大数据系统自检
第一章 大数据计算系统概述
1.1 大数据计算框架概述
Hadoop
Hadoop的运行过程(5个步骤?)
split => map => shuffle => reduce => output
Hadoop的详细运行过程?(4个大过程,6+6+6+2)
- 创建新Job实例,并调度HDFS资源
- 启用MapTask执行map函数
- 启动ReduceTask执行reduce函数
- JobClient轮询获知任务完成
Job 和 Task的区别?
作业(Job):MapReduce程序指定的一个完整计算过程
任务(Task):MapReduce框架中进行并行计算的基本事务单元
一个作业(Job)在执行过程中可以被拆分为若干Map和Reduce任务(Task)完成
MapReduce调度器(三种?默认的是什么?执行的作业顺序?)
FIFO,Fair,Capacity
Map后的2次排序(分别用的什么排序算法?对象是文件还是多个文件?)
文件内部快速排序(Sort)
多个文件归并排序(Merge)
MapReduce任务处理过程(六个步骤?)
待处理的大数据 => 划分 => 提交给主节点 => 传送给map节点,做一些数据整理工作(combining) => 传送给Reduce节点
失效结点处理(主节点失效会怎样?工作节点失效呢?)
主节点失效:一旦某个任务失效,可以从最近有效的检查点开始重新执行,避免从头开始计算的时间浪费。
工作节点失效:如果主节点检测工作节点没有得到回应,则认为该工作节点失效。主节点将把失效的任务重新调度到其它工作节点上执行。
MapReduce 1.0缺点(主要在哪二个方面的哪三个方向?)
JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
JobTracker 完成了太多的任务,造成了过多的资源消耗
YARN(引入了什么概念?有哪三个主要部分,它们都是干什么的?)
ApplicationMaster:头头,申请资源和分配任务
ResourceManager:小头,监控头头和下属,资源分配和调度
NodeManager:下属,资源管理,接受命令
1.2 大数据批处理计算框架
Spark
RDD概念(全称是?可分区吗?它放在主存还是内存?)
弹性分布式数据集
一个RDD的不同分区可以在集群中的不同节点上进行并行计算
放内存
RDD的操作(分为哪三种类型?用于?)
action,transformation,persistence
RDD的执行过程(怎么创建?怎么产生不同的RDD?怎么输出到外部数据源?优点是?)
读入外部数据源
transformation
action
RDD高效的原因(怎么容错?在磁盘还是内存?存放数据可以是什么?)
数据复制和记录日志
中间持久化到内存,中间数据在内存中的RDD操作中传递
存放对象可是Java对象
基本概念
- DAG:是什么的简称?
- Executor:是运行在哪的一个进程?负责运行什么?
- 应用,作业,阶段,任务的关系?和它们分别干什么用?
有向无环图
运行在工作节点(WorkerNode)的一个进程,负责运行Task
应用>作业>阶段>任务
架构设计(三层分别是?英文和中文名?第三层里有什么?两种Node分别是?基于什么存储结构?)
Driver Program(SparkContext)
Cluster Manager
Worker Nodes(Executor(Task))
HDFS、HBase
Spark运行代码的7个步骤?
① Driver解析生成Task
② Driver向Cluster Manager申请资源
③ Cluster Manager分配资源和节点,并创建Executor
④ Executor向Driver注册
⑤ Driver将代码和文件传给Executor
⑥ Executor运行Task
Shuffle操作(宽依赖和窄依赖分别是什么情况?)
宽依赖:一对多和多对多
窄依赖:多对一或一对一
阶段的划分(划分的依据?哪种依赖利于优化?)
逆流划分,遇到窄依赖就做合并,遇到宽依赖就断开
RDD运行过程(4个阶段?干了什么?)
① 创建RDD对象
② 创建DAG,也即RDD之间的依赖关系,再分解为多个Stage,每个Stage中有多个Task
③ Task被TaskScheduler分给WorkerNode上的Executor执行
④ Worker执行Tasks
RDD容错机制(维护用来重建的信息)
RDD维护可以用来创建丢失分区的信息
Spark中的存储机制(RDD缓存存在哪?如何从磁盘取得分区对应的数据块?Shuffle数据存在哪?)
RDD缓存:包括基于内存和磁盘的缓存
内存缓存=哈希表+存取策略
Shuffle数据的持久化:必须是在磁盘上进行缓存的
第二章 大数据管理系统
大数据管理系统一
概念
数据库的定义?
数据库是长期储存在计算机内、有组织的、可共享的数据集合。
DBMS(全称?主要功能?DDL是什么?DML是什么?)
Database Management System
数据定义语言,定义数据库中的数据对象。
数据操纵语言,操纵数据实现对数据库的基本操作。
DBS(包括什么?)
数据库、数据库管理系统、应用系统、数据库管理员、用户
数据库存储结构
-
RAID(是什么?由什么组成?)
磁盘冗余阵列
由若干同样的磁盘组成的阵列
-
文件内记录的组织(5种记录的组织方式?它们分别怎么记录的?)
堆文件组织:随便放
顺序文件组织:升序或降序的放,指针链结构
散列文件组织:某个属性值通过哈希函数求得的值作为存储地址
聚类文件组织:有联系的记录存储在同一块内
索引技术
- 索引是什么?它是文件吗?
- 索引分类(两大类?主索引是什么?聚类索引和非聚类的差别?聚类索引中的三种索引是?)
- 索引的更新(删除和插入分别对于稠密索引和稀疏索引是什么样的操作?)
独立于主文件记录的一个只含索引属性的小的文件
两大类:有序索引 vs 散列索引
聚类(非聚类)索引:区别在于是否与主文件顺序一致
稠密索引、稀疏索引、多级索引
删除:
对稠密索引,删除相应的索引项;
对稀疏索引,如果被删记录的索引值在索引块中出现,则用主文件被删记录的下一个记录的查找键A替换。若A已出现在索引块,则删除被删记录的对应索引键。插入:
对稠密索引且查找键未在索引块出现,在索引中插入。
对稀疏索引:若数据块有空闲放得下新数据,不用修改索引;否则加入新数据块,在索引块中插入一个新索引项
事务
- 定义,由什么组成?
- 事务的ACID性质?
是DBMS中一个逻辑工作单元,通常由一组数据库的操作组成
原子性(Atomic)
一致性(Consistency)
隔离性(Isolation)
持久性(Durability)
I/O并行
-
划分技术 定义(磁盘数 = n) 优点 缺点 循环划分 散列划分 范围划分
划分技术 定义(磁盘数 = n) 优点 缺点 循环划分 (i mod n) 最适合顺序扫描 难以处理范围查询 散列划分 值域为0…n-1的散列函数 h 顺序存取 无聚簇, 因此难以回答范围查询 范围划分 划分向量 [v0,v1,...,vn−2][v_0, v_1, ..., v_{n-2}][v0,v1,...,vn−2]
偏斜的处理
-
偏斜的种类(2种偏斜是?划分偏斜的两种划分是?)
-
处理偏斜(3种方法?)
属性值偏斜:某些值在许多元组的划分属性上出现,所有在划分属性上值相同的元组被分配在同一分区中
划分偏斜
范围划分:一个坏的划分向量可能将过多元组分配到一个分区以及过少元组分配到其他分区
散列划分:只要选择好的散列函数就不太可能发生
范围划分中处理偏斜:生成平衡的划分向量的方法——每读出关系的1/n,下一条元组的划分属性值就加入划分向量
利用直方图处理偏斜:从直方图可以相对直接地构造出平衡的划分向量
利用虚拟处理器来处理偏斜:偏斜的虚拟分区被分散到若干实际处理器上
查询间并行
增加事务吞吐量,主要用于扩展事务处理系统以支持更大的每秒事务数
缓存一致性协议
• 读/写一页之前, 该页必须以共享/排他方式加锁
• 对页加锁时, 该页必须从磁盘读出
• 释放页锁之前, 该页如果更新过则必须写到磁盘
查询内并行(查询内并行的两种互相补充的形式)
操作内并行 —— 查询内每个操作并行执行
操作间并行 —— 查询内不同操作并行执行
大数据管理系统二
NoSQL简介
Not Only SQL
典型的NoSQL数据库通常包括键值数据库、列族数据库、文档数据库和图数据库
CAP
C(Consistency):一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果;
A(Availability):可用性,是指快速获取数据,可以在确定的时间内返回操作结果;
P(Tolerance of Network Partition):分区容忍性,是指当出现网络分区的情况时,分离的系统也能够正常运行。
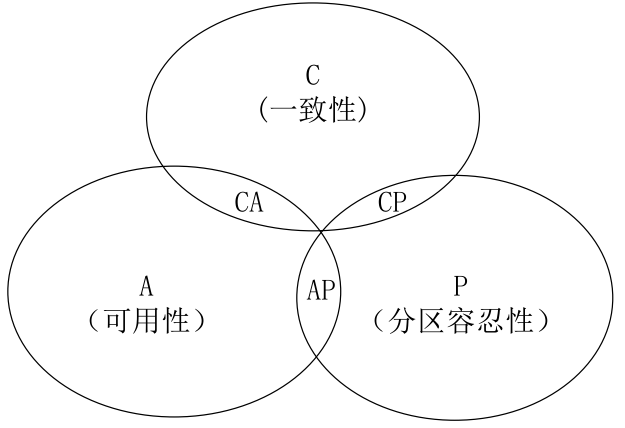
- CA:也就是强调一致性(C)和可用性(A),放弃分区容忍性(P),最简单的做法是把所有与事务相关的内容都放到同一台机器上。很显然,这种做法会严重影响系统的可扩展性。传统的关系数据库都采用了这种设计原则,因此,扩展性都比较差
- CP:也就是强调一致性(C)和分区容忍性(P),放弃可用性(A),当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务
- AP:也就是强调可用性(A)和分区容忍性(P),放弃一致性(C),允许系统返回不一致的数据
BASE
BASE(Basically Availble, Soft-state, Eventual consistency)
BASE的基本含义是基本可用(Basically Availble)、软状态(Soft state)和最终一致性(Eventual consistency)
NewSQL
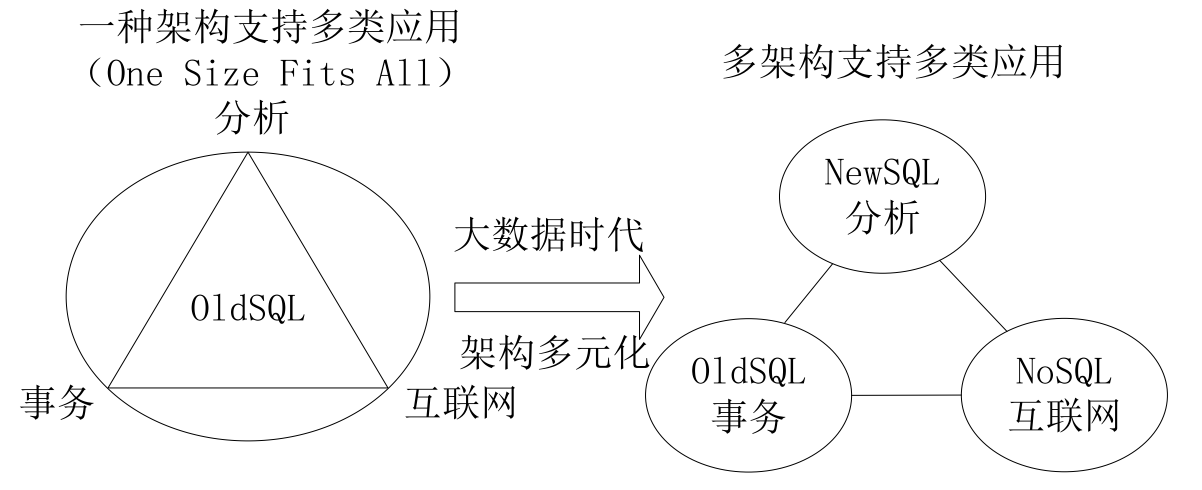
NewSQL是对各种新的可扩展/高性能数据库的简称
- 具有NoSQL对海量数据的存储管理能力
- 还保持了传统数据库支持ACID和SQL等特性
NewSQL特点:
支持关系数据模型
使用SQL作为主要的接口
第三章 大数据实时计算框架
3.1 Storm
定义?
实时、分布式、流式的计算系统
Storm的典型应用场景(同步,异步,数据流处理,连续计算,分布式远程程序调用)都是什么概念?
请求应答(同步):实时图片处理、实时网页分析
流式处理(异步):逐条处理、分析统计
数据流处理:可用来实时处理新数据和更新数据库,兼具容错性和可扩展性。
连续计算:可进行连续查询并把结果即时反馈给客户端。
分布式远程程序调用
Storm的特点
可靠、快速、高容错,水平扩展
技术架构(三个部分分别是什么?)
Nimbus(类JobTracker
zookeeper
Supervisor(类TaskTracker
worker(类Child
Worker、Executor和Task的关系
和前面类似
Storm的工作流程
Client提交Topology => Nimbus将任务存储到 => Zookeeper => Supervisor获取分配任务并启动 => Worker执行具体的 (Task)
Storm容错(任务级失败的处理方式?任务槽故障务级失败+集群节点(机器)故障分别会有什么?Nimbus节点故障没发生什么?)
任务级失败
Bolt任务crash引起的消息未被应答 或 acker任务失败
=> Spout的fail方法将被调用。Spout任务失败
=> 与Spout任务对接的外部设备(如MQ)负责消息的完整性。集群节点(机器)故障
- Storm集群中的节点故障:任务转移
- Zookeeper集群中的节点故障:保证少于半数的机器宕机仍可运行
Nimbus节点故障:没有Nimbus,Worker不会在必要时被安排到其他主机,客户端也无法提交任务。
Stream是什么?Spouts是什么?Tuple是什么?Bolts是什么?Topology是什么?
Stream:无限的Tuple序列
Spouts:水龙头,Stream的源头
Bolts:处理Tuple,创建新Streams
Topology:Spouts和Bolts组成的抽象网络
Stream Grouping是什么?有6种方式?
用于告知Topology如何再两个组件(Spouts、Bolts)之间进行Tuple的传送
ShuffleGrouping:随机分组
FieldsGrouping:按照字段分组
AllGrouping:广播发送,所有Tuple向所有Task发
GlobalGrouping:全局分组,所有Tuple送到同一Task
NonGrouping:不分组
DirectGrouping:指定发送,指定接收
3.2 Spark Streaming
输入数据按照时间片分成一段一段的DStream,每一段数据转换为Spark的RDD
Spark Streaming的核心概念
- DStream表示什么?
- Transformations 的功能?(标准的RDD操作,有状态操作)
表示数据流的RDDs序列
Transformations:从一个Dstream修改数据以创建另一个DStream
标准的RDD操作:map, countByValue, reduce, insert…
有状态操作:window, countByValueAndWindow…
DStream的输入源
- 基础来源?
- 高级来源?
Spark容错
- RDDs可以记住从原始的容错输入创建它的操作序列
- 批量输入数据被复制到多个工作节点的内存中,因此是容错的
一些对比
Spark Streaming与Storm对比
| Spark Streaming | Storm |
|---|---|
| 无法实现毫秒级的流计算 | 可以实现毫秒级响应 |
| 低延迟执行引擎可以用于实时计算 | |
| 相比于Storm,RDD数据集更容易做高效的容错处理 |
Storm和Hadoop架构组件功能对应关系
| Hadoop | Storm | |
|---|---|---|
| 应用名称 | Job | Topology |
| 系统角色 | JobTracker | Nimbus |
| TaskTracker | Supervisor | |
| 组件接口 | Map/Reduce | Spout/Bolt |
第四章 大图计算框架
计算模型
Superstep: 并行结点计算
-
对于每个结点(六种可能操作)
-
终止条件(两个)
接受上一个superstep发出的消息
执行相同的用户定义函数
修改它的值或者其输出边的值
将消息送到其他点(由下一个superstep接受)
改变图的拓扑结构
没有额外工作要做时结束迭代所有顶点同时变为非活跃状态
没有信息传递
4.1 Pregel
系统架构
Pregel系统也使用主/从模型
- 主节点:调度从节点、修复从节点的错误
- 从节点:处理自己的任务、与其他从节点通信
聚合器(用于?用什么结构聚合的?)
用于全局通信、全局数据和监控
在superstep末尾,来自每个从节点的部分聚合值聚合在一个树结构种
Pregel执行(5个步骤)
① 主节点分割图,并给每个从节点分配一个或多个部分
② 主节点指导每个从节点执行一个superstep
③ 最后,主节点指示每个从节点保存各自的图
4.2 GraphX
使用路由表连接站点选择
迭代mrTriplets的缓存
迭代mrTriplets的聚合
容错
- 检查点:主节点定期指示从节点将分区的状态保存到持久化存储中
- 错误检测:定时使用“ping”信息
- 恢复
主节点将图形分区重新分配给当前可用的从节点
所有工作人员都从最近可用的检查点重新加载分区状态- 局部恢复:记录传出的信息、只涉及恢复分区
第五章 大数据存储
在大规模下小概率事件将成为常态(小概率事件有什么?)
磁盘机器损坏、RAID卡故障、网络故障、电源故障、数据错误、系统异常
HDFS
相关术语
| HDFS | GFS | MooseFS | 说明 |
|---|---|---|---|
| NameNode | Master | Master | 提供文件系统的目录信息,分块信息,数据块的位置信息,管理各个数据服务器。 |
| DataNode | Chunk Server | Chunk Server | 分布式文件系统中的每一个文件,都被切分成若干个数据块,每一个数据块都被存储在不同的服务器上 |
| Block | Chunk | Chunk | 每个文件都会被切分成若干个块(默认64MB),每一块都有连续的一段文件内容,是存储的基本单位。 |
| Packet | 无 | 无 | 累计到Packet后,往文件系统中写入一次 |
| Chunk | 无 | Block(64KB) | 在每一个数据包中,都会将数据切成更小的块(512字节),每一个块配上一个奇偶校验码(CRC),这样的块就是传输块。 |
| Secondary NameNode | 无 | Metalogger | 备用的主控服务器,拉取着主控服务器的日志,等待被扶正 |
核心功能
| 功能 | 说明 |
|---|---|
| Namespace | 命名空间 |
| Shell命令 | 直接和HDFS以及其他Hadoop支持的文件系统进行交互 |
| 数据复制 | |
| 机架感知 | 存放策略是将一个副本存放在本地机架上的节点,一个副本放在同一机架上的另一个节点 |
| Editlog | 是整个日志体系的核心 |
| 集群均衡 | |
| 空间的回收 |
读取文件流程(5个步骤?)
① HDFS Client向远程的Namenode发起RPC请求
② Namenode返回文件的block拷贝的DataNode列表
③ Client选取离客户端近的DataNode读取block
④ 若文件读取还没结束,Client继续向NameNode获取下一批block列表
⑤ 读完后,关闭与DataNode的连接,为读取下一个block寻找最佳DataNode
写入文件流程(5个步骤?写数据的方式是?)
① HDFS Client向远程的Namenode发起RPC请求
② NameNode检查文件是否存在,是否有权操作
③ 将文件切分为多个packets,向NameNode申请新blocks,获取适合存储的DataNode列表
④ 开始以管道的形式将packet写入DataNode,存储后将剩下的传递到下一个DataNode,呈流水线的形式
⑤ 最后的DataNode会返回ack packet,在pipeline里传给Client。Client收到后从ack queue移除相应packet
数据写入流程总结
| 数据写入方式 | 优点 | 不足 |
|---|---|---|
| 链式写入 | 负载均衡 | 链条过长 |
| 主从写入 | 链条短 | 单点压力大 |
相关文章:
大数据系统自检
第一章 大数据计算系统概述 1.1 大数据计算框架概述 Hadoop Hadoop的运行过程(5个步骤?) split > map > shuffle > reduce > output Hadoop的详细运行过程?(4个大过程,6662) 创建…...
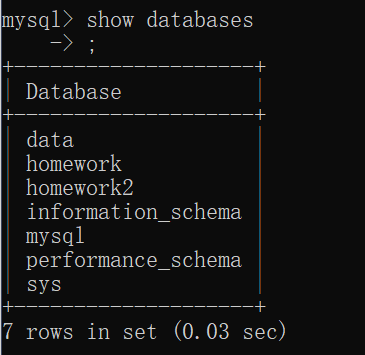
MySQL数据库操作
查看数据库语法show databases——列出所有的数据库 show databases [ like wild ];——列出和字符串wild名字相同的数据库 这里可以配合SQl的 "%" 和 "_" 通配符使用来查找多个数据库在SQL语句中"%"代表任意字符出现任意次数,"_"代表…...
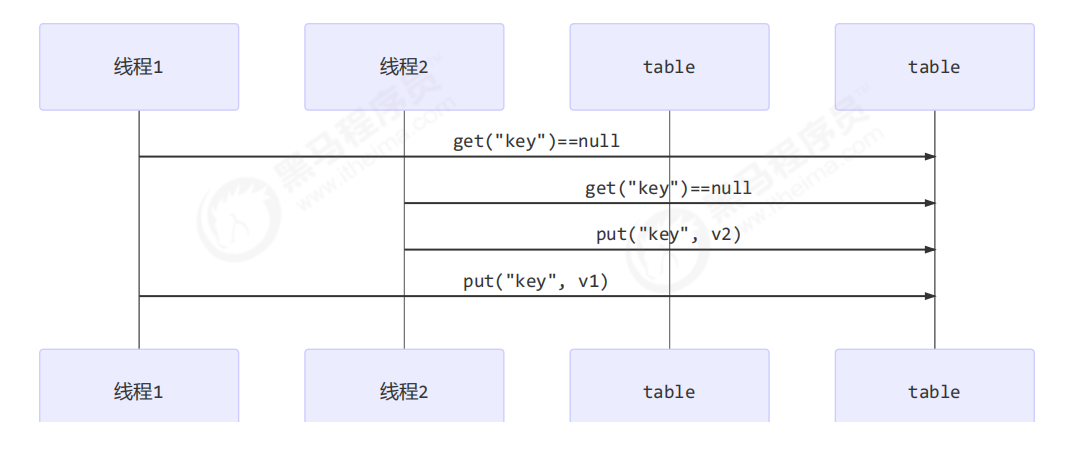
线程安全实例分析
一、变量的线程安全分析 成员变量和静态变量是否线程安全? ● 如果它们没有共享,则线程安全 ● 如果它们被共享了,根据它们的状态是否能够改变,又分两种情况 —— 如果只有读操作,则线程安全 —— 如果有读写操作&am…...
 Catalina初始化)
Tomcat源码分析-启动分析(二) Catalina初始化
Bootstrap Tomcat运行是通过Bootstrap的main方法,在开发工具中,我们只需要运行Bootstrap的main方法,便可以启动tomcat进行代码调试和分析。Bootstrap是tomcat的入口,它会完成初始化ClassLoader,实例化Catalina以及loa…...

基础复习第二十二天 泛型的使用
泛型JDK1.5设计了泛型的概念。泛型即为“类型参数”,这个类型参数在声明它的类、接口或方法中,代表未知的通用的类型。例如:java.lang.Comparable接口和java.util.Comparator接口,是用于对象比较大小的规范接口,这两个…...
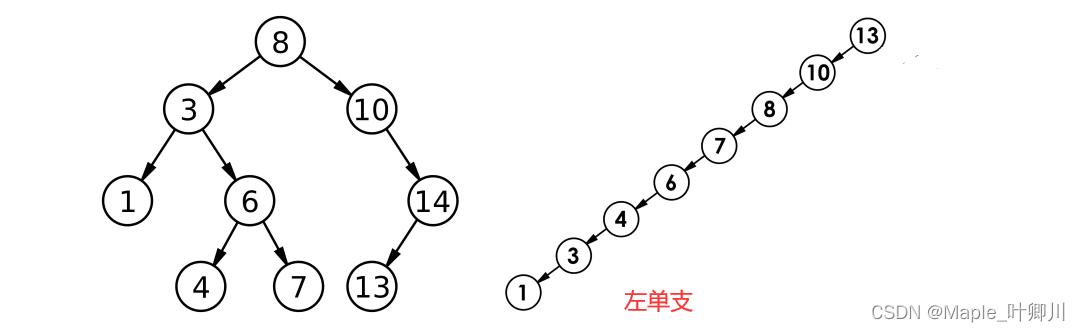
【C++进阶】三、二叉搜索树
目录 一、二叉搜索树 1.1 概念 1.2 二叉搜索树操作 二、二叉搜索树实现 2.1 框架总览 2.2 实现接口总览 2.2.1 构造函数 2.2.2 拷贝构造 2.2.3 赋值重载 2.2.4 析构函数 2.2.5 二叉搜索树的遍历 2.2.6 插入函数 2.2.7 查找函数 2.2.8 删除函数 2.3 二叉搜索数完整…...

电脑系统崩溃怎么修复教程
系统崩溃了怎么办? 如今的软件是越来越复杂、越来越庞大。由系统本身造成的崩溃即使是最简单的操作,比如关闭系统或者是对BIOS进行升级都可能会对PC合操作系统造成一定的影响。下面一起来看看电脑系统崩溃修复方法步骤。 工具/原料: 系统版本…...

语义分割数据标注案例分析
语义分割(Semantic Segmentation)是计算机视觉领域中的一种重要任务,它的目的是将图像中的每个像素分配到对应的语义类别中。简单来说,就是将一张图像分割成多个区域,并为每个像素指定一个标签,标识出它属于…...

回归预测 | MATLAB实现GRU(门控循环单元)多输入单输出(多指标评价)
回归预测 | MATLAB实现GRU(门控循环单元)多输入单输出(多指标评价) 文章目录 回归预测 | MATLAB实现GRU(门控循环单元)多输入单输出(多指标评价)预测效果基本介绍程序设计参考资料预测效果 基本介绍 GRU神经网络是LST...
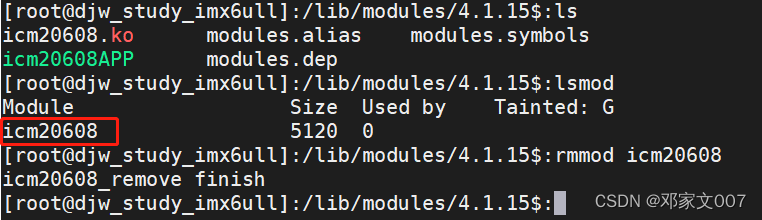
驱动程序开发:Buildroot根文件系统构建并加载驱动文件xxx.ko测试
目录一、buildroot根文件系统简介二、buildroot下载三、buildroot构建根文件系统1、配置 buildroot①配置 Target options②配置 Toolchain③配置 System configuration④配置 Filesystem images⑤禁止编译 Linux 内核和 uboot2、 buildroot 下的 busybox 配置①修改 Makefile&…...

R+VIC模型融合实践技术应用及未来气候变化模型预测
目录 理论专题一:VIC模型的原理及特点 综合案例一:基于QGIS的VIC模型建模 理论专题二:VIC模型率定验证 综合案例二:基于R语言VIC参数率定和优化 理论专题三:遥感技术与未来气候变化 综合案例三:运用V…...

第六章.决策树(Decision Tree)—ID3算法,C4.5算法
第六章.决策树(Decision Tree) 6.1 ID3算法,C4.5算法 1.决策树适用的数据类型 比较适合分析离散数据,如果是连续数据要先转换成离散数据再做分析 2.信息熵 1).概念: 一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常不确…...
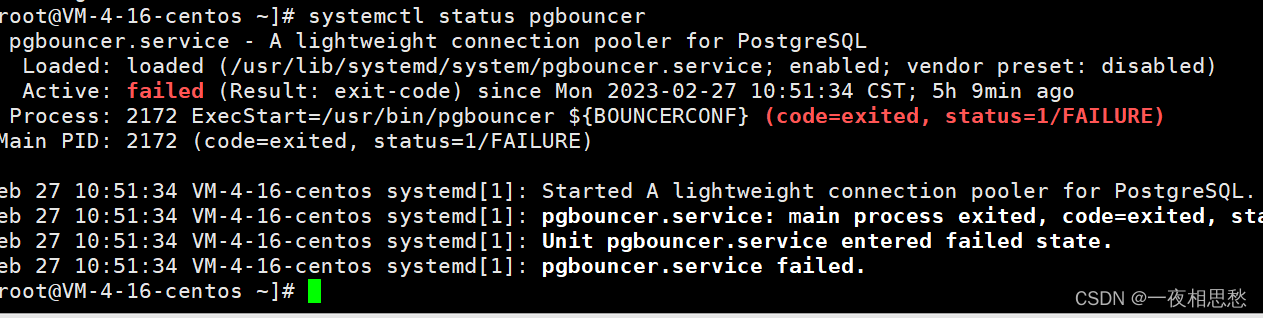
springboot+pgbouncer+postgres数据库连接池集成方案及问题解决
期望通过每一次分享,让技术的门槛变低,落地更容易。 —— around 前言 旨在解决微服务项目全是连接池并影响数据库并发连接,作者的环境是基于sprongboot微服务连接postgres数据库,每个微服务的DAO层配置都使用了连接池技术。后续…...

Mysql 常用日期处理函数
Mysql 常用日期处理函数 1 建表语句 SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS 0; -- ---------------------------- -- Table structure for emp -- ---------------------------- DROP TABLE IF EXISTS emp; CREATE TABLE emp (EMPNO int(4) NOT NULL,ENAME varchar(10…...

Pod中容器的健康检查
健康检查 上篇文章中我们了解了Pod中容器的生命周期的两个钩子函数,PostStart与PreStop,其中PostStart是在容器创建后立即执行的,而PreStop这个钩子函数则是在容器终止之前执行的。除了上面这两个钩子函数以外,还有一项配置会影响…...
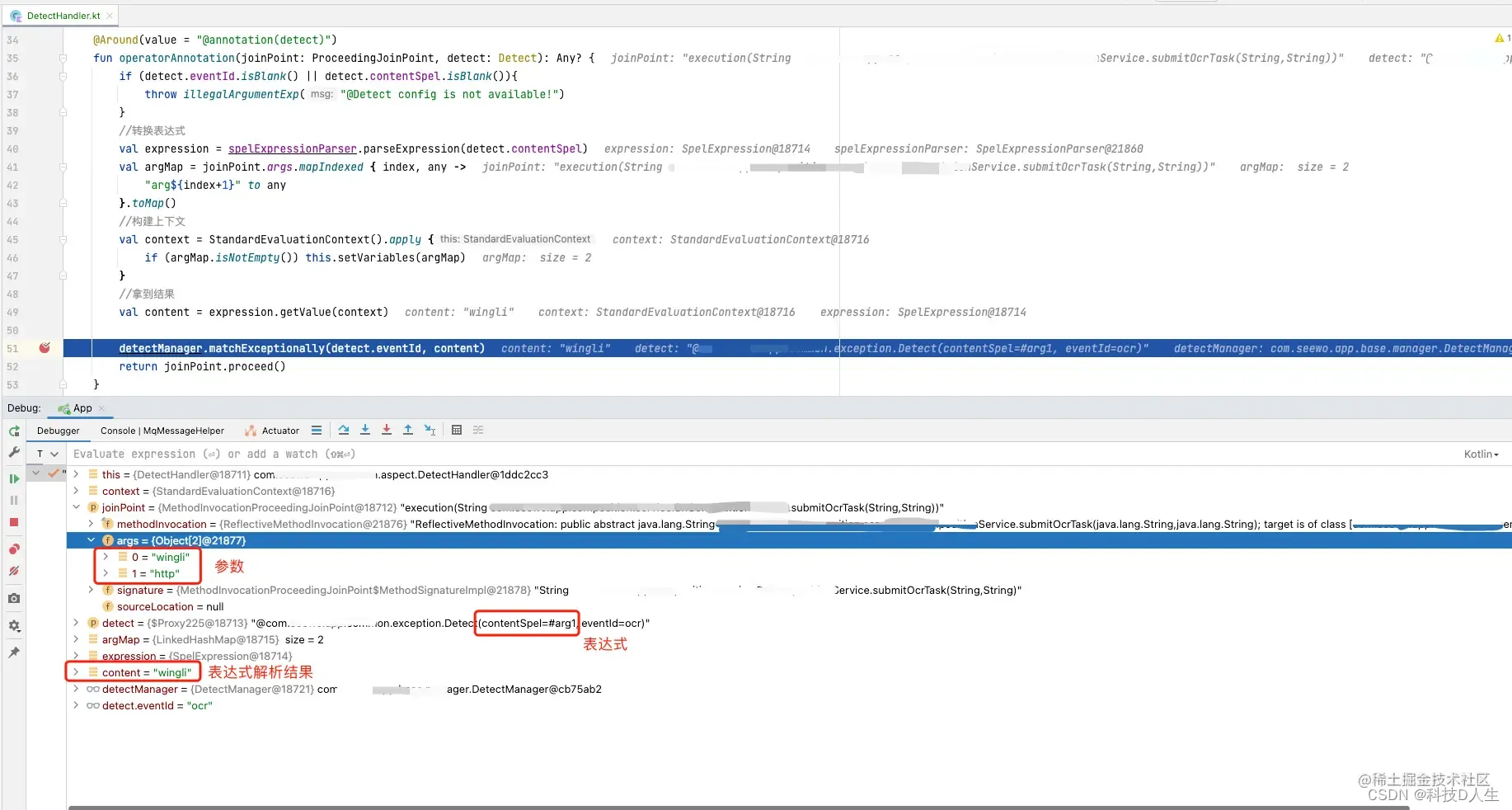
信贷系统学习总结(5)—— 简单的风控示例(含代码)
一、背景1.为什么要做风控?目前我们业务有使用到非常多的AI能力,如ocr识别、语音测评等,这些能力往往都比较费钱或者费资源,所以在产品层面也希望我们对用户的能力使用次数做一定的限制,因此风控是必须的!2.为什么要自己写风控?那么多开源的风控组件,为什么还要写呢?是不是想…...
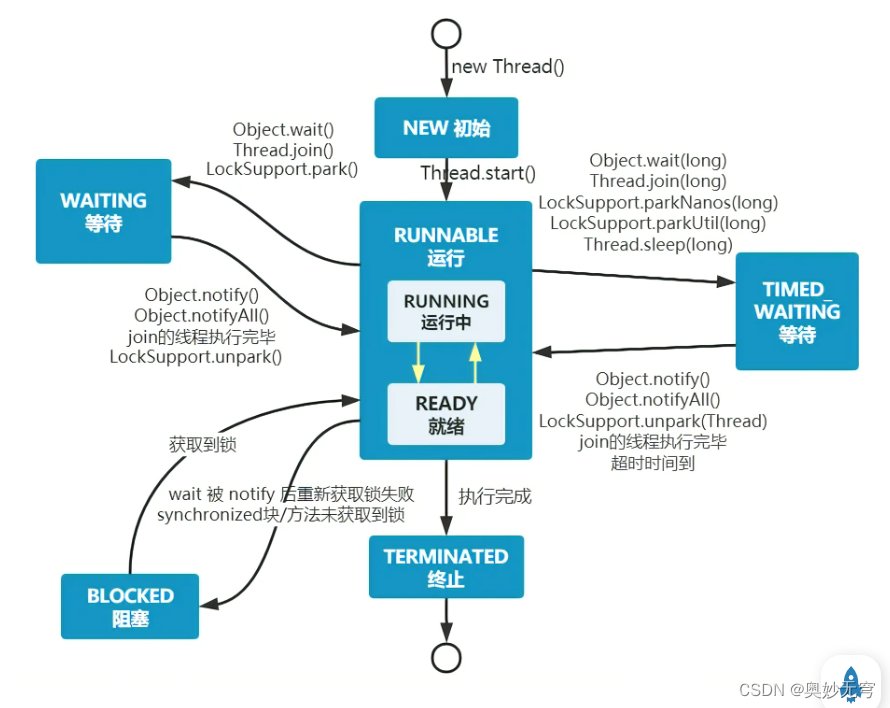
Java知识复习(四)多线程、并发编程
1、进程、线程和程序 进程:进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的;在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程…...

一个9个月测试经验的人,居然在面试时跟我要18K,我都被他吓到了····
2月初我入职了深圳某家创业公司,刚入职还是很兴奋的,到公司一看我傻了,公司除了我一个测试,公司的开发人员就只有3个前端2个后端还有2个UI,在粗略了解公司的业务后才发现是一个从零开始的项目,目前啥都没有…...
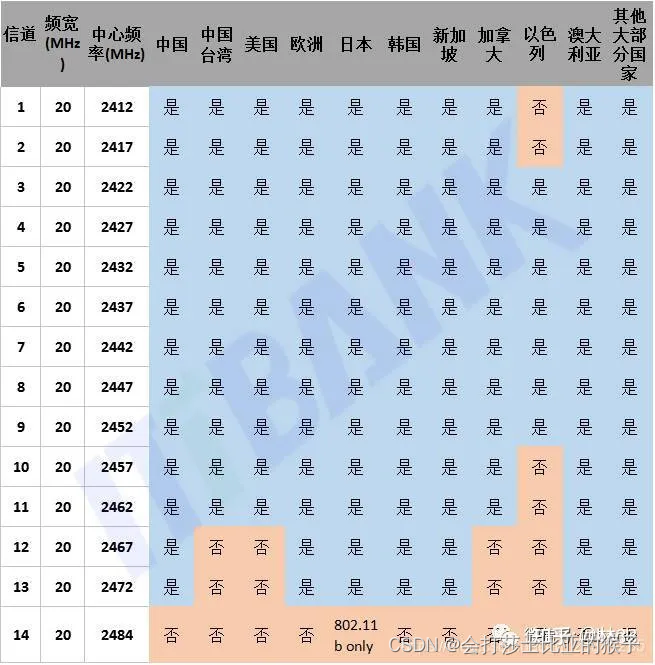
zigbee与WIFI同频干扰问题
zigbee与WIFI同频干扰 为了降低Wifi信道与Zigbee信道的同频干扰问题,Zigbee联盟在《Zigbee Home Automation Public Application Profile》中推荐使用11,14,15,19,20,24,25这七个信道。 为什么呢,我们看一下Wifi和Zigbee的信道分布。 WiFi带宽对干扰的…...
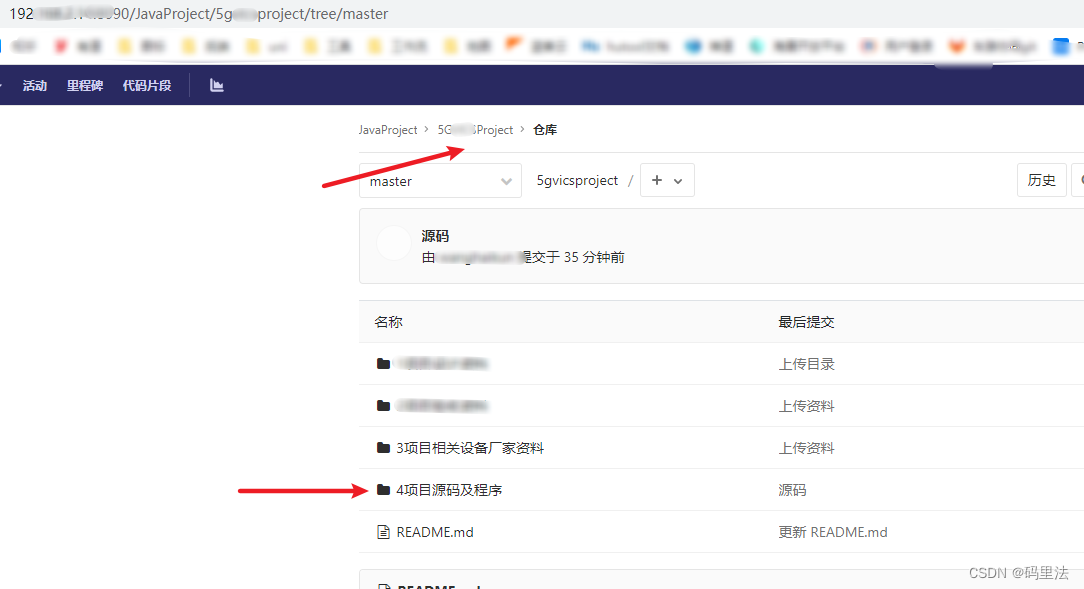
git拉取指定的单个或多个文件或文件夹
直接上步骤 初始化仓库 git init拉取远程仓库信息,省略号为仓库地址 git remote add -f origin http://****.git开启 sparse clone git config core.sparsecheckout true配置需要拉取的文件夹 有一个指定一个,有多个指定多个,路径写对即可&a…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...
)
C#学习第29天:表达式树(Expression Trees)
目录 什么是表达式树? 核心概念 1.表达式树的构建 2. 表达式树与Lambda表达式 3.解析和访问表达式树 4.动态条件查询 表达式树的优势 1.动态构建查询 2.LINQ 提供程序支持: 3.性能优化 4.元数据处理 5.代码转换和重写 适用场景 代码复杂性…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...