。如果扇出的链路上某个微服务的调用响应的时间过长或者不可用&am…...
相机突然断电,保存的DAT视频文件如何修复
3-7 本文主要解决因相机突然断电导致拍摄的视频文件损坏的问题。 在平常使用相机拍摄视频,比如用单反相机、无人机拍摄视频的时候,如果电池突然断电,或者突然炸机了,就非常有可能会得到一个损坏的视频文件,比如会产生…...

【数据结构与算法篇】顺序栈的C++实现
如何用C实现一个顺序栈 数据结构 -- 栈的简介顺序栈 - 结构体的定义顺序栈的初始化顺序栈的销毁入栈出栈获取栈顶元素判断顺序栈是否为空返回顺序栈中元素的个数 数据结构 – 栈的简介 栈是插入和删除遵循先进后出原则的一种容器。 也是一种线性表对象存放在栈, 可以…...

阿里云ESSD云盘、高效云盘和SSD云盘介绍和IOPS性能参数表
阿里云服务器系统盘或数据盘支持多种云盘类型,如高效云盘、ESSD Entry云盘、SSD云盘、ESSD云盘、ESSD PL-X云盘及ESSD AutoPL云盘等,阿里云服务器网aliyunfuwuqi.com详细介绍不同云盘说明及单盘容量、最大/最小IOPS、最大/最小吞吐量、单路随机写平均时延…...

VSG-001
VulkanSceneGraph (VSG), is a modern, cross platform, high performance scene graph library built upon Vulkan VSG 是一个基于vulkan的现代的、跨平台的高性能场景管理库 VSg特性: 使用C17作为c规范编码,支持 CppCoreGuidelines支持 FOSS Best P…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...