TensorRT基础知识及应用【学习笔记(十)】
这篇博客为修改过后的转载,因为没有转载链接,所以选了原创
文章目录
- 一、准备知识
- 1.1 环境配置
- A. CUDA Driver
- B. CUDA
- C. cuDNN
- D. TensorRT
- 1.2 编程模型
- 二、构建阶段
- 2.1 创建网络定义
- 2.2 配置参数
- 2.3 生成Engine
- 2.4 保存为模型文件
- 2.5 释放资源
- 三、运行时阶段
- 3.1 反序列化并创建Engine
- 3.2 创建一个`ExecutionContext`
- 3.3 为推理填充输入
- 3.4 调用enqueueV2来执行推理
- 3.5 释放资源
- 四、编译和运行
一、准备知识
NVIDIA® TensorRT™是一个用于高性能深度学习的推理框架。它可以与TensorFlow、PyTorch和MXNet等训练框架相辅相成地工作。
1.1 环境配置
A. CUDA Driver
-
使用CUDA前,要求GPU驱动与
cuda的版本要匹配,匹配关系如下:参考:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions
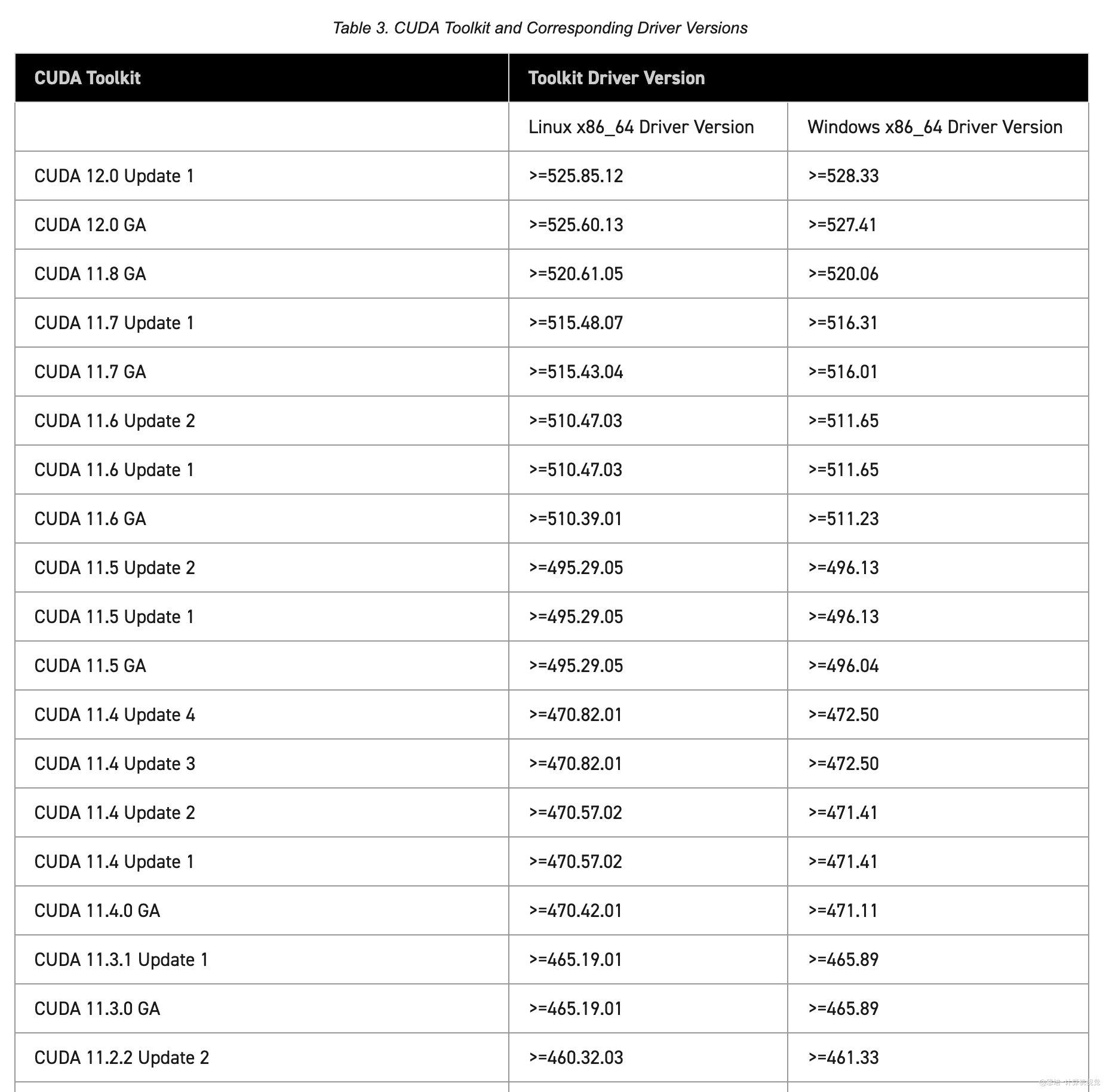
- 检查机器建议的驱动
有recommended这一行中的是系统推荐安装的nvidia-driver-525驱动版本
$ ubuntu-drivers devices// 比如我的机器输出如下(base) enpei@enpei-ubutnu-desktop:~$ ubuntu-drivers devices
== /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 ==
modalias : pci:v000010DEd00001C03sv000010DEsd000011D7bc03sc00i00
vendor : NVIDIA Corporation
model : GP106 [GeForce GTX 1060 6GB]
driver : nvidia-driver-525 - distro non-free recommended
driver : nvidia-driver-510 - distro non-free
driver : nvidia-driver-390 - distro non-free
driver : nvidia-driver-520 - third-party non-free
driver : nvidia-driver-515-server - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-418-server - distro non-free
driver : nvidia-driver-470-server - distro non-free
driver : nvidia-driver-525-server - distro non-free
driver : nvidia-driver-515 - distro non-free
driver : nvidia-driver-450-server - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
上面信息提示了,当前我使用的GPU是[GeForce GTX 1060 6GB],他推荐的(recommended)驱动是nvidia-driver-525。
-
安装指定版本
$ sudo apt install nvidia-driver-525 -
重启
$ sudo reboot -
检查安装
$ nvidia-smi(base) enpei@enpei-ubutnu-desktop:~$ nvidia-smi Mon Feb 2 12:23:45 2023 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 525.78.01 Driver Version: 525.78.01 CUDA Version: 12.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA GeForce ... Off | 00000000:01:00.0 On | N/A | | 40% 29C P8 9W / 120W | 239MiB / 6144MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 1079 G /usr/lib/xorg/Xorg 102MiB | | 0 N/A N/A 1387 G /usr/bin/gnome-shell 133MiB | +-----------------------------------------------------------------------------+可以看到当前安装的驱动版本是
525.78.01,需要注意CUDA Version: 12.0指当前驱动支持的最高版本。
B. CUDA
-
选择对应版本:https://developer.nvidia.com/cuda-toolkit-archive

-
根据提示安装,如我选择的11.8 版本的:https://developer.nvidia.com/cuda-11-8-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=20.04&target_type=deb_local

wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600 wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-ubuntu2004-11-8-local_11.8.0-520.61.05-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu2004-11-8-local_11.8.0-520.61.05-1_amd64.deb sudo cp /var/cuda-repo-ubuntu2004-11-8-local/cuda-*-keyring.gpg /usr/share/keyrings/ sudo apt-get update sudo apt-get -y install cuda -
安装
nvccsudo apt install nvidia-cuda-toolkit -
重启
C. cuDNN
-
下载安装包:访问:https://developer.nvidia.com/zh-cn/cudnn,选择对应的版本,下载对应的安装包(建议使用Debian包安装)
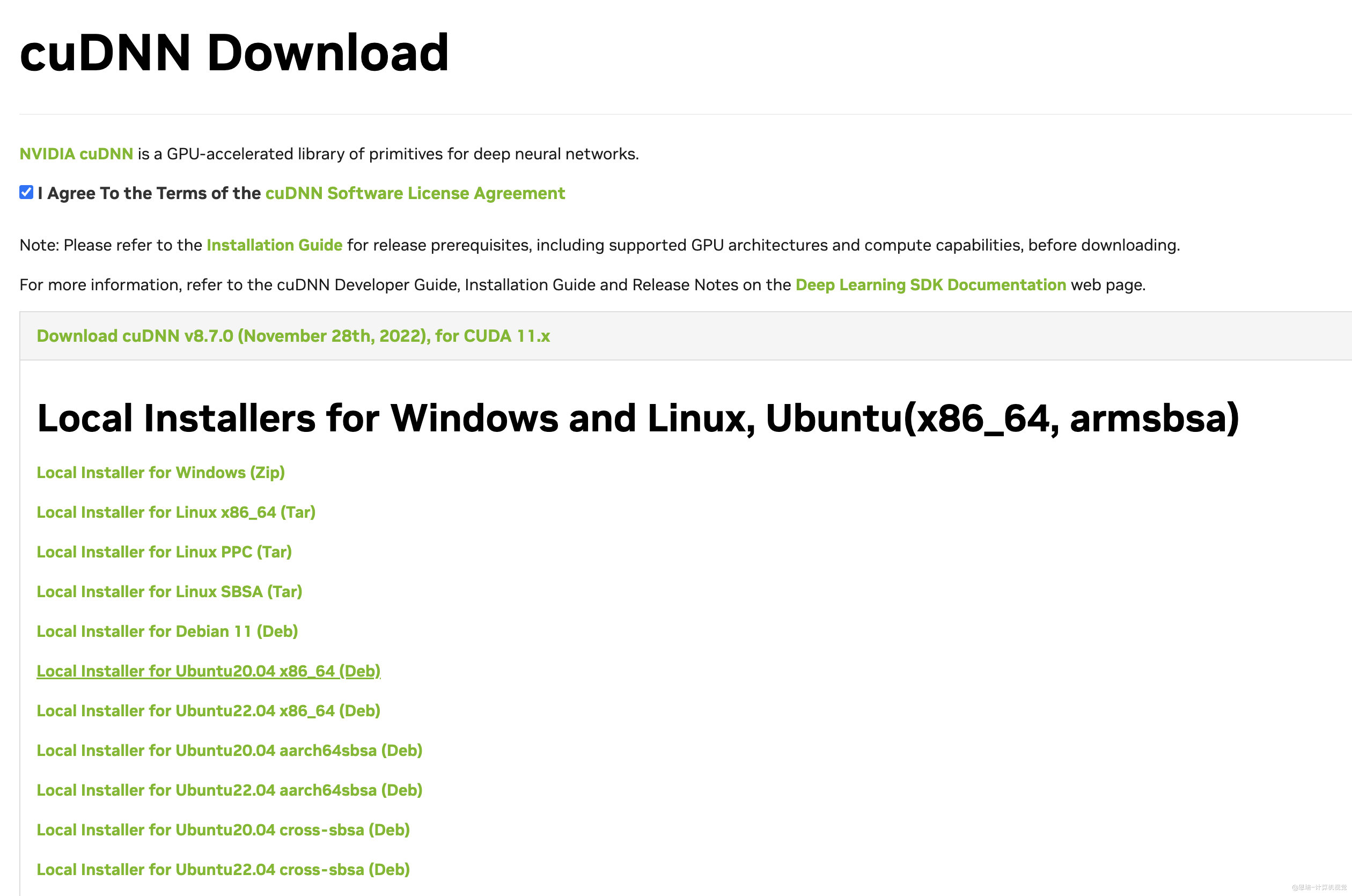
比如我下载的是:Local Installer for Ubuntu20.04 x86_64 (Deb),下载后的文件名为
cudnn-local-repo-ubuntu2004-8.7.0.84_1.0-1_amd64.deb。 -
安装:
参考链接:https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
# 注意,运行下面的命令前,将下面的 X.Y和v8.x.x.x 替换成自己具体的CUDA 和 cuDNN版本,如我的CUDA 版本是11.8,cuDNN 版本是 8.7.0.84sudo dpkg -i cudnn-local-repo-${OS}-8.x.x.x_1.0-1_amd64.deb # 我的:sudo dpkg -i cudnn-local-repo-ubuntu2004-8.7.0.84_1.0-1_amd64.debsudo cp /var/cudnn-local-repo-*/cudnn-local-*-keyring.gpg /usr/share/keyrings/ sudo apt-get updatesudo apt-get install libcudnn8=8.x.x.x-1+cudaX.Y # 我的:sudo apt-get install libcudnn8=8.7.0.84-1+cuda11.8sudo apt-get install libcudnn8-dev=8.x.x.x-1+cudaX.Y # 我的:sudo apt-get install libcudnn8-dev=8.7.0.84-1+cuda11.8sudo apt-get install libcudnn8-samples=8.x.x.x-1+cudaX.Y # 我的:sudo apt-get install libcudnn8-samples=8.7.0.84-1+cuda11.8 -
验证
# 复制文件 cp -r /usr/src/cudnn_samples_v8/ $HOME cd $HOME/cudnn_samples_v8/mnistCUDNN make clean && make ./mnistCUDNN可能报错:test.c:1:10: fatal error: FreeImage.h: No such file or directory
解决办法:sudo apt-get install libfreeimage3 libfreeimage-dev
D. TensorRT
TensorRT是什么:
- TensorRT是NVIDIA推出的深度学习推理SDK,能够在NVIDIA GPU上实现低延迟、⾼吞吐量的部署。
- TensorRT包含⽤于训练好的模型的优化器,以及⽤于执⾏推理的runtime。
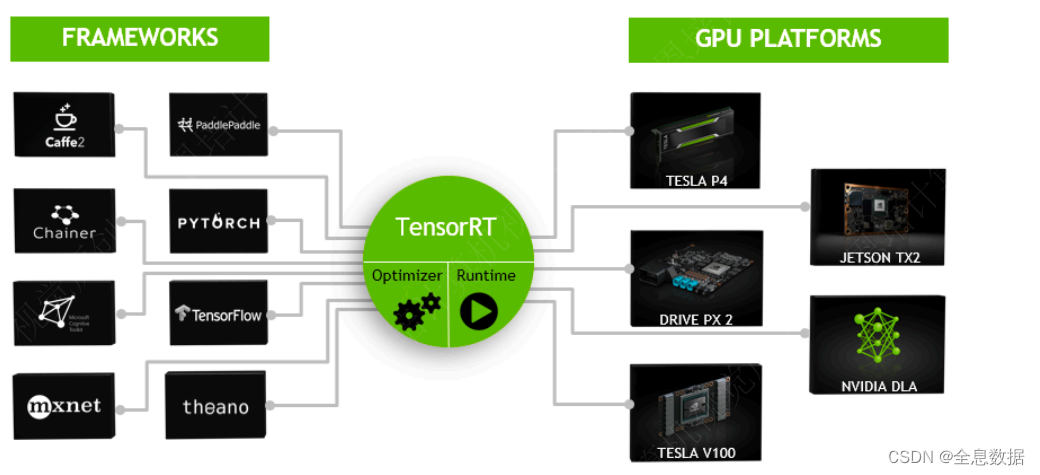
TensorRT优化策略:
- 消除不使⽤输出的层;
- 卷积、偏置和ReLU运算的融合;
- 具有⾜够相似的参数和相同的源张量的操作的集合(例如,GoogleNet v5的inception模块中的1x1卷积);
- 通过将层输出定向到正确的最终⽬的地来合并连接层;
- 如果有必要,构造器还会修改权重的精度。当⽣成8位整数精度的⽹络时,它使⽤⼀个称为校准的过程来确定中间激活的动态范围,从⽽确定量化所需的适当⽐例因⼦;
- 此外,构建阶段还在虚拟数据上运⾏层,以从其内核⽬录中选择最快的,
并在适当的地⽅执⾏权重预格式化和内存优化。
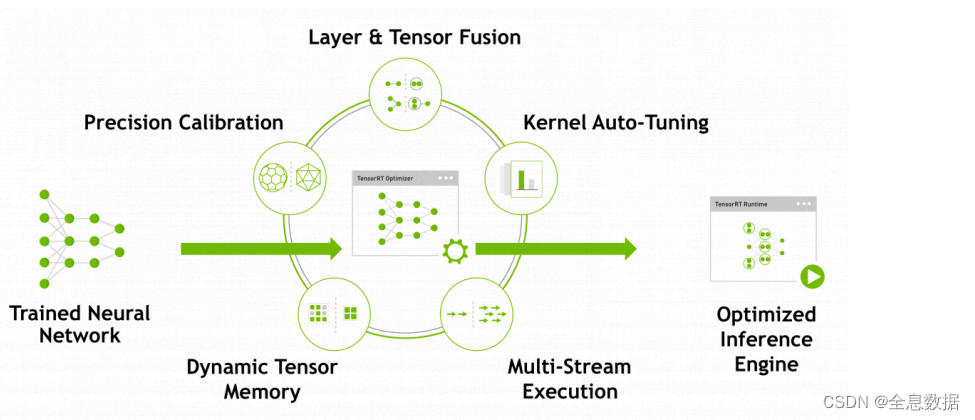
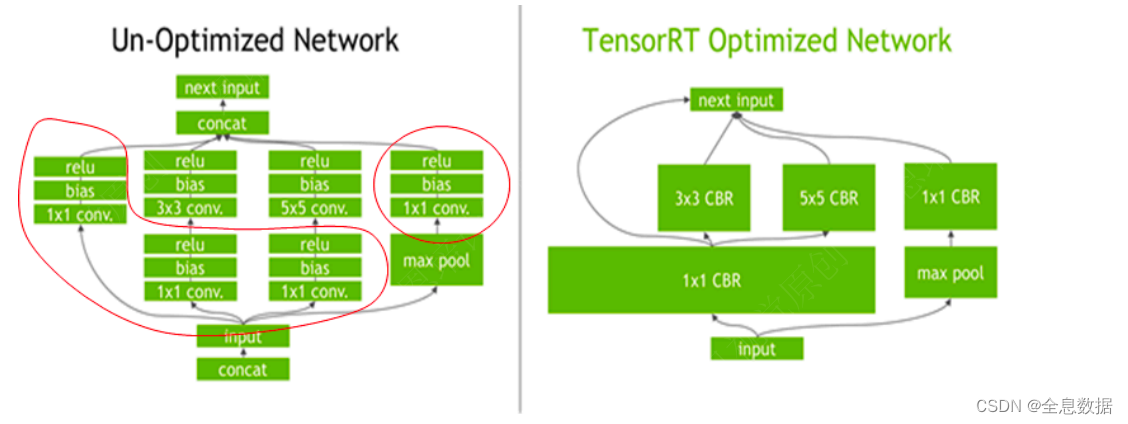
TensorRT优化策略:
- TensorRT需要在⽬标GPU设备上实际运⾏来选择最优算法和配置(根据硬件、软件环境版本等)
- 所以TensorRT⽣成的模型迁移到别的设备或其他版本的TensorRT下不⼀定能运⾏。
如何使⽤TensorRT?
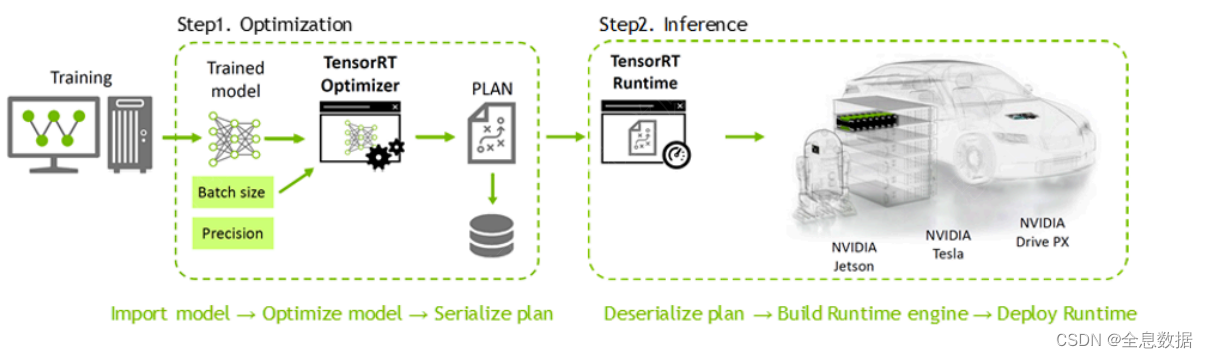
模型转换:
插件Plugin
-
访问:https://developer.nvidia.com/nvidia-tensorrt-8x-download 下载对应版本的TensorRT

比如我选择的是 8.5.3版本,下载完文件名为:
nv-tensorrt-local-repo-ubuntu2004-8.5.3-cuda-11.8_1.0-1_amd64.deb -
安装:
参考地址:https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html#installing-debian
# 替换成自己的OS 和 版本信息 os="ubuntuxx04" tag="8.x.x-cuda-x.x" sudo dpkg -i nv-tensorrt-local-repo-${os}-${tag}_1.0-1_amd64.deb # 我的:sudo dpkg -i nv-tensorrt-local-repo-ubuntu2004-8.5.3-cuda-11.8_1.0-1_amd64.deb sudo cp /var/nv-tensorrt-local-repo-${os}-${tag}/*-keyring.gpg /usr/share/keyrings/ # 我的:sudo cp /var/nv-tensorrt-local-repo-ubuntu2004-8.5.3-cuda-11.8/*-keyring.gpg /usr/share/keyrings/sudo apt-get update sudo apt-get install tensorrt -
验证:
dpkg -l | grep TensorRT# 输出 ii libnvinfer-bin 8.5.3-1+cuda11.8 amd64 TensorRT binaries ii libnvinfer-dev 8.5.3-1+cuda11.8 amd64 TensorRT development libraries and headers ii libnvinfer-plugin-dev 8.5.3-1+cuda11.8 amd64 TensorRT plugin libraries ii libnvinfer-plugin8 8.5.3-1+cuda11.8 amd64 TensorRT plugin libraries ii libnvinfer-samples 8.5.3-1+cuda11.8 all TensorRT samples ii libnvinfer8 8.5.3-1+cuda11.8 amd64 TensorRT runtime libraries ii libnvonnxparsers-dev 8.5.3-1+cuda11.8 amd64 TensorRT ONNX libraries ii libnvonnxparsers8 8.5.3-1+cuda11.8 amd64 TensorRT ONNX libraries ii libnvparsers-dev 8.5.3-1+cuda11.8 amd64 TensorRT parsers libraries ii libnvparsers8 8.5.3-1+cuda11.8 amd64 TensorRT parsers libraries ii tensorrt 8.5.3.1-1+cuda11.8 amd64 Meta package for TensorRT如果遇到
unmet dependencies的问题, 一般是cuda cudnn没有安装好。TensorRT的INCLUDE路径是/usr/include/x86_64-linux-gnu/,LIB路径是/usr/lib/x86_64-linux-gnu/,Sample code在/usr/src/tensorrt/samples,trtexec在/usr/src/tensorrt/bin下。
1.2 编程模型
TensorRT分两个阶段运行
- 构建(
Build)阶段:你向TensorRT提供一个模型定义,TensorRT为目标GPU优化这个模型。这个过程可以离线运行。 - 运行时(
Runtime)阶段:你使用优化后的模型来运行推理。
构建阶段后,我们可以将优化后的模型保存为模型文件,模型文件可以用于后续加载,以省略模型构建和优化的过程。
二、构建阶段
样例代码:
6.trt_basic/src/build.cpp
构建阶段的最高级别接口是 Builder。Builder负责优化一个模型,并产生Engine。通过如下接口创建一个Builder 。
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);
要生成一个可以进行推理的Engine,一般需要以下三个步骤:
- 创建一个网络定义
- 填写
Builder构建配置参数,告诉构建器应该如何优化模型 - 调用
Builder生成Engine
2.1 创建网络定义
NetworkDefinition接口被用来定义模型。如下所示:
// bit shift,移位:y左移N位,相当于 y * 2^N
// kEXPLICIT_BATCH(显性Batch)为0,1U << 0 = 1
// static_cast:强制类型转换
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
接口createNetworkV2接受配置参数,参数用按位标记的方式传入。比如上面激活explicitBatch,是通过1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH); 将explicitBatch对应的配置位设置为1实现的。在新版本中,请使用createNetworkV2而非其他任何创建NetworkDefinition 的接口。
将模型转移到TensorRT的最常见的方式是以ONNX格式从框架中导出(将在后续课程进行介绍),并使用TensorRT的ONNX解析器来填充网络定义。同时,也可以使用TensorRT的Layer和Tensor等接口一步一步地进行定义。通过接口来定义网络的代码示例如下:
- 添加输入层
nvinfer1::ITensor* input = network->addInput("data", nvinfer1::DataType::kFLOAT, nvinfer1::Dims4{1, input_size, 1, 1});
- 添加全连接层
nvinfer1::IFullyConnectedLayer* fc1 = network->addFullyConnected(*input, output_size, fc1w, fc1b);
- 添加激活层
nvinfer1::IActivationLayer* relu1 = network->addActivation(*fc1->getOutput(0), nvinfer1::ActivationType::kRELU);
通过调用network的方法,我们可以构建网络的定义。
无论你选择哪种方式,你还必须定义哪些张量是网络的输入和输出。没有被标记为输出的张量被认为是瞬时值,可以被构建者优化掉。输入和输出张量必须被命名,以便在运行时,TensorRT知道如何将输入和输出缓冲区绑定到模型上。示例代码如下:
// 设置输出名字
relu1->getOutput(0)->setName("output");
// 标记输出
network->markOutput(*relu1->getOutput(0));
TensorRT的网络定义不会复制参数数组(如卷积的权重)。因此,在构建阶段完成之前,你不能释放这些数组的内存。
2.2 配置参数
下面我们来添加相关Builder 的配置。createBuilderConfig接口被用来指定TensorRT应该如何优化模型。如下:
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
在可用的配置选项中,你可以控制TensorRT降低计算精度的能力,控制内存和运行时执行速度之间的权衡,并限制CUDA®内核的选择。由于构建器的运行可能需要几分钟或更长时间,你也可以控制构建器如何搜索内核,以及缓存搜索结果以用于后续运行。在我们的示例代码中,我们仅配置workspace(workspace 就是 tensorrt 里面算子可用的内存空间 )大小和运行时batch size ,如下:
// 配置运行时batch size参数
builder->setMaxBatchSize(1);
// 配置运行时workspace大小
std::cout << "Workspace Size = " << (1 << 28) / 1024.0f / 1024.0f << "MB" << std::endl; // 256Mib
config->setMaxWorkspaceSize(1 << 28);
2.3 生成Engine
在你有了网络定义和Builder配置后,你可以调用Builder来创建Engine。Builder以一种称为plan的序列化形式创建Engine,它可以立即反序列化,也可以保存到磁盘上供以后使用。需要注意的是,由TensorRT创建的Engine是特定于创建它们的TensorRT版本和创建它们的GPU的,当迁移到别的GPU和TensorRT版本时,不能保证模型能够被正确执行。生成Engine的示例代码如下:
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
2.4 保存为模型文件
当有了engine后我们可以将其保存为文件,以供后续使用。代码如下:
// 序列化
nvinfer1::IHostMemory* engine_data = engine->serialize();
// 保存至文件
std::ofstream engine_file("mlp.engine", std::ios::binary);
engine_file.write((char*)engine_data->data(), engine_data->size());
2.5 释放资源
// 理论上,前面申请的资源都应该在这里释放,但是这里只是为了演示,所以只释放了部分资源
file.close(); // 关闭文件
delete serialized_engine; // 释放序列化的engine
delete engine; // 释放engine
delete config; // 释放config
delete network; // 释放network
delete builder; // 释放builder
三、运行时阶段
样例代码:
6.trt_basic/src/runtime.cu
TensorRT运行时的最高层级接口是Runtime 如下:
nvinfer1::IRuntime *runtime = nvinfer1::createInferRuntime(looger);
当使用Runtime时,你通常会执行以下步骤:
- 反序列化一个计划以创建一个
Engine。 - 从引擎中创建一个
ExecutionContext。
然后,重复进行:
- 为Inference填充输入缓冲区。
- 在
ExecutionContext调用enqueueV2()来运行Inference
3.1 反序列化并创建Engine
通过读取模型文件并反序列化,我们可以利用runtime生成Engine。如下:
nvinfer1::ICudaEngine *engine = runtime->deserializeCudaEngine(engine_data.data(), engine_data.size(), nullptr);
Engine接口代表一个优化的模型。你可以查询Engine关于网络的输入和输出张量的信息,如:预期尺寸、数据类型、数据格式等。
3.2 创建一个ExecutionContext
有了Engine后我们需要创建ExecutionContext 以用于后面的推理执行。
nvinfer1::IExecutionContext *context = engine->createExecutionContext();
从Engine创建的ExecutionContext接口是调用推理的主要接口。ExecutionContext包含与特定调用相关的所有状态,因此你可以有多个与单个引擎相关的上下文,且并行运行它们,在这里我们暂不展开了解,仅做介绍。
3.3 为推理填充输入
我们首先创建CUDA Stream用于推理的执行。
stream 可以理解为一个任务队列,调用以 async 结尾的 api 时,是把任务加到队列,但执行是异步的,当有多个任务且互相没有依赖时可以创建多个 stream 分别用于不同的任务,任务直接的执行可以被 cuda driver 调度,这样某个任务做 memcpy时 另外一个任务可以执行计算任务,这样可以提高 gpu利用率。
cudaStream_t stream = nullptr;
// 创建CUDA Stream用于context推理
cudaStreamCreate(&stream);
然后我们同时在CPU和GPU上分配输入输出内存,并将输入数据从CPU拷贝到GPU上。
// 输入数据
float* h_in_data = new float[3]{1.4, 3.2, 1.1};
int in_data_size = sizeof(float) * 3;
float* d_in_data = nullptr;
// 输出数据
float* h_out_data = new float[2]{0.0, 0.0};
int out_data_size = sizeof(float) * 2;
float* d_out_data = nullptr;
// 申请GPU上的内存
cudaMalloc(&d_in_data, in_data_size);
cudaMalloc(&d_out_data, out_data_size);
// 拷贝数据
cudaMemcpyAsync(d_in_data, h_in_data, in_data_size, cudaMemcpyHostToDevice, stream);
// enqueueV2中是把输入输出的内存地址放到bindings这个数组中,需要写代码时确定这些输入输出的顺序(这样容易出错,而且不好定位bug,所以新的接口取消了这样的方式,不过目前很多官方 sample 也在用v2)
float* bindings[] = {d_in_data, d_out_data};
3.4 调用enqueueV2来执行推理
将数据从CPU中拷贝到GPU上后,便可以调用enqueueV2 进行推理。代码如下:
// 执行推理
bool success = context->enqueueV2((void**)bindings, stream, nullptr);
// 把数据从GPU拷贝回host
cudaMemcpyAsync(h_out_data, d_out_data, out_data_size, cudaMemcpyDeviceToHost, stream);
// stream同步,等待stream中的操作完成
cudaStreamSynchronize(stream);
// 输出
std::cout << "输出信息: " << host_output_data[0] << " " << host_output_data[1] << std::endl;
3.5 释放资源
cudaStreamDestroy(stream);
cudaFree(device_input_data_address);
cudaFree(device_output_data_address);
delete[] host_input_data;
delete[] host_output_data;delete context;
delete engine;
delete runtime;
四、编译和运行
样例代码:
6.trt_basic/CMakeLists.txt
利用我们前面cmake课程介绍的添加自定义模块的方法,创建cmake/FindTensorRT.cmake文件,我们运行下面的命令以编译示例代码:
cmake -S . -B build
cmake --build build
然后执行下面命令,build将生成mlp.engine,而runtime将读取mlp.engine并执行:
./build/build
./build/runtime
最后将看到输出结果:
输出信息: 0.970688 0.999697
相关文章:
TensorRT基础知识及应用【学习笔记(十)】
这篇博客为修改过后的转载,因为没有转载链接,所以选了原创 文章目录 一、准备知识1.1 环境配置A. CUDA DriverB. CUDAC. cuDNND. TensorRT 1.2 编程模型 二、构建阶段2.1 创建网络定义2.2 配置参数2.3 生成Engine2.4 保存为模型文件2.5 释放资源 三、运…...
[内存泄漏][PyTorch](create_graph=True)
PyTorch保存计算图导致内存泄漏 1. 内存泄漏定义2. 问题发现背景3. pytorch中关于这个问题的讨论 1. 内存泄漏定义 内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致…...

【Git学习二】时光回溯:git reset和git checkout命令详解
😁 作者简介:一名大四的学生,致力学习前端开发技术 ⭐️个人主页:夜宵饽饽的主页 ❔ 系列专栏:Git等软件工具技术的使用 👐学习格言:成功不是终点,失败也并非末日,最重要…...

多维时序 | MATLAB实现PSO-GRU-Attention粒子群优化门控循环单元融合注意力机制的多变量时间序列预测
多维时序 | MATLAB实现PSO-GRU-Attention粒子群优化门控循环单元融合注意力机制的多变量时间序列预测 目录 多维时序 | MATLAB实现PSO-GRU-Attention粒子群优化门控循环单元融合注意力机制的多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MAT…...

MySQL缓冲池的优化与性能提升
“不积跬步,无以至千里。” MySQL是许多Web应用的核心数据库,而数据库的性能对于应用的稳定运行至关重要。在MySQL中,缓冲池(Buffer Pool)是一个关键的组件,它直接影响着数据库的性能和响应速度。今天这篇文…...

一些RLHF的平替汇总
卷友们好,我是rumor。 众所周知,RLHF十分玄学且令人望而却步。我听过有的小道消息说提升很大,也有小道消息说效果不明显,究其根本还是系统链路太长自由度太高,不像SFT一样可以通过数据配比、prompt、有限的超参数来可控…...

7.docker部署前端vue项目,实现反向代理配置
介绍: 构建镜像:通过docker构建以nginx为基础的镜像,将vue项目生成的dist包拷贝至nginx目录下,.conf文件做反向代理配置;部署服务:docker stack启动部署服务; 通过执行两个脚本既可以实现构建…...

字符串函数详解
一.字母大小写转换函数. 1.1.tolower 结合cppreference.com 有以下结论: 1.头文件为#include <ctype.h> 2.使用规则为 #include <stdio.h> #include <ctype.h> int main() {char ch A;printf("%c\n",tolower(ch));//大写转换为小…...
Mybatis学习笔记-映射文件,标签,插件
目录 概述 mybatis做了什么 原生JDBC存在什么问题 MyBatis组成部分 Mybatis工作原理 mybatis和hibernate区别 使用mybatis(springboot) mybatis核心-sql映射文件 基础标签说明 1.namespace,命名空间 2.select,insert&a…...
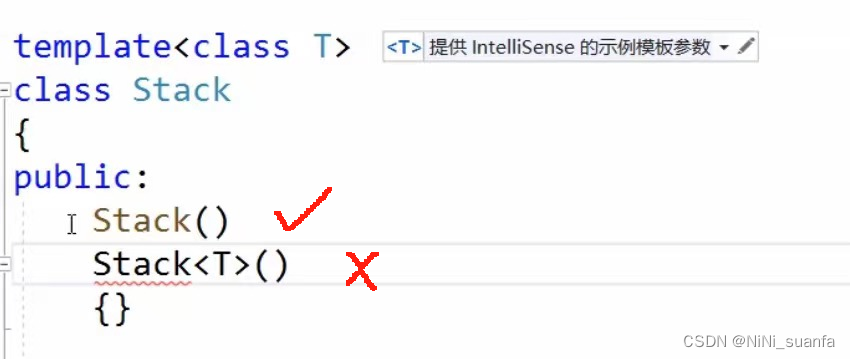
【C++】模板初阶 【 深入浅出理解 模板 】
模板初阶 前言:泛型编程一、函数模板(一)函数模板概念(二)函数模板格式(三)函数模板的原理(四)函数模板的实例化(五)模板参数的匹配原则 三、类模…...
无需API开发,伯俊科技实现电商与客服系统的无缝集成
伯俊科技的无代码开发实现系统连接 自1999年成立以来,伯俊科技一直致力于为企业提供全渠道一盘货的服务。凭借其24年的深耕零售行业的经验,伯俊科技推出了一种无需API开发的方法,实现电商系统和客服系统的连接与集成。这种无代码开发的方式不…...

Python | 机器学习之逻辑回归
🌈个人主页:Sarapines Programmer🔥 系列专栏:《人工智能奇遇记》🔖少年有梦不应止于心动,更要付诸行动。 目录结构 1. 机器学习之逻辑回归概念 1.1 机器学习 1.2 逻辑回归 2. 逻辑回归 2.1 实验目的…...
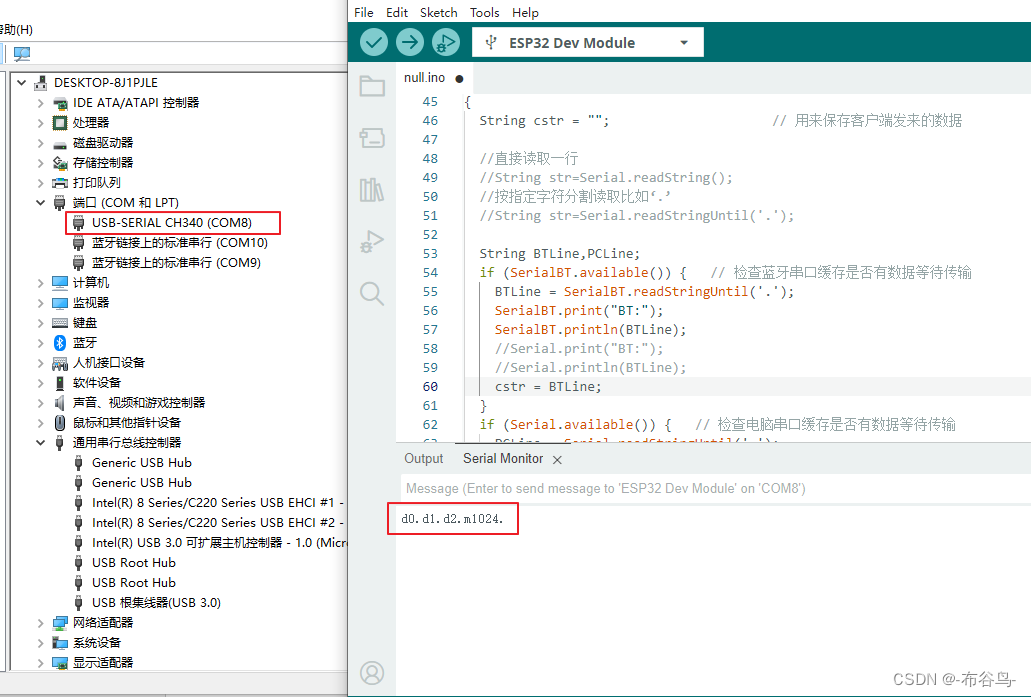
手机,蓝牙开发板,TTL/USB模块,电脑四者之间的通讯
一,意图 通过手机蓝牙连接WeMosD1R32开发板,开发板又通过TTL转USB与电脑连接.手机通过蓝牙控制开发板上的LED灯的开,关,闪等动作,在电脑上打开串口监视工具观察其状态.也可以通过电脑上的串口监视工具来控制开发板上LED灯的动作,而在手机蓝牙监测工具中显示灯的状态. 二,原料…...
Springboot更新用户头像
人们通常(为徒省事)把一个包含了修改后userName的完整userInfo对象传给后端,做完整更新。但仔细想想,这种做法感觉有点二,而且浪费带宽。 于是patch诞生,只传一个userName到指定资源去,表示该请求是一个局部更新&#…...
Express.js 与 Nest.js对比
Express.js 与 Nest.js对比 自从 Node.js 发布以来,Javascript 在后端领域的使用有所增加。由于 Node.js 的使用越来越多,每天都会有新的框架和工具发布。Express 和 Nest 是使用 Node.js 创建后端应用程序的最著名的框架之一,在本文中&…...
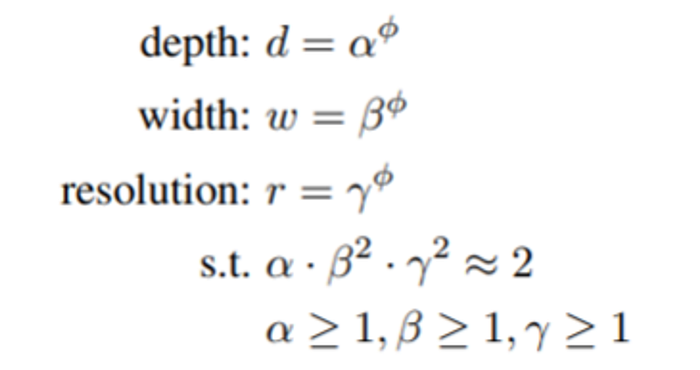
总结 CNN 模型:将焦点转移到基于注意力的架构
一、说明 在计算机视觉时代,卷积神经网络(CNN)几十年来一直是主导范式。直到 2021 年 Vision Transformers (ViTs) 出现,这个领域才开始发生变化。现在,是时候采用受 Transformer 架构启发的基于注意力的模型了&#x…...
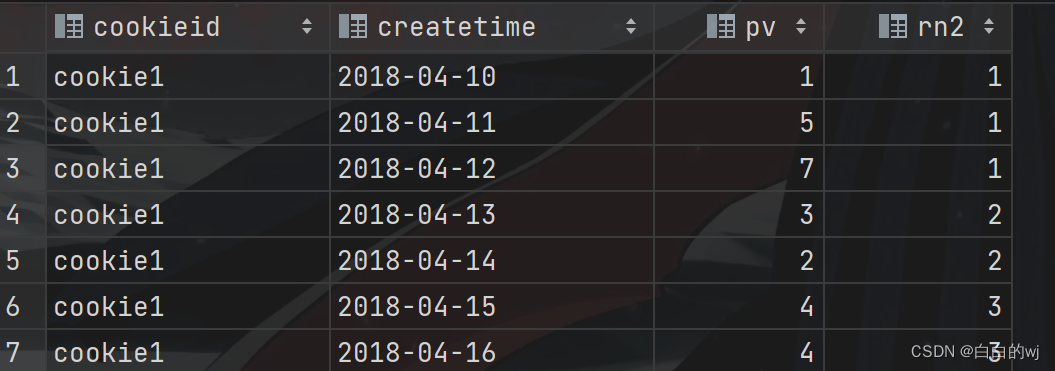
2023.11.16 hivesql高阶函数之开窗函数
目录 1.开窗函数的定义 2.数据准备 3.开窗函数之排序 需求:用三种排序方法查询学生的语文成绩排名,并降序显示 4.开窗函数分组 需求:按照科目来分类,使用三种排序方式来排序学生的成绩 5.聚合函数与分组配合使用 6.聚合函数同时和分组以及排序关键字配合使用 --需求1&…...

QTableWidget常用信号的功能
2023年11月18日,周六上午 itemPressed(QTableWidgetItem *item):当某个项目被按下时发出信号。itemClicked(QTableWidgetItem *item):当某个项目被单击时发出信号。itemDoubleClicked(QTableWidgetItem *item):当某个项目被双击时…...

Vue理解01
项目建立流程 项目文件夹终端vue ui可视化新建项目(需要一些时间)vscode打开项目npm run serve运行 架构理解: 首先打开的页面默认是index.htmlindex.html默认引用main.jsmain.js引用需要的页面,默认App.vue。Vue示例挂载可以在…...
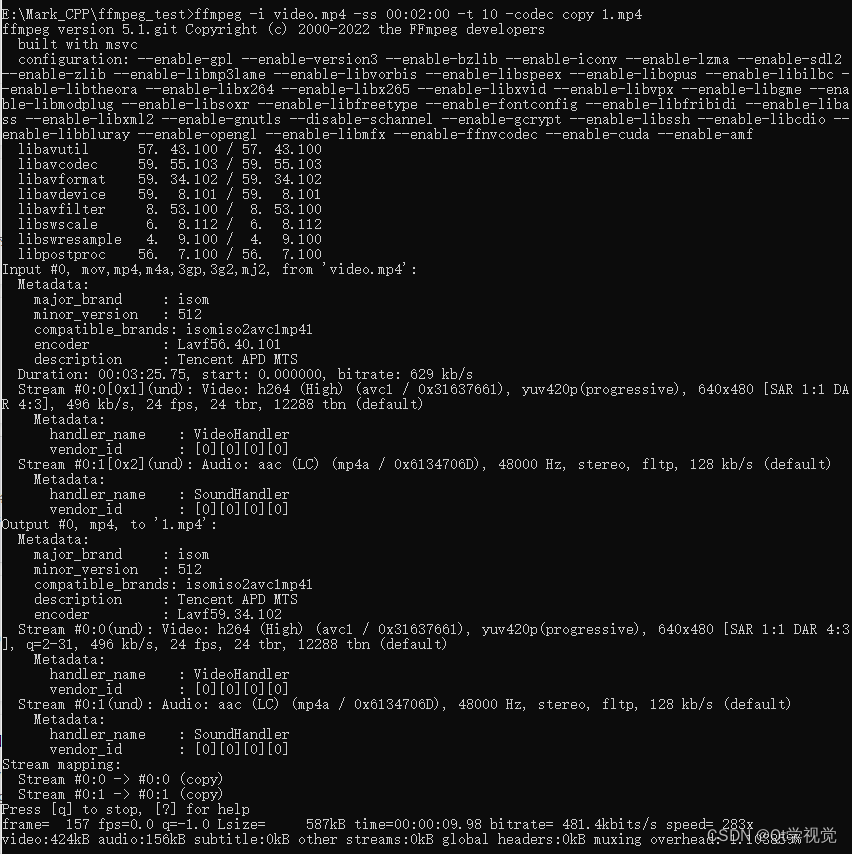
4、FFmpeg命令行操作8
生成测试文件 找三个不同的视频每个视频截取10秒内容 ffmpeg -i 沙海02.mp4 -ss 00:05:00 -t 10 -codec copy 1.mp4 ffmpeg -i 复仇者联盟3.mp4 -ss 00:05:00 -t 10 -codec copy 2.mp4 ffmpeg -i 红海行动.mp4 -ss 00:05:00 -t 10 -codec copy 3.mp4 如果音视…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

Visual Studio Code 扩展
Visual Studio Code 扩展 change-case 大小写转换EmmyLua for VSCode 调试插件Bookmarks 书签 change-case 大小写转换 https://marketplace.visualstudio.com/items?itemNamewmaurer.change-case 选中单词后,命令 changeCase.commands 可预览转换效果 EmmyLua…...