针对序列级和词元级应用微调BERT(需修改)
对于序列级和词元级自然语言处理应用,BERT只需要最小的架构改变(额外的全连接层),如单个文本分类(例如,情感分析和测试语言可接受性)、文本对分类或回归(例如,自然语言推断和语义文本相似性)、文本标记(例如,词性标记)和问答。
在下游应用的监督学习期间,额外层的参数是从零开始学习的,而预训练BERT模型中的所有参数都是微调的。
我们可以针对下游应用对预训练的BERT模型进行微调,例如在SNLI数据集上进行自然语言推断。
在微调过程中,BERT模型成为下游应用模型的一部分。仅与训练前损失相关的参数在微调期间不会更新。
在来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客中,我们介绍了一个名为BERT的预训练模型,该模型可以对广泛的自然语言处理任务进行最少的架构更改。一方面,在提出时,BERT改进了各种自然语言处理任务的技术水平。另一方面,原始BERT模型的两个版本分别带有1.1亿和3.4亿个参数。因此,当有足够的计算资源时,我们可以考虑为下游自然语言处理应用微调BERT。
下面,我们将自然语言处理应用的子集概括为序列级和词元级。在序列层次上,介绍了在单文本分类任务和文本对分类(或回归)任务中,如何将文本输入的BERT表示转换为输出标签。在词元级别,我们将简要介绍新的应用,如文本标注和问答,并说明BERT如何表示它们的输入并转换为输出标签。在微调期间,不同应用之间的BERT所需的“最小架构更改”是额外的全连接层。在下游应用的监督学习期间,额外层的参数是从零开始学习的,而预训练BERT模型中的所有参数都是微调的。
1.单文本分类
单文本分类将单个文本序列作为输入,并输出其分类结果。语言可接受性语料库(Corpus of Linguistic Acceptability,COLA)是一个单文本分类的数据集,它的要求判断给定的句子在语法上是否可以接受。 (Warstadt et al., 2019)。例如,“I should study.”是可以接受的,但是“I should studying.”不是可以接受的。
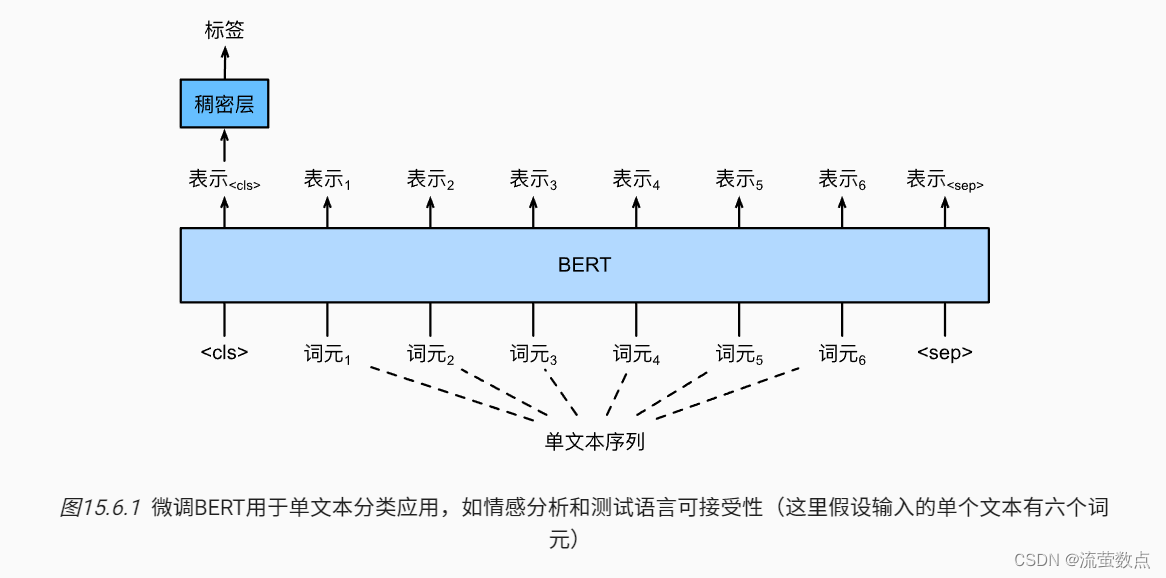
来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客描述了BERT的输入表示。BERT输入序列明确地表示单个文本和文本对,其中特殊分类标记“<cls>”用于序列分类,而特殊分类标记“<sep>”标记单个文本的结束或分隔成对文本。如 图15.6.1所示,在单文本分类应用中,特殊分类标记“<cls>”的BERT表示对整个输入文本序列的信息进行编码。作为输入单个文本的表示,它将被送入到由全连接(稠密)层组成的小多层感知机中,以输出所有离散标签值的分布。
2.文本对分类或回归
自然语言推断属于文本对分类,这是一种对文本进行分类的应用类型。
自然语言推断(natural language inference)主要研究 假设(hypothesis)是否可以从前提(premise)中推断出来, 其中两者都是文本序列。 换言之,自然语言推断决定了一对文本序列之间的逻辑关系。这类关系通常分为三种类型:
蕴涵(entailment):假设可以从前提中推断出来。
矛盾(contradiction):假设的否定可以从前提中推断出来。
中性(neutral):所有其他情况。
自然语言推断也被称为识别文本蕴涵任务。 例如,下面的一个文本对将被贴上“蕴涵”的标签,因为假设中的“表白”可以从前提中的“拥抱”中推断出来。
前提:两个女人拥抱在一起。
假设:两个女人在示爱。
下面是一个“矛盾”的例子,因为“运行编码示例”表示“不睡觉”,而不是“睡觉”。
前提:一名男子正在运行Dive Into Deep Learning的编码示例。
假设:该男子正在睡觉。
第三个例子显示了一种“中性”关系,因为“正在为我们表演”这一事实无法推断出“出名”或“不出名”。
前提:音乐家们正在为我们表演。
假设:音乐家很有名。
自然语言推断一直是理解自然语言的中心话题。它有着广泛的应用,从信息检索到开放领域的问答。
以一对文本作为输入但输出连续值,语义文本相似度是一个流行的“文本对回归”任务。 这项任务评估句子的语义相似度。例如,在语义文本相似度基准数据集(Semantic Textual Similarity Benchmark)中,句子对的相似度得分是从0(无语义重叠)到5(语义等价)的分数区间 (Cer et al., 2017)。我们的目标是预测这些分数。来自语义文本相似性基准数据集的样本包括(句子1,句子2,相似性得分):
-
“A plane is taking off.”(“一架飞机正在起飞。”),”An air plane is taking off.”(“一架飞机正在起飞。”),5.000分;
-
“A woman is eating something.”(“一个女人在吃东西。”),”A woman is eating meat.”(“一个女人在吃肉。”),3.000分;
-
“A woman is dancing.”(一个女人在跳舞。),”A man is talking.”(“一个人在说话。”),0.000分。
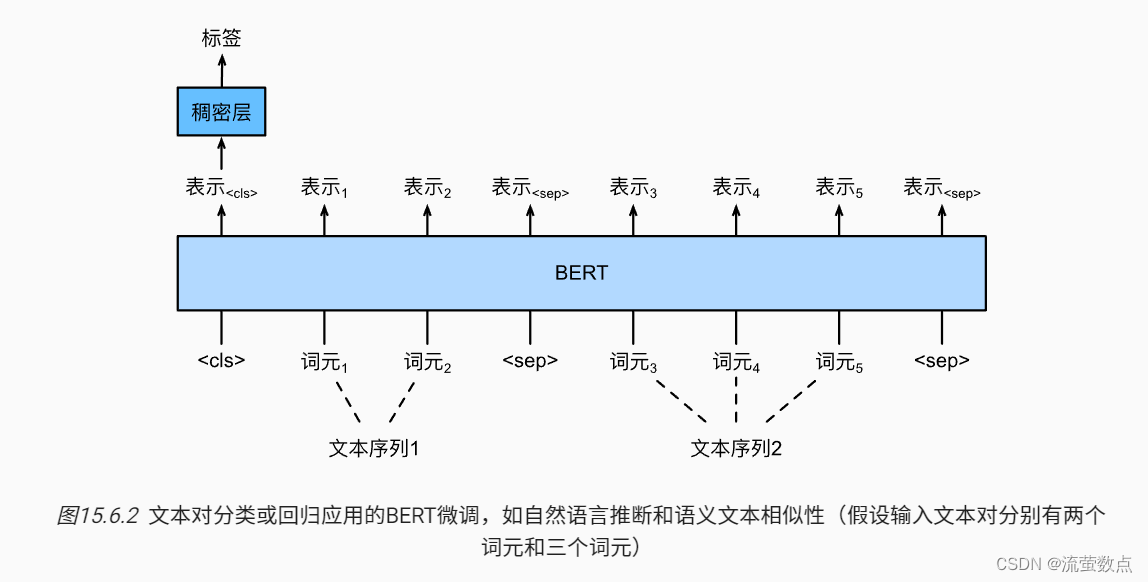
与 图15.6.1中的单文本分类相比, 图15.6.2中的文本对分类的BERT微调在输入表示上有所不同。对于文本对回归任务(如语义文本相似性),可以应用细微的更改,例如输出连续的标签值和使用均方损失:它们在回归中很常见。
3.文本标注
现在让我们考虑词元级任务,比如文本标注(text tagging),其中每个词元都被分配了一个标签。在文本标注任务中,词性标注为每个单词分配词性标记(例如,形容词和限定词)。 根据单词在句子中的作用。如,在Penn树库II标注集中,句子“John Smith‘s car is new”应该被标记为“NNP(名词,专有单数)NNP POS(所有格结尾)NN(名词,单数或质量)VB(动词,基本形式)JJ(形容词)”。
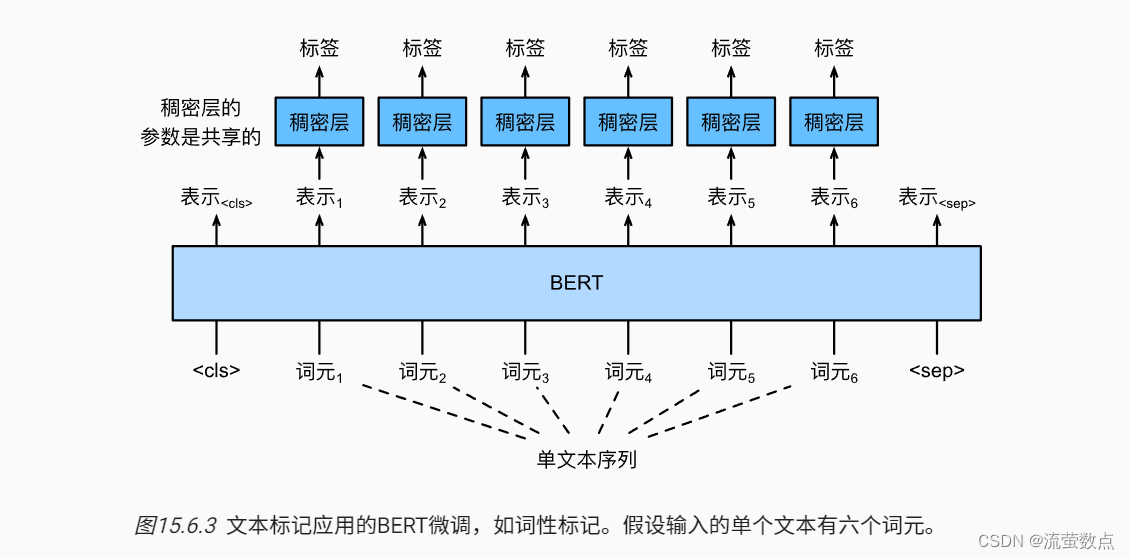
图15.6.3中说明了文本标记应用的BERT微调。与 图15.6.1相比,唯一的区别在于,在文本标注中,输入文本的每个词元的BERT表示被送到相同的额外全连接层中,以输出词元的标签,例如词性标签。
4.问答
作为另一个词元级应用,问答反映阅读理解能力。 例如,斯坦福问答数据集(Stanford Question Answering Dataset,SQuAD v1.1)由阅读段落和问题组成,其中每个问题的答案只是段落中的一段文本(文本片段) (Rajpurkar et al., 2016)。举个例子,考虑一段话:“Some experts report that a mask’s efficacy is inconclusive.However,mask makers insist that their products,such as N95 respirator masks,can guard against the virus.”(“一些专家报告说面罩的功效是不确定的。然而,口罩制造商坚持他们的产品,如N95口罩,可以预防病毒。”)还有一个问题“Who say that N95 respirator masks can guard against the virus?”(“谁说N95口罩可以预防病毒?”)。答案应该是文章中的文本片段“mask makers”(“口罩制造商”)。因此,SQuAD v1.1的目标是在给定问题和段落的情况下预测段落中文本片段的开始和结束。

为了微调BERT进行问答,在BERT的输入中,将问题和段落分别作为第一个和第二个文本序列。为了预测文本片段开始的位置,相同的额外的全连接层将把来自位置i的任何词元的BERT表示转换成标量分数。文章中所有词元的分数还通过softmax转换成概率分布,从而为文章中的每个词元位置i分配作为文本片段开始的概率
。预测文本片段的结束与上面相同,只是其额外的全连接层中的参数与用于预测开始位置的参数无关。当预测结束时,位置i的词元由相同的全连接层变换成标量分数ei。 图15.6.4描述了用于问答的微调BERT。
对于问答,监督学习的训练目标就像最大化真实值的开始和结束位置的对数似然一样简单。当预测片段时,我们可以计算从位置i到位置j的有效片段的分数+
(i≤j),并输出分数最高的跨度。
5.自然语言推断:微调BERT
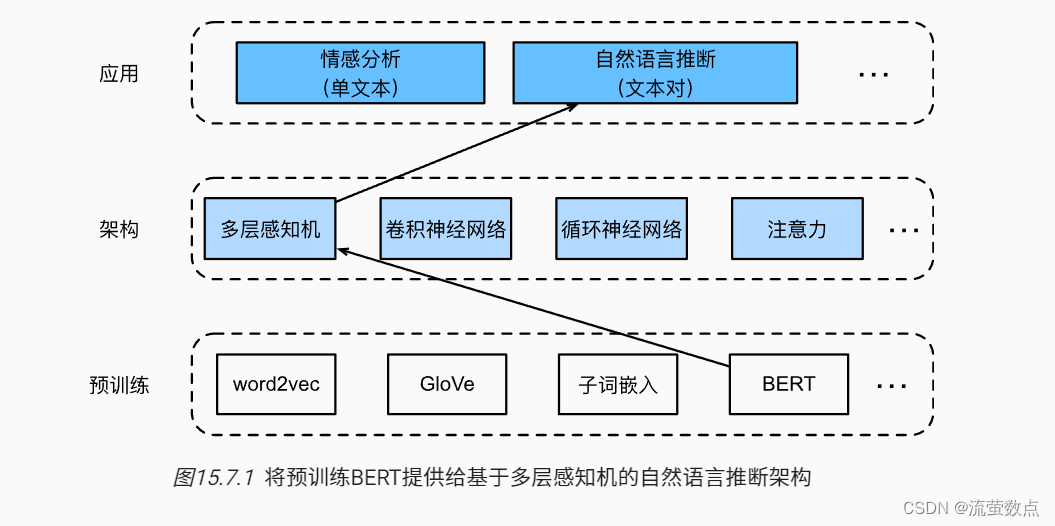
现在,我们通过微调BERT来解决SNLI数据集上的自然语言推断任务。斯坦福自然语言推断语料库(Stanford Natural Language Inference,SNLI)是由500000多个带标签的英语句子对组成的集合 (Bowman et al., 2015)。我们可以在路径https://nlp.stanford.edu/projects/snli/snli_1.0.zip中下载并存储提取的SNLI数据集。自然语言推断是一个序列级别的文本对分类问题,而微调BERT只需要一个额外的基于多层感知机的架构,如 图15.7.1中所示。
本节将下载一个预训练好的小版本的BERT,然后对其进行微调,以便在SNLI数据集上进行自然语言推断。
pip install mxnet==1.7.0.post1pip install d2l==0.17.0import json
import multiprocessing
import os
from mxnet import gluon, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2lnpx.set_np()5.1加载预训练的BERT
我们已经在 预训练BERT_流萤数点的博客-CSDN博客WikiText-2数据集上预训练BERT(请注意,原始的BERT模型是在更大的语料库上预训练的)。正如其中所讨论的,原始的BERT模型有数以亿计的参数。在下面,我们提供了两个版本的预训练的BERT:“bert.base”与原始的BERT基础模型一样大,需要大量的计算资源才能进行微调,而“bert.small”是一个小版本,以便于演示。
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.zip','7b3820b35da691042e5d34c0971ac3edbd80d3f4')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.zip','a4e718a47137ccd1809c9107ab4f5edd317bae2c')两个预训练好的BERT模型都包含一个定义词表的“vocab.json”文件和一个预训练参数的“pretrained.params”文件。我们实现了以下load_pretrained_model函数来加载预先训练好的BERT参数。
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,num_heads, num_layers, dropout, max_len, devices):data_dir = d2l.download_extract(pretrained_model)# 定义空词表以加载预定义词表vocab = d2l.Vocab()vocab.idx_to_token = json.load(open(os.path.join(data_dir,'vocab.json')))vocab.token_to_idx = {token: idx for idx, token in enumerate(vocab.idx_to_token)}bert = d2l.BERTModel(len(vocab), num_hiddens, ffn_num_hiddens,num_heads, num_layers, dropout, max_len)# 加载预训练BERT参数bert.load_parameters(os.path.join(data_dir, 'pretrained.params'),ctx=devices)return bert, vocab为了便于在大多数机器上演示,我们将在本节中加载和微调经过预训练BERT的小版本(“bert.small”)。在练习中,我们将展示如何微调大得多的“bert.base”以显著提高测试精度。
devices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model('bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,num_layers=2, dropout=0.1, max_len=512, devices=devices)Downloading ../data/bert.small.zip from http://d2l-data.s3-accelerate.amazonaws.com/bert.small.zip...
5.2微调BERT的数据集
对于SNLI数据集的下游任务自然语言推断,我们定义了一个定制的数据集类SNLIBERTDataset。在每个样本中,前提和假设形成一对文本序列,并被打包成一个BERT输入序列,如 图15.6.2所示。回想来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客,片段索引用于区分BERT输入序列中的前提和假设。利用预定义的BERT输入序列的最大长度(max_len),持续移除输入文本对中较长文本的最后一个标记,直到满足max_len。为了加速生成用于微调BERT的SNLI数据集,我们使用4个工作进程并行生成训练或测试样本。
class SNLIBERTDataset(gluon.data.Dataset):def __init__(self, dataset, max_len, vocab=None):all_premise_hypothesis_tokens = [[p_tokens, h_tokens] for p_tokens, h_tokens in zip(*[d2l.tokenize([s.lower() for s in sentences])for sentences in dataset[:2]])]self.labels = np.array(dataset[2])self.vocab = vocabself.max_len = max_len(self.all_token_ids, self.all_segments,self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens)print('read ' + str(len(self.all_token_ids)) + ' examples')def _preprocess(self, all_premise_hypothesis_tokens):pool = multiprocessing.Pool(4) # 使用4个进程out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)all_token_ids = [token_ids for token_ids, segments, valid_len in out]all_segments = [segments for token_ids, segments, valid_len in out]valid_lens = [valid_len for token_ids, segments, valid_len in out]return (np.array(all_token_ids, dtype='int32'),np.array(all_segments, dtype='int32'),np.array(valid_lens))def _mp_worker(self, premise_hypothesis_tokens):p_tokens, h_tokens = premise_hypothesis_tokensself._truncate_pair_of_tokens(p_tokens, h_tokens)tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens)token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \* (self.max_len - len(tokens))segments = segments + [0] * (self.max_len - len(segments))valid_len = len(tokens)return token_ids, segments, valid_lendef _truncate_pair_of_tokens(self, p_tokens, h_tokens):# 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置while len(p_tokens) + len(h_tokens) > self.max_len - 3:if len(p_tokens) > len(h_tokens):p_tokens.pop()else:h_tokens.pop()def __getitem__(self, idx):return (self.all_token_ids[idx], self.all_segments[idx],self.valid_lens[idx]), self.labels[idx]def __len__(self):return len(self.all_token_ids)下载完SNLI数据集后,我们通过实例化SNLIBERTDataset类来生成训练和测试样本。这些样本将在自然语言推断的训练和测试期间进行小批量读取。
# 如果出现显存不足错误,请减少“batch_size”。在原始的BERT模型中,max_len=512
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = gluon.data.DataLoader(train_set, batch_size, shuffle=True,num_workers=num_workers)
test_iter = gluon.data.DataLoader(test_set, batch_size,num_workers=num_workers)Downloading ../data/snli_1.0.zip from https://nlp.stanford.edu/projects/snli/snli_1.0.zip... read 549367 examples read 9824 examples
5.3微调BERT
如 图15.6.2所示,用于自然语言推断的微调BERT只需要一个额外的多层感知机,该多层感知机由两个全连接层组成(请参见下面BERTClassifier类中的self.hidden和self.output)。这个多层感知机将特殊的“<cls>”词元的BERT表示进行了转换,该词元同时编码前提和假设的信息为自然语言推断的三个输出:蕴涵、矛盾和中性。
class BERTClassifier(nn.Block):def __init__(self, bert):super(BERTClassifier, self).__init__()self.encoder = bert.encoderself.hidden = bert.hiddenself.output = nn.Dense(3)def forward(self, inputs):tokens_X, segments_X, valid_lens_x = inputsencoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)return self.output(self.hidden(encoded_X[:, 0, :]))在下文中,预训练的BERT模型bert被送到用于下游应用的BERTClassifier实例net中。在BERT微调的常见实现中,只有额外的多层感知机(net.output)的输出层的参数将从零开始学习。预训练BERT编码器(net.encoder)和额外的多层感知机的隐藏层(net.hidden)的所有参数都将进行微调。
net = BERTClassifier(bert)
net.output.initialize(ctx=devices)回想一下,在 来自Transformers的双向编码器表示(BERT)_流萤数点的博客-CSDN博客中,MaskLM类和NextSentencePred类在其使用的多层感知机中都有一些参数。这些参数是预训练BERT模型bert中参数的一部分,因此是net中的参数的一部分。然而,这些参数仅用于计算预训练过程中的遮蔽语言模型损失和下一句预测损失。这两个损失函数与微调下游应用无关,因此当BERT微调时,MaskLM和NextSentencePred中采用的多层感知机的参数不会更新(陈旧的,staled)。
为了允许具有陈旧梯度的参数,标志ignore_stale_grad=True在step函数d2l.train_batch_ch13中被设置。我们通过该函数使用SNLI的训练集(train_iter)和测试集(test_iter)对net模型进行训练和评估。由于计算资源有限,训练和测试精度可以进一步提高:我们把对它的讨论留在练习中。
lr, num_epochs = 1e-4, 5
trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': lr})
loss = gluon.loss.SoftmaxCrossEntropyLoss()
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices, d2l.split_batch_multi_inputs)如果您的计算资源允许,请微调一个更大的预训练BERT模型,该模型与原始的BERT基础模型一样大。修改load_pretrained_model函数中的参数设置:将“bert.small”替换为“bert.base”,将num_hiddens=256、ffn_num_hiddens=512、num_heads=4和num_layers=2的值分别增加到768、3072、12和12。通过增加微调迭代轮数(可能还会调优其他超参数),你可以获得高于0.86的测试精度吗?
相关文章:
针对序列级和词元级应用微调BERT(需修改)
对于序列级和词元级自然语言处理应用,BERT只需要最小的架构改变(额外的全连接层),如单个文本分类(例如,情感分析和测试语言可接受性)、文本对分类或回归(例如,自然语言推…...
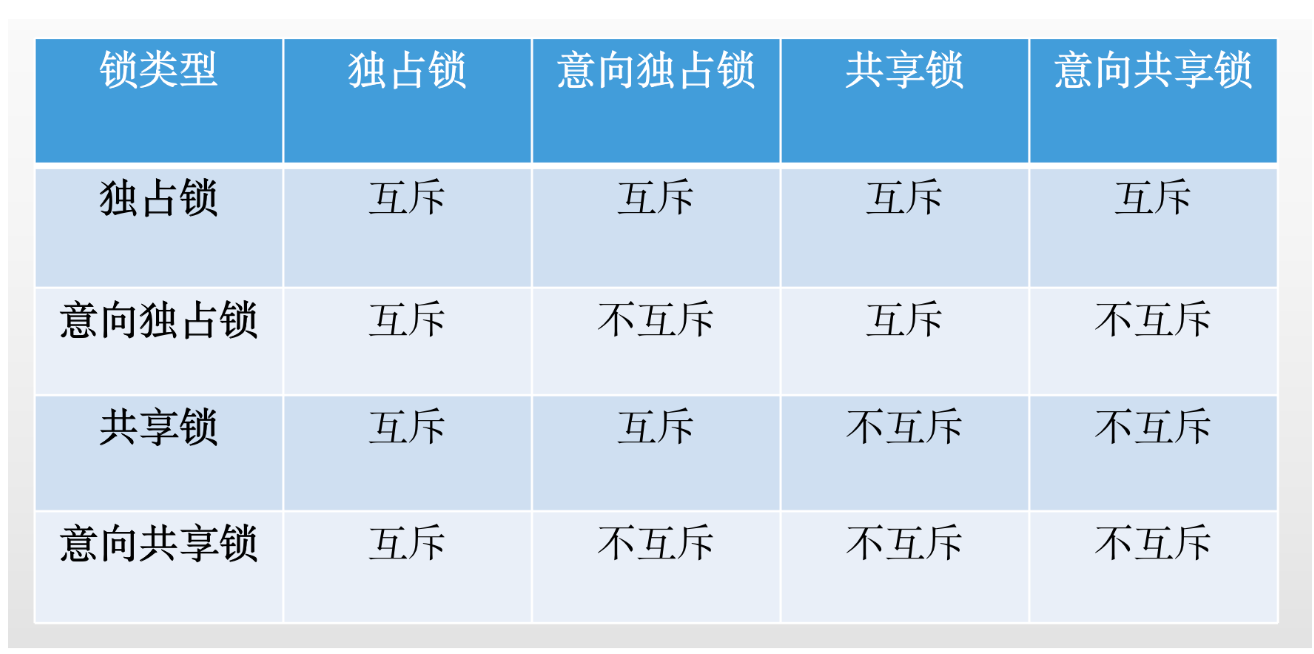
(四十七)大白话表锁和行锁互相之间的关系以及互斥规则是什么呢?
今天我们接着讲,MySQL里是如何加表锁的。这个MySQL的表锁,其实是极为鸡肋的一个东西,几乎一般很少会用到,表锁分为两种,一种就是表锁,一种是表级的意向锁,我们分别来看看。 首先说表锁…...

织梦TXT批量导入TAG标签并自动匹配相关文章插件
织梦TXT批量导入TAG标签并自动匹配相关文章插件是一种非常有用的插件,它可以帮助网站管理员快速地将TAG标签添加到文章中,并自动匹配相关文章。 以下是该织梦TXT批量导入TAG标签插件的几个优点: 1、提高网站的SEO效果:TAG标签是搜…...

Sentinel架构篇 - 10分钟带你看滑动窗口算法的应用
限流算法 以固定时间窗口算法和滑动时间窗口算法为例,展开两种限流算法的分析。 固定时间窗口算法 在固定的时间窗口内,设置允许固定数量的请求进入。如果超过设定的阈值就拒绝请求或者排队。 具体的,按照时间划分为若干个时间窗口&#…...

redis主从复制
<1> redis主从复制介绍: 首先来介绍一下什么是redis主从复制 Redis是一个使用ANSI C编写的开源、支持网络、基于内存、可选持久性的键值对存储数据库。但如果当把数据存储在单个Redis的实例中,当读写体量比较大的时候,服务端就很难承受…...
近期常见组件漏洞更新:
(1)mysql 5.7 在2023年1月17日,发布了到5.7.41版本 mysql 8.0 在2023年1月17日,发布了到8.0.32版本 MySQL :: Download MySQL Community Serverhttps://dev.mysql.com/downloads/mysql/ (2)Tomcat8在202…...

深度学习常用的激活函数总结
各种激活函数总结 目录一、sigmoid二、tanh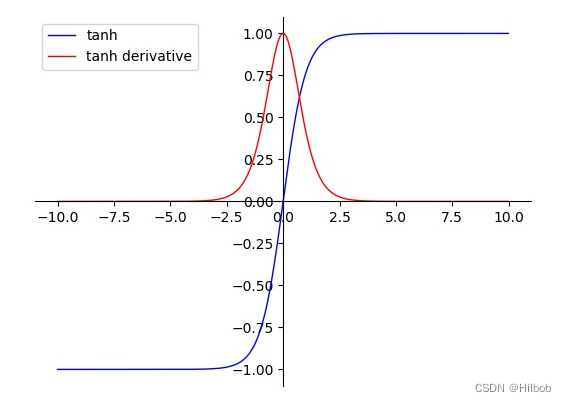三、ReLU系列1.原始ReLU2.ReLU改进:Leaky ReLU四、swish五、GeLU一、sigmoid 优点: 1.可以将任意范围的输出映射到 …...
)
Java编程问题top100---基础语法系列(二)
Java编程问题top100---基础语法系列(二)六、如何测试一个数组是否包含指定的值?简单且优雅的方法:自己动手写逻辑对象数组JDK 8 APIJDK 9 API Set.of()七、重写(Override)equlas和hashCode方法时应考虑的问题理论上讲&…...
网页打印与导出word实现在A4纸上相同效果
在工作中遇到这样一个需求,客户要求: 1、实现在浏览器中打印和导出到word中,要求浏览器打印出来的效果和word中打印的效果基本一致。2、打印的内容要自动分页,第一页的顶部有文件头,最后一页的底部有页尾。 这里记录一…...

备战英语6级——记录复习进度
开始记录—— 学习:如何记录笔记? 1:首先我认为:电脑打字比较适合我! 2:先记笔记,再“填笔记”! 记笔记就是一个框架,记录一个大概的东西。后面需要在笔记中࿰…...
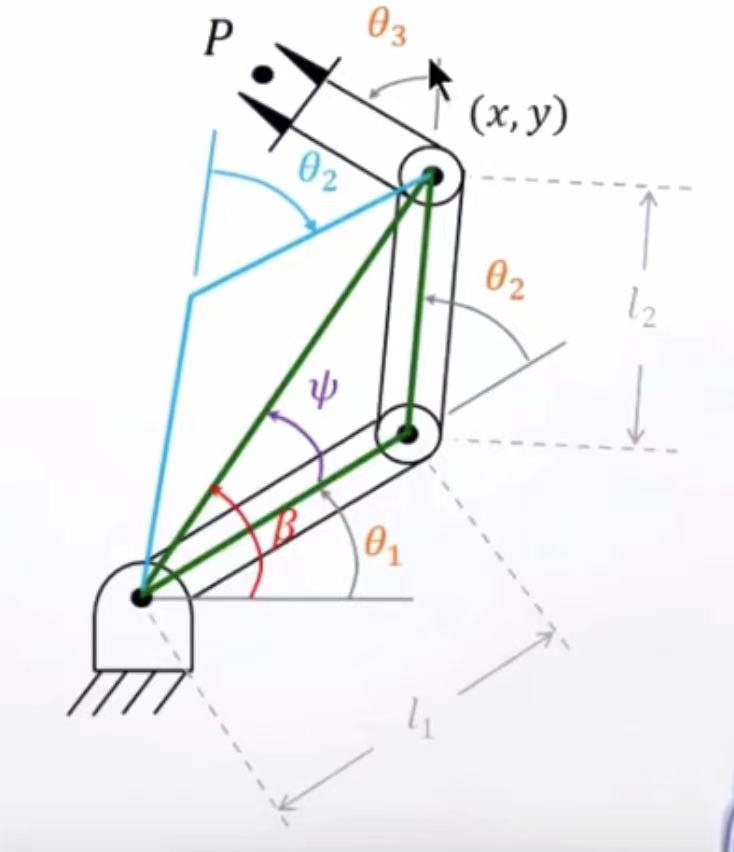
实例10:四足机器人运动学逆解可视化与实践
实例10: 四足机器人运动学逆解单腿可视化 实验目的 了解逆运动学的有无解、有无多解情况。了解运动学逆解的求解。熟悉逆运动学中求解的几何法和代数法。熟悉单腿舵机的简单校准。掌握可视化逆向运动学计算结果的方法。 实验要求 拼装一条mini pupper的腿部。运…...

Elasticsearch7.8.0版本优化——路由选择
目录一、Elasticsearch 如何知道一个文档存放在哪个分片二、不带 routing 查询三、带 routing 查询一、Elasticsearch 如何知道一个文档存放在哪个分片 其实是通过这个公式来计算出来:shard hash(routing) % number_of_primary_shardsrouting 默认值是文档的 id&a…...

Go常量的定义和使用const,const特性“隐式重复前一个表达式”,以及iota枚举常量的使用
Go常量的定义和使用const,以及iota枚举常量的使用Go常量constGo中常量的定义和使用Go特性const,"隐式重复前一个表达式"iota 实现枚举常量Go常量const Go语言中的const整合了C语言中的宏定义常量,const只读变量枚举变量 绝大多数情况下,Go常…...
Git学习(1)pro git阅读
目录 目录: 1. 起步 2. Git 基础 3. Git 分支 4. 服务器上的 Git 5. 分布式 Git 第一章 1.3 Git是什么 1.6运行git前的配置 该开源图书网站 Git - Book (git-scm.com) 目录: 1. 起步 1.1 关于版本控制1.2 Git 简史1.3 Git 是什么?1…...
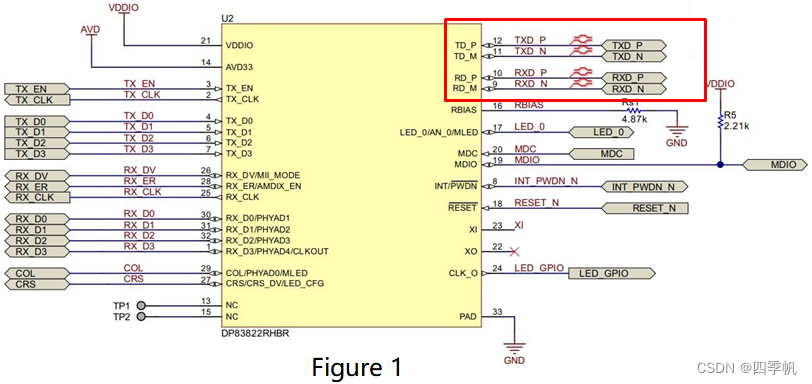
PHY自协商
1. 自协商定义 自动协商模式是端口根据另一端设备的连接速度和双工模式,自动把它的速度调节到最高的公共水平,即线路两端能具有的最快速度和双工模式。 自协商功能允许一个网络设备能够将自己所支持的工作模式信息传达给网络上的对端,并接受对…...

【大数据离线开发】8.2 Hive的安装和配置
8.3 Hive的安装和配置 安装模式: 嵌入模式 :不需要使用MySQL,需要Hive自带的一个关系型数据库:Derby本地模式、远程模式 ----> 需要MySQL数据库的支持 安装 hive 安装包 1、解压tar -zxvf apache-hive-2.3.0-bin.tar.gz -C…...

Capture Modules:车载网络报文捕获模块
(以下所有图片均来源于Technica官网) Technica Engineering的新一代硬件设备,即Capture Modules,提供了五种变体以涵盖不同带宽的车载以太网(100BASE-T1和1000BASE-T1)以及常见的IVN技术(CAN、C…...

数据结构与算法系列之时间与空间复杂度
这里写目录标题算法的复杂度大O的渐进表示法实例分析空间复杂度每日一题算法的复杂度 衡量一个算法的好坏,一般 是从时间和空间两个维度来衡量的, 即时间复杂度和空间复杂度。 时间复杂度主要衡量一个算法的运行快慢, 空间复杂度主要衡量一个…...

Python代码使用PyQt5制作界面并封装
目录参考链接续:https://blog.csdn.net/yulinxx/article/details/93344163 若要对此程序进行封装,加个界面,然后制作成 EXE, 使用 PyQt5 制作界面,PyInstaller 进行封装成 EXE 可参考: Python制作小软件…...
【Node.js】MySQL数据库的第三方模块(mysql)
mysql安装操作MySQL数据库的第三方模块(mysql)通过第三方模块(mysql2)连接到MySQL数据库mysql插入数据mysql插入数据的便捷方式mysql更新数据mysql更新数据的便捷方式mysql删除数据安装操作MySQL数据库的第三方模块(my…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...