【深度学习】吴恩达课程笔记(五)——超参数调试、batch norm、Softmax 回归
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~
【吴恩达课程笔记专栏】
【深度学习】吴恩达课程笔记(一)——深度学习概论、神经网络基础
【深度学习】吴恩达课程笔记(二)——浅层神经网络、深层神经网络
【深度学习】吴恩达课程笔记(三)——参数VS超参数、深度学习的实践层面
【深度学习】吴恩达课程笔记(四)——优化算法
吴恩达课程笔记——超参数调试、batch norm、Softmax 回归
- 九、超参数调试
- 1.调试处理
- 超参数优先级
- 2.超参数数值搭配选择方法
- 3.为超参数选择合适的范围(标尺)
- 4.超参数调整实践(Pandas VS Caviar)
- 熊猫法
- 鱼子酱法
- 十、batch norm
- 1.归一化网络的激活函数
- 2.把batch norm拟合进神经网络
- 使用的位置
- batch norm拟合进神经网络
- batch norm与minibatch一起使用
- 𝑏[l]参数没有意义
- 3.batch norm为什么好用?
- 问题的提出
- 总结
- 4.测试时的batch norm
- 十一、Softmax 回归
- 1.Softmax 回归简介
- 简介
- 计算方法
- softmax回归举例
- 2.训练一个 Softmax 分类器
- Softmax 名称来源
- 怎样训练带有 Softmax 输出层的神经网络
- 反向传播步骤或者梯度下降法
九、超参数调试
1.调试处理
超参数优先级

红色第一,黄色第二,紫色第三,没框的基本不调
2.超参数数值搭配选择方法

超参数少的时候可以像左面一样均匀取点研究效果。
超参数多的时候可以选择随机取点研究效果。如果此时发现某点及其附近的效果比其它部分好,那么就在这附近的区域较为密集地再多取一些点。如此研究直到得出足够满意的超参数搭配。如下图:

3.为超参数选择合适的范围(标尺)
举例说明:
-
神经网络某层的神经元个数:可以取50-100间均匀随机值
-
神经网络层数:可以取2-4间均匀随机值
-
学习率:可以取0.0001-1间不均匀随机值
α = 1 0 − 4 ∗ n p . r a n d o n . r a n d ( ) 例子中的范围为 [ − 4 , 0 ] \alpha=10^{-4*np.randon.rand()}\\ 例子中的范围为[-4,0] α=10−4∗np.randon.rand()例子中的范围为[−4,0]

标尺长上面这样。这样可以给不同的数量级分配相同的搜索资源。
- 指数平均的 𝛽 :可以取0.9-0.999间不均匀随机值。
因为指数平均计算的是1/(1- 𝛽 )个数的平均值,这个式子在beta接近1的时候对beta更加敏感,因此应该令beta越接近1时,给相应的beta范围分配更多的搜索权重。

如图所示,对1- 𝛽 施以类似上面的学习率的计算,即可达到效果。
实际上,即使不使用这类换标尺的方法,只要有足够数据,或者能恰当的使用逐渐缩小超参数组合范围的方法,也可以较快的算出超参数的恰当值。
4.超参数调整实践(Pandas VS Caviar)
熊猫法
同时运行一个模型,观察其性能随时间变化,手动调整超参数

鱼子酱法
同时运行多个模型,不进行人工干预。全部训练完毕后选出训练结果较好的模型。

十、batch norm
1.归一化网络的激活函数

含义:将z进行归一化。即将z的分布调整到平均值为0,值分布调整到0-1之间(方差为1)。
目的:使得神经网络的参数计算更有效率
注意:在训练隐藏层的时候,有时候为了发挥sigmoid、tanh等的效果,你不希望数据的方差变为1,那么你就没必要对z归一化
z ( 1 ) , . . . , z ( m ) —— > z [ l ] ( i ) , i 为 1 到 m 的某个隐藏层 i μ = 1 m ∑ i m z ( i ) σ n o r m 2 = 1 m ∑ i m ( z i − μ ) 2 z n o r m ( i ) = z ( i ) − μ σ 2 + ϵ z^{(1)},...,z^{(m)} ——>z^{[l](i)},i为1到m的某个隐藏层i\\ \mu=\frac{1}{m}\sum_{i}^{m}z^{(i)} \\ \sigma_{norm}^{2}=\frac{1}{m}\sum_{i}^{m}(z_i-\mu)^{2} \\ z_{norm}^{(i)}=\frac{z^{(i)}-\mu}{\sqrt{\sigma^{2}+\epsilon}}\\ z(1),...,z(m)——>z[l](i),i为1到m的某个隐藏层iμ=m1i∑mz(i)σnorm2=m1i∑m(zi−μ)2znorm(i)=σ2+ϵz(i)−μ
但是有时候我们不希望z分布在0-1、平均值为0,也许分布在别的地方会更有意义。
z ˜ ( i ) = γ z n o r m ( i ) + β 如果 γ , β 如下 : γ = σ 2 + ϵ β = μ 那么: z ˜ ( i ) = z ( i ) \~z^{(i)}=\gamma z_{norm}^{(i)}+\beta\\ 如果\gamma ,\beta如下: \\ \gamma=\sqrt{\sigma^{2}+\epsilon} \\ \beta=\mu \\ 那么:\~z^{(i)}=z^{(i)} z˜(i)=γznorm(i)+β如果γ,β如下:γ=σ2+ϵβ=μ那么:z˜(i)=z(i)
2.把batch norm拟合进神经网络
使用的位置
前向传播中:在计算出z后,使用激活函数前

每个单元负责计算两件事。第一,它先计算 𝑧,然后应用其到激活函数中再计算 𝑎 。每个圆圈代表着两步的计算过程。

batch norm拟合进神经网络
-
没有应用 Batch 归一化:
把输入𝑋拟合到第一隐藏层,然后首先应用 𝑤[1] 和 𝑏[1] 计算 𝑧[1]。
接着,把 𝑧[1] 拟合到激活函数以计算 𝑎[1]。
-
应用 Batch 归一化:Batch 归一化是发生在计算𝑧和𝑎之间的。
-
把输入𝑋拟合到第一隐藏层,然后首先应用 𝑤[1] 和 𝑏[1] 计算 𝑧[1]。
-
(第一层)将 𝑧[1] 值进行 Batch 归一化,简称 BN,此过程将由 𝛽[1] 和 𝛾[1] 两参数控制,这一操作会给你一个新的规范化的 𝑧[1] 值(𝑧̃[1] ),然后将其输入激活函数中得到 𝑎[1],即 𝑎[1] = 𝑔[1] (𝑧̃[l])。
-
(第二层)应用 𝑎[1] 值来计算 𝑧[2],此过程是由 𝑤[2] 和 𝑏[2] 控制的。与你在第一层所做的类似,通过 𝛽[2] 和 𝛾[2] 将 𝑧[2] 进行 Batch 归一化,得到 𝑧̃[2],再通过激活函数计算出 𝑎[2]。
注意:这里的这些( 𝛽[1], 𝛽[2]等等)和超参数𝛽没有任何关系。
( 𝛽[1], 𝛽[2]等等)是算法的新参数 ,接下来你可以使用想用的任何一种优化算法,比如使用梯度下降法来执行它。更新参数 𝛽为 𝛽[l] = 𝛽[l] - 𝛼 𝑑𝛽[l]。你也可以使用 Adam 或 RMSprop 或 Momentum,以更新参数 𝛽 和 𝛾,并不是只应用梯度下降法。
后者是用于 Momentum、 Adam、 RMSprop 或计算各个指数的加权平均值。
-
batch norm与minibatch一起使用

第一个 mini-batch:𝑋{1}
- 应用参数𝑤[1]和𝑏[1] ,计算𝑧[1]
- Batch 归一化减去均值,除以标准差,由𝛽[1]和𝛾[1]得到𝑧̃[1]
- 再应用激活函数得到𝑎[1]
- 应用参数𝑤[2]和𝑏[2],计算𝑧[2]
- 然后继续下去
继续第二个 mini-batch:𝑋{2}
继续第三个 mini-batch:𝑋{3}
𝑏[l]参数没有意义

在使用 Batch 归一化,其实你可以消除参数 𝑏[l],或者设置为 0,参数变成𝑧[l] = 𝑤[l]𝑎[[l-1]
然后对𝑧[l]进行归一化,𝑧̃[l] = 𝛾[l]z[l] +𝛽[l],最后会用参数𝛽[l],以便决定𝑧̃[l]的取值。
**总结:**Batch 归一化,z[l]所有的偏移最终都由归一化确定了, 𝑏[l]参数没有意义,所以由控制参数𝛽[l]代替来影响转移或偏置条件。
3.batch norm为什么好用?
问题的提出

如上图,如果你的训练集是左边的那些黑猫,那么你的训练样本分布可以由左侧坐标系图代替。如果你的训练集是右边那些花猫,那么你的样本分布可由右侧坐标图代替。
假设你分别用两组训练集训练两个模型,那么由于样本分布不同,最后得到的“找猫函数”也会不同。
现在你希望有一个模型,能同时识别黑猫和不同颜色的猫,但是由上可知,如果你同时用黑猫和花猫的训练集进行训练,就容易让神经元感到“迷惑”
总结

- Batch 归一化,从神经网络后层角度而言,前层不会左右移动的那么多,因为被均值和方差所限制,使后层的学习工作变得更容易些。
- Batch 归一化有轻微正则化效果
4.测试时的batch norm
μ = 1 m ∑ i m z ( i ) σ n o r m 2 = 1 m ∑ i m ( z i − μ ) 2 z n o r m ( i ) = z ( i ) − μ σ 2 + ϵ z ˜ ( i ) = γ z n o r m ( i ) + β \mu=\frac{1}{m}\sum_{i}^{m}z^{(i)} \\ \sigma_{norm}^{2}=\frac{1}{m}\sum_{i}^{m}(z_i-\mu)^{2} \\ z_{norm}^{(i)}=\frac{z^{(i)}-\mu}{\sqrt{\sigma^{2}+\epsilon}}\\ \~z^{(i)}=\gamma z_{norm}^{(i)}+\beta\\ μ=m1i∑mz(i)σnorm2=m1i∑m(zi−μ)2znorm(i)=σ2+ϵz(i)−μz˜(i)=γznorm(i)+β
测试时,我们可能不使用minibatch,而是一个一个的过训练样本。这个时候训练集的平均数 𝜇 和方差 𝜎2 怎么获得呢?
-
使用指数加权平均计算
-
使用流动平均来粗略估算
-
使用深度学习框架自默认的方式估算
十一、Softmax 回归
1.Softmax 回归简介
简介
softmax回归是logistic回归的一般形式,它做的不只是二分分类,也可以做多分分类

区分四个种类(class),0-其他、1-猫、2-狗、3-鸡
定义C为种类数,这里C=4,可以看到输出层有四个神经元,他们分别输出结果是0、1、2、3的概率,且总和为1 ,输出结果是一个4*1的向量。
计算方法

左侧是softmax输出层激活函数计算方法:
z [ l ] = W [ l ] a [ l − 1 ] + b [ l ] S o f t m a x 激活函数 : a [ l ] = g [ l ] ( z [ l ] ) t = e z [ l ] a [ l ] = e z [ l ] ∑ j = 1 4 t i a i [ l ] = t i ∑ j = 1 4 t i z^{[l]} = W^{[l]}a^{[l-1]} + b^{[l]} \\ Softmax 激活函数: a^{[l]}=g^{[l]}(z^{[l]})\\ t=e^{z^{[l]}} \\ a^{[l]}=\frac{e^{z^{[l]}}}{\sum_{j=1}^{4}t_i} \\ a_i^{[l]}=\frac{t_i}{\sum_{j=1}^{4}t_i} \\ z[l]=W[l]a[l−1]+b[l]Softmax激活函数:a[l]=g[l](z[l])t=ez[l]a[l]=∑j=14tiez[l]ai[l]=∑j=14titi
右侧是一个例子:

softmax回归举例

2.训练一个 Softmax 分类器
Softmax 名称来源
hardmax 会把向量𝑧变成这个向量[1 0 0 0], 与hardmax 对比,Softmax所做的从𝑧到概率的映射更为温和

怎样训练带有 Softmax 输出层的神经网络

举例:单个样本为猫,这个样本中神经网络的表现不佳,这实际上是一只猫,但却只分配到 20%是猫的概率,所以在本例中表现不佳。
用什么损失函数来训练这个神经网络?
损失函数:
L ( y ^ , y ) = − ∑ j = 1 C y j l o g y ^ j y 1 = y 3 = y 4 = 0 , y 2 = 1 ,则 L ( y ^ , y ) = − l o g y ^ 2 L ( y ^ , y ) 越小越好,则 y ^ 2 需要尽量大 L(ŷ,y)=-\sum_{j=1}^{C}y_jlogŷ_j \\ y_1 = y_3 = y_4 = 0,y_2= 1,则L(ŷ,y)=-logŷ_2 \\ L(ŷ,y)越小越好,则ŷ_2需要尽量大 L(y^,y)=−j=1∑Cyjlogy^jy1=y3=y4=0,y2=1,则L(y^,y)=−logy^2L(y^,y)越小越好,则y^2需要尽量大
反向传播步骤或者梯度下降法
公式:
d z [ l ] = y ^ − y dz^{[l]}=ŷ-y dz[l]=y^−y

相关文章:
【深度学习】吴恩达课程笔记(五)——超参数调试、batch norm、Softmax 回归
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ 【吴恩达课程笔记专栏】 【深度学习】吴恩达课程笔记(一)——深度学习概论、神经网络基础 【深度学习】吴恩达课程笔记(二)——浅层神经网络、深层神经网络 【深度学习】吴恩达课程笔记(三)——参数VS超参数、深度…...
腾讯云轻量级服务器和云服务器什么区别?轻量服务器是干什么用的
随着互联网的迅速发展,服务器成为了许多人必备的工具。然而,面对众多的服务器选择,我们常常会陷入纠结之中。在这篇文章中,我们将探讨轻量服务器和标准云服务器的区别,帮助您选择最适合自己需求的服务器。 腾讯云双十…...

解决:虚拟机远程连接失败
问题 使用FinalShell远程连接虚拟机的时候连接不上 发现 虚拟机用的VMware,Linux发行版是CentOs 7,发现在虚拟机中使用ping www.baidu.com是成功的,但是使用FinalShell远程连接不上虚拟机,本地网络也ping不通虚拟机,…...
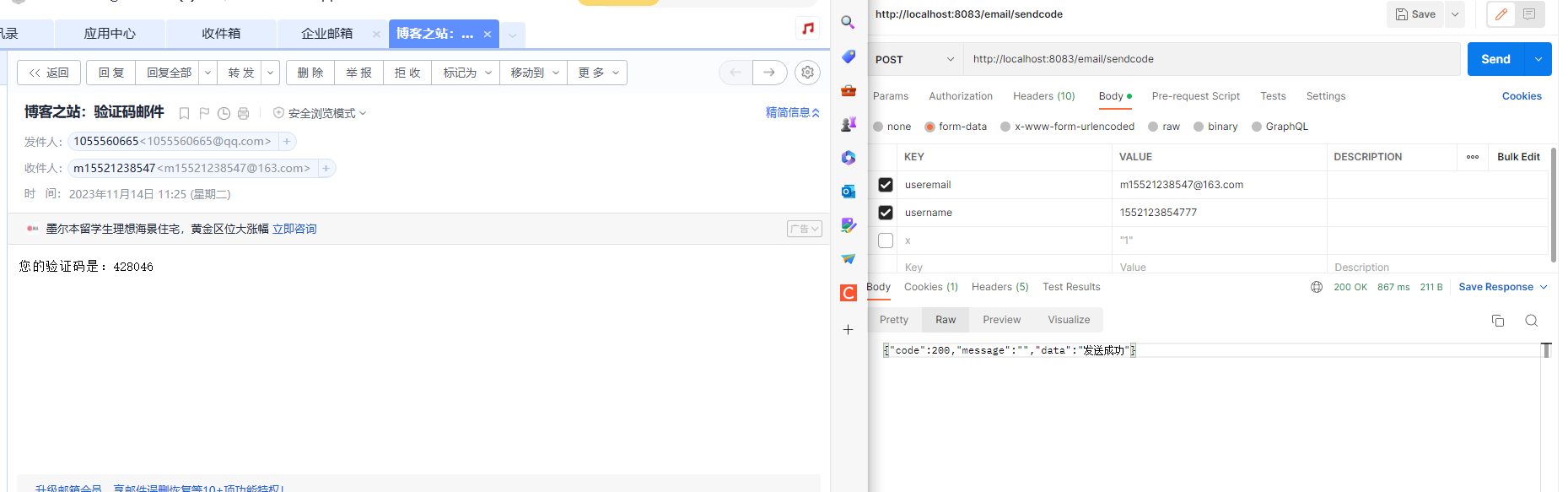
SpringBoot项目集成发邮件功能
1:引入依赖2:配置设置3:授权码获取:4:核心代码5:postman模拟验证6:安全注意 1:引入依赖 <dependency><groupId>org.apache.commons</groupId><artifactId>c…...

【Spring篇】使用注解进行开发
🎊专栏【Spring】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【如愿】 🥰欢迎并且感谢大家指出小吉的问题 文章目录 🌺原代码(无注解)🎄加上注解⭐两个注…...
Flink(六)【DataFrame 转换算子(下)】
前言 今天学习剩下的转换算子:分区、分流、合流。 每天出来自学是一件孤独又充实的事情,希望多年以后回望自己的大学生活,不会因为自己的懒惰与懈怠而悔恨。 回答之所以起到了作用,原因是他们自己很努力。 …...
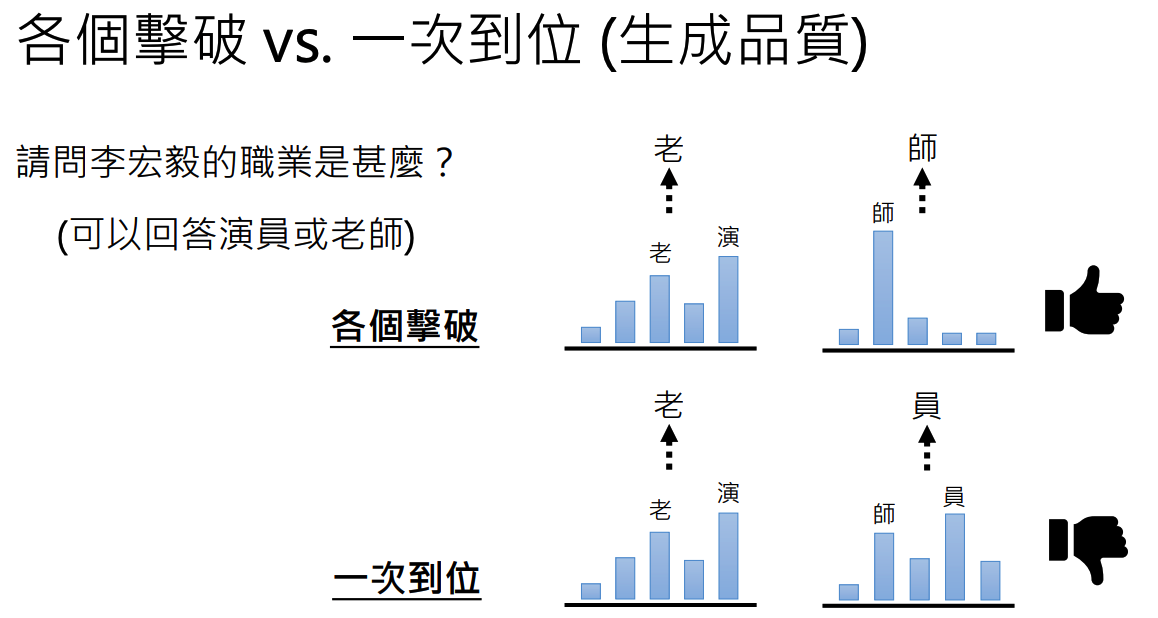
【2023春李宏毅机器学习】生成式学习的两种策略
文章目录 1 各个击破2 一步到位3 两种策略的对比 生成式学习的两种策略:各个击破、一步到位 对于文本生成:把每一个生成的元素称为token,中文当中token指的是字,英文中的token指的是word piece。比如对于unbreakable,他…...

Android13 adb 无法连接?
Android13 adb 无法连接? 文章目录 Android13 adb 无法连接?一、前言二、替换adbGoogle 官网对adb的介绍:Google 提供的adb tools的下载: 三、总结1、adb connect 连接后显示offline2、输入adb devices 报错:版本不匹配导致3、adb常用命令4…...

Ubuntu 20.04 调整交换分区大小
Ubuntu 调整交换分区大小 一、系统情况二、去除旧的交换分区文件三、配置并启用交换分区四、查看swap文件大小 一、系统情况 Ubuntu :Ubuntu 20.04.6 LTS 交换分区位置: cat /proc/swaps二、去除旧的交换分区文件 去掉旧的交换分区有两个步骤&#x…...
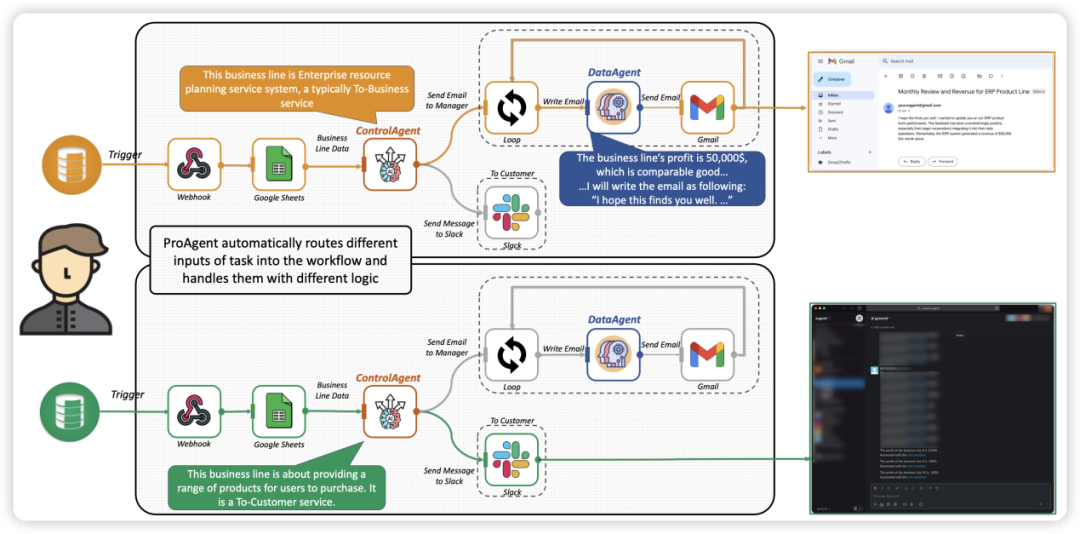
将Agent技术的灵活性引入RPA,清华等发布自动化智能体ProAgent
近日,来自清华大学的研究人员联合面壁智能、中国人民大学、MIT、CMU 等机构共同发布了新一代流程自动化范式 “智能体流程自动化” Agentic Process Automation(APA),结合大模型智能体帮助人类进行工作流构建,并让智能…...

高济健康:数字化科技创新与新零售碰撞 助推医疗产业优化升级
近日,第六届中国国际进口博览会在上海圆满落幕,首次亮相的高济健康作为一家专注大健康领域的疾病和健康管理公司,在本届进博会上向业内外展示了围绕“15分钟步行健康生活圈”构建进行的全域数字化升级成果。高济健康通过数字化科技创新与新零…...

SystemVerilog学习 (5)——接口
一、概述 验证一个设计需要经过几个步骤: 生成输入激励捕获输出响应决定对错和衡量进度 但是,我们首先需要一个合适的测试平台,并将它连接到设计上。 测试平台包裹着设计,发送激励并且捕获设计的输出。测试平台组成了设计周围的“真实世界”,…...
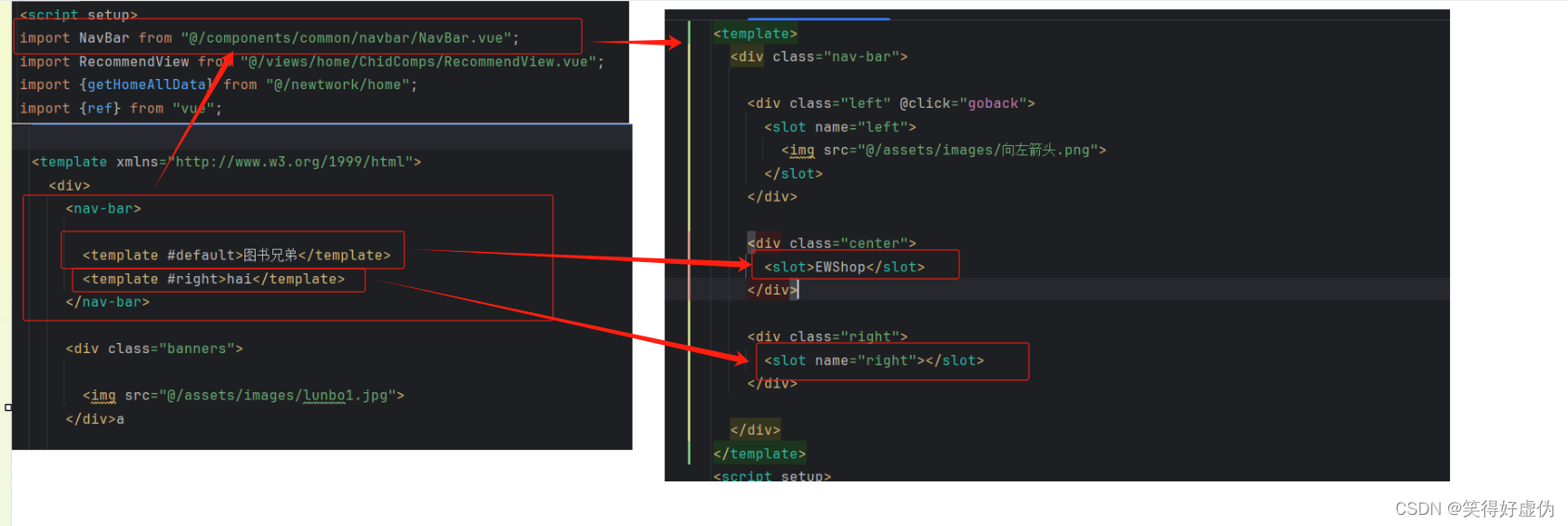
vue3插槽的使用
什么是插槽 Vue 3 插槽(Slots)是一个强大的工具,用于在组件之间传递内容和逻辑。通过使用插槽,我们可以将子组件中的内容插入到父组件中的特定位置。本篇文章将总结 Vue 3 插槽的基本用法、特点以及使用场景。 基本用法 插槽分为…...

IPTABLES问题:DNAT下如何解决内网访问内部服务器问题
这个问题,困扰了我几年了,今天终于得到解决。 问题是这样的,在局域网内部有一台服务器,通过IPTABLES的网关提供对外服务,做过IPTABLES网关的人都知道,这很容易做到,只要在网关机器上写一个DNAT…...
异步任务线程池——最优雅的方式创建异步任务
对于刚刚从校园出来的菜鸡选手很容易写出自以为没问题的屎山代码,可是当上线后就会立即暴露出问题,这说到底还是基础不够扎实!只会背八股文,却不理解,面试头头是道,一旦落地就啥也不是。此处,抛…...

uniapp 跨页面传值及跨页面方法调用
uniapp 跨页面传值及跨页面方法调用 1、跨页面传值 使用全局方法监听uni.$emit、uni.$on、uni.$off 发布、监听、移除 methods: {addFun(){let data [1]uni.navigateBack({ // 返回上一页delta: 1})uni.$emit(successFun,{data}) // 传值} }监听页 onLoad() {uni.$on(succ…...
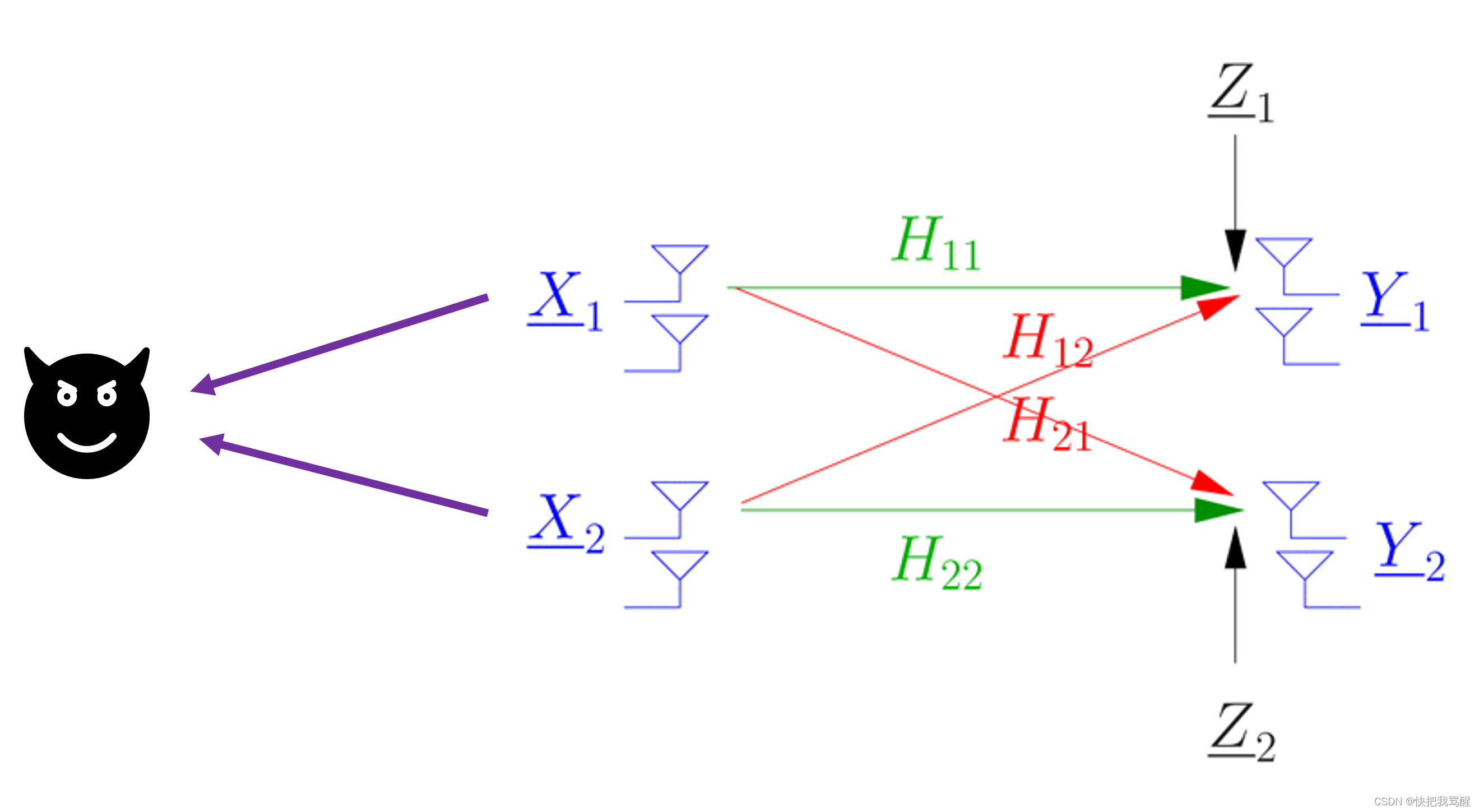
无线物理层安全大作业
这个标题很帅 Beamforming Optimization for Physical Layer Security in MISO Wireless NetworksProblem Stateme Beamforming Optimization for Physical Layer Security in MISO W…...
目标检测标注工具AutoDistill
引言 在快速发展的机器学习领域,有一个方面一直保持不变:繁琐和耗时的数据标注任务。无论是用于图像分类、目标检测还是语义分割,长期以来人工标记的数据集一直是监督学习的基础。 然而,由于一个创新性的工具 AutoDistill&#x…...

关于SPJ表的数据库作业
打字不易,且复制且珍惜 建表 use 库名;create table S( --供应商 SNO char(6) not null, SNAME char(10) not null, STATUS INT, CITY char(10), primary key(SNO));create table P( --零件 PNO char(6) not null, PNAME char(12)not null, COLOR char(4), WEIGHT…...
【Nacos】配置管理、微服务配置拉取、实现配置热更新、多环境配置
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 Nacos 一、nacos实现配置管理1.1 统一配置管…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...