六、并发集合
文章目录
- 并发集合
- ConcurrentHashMap
- 存储结构
- 存储操作
- put方法
- putVal方法-散列算法
- putVal方法-添加数据到数组&初始化数组
- putVal方法-添加数据到链表
- 扩容操作
- treeifyBin方法触发扩容
- tryPreSize方法-针对putAll的初始化操作
- tryPreSize方法-计算扩容戳并且查看BUG
- tryPreSize方法-对sizeCtl的修改以及条件判断的BUG
- transfer方法-计算每个线程迁移的长度
- transfer方法-构建新数组并查看标识属性
- transfer方法-线程领取迁移任务
- transfer方法-迁移结束操作
- transfer方法-迁移数据(链表)
- helpTransfer方法-协助扩容
- 红黑树操作
- 什么是红黑树
- TreeifyBin方法-封装TreeNode和双向链表
- TreeBin有参构造-双向链表转为红黑树
- balanceInsertion方法-保证红黑树平衡以及特性
- putTreeVal方法-添加节点
- TreeBin的锁操作
- transfer迁移数据
- 查询数据
- get方法-查询数据的入口
- ForwardingNode的find方法
- ReservationNode的find方法
- TreeBin的find方法
- TreeNode的findTreeNode方法
- ConcurrentHashMap其他方法
- compute方法
- compute方法源码分析
- computeIfPresent、computeIfAbsent、compute区别
- replace方法详解
- merge方法详解
- ConcurrentHashMap计数器
- addCount方法分析
- size方法方法分析
- CopyOnWriteArrayList
- CopyOnWriteArrayList介绍
- 核心属性&方法
- 读操作
- 写操作
- 移除数据
- 覆盖数据&清空集合
- 迭代器
并发集合
ConcurrentHashMap
存储结构
ConcurrentHashMap是线程安全的HashMap
ConcurrentHashMap在JDK1.8中是以CAS+synchronized实现的线程安全
CAS:在没有hash冲突时(Node要放在数组上时)
synchronized:在出现hash冲突时(Node存放的位置已经有数据了)
存储的结构:数组+链表+红黑树

存储操作
put方法
public V put(K key, V value) {// 在调用put方法时,会调用putVal,第三个参数默认传递为false// 在调用putIfAbsent时,会调用putVal方法,第三个参数传递的为true// 如果传递为false,代表key一致时,直接覆盖数据// 如果传递为true,代表key一致时,什么都不做,key不存在,正常添加(Redis,setnx)return putVal(key, value, false);
}
putVal方法-散列算法
final V putVal(K key, V value, boolean onlyIfAbsent) {// ConcurrentHashMap不允许key或者value出现为null的值,跟HashMap的区别if (key == null || value == null) throw new NullPointerException();// 根据key的hashCode计算出一个hash值,后期得出当前key-value要存储在哪个数组索引位置int hash = spread(key.hashCode());// 一个标识,在后面有用int binCount = 0;// 省略大量的代码......
}// 计算当前Node的hash值的方法
static final int spread(int h) {// 将key的hashCode值的高低16位进行^运算,最终又与HASH_BITS进行了&运算// 将高位的hash也参与到计算索引位置的运算当中// 为什么HashMap、ConcurrentHashMap,都要求数组长度为2^n// HASH_BITS让hash值的最高位符号位肯定为0,代表当前hash值默认情况下一定是正数,因为hash值为负数时,有特殊的 // static final int MOVED = -1; // 代表当前hash位置的数据正在扩容!// static final int TREEBIN = -2; // 代表当前hash位置下挂载的是一个红黑树// static final int RESERVED = -3; // 预留当前索引位置......return (h ^ (h >>> 16)) & HASH_BITS;// 计算数组放到哪个索引位置的方法 (f = tabAt(tab, i = (n - 1) & hash)// n:是数组的长度
}/*00001101 00001101 00101111 10001111 - h = key.hashCode运算方式00000000 00000000 00000000 00001111 - 15 (n - 1) &((00001101 00001101 00101111 10001111 - h^00000000 00000000 00001101 00001101 - h >>> 16)&01111111 11111111 11111111 11111111 - HASH_BITS )*/
putVal方法-添加数据到数组&初始化数组
final V putVal(K key, V value, boolean onlyIfAbsent) {// 省略部分代码............// 将Map的数组赋值给tab,死循环for (Node<K,V>[] tab = table;;) {// 声明了一堆变量~~// n:数组长度// i:当前Node需要存放的索引位置// f: 当前数组i索引位置的Node对象// fn:当前数组i索引位置上数据的hash值Node<K,V> f; int n, i, fh;// 判断当前数组是否还没有初始化if (tab == null || (n = tab.length) == 0)// 将数组进行初始化。tab = initTable();// 基于 (n - 1) & hash 计算出当前Node需要存放在哪个索引位置// 基于tabAt获取到i位置的数据else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 现在数组的i位置上没有数据,基于CAS的方式将数据存在i位置上if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))// 如果成功,执行break跳出循环,插入数据成功break; // no lock when adding to empty bin}// 判断当前位置数据是否正在扩容......else if ((fh = f.hash) == MOVED)// 让当前插入数据的线程协助扩容tab = helpTransfer(tab, f);// 省略部分代码............}// 省略部分代码............
}/*
sizeCtl:是数组在初始化和扩容操作时的一个控制变量
-1:代表当前数组正在初始化
小于-1:低16位代表当前数组正在扩容的线程个数(如果1个线程扩容,值为-2,如果2个线程扩容,值为-3)
0:代表数组还没初始化
大于0:代表当前数组的扩容阈值,或者是当前数组的初始化大小
*/
// 初始化数组方法
private final Node<K,V>[] initTable() {// 声明标识Node<K,V>[] tab; int sc;// 再次判断数组没有初始化,并且完成tab的赋值while ((tab = table) == null || tab.length == 0) {// 将sizeCtl赋值给sc变量,并判断是否小于0if ((sc = sizeCtl) < 0)Thread.yield(); // lost initialization race; just spin// 可以尝试初始化数组,线程会以CAS的方式,将sizeCtl修改为-1,代表当前线程可以初始化数组else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {// 尝试初始化!try {// 再次判断当前数组是否已经初始化完毕。if ((tab = table) == null || tab.length == 0) {// 开始初始化,// 如果sizeCtl > 0,就初始化sizeCtl长度的数组// 如果sizeCtl == 0,就初始化默认的长度int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")// 初始化数组!Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];// 将初始化的数组nt,赋值给tab和tabletable = tab = nt;// sc赋值为了数组长度 - 数组长度 右移 2位// 将sc赋值为下次扩容的阈值sc = n - (n >>> 2);}} finally {// 将赋值好的sc,设置给sizeCtlsizeCtl = sc;}break;}}return tab;
}
putVal方法-添加数据到链表
final V putVal(K key, V value, boolean onlyIfAbsent) {// 省略部分代码............int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// n:数组长度// i:当前Node需要存放的索引位置// f: 当前数组i索引位置的Node对象// fn:当前数组i索引位置上数据的hash值 // 省略部分代码............else {// 声明变量为oldValV oldVal = null;// 基于当前索引位置的Node,作为锁对象......synchronized (f) {// 判断当前位置的数据还是之前的f么......(避免并发操作的安全问题)if (tabAt(tab, i) == f) {// 再次判断hash值是否大于0(不是树)if (fh >= 0) {// binCount设置为1(在链表情况下,记录链表长度的一个标识)binCount = 1;// 死循环,每循环一次,对binCountfor (Node<K,V> e = f;; ++binCount) {// 声明标识ekK ek;// 当前i索引位置的数据,是否和当前put的key的hash值一致if (e.hash == hash &&// 如果当前i索引位置数据的key和put的key == 返回为true // 或者equals相等((ek = e.key) == key ||(ek != null && key.equals(ek)))) {// key一致,可能需要覆盖数据!// 当前i索引位置数据的value复制给oldValoldVal = e.val;// 如果传入的是false,代表key一致,覆盖value// 如果传入的是true,代表key一致,什么都不做!if (!onlyIfAbsent)// 覆盖valuee.val = value;break;}// 拿到当前指定的Node对象Node<K,V> pred = e;// 将e指向下一个Node对象,如果next指向的是一个null,可以挂在当前Node下面if ((e = e.next) == null) {// 将hash,key,value封装为Node对象,挂在pred的next上pred.next = new Node<K,V>(hash, key,value, null);break;}}}// 省略部分代码............}}// binCount长度不为0if (binCount != 0) {// binCount是否大于8(链表长度是否 >= 8)if (binCount >= TREEIFY_THRESHOLD)// 尝试转为红黑树或者扩容// 基于treeifyBin方法和上面的if判断,可以得知链表想要转为红黑树,必须保证数组长度大于等于64,并且链表长 // 如果数组长度没有达到64的话,会首先将数组扩容treeifyBin(tab, i);// 如果出现了数据覆盖的情况,if (oldVal != null)// 返回之前的值return oldVal;break;}}}// 省略部分代码............
}// 为什么链表长度为8转换为红黑树,不是能其他数值嘛?
// 因为布松分布
/*
The main disadvantage of per-bin locks is that other update
* operations on other nodes in a bin list protected by the same
* lock can stall, for example when user equals() or mapping
* functions take a long time. However, statistically, under
* random hash codes, this is not a common problem. Ideally, the * frequency of nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average, given the resizing threshold
* of 0.75, although with a large variance because of resizing
* granularity. Ignoring variance, the expected occurrences of
* list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The
* first values are: *
* 0:
* 1:
* 2:
* 3:
* 4:
* 5:
* 6:
* 7:
* 8:
* more: less than 1 in ten million
*/
扩容操作
treeifyBin方法触发扩容
// 在链表长度大于等于8时,尝试将链表转为红黑树
private final void treeifyBin(Node<K,V>[] tab, int index) {Node<K,V> b; int n, sc;// 数组不能为空if (tab != null) {// 数组的长度n,是否小于64if ((n = tab.length) < MIN_TREEIFY_CAPACITY)// 如果数组长度小于64,不能将链表转为红黑树,先尝试扩容操作tryPresize(n << 1);// 省略部分代码......}
}
tryPreSize方法-针对putAll的初始化操作
// size是将之前的数组长度 左移 1位得到的结果
private final void tryPresize(int size) {// 如果扩容的长度达到了最大值,就使用最大值// 否则需要保证数组的长度为2的n次幂// 这块的操作,是为了初始化操作准备的,因为调用putAll方法时,也会触发tryPresize方法// 如果刚刚new的ConcurrentHashMap直接调用了putAll方法的话,会通过tryPresize方法进行初始化int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :tableSizeFor(size + (size >>> 1) + 1);// 这些代码和initTable一模一样// 声明scint sc;// 将sizeCtl的值赋值给sc,并判断是否大于0,这里代表没有初始化操作,也没有扩容操作while ((sc = sizeCtl) >= 0) {// 将ConcurrentHashMap的table赋值给tab,并声明数组长度nNode<K,V>[] tab = table; int n;// 数组是否需要初始化if (tab == null || (n = tab.length) == 0) {// 进来执行初始化// sc是初始化长度,初始化长度如果比计算出来的c要大的话,直接使用sc,如果没有sc大,// 说明sc无法容纳下putAll中传入的map,使用更大的数组长度n = (sc > c) ? sc : c;// 设置sizeCtl为-1,代表初始化操作if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {// 再次判断数组的引用有没有变化if (table == tab) {// 初始化数组@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];// 数组赋值table = nt;// 计算扩容阈值sc = n - (n >>> 2);}} finally {// 最终赋值给sizeCtlsizeCtl = sc;}}}else if (c <= sc || n >= MAXIMUM_CAPACITY)break;// 省略部分代码}
}// 将c这个长度设置到最近的2的n次幂的值,15-16,17-32
// c == size + (size >>> 1) + 1
// size = 17/*00000000 00000000 00000000 00010001 +00000000 00000000 00000000 00001000 +00000000 00000000 00000000 00000001// c=2600000000 00000000 00000000 00011010
*/private static final int tableSizeFor(int c) {// 00000000 00000000 00000000 00011001 int n = c - 1;// 00000000 00000000 00000000 00011001 // 00000000 00000000 00000000 00001100 // 00000000 00000000 00000000 00011101 n |= n >>> 1;// 00000000 00000000 00000000 00011101 // 00000000 00000000 00000000 00000111 // 00000000 00000000 00000000 00011111 n |= n >>> 2;// 00000000 00000000 00000000 00011111 // 00000000 00000000 00000000 00000001 // 00000000 00000000 00000000 00011111 n |= n >>> 4;// 00000000 00000000 00000000 00011111 // 00000000 00000000 00000000 00000000 // 00000000 00000000 00000000 00011111 n |= n >>> 8;// 00000000 00000000 00000000 00011111n |= n >>> 16;// 00000000 00000000 00000000 00100000return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
tryPreSize方法-计算扩容戳并且查看BUG
private final void tryPresize(int size) {// n:数组长度while ((sc = sizeCtl) >= 0) {// 判断当前的tab是否和table一致,else if (tab == table) {// 计算扩容表示戳,根据当前数组的长度计算一个16位的扩容戳// 第一个作用是为了保证后面的sizeCtl赋值时,保证sizeCtl为小于-1的负数 // 第二个作用用来记录当前是从什么长度开始扩容的int rs = resizeStamp(n);// BUG --- sc < 0,永远进不去~// 如果sc小于0,代表有线程正在扩容。if (sc < 0) {// 省略部分代码......协助扩容的代码(进不来~~~~)}// 代表没有线程正在扩容,我是第一个扩容的。else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))// 省略部分代码......第一个扩容的线程......}}
}// 计算扩容表示戳
// 32 = 00000000 00000000 00000000 00100000
// Integer.numberOfLeadingZeros(32) = 26
// 1 << (RESIZE_STAMP_BITS - 1)
// 00000000 00000000 10000000 00000000
// 00000000 00000000 00000000 00011010
// 00000000 00000000 10000000 00011010
static final int resizeStamp(int n) {return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
tryPreSize方法-对sizeCtl的修改以及条件判断的BUG
private final void tryPresize(int size) {// sc默认为sizeCtlwhile ((sc = sizeCtl) >= 0) {// rs:扩容戳 00000000 00000000 10000000 00011010else if (tab == table) {int rs = resizeStamp(n);if (sc < 0) {// 说明有线程正在扩容,过来帮助扩容Node<K,V>[] nt;// 依然有BUG// 当前线程扩容时,老数组长度是否和我当前线程扩容时的老数组长度一致 // 00000000 00000000 10000000 00011010if ((sc >>> RESIZE_STAMP_SHIFT) != rs // 10000000 00011010 00000000 00000010// 00000000 00000000 10000000 00011010// 这两个判断都是有问题的,核心问题就应该先将rs左移16位,再追加当前值。 // 这两个判断是BUG// 判断当前扩容是否已经即将结束|| sc == rs + 1 // sc == rs << 16 + 1 BUG|| sc == rs + MAX_RESIZERS // sc == rs << 16 + MAX_RESIZERS BUG// 扩容已经结束了。|| (nt = nextTable) == null // 记录迁移的索引位置,从高位往低位迁移,也代表扩容即将结束。|| transferIndex <= 0)break;// 如果线程需要协助扩容,首先就是对sizeCtl进行+1操作,代表当前要进来一个线程协助扩容if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))// 上面的判断没进去的话,nt就代表新数组transfer(tab, nt);}// 是第一个来扩容的线程// 基于CAS将sizeCtl修改为 10000000 00011010 00000000 00000010// 将扩容戳左移16位之后,符号位是1,就代码这个值为负数// 低16位在表示当前正在扩容的线程有多少个,// 为什么低位值为2时,代表有一个线程正在扩容// 每一个线程扩容完毕后,会对低16位进行-1操作,当最后一个线程扩容完毕后,减1的结果还是-1,// 当值为-1时,要对老数组进行一波扫描,查看是否有遗漏的数据没有迁移到新数组else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))// 调用transfer方法,并且将第二个参数设置为null,就代表是第一次来扩容!transfer(tab, null);}}
}
transfer方法-计算每个线程迁移的长度
// 开始扩容 tab=oldTable
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// n = 数组长度// stride = 每个线程一次性迁移多少数据到新数组int n = tab.length, stride;// 基于CPU的内核数量来计算,每个线程一次性迁移多少长度的数据最合理// NCPU = 4// 举个栗子:数组长度为1024 - 512 - 256 - 128 / 4 = 32// MIN_TRANSFER_STRIDE = 16,为每个线程迁移数据的最小长度if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide range// 根据CPU计算每个线程一次迁移多长的数据到新数组,如果结果大于16,使用计算结果。 如果结果小于16,就使用最小长
}
transfer方法-构建新数组并查看标识属性
// 以32长度数组扩容到64位例子
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// n = 老数组长度 32// stride = 步长 16// 第一个进来扩容的线程需要把新数组构建出来if (nextTab == null) { // initiatingtry {// 将原数组长度左移一位,构建新数组长度@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];// 赋值操作nextTab = nt;} catch (Throwable ex) { // try to cope with OOME// 到这说明已经达到数组长度的最大取值范围sizeCtl = Integer.MAX_VALUE;// 设置sizeCtl后直接结束return;}// 将成员变量的新数组赋值nextTable = nextTab;// 迁移数据时,用到的标识,默认值为老数组长度transferIndex = n; //32}// 新数组长度int nextn = nextTab.length;// 在老数组迁移完数据后,做的标识ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// 迁移数据时,需要用到的标识boolean advance = true;boolean finishing = false; // to ensure sweep before committing nextTab// 省略部分代码
}
transfer方法-线程领取迁移任务
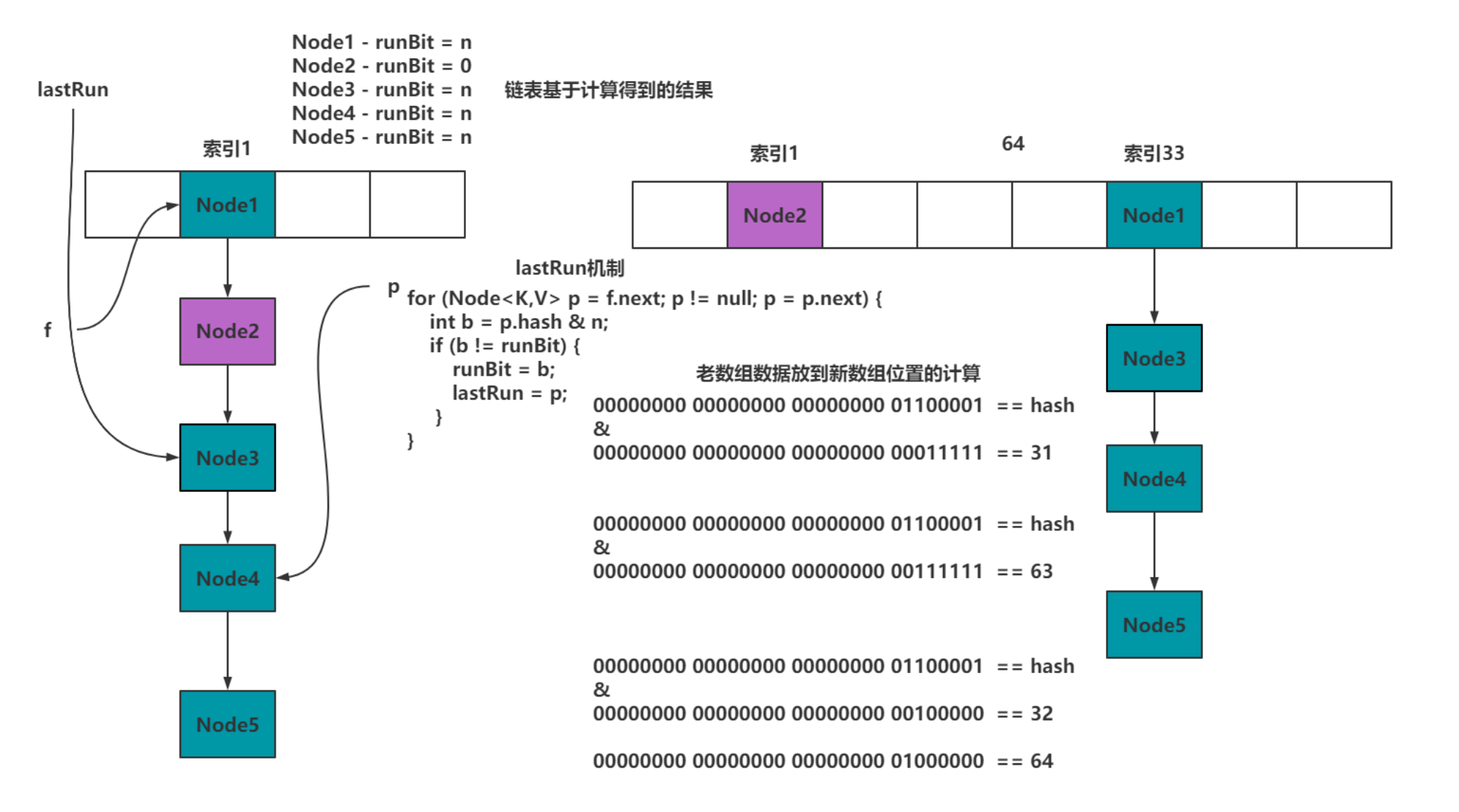
// 以32长度扩容到64位为例子
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// n:32// stride:16int n = tab.length, stride;if (nextTab == null) { // initiating// 省略部分代码............ // nextTable:新数组nextTable = nextTab;transferIndex = n;}// nextn:64int nextn = nextTab.length;ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);// advance:true,代表当前线程需要接收任务,然后再执行迁移, 如果为false,代表已经接收完任务boolean advance = true;// finishing:false,是否迁移结束!boolean finishing = false; // to ensure sweep before committing nextTab// 循环......// i = 15 代表当前线程迁移数据的索引值!!// bound = 0for (int i = 0, bound = 0;;) {// f = null// fh = 0Node<K,V> f; int fh;// 当前线程要接收任务while (advance) {// nextIndex = 16// nextBound = 16int nextIndex, nextBound;// 第一次进来,这两个判断肯定进不去。// 对i进行--,并且判断当前任务是否处理完毕!if (--i >= bound || finishing)advance = false;// 判断transferIndex是否小于等于0,代表没有任务可领取,结束了。// 在线程领取任务会,会对transferIndex进行修改,修改为transferIndex - stride// 在任务都领取完之后,transferIndex肯定是小于等于0的,代表没有迁移数据的任务可以领取else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}// 当前线程尝试领取任务else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {// 对bound赋值bound = nextBound;// 对i赋值i = nextIndex - 1;// 设置advance设置为false,代表当前线程领取到任务了。advance = false;}}// 开始迁移数据,并且在迁移完毕后,会将advance设置为true}
}
transfer方法-迁移结束操作
// 以32长度扩容到64位为例子
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {for (int i = 0, bound = 0;;) {// 判断扩容是否已经结束!// i < 0:当前线程没有接收到任务!// i >= n: 迁移的索引位置,不可能大于数组的长度,不会成立// i + n >= nextn:因为i最大值就是数组索引的最大值,不会成立if (i < 0 || i >= n || i + n >= nextn) {// 如果进来,代表当前线程没有接收到任务int sc;// finishing为true,代表扩容结束if (finishing) {// 将nextTable新数组设置为nullnextTable = null;// 将当前数组的引用指向了新数组~table = nextTab;// 重新计算扩容阈值 64 - 16 = 48sizeCtl = (n << 1) - (n >>> 1);// 结束扩容return;}// 当前线程没有接收到任务,让当前线程结束扩容操作。// 采用CAS的方式,将sizeCtl - 1,代表当前并发扩容的线程数 - 1if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// sizeCtl的高16位是基于数组长度计算的扩容戳,低16位是当前正在扩容的线程个数if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)// 代表当前线程并不是最后一个退出扩容的线程,直接结束当前线程扩容return;// 如果是最后一个退出扩容的线程,将finishing和advance设置为truefinishing = advance = true;// 将i设置为老数组长度,让最后一个线程再从尾到头再次检查一下,是否数据全部迁移完毕。i = n; // recheck before commit}}// 开始迁移数据,并且在迁移完毕后,会将advance设置为true}
}
transfer方法-迁移数据(链表)
// 以32长度扩容到64位为例子
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {// 省略部分代码............for (int i = 0, bound = 0;;) {// 省略部分代码............if (i < 0 || i >= n || i + n >= nextn) {// 省略部分代码............}// 开始迁移数据,并且在迁移完毕后,会将advance设置为true// 获取指定i位置的Node对象,并且判断是否为nullelse if ((f = tabAt(tab, i)) == null)// 当前桶位置没有数据,无需迁移,直接将当前桶位置设置为fwdadvance = casTabAt(tab, i, null, fwd);// 拿到当前i位置的hash值,如果为MOVED,证明数据已经迁移过了。else if ((fh = f.hash) == MOVED)// 一般是给最后扫描时,使用的判断,如果迁移完毕,直接跳过当前位置。advance = true; // already processedelse {// 当前桶位置有数据,先锁住当前桶位置synchronized (f) {// 判断之前取出的数据是否为当前的数据。if (tabAt(tab, i) == f) {// ln:null - lowNode// hn:null - highNodeNode<K,V> ln, hn;if (fh >= 0) {int runBit = fh & n;// 将f赋值给lastRunNode<K,V> lastRun = f;// 循环的目的就是为了得到链表下经过hash & n结算,结果一致的最后一些数据// 在迁移数据时,值需要迁移到lastRun即可,剩下的指针不需要变换。for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}// runBit == 0,赋值给lnif (runBit == 0) {ln = lastRun;hn = null;}// rubBit == n,赋值给hnelse {hn = lastRun;ln = null;}// 循环到lastRun指向的数据即可,后续不需要再遍历for (Node<K,V> p = f; p != lastRun; p = p.next) {// 获取当前Node的hash值,key值,value值。int ph = p.hash; K pk = p.key; V pv = p.val;// 如果hash&n为0,挂到lowNode上if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);// 如果hash&n为n,挂到highNode上elsehn = new Node<K,V>(ph, pk, pv, hn);}// 采用CAS的方式,将ln挂到新数组的原位置setTabAt(nextTab, i, ln);// 采用CAS的方式,将hn挂到新数组的原位置 + 老数组长度setTabAt(nextTab, i + n, hn);// 采用CAS的方式,将当前桶位置设置为fwdsetTabAt(tab, i, fwd);// advance设置为true,保证可以进入到while循环,对i进行--操作advance = true;}// 省略迁移红黑树的操作}}}}
}
helpTransfer方法-协助扩容
// 在添加数据时,如果插入节点的位置的数据,hash值为-1,代表当前索引位置数据已经被迁移到了新数组
// tab:老数组
// f:数组上的Node节点
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {// nextTab:新数组// sc:给sizeCtl做临时变量Node<K,V>[] nextTab; int sc;// 第一个判断:老数组不为null// 第二个判断:新数组不为null (将新数组赋值给nextTab)if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {// ConcurrentHashMap正在扩容// 基于老数组长度计算扩容戳int rs = resizeStamp(tab.length);// 第一个判断:fwd中的新数组,和当前正在扩容的新数组是否相等。 相等:可以协助扩容。不相等:要么扩容结束, // 第二个判断:老数组是否改变了。 相等:可以协助扩容。不相等:扩容结束了// 第三个判断:如果正在扩容,sizeCtl肯定为负数,并且给sc赋值while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {// 第一个判断:将sc右移16位,判断是否与扩容戳一致。 如果不一致,说明扩容长度不一样,退出协助扩容// 第二个、三个判断是BUG: /*sc == rs << 16 + 1 || 如果+1和当前sc一致,说明扩容已经到了最后检查的阶段sc == rs << 16 + MAX_RESIZERS || 判断协助扩容的线程是否已经达到了最大值 */// 第四个判断:transferIndex是从高索引位置到低索引位置领取数据的一个核心属性,如果满足 小于等于0,说明任务if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || transferIndex <= 0)// 不需要协助扩容break;// 将sizeCtl + 1,进来协助扩容if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {// 协助扩容transfer(tab, nextTab);break;}}return nextTab;}return table;
}
红黑树操作
在前面搞定了关于数据+链表的添加和扩容操作,现在要搞定红黑树。因为红黑树的操作有点乱,先对红黑树结构有一定了解。
什么是红黑树
红黑树是一种特殊的平衡二叉树,首选具备了平衡二叉树的特点:左子树和右子数的高度差不会超过1,如果超过了,平衡二叉树就会基于左旋和右旋的操作,实现自平衡。
红黑树在保证自平衡的前提下,还保证了自己的几个特性:
- 每个节点必须是红色或者黑色。
- 根节点必须是黑色。
- 如果当前节点是红色,子节点必须是黑色
- 所有叶子节点都是黑色。
- 任意节点到每个叶子节点的路径中,黑色节点的数量是相同的。
当对红黑树进行增删操作时,可能会破坏平衡或者是特性,这是红黑树就需要基于左旋、右旋、变色来保证平衡和特性。
左旋操作:
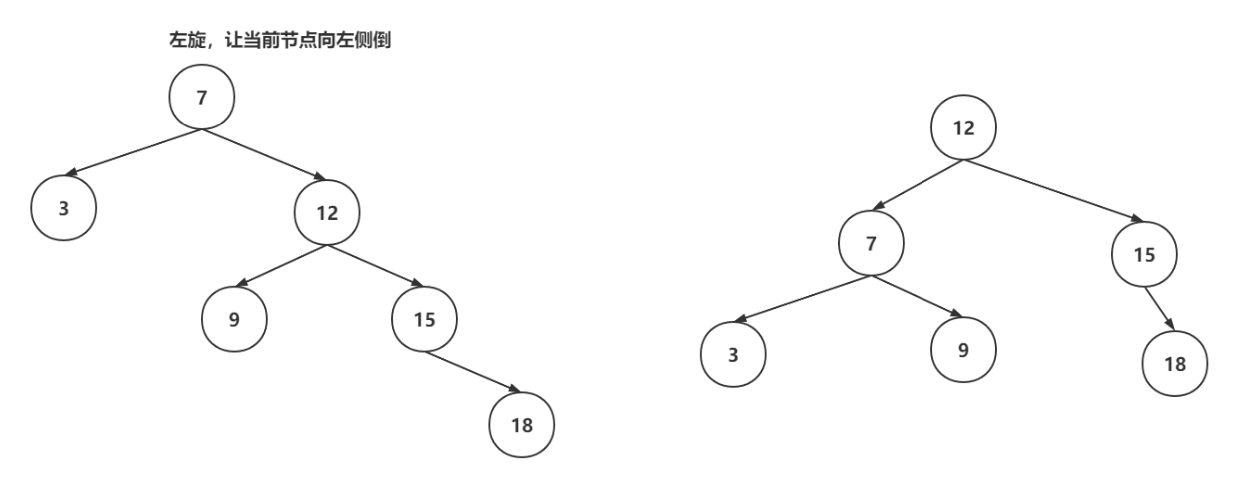
右旋操作:
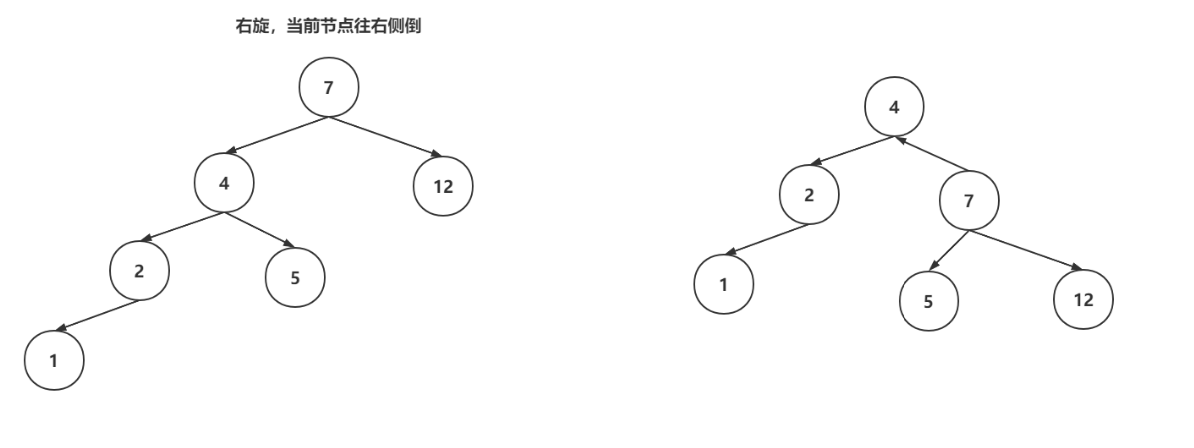
变色操作:节点的颜色从黑色变为红色,或者从红色变为黑色,就成为变色。变色操作是在增删数据之后,可能出现的操作。插入数据时,插入节点的颜色一般是红色,因为插入红色节点的破坏红黑树结构的可能性比较低的。如果破坏了红黑树特性,会通过变色来调整。
红黑树相对比较复杂,完整的红黑树代码400~500行内容,没有必要全部记下来,或者首先红黑树。
TreeifyBin方法-封装TreeNode和双向链表
// 将链表转为红黑树的准备操作
private final void treeifyBin(Node<K,V>[] tab, int index) {// b:当前索引位置的NodeNode<K,V> b; int n, sc;if (tab != null) {// 省略部分代码// 开启链表转红黑树操作// 当前桶内有数据,并且是链表结构else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {// 加锁,保证线程安全synchronized (b) {// 再次判断数据是否有变化,DCLif (tabAt(tab, index) == b) {// 开启准备操作,将之前的链表中的每一个Node,封装为TreeNode,作为双向链表 // hd:是整个双向链表的第一个节点。// tl:是单向链表转换双向链表的临时存储变量TreeNode<K,V> hd = null, tl = null;for (Node<K,V> e = b; e != null; e = e.next) {TreeNode<K,V> p =new TreeNode<K,V>(e.hash, e.key, e.val,null, null);if ((p.prev = tl) == null)hd = p;elsetl.next = p;tl = p;}// hd就是整个双向链表// TreeBin的有参构建,将双向链表转为了红黑树。setTabAt(tab, index, new TreeBin<K,V>(hd));}}}}
}
TreeBin有参构造-双向链表转为红黑树
TreeBin中不但保存了红黑树结构,同时还保存在一套双向链表。
// 将双向链表转为红黑树的操作。 b:双向链表的第一个节点
// TreeBin继承自Node,root:代表树的根节点,first:双向链表的头节点
TreeBin(TreeNode<K,V> b) {// 构建Node,并且将hash值设置为-2super(TREEBIN, null, null, null);// 将双向链表的头节点赋值给firstthis.first = b;// 声明r的TreeNode,最后会被赋值为根节点TreeNode<K,V> r = null;// 遍历之前封装好的双向链表for (TreeNode<K,V> x = b, next; x != null; x = next) {next = (TreeNode<K,V>)x.next;// 先将左右子节点清空x.left = x.right = null;// 如果根节点为null,第一次循环if (r == null) {// 将第一个节点设置为当前红黑树的根节点x.parent = null;// 根节点没父节点x.red = false;// 不是红色,是黑色r = x;// 将当前节点设置为r}// 已经有根节点,当前插入的节点要作为父节点的左子树或者右子树else {// 拿到了当前节点key和hash值。K k = x.key;int h = x.hash;Class<?> kc = null;// 循环?for (TreeNode<K,V> p = r;;) {// dir:如果为-1,代表要插入到父节点的左边,如果为1,代表要插入的父节点的右边 // ph:是父节点的hash值int dir, ph;// pk:是父节点的keyK pk = p.key;// 父节点的hash值,大于当前节点的hash值,就设置为-1,代表要插入到父节点的左边if ((ph = p.hash) > h)dir = -1;// 父节点的hash值,小于当前节点的hash值,就设置为1,代表要插入到父节点的右边else if (ph < h)dir = 1;// 父节点的hash值和当前节点hash值一致,基于compare方式判断到底放在左子树还是右子树else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0)dir = tieBreakOrder(k, pk);// 拿到当前父节点。TreeNode<K,V> xp = p;// 将p指向p的left、right,并且判断是否为null // 如果为null,代表可以插入到这位置。if ((p = (dir <= 0) ? p.left : p.right) == null) {// 进来就说明找到要存放当前节点的位置了// 将当前节点的parent指向父节点x.parent = xp;// 根据dir的值,将父节点的left、right指向当前节点if (dir <= 0)xp.left = x;elsexp.right = x;// 插入一个节点后,做一波平衡操作r = balanceInsertion(r, x);break;}}}}// 将根节点复制给rootthis.root = r;// 检查红黑树结构assert checkInvariants(root);
}
balanceInsertion方法-保证红黑树平衡以及特性
// 红黑树的插入动画:https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
// 红黑树做自平衡以及保证特性的操作。 root:根节点, x:当前节点
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,TreeNode<K,V> x) {// 先将节点置位红色x.red = true;// xp:父节点// xpp:爷爷节点// xppl:爷爷节点的左子树// xxpr:爷爷节点的右子树for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {// 拿到父节点,并且父节点为红if ((xp = x.parent) == null) {// 当前节点为根节点,置位黑色x.red = false;return x;}// 父节点不是红色,爷爷节点为nullelse if (!xp.red || (xpp = xp.parent) == null)// 什么都不做,直接返回return root;// ===================================== // 左子树的操作if (xp == (xppl = xpp.left)) {// 通过变色满足红黑树特性if ((xppr = xpp.right) != null && xppr.red) {// 叔叔节点和父节点变为黑色xppr.red = false;xp.red = false;// 爷爷节点置位红色xpp.red = true;// 让爷爷节点作为当前节点,再走一次循环x = xpp;}else {// 如果当前节点是右子树,通过父节点的左旋,变为左子树的结构if (x == xp.right) {// 父节点做左旋操作root = rotateLeft(root, x = xp);xpp = (xp = x.parent) == null ? null : xp.parent;}if (xp != null) {// 父节点变为黑色xp.red = false;if (xpp != null) {// 爷爷节点变为红色xpp.red = true;// 爷爷节点做右旋操作root = rotateRight(root, xpp);}}}}// 右子树(只讲左子树就足够了,因为业务都是一样的)else {if (xppl != null && xppl.red) {xppl.red = false;xp.red = false;xpp.red = true;x = xpp;}else {if (x == xp.left) {root = rotateRight(root, x = xp);xpp = (xp = x.parent) == null ? null : xp.parent;}if (xp != null) {xp.red = false;if (xpp != null) {xpp.red = true;root = rotateLeft(root, xpp);}}}}}
}
putTreeVal方法-添加节点
整体操作就是判断当前节点要插入到左子树,还是右子数,还是覆盖操作。
确定左子树和右子数之后,直接维护双向链表和红黑树结构,并且再判断是否需要自平衡。
TreeBin的双向链表用的头插法。
// 添加节点到红黑树内部
final TreeNode<K,V> putTreeVal(int h, K k, V v) {// Class对象Class<?> kc = null;// 搜索节点boolean searched = false;// 死循环,p节点是根节点的临时引用for (TreeNode<K,V> p = root;;) {// dir:确定节点是插入到左子树还是右子数 // ph:父节点的hash值// pk:父节点的keyint dir, ph; K pk;// 根节点是否为诶null,把当前节点置位根节点if (p == null) {first = root = new TreeNode<K,V>(h, k, v, null, null);break;}// 判断当前节点要放在左子树还是右子数else if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;// 如果key一致,直接返回p,由putVal去修改数据else if ((pk = p.key) == k || (pk != null && k.equals(pk)))return p;// hash值一致,但是key的==和equals都不一样,基于Compare去判断else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||// 基于compare判断也是一致,就进到if判断(dir = compareComparables(kc, k, pk)) == 0) {// 开启搜索,查看是否有相同的key,只有第一次循环会执行。if (!searched) {TreeNode<K,V> q, ch;searched = true;if (((ch = p.left) != null &&(q = ch.findTreeNode(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.findTreeNode(h, k, kc)) != null))// 如果找到直接返回return q;}// 再次判断hash大小,如果小于等于,返回-1dir = tieBreakOrder(k, pk);}// xp是父节点的临时引用TreeNode<K,V> xp = p;// 基于dir判断是插入左子树还有右子数,并且给p重新赋值if ((p = (dir <= 0) ? p.left : p.right) == null) {// first引用拿到TreeNode<K,V> x, f = first;// 将当前节点构建出来first = x = new TreeNode<K,V>(h, k, v, f, xp);// 因为当前的TreeBin除了红黑树还维护这一个双向链表,维护双向链表的操作if (f != null)f.prev = x;// 维护红黑树操作if (dir <= 0)xp.left = x;elsexp.right = x;// 如果如节点是黑色的,当前节点红色即可,说明现在插入的节点没有影响红黑树的平衡if (!xp.red)x.red = true;else {// 说明插入的节点是黑色的// 加锁操作lockRoot();try {// 自平衡一波。root = balanceInsertion(root, x);} finally {unlockRoot();}}break;}}// 检查一波红黑树结构assert checkInvariants(root);// 代表插入了新节点return null;
}
TreeBin的锁操作
TreeBin的锁操作,没有基于AQS,仅仅是对一个变量的CAS操作和一些业务判断实现的。 每次读线程操作,对lockState+4。
写线程操作,对lockState + 1,如果读操作占用着线程,就先+2,waiter是当前线程,并挂起当前线程。
// TreeBin的锁操作
// 如果说有读线程在读取红黑树的数据,这时,写线程要阻塞(做平衡前)
// 如果有写线程正在操作红黑树(做平衡),读线程不会阻塞,会读取双向链表
// 读读不会阻塞!
static final class TreeBin<K,V> extends Node<K,V> {TreeNode<K,V> root;volatile TreeNode<K,V> first;// waiter:等待获取写锁的线程volatile Thread waiter;// lockState:当前TreeBin的锁状态volatile int lockState;// values for lockState// 对锁状态进行运算的值// 有线程拿着写锁static final int WRITER = 1; // set while holding write lock// 有写线程,再等待获取写锁static final int WAITER = 2; // set when waiting for write lock// 读线程,在红黑树中检索时,需要先对lockState + READER // 这个只会在读操作中遇到static final int READER = 4; // increment value for setting read lock// 加锁-写锁private final void lockRoot() {// 将lockState从0设置为1,代表拿到写锁成功if (!U.compareAndSwapInt(this, LOCKSTATE, 0, WRITER))// 如果写锁没拿到,执行contendedLockcontendedLock(); // offload to separate method}// 释放写锁private final void unlockRoot() {lockState = 0;}// 写线程没有拿到写锁,执行当前方法private final void contendedLock() {// 是否有线程正在等待boolean waiting = false;// 死循环,s是lockState的临时变量for (int s;;) {// lockState & 11111101 ,只要结果为0,说明当前写锁,和读锁都没线程获取if (((s = lockState) & ~WAITER) == 0) {// CAS一波,尝试将lockState再次修改为1,if (U.compareAndSwapInt(this, LOCKSTATE, s, WRITER)) {// 成功拿到锁资源,并判断是否在waitingif (waiting)// 如果当前线程挂起过,直接将之前等待的线程资源设置为nullwaiter = null;return;}}// 有读操作在占用资源// lockState & 00000010,代表当前没有写操作挂起等待。else if ((s & WAITER) == 0) {// 基于CAS,将LOCKSTATE的第二位设置为1if (U.compareAndSwapInt(this, LOCKSTATE, s, s | WAITER)) {// 如果成功,代表当前线程可以waiting等待了waiting = true;waiter = Thread.currentThread();}}else if (waiting)// 挂起当前线程!会由写操作唤醒LockSupport.park(this);}}
}
transfer迁移数据
首先红黑结构的数据迁移是基于双向链表封装的数据。
如果高低位的长度小于等于6,封装为链表迁移到新数组。
如果高低位的长度大于6,依然封装为红黑树迁移到新数组。
// 红黑树的迁移操作单独拿出来,TreeBin中不但有红黑树,还有双向链表,迁移的过程是基于双向链表迁移
TreeBin<K,V> t = (TreeBin<K,V>)f;
// lo,hi扩容后要放到新数组的高低位的链表
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
// lc,hc在记录高低位数据的长度
int lc = 0, hc = 0;
// 遍历TreeBin中的双向链表
for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);// 与老数组长度做&运算,基于结果确定需要存放到低位还是高位if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;// 低位长度++++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;// 高位长度++++hc;}
}
// 封装低位节点,如果低位节点的长度小于等于6,转回成链表。 如果长度大于6,需要重新封装红黑树
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :(hc != 0) ? new TreeBin<K,V>(lo) : t;
// 封装高位节点
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;
// 低位数据设置到新数组
setTabAt(nextTab, i, ln);
// 高位数据设置到新数组
setTabAt(nextTab, i + n, hn);
// 当前位置数据迁移完毕,设置上fwd
setTabAt(tab, i, fwd);
// 开启前一个节点的数据迁移
advance = true;
查询数据
get方法-查询数据的入口
在查询数据时,会先判断当前key对应的value,是否在数组上。
其次会判断当前位置是否属于特殊情况:数据被迁移、位置被占用、红黑树结构。
最后判断链表上是否有对应的数据。
找到返回指定的value,找不到返回null即可。
// 基于key查询value
public V get(Object key) {// tab:数组, e:查询指定位置的节点 n:数组长度Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;// 基于传入的key,计算hash值int h = spread(key.hashCode());// 数组不为null,数组上得有数据,拿到指定位置的数组上的数据if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {// 数组上数据恩地hash值,是否和查询条件key的hash一样if ((eh = e.hash) == h) {// key的==或者equals是否一致,如果一致,数组上就是要查询的数据if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}// 如果数组上的数据的hash为负数,有特殊情况,else if (eh < 0)// 三种情况,数据迁移走了,节点位置被占,红黑树return (p = e.find(h, key)) != null ? p.val : null;// 肯定走链表操作while ((e = e.next) != null) {// 如果hash值一致,并且key的==或者equals一致,返回当前链表位置的数据if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}// 如果上述三个流程都没有知道指定key对应的value,那就是key不存在,返回null即可return null;
}
ForwardingNode的find方法
在查询数据时,如果发现已经扩容了,去新数组上查询数据。
在数组和链表上正常找key对应的value
可能依然存在特殊情:
- 再次是fwd,说明当前线程可能没有获取到CPU时间片,导致CHM再次触发扩容,重新走当前方法
- 可能是被占用或者是红黑树,再次走另外两种find方法的逻辑。
// 在查询数据时,发现当前桶位置已经放置了fwd,代表已经被迁移到了新数组
Node<K,V> find(int h, Object k) {// loop to avoid arbitrarily deep recursion on forwarding nodes// key:get(key) h:key的hash tab:新数组outer: for (Node<K,V>[] tab = nextTable;;) {// n:新数组长度, e:新数组上定位的位置上的数组Node<K,V> e; int n;if (k == null || tab == null || (n = tab.length) == 0 ||(e = tabAt(tab, (n - 1) & h)) == null)return null;// 开始在新数组中走逻辑for (;;) {// eh:新数组位置的数据的hashint eh; K ek;// 判断hash是否一致,如果一致,再判断==或者equals。if ((eh = e.hash) == h &&((ek = e.key) == k || (ek != null && k.equals(ek))))// 在新数组找到了数据return e;// 发现到了新数组,hash值又小于0if (eh < 0) {// 套娃,发现刚刚在扩容,到了新数组,发现又扩容if (e instanceof ForwardingNode) {// 再次重新走最外层循环,拿到最新的nextTabletab = ((ForwardingNode<K,V>)e).nextTable;continue outer;}else// 占了,红黑树return e.find(h, k);}// 说明不在数组上,往下走链表if ((e = e.next) == null)// 进来说明链表没找到,返回nullreturn null;}}
}
ReservationNode的find方法
没什么说的,直接返回null。
因为当前桶位置被占用的话,说明数据还没放到当前位置,当前位置可以理解为就是null。
Node<K,V> find(int h, Object k) {return null;
}
TreeBin的find方法
在红黑树中执行find方法后,会有两个情况:
- 如果有线程在持有写锁或者等待获取写锁,当前查询就要在双向链表中锁检索。
- 如果没有线程持有写锁或者等待获取写锁,完全可以对lockState + 4,然后去红黑树中检索, 并且在检索完毕后,需要对lockState - 4,再判断是否需要唤醒等待写锁的线程。
// 在红黑树中检索数据
final Node<K,V> find(int h, Object k) {// 非空判断if (k != null) {// e:Treebin中的双向链表,for (Node<K,V> e = first; e != null; ) {int s; K ek;// s:TreeBin的锁状态// 00000010// 00000001if (((s = lockState) & (WAITER|WRITER)) != 0) {// 如果进来if,说明要么有写线程在等待获取写锁,要么是由写线程持有者写锁// 如果出现这个情况,他会去双向链表查询数据if (e.hash == h &&((ek = e.key) == k || (ek != null && k.equals(ek))))return e;e = e.next;}// 说明没有线程等待写锁或者持有写锁,将lockState + 4,代表当前读线程可以去红黑树中检索数据else if (U.compareAndSwapInt(this, LOCKSTATE, s,s + READER)) {TreeNode<K,V> r, p;try {// 基于findTreeNode在红黑树中检索数据p = ((r = root) == null ? null :r.findTreeNode(h, k, null));} finally {Thread w;// 会对lockState - 4,读线程拿到数据了,释放读锁// 可以确认,如果-完4,等于WAITER,说明有写线程可能在等待,判断waiter是否为nullif (U.getAndAddInt(this, LOCKSTATE, -READER) ==(READER|WAITER) && (w = waiter) != null)// 当前我是最后一个在红黑树中检索的线程,同时有线程在等待持有写锁,唤醒等待的写线程LockSupport.unpark(w);}return p;}}}return null;
}
TreeNode的findTreeNode方法
红黑树的检索方式,套路很简单,及时基于hash值,来决定去找左子树还有右子数。
如果hash值一致,判断是否 == 、equals,满足就说明找到数据。
如果hash值一致,并不是找的数据,基于compare方式,再次决定找左子树还是右子数,知道找到 当前节点的子节点为null,停住。
// 红黑树中的检索方法
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {if (k != null) {TreeNode<K,V> p = this;do {int ph, dir; K pk; TreeNode<K,V> q;// 声明左子树和右子数TreeNode<K,V> pl = p.left, pr = p.right;// 直接比较hash值,来决决定走左子树还是右子数if ((ph = p.hash) > h)p = pl;else if (ph < h)p = pr;// 判断当前的子树是否和查询的k == 或者equals,直接返回else if ((pk = p.key) == k || (pk != null && k.equals(pk)))return p;else if (pl == null)p = pr;else if (pr == null)p = pl;else if ((kc != null ||(kc = comparableClassFor(k)) != null) &&(dir = compareComparables(kc, k, pk)) != 0)p = (dir < 0) ? pl : pr;// 递归继续往底层找else if ((q = pr.findTreeNode(h, k, kc)) != null)return q;elsep = pl;} while (p != null);}return null;
}
ConcurrentHashMap其他方法
compute方法
修改ConcurrentHashMap中指定key的value时,一般会选择先get出来,然后再拿到原value值, 基于原value值做一些修改,最后再存放到咱们ConcurrentHashMap。
public static void main(String[] args) {ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap();map.put("key", 1);// 修改key对应的value,追加上1// 之前的操作方式Integer oldValue = map.get("key");Integer newValue = oldValue + 1;map.put("key", newValue);System.out.println(map);// 现在的操作方式map.compute("key", (key, computeOldValue) -> {if (computeOldValue == null) {computeOldValue = 0;}return computeOldValue + 1;});System.out.println(map);
}
compute方法源码分析
整个流程和putVal方法很类似,但是内部涉及到了占位的情况RESERVED。
整个compute方法和putVal的区别就是,compute方法的value需要计算,如果key存在,基于oldValue计算出新结果,如果key不存在,直接基于oldValue为null的情况,去计算新的value。
// compute 方法
public V compute(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) {if (key == null || remappingFunction == null)throw new NullPointerException();// 计算key的hashint h = spread(key.hashCode());V val = null;int delta = 0;int binCount = 0;// 初始化,桶上赋值,链表插入值,红黑树插入值for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 初始化if (tab == null || (n = tab.length) == 0)tab = initTable();// 桶上赋值else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {// 数组指定的索引位置是没有数据,当前数据必然要放到数组上。// 因为value需要计算得到,计算的时间不可估计,所以这里并没有通过CAS的方式处理并发操作,直接添加临时占用节// 并占用当前临时节点的锁资源。Node<K,V> r = new ReservationNode<K,V>();synchronized (r) {// 以CAS的方式将数据放上去if (casTabAt(tab, i, null, r)) {binCount = 1;Node<K,V> node = null;try {// 如果ReservationNode临时Node存放成功,直接开始计算valueif ((val = remappingFunction.apply(key, null)) != null) {delta = 1;// 将计算的value和传入的key封装成一个新Node,通过CAS存储到当前数组上node = new Node<K,V>(h, key, val, null);}} finally {setTabAt(tab, i, node);}}}if (binCount != 0)break;}else {// 省略部分代码。主要是针对在链表上的替换、添加,以及在红黑树上的替换、添加}}if (delta != 0)addCount((long)delta, binCount);return val;
}
computeIfPresent、computeIfAbsent、compute区别
compute的BUG,如果在计算结果的函数中,又涉及到了当前的key,会造成死锁问题。
public static void main(String[] args) {ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap();map.compute("key", (k, v) -> {return map.compute("key", (key, value) -> {return 1111;});});System.out.println(map);
}
computeIfPresent和computeIfAbsent其实就是将compute方法拆开成了两个方法。
compute会在key不存在时,正常存放结果,如果key存在,就基于oldValue计算newValue。
computeIfPresent:要求key在map中必须存在,需要基于oldValue计算newValue。
computeIfAbsent:要求key在map中不能存在,必须为null,才会基于函数得到value存储进去。
computeIfPresent:
// 如果key存在,才执行修改操作
public V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) {if (key == null || remappingFunction == null)throw new NullPointerException();int h = spread(key.hashCode());V val = null;int delta = 0;int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();// 如果key不存在,什么事都不做~else if ((f = tabAt(tab, i = (n - 1) & h)) == null)break;else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f, pred = null;; ++binCount) {K ek;// 如果查看到有 == 或者equals的key,就直接修改即可if (e.hash == h &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {val = remappingFunction.apply(key, e.val);if (val != null)e.val = val;else {delta = -1;Node<K,V> en = e.next;if (pred != null)pred.next = en;elsesetTabAt(tab, i, en);}break;}pred = e;// 走完链表,还是没找到指定数据,直接break;if ((e = e.next) == null)break;}}// 省略部分代码}}// 省略部分代码}}// 省略部分代码return val;
}
computeIfAbsent核心位置源码:
// key必须不存在才会执行添加操作
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {if (key == null || mappingFunction == null)throw new NullPointerException();int h = spread(key.hashCode());V val = null;int binCount = 0;// 如果key不存在,正常添加;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {Node<K,V> r = new ReservationNode<K,V>();synchronized (r) {if (casTabAt(tab, i, null, r)) {binCount = 1;Node<K,V> node = null;try {if ((val = mappingFunction.apply(key)) != null)node = new Node<K,V>(h, key, val, null);} finally {setTabAt(tab, i, node);}}}if (binCount != 0)break;}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {boolean added = false;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek; V ev;// 如果key存在,直接break;if (e.hash == h &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {val = e.val;break;}// 如果没有找到一样的key,计算value结果接口Node<K,V> pred = e;if ((e = e.next) == null) {if ((val = mappingFunction.apply(key)) != null) {added = true;pred.next = new Node<K,V>(h, key, val, null);}break;}}}// 省略部分代码}}// 省略部分代码}}// 省略部分代码return val;
}
replace方法详解
涉及到类似CAS的操作,需要将ConcurrentHashMap的value从val1改为val2的场景就可以使用 replace实现。
replace内部要求key必须存在,替换value值之前,要先比较oldValue,只有oldValue一致时,才 会完成替换操作。
// replace方法调用的replaceNode方法, value:newValue, cv:oldValue
final V replaceNode(Object key, V value, Object cv) {int hash = spread(key.hashCode());for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 在数组没有初始化时,或者key不存在时,什么都不干。if (tab == null || (n = tab.length) == 0 ||(f = tabAt(tab, i = (n - 1) & hash)) == null)break;else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;boolean validated = false;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {validated = true;for (Node<K,V> e = f, pred = null;;) {K ek;// 找到key一致的Node了。if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {// 拿到当前节点的原值。V ev = e.val;// 拿oldValue和原值做比较,如果一致,if (cv == null || cv == ev ||(ev != null && cv.equals(ev))) {// 可以开始替换oldVal = ev;if (value != null)e.val = value;else if (pred != null)pred.next = e.next;elsesetTabAt(tab, i, e.next);}break;}pred = e;if ((e = e.next) == null)break;}}else if (f instanceof TreeBin) {validated = true;TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> r, p;if ((r = t.root) != null &&(p = r.findTreeNode(hash, key, null)) != null) {V pv = p.val;if (cv == null || cv == pv ||(pv != null && cv.equals(pv))) {oldVal = pv;if (value != null)p.val = value;else if (t.removeTreeNode(p))setTabAt(tab, i, untreeify(t.first));}}}}}if (validated) {if (oldVal != null) {if (value == null)addCount(-1L, -1);return oldVal;}break;}}}return null;
}
merge方法详解
merge(key,value,Function<oldValue,value>);
在使用merge时,有三种情况可能发生:
- 如果key不存在,就跟put(key,value);
*如果key存在,就可以基于Function计算,得到最终结果- 结果不为null,将key对应的value,替换为Function的结果
- 结果为null,删除当前key
分析merge源码
public V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) {if (key == null || value == null || remappingFunction == null)throw new NullPointerException();int h = spread(key.hashCode());V val = null;int delta = 0;int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();// key不存在,直接执行正常的添加操作,将value作为值,添加到hashMapelse if ((f = tabAt(tab, i = (n - 1) & h)) == null) {if (casTabAt(tab, i, null, new Node<K,V>(h, key, value, null))) {delta = 1;val = value;break;}}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f, pred = null;; ++binCount) {K ek;// 判断链表中,有当前的keyif (e.hash == h &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {// 基于函数,计算valueval = remappingFunction.apply(e.val, value);// 如果计算的value不为null,正常替换if (val != null)e.val = val;// 计算的value是null,直接让上一个指针指向我的next,绕过当前节点else {delta = -1;Node<K,V> en = e.next;if (pred != null)pred.next = en;elsesetTabAt(tab, i, en);}break;}pred = e;if ((e = e.next) == null) {delta = 1;val = value;pred.next =new Node<K,V>(h, key, val, null);break;}}}else if (f instanceof TreeBin) {binCount = 2;TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> r = t.root;TreeNode<K,V> p = (r == null) ? null :r.findTreeNode(h, key, null);val = (p == null) ? value :remappingFunction.apply(p.val, value);if (val != null) {if (p != null)p.val = val;else {delta = 1;t.putTreeVal(h, key, val);}}else if (p != null) {delta = -1;if (t.removeTreeNode(p))setTabAt(tab, i, untreeify(t.first));}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);break;}}}if (delta != 0)addCount((long)delta, binCount);return val;
}
ConcurrentHashMap计数器
addCount方法分析
addCount方法本身就是为了记录ConcurrentHashMap中元素的个数。
两个方向组成:
- 计数器,如果添加元素成功,对计数器 + 1
- 检验当前ConcurrentHashMap是否需要扩容
计数器选择的不是AtomicLong,而是类似LongAdder的一个功能
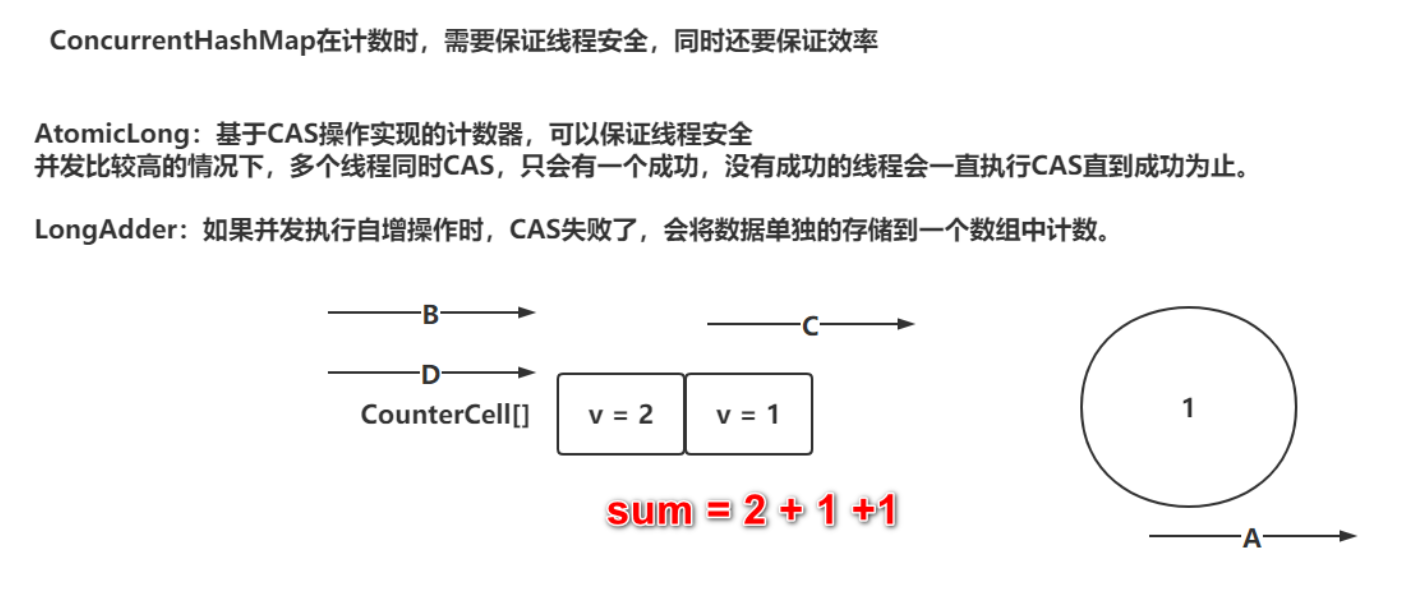
addCount源码分析
private final void addCount(long x, int check) {// ================================计数===================================== // as: CounterCell[]// s:是自增后的元素个数// b:原来的baseCountCounterCell[] as; long b, s;// 判断CounterCell不为null,代表之前有冲突问题,有冲突直接进到if中// 如果CounterCell[]为null,直接执行||后面的CAS操作,直接修改baseCountif ((as = counterCells) != null ||// 如果对baseCount++成功。直接告辞。 如果CAS失败,直接进到if中!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {// 导致,说明有并发问题。// 进来的方式有两种:// 1. counterCell[] 有值。// 2. counterCell[] 无值,但是CAS失败。// m:数组长度 - 1// a:当前线程基于随机数,获得到的数组上的某一个CounterCellCounterCell a; long v; int m;// 是否有冲突,默认为true,代表没有冲突boolean uncontended = true;// 判断CounterCell[]没有初始化,执行fullAddCount方法,初始化数组if (as == null || (m = as.length - 1) < 0 ||// CounterCell[]已经初始化了,基于随机数拿到数组上的一个CounterCell,如果为null,执行fullAddCount方法,初(a = as[ThreadLocalRandom.getProbe() & m]) == null ||// CounterCell[]已经初始化了,并且指定索引位置上有CounterCell// 直接CAS修改指定的CounterCell上的value即可。// CAS成功,直接告辞!// CAS失败,代表有冲突,uncontended = false,执行fullAddCount方法!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {fullAddCount(x, uncontended);return;}// 如果链表长度小于等于1,不去判断扩容if (check <= 1)return;// 将所有CounterCell中记录的信累加,得到最终的元素个数s = sumCount();}// ================================判断扩容===================================// 判断check大于等于,remove的操作就是小于0的。 因为添加时,才需要去判断是否需要扩容if (check >= 0) {// 一堆小变量Node<K,V>[] tab, nt; int n, sc;// 当前元素个数是否大于扩容阈值,并且数组不为null,数组长度没有达到最大值。while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&(n = tab.length) < MAXIMUM_CAPACITY) {// 扩容表示戳int rs = resizeStamp(n);// 正在扩容if (sc < 0) {// 判断是否可以协助扩容if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0)break;// 协助扩容if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}// 没有线程执行扩容,我来扩容else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))transfer(tab, null);// 重新计数。s = sumCount();}}
}// CounterCell的类,就类似于LongAdder的Cell
@sun.misc.Contended static final class CounterCell {// volatile修饰的value,并且外部基于CAS的方式修改volatile long value;CounterCell(long x) { value = x; }
}/*@sun.misc.Contended(JDK1.8): 这个注解是为了解决伪共享的问题(解决缓存行同步带来的性能问题)。CPU在操作主内存变量前,会将主内存数据缓存到CPU缓存(L1,L2,L3)中,CPU缓存L1,是以缓存行为单位存储数据的,一般默认的大小为64字节。 缓存行同步操作,影响CPU一定的性能。@Contented注解,会将当前类中的属性,会独占一个缓存行,从而避免缓存行失效造成的性能问题。@Contented注解,就是将一个缓存行的后面7个位置,填充上7个没有意义的数据。long value; long l1,l2,l3,l4,l5,l6,l7;
*/// 整体CounterCell数组数据到baseCount
final long sumCount() {// 拿到CounterCell[]CounterCell[] as = counterCells; CounterCell a;// 拿到baseCountlong sum = baseCount;// 循环走你,遍历CounterCell[],将值累加到sum中,最终返回sumif (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}// See LongAdder version for explanation
// CounterCell数组没有初始化
// CounterCell对象没有构建
// 什么都有,但是有并发问题,导致CAS失败
private final void fullAddCount(long x, boolean wasUncontended) {// h:当前线程的随机数int h;// 判断当前线程的Probe是否初始化。if ((h = ThreadLocalRandom.getProbe()) == 0) {// 初始化一波ThreadLocalRandom.localInit(); // force initialization// 生成随机数。h = ThreadLocalRandom.getProbe();// 标记,没有冲突wasUncontended = true;}boolean collide = false; // True if last slot nonemptyfor (;;) {// as:CounterCell[]// a:CounterCell对 null// n:数组长度// v:value值CounterCell[] as; CounterCell a; int n; long v;// CounterCell[]不为null时,做CAS操作if ((as = counterCells) != null && (n = as.length) > 0) {// 拿到当前线程随机数对应的CounterCell对象,为null// 第一个if:当前数组已经初始化,但是指定索引位置没有CounterCell对象,构建CounterCell对象放到数组上if ((a = as[(n - 1) & h]) == null) {// 判断cellsBusy是否为0,if (cellsBusy == 0) { // Try to attach new Cell// 构建CounterCell对象CounterCell r = new CounterCell(x); // Optimistic create// 在此判断cellsBusy为0,CAS从0修改为1,代表可以操作当前数组上的指定索引,构建CounterCell,赋值进去if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {// 构建未完成boolean created = false;try { // Recheck under lockCounterCell[] rs; int m, j;// DCL,还包含复制if ((rs = counterCells) != null &&(m = rs.length) > 0 &&// 再次拿到指定索引位置的值,如果为null,正常将前面构建的CounterCell对象,赋值给数组rs[j = (m - 1) & h] == null) {// 将CounterCell对象赋值到数组rs[j] = r;// 构建完成created = true;}} finally {// 归位cellsBusy = 0;}if (created)// 跳出循环,告辞break;continue; // Slot is now non-empty}}collide = false;}// 指定索引位置上有CounterCell对象,有冲突,修改冲突标识else if (!wasUncontended) // CAS already known to failwasUncontended = true; // Continue after rehash// CAS,将数组上存在的CounterCell对象的value进行 + 1操作else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))// 成功,告辞。break;// 之前拿到的数组引用和成员变量的引用值不一样了,// CounterCell数组的长度是都大于CPU内核数,不让CounterCell数组长度大于CPU内核数。else if (counterCells != as || n >= NCPU)// 当前线程的循环失败,不进行扩容collide = false; // At max size or stale// 如果没并发问题,并且可以扩容,设置标示位,下次扩容else if (!collide)collide = true;// 扩容操作// 先判断cellsBusy为0,再基于CAS将cellsBusy从0修改为1。else if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {try {if (counterCells == as) {// Expand table unless stale// 构建一个原来长度2倍的数组CounterCell[] rs = new CounterCell[n << 1];// 将老数组数据迁移到新数组for (int i = 0; i < n; ++i)rs[i] = as[i];// 新数组复制给成员变量counterCells = rs;}} finally {// 归位cellsBusy = 0;}// 归位collide = false;// 开启下次循环continue; // Retry with expanded table}// 重新设置当前线程的随机数,争取下次循环成功!h = ThreadLocalRandom.advanceProbe(h);}// CounterCell[]没有初始化// 判断cellsBusy为0.代表没有其他线程在初始化或者扩容当前CounterCell[]// 判断counterCells还是之前赋值的as,代表没有并发问题else if (cellsBusy == 0 && counterCells == as &&// 修改cellsBusy,从0改为1,代表当前线程要开始初始化了U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {// 标识,init未成功boolean init = false;try { // Initialize table// DCL!if (counterCells == as) {// 构建CounterCell[],默认长度为2CounterCell[] rs = new CounterCell[2];// 用当前线程的随机数,和数组长度 - 1,进行&运算,将这个位置上构建一个CounterCell对象,赋值value为1rs[h & 1] = new CounterCell(x);// 将声明好的rs,赋值给成员变量counterCells = rs;// init成功init = true;}} finally {// cellsBusy归位。cellsBusy = 0;}if (init)// 退出循环break;}// 到这就直接在此操作baseCount。else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))break; // Fall back on using base}
}
size方法方法分析
size获取ConcurrentHashMap中的元素个数
public int size() {// 基于sumCount方法获取元素个数long n = sumCount();// 做了一些简单的健壮性判断return ((n < 0L) ? 0 :(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :(int)n);
}// 整体CounterCell数组数据到baseCount
final long sumCount() {// 拿到CounterCell[]CounterCell[] as = counterCells; CounterCell a;// 拿到baseCountlong sum = baseCount;// 循环走你,遍历CounterCell[],将值累加到sum中,最终返回sumif (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}
CopyOnWriteArrayList
CopyOnWriteArrayList介绍
CopyOnWriteArrayList是一个线程安全的ArrayList。
CopyOnWriteArrayList是基于lock锁和数组副本的形式去保证线程安全。
在写数据时,需要先获取lock锁,需要复制一个副本数组,将数据插入到副本数组中,将副本数组赋值给CopyOnWriteArrayList中的array。
因为CopyOnWriteArrayList每次写数据都要构建一个副本,如果你的业务是写多,并且数组中的数据量比较大,尽量避免去使用CopyOnWriteArrayList,因为这里会构建大量的数组副本,比较占用内存资源。
CopyOnWriteArrayList是弱一致性的,写操作先执行,但是副本还有落到CopyOnWriteArrayList的array属性中,此时读操作是无法查询到的。
核心属性&方法
主要查看2个核心属性,以及2个核心方法,还有无参构造
/** 写操作时,需要先获取到的锁资源,CopyOnWriteArrayList全局唯一的。 */
final transient ReentrantLock lock = new ReentrantLock();/** CopyOnWriteArrayList真实存放数据的位置,查询也是查询当前array */
private transient volatile Object[] array;// 获取array属性
final Object[] getArray() {return array;
}// 替换array属性
final void setArray(Object[] a) {array = a;
}/**
* 默认new的CopyOnWriteArrayList数组长度为0。
* 不像ArrayList,初始长度是10,每次扩容1/2, CopyOnWriteArrayList不存在这个概念
* 每次写的时候都会构建一个新的数组
*/
public CopyOnWriteArrayList() {setArray(new Object[0]);
}
读操作
CopyOnWriteArrayList的读操作就是get方法,基于数组索引位置获取数据。
方法之所以要差分成两个,是因为CopyOnWriteArrayList中在获取数据时,不单单只有一个array的数组需要获取值,还有副本中数据的值。
// 查询数据时,只能通过get方法查询CopyOnWriteArrayList中的数据
public E get(int index) {// getArray拿到array数组,调用get方法的重载return get(getArray(), index);
}// 执行get(int)时,内部调用的方法
private E get(Object[] a, int index) {// 直接拿到数组上指定索引位置的值return (E) a[index];
}
写操作
CopyOnWriteArrayList是基于lock锁和副本数组的形式保证线程安全。
// 写入元素,不指定索引位置,直接放到最后的位置
public boolean add(E e) {// 获取全局锁,并执行lockfinal ReentrantLock lock = this.lock;lock.lock();try {// 获取原数组,还获取了原数组的长度Object[] elements = getArray();int len = elements.length;// 基于原数组复制一份副本数组,并且长度比原来多了一个Object[] newElements = Arrays.copyOf(elements, len + 1);// 将添加的数据放到副本数组最后一个位置newElements[len] = e;// 将副本数组,赋值给CopyOnWriteArrayList的原数组setArray(newElements);// 添加成功,返回truereturn true;} finally {// 释放锁lock.unlock();}
}// 写入元素,指定索引位置。(不会覆盖数据)
public void add(int index, E element) {// 拿锁,加锁~final ReentrantLock lock = this.lock;lock.lock();try {// 获取原数组,还获取了原数组的长度Object[] elements = getArray();int len = elements.length;// 如果索引位置大于原数组的长度,或者索引位置是小于0的。if (index > len || index < 0)throw new IndexOutOfBoundsException("Index: "+index+", Size: "+len);// 声明了副本数组Object[] newElements;// 原数组长度 - 索引位置等到numMovedint numMoved = len - index;// 如果numMoved为0,说明数据要放到最后面的位置if (numMoved == 0)// 直接走了原生态的方式,正常复制一份副本数组newElements = Arrays.copyOf(elements, len + 1);else {// 数组要插入的位置不是最后一个位置// 副本数组长度依然是原长度 + 1newElements = new Object[len + 1];// 将原数组从0索引位置开始复制,复制到副本数组中的前置位置System.arraycopy(elements, 0, newElements, 0, index);// 将原数组从index位置开始复制,复制到副本数组的index + 1往后放。// 这时,index就空缺出来了。System.arraycopy(elements, index, newElements, index + 1,numMoved);}// 数据正常放到指定的索引位置newElements[index] = element;// 将副本数组,赋值给CopyOnWriteArrayList的原数组setArray(newElements);} finally {// 释放锁lock.unlock();}
}移除数据
关于remove操作,要分析两个方法
- 基于索引位置移除指定数据
- 基于具体元素删除数组中最靠前的数据
- 当前这种方式,嵌套了一层,导致如果元素存在话,成本是比较高的。
- 如果元素不存在,这种设计不需要加锁,提升写的效率
// 删除指定索引位置的数据
public E remove(int index) {// 拿锁,加锁final ReentrantLock lock = this.lock;lock.lock();try {// 获取原数组和原数组长度Object[] elements = getArray();int len = elements.length;// 通过get方法拿到index位置的数据E oldValue = get(elements, index);// 声明numMovedint numMoved = len - index - 1;// 如果numMoved为0,说明删除的元素是最后的位置if (numMoved == 0)// Arrays.copyOf复制一份新的副本数组,并且将最后一个数据不要了 // 基于setArray将副本数组赋值给array原数组setArray(Arrays.copyOf(elements, len - 1));else {// 删除的元素不在最后面的位置// 声明副本数组,长度是原数组长度 - 1Object[] newElements = new Object[len - 1];// 从0开始复制的index前面System.arraycopy(elements, 0, newElements, 0, index);// 从index后面复制到最后System.arraycopy(elements, index + 1, newElements, index,numMoved);setArray(newElements);}// 返回被干掉的数据return oldValue;} finally {// 释放锁lock.unlock();}
}// 删除元素(最前面的)
public boolean remove(Object o) {// 没加锁!!!!// 获取原数组Object[] snapshot = getArray();// 用indexOf获取元素在数组的哪个索引位置// 没找到的话,返回-1int index = indexOf(o, snapshot, 0, snapshot.length);// 如果index < 0,说明元素没找到,直接返回false,告辞// 如果找到了元素的位置,直接执行remove方法的重载return (index < 0) ? false : remove(o, snapshot, index);
}// 执行remove(Object o),找到元素位置时,执行当前方法
private boolean remove(Object o, Object[] snapshot, int index) {// 拿锁,加锁final ReentrantLock lock = this.lock;lock.lock();try {// 拿到原数组和长度Object[] current = getArray();int len = current.length;// findIndex: 是给if起标识,break 标识的时候,直接跳出if的代码块~~if (snapshot != current) findIndex: {// 如果没进到if,说明数组没变化,按照原来的index位置删除即可// 进到这,说明数组有变化,之前的索引位置不一定对// 拿到index位置和原数组长度的值int prefix = Math.min(index, len);// 循环判断,数组变更后,是否影响到了要删除元素的位置for (int i = 0; i < prefix; i++) {// 如果不相等,说明元素变化了。// 同时判断变化的元素是否是我要删除的元素oif (current[i] != snapshot[i] && eq(o, current[i])) {// 如果满足条件,说明当前位置就是我要删除的元素index = i;break findIndex;}}// 如果for循环结束,没有退出if,说明元素可能变化了,总之没找到要删除的元素// 如果删除元素的位置,已经大于等于数组长度了。if (index >= len)// 超过索引范围了,没法删除了。return false;// 索引还在范围内,判断是否是还是原位置,如果是,直接跳出if代码块if (current[index] == o)break findIndex;// 重新找元素在数组中的位置index = indexOf(o, current, index, len);// 找到直接跳出if代码块// 没找到。执行下面的return falseif (index < 0)return false;}// 删除套路,构建新数组,复制index前的,复制index后的Object[] newElements = new Object[len - 1];System.arraycopy(current, 0, newElements, 0, index);System.arraycopy(current, index + 1,newElements, index,len - index - 1);// 复制到arraysetArray(newElements);// 返回true,删除成功return true;} finally {lock.unlock();}
}
覆盖数据&清空集合
覆盖数据就是set方法,可以将指定位置的数据替换
// 覆盖数据
public E set(int index, E element) {// 拿锁,加锁final ReentrantLock lock = this.lock;lock.lock();try {// 获取原数组Object[] elements = getArray();// 获取原数组的原位置数据E oldValue = get(elements, index);// 原数据和新数据不一样if (oldValue != element) {// 拿到原数据的长度,复制一份副本。int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len);// 将element替换掉副本数组中的数据newElements[index] = element;// 写回原数组setArray(newElements);} else {// Not quite a no-op; ensures volatile write semantics// 原数据和新数据一样,啥不干,把拿出来的数组再写回去setArray(elements);}// 返回原值return oldValue;} finally {// 释放锁lock.unlock();}
}
清空就是清空了~~~
public void clear() {// 加锁final ReentrantLock lock = this.lock;lock.lock();try {// 扔一个长度为0的数组setArray(new Object[0]);} finally {lock.unlock();}
}
迭代器
用ArrayList时,如果想在遍历的过程中去移除或者修改元素,必须使用迭代器才可以。
但是CopyOnWriteArrayList这哥们即便用了迭代器也不让做写操作。
不让在迭代时做写操作是因为不希望迭代操作时,会影响到写操作,还有,不希望迭代时,还需要加锁。
// 获取遍历CopyOnWriteArrayList的iterator。
public Iterator<E> iterator() {// 其实就是new了一个COWIterator对象,并且获取了array,指定从0开始遍历return new COWIterator<E>(getArray(), 0);
}static final class COWIterator<E> implements ListIterator<E> {/** 遍历的快照 */private final Object[] snapshot;/** Index of element to be returned by subsequent call to next. *//** 游标,索引~~~ */private int cursor;// 有参构造private COWIterator(Object[] elements, int initialCursor) {cursor = initialCursor;snapshot = elements;}// 有没有下一个元素,基于遍历的索引位置和数组长度查看public boolean hasNext() {return cursor < snapshot.length;}// 有没有上一个元素public boolean hasPrevious() {return cursor > 0;}// 获取下一个值,游标动一下@SuppressWarnings("unchecked")public E next() {// 确保下个位置有数据if (! hasNext())throw new NoSuchElementException();return (E) snapshot[cursor++];}// 获取上一个值,游标往上移动@SuppressWarnings("unchecked")public E previous() {if (! hasPrevious())throw new NoSuchElementException();return (E) snapshot[--cursor];}// 拿到下一个值的索引,返回游标public int nextIndex() {return cursor;}// 拿到上一个值的索引,返回游标public int previousIndex() {return cursor-1;}// 写操作全面禁止!!public void remove() {throw new UnsupportedOperationException();}public void set(E e) {throw new UnsupportedOperationException();}public void add(E e) {throw new UnsupportedOperationException();}// 兼容函数式编程@Overridepublic void forEachRemaining(Consumer<? super E> action) {Objects.requireNonNull(action);Object[] elements = snapshot;final int size = elements.length;for (int i = cursor; i < size; i++) {@SuppressWarnings("unchecked") E e = (E) elements[i];action.accept(e);}cursor = size;}
}
相关文章:
六、并发集合
文章目录并发集合ConcurrentHashMap存储结构存储操作put方法putVal方法-散列算法putVal方法-添加数据到数组&初始化数组putVal方法-添加数据到链表扩容操作treeifyBin方法触发扩容tryPreSize方法-针对putAll的初始化操作tryPreSize方法-计算扩容戳并且查看BUGtryPreSize方法…...

PHY调试经验
1. PHY调试过程 1.设备树中配置正确的PHY ADDR、PHY ID、clause 45或者22协议,PHY ADDR配置不正确会导致MDC/MDIO通信不正常或失败,PHY ID用于匹配PHY驱动程序。 2.通过MDC/MDIO读写PHY ID并对比datasheet中的PHY ID,确认MDC/MDIO通信是否正常…...

从Java培训班出来好找工作吗?
个人觉得这个问题要从两方面来看,首先是培训班的Java课程质量如何,是否贴合用人单位实际需求,学出来的技术能对口;其次是培训班是否保障就业,有就业机会渠道推荐,比如老学员内推、合作企业人才输送以及企业…...
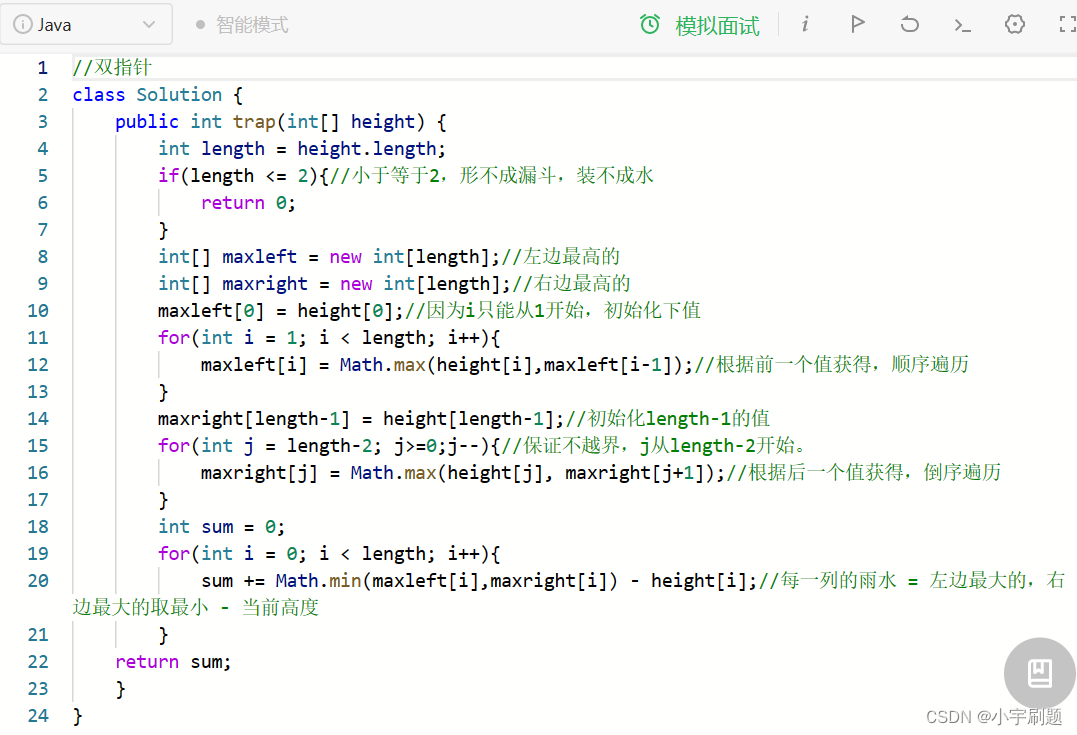
第51天|LeetCode503.下一个更大元素 II、LeetCode42. 接雨水
1.题目链接:下一个更大元素 II 题目描述: 给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是 nums[0] ),返回 nums 中每个元素的 下一个更大元素 。 数字 x 的 下一个更大的元素 是按数组遍历顺序&#…...
[12]云计算概念、技术与架构Thomas Erl-第5章 云使能技术
目录 第五章 云使能技术 5.1宽带网络和Internet架构 5.1.1Internet服务提供者(ISP) 5.1.2无连接分组(数据报网络) 5.1.3基于路由器的互联 5.1.4技术和商业考量 总结 5.2数据中心技术 5.2.1虚拟化 5.2.2标准化与模块化 …...

超实用的公众号用户运营方案分享,纯干货
公众运营是以用户为主的: 但是你知道什么是用户运营吗?你的公众号有没有维护好目标用户群体呢?你知道该怎么分析你的公众号用户群体吗?你知道分析完之后具体应该怎么做用户运营吗? 接下来伯乐网络传媒就来给大家分享…...
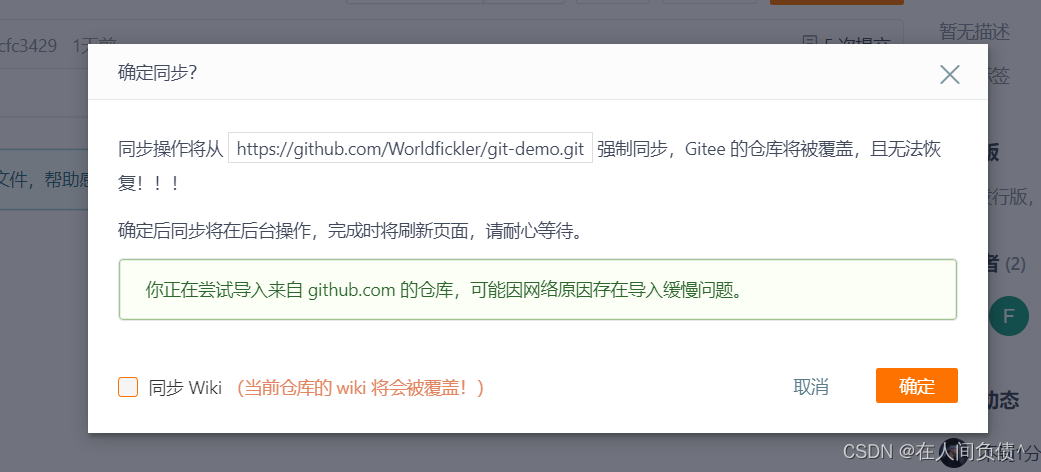
Git ---- 国内代码托管中心-码云
Git ---- 国内代码托管中心-码云1. 简介2. 码云账号注册和登录3. 码云创建远程仓库4. IDEA 集成码云1. IDEA 安装码云插件2. IDEA 连接码云5. 码云复制 GitHub 项目1. 简介 众所周知,GitHub 服务器在国外,使用 GitHub 作为项目托管网站,如果…...

【学习笔记】NOIP爆零赛8
trash ,但不完全是trash t1t1t1考了一个神奇的结论还没有证明,t2t2t2玩了一些复杂度的花样,t3t3t3稍微阳间一点,是一个并不复杂的容斥,如果放在t1t1t1可能更合适一些,t4t4t4就是在原题的基础上改了一下然后就成了一道毒…...
【Linux驱动】驱动设计硬件基础----串口、I2C、SPI、以太网接口、PCIE
1.前言 常见的外设接口与总线的工作方式,包括串口、I2C、SPI、USB、以太网接口、PCI和PCI-E、SD和SDIO等。 2.串口 RS-232、RS-422与RS-485都是串行数据接口标准,最初都是由电子工业协会(EIA)制订并发布的。 3.I2C I2C&…...

同为(TOWE)防雷产品助力福建移动南平分公司防雷改造
01 公司简介中国移动通信集团福建有限公司南平分公司属于福建移动地级分公司,所属行业为电信、广播电视和卫星传输服务。现已建成覆盖范围广、业务品种多、通信质量高的综合通信网络,具备行业领先的经营管理制度。移动通信大楼的综合防雷及地接系统&…...

Win10安装mediapipe的步骤
我之前想自己安装mediapipe包进行人体检测的学习,但整了好几个月都不行,这次终于让我整好了,我的python版本为python 3.7.1。注意,不要直接用pip install mediapipe 进行安装,我之前这样安装的,mediapipe安…...
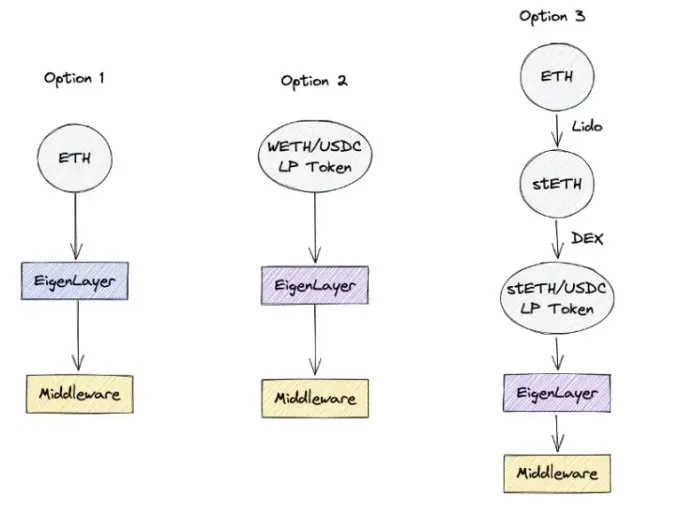
项目调研丨以太坊再质押项目EigenLayer白皮书四大看点(内附完整版中文白皮书)
北京时间2月21日下午,被众多一线投研机构视为2023年以太坊最重要的创新,有可能开启以太坊新叙事方向的项目Eigenlayer终于披露了其第一版白皮书。EigenLayer是以太坊的再质押集,允许共识层ETH质押者选择验证构建在以太坊生态系统之上的新软件…...
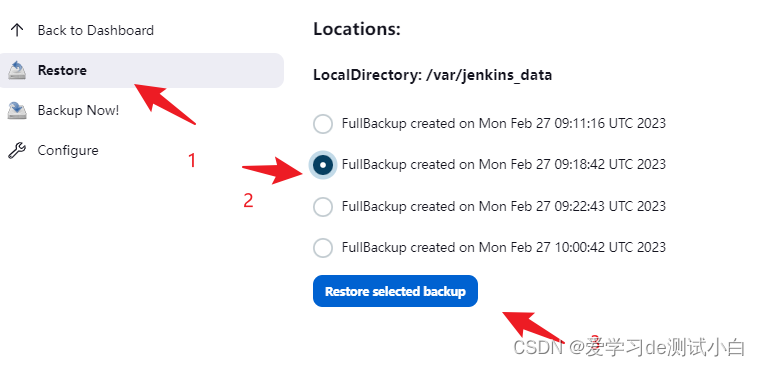
51-Jenkins-Periodic Backup插件实现Jenkins备份
Periodic Backup插件实现Jenkins备份前言目录结构插件备份安装插件使用插件前言 本篇来学习下使用Periodic Backup插件实现Jenkins备份 目录结构 Jenkins的所有数据都是存放在文件中的,所以,Jenins备份其实就是备份Jenkins_HOME目录。 Jenkins_Home目…...
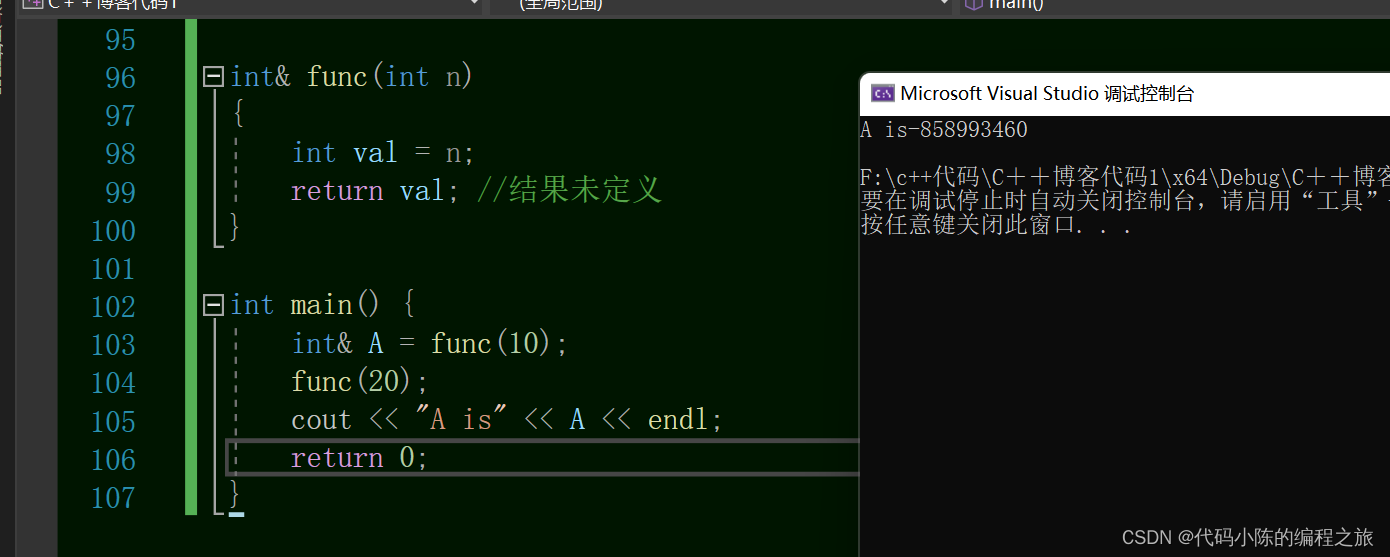
C++之入门之引用,内联函数
一、引用 1、引用的概念 在C中,引用的本质其实就是给一个已经存在的变量”起别名“。也就是说,引用与它所引用的对象共用一块空间。(同一块空间的多个名字) 就比如说,李逵又叫黑旋风,而黑旋风就是指李逵…...

linux kprobe使用
使用场景 监控某个内核函数是否被调用获取某个内核函数耗费的时间获取某个内核函数的入参获取某个内核函数的调用栈(dump_stack())获取某个内核函数的返回值 参数传递规则 x86平台对pt_regs的定义 arch/x86/include/asm/ptrace.h // i386架构 #ifdef…...
)
2023年超全前端面试题-背完稳稳拿offer(欢迎补充)
HTML、CSS相关 HTML5 HTML5新特性 增强了表单,input新增了一些type: color----定义调色板 tel-----定义包含电话号码的输入域 email—定义包含email地址的输入域 search–定义搜索域 number–定义包含数值的输入域 date----定义选取日、月、年的输入域…...

python之web自动化测试框架
梳理下搭建web自动化框架的流程: 创建目录: cases:存放测试用例,unittest框架要求用例名必须以test开头,所以命名test_case.py test_case.py代码如下:继承unittest.TestCase类下面的方法setupclass(),te…...
算法笔记(十五)—— 动态规划(暴力递归到动态规划)习题训练!
通过递归到记忆化搜索再到严格表结构的动态规划 递归方法的评价:1. 单可变参数的维度;2. 可变参数的个数 记忆化搜索 在暴力递归中会存在很多的重复计算,可以使用存储结构来实现空间换时间。 严格表结构的动态规划 整理位置之间的依赖关系…...
云原生架构基础概念及应用办法
什么是云原生? 云原生是一种基于容器、微服务和自动化运维的软件开发和部署方法。它可以使应用程序更加高效、可靠和可扩展,适用于各种不同的云平台。 如果要更直接通俗的来解释下上面的概念。 云原生更准确来说就是一种文化,是一种潮流&a…...
RedisTemplate 的基本使用手把手教
下载实例源码 使用步骤 1、引入 spring-boot-starter-data-redis 依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId> </dependency>2、在 application.yml 配置 R…...

突破试用限制:开源脚本实现IDM无限使用的完整解决方案
突破试用限制:开源脚本实现IDM无限使用的完整解决方案 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 一、问题引入:IDM用户的痛点与解决…...

Kandinsky-5.0-I2V-Lite-5s企业实操:单任务串行设计规避显存过载,保障服务稳定性
Kandinsky-5.0-I2V-Lite-5s企业实操:单任务串行设计规避显存过载,保障服务稳定性 1. 产品概述 Kandinsky-5.0-I2V-Lite-5s是一款轻量级图生视频模型,专为企业级稳定运行而优化。只需上传一张首帧图片,再补充运动或镜头描述&…...

如何高效使用猫抓插件:浏览器资源嗅探实用指南
如何高效使用猫抓插件:浏览器资源嗅探实用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字化时代,我们每天浏览网…...
)
从GC停顿2.3s到零暂停:Java函数GraalVM Native Image迁移全周期复盘(含12个兼容性雷区)
第一章:从GC停顿2.3s到零暂停:Java函数GraalVM Native Image迁移全周期复盘(含12个兼容性雷区)在高吞吐、低延迟的Serverless函数场景中,一个Spring Boot微服务因频繁Full GC导致单次停顿高达2.3秒,严重违反…...

MTK平台录音杂音怎么来的?从AudioALSACaptureDataClientAurisysNormal的mDropPopSize说起
MTK平台录音杂音问题深度解析:从硬件初始化到算法优化的全链路解决方案 在移动设备音频开发领域,MTK平台的录音杂音问题一直是困扰开发者的典型痛点。特别是录音起始阶段出现的"爆破音"或"电流声",不仅影响用户体验&…...

Phi-3-mini-4k-instruct-gguf应用落地:律师助理合同风险点识别与提示生成
Phi-3-mini-4k-instruct-gguf应用落地:律师助理合同风险点识别与提示生成 1. 项目背景与价值 在法律服务领域,合同审查是律师日常工作中最耗时且重复性高的任务之一。传统人工审查方式存在效率低下、容易遗漏细节等问题。Phi-3-mini-4k-instruct-gguf作…...

实战指南:借鉴vmware官网混合云方案,用快马平台生成高可用应用部署模板
今天在VMware官网上研究混合云方案时,发现他们的企业级架构设计特别值得借鉴。正好最近在用InsCode(快马)平台做项目部署,就尝试把官网的混合云方案转化成可落地的模板。整个过程比想象中顺利,分享下我的实战经验。 架构设计思路 VMware官网…...

如何永久备份微信聊天记录?WeChatMsg完整解决方案指南
如何永久备份微信聊天记录?WeChatMsg完整解决方案指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

W25Q16 Flash存储器:从基础概念到SPI通信实战
1. 认识W25Q16 Flash存储器 第一次接触W25Q16是在做一个智能家居项目时,需要保存用户的WiFi配置和房间温湿度记录。当时试过用单片机内部的EEPROM,但容量太小不够用,后来发现了这款性价比超高的外部Flash芯片。简单来说,W25Q16就像…...
开源翻译终端效果展示:Pixel Language Portal处理专业术语准确率分析
开源翻译终端效果展示:Pixel Language Portal处理专业术语准确率分析 1. 产品概览 Pixel Language Portal(像素语言跨维传送门)是一款基于腾讯Hunyuan-MT-7B核心引擎构建的创新翻译工具。与传统翻译软件不同,它将翻译过程转化为…...