数据结构与算法面试题——C++
自己在秋招过程中遇到的数据结构与算法方面的面试题
数据结构
vector
vector是⼀种序列式容器,与array唯⼀差别就是对于空间运⽤的灵活性
array占⽤的是静态空间,⼀旦配置了就不可以改变⼤⼩,如果遇到空间不⾜的情况还要⾃⾏创建更⼤的空间,并⼿动将数据拷⻉到新的空间中,再把原来的空间释放。
vector则使⽤灵活的动态空间配置,维护⼀块连续的线性空间,在空间不⾜时,可以⾃动扩展空间容纳新元素,做到按需供给。其在扩充空间的过程中仍然需要经历: 重新配置空间,移动数据,释放原空间等操作。
动态扩容的规则:以原⼤⼩的两倍配置另外⼀块较⼤的空间(或者旧⻓度+新增元素的个数)
Vector扩容倍数与平台有关,在Win + VS 下是 1.5倍,在 Linux + GCC 下是 2 倍
频繁对vector调⽤push_back()对性能是有影响的,这是因为每插⼊⼀个元素,如果空间够⽤的话还能直接插⼊,若空间不够⽤,则需要重新配置空间,移动数据,释放原空间等操作,对程序性能会造成⼀定的影响
链表的定义
//定义一个单链表
struct ListNode {int val;ListNode* next;ListNode() : val(0), next(nullptr) {}ListNode(int x) : val(x), next(nullptr) {}ListNode(int x, ListNode *next) : val(x), next(next) {}
};
二叉树的定义
//定义一个二叉树
struct TreeNode {int val;TreeNode* left;TreeNode* right;TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};
STL 中对比一下 unordered_map 和 map 的区别
在STL(标准模板库)中,unordered_map和map是两种不同的关联容器,它们在实现和特性上有一些区别。
- 排序:map中的元素是按照键的顺序进行排序的,而unordered_map中的元素则没有特定的顺序。unordered_map使用哈希表实现,根据键的哈希值进行快速查找,因此元素的存储顺序是不确定的。
- 查找效率:unordered_map的查找操作的平均时间复杂度为O(1),即常数时间。这是因为它使用哈希表来组织元素,可以通过哈希值直接定位到元素的位置。而map的查找操作的平均时间复杂度为O(log n),即对数时间,它使用红黑树实现,需要进行树的搜索操作。
- 内存占用:由于unordered_map使用哈希表,它通常需要更多的内存来存储哈希表和链表(用于处理哈希冲突)。而map使用红黑树,它需要额外的指针和节点来构建树结构,但在某些情况下可能会更节省内存。
- 顺序性:由于map中元素是有序的,因此可以对其进行范围遍历和有序访问。而unordered_map中元素的顺序是不确定的,因此无法直接进行有序遍历,需要使用其他手段进行操作。
- 支持的操作:unordered_map和map都提供了常用的关联容器操作,如插入、删除、查找等。它们的接口和用法也很相似,因此可以根据具体需求选择适合的容器。
综上所述,选择unordered_map还是map取决于你的具体需求。如果你需要高效的查找操作,并不关心元素的顺序,可以选择unordered_map。如果你需要有序的元素以及范围遍历功能,可以选择map。
当 unordered_map 中元素比较多的时候,一个链表上元素可能会比较多
当unordered_map中的元素比较多时,特定的哈希桶可能会包含较多的元素,形成一个链表。这种情况被称为哈希冲突。哈希冲突发生时,哈希函数将不同的键映射到相同的哈希桶,导致链表的长度增长。
哈希冲突会对unordered_map的性能产生一定的影响。当链表长度较长时,查找操作的平均时间复杂度可能会增加,因为需要遍历链表来找到对应的键值对。最坏情况下,哈希冲突可能导致查找操作的时间复杂度接近O(n),其中n是unordered_map中元素的数量。
这时候查询就比较慢该怎么办
C++标准库在unordered_map中使用了一种称为“链地址法”的方法来处理哈希冲突。当链表长度超过一定阈值时,会将链表转换为更高效的数据结构,如平衡二叉树或跳表,以减少查找的时间复杂度。
尽管如此,当unordered_map中的元素数量较大时,仍然需要谨慎选择合适的哈希函数,以及调整哈希桶的数量和负载因子,以平衡性能和空间的消耗。
如果对于大规模的数据集和高性能要求,可以考虑使用其他的哈希表实现,如Google的Dense Hash Map或Facebook的Folly库中的AtomicHashMap,它们提供了更高效的哈希表实现来处理大规模的数据。
说一下优先队列可以用来做什么
优先队列(Priority Queue)是一种特殊类型的队列,其中每个元素都关联有一个优先级值。优先队列允许高优先级的元素优先于低优先级的元素被访问和处理。它可以用于以下几个方面:
- 排序:优先队列可以用来对元素进行排序。元素根据其优先级被插入到队列中,高优先级的元素会排在前面,低优先级的元素排在后面。当从优先队列中取出元素时,会首先取出优先级最高的元素,从而实现排序的效果。
- 调度:优先队列可用于调度任务或事件。任务可以根据其优先级被添加到优先队列中,并按照优先级顺序进行处理。例如,在操作系统中,可以使用优先队列调度各种进程或线程的执行。
- 最小/最大值查找:通过使用最小堆或最大堆实现的优先队列,可以方便地找到队列中的最小值或最大值。最小堆优先队列保证队列头部元素是最小值,而最大堆优先队列则保证队列头部元素是最大值。
4**. 贪心算法**:优先队列在贪心算法中经常被使用。贪心算法是一种算法范式,它每次选择局部最优解,然后逐步构建全局最优解。优先队列可以帮助贪心算法在每个步骤中选择具有最高优先级的元素。
优先队列提供了一种有序存储和访问元素的数据结构,可以在许多应用中用于排序、调度和选择最值等操作。它是一个非常有用和灵活的数据结构,在算法和数据处理领域有广泛的应用。
STL中的map底层是怎么实现的?红黑树为什么是相对平衡?换做是AVL树会怎么样?红黑树的插入过程
在STL中,map底层一般使用红黑树(Red-Black Tree)实现。
红黑树是一种自平衡的二叉搜索树,它通过在节点上添加额外的颜色属性,并通过一组规则来保持树的平衡性。这些规则确保了红黑树的高度相对平衡,使得在最坏情况下的操作时间复杂度为O(log n)。
为什么红黑树是相对平衡的呢?这是因为红黑树满足以下性质:
- 每个节点要么是红色,要么是黑色。
- 根节点是黑色的。
- 叶子节点(即空节点)都是黑色的。
- 如果一个节点是红色的,则其子节点必须是黑色的。
- 从任意节点到其每个叶子节点的路径都包含相同数目的黑色节点(即黑色节点的高度相等)
这些性质保证了红黑树的关键特性: - 黑色节点的高度相等:根据性质5,红黑树的黑色节点高度相等,从而保证了树的相对平衡性。
- 最长路径不超过最短路径的两倍:根据性质4,红色节点不能相邻,这样就避免了最长路径过长的情况。
如果使用AVL树来实现map,则会得到更严格的平衡性,但付出的代价是在插入和删除操作时需要更多的旋转操作来保持平衡。AVL树要求任何节点的左子树和右子树的高度之差(平衡因子)不超过1,因此在插入新节点时可能需要进行更多的旋转操作,使树保持平衡。尽管AVL树的查找操作稍微快一些,但由于更多的旋转操作,插入和删除的性能相对较低。
红黑树在插入节点时的过程如下: - 将新节点插入到红黑树中,按照二叉搜索树的规则找到合适的位置。
- 将新节点标记为红色。
- 根据红黑树的规则,通过旋转和重新着色等操作,逐步调整树的结构以保持红黑树的平衡性和性质。
- 最后,将根节点标记为黑色,确保性质2成立。
通过这些调整,红黑树可以保持相对平衡,同时满足所有红黑树的性质。
多线程去访问哈希表要注意什么
- 线程安全性:哈希表的线程安全性是最重要的考虑因素之一。如果哈希表的实现不是线程安全的,那么多个线程同时对其进行读写操作可能导致数据不一致或者出现竞态条件。确保选择或实现线程安全的哈希表数据结构,或者采取同步机制(如锁)来保护哈希表的访问。
- 并发写入冲突:在多线程环境下,如果多个线程同时进行写入操作,可能导致写入冲突或数据丢失。为了避免这种情况,可以考虑使用线程安全的哈希表实现,或者采取互斥机制(如锁或读写锁)来保护写入操作。
- 并发读写一致性:当多个线程同时进行读写操作时,需要确保数据的一致性。例如,在一个线程进行写入操作时,其他线程可能正在进行读取操作。为了保证读写一致性,可以采取适当的同步机制,如使用读写锁,允许多个线程同时读取,但在写入时进行独占。
- 哈希冲突处理:哈希表中可能存在哈希冲突,即不同的键可能映射到同一个哈希桶中。在多线程环境下,处理哈希冲突需要特别注意,以避免数据丢失或不一致。常见的解决方法包括链表法和开放地址法。确保选择适当的哈希冲突解决策略,并考虑并发访问时的一致性问题。
- 性能考虑:多线程访问哈希表时,还需要考虑性能因素。竞争条件和同步机制可能引入额外的开销,降低整体性能。因此,需要权衡并发性和性能之间的关系,选择合适的数据结构和同步策略来提高并发访问的效率。
除了加锁还有没有别的方法
- 无锁数据结构:使用无锁的数据结构可以避免使用显式锁带来的开销和竞争条件。无锁数据结构采用原子操作或基于硬件指令的原子性保证,确保并发操作的正确性。例如,无锁的哈希表实现可以使用CAS(Compare-and-Swap)操作来实现并发安全性。
- 分段锁:分段锁将哈希表分成多个段(或分片),每个段都有一个独立的锁。不同的线程可以同时访问不同的段,从而减少了锁的竞争范围,提高并发性能。这种方式可以在保证线程安全的前提下提升并发访问的效率。
- 读写锁:读写锁(也称为共享-独占锁)允许多个线程同时读取数据,但只允许单个线程进行写入操作。这样可以提高读取操作的并发性能,同时保证写入操作的互斥性。读写锁适用于读多写少的场景,可以有效降低锁的粒度。
- 无阻塞算法:无阻塞算法允许多个线程同时进行操作而不需要等待其他线程的完成。这种算法通常使用原子操作、自旋和CAS等技术来实现,并尽量避免线程的阻塞和调度开销。无阻塞算法可以提高并发访问的效率,但也需要更复杂的实现和对内存模型的理解。
vector和list的区别
vector:在内存空间连续分布,支持下标随机访问,查询时间复杂度O(1),插入和删除时间复杂度O(n),迭代器可能会在插入或删除后失效,因为可能会重新分配到新的内存位置
list:在内存空间是节点相连方式,需要通过迭代器遍历,查询时间复杂度O(n),插入和删除时间复杂度O(1),迭代器是稳定的,插入删除不会影响,每个元素需要额外的指针,内存占用
vector是怎么扩容的
1)分配一块更大的内存空间,通常是2倍
2)将原来空间的元素全部拷贝到新的内存空间
3)释放原来的内存空间
vector的内存是怎么分配的
在 C++ 中,std::vector 是一个动态数组,它使用连续的内存块来存储元素。当创建 std::vector 并添加元素时,它会动态地分配和管理内存。下面是 std::vector 内存分配的一般过程:
- 初始分配:当创建一个空的
std::vector对象时,它不会分配任何内存。只有在开始添加元素时,才会进行初始分配。这通常发生在第一个元素被插入时。 - 分配内存块:当需要存储元素时,
std::vector会根据需要动态地分配一块连续的内存空间。它使用动态内存分配函数(如new或malloc)来分配内存。分配的内存块的大小通常会根据实现细节和策略来确定,但至少足够存储当前的元素。 - 扩容:当
std::vector中的元素数量达到当前内存块的容量时,需要进行扩容。此时,std::vector会分配一块更大的内存空间,并将现有元素复制到新的内存块中。这涉及到分配更大的内存块,并将旧数据复制到新的内存块中,然后释放旧内存块。 - 内存释放:当
std::vector对象被销毁或显式调用clear()函数时,它会释放所分配的内存,确保没有内存泄漏。释放内存通常使用动态内存释放函数(如delete或free)来完成。
需要注意的是,std::vector的内存分配可能会引起元素的复制和内存的重新分配,因此在对大量元素进行插入或删除操作时,性能开销可能会增加。为了避免频繁的内存分配和复制,可以通过使用 **reserve()**函数预留足够的内存空间,以减少重新分配的次数。
vector的reserve()和resize()的区别,也就是说容量和大小是不一样的是吗?
std::vector 的 reserve() 和 resize() 是用于调整容器的容量和大小的函数,它们具有不同的作用和行为:
reserve(n):reserve()函数用于预留足够的内存空间,以容纳至少n个元素,但不改变实际的元素数量(大小)。它会在不触发元素复制或构造的情况下,仅仅分配足够的内存,以提前为未来的元素添加操作做准备。reserve()不会改变size(),即元素的实际数量不变。
std::vector<int> vec;
vec.reserve(10); // 预留至少能容纳10个元素的内存空间,但元素数量仍为0
resize(n):resize()函数用于改变std::vector的大小(元素数量),并相应地分配或释放内存空间。如果n大于当前的size(),则会在尾部添加默认构造的元素,使得size()等于n。如果n小于当前的size(),则会删除尾部的元素,使得size()等于n。
std::vector<int> vec;
vec.resize(5); // 改变元素数量为5,新增的元素使用默认构造
vec.resize(3); // 改变元素数量为3,删除尾部的元素
总结:
reserve()用于预留足够的内存空间,不改变实际的元素数量。resize()用于改变std::vector的大小(元素数量),并相应地分配或释放内存空间。
容量(capacity)指的是为std::vector分配的内存空间大小,可以容纳的最大元素数量。大小(size)指的是std::vector实际包含的元素数量。因此,容量和大小是两个不同的概念,reserve()和resize()分别用于调整容量和大小。
vector的内存怎么释放?用clear()能释放掉吗
std::vector 的内存会在对象销毁时自动释放,或者在调用 clear() 函数时进行释放。
- 对象销毁:当
std::vector对象超出其作用域或被显式销毁时,其析构函数会被调用,从而释放所分配的内存。
{std::vector<int> vec; // 创建 std::vector 对象// 使用 vec ...
} // vec 超出作用域,其析构函数会被调用,释放内存
clear()函数:clear()函数用于清空std::vector中的所有元素,并释放相应的内存。调用clear()后,std::vector的大小变为 0,但其容量并不改变,内存并未立即释放。
```cpp
std::vector<int> vec;
// 向 vec 添加元素 ...
vec.clear(); // 清空元素,但内存空间仍保留,容量不变
注意,调用 `clear()` 并不会立即释放内存,而是将 `std::vector` 的大小设置为 0,但保留已分配的内存空间。这样做是为了避免频繁的内存分配和释放,以提高性能。
如果希望释放内存并将容量设置为0,可以使用 `std::vector` 的 `shrink_to_fit()` 函数,它会要求释放未使用的内存空间,并将容量调整为与实际大小相匹配。
```cpp
std::vector<int> vec;
// 向 vec 添加元素 ...
vec.clear(); // 清空元素,但内存空间保留
vec.shrink_to_fit(); // 释放未使用的内存空间,容量变为0
总结:
std::vector的内存会在对象销毁时自动释放。clear()函数用于清空元素,但并不立即释放内存。- 如果希望释放未使用的内存并将容量设置为0,可以使用
**shrink_to_fit()** 函数。
push_back和emplace_back的区别
- 参数传递方式:
- push_back:接受一个已经构造的对象,并将其拷贝(或移动)到容器中。需要在调用 push_back之前创建一个完整的对象。
- emplace_back:接受构造函数的参数,直接在容器内部构造一个新的对象。不需要提前创建对象,可以直接传递构造函数的参数。
- 对象构造方式:
- push_back:通过拷贝(或移动)已有的对象,需要调用拷贝构造函数或移动构造函数。
- emplace_back:直接在容器内部构造一个新对象,使用适当的构造函数。
- 性能:
- push_back:由于需要先创建对象,然后再进行拷贝(或移动),可能会引入额外的构造和拷贝开销。
- emplace_back:直接在容器内部构造对象,避免了**拷贝(或移动)**的开销,可以更高效地插入元素。
- 方便性:
- push_back:适用于已经存在的对象,可以方便地将它们添加到容器中。
- emplace_back:适用于通过构造函数的参数直接在容器中构造对象,无需显式创建对象。
总结:push_back 适用于已经存在的对象,需要通过拷贝(或移动)来添加到容器中。emplace_back则适用于直接在容器内部构造新对象,避免了额外的拷贝(或移动)开销,提供了更高的性能和方便性。因此,如果可以直接传递构造函数的参数,并且不需要提前创建对象,推荐使用 emplace_back。否则,如果已经有完整的对象,并且需要将其添加到容器中,可以使用 push_back
emplace_back插入的时候如果内存区域被占了,怎么办
当使用 emplace_back 向容器中插入元素时,如果内存区域被占用(例如,容器的内部存储空间已满),容器会自动进行内存重新分配以容纳新元素。这个过程是由容器自动处理的,你不需要额外的操作。
具体地,当容器的内部存储空间不足时,容器会执行以下操作:
- 分配更大的内存空间:容器会分配一个更大的内存块,以容纳更多的元素。它可能会使用不同的策略来确定新的内存大小,例如按一定的倍数扩展(如1.5倍或2倍)。
- 复制现有元素:容器会将现有的元素从旧的内存位置复制到新的内存位置,以便在容器扩展后仍然保留原有的元素。
- 构造新元素:在容器的扩展内存区域中构造新的元素。
- 释放旧内存:容器会释放旧的内存空间,确保不再使用。
通过动态扩展内存,容器可以容纳更多的元素,而不会因为内存限制而导致插入操作失败。你可以继续使用 emplace_back`来插入新元素,容器会自动处理内存的重新分配。需要注意的是,动态扩展内存的过程可能涉及内存分配和元素复制或移动,这可能会带来一定的性能开销。因此,在需要大规模插入元素的情况下,可以通过预分配足够的内存空间或使用 reserve函数提前预留容器的内存,以避免频繁的动态扩展和复制操作,提高性能。
vector迭代器失效
在处理一个 vector 列表时,如果使用迭代器进行元素删除操作,只有被删除的元素之后的迭代器会失效。被删除元素之前的迭代器仍然有效。
为了避免迭代器失效的问题,你可以使用 erase函数,该函数接受一个迭代器参数并在删除元素后返回一个指向下一个元素的迭代器。
vector扩容迭代器会失效吗
进行扩容时,迭代器可能会失效。这是因为在扩容过程中,vector可能会重新分配内存并将现有的元素复制到新的内存位置。这导致之前获取的迭代器指向的是旧的内存位置,因此它们会失效。
当 vector 的大小超过其容量时,会触发重新分配内存的过程。这通常涉及将元素复制到一个新的内存位置,并释放旧的内存。在这个过程中,迭代器指向旧的内存位置,但复制后的元素存储在新的内存位置上。
为了避免迭代器失效的问题,可以使用索引来代替迭代器,或者在扩容之后重新获取迭代器。
list迭代器会失效吗
list进行插入或删除操作时,迭代器不会失效。这是因为 list是一个双向链表的容器,其内部结构允许在插入或删除元素时保持现有的迭代器的有效性。
list的迭代器是以节点为基础的,每个节点存储一个元素,并包含指向前一个节点和后一个节点的指针。当进行插入或删除操作时,list可以通过重新链接节点来维护迭代器的有效性,而不需要重新分配内存或复制元素。
与 vector 不同,list的迭代器在插入和删除操作后仍然保持有效。这使得 list在需要频繁插入和删除元素的场景中更加适用。
如果是单向链表slist呢?
如果是单向链表(单链表),则在删除节点之后,节点的迭代器会失效,因为单向链表的节点只包含指向下一个节点的指针,无法回溯到前一个节点。
当删除单向链表中的节点时,需要特别注意迭代器的失效问题。如果要删除当前节点,需要在删除之前记录下一个节点的指针,然后删除当前节点,并使用记录的下一个节点的指针更新迭代器。
需要注意的是,由于单向链表只有指向下一个节点的指针,无法回溯到前一个节点**,因此删除当前节点后,该节点之后的迭代器都会失效**。
优先级队列
优先级队列(Priority Queue)是一种特殊类型的队列,其中每个元素都具有与之关联的优先级值。这使得优先级队列能够以特定顺序处理元素,通常按照优先级从高到低或从低到高的顺序。
以下是关于优先级队列的一些关键特点和用途:
- 元素排序:元素按照其优先级值进行排序,通常由比较函数或比较算子定义。元素的优先级高的会排在前面。
- 插入和删除:优先级队列支持在队尾插入元素和在队首删除元素。插入操作将元素按照其优先级插入到正确的位置,而删除操作通常会删除队首元素,即最高优先级元素。
- 高效的操作:优先级队列通常基于堆(Heap)数据结构实现,因此插入和删除操作的时间复杂度是O(log N),其中N是队列中元素的数量。这使得它非常适合在大型数据集上执行高效的优先级排序。
- 用途:优先级队列在很多应用中都有用,如任务调度、数据压缩、图算法(如Dijkstra算法和Prim算法)、时间管理等。它们可以帮助处理需要按照重要性或优先级排序的元素的情况。
在C++中,STL提供了std::priority_queue类模板,它是一个优先级队列的标准实现,可以用于各种应用中。你可以使用push方法插入元素,使用top方法访问队首元素,以及使用pop方法删除队首元素。
下面是一个简单的示例,演示如何使用C++的std::priority_queue创建一个升序的整数优先级队列:
#include <iostream>
#include <queue>int main() {std::priority_queue<int, std::vector<int>, std::greater<int>> pq;pq.push(3);pq.push(1);pq.push(4);while (!pq.empty()) {std::cout << pq.top() << " ";pq.pop();}return 0;
}二叉树,AVL树,红黑树的插入删除查找时间复杂度
n代表容器元素数量
二叉树
- 插入:O(1)
- 删除:O(1)
- 查找:O(n)
二叉搜索树
- 插入:O(log n) 平均,O(n) 最坏情况(树不平衡时)
- 删除:O(log n) 平均,O(n) 最坏情况(树不平衡时)
- 查找:O(log n) 平均,O(n) 最坏情况(树不平衡时)
AVL树(平衡二叉搜索树)
- 插入:O(log n)
- 删除:O(log n)
- 查找:O(log n)
红黑树
- 插入:O(log n)
- 删除:O(log n)
- 查找:O(log n)
map和set介绍一下,底层结构
都是关联式容器,底层数据结构都是红黑树
set存储不重复的元素
map存储键值对,通常用于建立一 一对应的关系
hashtable的思想
最简单的实现就是数组,通过下标访问元素
其实hashtable就是通过哈希function将关键字映射到数组中的位置
使得散列表能够在O(1)时间复杂度内进行数据的插入、删除和查找操作
如何解决哈希冲突
不同关键字映射到相同的哈希码
线性探测法:发生冲突寻找下一个可用位置,直到找到空槽
拉链法:每个数组位置维护一个链表,映射到同一位置的存储在链表上
线性数据结构和非线性数据结构
不是指在内存中的排列方式,是数据元素是否按照顺序的方式排列
线性:数组,链表(逻辑线性),栈,队列
非线性:没有严格的顺序关系,树,图,堆
二叉树,AVL树,红黑树的插入删除查找时间复杂度
n代表容器元素数量
二叉树
- 插入:O(1)
- 删除:O(1)
- 查找:O(n)
二叉搜索树
- 插入:O(log n) 平均,O(n) 最坏情况(树不平衡时)
- 删除:O(log n) 平均,O(n) 最坏情况(树不平衡时)
- 查找:O(log n) 平均,O(n) 最坏情况(树不平衡时)
AVL树(平衡二叉搜索树)
- 插入:O(log n)
- 删除:O(log n)
- 查找:O(log n)
红黑树
- 插入:O(log n)
- 删除:O(log n)
- 查找:O(log n)
map和set介绍一下,底层结构
都是关联式容器,底层数据结构都是红黑树
set存储不重复的元素
map存储键值对,通常用于建立一 一对应的关系
hashtable的思想
最简单的实现就是数组,通过下标访问元素
其实hashtable就是通过哈希function将关键字映射到数组中的位置
使得散列表能够在O(1)时间复杂度内进行数据的插入、删除和查找操作
哈希表怎么处理碰撞问题?最差能退化到什么复杂度?
哈希表在处理碰撞问题时有几种常见的策略:
- 链地址法(Chaining):将哈希表中每个桶(bucket)设置为一个链表或其他数据结构,当发生碰撞时,将冲突的元素添加到对应桶的链表中。这样,同一个桶中的元素都具有相同的哈希值,但可能有不同的键值。在查找元素时,首先根据哈希值找到对应的桶,然后在桶的链表中线性搜索目标元素。
- 开放地址法(Open Addressing):当发生碰撞时,通过一系列的探测(probe)步骤,在哈希表中寻找下一个可用的空槽来存放冲突的元素。常见的探测方法包括线性探测(Linear Probing)、二次探测(Quadratic Probing)、双重散列(Double Hashing)等。在查找元素时,根据哈希值找到对应的桶,如果目标元素不在该桶中,则按照一定规则依次探测下一个槽,直到找到目标元素或者遇到空槽。
- 建立公共溢出区域(Overflow Area):将所有冲突的元素存放在一个单独的溢出区域中,这样哈希表的桶只存放不冲突的元素。在查找元素时,先根据哈希值找到桶,如果目标元素不在桶中,则在溢出区域中进行查找。
最差情况下,如果哈希函数的质量较差或者哈希表的负载因子过高,导致冲突频繁发生,哈希表的性能可能会退化到O(n)的复杂度,其中n为哈希表中元素的数量。这是因为每次查找或插入时都需要遍历链表或进行多次探测,直到找到合适的位置或者遍历完所有元素。
为了避免哈希表退化到最差情况,可以采取以下策略:
- 选择合适的哈希函数,尽量减少哈希冲突的发生。
- 控制哈希表的负载因子,即哈希表中元素数量与桶的数量之比,一般保持在合理范围内,如0.7左右。
- 当哈希表负载因子过高时,进行动态扩容,增加桶的数量,从而降低冲突的概率。
- 在使用开放地址法时,选择合适的探测方法,避免产生聚集(clustering)现象,即相邻位置的冲突倾向聚集在一起,导致探测路径较长。
总结起来,处理哈希表碰撞问题的关键是选择合适的解决策略,并合理调整哈希函数和哈希表参数,以在大多数情况下保持较好的性能。
线性数据结构和非线性数据结构
不是指在内存中的排列方式,是数据元素是否按照顺序的方式排列
线性:数组,链表(逻辑线性),栈,队列
非线性:没有严格的顺序关系,树,图,堆
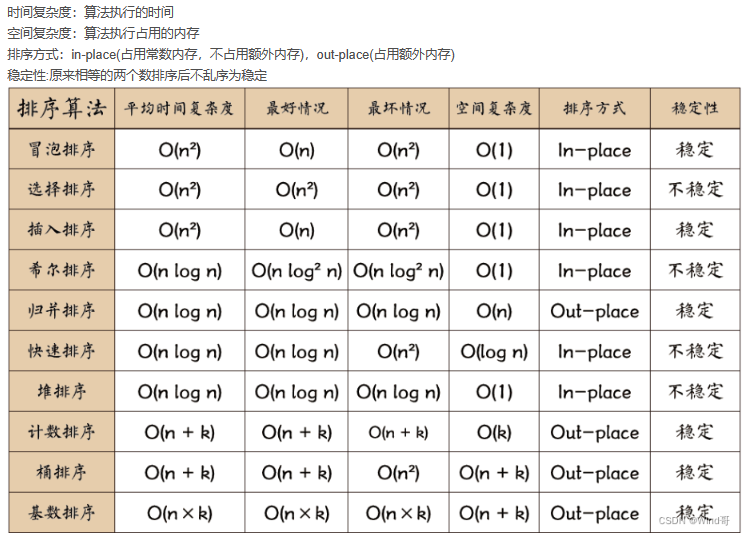
排序算法
:::info
时间复杂度最好情况 最坏情况 空间复杂度 是否稳定 是否基于比较 排序方式
冒泡 O(n) O(n2) O(1) 稳定 是 内部
插入 O(n) O(n2) O(1) 稳定 是 内部
选择 O(n2) O(n2) O(1) 不稳定 是 内部
快排 O(nlogn) O(n2) O(logn) 不稳定 是 内部
堆排 O(nlogn) O(nlogn) O(1) 不稳定 是 内部
归并 O(nlogn) O(nlogn) O(n) 稳定 是 外部
希尔 O(nlog2n) O(nlog2n) O(1) 不稳定 是 内部
桶 O(n+k) O(n+k) O(k) 稳定 否 外部
计数 O(n+k) O(n2) O(n+k) 稳定 否 外部
基数 O(nk) O(nk) O(n+k) 稳定 否 外部
:::
归并排序、快排、堆排分别的复杂度和应用场景
要稳定就用归并
要节省空间就用堆排
外部排序和内部排序的区别
内部排序:内存中对小规模数据进行排序,效率高
外部排序:大规模数据集,数据分块,适应内存大小,每个块排序,涉及磁盘的使用,效率低
稳定
冒泡:布尔值
比较相邻元素的大小
void bubbleSort(vector<int>& nums) {int n = nums.size();bool flag = false;for (int i = 0; i < n - 1; ++i) {//i = 0 起,循环了n - 1趟,更符合规范理解//for (int i = 0; i < n; ++i) {//i = 0 起,循环了n 趟,不影响结果flag = false;for (int j = 0; j < n - 1 - i; ++j) {if (nums[j] > nums[j + 1]) {//某⼀趟排序中,只要发⽣⼀次元素交换,flag就从false变为了true//也即表示这⼀趟排序还不能确定所剩待排序列是否已经有序,应继续下⼀趟循环swap(nums[j], nums[j + 1]);flag = true;}}//但若某⼀趟中⼀次元素交换都没有,即依然为flag = false//那么表明所剩待排序列已经有序//不必再进⾏趟数⽐,外层循环应该结束,即此时if (!flag) break; 跳出循环if (!flag) { break; }}
}
插入:打扑克牌
将元素插入到已排序的部分中,通过比较找到正确位置
归并:中间划分区间递归
分治策略,比较和合并
计数:统计小于某个元素的个数,不是比较排序
桶排序:将值为i的元素放⼊i号桶,最后依次把桶⾥的元素倒出来
基数:多关键字排序,可用桶排序实现
不稳定
选择:选择一个最小的放前面
通过多次选择未排序部分的最小元素来排序
希尔:插入排序变种,跳跃式接近
插入排序的改进,跳跃式接近
快排:找枢轴点,递归
分治策略,将元素分为较小和较大的两部分
堆排:建堆,堆排
构建二叉堆,反复删除最大元素
sort排序用的是什么
数量比较少的时候用的插入,数量多的话用的是快排,递归深度达到某个阈值用堆排
sort里的cmp
//把数组排成最小的数
/*对vector容器内的数据进行排序,按照 将a和b转为string后若 a+b<b+a a排在在前 的规则排序,如 2 21 因为 212 < 221 所以 排序后为 21 2 to_string() 可以将int 转化为string*/class Solution {public:static bool cmp(int a,int b){string A="",B="";A+=to_string(a);A+=to_string(b);B+=to_string(b);B+=to_string(a); return A<B;}string PrintMinNumber(vector<int> numbers) {string answer="";sort(numbers.begin(),numbers.end(),cmp);for(int i=0;i<numbers.size();i++){answer+=to_string(numbers[i]);}return answer;}};//法二
/**string minNumber(vector<int>& nums) {vector<string> temp;for (auto num : nums) {temp.push_back(to_string(num));}sort(temp.begin(), temp.end(), [](const string& a, const string& b) { return a + b < b + a; });string result;for (auto& t : temp) {result += t;}return result;
}*/sort中的比较函数compare要声明为静态成员函数或全局函数,不能作为普通成员函数,否则会报错。 因为:非静态成员函数是依赖于具体对象的,而std::sort这类函数是全局的,因此无法再sort中调用非静态成员函数。静态成员函数或者全局函数是不依赖于具体对象的, 可以独立访问,无须创建任何对象实例就可以访问。同时静态成员函数不可以调用类的非静态成员。
快速排序:时间复杂度为nlogn,不稳定
快排的原理
- 选择一个基准元素。
- 将小于等于基准元素的元素移动到数组左边,大于基准元素的元素移动到数组右边,这个过程称为划分。
- 递归地对划分后的左右两个子序列进行排序。
在实际实现中,sort函数还有一些优化,例如:
- 当排序的元素个数小于一定阈值时,使用插入排序算法。
- 当出现大量重复元素时,使用三向划分快速排序算法。
为什么选快排
默认它的分布是比较随机的那种分布,然后快排在比较随机的分布上,表现的比较好,速度比较快
算法思想
1、选取第⼀个数为基准
2、将⽐基准⼩的数交换到前⾯,⽐基准⼤的数交换到后⾯
3、对左右区间重复第⼆步,直到各区间只有⼀个数
从数组中选择⼀个元素,把这个元素称之为中轴元素吧,然后把数组中所有⼩于中轴元素的元素放在其左边,所有⼤于或等于中轴元素的元素放在其右边,显然,此时中轴元素所处的位置的是有序的。也就是说,我们⽆需再移动中轴元素的位置。 从中轴元素那⾥开始把⼤的数组切割成两个⼩的数组(两个数组都不包含中轴元素),接着我们通过递归的⽅式,让 中轴元素左边的数组和右边的数组也᯿复同样的操作,直到数组的⼤⼩为1,此时每个元素都处于有序的位置
void quickSort(vector<int>& a, int low, int high) {//结束标志if (low >= high) return;int last = high; // ⾼位下标int first=low;int key = a[first]; // 设第⼀个为基准while (first < last){// 从后往前⾛,将⽐第⼀个⼩的移到前⾯while (first < last && a[last] > key){last--;}if (first < last) a[first++] = a[last];//从前往后⾛, 将⽐第⼀个⼤的移到后⾯while (first < last && a[first] <= key){ first++;}if (first < last) a[last--] = a[first];}a[first] = key;// 前半递归quickSort(a, low, first - 1);// 后半递归quickSort(a, first + 1, high);
}//调用
quickSort(A, 0,A.size()-1);
for (auto a : A) {cout << a << endl;
}
打印版本
#include<iostream>
#include<vector>
using namespace std;void print_nums(vector<int>& nums) {for (auto& i : nums) {cout << i << " ";}
}void quick_sort(vector<int>&nums,int left,int right) {if (left >= right) return;int low = left;int high = right;int val=nums[low];cout << low << " " << high << " " << val << endl;print_nums(nums);cout << endl;while (low < high) {while (low < high && nums[high]>val) {high--;}if (low < high) {nums[low++] = nums[high];}while (low < high && nums[low] <= val) {low++;}if (low < high) {nums[high--] = nums[low];}}nums[low]=val;cout << "the index " << low << " value " << val << endl;quick_sort(nums,left,low-1);quick_sort(nums,low + 1, right);
}int main() {vector<int>nums{ 1,5,3,7,2,6,9,8 };quick_sort(nums, 0, nums.size() - 1);cout << "快速排序后" << endl;print_nums(nums);return 0;
}
归并排序:时间复杂度为nlogn ,稳定
将⼀个⼤的⽆序数组有序,我们可以把⼤的数组分成两个,然后对这两个数组分别进⾏排序,之后在把这两个数组 合并成⼀个有序的数组。由于两个⼩的数组都是有序的,所以在合并的时候是很快的。 通过递归的⽅式将⼤的数组⼀直分割,直到数组的⼤⼩为 1,此时只有⼀个元素,那么该数组就是有序的了,之后 再把两个数组⼤⼩为1的合并成⼀个⼤⼩为2的,再把两个⼤⼩为2的合并成4的 … 直到全部⼩的数组合并起来
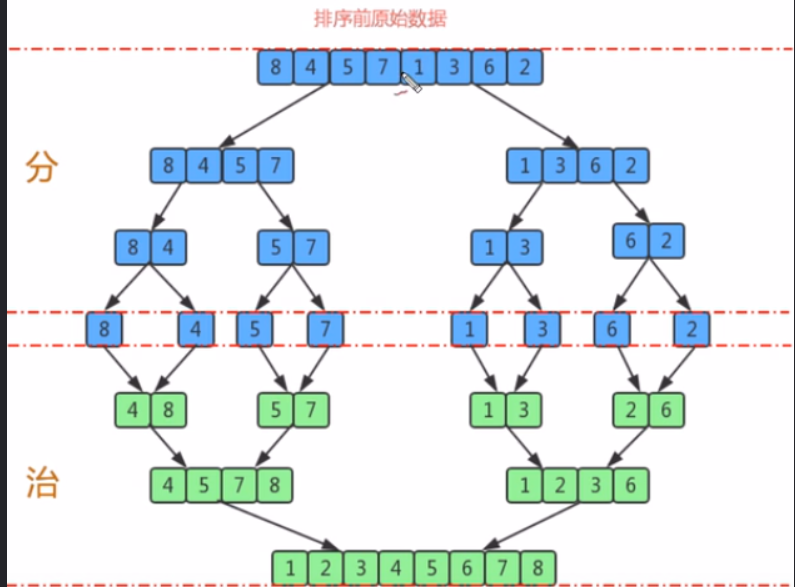
归并排序是建⽴在归并操作上的⼀种有效的排序算法。该算法是采⽤分治法(Divide and Conquer)的⼀个⾮常典 型的应⽤。将已有序的⼦序列合并,得到完全有序的序列;即先使每个⼦序列有序,再使⼦序列段间有序。若将两个有序表合并成⼀个有序表,称为2-路归并。
算法思想
1、把⻓度为n的输⼊序列分成两个⻓度为n/2的⼦序列;
2、对这两个⼦序列分别采⽤归并排序;
3、 将两个排序好的⼦序列合并成⼀个最终的排序序列。
比如将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8]
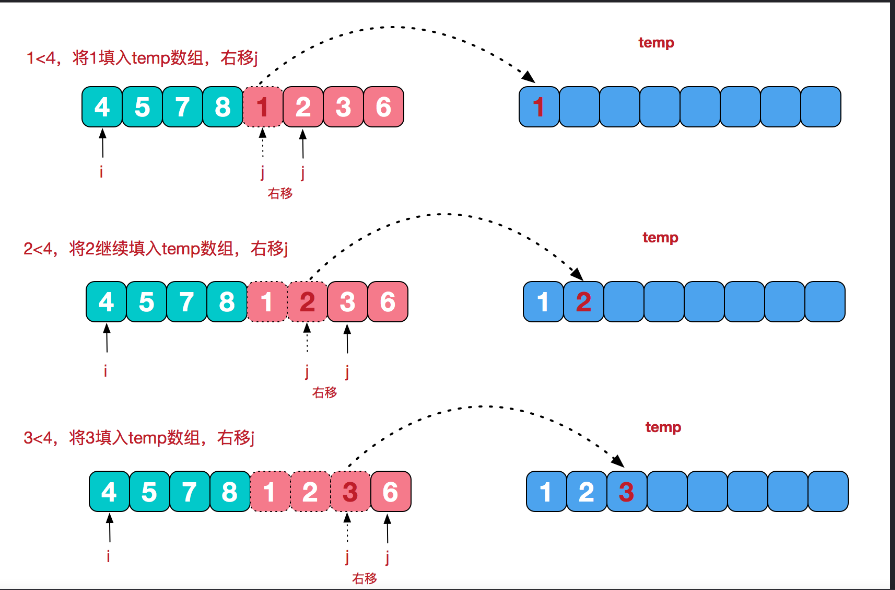
void mergeSortCore(vector<int>& data, vector<int>& dataTemp, int low, int high) {if (low >= high) return;int len = high - low, mid = low + len / 2;int start1 = low, end1 = mid, start2 = mid + 1, end2 = high;mergeSortCore(data, dataTemp, start1, end1);mergeSortCore(data, dataTemp, start2, end2);int index = low;while (start1 <= end1 && start2 <= end2) {dataTemp[index++] = data[start1] < data[start2] ? data[start1++] : data[start2++];}while (start1 <= end1) {dataTemp[index++] = data[start1++];}while (start2 <= end2) {dataTemp[index++] = data[start2++];}for (index = low; index <= high; ++index) {data[index] = dataTemp[index];}
}
void mergeSort(vector<int>& data) {int len = data.size();vector<int> dataTemp(len, 0);mergeSortCore(data, dataTemp, 0, len - 1);
}
打印版本
#include<iostream>
#include<vector>
using namespace std;void print_nums(vector<int>& nums) {for (auto& i : nums) {cout << i << " ";}
}void merge_sort(vector<int>&nums, vector<int>&temp, int low, int high) {if (low >= high) return;int mid = low + (high - low) / 2;int start1 = low, end1 = mid;int start2 = mid+1, end2 = high;merge_sort(nums, temp, start1,end1);merge_sort(nums, temp, start2,end2);int index = low;while (start1 <= end1 && start2 <= end2) {temp[index++] = nums[start1] < nums[start2] ? nums[start1++] : nums[start2++];}while (start1 <= end1) {temp[index++] = nums[start1++];}while (start2 <= end2) {temp[index++] = nums[start2++];}for (index = low; index <= high; index++) {nums[index] = temp[index];}
}int main() {vector<int>nums{ 1,5,3,7,2,6,9,8 };vector<int>temp(nums.size(), 0);merge_sort(nums,temp, 0, nums.size() - 1);cout << "归并排序后" << endl;print_nums(nums);return 0;
}
堆排序:时间复杂度为nlogn,不稳定
大根堆:每个节点的值都大于或者等于他的左右孩子节点的值
小根堆:每个结点的值都小于或等于其左孩子和右孩子结点的值
注意:升序用大根堆,降序就用小根堆(默认为升序)
算法思想:大根堆升序为例
1.首先将待排序的数组构造成一个大根堆,此时,整个数组的最大值就是堆结构的顶端
2.将顶端的数与末尾的数交换,此时,末尾的数为最大值,剩余待排序数组个数为n-1
3.将剩余的n-1个数再构造成大根堆,再将顶端数与n-1位置的数交换,如此反复执行,便能得到有序数组
void HeapAdjust(int* arr, int start, int end){int tmp = arr[start];for (int i = 2 * start + 1; i <= end; i = i * 2 + 1){//有右孩子并且左孩子小于右孩子if (i < end&& arr[i] < arr[i + 1]){i++;}//i一定是左右孩子的最大值if (arr[i] > tmp){arr[start] = arr[i];start = i;}else{break;}}arr[start] = tmp;
}void HeapSort(int* arr, int len){//第一次建立大根堆,从后往前依次调整for(int i=(len-1-1)/2;i>=0;i--){HeapAdjust(arr, i, len - 1);}//每次将根和待排序的最后一次交换,然后在调整int tmp;for (int i = 0; i < len - 1; i++){tmp = arr[0];arr[0] = arr[len - 1-i];arr[len - 1 - i] = tmp;HeapAdjust(arr, 0, len - 1-i- 1);}
}int main(){int arr[] = { 9,5,6,3,5,3,1,0,96,66 };HeapSort(arr, sizeof(arr) / sizeof(arr[0]));printf("排序后为:");for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){cout<<arr[i]<<" ";}return 0;
}
图论
最短路径算法
迪杰斯特拉算法(Dijkstra’s algorithm):
- 类型: 单源最短路径算法。
- 目标: 用于找到从一个起始节点到图中所有其他节点的最短路径。
- 运行方式: 从起始节点开始,依次将距离最短的节点加入到已经确定最短路径的集合中,然后更新其他节点到起始节点的距离。
- 适用性: 适用于没有负权边的图。
- 时间复杂度: 在一般实现中,时间复杂度为O((V + E) * log(V)),其中V是节点数,E是边数。
弗洛伊德算法(Floyd’s algorithm):
- 类型: 全源最短路径算法。
- 目标: 用于找到图中所有节点之间的最短路径。
- 运行方式: 采用动态规划的思想,逐步更新节点之间的最短路径。
- 适用性: 适用于有向图或无向图,边的权值可以是负数。
- 时间复杂度: 时间复杂度为O(V^3),其中V是节点数。
区别总结:
- 问题类型: 迪杰斯特拉算法解决的是单源最短路径问题,而弗洛伊德算法解决的是全源最短路径问题。
- 适用性: 迪杰斯特拉算法对负权边不敏感,但不能处理带有负权环的图,而弗洛伊德算法可以处理带有负权边和负权环的图。
- 时间复杂度: 迪杰斯特拉算法的时间复杂度相对较低,但在处理大规模图时可能不如弗洛伊德算法高效。
拓扑排序
拓扑排序是一种对有向无环图(DAG,Directed Acyclic Graph)进行排序的算法。在拓扑排序中,图中的每个节点代表一个任务,而图中的有向边则表示任务之间的依赖关系。拓扑排序的目标是找到一种排列,使得所有的任务都按照依赖关系的方向进行排序。
拓扑排序的主要特点是:如果图中存在一条从节点A到节点B的有向边,那么在排序中节点A一定出现在节点B的前面。
拓扑排序的步骤:
- 选择一个没有入边的节点作为起始点。 在图中可能存在多个入度为0的节点,选择其中任意一个作为起始点。
- 删除起始点及其出边。 将选定的起始点从图中删除,并更新其他节点的入度。
- 重复步骤1和2,直到所有节点都被选择。 按照上述步骤选择节点,直到图中所有节点都被选择为止。
拓扑排序的应用:
拓扑排序广泛应用于任务调度、编译器优化、依赖关系分析等领域。例如,如果你有一系列任务,每个任务都有一些依赖关系,拓扑排序可以帮助确定任务的执行顺序,确保满足所有的依赖关系。
在编译器中,源代码中的函数或模块之间存在依赖关系,拓扑排序可以确定编译的顺序,确保每个模块在被调用之前已经被编译。
相关文章:
数据结构与算法面试题——C++
自己在秋招过程中遇到的数据结构与算法方面的面试题 数据结构 vector vector是⼀种序列式容器,与array唯⼀差别就是对于空间运⽤的灵活性 array占⽤的是静态空间,⼀旦配置了就不可以改变⼤⼩,如果遇到空间不⾜的情况还要⾃⾏创建更⼤的空间…...

数字音频工作站FL Studio21.1中文版本如何下载?
在现在这个数字音乐时代,各种音乐中都或多或少有些电子音乐的影子,或是合成器音色、或是通过数字效果器制作出的变幻莫测的变化效果。而小马丁、Brooks、Eliminate等众多电子音乐巨头便是使用FL Studio来制作音乐的。今天小编就以FL Studio五年的资深用户…...
Linux 无名管道实现文件复制
无名管道 通过一个管道(假象)进行传输数据,但是这个管道的传输方式是单工(半双工)的,就是这个管道允许进行发送和接受数据,不过不能同时进行。 创建无名管道 这里用到一个pipe(&…...
【机器学习】 逻辑回归算法:原理、精确率、召回率、实例应用(癌症病例预测)
1. 概念理解 逻辑回归,简称LR,它的特点是能够将我们的特征输入集合转化为0和1这两类的概率。一般来说,回归不用在分类问题上,但逻辑回归却能在二分类(即分成两类问题)上表现很好。 逻辑回归本质上是线性回归,只是在特…...

算法萌新闯力扣:存在重复元素II
力扣题:存在重复元素II 开篇 这道题是217.存在重复元素的升级版,难度稍微提高。通过这道题,能加强对哈希表和滑动窗口的运用。 题目链接:219.存在重复元素II 题目描述 代码思路 1.利用哈希表,来保存数组元素及其索引位置 2.遍…...
《洛谷深入浅出基础篇》——P3405 citis and state ——哈希表
上链接:P3405 [USACO16DEC] Cities and States S - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)https://www.luogu.com.cn/problem/P3405 上题干: 题目描述 Farmer John 有若干头奶牛。为了训练奶牛们的智力,Farmer John 在谷仓的墙上放了一…...
在QGIS中加载显示3DTiles数据
“我们最近有机会在QGIS 3.34中实现一个非常令人兴奋的功能–能够以“Cesium 3D Tiles”格式加载和查看3D内容!” ——QGIS官方的 宣传介绍。 体验一下,感觉就是如芒刺背、如坐针毡、如鲠在喉。 除非我电脑硬件有问题,要么QGIS的3Dtiles是真…...

HBase学习笔记(3)—— HBase整合Phoenix
目录 Phoenix Shell 操作 Phoenix JDBC 操作 Phoenix 二级索引 HBase整合Phoenix Phoenix 简介 Phoenix 是 HBase 的开源 SQL 皮肤。可以使用标准 JDBC API 代替 HBase 客户端 API来创建表,插入数据和查询 HBase 数据 使用Phoenix的优点 在 Client 和 HBase …...

CentOS 7上生成HTTPS证书
在CentOS 7上生成HTTPS证书,可以使用OpenSSL工具。以下是在CentOS 7上生成自签名HTTPS证书的步骤: 安装OpenSSL: sudo yum install openssl生成证书和私钥: openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout ssl.…...

解决React遍历每次渲染多个根元素导致无法为元素赋值key的问题
遍历时,存在多个根标签,如果使用<></>无法正确赋值key,代码如下: function App() {const list [{ id:1, name:"小明" },{ id:2, name:"小田" },{ id:3, name:"小王" }]const listCon…...

2023年软件安装管家目录最新
软件目录 ①【电脑办公】电脑系统(直接安装)Win7Win8Win10OfficeOffice激活office2003office2007office2010office2013office2016office2019office365office2021wps2021Projectproject2007project2010project2016project2019project2013project2021Visio…...
mac苹果笔记本应用程序在哪?有什么快捷方式吗?
苹果笔记本电脑一直以来都被广泛使用,而苹果的操作系统 macOS 也非常受欢迎。一台好的笔记本电脑不仅仅依赖于硬件配置,还需要丰富多样的应用程序来满足用户的需求。苹果笔记本应用程序在哪,不少mac新手用户会有这个疑问。在这篇文章中&#…...

py 循环打开多个页面
在Python中,你可以使用selenium库来循环打开多个页面并进行场控。Selenium是一个用于网页自动化测试的工具,它能够模拟用户与网页交互的操作,如点击、输入等。 以下是一个基本的示例代码,演示如何使用Selenium循环打开多个页面并…...

AD教程 (十八)导入常见报错解决办法(unkonw pin及绿色报错等)
AD教程 (十八)导入常见报错解决办法(unkonw pin及绿色报错等) 常见报错解决办法 绿色报错 可以先按TM,复位错位标识绿色报错原因一般是由于规则冲突的原因,和规则冲突就会报错 点击工具,设计…...

ubuntu22.04下hadoop3.3.6+hbase2.5.6+phoenix5.1.3开发环境搭建
一、涉及软件包资源清单 1、java 这里使用的是openjdk 2、hadoop-3.3.6.tar.gz 3、hbase-2.5.6-hadoop3-bin.tar.gz 4、phoenix-hbase-2.5-5.13-bin.tar.gz 5、apache-zookeeper-3.8.3-bin.tar.gz 6、openssl-3.0.12.tar.gz 二、安装 1、操作系统环境准备 换源 sudo vim /et…...

【随手记】python语言的else语句在for、while等循环语句中的运用
在Python中,else语句可以与if语句一起使用,用于处理条件不成立时的情况。但是,else语句也可以与循环结构(如for循环、while循环)一起使用,用于处理循环正常结束时的情况,即循环没有被break语句中…...

RK3568 + YT 9215交换机芯片,MAC TO MAC 调试记录
前言 原来的方案是rk3568 gmac 直接接phy,phy 接 switch 芯片,只是把交换芯片当交换用,驱动方面基本不用开发,但是要做vlan 那么必须涉及交换芯片的开发。 选择裕太微有两个方面的原因:1.国产化替代2.可获得原厂技术支持3.目前已经完成 两个gmac 口交换芯片的配置,实现v…...
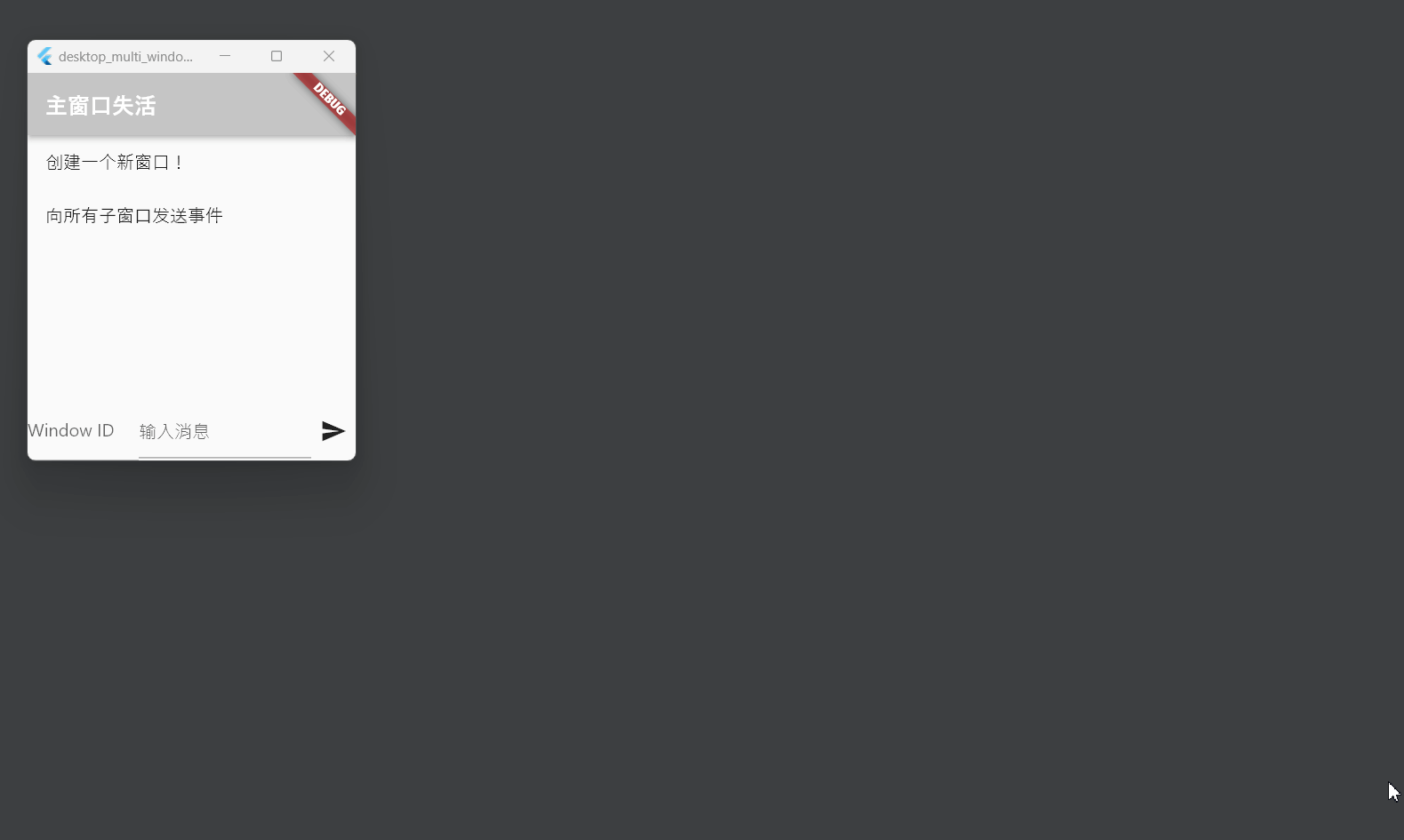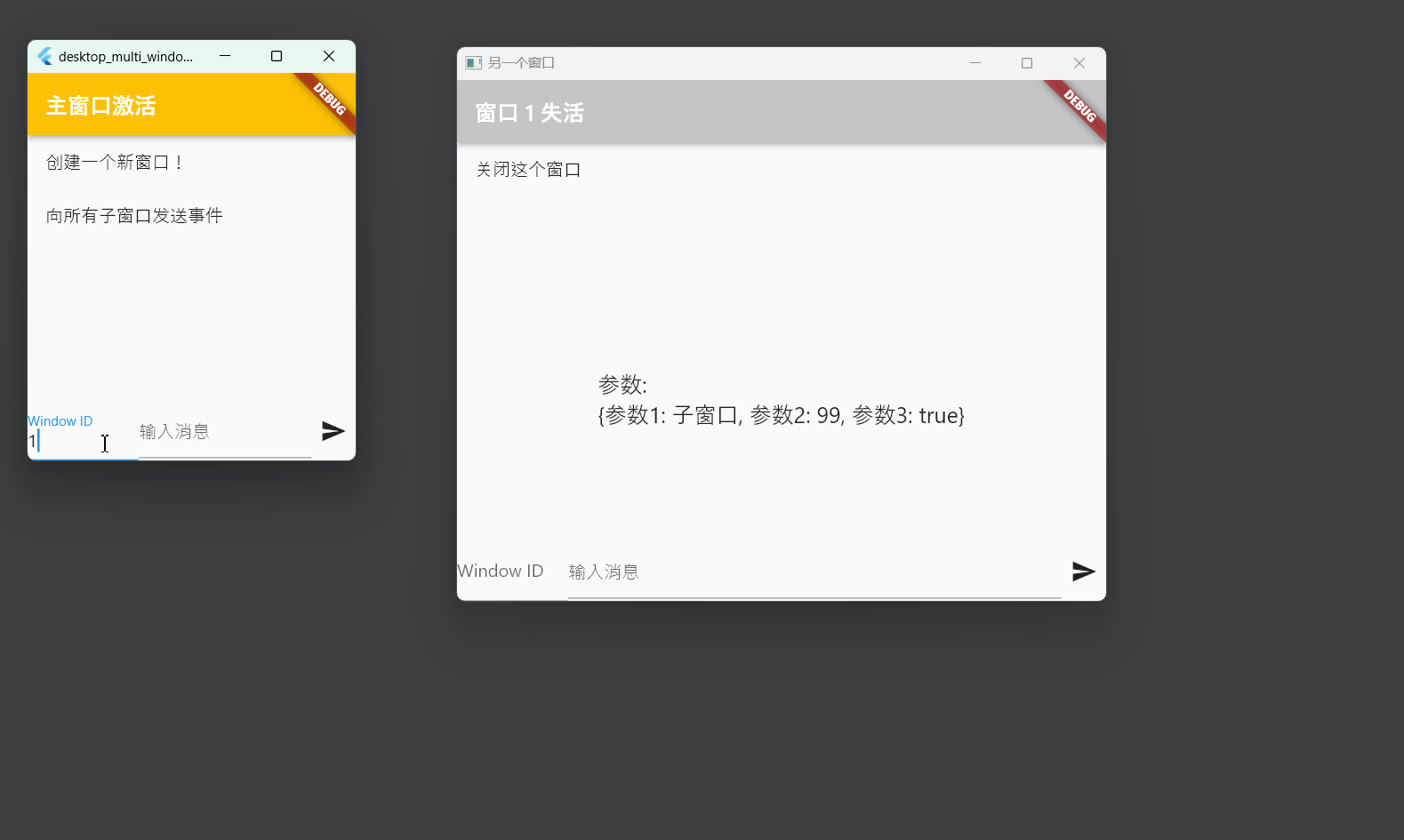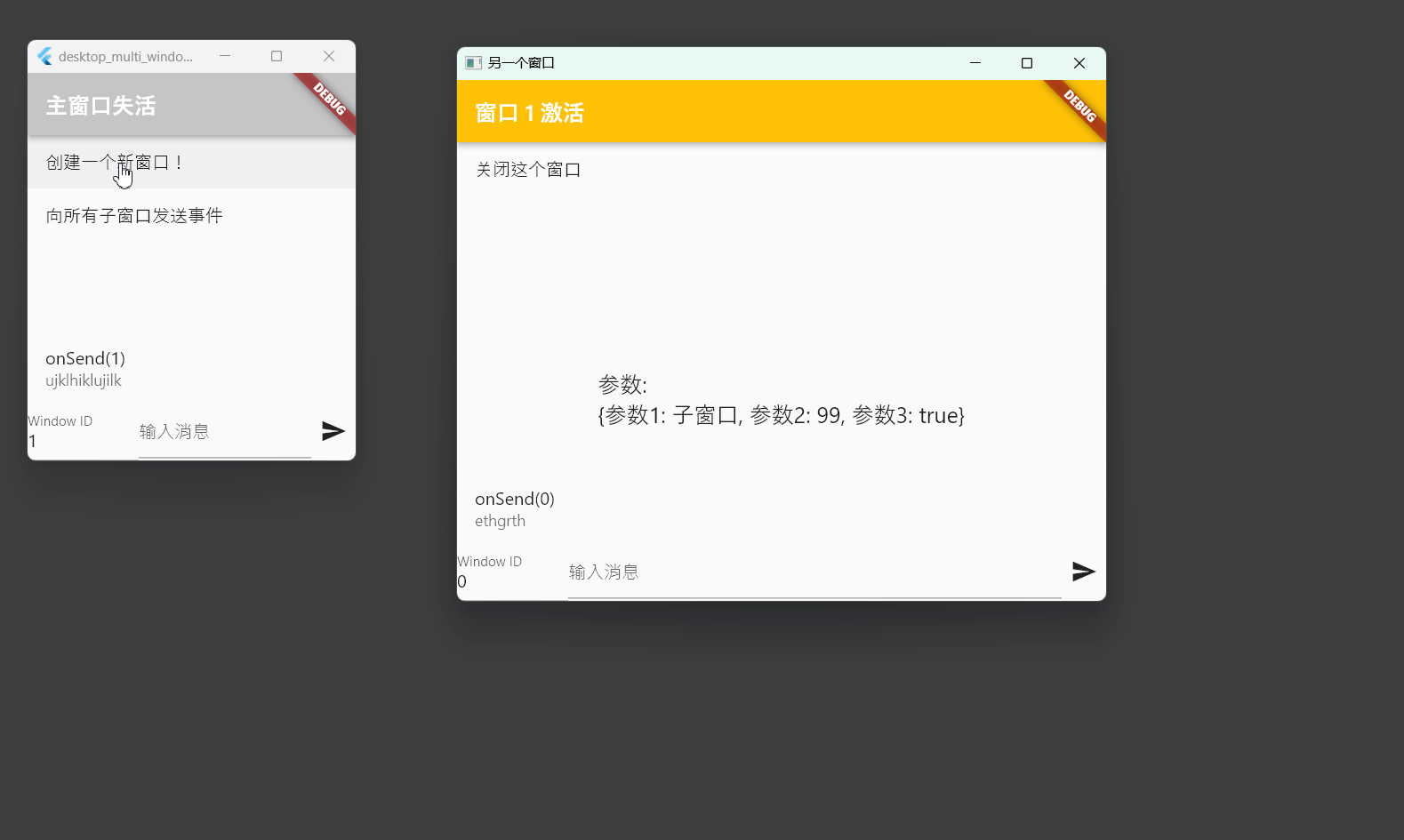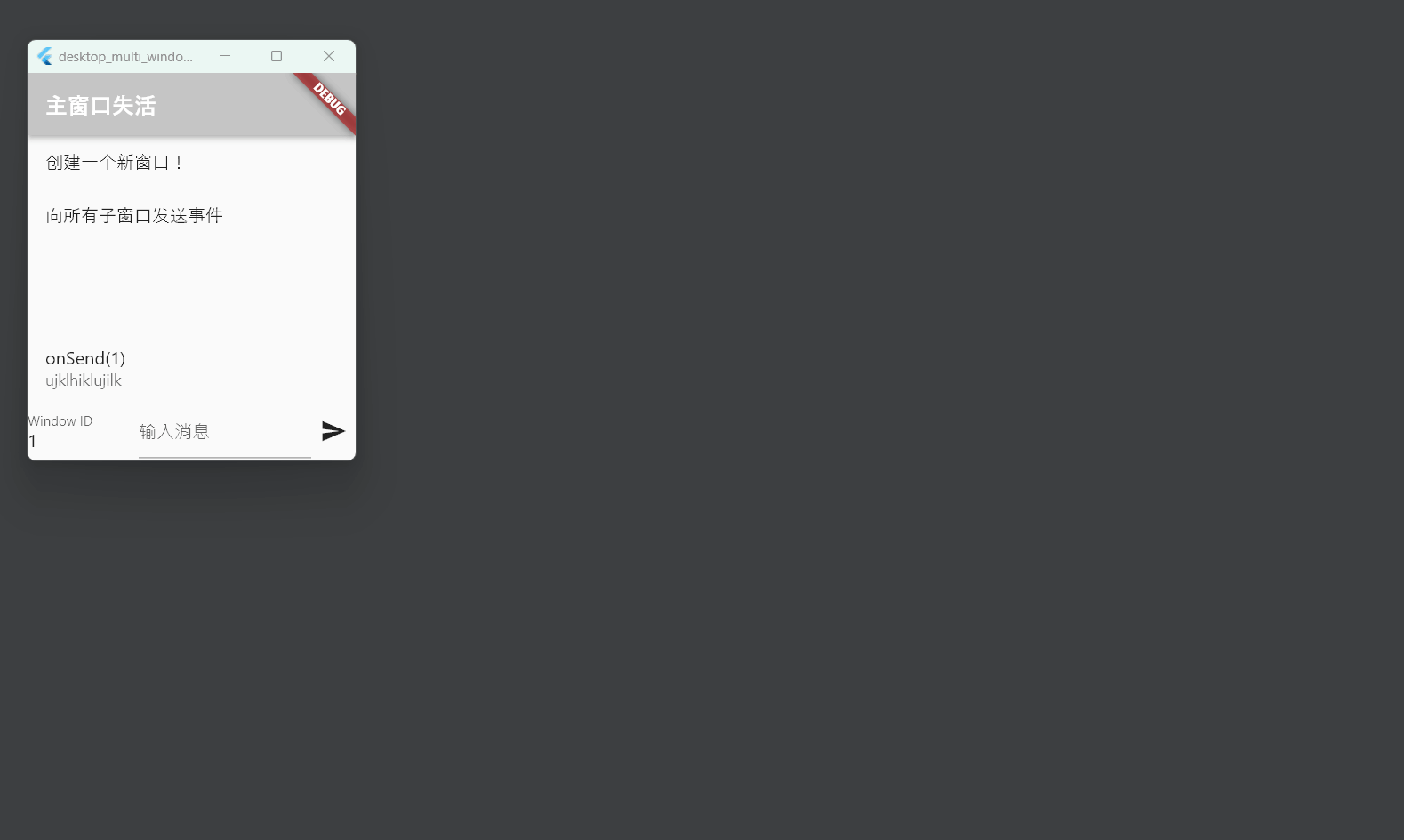
Flutter笔记:桌面端应用多窗口管理方案
Flutter笔记 桌面端应用多窗口管理方案 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/134468587 【简介…...
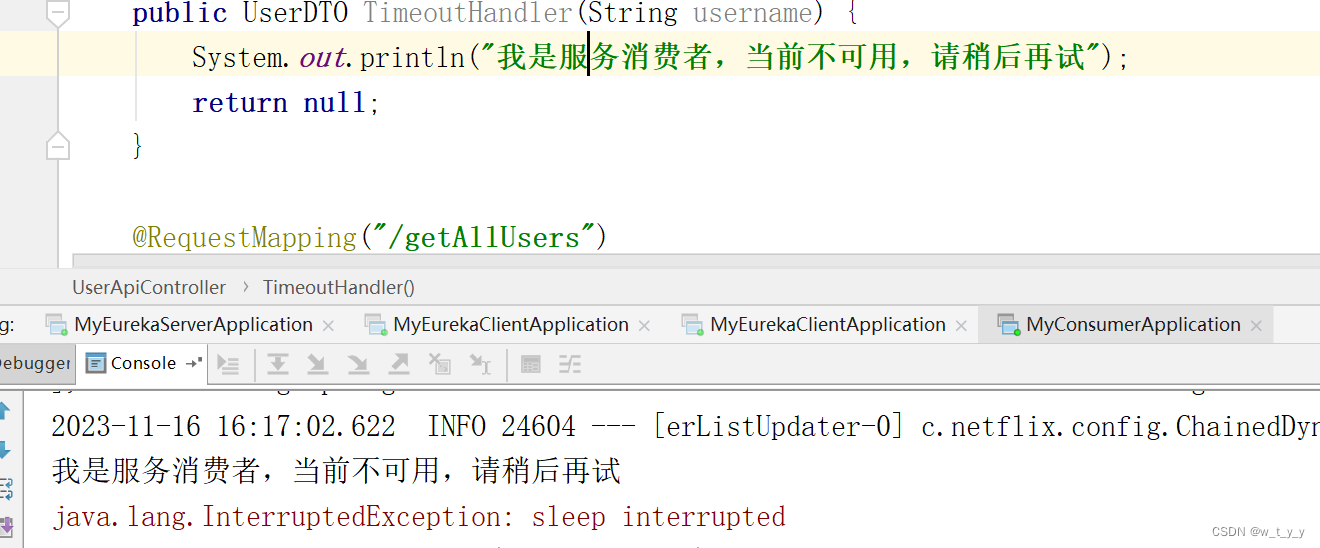
demo(三)eurekaribbonhystrix----服务降级熔断
一、介绍: 1、雪崩: 多个微服务之间调用的时候,假如微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的"扇出"。如果扇出的链路上某个微服务的调用响应的时间过长或者不可用&am…...
相机突然断电,保存的DAT视频文件如何修复
3-7 本文主要解决因相机突然断电导致拍摄的视频文件损坏的问题。 在平常使用相机拍摄视频,比如用单反相机、无人机拍摄视频的时候,如果电池突然断电,或者突然炸机了,就非常有可能会得到一个损坏的视频文件,比如会产生…...

华三交换机流行为配置避坑指南:ACL优先级与接口方向选择详解
华三交换机流策略实战:从ACL优先级到接口方向的深度避坑解析 如果你曾经在华三交换机上配置过流策略,大概率经历过这样的场景:策略明明配好了,流量却像没看见一样,该怎么走还怎么走;或者,你以为…...
)
避坑指南:uniapp中scroll-view滚动定位的那些坑(商品分类案例详解)
避坑指南:uniapp中scroll-view滚动定位的那些坑(商品分类案例详解) 最近在做一个电商类小程序,产品经理拿着某头部电商App的原型过来,指着那个经典的“左侧分类、右侧商品列表”的布局说:“咱们也要这个效果…...

C#国际化开发避坑指南:如何正确处理俄罗斯客户的小数点问题
C#国际化开发避坑指南:如何正确处理俄罗斯客户的小数点问题 最近和一位做外贸管理软件的同行聊天,他提到一个让人哭笑不得的“事故”:他们团队精心打磨了一年的软件,在国内和北美市场跑得稳稳当当,结果刚到第一个俄罗斯…...

LangChain-2-Model
可以把对模型的使用过程拆解成三块: 输入提示(Format)、调用模型(Predict)、输出解析(Parse) 1.提示模板: LangChain的模板允许动态选择输入,根据实际需求调整输入内容,适用于各种特定任务和应用。 2.语言模型: LangChain 提供通用接口调用不同类型的语…...

开学焕新,一步到位!这台「全能学霸本」,让你从宿舍赢到图书馆
回想一下当年选电脑的自己,是不是满脑子的“性能拉满,游戏全开”,非高性能游戏本不选?结果呢,明明也不怎么玩游戏,愣是每天背着不够轻便的笔记本爬四五层楼,去教室、去图书馆、去自习室。还没毕…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...