Django模型层
模型层
与数据库相关的,用于定义数据模型和数据库表结构。 在Django应用程序中,模型层是数据库和应用程序之间的接口,它负责处理所有与数据库相关的操作,例如创建、读取、更新和删除记录。Django的模型层还提供了一些高级功能
首先准备工作:切换mysql数据库
DATABASES = {'default': {# 'ENGINE': 'django.db.backends.sqlite3','ENGINE': 'django.db.backends.mysql','NAME': 'db2','USER': 'root','PASSWORD': '12345','HOST': '127.0.0.1','PORT': 3306,'CHARSET': 'utf8'}测试脚本
接下来我们可以使用测试脚本来直接运行,注意后面的Django代码必须写在测试脚本下面
把测试脚本放进一个py文件即可
import os
import sys
import django
if __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "项目名称.settings")import djangodjango.setup()django.setup()from app01 import models常用的关键字
| create | 描述 |
|---|---|
| filter | 创建数据并直接获取当前创建的数据对象 |
| first/last | 根据条件筛选数据 结果是QuerySet [数据对象1,数据对象2] |
| update | 拿queryset里面第一个元素/拿queryset里面最后一个元素 |
| delete | 删除数据(批量删除) |
| all | 查询所有数据 结果是QuerySet [数据对象1,数据对象2] |
| values | 根据指定字段获取数据 结果是QuerySet [{}},{},{},{}] |
| values_list | 根据指定字段获取数据 结果是QuerySet [(),(),(),()] |
| distinct | 去重 数据一定要一模一样才可以 如果有主键肯定不行 |
| order_by | 根据指定条件排序 默认是升序 字段前面加负号就是降序 |
| get | 根据条件筛选数据并直接获取到数据对象 一旦条件不存在会直接报错 不建议使用 |
| exclude | 取反操作 |
| reverse | 颠倒顺序(被操作的对象必须是已经排过序的才可以) |
| count | 统计结果集中数据的个数 |
| exists | 判断结果集中是否含有数据 如果有则返回True 没有则返回False |
示例
如果使用get,建议加上try
if __name__ == "__main__":os.environ.setdefault("DJANGO_SETTINGS_MODULE", "djangoProject.settings")import djangodjango.setup()from app01 import modelstry:res = models.Userinfo.objects.filter(pk=1).get()except Exception as f:print(f)value与value_list
res = models.Userinfo.objects.values('id', 'username', 'password')for i in res:print(i.get('id')) # <QuerySet [{'id': 1, 'username': 'kk', 'password': '1234'}, {'id': 2, 'username': 'cc', 'password': '232'}, {'id': 3, 'username': 'rer', 'password': '323'}]># 1 2 3 索引0为id,1为usernameprint(res) # <QuerySet [(1, 'kk', '1234'), (2, 'cc', '232'), (3, 'rer', '323')]>查看内部sql语句
只有返回的结果是queryset对时才能用query查看
res = models.Userinfo.objects.values('id', 'username', 'password')for i in res:print(i.get('id')) print(res.query)"""SELECT `app01_userinfo`.`id`, `app01_userinfo`.`username`, `app01_userinfo`.`password` FROM `app01_userinfo`"""distinct 去重
res = models.Userinfo.objects.all().values('password').distinct()print(res)
order_by 排序
res1 = models.Userinfo.objects.all().order_by('username') # <QuerySet [<Userinfo: Userinfo object (2)>, <Userinfo: Userinfo object (1)>, <Userinfo: Userinfo object (3)>]print(res1)
"""默认升序"""基于双下划线的查询
查询年龄大于xx
"""查看年龄大于或小于32的数据"""res = models.Userinfo.objects.filter(age__gt=32)\(age__lt=32)print(res)"""查看大于等于或小于等于32的数据"""res = models.Userinfo.objects.filter(age__gte=32)\(age__lte=32)print(res)"""查看18-32之间的数据,收尾都要"""res = models.Userinfo.objects.filter(age__range=[18, 32])print(res)"""查看带s字段的数据"""res = models.Userinfo.objects.filter(username__contains='s')print(res) # <QuerySet [<Userinfo: Userinfo object (2)>]>"""姓名以c开头或结尾startwith\endwith"""res = models.Userinfo.objects.filter(username__startswith='c')print(res)"""查看注册时间两个参数auto_now = false 当我们更新数据时,只要更新就会更新时间auto_add = False 当auto_add=True时,添加数据时会自动添加当前时间"""register_time = models.DateTimeField(auto_now=True, auto_now_add=True)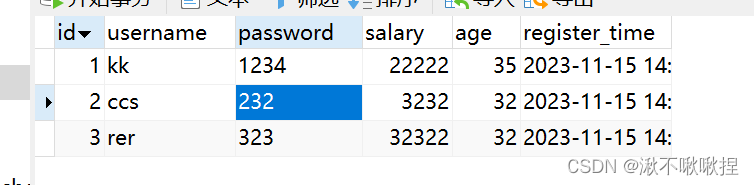
多表查询(跨表查询)
orm外键字段的创建
和mysql外键关系一样的判断规律
1.一对多 外键字段建在多的一方2.多对多 外键字段统一建在第三张关系表3.一对一 建在任何一方都可以,但是建议建在查询频率较高的表中注意:目前关系的判断可以采用表与表之间换位思考原则基础表的准备
-
创建基础表(书籍表、出版社表、作者表、作者详情)
-
确定外键关系
-
orm的创建
一对一 ORM与MySQL一致 外键字段建在查询较高的一方 一对多 ORM与MySQL一致 外键建在多的一方多对多 ORM比MySQL有更多的变化1.外键字段可以直接建在某张表中(查询频率较高的)内部会自动帮你创建第三张关系表2.自己创建第三张关系表并创建外键字段4. 针对一对多和一对一同步到表中之后自动_id的后缀,如book中的外键字段publish,会自动变成publish_id。
建表
class Book(models.Model):name = models.CharField(max_length=32) # 书名price = models.DecimalField(max_digits=8, decimal_places=2) # 价格publish_date = models.DateField(auto_now_add=True) # 出版日期maichu = models.IntegerField(2000) # 卖出数量kucun = models.IntegerField(3000) # 库存"""建立外键"""# 一对多publish = models.ForeignKey(to='Publish', on_delete=True) # publish不需要加_id,当为外键时自动会加# 多对多authors = models.ManyToManyField(to='Author')class Publish(models.Model):name = models.CharField(max_length=32) # 出版社名称addr = models.CharField(max_length=32) # 出版社def __str__(self):return self.nameclass Author(models.Model): #作者表name = models.CharField(max_length=32)age = models.IntegerField()# 一对一author_list = models.OneToOneField(to='AuthorList', on_delete=True)class AuthorList(models.Model): # 作者详情表phone = models.CharField(max_length=32)addr = models.CharField(max_length=32)注意事项
1.创建一对多关系和sql语句一样,外键建立到多的那张表上,不同的是,我们可以不讲究关联表和被关联表的建立顺序。字段类为ForeignKey在django2.x版本以上,建立一对多关系时需要指定on_delete参数为CASCADE,不加会报错,不过也不一定就是CASCADE,可能为其他实参,这里不展开。建立外键时,系统会自动加上_id后缀作为字段名。2.创建多对多关系sql中是将两张表建立好后,将外键字段创建在第三张表中,而django为我们省去了这一步骤,我们可以在多对多关系双方的一个模型表中直接建立一个虚拟外键,ManyToManyField在底层,sql依旧创建了第三张表来存储两表的多对多关系,但是在orm操作中我们就可以将模型表中的外键当做实实在在的联系,因为在查询时,我们感受不到第三张的表的存在。多对多关系的外键没有on_delete关键字参数。3.创建一对多关系一对一的字段类为OneToOneField,建议建立在查询频率高的一方。建立一对一关系时需要指定on_delete参数,否则报错。一对多的外键增删改查
增加
models.Book.objects.create(name='三味书屋', price=1500, publish_date='2022-1-1', maichu=3500, kucun=2000, publish_id=1)"""第二种方式通过对象来添加"""publish_obj = models.Publish.objects.filter(pk=1).first()models.Book.objects.create(name='三味书屋', price=1500, publish_date='2022-1-1', maichu=3500, kucun=2000,publish=publish_obj)删除
"""删除"""models.Publish.objects.filter(pk=1).delete() # 级联删除时,会删除出版社里所有的书籍,所以不建议这样删除models.Book.objects.filter(pk=1).delete() # 只删除图书即可修改
"""修改"""models.Book.objects.filter(pk=1).update(publish_id=3)"""第二种方式"""publish_obj = models.Publish.objects.filter(pk=1).first()models.Book.objects.filter(pk=1).update(publish_id=publish_obj)多对多的外键增删改查
增加(add)
book_obj = models.Book.objects.filter(pk=3).first()
print(book_obj.authors) # 打印结果为dj5.Author.None,说明已经跳转到第三张表了
book_obj.authors.add(1)使用对象添加book_obj=models.Book.objects.filter(pk=2).first()authors_obj = models.Author.objects.filter(pk=3).filter()
authors_obj1 = models.Author.objects.filter(pk=4).filter()
book_obj.authors.add(authors_obj,authors_obj1)修改(set)
修改作者
"""修改"""
book_obj.authors.set([2, 4]) # 将d为2的书籍绑定给主键为2,4的作者
"""使用对象修改"""book_obj.authors.set(authors_obj)删除(remove)
"""删除"""
book_obj.authors.remove(1,2,3) # 删除主键id为1,2,3的书籍"""使用对象删除"""
book_obj.authors.remove(authors_obj)清空(creal)
清空i书籍id为1 的所有作者
使用clear(清空)直接清理即可
book_obj.authors.clear()
直接清空所有id查询之正反向
正向:外键字段在我这边,那么我查询你就是正向
反向:外键字段不在我这边,那么我查询你就是反向
图书与出版社比较,图书为多,出版社为一,那么外键字段就在我这边,使用图书查询出版社就是正向查询
book------>外键字段再我这(正向查询)-------->publish,按(外键)字段
publish----->外键字段不在我这(反向查询)------>book,按表名小写
或加上_set
出版社查询图书,出版社为一,图书为多,那么外接字段就不在我这边,使用出版社查询图书就是反向查询
子查询例题
查询书籍主键为3的出版社
res = models.Book.objects.filter(pk=3).first()
"""1.首先筛选出id=3的书籍2.判断正反向:图书差出版社,一对多为正向3.直接打印出结果,如果需要地址则可以使用。addr"""print(res.publish)
print(res.publish.addr)
查询书籍主键为3的作者
# 查询书籍主键为3的作者
res = models.Book.objects.filter(pk=3).first()
print(res.authors.all())查询作者鲁迅的电话号码
# 3.查询作者鲁迅的电话号码
res = models.Author.objects.filter(name='鲁迅').first()
print(res.author_list.phone)查询出版社是浓浓出版社出版的书
查询出版社是东方出版社出版的书
publish_obj = models.Publish.objects.filter(name='浓浓出版社').first()
res = publish_obj.book_set
print(res.all())# <QuerySet [<Book: Book object (3)>, <Book: Book object (4)>]>查询作者是鲁迅写过的书
publish_obj = models.Author.objects.filter(name='鲁迅').first()
res = publish_obj.book_set.all()
print(res)查询手机号是110的作者姓名
查询手机号是110的作者姓名
publish_obj = models.AuthorList.objects.filter(phone=110).first()
res = publish_obj.author
print(res.name)联表查询
基于双下划线的查询
1.查询鲁迅的手机号和作者姓名
res = models.Author.objects.filter(name='鲁迅').values('author_list__phone', 'name')
print(res)2.查询书籍主键为3的出版社名称和书的名称
查询书籍主键为3的出版社名称和书的名称
res = models.Book.objects.filter(pk=3).values('publish__name', 'name')
print(res) # <QuerySet [{'publish__name': '浓浓出版社', 'name': '三味书屋'}]>3.查询书籍主键为1的作者姓名
查询书籍主键为3的作者姓名
res = models.Book.objects.filter(pk=3).values('authors__name')
print(res)查询书籍主键为3的作者手机号
查询书籍主键是3的作者的手机号
res = models.Book.objects.filter(pk=3).values('authors__author_list__phone')
print(res)聚合查询
通常聚合都是通过分组使用,只要和数据库相关的模块基本都在Django.db.models里,如果没有可能在Django.db中
在orm中,聚合函数的关键字:aggregate
from django.db.models import Avg, Sum, Max, Min, Count
res = models.Book.objects.aggregate()查询所有书籍的金额
sql语句:
select avg(price)from bookorm语句:from django.db.models import Avg, Sum, Max, Min, Count
res = models.Book.objects.aggregate(agv_price=Avg('price'), sum_price=Sum('price'))分组查询
严格模式:ONLY_FULL_GROUP_BY
set global sql_mode='ONLY_FULL_GROUP_BY'
案例:
1.统计每一本书的作者个数
# 统计每个书的作者
res = models.Book.objects.annotate(authors_num=Count('authors')).values('name', 'authors__name')
print(res)事物
事物是mysql数据库中一个重要的概念,
目的:是为了保证多sql语句执行成功,或执行失败,前后保持一致,保证数据安全
开启事物
相关文章:
Django模型层
模型层 与数据库相关的,用于定义数据模型和数据库表结构。 在Django应用程序中,模型层是数据库和应用程序之间的接口,它负责处理所有与数据库相关的操作,例如创建、读取、更新和删除记录。Django的模型层还提供了一些高级功能 首…...

计算机视觉的应用18-一键抠图人像与更换背景的项目应用,可扩展批量抠图与背景替换
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用18-一键抠图人像与更换背景的项目应用,可扩展批量抠图与背景替换。该项目能够让你轻松地处理和编辑图片。这个项目的核心功能是一键抠图和更换背景。这个项目能够自动识别图片中的主体&…...

Redis(哈希Hash和发布订阅模式)
哈希是一个字符类型字段和值的映射表。 在Redis中,哈希是一种数据结构,用于存储键值对的集合。哈希可以理解为一个键值对的集合,其中每个键都对应一个值。哈希在Redis中的作用主要有以下几点: 1. 存储对象:哈希可以用…...

php正则表达式汇总
php正则表达式有"/pattern/“、”“、”$“、”.“、”[]“、”[]“、”[a-z]“、”[A-Z]“、”[0-9]“、”\d"、“\D”、“\w”、“\W”、“\s”、“\S”、“\b”、“*”、“”、“?”、“{n}”、“{n,}”、“{n,m}”、“\bword\b”、“(pattern)”、“x|y"和…...
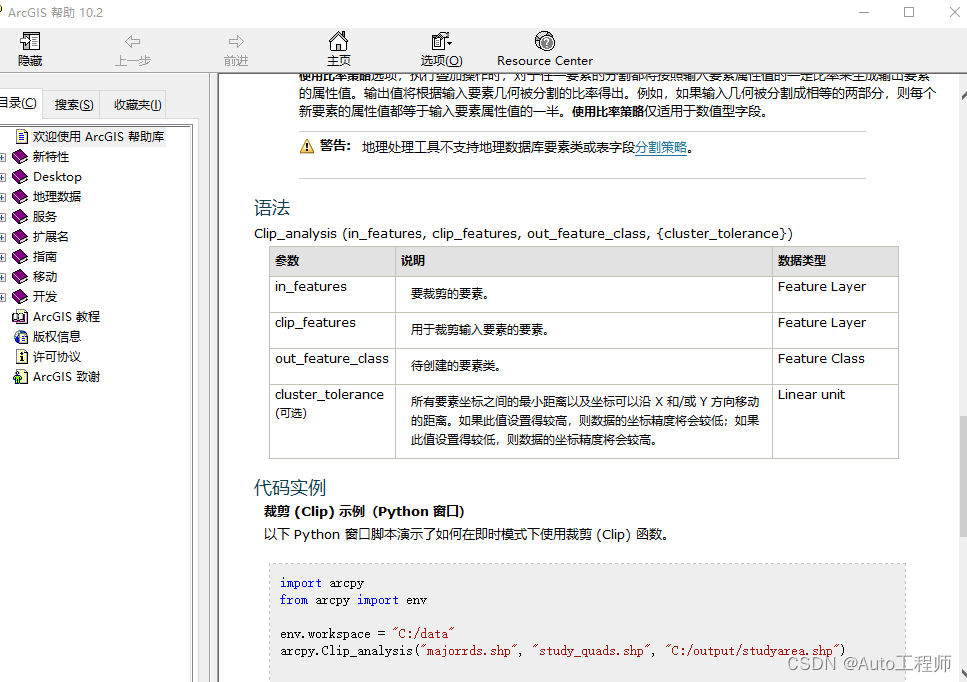
Python与ArcGIS系列(八)通过python执行地理处理工具
目录 0 简述1 脚本执行地理处理工具2 在地理处理工具间建立联系0 简述 arcgis包含数百种可以通过python脚本执行的地理处理工具,这样就通过python可以处理复杂的工作和批处理。本篇将介绍如何利用arcpy实现执行地理处理工具以及在地理处理工具间建立联系。 1 脚本执行地理处理…...
cocos----刚体
刚体(Rigidbody) 刚体(Rigidbody)是运动学(Kinematic)中的一个概念,指在运动中和受力作用后,形状和大小不变,而且内部各点的相对位置不变的物体。在 Unity3D 中ÿ…...

【SAP-HCM】--HR人员信息导入函数
人员基本信息导入函数:HR_MAINTAIN_MASTERDATA 人员其他信息类型导入函数:HR_INFOTYPE_OPERATION 不逼逼,直接上代码,这两个函数还是相对简单易懂的 *根据操作类型查找对应的T529A 操作类型对应的值IF gt_alv IS NOT INITIAL.S…...

【开源】基于JAVA的大学兼职教师管理系统
项目编号: S 004 ,文末获取源码。 \color{red}{项目编号:S004,文末获取源码。} 项目编号:S004,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、研究内容三、界面展示3.1 登录注册3.2 学生教师管…...

Pyhon函数
import time # # for i in range(1,10): # j1 # for j in range(1,i1): # print(f"{i}x{j}{i*j} " ,end) # print() #复用,代码,精简,复用度高def j99(n1,max10): for i in range(n,max):jifor j in ran…...

使用vuex完成小黑记事本案例
使用vuex完成小黑记事本案例 App.vue <template><div id"app"><TodoHeader></TodoHeader><TodoMain ></TodoMain><TodoFooter></TodoFooter></div> </template><script> import TodoMain from …...
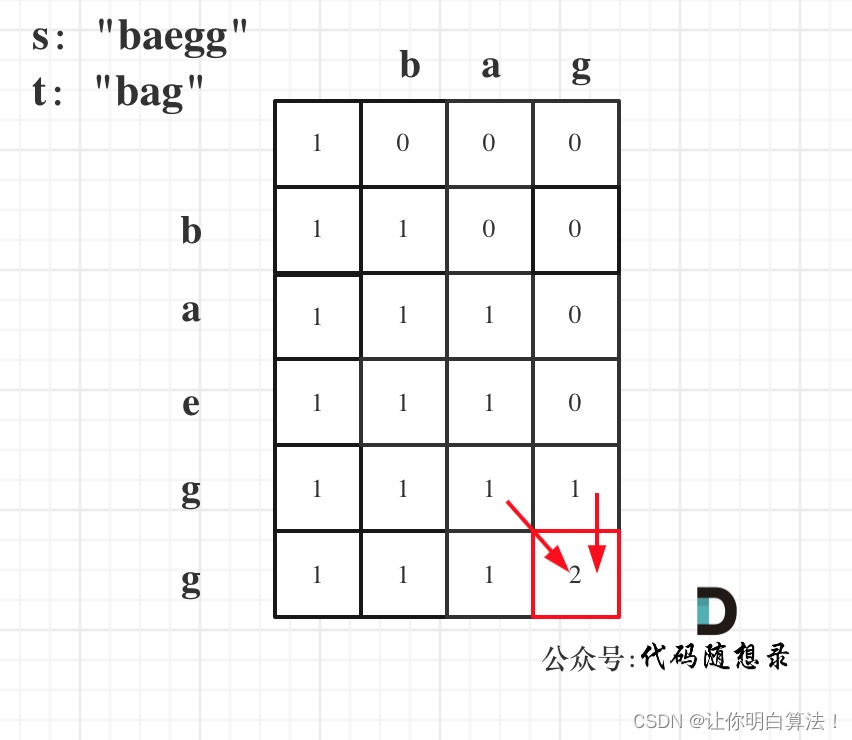
进阶理解:leetcode115.不同的子序列(细节深度)
这道题是困难题,本章是针对于动态规划解决,对于思路进行一个全面透彻的讲解,但是并不是对于基础讲解思路,而是渗透到递推式和dp填数的详解,如果有读者不清楚基本的解题思路,请看我的这篇文章算法训练营DAY5…...
数据结构-哈希表(C语言)
哈希表的概念 哈希表就是: “将记录的存储位置与它的关键字之间建立一个对应关系,使每个关键字和一个唯一的存储位置对 应。” 哈希表又称:“散列法”、“杂凑法”、“关键字:地址法”。 哈希表思想 基本思想是在关键字和存…...
HCIA-综合实验(三)
综合实验(三) 1 实验拓扑2 IP 规划3 实验需求一、福州思博网络规划如下:二、上海思博网络规划如下:三、福州思博与上海思博网络互联四、网络优化 4 配置思路4.1 福州思博配置在 SW1、SW2、SW3 上配置交换网络SW1、SW2、SW3 运行 S…...

Java程序员的成长路径
熟悉JAVA语言基础语法。 学习JAVA基础知识,推荐阅读书单中的经典书籍。 理解并掌握面向对象的特性,比如继承,多态,覆盖,重载等含义,并正确运用。 熟悉SDK中常见类和API的使用,比如࿱…...

几种常用的排序
int[] arr new int[]{1, 2,8, 7, 5};这是提前准备好的数组 冒泡排序 public static void bubbleSort(int[] arr) {int len arr.length;for (int i 0; i < len - 1; i) {for (int j 0; j < len - i - 1; j) {if (arr[j] > arr[j1]) {int temp arr[j];arr[j] ar…...

性能测试【第三篇】Jmeter的使用
线程数:10 ,设置10个并发 Ramp-Up时间(秒):所有线程在多少时间内启动,如果设置5,那么每秒启动2个线程 循环次数:请求的重复次数,如果勾选"永远"将一直发送请求 持续时间时间:设置场景运行的时间 启动延迟:设置场景延迟启动时间 响应断言 响应断言模式匹配规则 包括…...

业务:业务系统检查项参考
名录明细云平台摸底1.原有云平台体系:VMware、openstack、ovirt、k8s、docker、混合云系列及版本 2.原有云平台规模,物理机数量、虚拟机数量、迁移业务系统所占配额 3.待补充系统摸底 (适用于物理主机)每一台虚拟机或物理机: 1.系统全局参数…...
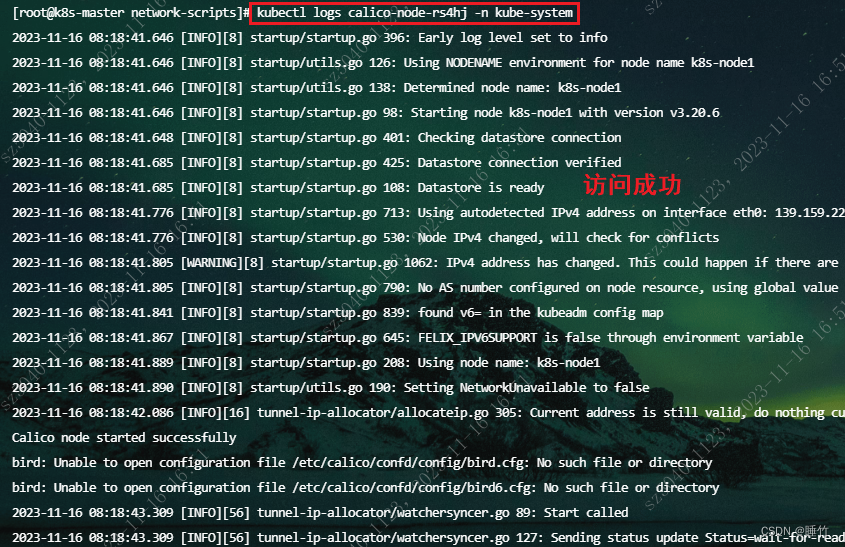
解决公网下,k8s calico master节点无法访问node节点创建的pod
目的:解决pod部署成功后,只能在node节点访问,而master节点无法访问 原因:集群搭建时,没有配置公网进行kubectl操作,从而导致系统默认node节点,使用内网IP加入k8s集群!如下ÿ…...

六边形架构
Alistair Cockburn是于1953年出生在美国的一位软件开发方法学家。他毕业于康奈尔大学计算机科学专业,并获得了博士学位。 Cockburn在敏捷软件开发领域做出了许多重要的贡献,他被广泛认可为敏捷方法学的奠基人之一。他提出了许多关于敏捷开发的原则和实践…...

基于单片机的智能家居安保系统(论文+源码)
1.系统设计 本次基于单片机的智能家居安保系统设计,在功能上如下: 1)以51单片机为系统控制核心; 2)温度传感器、人体红外静释电、烟雾传感器来实现检测目的; 3)以GSM模块辅以按键来实现远/近程…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

BLEU评分:机器翻译质量评估的黄金标准
BLEU评分:机器翻译质量评估的黄金标准 1. 引言 在自然语言处理(NLP)领域,衡量一个机器翻译模型的性能至关重要。BLEU (Bilingual Evaluation Understudy) 作为一种自动化评估指标,自2002年由IBM的Kishore Papineni等人提出以来,…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...