高性能面试八股文之编译流程程序调度
1. C的编译流程
C语言程序的编译过程通常包括预处理(Preprocessing)、编译(Compilation)、汇编(Assembly)、链接(Linking)四个主要阶段。下面是这些阶段的详细说明:
1.预处理(Preprocessing):
- 目的:在编译前进行一些预处理操作,如宏替换、文件包含等,生成一个扩展名为
.i的中间文件。 - 命令:
gcc -E source.c -o output.i。 -
#include <stdio.h>#define PI 3.14159int main() {printf("The value of PI is: %f\n", PI);return 0; }经过预处理后的代码可能包含
#include指令中的文件内容,以及宏替换后的内容。
2.编译(Compilation):
-
- 目的:将预处理后的文件进行编译,生成一个汇编语言代码文件,扩展名为
.s。 - 命令:
gcc -S output.i -o output.s。 - 示例:
-
.section __TEXT,__text,regular,pure_instructions .globl _main .align 4, 0x90 _main: ## @main.cfi_startproc ## BB#0:pushq %rbp.cfi_def_cfa_offset 16.cfi_offset %rbp, -16movq %rsp, %rbp.cfi_def_cfa_register %rbpsubq $16, %rspleaq L_.str(%rip), %rdimovabsq $4614256656552045848, %rax # imm = 0x3FF921FB54442D18movq %rax, -8(%rbp)movb $0, %alcallq _printfxorl %eax, %eaxaddq $16, %rsppopq %rbpretq.cfi_endproc L_.str: ## @.str.asciz "The value of PI is: %f\n".subsections_via_symbols -
- 这是一个汇编语言的代码文件,展示了C代码的汇编翻译。
- 目的:将预处理后的文件进行编译,生成一个汇编语言代码文件,扩展名为
3.汇编(Assembly):
- 目的:将汇编语言代码转换成机器码,生成一个目标文件,扩展名为
.o。 - 命令:
gcc -c output.s -o output.o。 - 示例:生成一个目标文件,包含机器可执行代码。
-
这是一个简化的编译过程,实际上可能涉及到更多的细节和选项。编译器(如gcc)通常会在后台处理这些步骤,使得编译过程对用户来说更加方便。
-
4.链接(Linking):
- 目的:将程序中使用的函数和库连接在一起,生成最终的可执行文件。
- 命令:
gcc output.o -o executable。 - 示例:将目标文件与系统库进行链接,生成可执行文件。
2. C++的编译流程
C++的编译流程与C语言的编译流程基本相似,因为C++是在C的基础上发展而来的,但C++引入了面向对象的特性,因此在编译过程中可能会包括更多的步骤。下面是C++程序的典型编译流程:
1.预处理(Preprocessing):
- 目的:执行预处理,包括宏替换、文件包含等,生成一个扩展名为
.ii的中间文件。 - 命令:
g++ -E source.cpp -o output.ii。 - 示例:
#include <iostream>#define PI 3.14159int main() {std::cout << "The value of PI is: " << PI << std::endl;return 0; } - 经过预处理后的代码可能包含
#include指令中的文件内容,以及宏替换后的内容。
2.编译(Compilation):
- 目的:将预处理后的文件进行编译,生成一个汇编语言代码文件,扩展名为
.s。 - 命令:
g++ -S output.ii -o output.s。
示例:
.section __TEXT,__text,regular,pure_instructions
.globl _main
.align 4, 0x90
_main: ## @main.cfi_startproc
## BB#0:pushq %rbp.cfi_def_cfa_offset 16.cfi_offset %rbp, -16movq %rsp, %rbp.cfi_def_cfa_register %rbpleaq L_.str(%rip), %rdimovabsq $4614256656552045848, %rax # imm = 0x3FF921FB54442D18movq %rax, -8(%rbp)movb $0, %alcallq __ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKcmovabsq $4614256656552045848, %rcx # imm = 0x3FF921FB54442D18movq %rcx, -16(%rbp)movq %rax, %rdicallq __ZNSolsEdleaq L_.str.1(%rip), %rdimovq %rax, -24(%rbp)movq %rax, %rsimovq %rdi, %raxmovq %rax, %rdicallq __ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKcmovq -16(%rbp), %rsimovabsq $4614256656552045848, %rcx # imm = 0x3FF921FB54442D18movq %rcx, %rdimovq %rax, %rdxcallq __ZNSolsEdleaq L_.str.2(%rip), %rdimovq %rax, %rsicallq __ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKcmovq %rax, %rsimovq -24(%rbp), %rdicallq __ZNSolsEPFRSoS_Emovl $0, %eaxaddq $8, %rsppopq %rbpretq.cfi_endproc.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str.asciz "The value of PI is: %f\n".section __TEXT,__cstring,cstring_literals
L_.str.1: ## @.str.1.asciz "%f".section __TEXT,__cstring,cstring_literals
L_.str.2: ## @.str.2.asciz "\n".subsections_via_symbols
这是一个汇编语言的代码文件,展示了C++代码的汇编翻译。
3.汇编(Assembly):
- 目的:将汇编语言代码转换成机器码,生成一个目标文件,扩展名为
.o。 - 命令:
g++ -c output.s -o output.o。 - 示例:生成一个目标文件,包含机器可执行代码。
4.链接(Linking):
- 目的:将程序中使用的函数和库连接在一起,生成最终的可执行文件。
- 命令:
g++ output.o -o executable。 - 示例:将目标文件与系统库进行链接,生成可执行文件。
这个流程大致描述了C++程序的编译过程。实际上,C++编译器(如g++)可能会在后台执行更多的优化和处理步骤。
3. cuda程序的编译流程
CUDA(Compute Unified Device Architecture)是一种由NVIDIA提供的并行计算平台和编程模型,用于利用NVIDIA GPU的计算能力。CUDA程序的编译过程涉及到主机端(Host)和设备端(Device)两个部分。
以下是简化的CUDA程序编译流程:
-
CUDA源代码:
- 主机端代码(运行在CPU上)和设备端代码(运行在GPU上)都包含在CUDA源代码中,通常具有
.cu或.cuh的文件扩展名。
- 主机端代码(运行在CPU上)和设备端代码(运行在GPU上)都包含在CUDA源代码中,通常具有
-
主机端编译:
- 使用主机端编译器(如
nvcc)对CUDA源代码进行编译。nvcc会将主机端代码编译成可执行文件,同时将设备端代码提取出来。 - 命令:
nvcc -o executable host_code.cu。
- 使用主机端编译器(如
-
设备端编译:
- 使用设备端编译器(PTX(Parallel Thread Execution)编译器)将设备端代码编译成PTX汇编代码。PTX是一种中间表示,可以在不同的GPU上运行。
- 命令:生成的PTX文件通常以
.ptx为扩展名。
-
设备端汇编:
- 使用设备端汇编器将PTX汇编代码转换为针对特定GPU架构的二进制代码(CUBIN文件)。
- 命令:生成的CUBIN文件通常以
.cubin为扩展名。
-
链接:
- 使用链接器将主机端可执行文件与设备端CUBIN文件进行链接,生成最终的可执行文件。
- 命令:通常不需要手动执行链接步骤,
nvcc会自动完成。
总体来说,nvcc编译器会负责协调这些步骤,将主机端和设备端的代码整合在一起,生成可在GPU上执行的最终可执行文件。这个文件可以在CPU上运行主机端代码,并在GPU上运行设备端代码,实现协同计算。需要注意的是,CUDA编程通常需要考虑设备内存管理、线程调度等与GPU相关的特性。
4. cuda SM的调度逻辑以及如何进行调度优化
CUDA中的SM(Streaming Multiprocessor)是NVIDIA GPU中的一个核心执行单元,负责执行CUDA线程块(Thread Blocks)中的线程。SM的调度逻辑涉及到线程调度和指令调度两个方面。
线程调度:
-
Warp:
- SM中的线程以Warp为单位进行调度。Warp是包含32个线程的基本调度单元。
- 同一Warp中的线程同时执行相同的指令,称为SIMD(Single Instruction, Multiple Data)执行模型。
-
调度单元:
- SM包含多个调度单元(Scheduler),每个调度单元负责调度一个Warp的执行。
- 当一个Warp中的某个线程暂停(如等待数据或分支等待)时,调度单元可以调度其他活跃的Warp。
-
上下文切换:
- 当一个Warp中的线程在执行过程中发生分支等待或者数据相关的暂停时,调度单元会切换到另一个Warp,以保持GPU的执行单元忙碌。
指令调度:
-
指令发射:
- 每个调度单元负责将Warp中的指令发射到执行单元。发射的指令会进入指令缓存。
-
执行单元:
- SM包含多个执行单元,每个执行单元可以执行特定类型的指令(整数、浮点数、特殊操作等)。
- 每个Warp中的指令通过执行单元并行执行,以提高整体吞吐量。
调度优化:
-
Warp Divergence:
- 尽量避免Warp中的线程分支等待导致的Warp Divergence,即不同线程执行不同的分支。
- 同一Warp中的线程应尽量执行相同的代码路径,以最大程度地利用SIMD执行模型。
-
隐藏内存访问延迟:
- 通过使用共享内存、使用纹理缓存等手段,尽量隐藏对全局内存的访问延迟,以充分利用SM中的调度资源。
-
减小资源竞争:
- 避免过多的资源竞争,例如使用原子操作时可能导致的竞争问题,以减小SM中调度单元的负担。
-
最大化吞吐量:
- 在设计CUDA内核时,应考虑尽量提高Warp的吞吐量,使得SM能够同时执行多个Warp以充分发挥并行计算能力。
-
使用适当的数据类型:
- 选择适当的数据类型可以提高内存带宽利用率,从而优化调度效率。
调度优化是一个复杂的任务,需要深入理解GPU架构、CUDA编程模型和具体应用的特点。通过合理设计CUDA内核,可以最大程度地发挥GPU的性能。可以使用CUDA的性能分析工具,如NVIDIA Visual Profiler(nvvp)等,来进行调度效率的评估和优化。
5. 多stream程序调度优化
在CUDA编程中,使用多个流(streams)可以提高并行性,充分利用GPU资源。流是一组按照顺序执行的CUDA操作,而多个流可以在同一设备上并发执行。以下是一些多流程序调度的优化策略:
-
流的创建和销毁:
- 尽可能在程序的生命周期中创建一次流并多次重复使用,而不是频繁地创建和销毁流。
- 流的创建和销毁本身会涉及一些开销,因此最好在初始化阶段创建所需的流,并在整个应用程序的执行过程中重复使用它们。
-
异步执行:
- 在程序中使用异步执行,即在主机端和设备端之间异步启动和等待流。
- 通过异步执行,可以在主机端执行计算或数据传输的同时,让设备端执行其他任务,提高整体性能。
-
流之间的任务划分:
- 将任务划分到不同的流中,确保在同一流上的任务之间有一定的并行性。
- 如果任务之间存在依赖关系,确保这些依赖关系不会导致流之间的同步,以最大程度地发挥流并发性。
-
数据传输优化:
- 在使用多流时,考虑数据传输的优化。可以使用异步传输、使用页锁内存(pinned memory)以及使用DMA引擎等技术来最小化主机与设备之间的数据传输时间。
-
流同步:
- 在需要等待某个流上的任务完成时使用显式同步。可以使用
cudaStreamSynchronize函数等待流上的任务完成。 - 注意,不同流之间的同步会导致性能损失,因此只在必要时使用同步。
- 在需要等待某个流上的任务完成时使用显式同步。可以使用
-
流的数量:
- 流的数量不是越多越好,过多的流可能导致资源竞争和调度开销。
- 在选择流的数量时,可以进行一些实验和性能分析,以找到最佳的流的数量,以平衡并行性和调度开销。
-
使用CUDA事件:
- 使用CUDA事件(
cudaEvent_t)可以更细粒度地控制流之间的同步和异步操作。 - 通过记录事件,可以在流之间建立更复杂的依赖关系,提高并行性。
- 使用CUDA事件(
-
动态并行性调整:
- 根据硬件配置和程序特点,动态调整并行性。有些情况下,调整并行任务的数量和大小可以获得更好的性能。
通过合理利用这些优化策略,可以最大程度地发挥多流程序的性能,提高GPU资源的利用率。在实践中,通过使用性能分析工具(如NVIDIA Visual Profiler)可以更好地了解程序在GPU上的执行情况,帮助识别性能瓶颈和进行进一步的优化。
6. Cuda内存管理,资源申请及内存释放
CUDA内存管理是GPU编程中的重要方面,合理的资源申请和内存释放可以显著影响程序的性能。以下是一些CUDA内存管理的优化方案:
资源申请:
-
使用静态内存分配:
- 对于大小已知且固定的数据结构,可以使用静态内存分配,即通过定义数组或结构体来分配内存。这样可以避免动态内存分配的开销和管理。
-
使用共享内存:
- 在CUDA编程中,共享内存是每个线程块(block)私有的高速缓存,对于线程块内的线程可以共享数据。共享内存的访问速度比全局内存快得多。
- 将频繁访问的数据放入共享内存,以提高访问速度。
-
使用纹理内存:
- 对于某些访问模式,如全局内存的随机访问,可以考虑使用纹理内存。纹理内存具有缓存机制,适用于某些数据访问模式,可以提高存取效率。
-
延迟内存分配:
- 在程序初始化阶段,将可能的内存分配推迟到真正需要使用时。这样可以避免在启动时一次性分配大量内存,节省资源。
内存释放:
-
手动管理内存:
- 在某些情况下,手动管理内存的释放可以提高性能。CUDA提供了
cudaMalloc和cudaFree等函数,可以手动分配和释放内存。
- 在某些情况下,手动管理内存的释放可以提高性能。CUDA提供了
-
使用对象池(Object Pool):
- 对于需要频繁创建和销毁的对象,可以考虑使用对象池。对象池在程序初始化时分配一块内存,然后重复使用其中的对象,而不是频繁地进行内存分配和释放。
-
内存合并:
- 当多个小内存块需要释放时,可以考虑将它们合并成一个较大的内存块,再进行释放。这可以减少内存碎片,提高内存利用率。
-
使用统一内存:
- 对于一些较新的NVIDIA GPU,支持统一内存(Unified Memory)。统一内存可以由CPU和GPU同时访问,CUDA运行时会自动进行数据迁移。使用统一内存可以简化内存管理,但需要注意性能开销。
-
注意内存对齐:
- 确保数据结构和数组的内存对齐,以提高访问效率。可以使用
cudaMallocPitch等函数来分配按照特定对齐方式的内存。
- 确保数据结构和数组的内存对齐,以提高访问效率。可以使用
-
使用内存池:
- 对于多次申请和释放同样大小的内存块,可以使用内存池,避免频繁的内存分配和释放,提高效率。
在进行内存管理时,除了考虑性能,还需要考虑代码的可读性和维护性。选择适当的内存管理策略取决于具体应用场景和需求。在进行优化时,建议通过性能分析工具(如NVIDIA Visual Profiler)来评估和验证内存管理的效果
7. GPU中tensor core及cuda core的关系
- 简单介绍一下 tensor core 和 cuda core
-
Tensor Cores 是 NVIDIA GPU 中的一种硬件功能,旨在加速深度学习任务的矩阵乘法运算。CUDA Cores 是 GPU 中的通用处理单元,负责执行通用的计算任务。
在 NVIDIA Volta 架构及之后的一些架构中,Tensor Cores 被引入以提高深度学习任务的性能。这些 Tensor Cores 是在 GPU 的 SM(Streaming Multiprocessor)中的特殊功能单元,与传统的 CUDA Cores 不同。Tensor Cores 主要用于执行矩阵乘法运算,这是深度学习中的一个关键操作。
下面是 Tensor Cores 和 CUDA Cores 之间的关系:
-
CUDA Cores:
- CUDA Cores 是通用的处理单元,负责执行通用的 GPU 计算任务。它们可以执行各种类型的指令,适用于广泛的计算工作负载,包括图形渲染、科学计算、物理模拟等。
- 在深度学习任务中,CUDA Cores 也会执行一些通用的计算,但并不专门优化矩阵乘法等深度学习操作。
-
Tensor Cores:
- Tensor Cores 是一种专门用于执行深度学习中矩阵乘法运算的硬件单元。它们采用低精度(通常是半精度浮点数)运算,通过同时处理多个元素来提高计算性能。
- Tensor Cores 通常以矩阵乘法的形式工作,如 A*B=C,其中 A、B 和 C 都是矩阵。Tensor Cores 对于矩阵乘法的计算效率更高。
-
- tensor core的实现原理
-
-
Mixed-Precision Arithmetic:
- Tensor Cores 使用混合精度算术进行计算,主要包括浮点 16 位(half precision)和整数 32 位(integer)计算。
- 输入和输出通常是浮点 16 位,而中间计算过程可能使用整数 32 位。
-
4x4 Matrix Multiply and Accumulate(MMA):
- Tensor Cores 主要通过 4x4 矩阵乘法和累加(MMA)来执行计算。这意味着它们能够同时处理 4x4 的矩阵块,从而实现更高的计算并行度。
- 计算过程中,输入矩阵被加载到 Tensor Cores 中,进行 4x4 矩阵乘法,然后结果累加到输出矩阵中。
-
数据压缩:
- Tensor Cores 使用权重和激活值的低精度表示,从而减少了内存带宽需求和计算开销。
- 例如,在矩阵乘法计算中,通常使用 float16 数据类型进行计算,减少了数据传输和计算时的存储需求。
-
Fused Multiply-Add(FMA):
- Tensor Cores 支持融合乘法累加(FMA)操作,即乘法和加法可以在一个时钟周期内完成。
- 这使得 Tensor Cores 能够在单个指令中同时执行乘法和累加,提高计算效率。
-
独立单元:
- Tensor Cores 是 GPU 中的特殊硬件单元,与 CUDA Cores 独立。它们具有专门的电路和指令集,用于执行深度学习中的矩阵乘法。
-
支持 FP16 和 INT8 算术:
- Tensor Cores 可以执行浮点 16 位(FP16)和整数 8 位(INT8)的混合精度计算,以适应不同的深度学习模型需求。
-
- fp16 非卷积和矩阵乘预算是在哪里执行
- 简而言之:
-
矩阵乘法: Tensor Cores 设计用于加速大规模矩阵乘法运算,专门使用 FP16 或 INT8 数据类型。
-
非矩阵操作: 除矩阵乘法之外的操作,例如卷积、逐元素操作和其他非矩阵数学运算,通常由 CUDA Cores 完成。
-
在使用 TensorFlow 或 PyTorch 等深度学习框架时,框架会在支持的 GPU 上自动利用 Tensor Cores 加速适用的矩阵运算。对于非矩阵操作,CUDA Cores 负责执行计算。
值得注意的是,不同 GPU 架构的确切功能和特性可能有所不同,而 Tensor Cores 的利用也取决于深度学习框架的实现和配置方式。
-
- 简而言之:
- 如何高效的使用tensor core 和cuda core
-
高效使用 Tensor Cores:
-
使用 FP16 数据类型:
- Tensor Cores 主要用于加速 FP16(float16)计算。确保你的深度学习模型和框架支持使用 FP16 数据类型。
-
合理设置混合精度:
- 在深度学习框架中,如 TensorFlow 和 PyTorch,启用混合精度训练(mixed precision training)。这样可以在前向传播时使用 FP16 计算,从而利用 Tensor Cores 进行加速。
-
注意数据范围:
- 由于 FP16 的数据范围相对较小,确保在使用时不会导致数值溢出或损失过多的精度。
-
优化数据传输:
- 减少主机与设备之间的数据传输次数,使用异步传输和页锁定内存(pinned memory)来优化数据传输性能。
-
减小线程阻塞:
- 优化 CUDA Kernel 中的线程布局和块大小,以减小线程阻塞,确保 GPU 的计算资源得到最大利用。
-
使用共享内存:
- 对于涉及共享内存的计算密集型任务,合理使用共享内存以提高访问速度。
-
减少数据竞争:
- 考虑减少线程间的数据竞争,使用原子操作或其他同步机制以避免竞争条件。
-
并行任务划分:
- 将任务划分成适当的大小,以充分利用 CUDA Cores 的并行性。这包括适当的网格和块大小设置。
-
使用 Warp-Level Primitives:
- NVIDIA提供了 Warp-Level Primitives 库,其中包含了一些 Warp 级别的原语,可用于高效的 Warp 级别操作。
-
合理利用流:
- 使用 CUDA 流(stream)以实现异步执行,充分利用 GPU 上的计算和数据传输资源。
-
适用性能分析工具:
- 使用性能分析工具,如 NVIDIA Nsight、NVIDIA Visual Profiler 等,来评估和优化你的 CUDA Kernel 和整体程序性能。
-
相关文章:

高性能面试八股文之编译流程程序调度
1. C的编译流程 C语言程序的编译过程通常包括预处理(Preprocessing)、编译(Compilation)、汇编(Assembly)、链接(Linking)四个主要阶段。下面是这些阶段的详细说明: 1.…...

opencv的MinGW-W64编译
最近使用Qt,需要用到opencv,安装详情参考下面这个网址,写的挺好: opencv的MinGW-W64编译 - 知乎 我电脑安装Qt中自带了MinGW,所以不需要像上面网址中的下载MinGw,只需要将Qt中自带的MinGW添加到环境变量即可,如&…...
在Go编程中调用外部命令的几种场景
1.摘要 在很多场合, 使用Go语言需要调用外部命令来完成一些特定的任务, 例如: 使用Go语言调用Linux命令来获取执行的结果,又或者调用第三方程序执行来完成额外的任务。在go的标准库中, 专门提供了os/exec包来对调用外部程序提供支持, 本文将对调用外部命令的几种使用方法进行总…...

python学习:break用法详解
嗨喽,大家好呀~这里是爱看美女的茜茜呐 在执行while循环或者for循环时,只要循环条件满足,程序会一直执行循环体。 但在某些场景,我们希望在循环结束前就强制结束循环。 Python中有两种强制结束循环的方法: continue语…...

【算法萌新闯力扣】:找到所有数组中消失对数字
力扣热题:找到所有数组中消失对数字 开篇 这两天刚交了蓝桥杯的报名费,刷题的积极性高涨。算上打卡题,今天刷了10道算法题了,题目都比较简单,挑选了一道还不错的题目与大家分享。 题目链接:448.找到所有数组中消失对…...
Node.js 安装配置
文章目录 安装检测Node是否可用 安装 首先我们需要从官网下载Node安装包:Node.Js中文网,下载后双击安装没有什么特殊的地方,安装路径默认是C盘,不想安装C盘的话可以选择一下其他的盘符。安装完成以后可以不用配置环境变量,Node安装已经自动给…...
前端JS 使用input完成文件上传操作,并对文件进行类型转换
使用input实现文件上传 // 定义一个用于文件上传的按钮<input type"file" name"upload1" />// accept属性用于定义允许上传的文件类型, onchange用于绑定文件上传之后的相应函数<input type"file" name"upload2"…...

探索AI交互:Python与ChatGPT的完美结合!
大家好!我是爱摸鱼的小鸿,人生苦短,我用Python!关注我,收看技术干货。 随着人工智能的迅速发展,AI交互正成为技术领域的一大亮点。在这个过程中,Python编程语言和ChatGPT模型的结合展现出强大的…...
CI/CD - jenkins
目录 一、部署 1、简介 2、部署 二、配置 三、实时触发 四、自动化构建docker镜像 五、通过ssh插件交付任务 六、添加jenkins节点 七、RBAC 八、pipeline 九、jenkins结合ansible参数化构建 1、安装ansible 2、新建gitlab项目 3、jenkins新建项目playbook 一、部…...
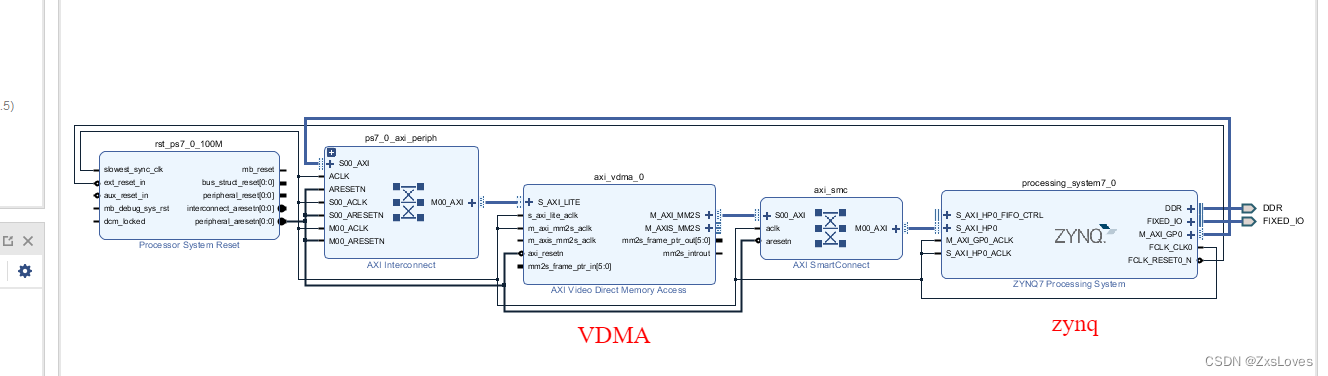
【【萌新的SOC学习之 VDMA 彩条显示实验之一】】
萌新的SOC学习之 VDMA 彩条显示实验之一 实验任务 : 本章的实验任务是 PS写彩条数据至 DDR3 内存中 然后通过 VDMA IP核 将彩条数据显示在 RGB LCD 液晶屏上 下面是本次实验的系统框图 VDMA 通过 HP接口 与 PS端的 DDR 存储器 进行交互 因为 VDMA 出来的是 str…...
,并输出halcon格式对象)
相机通用类之海康相机,软触发硬触发(飞拍),并输出halcon格式对象
//在此之前可以先浏览我编写的通用上位机类,更方便理解 https://blog.csdn.net/m0_51559565/article/details/134403745最近完成一个关于海康采图的demo,记录并说明用法。 先上代码。using System; using System.Collections.Generic; using System.Runt…...

linux时间调整
查看当前系统时间 [rootVM-12-12-centos ~]# date Sat Nov 18 16:09:11 CST 2023 Sat:表示星期六Saturday的缩写 Nov:表示十一月November的缩写 18:表示日期18号 16:09:11:时间 CST:China Standard Time中国标准…...

C++模版初阶
泛型编程 如下的交换函数中,它们只有类型的不同,应该怎么实现一个通用的交换函数呢? void Swap(int& left, int& right) {int temp left;left right;right temp; }void Swap(double& left, double& right) {double temp…...
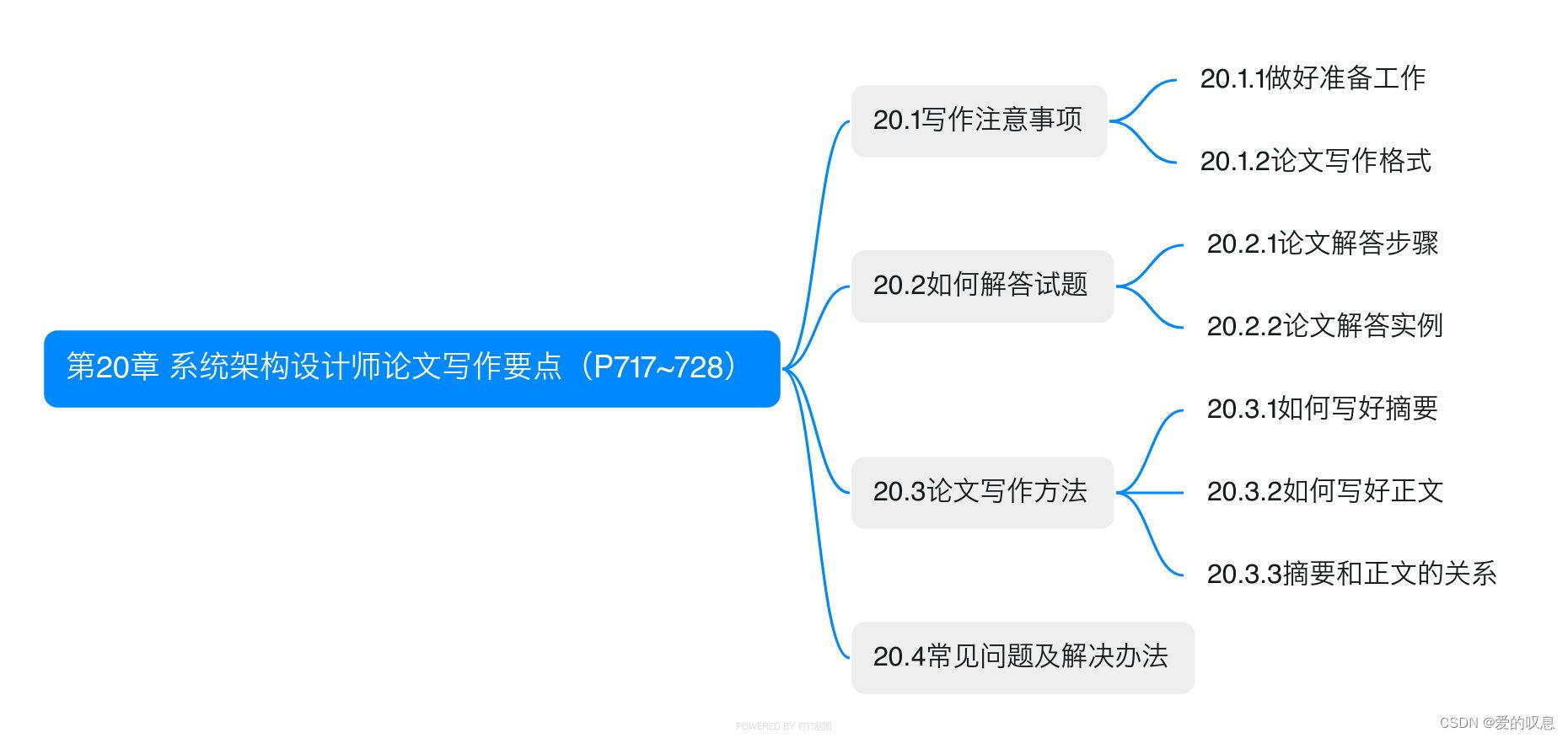
软考-高级-系统架构设计师教程(清华第2版)【第20章 系统架构设计师论文写作要点(P717~728)-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第20章 系统架构设计师论文写作要点(P717~728)-思维导图】 课本里章节里所有蓝色字体的思维导图...

Go 语言结构体验证详解:validate 标签与自定义规则
介绍 Go 语言中,结构体验证是保障数据完整性和正确性的重要手段之一。本文将深入探讨 validate 标签的使用方式,并介绍如何结合验证库 go-playground/validator 进行自定义验证规则。 安装与导入验证库 首先,请确保已安装验证库:…...
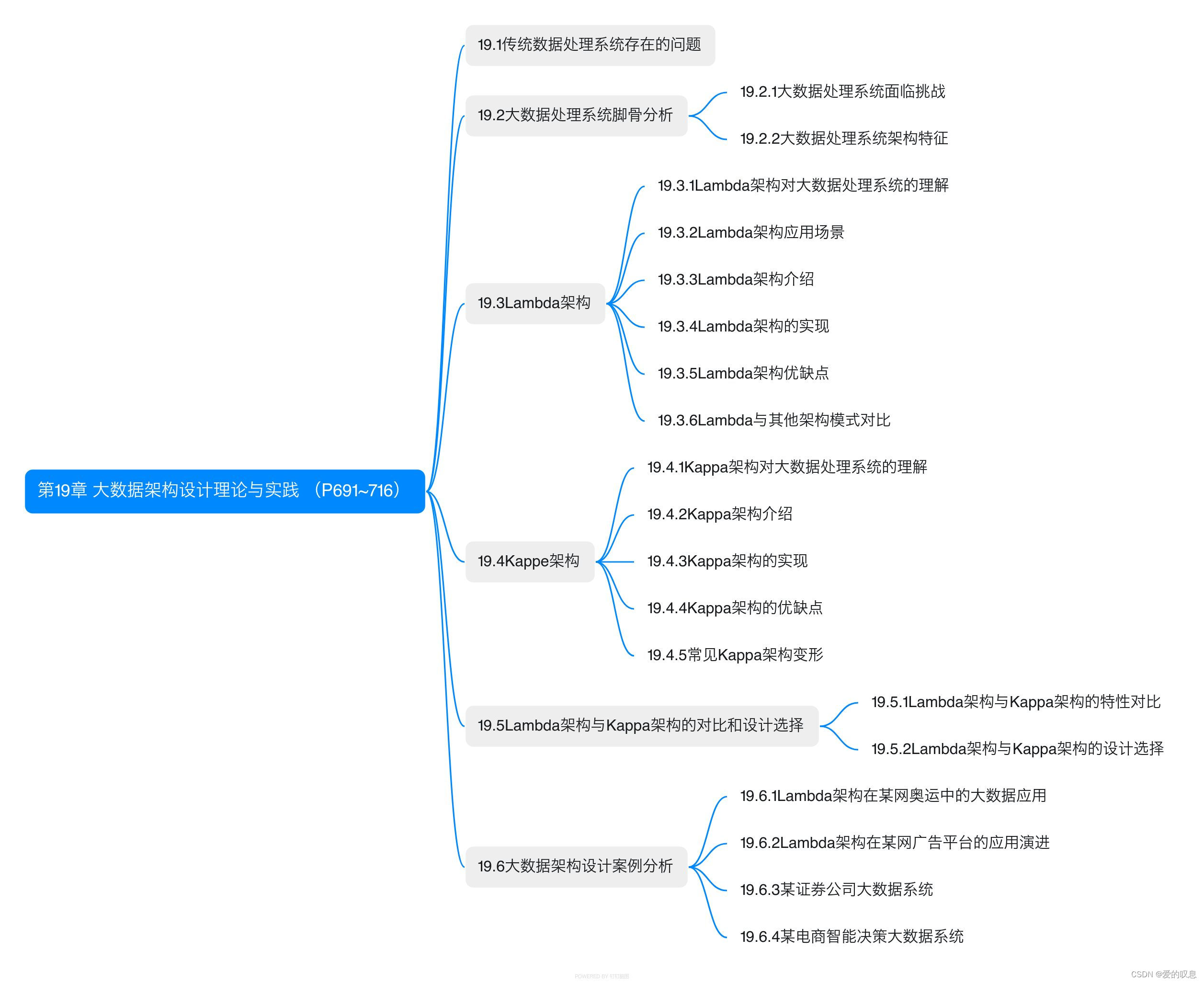
软考-高级-系统架构设计师教程(清华第2版)【第19章 大数据架构设计理论与实践 (P691~716)-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第19章 大数据架构设计理论与实践 (P691~716)-思维导图】 课本里章节里所有蓝色字体的思维导图...

深度学习YOLOv5车辆颜色识别检测 - python opencv 计算机竞赛
文章目录 1 前言2 实现效果3 CNN卷积神经网络4 Yolov56 数据集处理及模型训练5 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习YOLOv5车辆颜色识别检测 ** 该项目较为新颖,适合作为竞赛课题方向࿰…...

c语言-浅谈指针(3)
文章目录 1.字符指针变量常见的字符指针初始化另一种字符指针初始化例: 2.数组指针变量什么是数组指针变量数组指针变量创建数组指针变量初始化例(二维数组传参的本质) 3.函数指针变量什么是函数指针变量呢?函数指针变量创建函数指…...

从服务器端获取人脸数据,在本地检测特征,并将特征发送给服务器
目录 1.定义函数get_database_process: 2.定义函数features_construct: 3.定义函数send_features_data: 4. 定义函数database_features_construct: 5. main 函数 1.定义函数get_database_process: …...
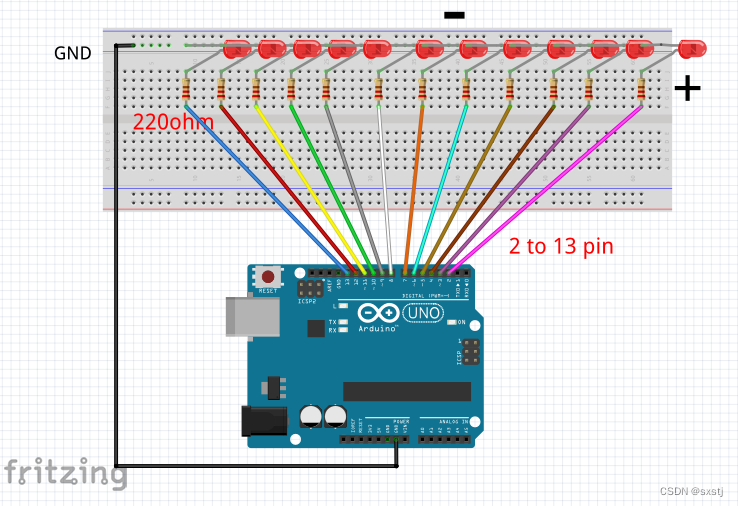
ARDUINO UNO 12颗LED超酷流水灯效果
效果代码: #define t 30 #define t1 20 #define t2 100 #define t3 50 void setup() { // set up pins 2 to 13 as outputs for (int i 2; i < 13; i) { pinMode(i, OUTPUT); } } /Effect 1 void loop() { effect_1(); effect_1(); effect_…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...
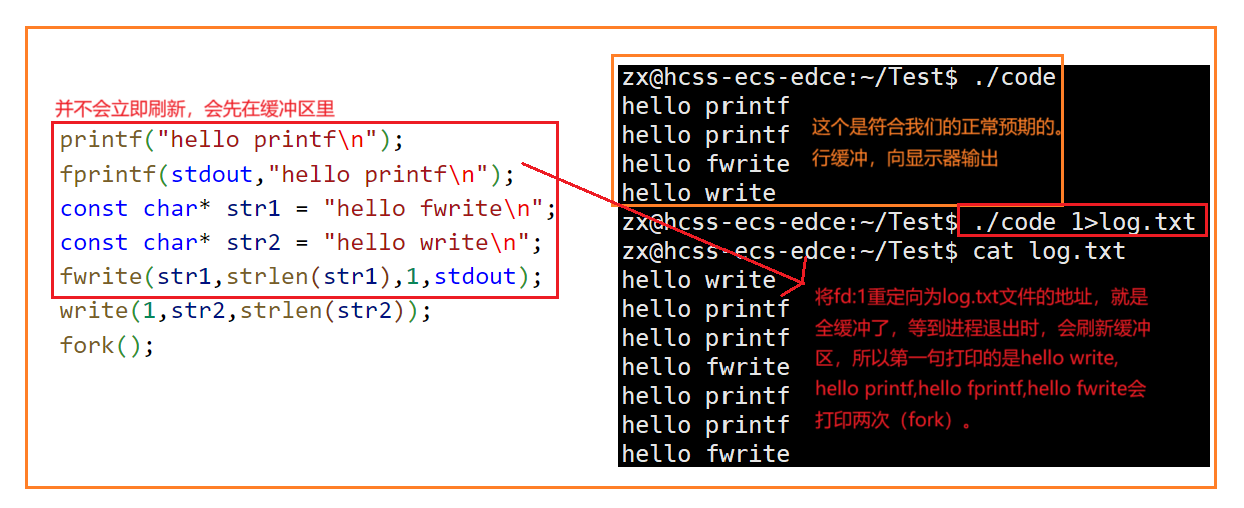
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现指南针功能
指南针功能是许多位置服务应用的基础功能之一。下面我将详细介绍如何在HarmonyOS 5中使用DevEco Studio实现指南针功能。 1. 开发环境准备 确保已安装DevEco Studio 3.1或更高版本确保项目使用的是HarmonyOS 5.0 SDK在项目的module.json5中配置必要的权限 2. 权限配置 在mo…...
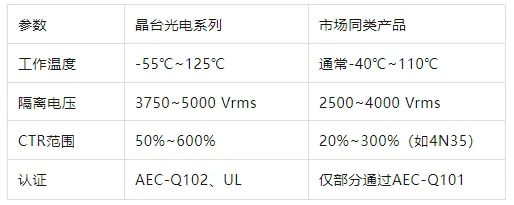
高抗扰度汽车光耦合器的特性
晶台光电推出的125℃光耦合器系列产品(包括KL357NU、KL3H7U和KL817U),专为高温环境下的汽车应用设计,具备以下核心优势和技术特点: 一、技术特性分析 高温稳定性 采用先进的LED技术和优化的IC设计,确保在…...
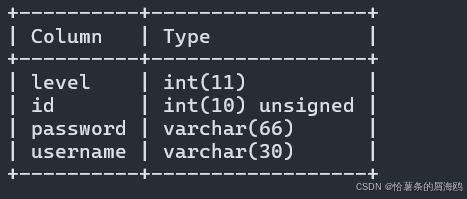
SQL注入篇-sqlmap的配置和使用
在之前的皮卡丘靶场第五期SQL注入的内容中我们谈到了sqlmap,但是由于很多朋友看不了解命令行格式,所以是纯手动获取数据库信息的 接下来我们就用sqlmap来进行皮卡丘靶场的sql注入学习,链接:https://wwhc.lanzoue.com/ifJY32ybh6vc…...