Flink(六)【DataFrame 转换算子(下)】
前言
今天学习剩下的转换算子:分区、分流、合流。
每天出来自学是一件孤独又充实的事情,希望多年以后回望自己的大学生活,不会因为自己的懒惰与懈怠而悔恨。
回答之所以起到了作用,原因是他们自己很努力。 -《解忧杂货店》
1、物理分区算子
常见的物理分区策略有随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast),下边我们分别来做了解。
此外还有我们之前用过的 keyBy 聚合算子,它也是一个分区算子。
1.1、随机分区(shuffle)
package com.lyh.partition;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class PartitionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStreamSource<String> socketDS = env.socketTextStream("localhost", 9999);// 随机分区: random.nextInt(numberOfChannels:下游算子并行度)socketDS.shuffle().print();env.execute();}
}
这里的下游算子并行度在这个案例中指的是我们的 Sink(print)算子,因为我们的并行度是 2 ,所以 random.nextInnt(2) 的结果只会是 0 或 1,也就是说我们的数据会被随机分到这两个编号的任务槽中。
运行结果:
1>4
2>5
1>4
1>2
1>1
2>3
1>5可以看到,随机分区的结果,数据是被随机分到各个区的并没有什么规律。
1.2、轮询分区(reblancce)
轮询分区就是根据并行度把数据对每个下游的算子进行轮流分配。这种处理方式非常适合于当 数据源倾斜 的情况下,我们读取的时候利用轮询分区的方式均匀的把数据分给下游的算子。
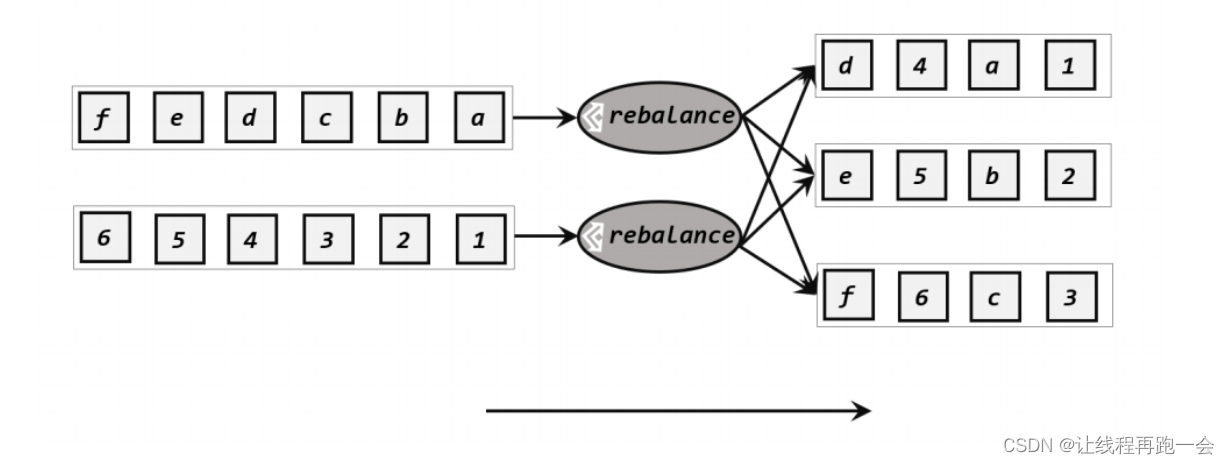
分区逻辑:
// 轮询分区:socketDS.rebalance().print();运行结果:
2> 1
1> 2
2> 3
1> 1
2> 5
1> 2
2> 2
1> 1
1.3、重缩放分区(rescale)
重缩放分区和轮询分区特别相似,对于下游的 n 个子任务,我们假设有 2 个 source 算子(不一定就是 source 而是带有分区方法的算子),那么使用轮询分区每个 source 算子次都要 n 个子任务都轮询发送数据。而重缩放分区的逻辑就是,每个 source 算子只负责 n/2 个任务,
所以当下游任务(数据接收方)的数量是上游任务(数据发送方)数量的整数倍时,rescale的效率明显会更高。比如当上游任务数量是 2,下游任务数量是 6 时,上游任务其中一个分区的数据就将会平均分配到下游任务的 3 个分区中。由于 rebalance 是所有分区数据的“重新平衡”,当 TaskManager 数据量较多时,这种跨节点的网络传输必然影响效率;而如果我们配置的 task slot 数量合适,用 rescale 的方式进行“局部重缩放”,就可以让数据只在当前 TaskManager 的多个 slot 之间重新分配,从而避免了网络传输带来的损耗。
从底层实现上看,rebalance 和 rescale 的根本区别在于任务之间的连接机制不同。rebalance将会针对所有上游任务(发送数据方)和所有下游任务(接收数据方)之间建立通信通道,这是一个笛卡尔积的关系;而 rescale 仅仅针对每一个任务和下游对应的部分任务之间建立通信通道,节省了很多资源。
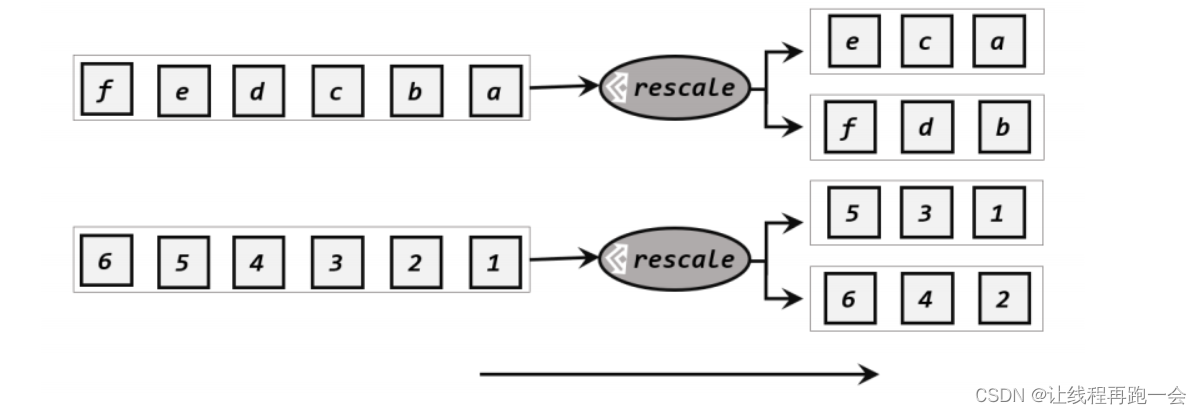
// 缩放分区:socketDS.rescale().print();这里由于 Socket 这种数据源只支持一个 Source 算子读取,所以不做演示。
1.4、广播(broadcast)
广播类似于一种轮询,只不过它每次轮询都会把每个数据发送给所有下游任务。
// 广播分区(使用两个并行度来模拟)
socketDS.broadcast().print();运行结果:
1> 1
2> 1
2> 2
1> 2
1> 3
2> 3
1> 4
2> 4
2> 5
1> 51.5、全局分区(global)
全局分区会把所有数据都发往下游的第一个任务当中。
// 全局分区:socketDS.global().print();并行度为 2 的情况下,运行结果:
1> 1
1> 2
1> 3
1> 4
1> 51.6、自定义分区(custom)
我们可以通过使用 partitionCustom(partitioner,keySelector) 方法来自定义分区策略。在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个是应用分区器的键字段选择器,我们一般都是自己实现一个 KeySelector。
1、自定义分区器
// 自定义分区器
public class MyPartitioner implements Partitioner<String> {// 返回分区号,我们传进来的是一个数字类型的字符串@Overridepublic int partition(String key, int numPartitions) {// 这里我们自己实现一个取模 我们的并行度为2 奇数%2=1 偶数%2=0return Integer.parseInt(key) % numPartitions;}
}public class CustomPartitionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStreamSource<String> socketDS = env.socketTextStream("localhost", 9999);socketDS.partitionCustom(new MyPartitioner(),key->key).print();env.execute();}
}运行结果
2> 1
1> 2
2> 3
1> 4
2> 5
1> 6
1> 8可以看到,奇数都被分到 2 号线程,偶数被分到了 1 号。
2、分流
分流就是把我们传进来的数据流根据一定的规则进行筛选后,将符合条件的数据放到对应的流里。
2.1、Filter
读取一个整数数据流,将数据划分为奇数数据流和偶数数据流。其实我们上面在自定义分区器已经实现了,但那是并行度为 2 的情况刚好达到的这么一种效果。
package com.lyh.split;import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class SplitByFilterDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStreamSource<String> socketDS = env.socketTextStream("localhost", 9999);socketDS.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) throws Exception {if (Integer.parseInt(value)%2==0){return true; // 为true则留下来}return false;}});// lambda 表达式// 偶数流socketDS.filter(value -> Integer.parseInt(value) % 2 == 0).print("偶数流");// 奇数流socketDS.filter(value -> Integer.parseInt(value)%2==1).print("奇数流");env.execute();}
}
运行结果:
偶数流:1> 2
奇数流:2> 1
奇数流:1> 3
偶数流:2> 4
偶数流:1> 6
偶数流:2> 8
奇数流:1> 7
奇数流:2> 9缺点:明显每次 Source 算子传过来的数据需要把所有数据发送给每个转换算子(Filter),明显性能要差一些。
2.2、侧输出流
侧输出流后面我们再做详细介绍,这里只做简单使用。简单来说,只需要调用上下文 context 的 .output() 方法,就可以输出任意类型的数据了,而侧输出流的标记和提取,都离不开一个“输出标签” (OutputTag),指定了侧输出流的 id 和 类型。
案例-我们根据上一节的 POJO 类 WaterSensor 的 id 进行分流(将s1和s2分别分到不同的数据流中去,把非s1、s2的数据保留在主流当中)
package com.lyh.split;import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;/*** @author 刘xx* @version 1.0* @date 2023-11-16 19:25* 使用侧输出流实现数据分流*/
public class SideOutputDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<WaterSensor> sensorDS = env.fromElements(new WaterSensor("s1", 1L, 1),new WaterSensor("s2", 2L, 2),new WaterSensor("s3", 3L, 3),new WaterSensor("s2", 2L, 2));//这里的泛型是我们测流中的数据类型, 注意:如果不是基本数据类型需要单独设置数据类型OutputTag<WaterSensor> s1 = new OutputTag<WaterSensor>("s1", Types.POJO(WaterSensor.class));OutputTag<WaterSensor> s2 = new OutputTag<WaterSensor>("s2", Types.POJO(WaterSensor.class));/*** Flink一共有4层API:底层API、DataStream、Table API、Flink SQL* process(processFunction: 处理逻辑,outputType: 主流的输出类型) 是Flink的底层API*/SingleOutputStreamOperator<WaterSensor> process = sensorDS.process(new ProcessFunction<WaterSensor, WaterSensor>() {@Overridepublic void processElement(WaterSensor sensor, Context context, Collector<WaterSensor> out) throws Exception {if (sensor.getId().equals("s1")) { // 放到侧流s1中context.output(s1, sensor);} else if (sensor.getId().equals("s2")) { // 放到测流s2中context.output(s2, sensor);} else { // 放到主流out.collect(sensor);}}});// 这里打印的是主流的数据,测流需要调用getSideOutput()方法process.print("主流");// 打印测流 s1process.getSideOutput(s1).print("测流s1");// 打印测流 s2process.getSideOutput(s2).print("测流s2");env.execute();}
}
运行结果:
测流s1> WaterSensor{id='s1', ts=1, vc=1}
测流s2> WaterSensor{id='s2', ts=2, vc=2}
主流> WaterSensor{id='s3', ts=3, vc=3}
测流s2> WaterSensor{id='s2', ts=2, vc=2}
这种方式相较于 Filter 明显要效率更高,因为它对每个数据只处理一次。
3、合流
在实际应用中,我们经常会遇到来源不同的多种数据流,需要将它们进行联合处理。这就需要先进行合流,Flink 为我们提供了相应的 API。
3.1、联合(Union)
联合是最简单的合流操作,就是直接将多条数据流合在一起。但是它要求每个流中的数据类型必须是相同的,合并之后的新流会包括所有流中的元素,数据类型不变。
public class UnionDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Integer> source1 = env.fromElements(1, 2, 3, 4, 5);DataStreamSource<Integer> source2 = env.fromElements(11, 22, 33, 44, 55);DataStreamSource<String> source3 = env.fromElements("1", "2", "3", "4", "5");DataStream<Integer> union = source1.union(source2,source3.map(Integer::valueOf));// 使用parseInt也可以,因为它默认是10进制union.print();env.execute();}
}总结:
- 使用 union 时,每条流的数据类型必须一致
- 可以合并多条流
3.2、连接(Connect)
流的联合虽然简单,不过受限于数据类型不能改变,灵活性大打折扣,所以实际应用较少出现。除了联合(union),Flink 还提供了另外一种方便的合流操作——连接(connect)。顾名思义,这种操作就是直接把两条流像接线一样对接起来。
为了处理更加灵活,连接操作允许流的数据类型不同。但我们知道一个 DataStream 中的数据只能有唯一的类型,所以连接得到的并不是 DataStream,而是一个“连接流”(ConnectedStreams)。连接流可以看成是两条流形式上的“统一”,被放在了一个同一个流中;事实上内部仍保持各自的数据形式不变,彼此之间是相互独立的。要想得到新的 DataStream,还需要进一步定义一个“同处理”(co-process)转换操作,用来说明对于不同来源、不同类型的数据,怎样分别进行处理转换、得到统一的输出类型。所以整体上来,两条流的连接就像是“一国两制”,两条流可以保持各自的数据类型、处理方式也可以不同,不过最终还是会统一到同一个 DataStream 中。
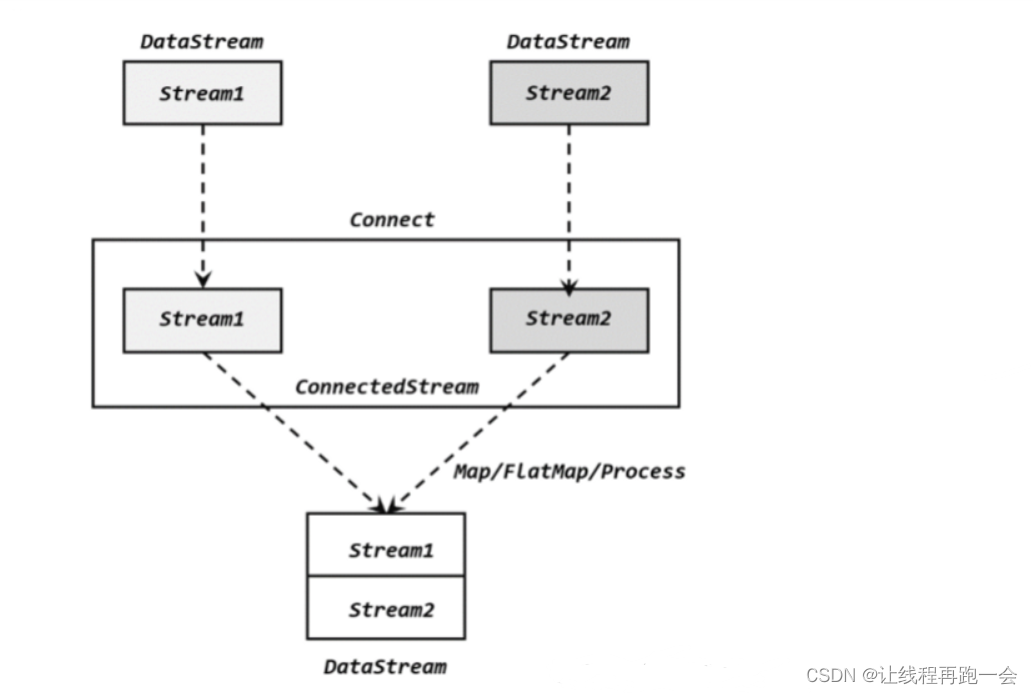
(1)CoMapFunction
package com.lyh.combine;import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;/*** @author 刘xx* @version 1.0* @date 2023-11-16 20:04*/
public class ConnectDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Integer> source1 = env.fromElements(1, 2, 3, 4, 5);DataStreamSource<String> source2 = env.fromElements("a", "b", "c", "d", "e");// connect 合并后,两个数据流仍然是独立的ConnectedStreams<Integer, String> connectedStreams = source1.connect(source2);// map 将两个不同类型的数据转为统一的数据类型SingleOutputStreamOperator<String> res = connectedStreams.map(new CoMapFunction<Integer, String, String>() {@Overridepublic String map1(Integer value) throws Exception {return String.valueOf(value);}@Overridepublic String map2(String value) throws Exception {return value;}});res.print();env.execute();}
}
运行结果:
1
a
2
b
3
c
4
d
5
e总结:
- 一次只能连接 2 条流
- 流的数据类型可以不一样
- 连接后可以调用 map(实现 CoMapFunction 接口)、flatMap(实现 CoFlatMapFunction接口)、process(实现 CoProcessFunction 接口) 来处理,但是各处理各的
(2)CoFlatMapFunction
flatMap 和 map 一样,同样对两种数据流实现两种不同的处理方法(flatMap1 和 flatMap2)。
(3)CoProcessFunction
调用 .process()时,传入的则是一个 CoProcessFunction 实现类。抽象类CoProcessFunction 在源码中定义如下:
// IN1: 第一条流的类型 IN2: 第二条流的类型 OUT: 输出类型
public abstract class CoProcessFunction<IN1, IN2, OUT> extends AbstractRichFunction {...public abstract void processElement1(IN1 value, Context ctx, Collector<OUT> out) throws Exception;public abstract void processElement2(IN2 value, Context ctx, Collector<OUT> out) throws Exception;public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception {}public abstract class Context {...}...
}
它需要实现的也是两个方法(processElement1、processElement2),当数据到来的时候,它会根据其来源调用其中的一个方法进行处理。CoProcessFunction 同样可以通过上下文 ctx 来访问 timestamp、水位线,并通过 TimerService 注册定时器;另外也提供了.onTimer()方法,用于定义定时触发的处理操作。
案例-我们创建两个数据流(一个二元组,一个三元组),要求根据两个不同类型元组的第一个字段匹配,以字符串的形式输出该元组。
package com.lyh.combine;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;/*** @author 刘xx* @version 1.0* @date 2023-11-17 10:02*/
public class ConnectKeyByDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Tuple2<Integer, String>> source1 = env.fromElements(Tuple2.of(1, "a1"),Tuple2.of(1, "a2"),Tuple2.of(3, "b"),Tuple2.of(4, "c"));DataStreamSource<Tuple3<Integer, String,Integer>> source2 = env.fromElements(Tuple3.of(1, "a1",1),Tuple3.of(1, "a2",2),Tuple3.of(3, "b",1),Tuple3.of(4, "c",1));// 连接两条流 输出能根据 id 匹配上的数据(类似 inner join)ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connect = source1.connect(source2);/*** 每条流实现相互匹配:* 1、每条流的数据来了之后,因为是各处理各的,所以要关联在一起必须存到一个变量中去* HashMap<key:String,value:List<Tuple>>* 2、除了存变量外,还需要去另一条流存的变量中去查找是否有匹配的*/SingleOutputStreamOperator<String> process = connect.process(new CoProcessFunction<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>, String>() {Map<Integer, List<Tuple2<Integer, String>>> s1Cache = new HashMap<>();Map<Integer, List<Tuple3<Integer, String, Integer>>> s2Cache = new HashMap<>();@Overridepublic void processElement1(Tuple2<Integer, String> value, Context ctx, Collector<String> out) throws Exception {Integer id = value.f0;// source1 的数据来了就存到变量中去if (!s1Cache.containsKey(id)) {List<Tuple2<Integer, String>> list = new ArrayList<>();list.add(value);s1Cache.put(id, list);} else {s1Cache.get(id).add(value);}// 去 s2Cache 中去查找是否有匹配的if (s2Cache.containsKey(id)) {for (Tuple3<Integer, String, Integer> s2Element : s2Cache.get(id)) {out.collect("s1:" + value + "<-------->" + "s2:" + s2Element);}}}@Overridepublic void processElement2(Tuple3<Integer, String, Integer> value, Context ctx, Collector<String> out) throws Exception {Integer id = value.f0;// source2 的数据来了就存到变量中去if (!s2Cache.containsKey(id)) {List<Tuple3<Integer, String, Integer>> list = new ArrayList<>();list.add(value);s2Cache.put(id, list);} else {s2Cache.get(id).add(value);}// 去 s1Cache 中去查找是否有匹配的if (s1Cache.containsKey(id)) {for (Tuple2<Integer, String> s1Element : s1Cache.get(id)) {out.collect("s2:" + value + "<-------->" + "s1:" + s1Element);}}}});process.print();env.execute();}
}
运行结果:
s2:(1,a1,1)<-------->s1:(1,a1)
s1:(1,a2)<-------->s2:(1,a1,1)
s2:(1,a2,2)<-------->s1:(1,a1)
s2:(1,a2,2)<-------->s1:(1,a2)
s2:(3,b,1)<-------->s1:(3,b)
s2:(4,c,1)<-------->s1:(4,c)我们设置并行度为 2 再运行:
env.setParallelism(2);运行结果:
第一次:
2> s1:(1,a2)<-------->s2:(1,a1,1)
1> s1:(1,a1)<-------->s2:(1,a2,2)第二次:
2> s2:(1,a2,2)<-------->s1:(1,a2)
1> s2:(1,a1,1)<-------->s1:(1,a1)
2> s2:(4,c,1)<-------->s1:(4,c)
1> s2:(3,b,1)<-------->s1:(3,b)我们发现,当并行度为多个的时候,如果不指定分区器的话,每次的运行结果都不一样。
在CoProcessFunction中,可以通过RuntimeContext对象来获取自己的任务编号。所以我们通过在 processElement1 和 processElement2 方法中 调用getRuntimeContext().getIndexOfThisSubtask() 方法获得当前数据所在的 任务编号可以发现,几乎每次数据的分区结果都不一样,但元组对象的 hash值却是一样的。具体分区细节还得去看源码。
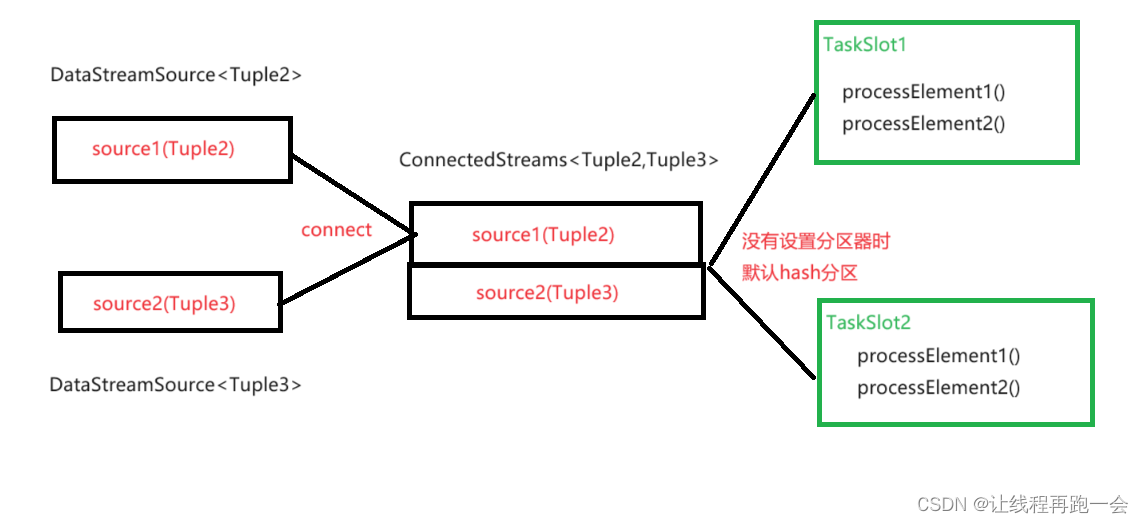
指定按照 元组的第一个字段进行 keyBy 分区:
// 多并行度条件下需要根据关联条件进行 keyBy 才能保证相同的 key 分到同一任务中去ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connect = source1.connect(source2).keyBy(s1 -> s1.f0,s2->s2.f0);运行结果:
1> s1:(4,c)<-------->s2:(4,c,1)
2> s1:(1,a1)<-------->s2:(1,a1,1)
2> s2:(1,a2,2)<-------->s1:(1,a1)
2> s1:(1,a2)<-------->s2:(1,a1,1)
2> s1:(1,a2)<-------->s2:(1,a2,2)
2> s1:(3,b)<-------->s2:(3,b,1)相关文章:
Flink(六)【DataFrame 转换算子(下)】
前言 今天学习剩下的转换算子:分区、分流、合流。 每天出来自学是一件孤独又充实的事情,希望多年以后回望自己的大学生活,不会因为自己的懒惰与懈怠而悔恨。 回答之所以起到了作用,原因是他们自己很努力。 …...
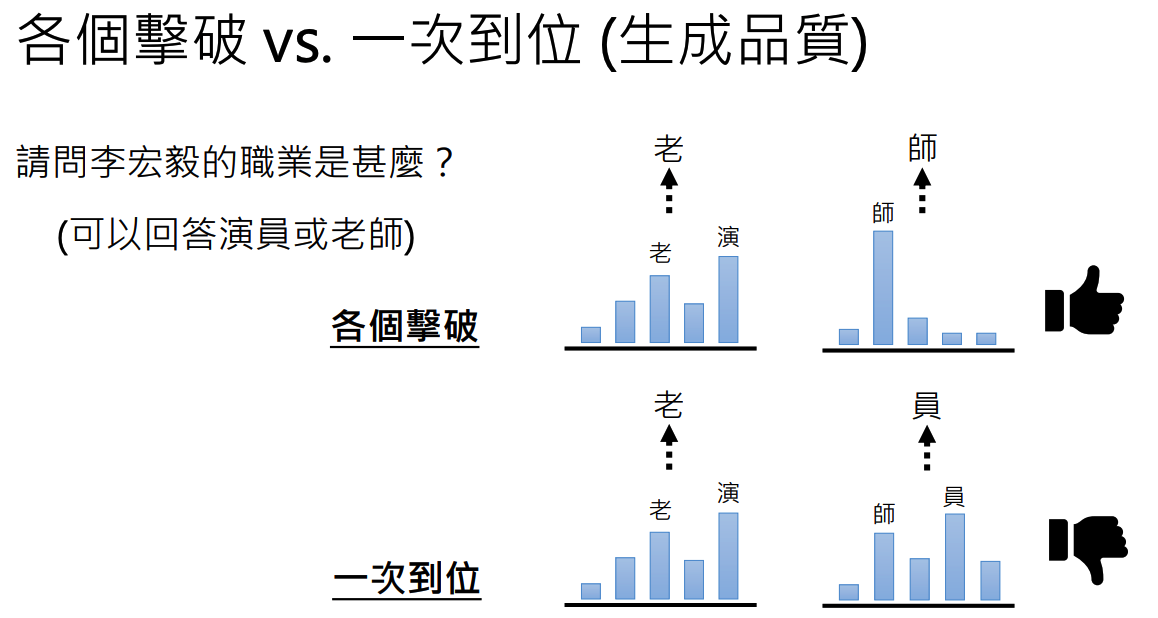
【2023春李宏毅机器学习】生成式学习的两种策略
文章目录 1 各个击破2 一步到位3 两种策略的对比 生成式学习的两种策略:各个击破、一步到位 对于文本生成:把每一个生成的元素称为token,中文当中token指的是字,英文中的token指的是word piece。比如对于unbreakable,他…...

Android13 adb 无法连接?
Android13 adb 无法连接? 文章目录 Android13 adb 无法连接?一、前言二、替换adbGoogle 官网对adb的介绍:Google 提供的adb tools的下载: 三、总结1、adb connect 连接后显示offline2、输入adb devices 报错:版本不匹配导致3、adb常用命令4…...

Ubuntu 20.04 调整交换分区大小
Ubuntu 调整交换分区大小 一、系统情况二、去除旧的交换分区文件三、配置并启用交换分区四、查看swap文件大小 一、系统情况 Ubuntu :Ubuntu 20.04.6 LTS 交换分区位置: cat /proc/swaps二、去除旧的交换分区文件 去掉旧的交换分区有两个步骤&#x…...
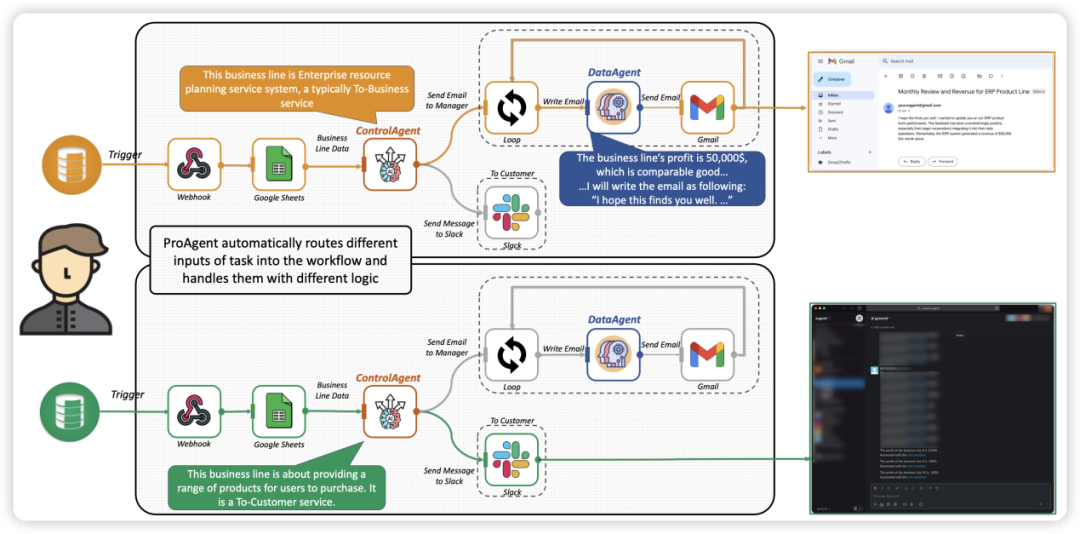
将Agent技术的灵活性引入RPA,清华等发布自动化智能体ProAgent
近日,来自清华大学的研究人员联合面壁智能、中国人民大学、MIT、CMU 等机构共同发布了新一代流程自动化范式 “智能体流程自动化” Agentic Process Automation(APA),结合大模型智能体帮助人类进行工作流构建,并让智能…...

高济健康:数字化科技创新与新零售碰撞 助推医疗产业优化升级
近日,第六届中国国际进口博览会在上海圆满落幕,首次亮相的高济健康作为一家专注大健康领域的疾病和健康管理公司,在本届进博会上向业内外展示了围绕“15分钟步行健康生活圈”构建进行的全域数字化升级成果。高济健康通过数字化科技创新与新零…...

SystemVerilog学习 (5)——接口
一、概述 验证一个设计需要经过几个步骤: 生成输入激励捕获输出响应决定对错和衡量进度 但是,我们首先需要一个合适的测试平台,并将它连接到设计上。 测试平台包裹着设计,发送激励并且捕获设计的输出。测试平台组成了设计周围的“真实世界”,…...
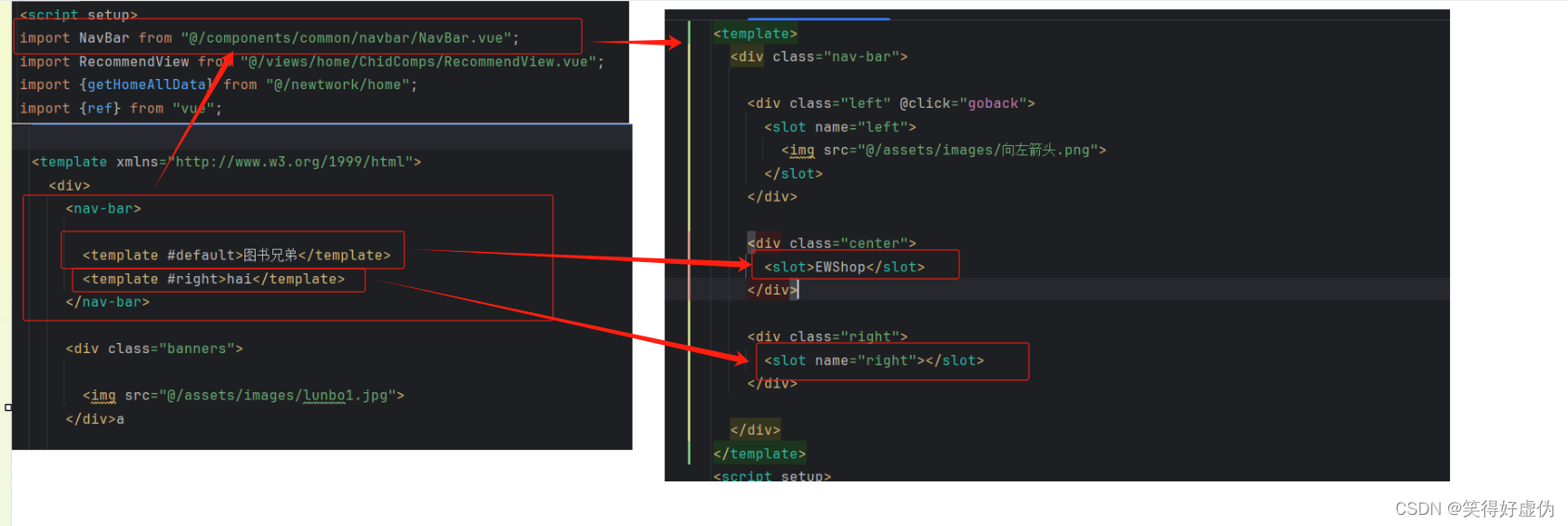
vue3插槽的使用
什么是插槽 Vue 3 插槽(Slots)是一个强大的工具,用于在组件之间传递内容和逻辑。通过使用插槽,我们可以将子组件中的内容插入到父组件中的特定位置。本篇文章将总结 Vue 3 插槽的基本用法、特点以及使用场景。 基本用法 插槽分为…...

IPTABLES问题:DNAT下如何解决内网访问内部服务器问题
这个问题,困扰了我几年了,今天终于得到解决。 问题是这样的,在局域网内部有一台服务器,通过IPTABLES的网关提供对外服务,做过IPTABLES网关的人都知道,这很容易做到,只要在网关机器上写一个DNAT…...
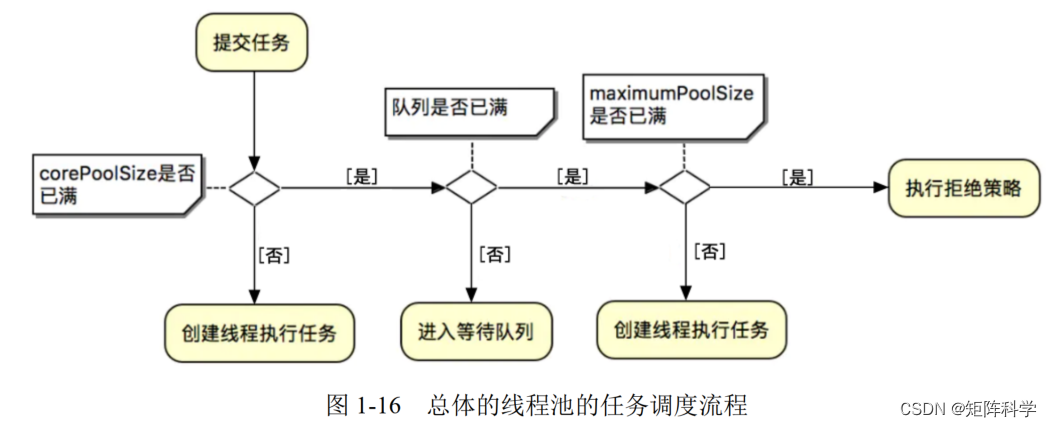
异步任务线程池——最优雅的方式创建异步任务
对于刚刚从校园出来的菜鸡选手很容易写出自以为没问题的屎山代码,可是当上线后就会立即暴露出问题,这说到底还是基础不够扎实!只会背八股文,却不理解,面试头头是道,一旦落地就啥也不是。此处,抛…...

uniapp 跨页面传值及跨页面方法调用
uniapp 跨页面传值及跨页面方法调用 1、跨页面传值 使用全局方法监听uni.$emit、uni.$on、uni.$off 发布、监听、移除 methods: {addFun(){let data [1]uni.navigateBack({ // 返回上一页delta: 1})uni.$emit(successFun,{data}) // 传值} }监听页 onLoad() {uni.$on(succ…...
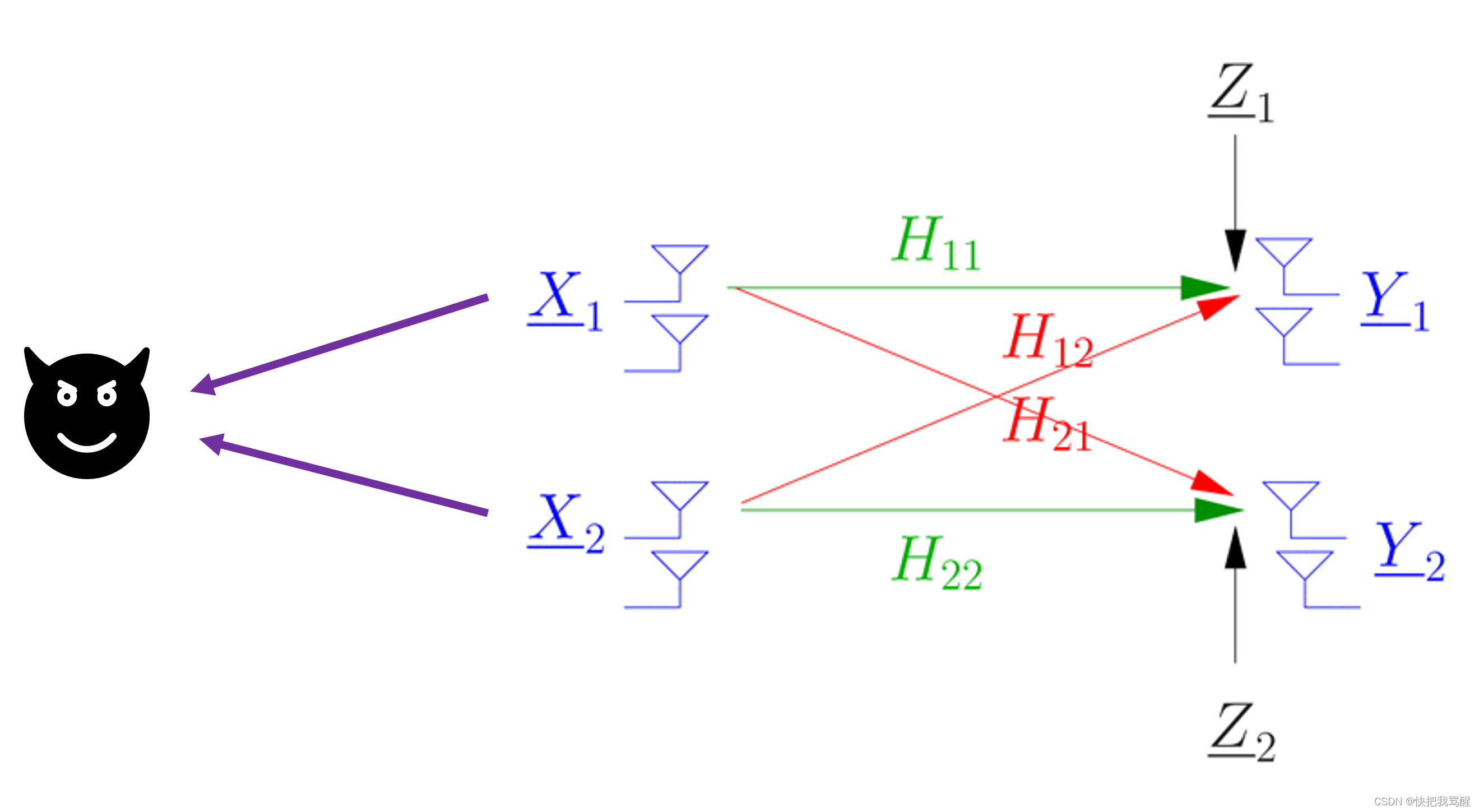
无线物理层安全大作业
这个标题很帅 Beamforming Optimization for Physical Layer Security in MISO Wireless NetworksProblem Stateme Beamforming Optimization for Physical Layer Security in MISO W…...
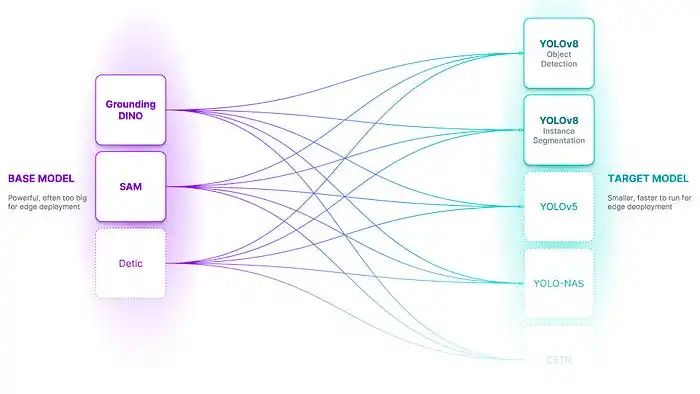
目标检测标注工具AutoDistill
引言 在快速发展的机器学习领域,有一个方面一直保持不变:繁琐和耗时的数据标注任务。无论是用于图像分类、目标检测还是语义分割,长期以来人工标记的数据集一直是监督学习的基础。 然而,由于一个创新性的工具 AutoDistill&#x…...

关于SPJ表的数据库作业
打字不易,且复制且珍惜 建表 use 库名;create table S( --供应商 SNO char(6) not null, SNAME char(10) not null, STATUS INT, CITY char(10), primary key(SNO));create table P( --零件 PNO char(6) not null, PNAME char(12)not null, COLOR char(4), WEIGHT…...
【Nacos】配置管理、微服务配置拉取、实现配置热更新、多环境配置
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 Nacos 一、nacos实现配置管理1.1 统一配置管…...

HTML5学习系列之网页图像
HTML5学习系列之网页图像 前言定义图像定义流定义图标 总结 前言 学习记录 定义图像 标签可以直接把图像插入网页中。 <img src"xx" alt"xx"/>src:显示图像的URLalt:设置图像的替代文本height、width:图像的高度…...

go语言学习之旅之Go语言数据类型
学无止境,今天学习Go 语言数据类型 Go(或Golang)是一种静态类型语言,这意味着变量的数据类型必须显式声明,并且在运行时不能更改。以下是Go中的一些基本数据类型: 这里仅介绍最常用的类型 数值类型: int: …...

Day49 力扣单调栈 : 739. 每日温度 |496.下一个更大元素 I
Day49 力扣单调栈 : 739. 每日温度 |496.下一个更大元素 I 739. 每日温度第一印象看完题解的思路什么是单调栈?我的总结 实现中的苦难感悟代码 496.下一个更大元素 I第一印象看完题解的思路实现中的困难感悟代码 739. 每日温度 今天正式开始单调栈,这是…...
实用篇-ES-RestClient查询文档
一、快速入门 上面的查询文档都是依赖kibana,在浏览器页面使用DSL语句去查询es,如何用java去查询es里面的文档(数据)呢 我们通过match_all查询来演示基本的API,注意下面演示的是 match_all查询,也叫基础查询 首先保证你已经做好了…...

2023年第九届数维杯国际大学生数学建模挑战赛
2023年第九届数维杯国际大学生数学建模挑战赛正在火热进行,小云学长又在第一时间给大家带来最全最完整的思路代码解析!!! 下面是数维杯B题思路解析: 前面三问主要是绘制趋势图、散点图等这些比较简单的统计学分析方法…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...