【机器学习基础】机器学习的基本术语
🚀个人主页:为梦而生~ 关注我一起学习吧!
💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~
💡往期推荐:
【机器学习基础】机器学习入门(1)
【机器学习基础】机器学习入门(2)
💡本期内容:介绍一下机器学习的一些基本术语,其实术语有很多,这里只枚举其中一些比较常用的,另外的一些等讲到相应的知识点的时候再讲。
文章目录
- 1 模型(Model)
- 2 训练数据(Training Data)
- 3 验证数据(Validation Data)
- 4 测试数据(Test Data)
- 5 输入特征(Input Feature)
- 5.1 如何选择特征
- 6 标签(Label)
- 6.1 如何区别标签和特征
- 7 参数(Parameter)
- 8 超参数(Hyperparameter)
- 9 损失函数(Loss Function)
- 10 权重(Weight)
- 11 偏置(Bias)
- 12 正则化(Regularization)
- 13 过拟合(Overfitting)和欠拟合(Underfitting)
- 14 交叉验证(Cross-validation)
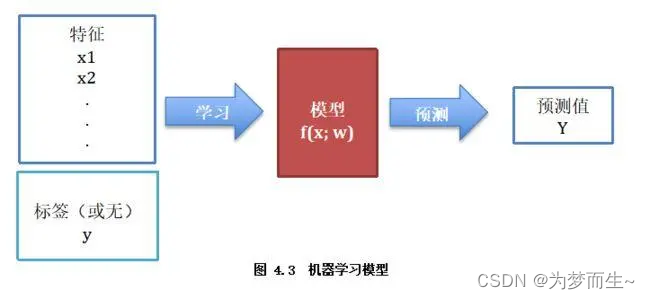
1 模型(Model)
模型是机器学习中的核心概念,它是对数据或系统的简化表示。模型可以是统计模型、神经网络、决策树等。
在机器学习中,模型是指一种数学函数,它能够将输入数据映射到预测输出。模型是机器学习算法的核心部分,通过学习训练数据来自适应地调整模型参数,以最小化预测输出与真实标签之间的误差。在机器学习中,模型可以分为线性模型和非线性模型。线性模型是最简单的模型,它可以用一条直线或超平面对数据进行划分或预测。非线性模型则可以更好地拟合复杂的数据分布情况。

总之,机器学习中的模型是用来对输入数据进行预测或分类的数学函数,不同类型的模型适用于不同类型的数据和问题。选择合适的模型并对其进行调参和优化是机器学习中非常重要的环节。
2 训练数据(Training Data)
机器学习中的训练数据是用于训练机器学习算法的初始数据集,也称为训练集或学习集。训练数据是一组用于拟合机器学习模型的参数的样本,这些样本通常经过预处理(如人工标注)并具有相对稳妥、精确的特征描述。训练数据的主要目的是帮助机器学习算法理解数据特征和模式,从而在给定输入时能够准确预测输出结果。
在机器学习中,训练数据是不可或缺的,因为机器学习算法需要使用这些数据来学习和建立模型。通过分析训练数据集并反复调整模型参数,机器学习算法可以逐渐适应和理解数据中的特征和模式,从而在预测新样本时达到更高的准确率和泛化能力。
训练数据的来源可以是多种多样的,包括历史数据、实验数据、用户行为数据等等。这些数据需要进行预处理和清洗,以确保其质量和准确性,从而为机器学习算法提供良好的训练环境。

总之,训练数据是机器学习中非常重要的组成部分,它为机器学习算法提供了学习和建立模型的初始样本集,帮助算法适应和理解数据中的特征和模式,最终达到更高的预测准确率和泛化能力。
3 验证数据(Validation Data)
机器学习中的验证数据用于验证模型的有效性和性能。通常从原始数据中划分出来,用于对模型的训练过程进行监督和调整。验证数据集可以用来评估模型的性能,如准确率、召回率、F1分数等指标,以便对模型进行优化和改进。在模型训练过程中,验证数据集还可以用来防止过拟合和欠拟合,以及调整超参数等。
与训练数据集不同,验证数据集不用于训练模型,而是用于评估模型的性能和泛化能力。因此,验证数据集的选择和划分对模型性能的评估非常重要。通常来说,验证数据集应该具有代表性,与训练数据集相似且独立。在实践中,可以通过交叉验证的方法来选择最佳的模型和超参数。

总之,机器学习中的验证数据是用于评估模型性能和泛化能力的重要数据集,可以帮助我们更好地理解和改进模型。
4 测试数据(Test Data)
机器学习中的测试数据用于评估机器学习模型的泛化能力。在机器学习中,训练数据用于训练模型,验证数据用于调整模型参数和选择最佳模型,而测试数据用于评估模型的泛化能力。
测试数据集通常是在模型训练完成后才使用的,用于评估模型在未见过的数据上的性能和泛化能力。通过使用测试数据集对模型进行评估,我们可以了解模型在实际应用中的效果和表现,以及是否会出现过拟合或欠拟合等问题。
在机器学习中,测试数据集的选择和划分同样非常重要。通常来说,测试数据集应该与训练数据集和验证数据集相似且独立,以避免数据泄露和过拟合等问题。在实践中,可以通过交叉验证的方法来选择最佳的模型和超参数。

总之,机器学习中的测试数据是用于评估模型泛化能力的重要数据集,可以帮助我们了解模型在实际应用中的性能和表现。
5 输入特征(Input Feature)
在机器学习中,输入特征指的是描述一个实例的属性或特征,也可以称为自变量或输入变量。特征是机器学习中非常重要的概念,因为它们是训练和评估机器学习模型的基础。特征可以是任何类型的数据,包括数字、文本、图像和音频等。
5.1 如何选择特征
特征选择是从原始特征中选择出一些最有效特征以降低数据集维度、提高法性能的方法。

特征选择有很多方法,比如:
- 方差阈值特征选择:具有较高方差的特征表示该特征内的值变化大,较低的方差意味着要素内的值相似,而零方差意味着您具有相同值的要素。
- 卡方检验:经典的卡方检验是检验定性自变量对定性因变量的相关性。
- 互信息法(信息增益):互信息法经典的互信息也是评价定性自变量对定性因变量的相关性的。互信息指的是两个随机变量之间的关联程度,即给定一个随机变量后,另一个随机变量不确定性的削弱程度,因而互信息取值最小为0,意味着给定一个随机变量对确定一另一个随机变量没有关系,最大取值为随机变量的熵,意味着给定一个随机变量,能完全消除另一个随机变量的不确定性。
- 过滤式变量排序:这种方法独立于后续要使用的模型,通过找到一种能度量特征重要性的方法(如Pearson相关系数、互信息等)来对变量进行排序,然后选择排序靠前的变量。但是,这种方法忽略了特征之间的相互依赖关系,可能会引入冗余特征或损失有价值的特征。
- 包裹式:这类方法的核心思想在于,给定了某种模型及预测效果评价的方法后,针对特征空间中的不同子集,计算每个子集的预测效果,效果最好的即作为最终被挑选出来的特征子集。但是,集合的子集是一个指数的量级,故此类方法计算量较大。
6 标签(Label)
在机器学习中,标签(label)是指一个实例的正确输出或类别,也可以称为目标变量(target variable)或响应变量(response variable)。通常情况下,数据集包含特征和标签两部分:特征是用于描述实例的属性或特征,而标签则是用于训练和评估机器学习模型的目标变量。
例如,在图像分类问题中,特征可能是像素值或特征描述符,标签则是图像的类别,如猫、狗或鸟等。
6.1 如何区别标签和特征
标签和特征在机器学习中有着明显的区别。特征是用于描述实例的属性或特征,而标签则是用于训练和评估机器学习模型的目标变量。
**特征是机器学习算法处理的数据,它们是用于描述数据集中每个实例的属性或特征的.**特征可以是任何类型的数据,包括数字、文本、图像和音频等。例如,在图像分类问题中,特征可能是像素值或特征描述符,在文本分类问题中,特征可能是文本中的单词或短语。
**标签是与数据集中的每个实例相关联的目标变量或类别。标签通常是在机器学习任务中需要预测或分类的结果。**例如,在垃圾邮件检测数据集中,标签可能是“垃圾邮件”或“非垃圾邮件”。在图像分类任务中,标签可能是图像的类别,如猫、狗或鸟等。
需要注意的是,特征和标签之间的关系非常密切。在机器学习任务中,特征和标签都是重要的组成部分,它们共同构成了训练和评估机器学习模型的基础。通过对特征的选择和处理,可以影响机器学习算法的性能和预测准确率。同时,标签的质量和准确性对于机器学习算法的训练和评估也是至关重要的。
7 参数(Parameter)
在机器学习中,参数通常指模型内部的可调整变量,它们决定了模型的行为和性能。这些参数可以通过学习算法进行训练和优化,以使模型能够更好地适应数据和任务。
参数可以是任何可以调整的变量,例如线性回归中的权重和偏差,神经网络中的权重和偏置等。这些参数的作用是拟合数据,使模型能够根据输入数据预测输出结果。
在训练机器学习模型时,通常需要使用训练数据集来训练模型并优化参数。训练过程可以通过梯度下降、随机梯度下降(SGD)、牛顿法等优化算法来实现。这些算法会根据损失函数(或目标函数)来评估模型的性能,并不断调整参数以最小化损失函数,从而提高模型的预测性能。
总之,机器学习中的参数是指模型内部的可调整变量,通过优化参数可以提高模型的性能和泛化能力,使模型能够更好地适应数据和任务。
8 超参数(Hyperparameter)
在机器学习中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。这些参数不能直接从数据中学习,而是通过经验和试验来选择。超参数可以对模型的性能和训练过程产生重要影响,不同的超参数值可能导致不同的模型性能。因此,需要通过尝试不同的超参数组合来找到最佳的配置。这通常需要进行交叉验证或使用其他技术来评估不同超参数组合的性能。
- 常见的超参数包括学习率、正则化参数、批量大小、迭代次数、隐藏层的数量和大小、卷积神经网络中的滤波器大小和数量等。
- 超参数可以分为以下几类:
网络参数:包括网络层与层之间的交互方式(相加、相乘或者串接等)、卷积核数量和卷积核尺寸、网络层数(也称深度)和激活函数等。
优化参数:一般指学习率(learning rate)、批样本数量(batch size)、不同优化器的参数以及部分损失函数的可调参数。
正则化参数:包括权重衰减系数,丢弃法比率(dropout)等。
此外,学习率、批量大小、迭代次数、隐藏层的数量和大小、卷积神经网络中的滤波器大小和数量等也是常见的超参数。
9 损失函数(Loss Function)
在机器学习中,损失函数(loss function)是用来估量模型预测值与真实值之间不一致程度的非负实值函数。它通常被用来衡量模型的预测性能,损失函数越小,模型的鲁棒性就越好。
损失函数的选择对于机器学习算法的性能和准确性有着重要影响。不同的损失函数适用于不同的机器学习任务和算法,例如交叉熵损失函数适用于分类问题,均方误差损失函数适用于回归问题。
在训练机器学习模型时,损失函数提供了一个目标和标准,通过最小化损失函数可以使得模型预测结果与真实结果之间的差距最小化。因此,损失函数在模型训练过程中起着至关重要的作用。

- 除了均方误差损失函数和交叉熵损失函数之外,还有许多其他的损失函数可供选择,例如:
铰链损失(Hinge Loss):主要用于支持向量机(SVM)中。
互熵损失(Cross Entropy Loss,Softmax Loss):用于Logistic回归与Softmax分类中。
平方损失(Square Loss):主要是最小二乘法(OLS)中。
指数损失(Exponential Loss):主要用于Adaboost集成学习算法中。
其他损失(如0-1损失,绝对值损失)。
这些损失函数各有其特点和适用范围,选择合适的损失函数能够提高模型的性能和准确性。
10 权重(Weight)
在机器学习中,权重通常指给定一组数据项,为其中每一项分配一个数值,用以衡量在某种计算过程中它们的重要性。这些权重可以是实数,可以是正数、负数或零,它表示变量的重要性。
权重的运用可以让某个元素在某个结果中获得更大的影响力,从而达到期望的结果。例如,在搜索引擎中,搜索关键词的权重可以控制它们在搜索结果中的排名,从而提高搜索结果的准确性。
在机器学习的不同领域和应用中,权重的具体含义可能会有所不同。
- 在搜索引擎中,权重被广泛应用于排名算法中。搜索引擎会根据网站的权重、内容质量、链接质量等因素来决定网站的排名。权重高的网站在搜索结果中的排名更靠前,从而能够获得更多的流量和曝光。
- 在金融投资中,权重被广泛应用于投资组合的构建和管理。投资者可以根据不同的因素如市场表现、资产质量等来决定投资组合中每个资产的权重。通过调整资产的权重,投资者可以优化投资组合,最大化投资回报。
- 在机器翻译中,权重可以用于衡量不同翻译结果的重要性。在多个翻译结果中,权重高的翻译结果会被认为更可靠,从而被优先采用。
- 在图像处理中,权重可以用于衡量不同像素的重要性。在图像识别或分类中,权重高的像素对最终结果的影响更大。
- 在自然语言处理中,权重可以用于衡量不同单词或特征的重要性。在文本分类或情感分析中,权重高的单词或特征会被认为更能代表文本的主题或情感。
这些例子只是权重运用的一部分,实际上,权重的运用非常广泛,可以适用于各种不同的领域和应用。
11 偏置(Bias)
在机器学习中,偏执(bias)通常指对模型的偏好。换句话说,它表示在训练数据上对模型预测结果的一种倾向或偏见。

具体来说,当我们在训练机器学习模型时,我们通常会尝试使模型尽可能地适应训练数据。然而,如果模型过于复杂或过于灵活,它可能会对训练数据产生过拟合,导致模型在遇到新的、未见过的数据时表现不佳。
为了解决这个问题,我们通常会引入一种称为“正则化”的技术,以减少模型的复杂性和避免过拟合。正则化的一种方法是L1和L2正则化,它们通过在模型的损失函数中添加一项,惩罚那些系数绝对值大的特征,从而减少模型的复杂性。
然而,这也会导致一个问题,即模型可能会忽略某些特征或更偏向于使用其他特征进行预测。这种现象被称为偏执(bias)。
因此,在机器学习中,偏执一词的含义是模型对某些特征或假设的偏好。如果模型过于简单或过于复杂,或者如果我们没有正确地选择特征或调整模型参数,那么模型可能会表现出偏执。
为了减少偏执,我们需要仔细地选择特征、调整模型参数,并使用交叉验证等技术来评估模型的性能。
12 正则化(Regularization)
正则化(regularization)是指在机器学习和统计学中,对模型进行约束或加权,以改善模型性能和防止过拟合的技术。正则化可以通过对模型参数进行惩罚或约束,以增加模型的平滑性、缩小模型的规模或限制模型的复杂性,从而提高模型的泛化能力。
正则化方法有多种,包括L1正则化、L2正则化、L1/L2混合正则化、弹性网正则化等。这些方法通过在损失函数中添加惩罚项,对模型参数进行约束或加权,从而改善模型的性能。
-
L1正则化,也称为Lasso回归,它通过惩罚项来控制模型的复杂度,使模型中的某些系数变为0,从而进行特征选择。
-
L2正则化,也称为岭回归,它通过惩罚项来控制模型的复杂度,使模型中的系数变小,从而避免过拟合问题。
-
L1/L2混合正则化,将L1正则化和L2正则化结合,既可以进行特征选择,又可以避免过拟合问题。
-
弹性网正则化,将L1正则化和L2正则化结合,但惩罚项的系数不同,可以更好地控制模型的复杂度。
以上正则化方法在机器学习领域都有广泛的应用,可以根据不同的需求和场景选择合适的正则化方法。
正则化在机器学习领域的应用广泛,如线性回归、逻辑回归、支持向量机(SVM)等算法中都有应用。正则化可以有效地防止过拟合,提高模型的泛化能力,从而在实际应用中获得更好的性能表现。
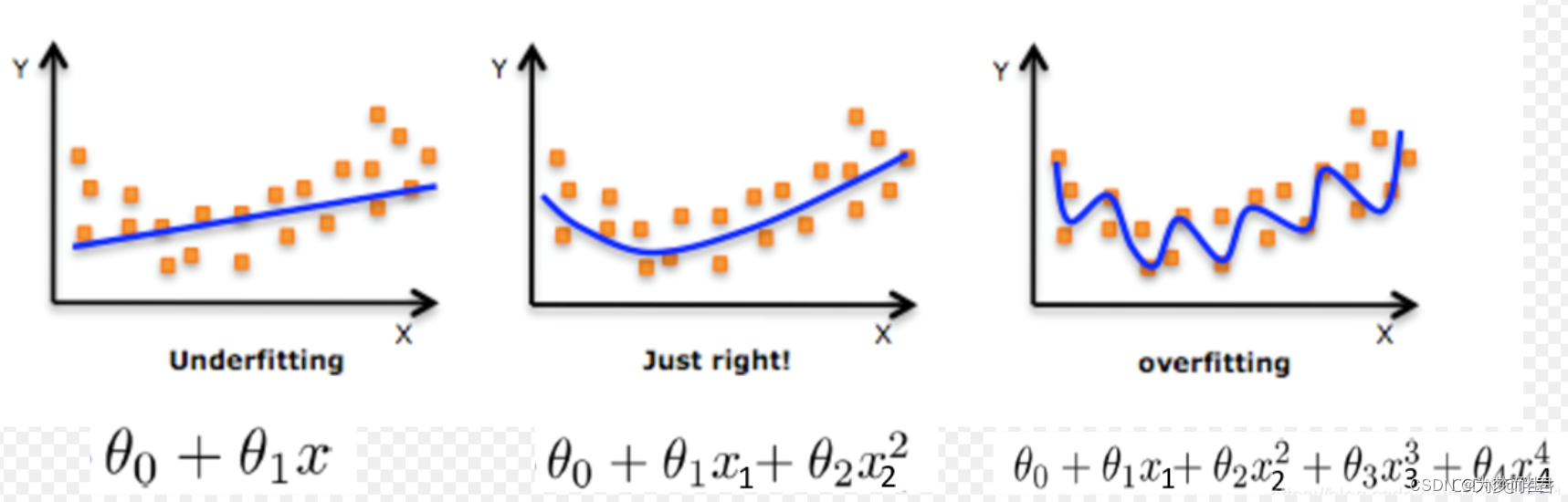
13 过拟合(Overfitting)和欠拟合(Underfitting)
在机器学习中,过拟合(overfitting)是指模型在训练集上表现很好,但在测试集上表现差,即模型对未知样本的预测能力弱。
具体来说,过拟合是指当模型过于复杂时,它会记住训练数据中的噪声和异常值,而不仅仅是学习真实的输入输出关系。这样会导致模型在新数据上泛化能力弱,因为新数据可能包含与训练数据不同的特征或噪声。
过拟合的原因可能是训练数据集过于单一、训练数据中的噪声干扰过大、过度追求与训练集样本的一致性,以及对噪声造成的影响也进行了拟合。为了减少过拟合,可以采取以下方法:
- 增加训练数据集的数量和多样性,以使模型能够更好地学习输入输出之间的关系。
- 在模型训练中加入正则化项,如L1正则化、L2正则化等,以减少模型的复杂度并避免过拟合。
- 采用集成学习方法,如bagging和boosting,将多个模型的预测结果结合起来,以提高模型的泛化能力。
- 调整模型复杂度,如增加或减少模型中的参数数量或调整模型的层数和神经元数量等。
- 在模型训练过程中使用交叉验证技术,以评估模型在测试集上的性能并防止过拟合。
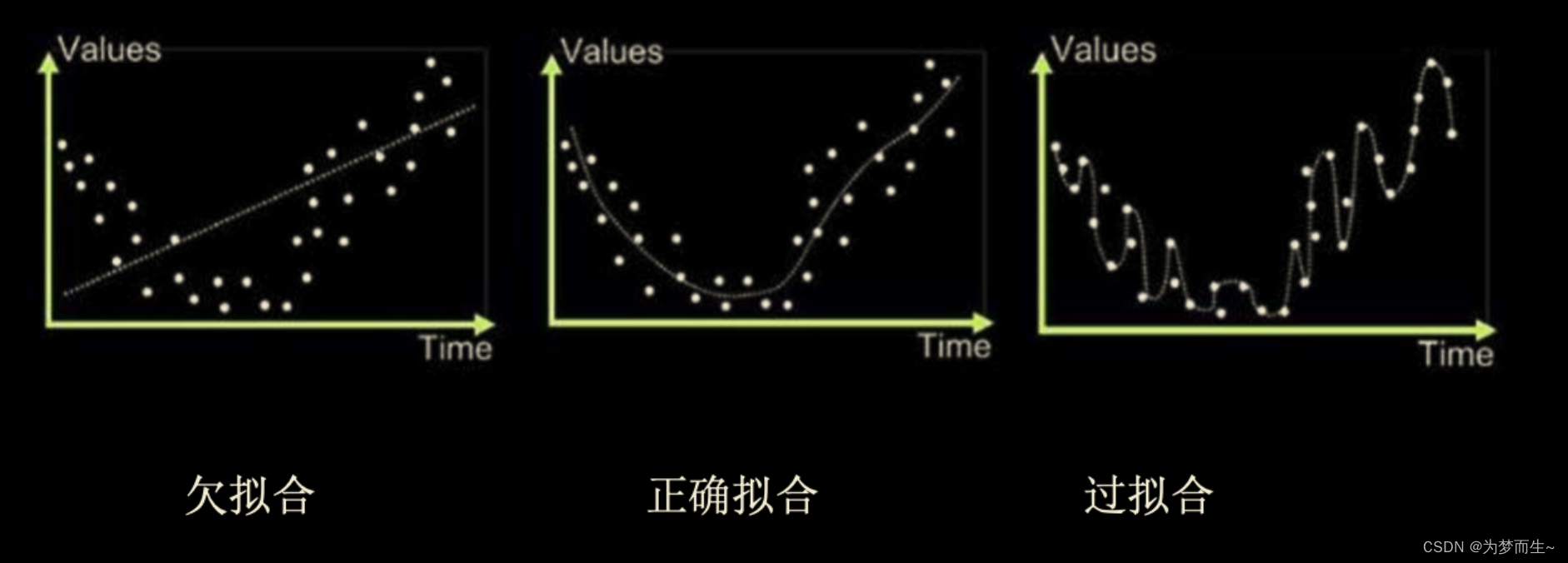
欠拟合(underfitting)是指模型在训练集和测试集上表现都较差,即模型不能很好地学习和预测数据的特征和规律。
欠拟合的原因可能是模型过于简单,无法捕捉到数据中的复杂特征和模式。
例如,如果使用线性回归模型去拟合一个非线性的数据集,就可能会出现欠拟合现象。另外,如果训练数据集的数量不足或者质量不高,也会导致欠拟合。
为了解决欠拟合问题,可以采取以下方法:
- 增加特征数量或者选择更复杂的特征,以使模型能够更好地捕捉到数据中的模式。
- 增加训练数据集的数量和质量,以增强模型的泛化能力。
- 调整模型的复杂度,例如增加模型的层数或神经元数量,以使模型能够更好地适应数据的特征和规律。
- 在模型训练中加入正则化项,以减少模型的复杂度并避免过拟合。
- 采用集成学习方法,将多个模型的预测结果结合起来,以提高模型的泛化能力和性能表现。
14 交叉验证(Cross-validation)
交叉验证(cross-validation)是机器学习中常用的数据处理方法,它通过将原始数据集分成多个子集,对每个子集进行独立的分析和验证,以评估模型的泛化能力和性能表现。
交叉验证的主要目的是为了防止模型过拟合和欠拟合。通过将数据集分成多个子集,并对每个子集进行独立的分析和验证,可以更好地评估模型的泛化能力和性能表现,从而避免过拟合和欠拟合问题。同时,交叉验证还可以用于评估不同模型或参数的优劣,以选择最优的模型或参数组合。
需要注意的是,在进行交叉验证时,需要确保每个子集的样本数量足够多,且均匀抽样,以避免出现数据倾斜或信息泄露等问题。同时,还需要根据具体问题和数据集的特点选择合适的交叉验证方法,以获得更准确和可靠的评估结果。

交叉验证主要分为以下四种类型:
- 留出法(Leave-out cross-validation):将原始数据集分为训练集和测试集,其中训练集用于模型训练,测试集用于模型验证。
- 留一法(Leave-one-out cross-validation):将原始数据集中的每个样本依次作为测试集,其余样本作为训练集,进行多次验证。
- k-fold交叉验证(k-fold cross-validation):将原始数据集分成k个子集,每个子集均做一次测试集,其余的作为训练集。
- 嵌套交叉验证(Nested cross-validation):在k-fold交叉验证的基础上,对每个子集再进行一次k-fold交叉验证,用于评估模型的估计误差和泛化能力。
以上就是交叉验证的主要类型,每种类型都有其特点和应用场景,需要根据具体情况选择合适的交叉验证方法。
相关文章:
【机器学习基础】机器学习的基本术语
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~ 💡往期推荐: 【机器学习基础】机器学习入门(1) 【机器学习基…...

区别Vue 2.0 和 Vue 3.0
Vue 3.0 是在 Vue 2.0 的基础上进行了重大的更新和改进。下面列举了一些主要的区别: 性能优化 Proxy 取代 Object.defineProperty:Vue 3.0 中使用 Proxy 监听数据的变化,相比 Vue 2.0 使用 Object.defineProperty,性能有所提升。…...

react antd下拉选择框选项内容换行
下拉框选项字太多,默认样式是超出就省略号,需求要换行全展示,选完在选择框里还是要省略的 .less: .aaaDropdown {:global {.ant-select-dropdown-menu-item {white-space: pre-line !important;word-break: break-all !important;}} } html…...

图像分类(一) 全面解读复现AlexNet
解读 论文原文:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf Abstract-摘要 翻译 我们训练了一个庞大的深层卷积神经网络,将ImageNet LSVRC-2010比赛中的120万张高分辨率图像分为1000个不…...

JAXB实现XML和Bean相互转换
目录 XML和Bean转换工具简介JAXB简介Java Bean类XMLUtil工具类 另一篇转换方式 xstream实现xml和java bean 互相转换 XML和Bean转换工具简介 Java中实现XML和Bean的转换的方式或插件有以下几种: JAXB(Java Architecture for XML Binding)&…...

视频剪辑技巧:简单步骤,批量剪辑并随机分割视频
随着社交媒体平台的广泛普及和视频制作需求的急剧增加,视频剪辑已经成为了当今社会一项不可或缺的技能。然而,对于许多初学者来说,视频剪辑可能是一项令人望而生畏的复杂任务。可能会面临各种困难,如如何选择合适的软件和硬件、如…...

Vue3-shallowRef 和 shallowReactive函数(浅层次的响应式)
Vue3-shallowRef 和 shallowReactive函数(浅层次的响应式) shallowRef函数 功能:只给基本数据类型添加响应式。如果是对象,则不会支持响应式,层成也不会创建Proxy对象。ref和shallowRef在基本数据类型上是没有区别的…...

ExoPlayer架构详解与源码分析(8)——Loader
系列文章目录 ExoPlayer架构详解与源码分析(1)——前言 ExoPlayer架构详解与源码分析(2)——Player ExoPlayer架构详解与源码分析(3)——Timeline ExoPlayer架构详解与源码分析(4)—…...

ExoPlayer架构详解与源码分析(9)——TsExtractor
系列文章目录 ExoPlayer架构详解与源码分析(1)——前言 ExoPlayer架构详解与源码分析(2)——Player ExoPlayer架构详解与源码分析(3)——Timeline ExoPlayer架构详解与源码分析(4)—…...

【Python 千题 —— 基础篇】输出列表方差
题目描述 题目描述 输出列表的方差。题中有一个包含数字的列表 [10, 39, 13, 48, 32, 10, 9],使用 for 循环获得这个列表中所有项的方差。 输入描述 无输入。 输出描述 输出列表的方差。 示例 示例 ① 输出: 列表的方差是:228.0代码…...

【Spring总结】基于配置的方式来写Spring
本篇文章是对这两天所学的内容做一个总结,涵盖我这两天写的所有笔记: 【Spring】 Spring中的IoC(控制反转)【Spring】Spring中的DI(依赖注入)Dependence Import【Spring】bean的基础配置【Spring】bean的实…...
Unity在Windows选项下没有Auto Streaming
Unity在Windows选项下没有Auto Streaming Unity Auto Streaming插件按网上说的不太好使最终解决方案 Unity Auto Streaming插件 我用的版本是个人版免费版,版本号是:2021.2.5f1c1,我的里边Windows下看不到Auto Streaming选项,就像下边这张图…...

下厨房网站月度最佳栏目菜谱数据获取及分析
目录 概要 源数据获取 写Python代码爬取数据 Scala介绍与数据处理 1.Sacla介绍...

【Java 进阶篇】深入理解 JQuery 事件绑定:标准方式
在前端开发中,处理用户与页面的交互是至关重要的一部分。JQuery作为一个广泛应用的JavaScript库,为我们提供了简便而强大的事件绑定机制,使得我们能够更加灵活地响应用户的行为。本篇博客将深入解析 JQuery 的标准事件绑定方式,为…...

某app c++层3处魔改md5详解
hello everybody,本期是安卓逆向so层魔改md5教学,干货满满,可以细细品味,重点介绍的是so层魔改md5的处理. 常见的魔改md5有: 1:明文加密前处理 2:改初始化魔数 3:改k表中的值 4:改循环左移的次数 本期遇到的是124.且循环左移的次数是动态的,需要前面的加密结果处理生成 目录…...

安装MongoDB
查看MongoDB版本可以执行如下命令 mongod --version 如果是Ubuntu,则直接安装 sudo apt-get install -y mongodb如果是其他,比如Amazon Linux2。 查看Linux系统发行版类型 grep ^NAME /etc/*release 如果是 Amazon Linux 2,则创建一个r…...
C++加持让python程序插上翅膀——利用pybind11进行c++和python联合编程示例
目录 0、前言1、安装 pybind11库c侧python侧 2、C引入bybind11vs增加相关依赖及设置cpp中添加头文件及导出模块cpp中添加numpy相关数据结构的接收和返回编译生成dll后改成导出模块同名文件的.pyd 3、python调用c4、C引入bybind11 0、前言 在当今的计算机视觉和机器学习领域&am…...
ubuntu20.04安装cv2
查看ubuntu的版本 cat /etc/lsb-release DISTRIB_IDUbuntu DISTRIB_RELEASE20.04 DISTRIB_CODENAMEfocal DISTRIB_DESCRIPTION"Ubuntu 20.04.3 LTS"更改镜像源 cp /etc/apt/sources.list /etc/apt/sources.list.bak cat > /etc/apt/sources.listdeb http://mirr…...

Android 13.0 recovery出厂时清理中字体大小的修改
1.前言 在13.0的系统rom定制化开发中,在recovery模块也是系统中比较重要的模块,比如恢复出厂设置,recovery ota升级, 清理缓存等等,在一些1080p的设备,但是density只是240这样的设备,会在恢复出厂设置的时候,显示的字体有点小, 产品要求需要将正在清理的字体调大点,这…...

spring+pom-注意多重依赖时的兼容问题[java.lang.NoSuchMethodError]
背景: 项目中同时引入了依赖A和依赖B,而这两个依赖都依赖于项目C,但它们指定的C版本不一致,导致运行时出现了错误。 报错如: java.lang.NoSuchMethodError 解决方案: 需要在项目pom文件中引入依赖C并指定需…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

自制射频功率计:基于AD8317芯片,成本43欧元实现1MHz-10GHz测量
1. 项目概述:为什么我要亲手打造一台射频功率计在无人机和模型飞行器的圈子里,尤其是在我们荷兰FMS Spaarnwoude俱乐部,合规飞行是头等大事。我给我的八轴飞行器加装了云台相机和图传系统,工作在5.8GHz频段。根据本地法规…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

三步破解百度网盘限速:免费获取真实下载链接的终极指南
三步破解百度网盘限速:免费获取真实下载链接的终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的龟速下载而苦恼吗?想要彻…...