Day903.自增主键不能保证连续递增 -MySQL实战
自增主键不能保证连续递增
Hi,我是阿昌,今天学习记录的是关于自增主键不能保证连续递增的内容。
MySql保证了主键是自增,但不相对连续;帮助开发人员快速识别每个行的唯一性,并提高查询效率。
自增主键可以让主键索引尽量地保持递增顺序插入,避免了页分裂,因此索引更紧凑。
之前我见过有的业务设计依赖于自增主键的连续性,也就是说,这个设计假设自增主键是连续的。但实际上,这样的假设是错的,因为自增主键不能保证连续递增。
创建一个表 t,其中 id 是自增主键字段、c 是唯一索引。
CREATE TABLE `t` (`id` int(11) NOT NULL AUTO_INCREMENT,`c` int(11) DEFAULT NULL,`d` int(11) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `c` (`c`)
) ENGINE=InnoDB;
一、自增值保存在哪儿?
在这个空表 t 里面执行 insert into t values(null, 1, 1);
插入一行数据,再执行 show create table 命令,就可以看到如下图所示的结果:
可以看到,表定义里面出现了一个 AUTO_INCREMENT=2,表示下一次插入数据时,如果需要自动生成自增值,会生成 id=2。
其实,这个输出结果容易引起这样的误解:自增值是保存在表结构定义里的。
实际上,表的结构定义存放在后缀名为.frm 的文件中,但是并不会保存自增值。
不同的引擎对于自增值的保存策略不同。
MyISAM引擎的自增值保存在数据文件中。InnoDB引擎的自增值,其实是保存在了内存里,并且到了 MySQL 8.0 版本后,才有了“自增值持久化”的能力,也就是才实现了“如果发生重启,表的自增值可以恢复为 MySQL 重启前的值”,具体情况是:- 在 MySQL 5.7 及之前的版本,自增值
保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值 max(id),然后将 max(id)+1 作为这个表当前的自增值。举例来说,如果一个表当前数据行里最大的 id 是 10,AUTO_INCREMENT=11。这时候,我们删除 id=10 的行,AUTO_INCREMENT 还是 11。但如果马上重启实例,重启后这个表的 AUTO_INCREMENT 就会变成 10。也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。 - 在 MySQL 8.0 版本,将自增值的变更
记录在了 redo log中,重启的时候依靠 redo log 恢复重启之前的值。
- 在 MySQL 5.7 及之前的版本,自增值
二、自增值修改机制
在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下:
- 如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段;
- 如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。
根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。
假设,某次要插入的值是 X,当前的自增值是 Y。
- 如果 X<Y,那么这个表的自增值不变;
- 如果 X≥Y,就需要把当前自增值修改为新的自增值。
新的自增值生成算法是:从 auto_increment_offset 开始,以 auto_increment_increment 为步长,持续叠加,直到找到第一个大于 X 的值,作为新的自增值。
其中,auto_increment_offset 和 auto_increment_increment 是两个系统参数,分别用来表示自增的初始值和步长,默认值都是 1。
备注:在一些场景下,使用的就不全是默认值。比如,双 M 的主备结构里要求双写的时候,我们就可能会设置成 auto_increment_increment=2,让一个库的自增 id 都是奇数,另一个库的自增 id 都是偶数,避免两个库生成的主键发生冲突。
当 auto_increment_offset 和 auto_increment_increment 都是 1 的时候,新的自增值生成逻辑很简单,就是:
- 如果准备插入的值 >= 当前自增值,新的自增值就是“准备插入的值 +1”;
- 否则,自增值不变。
三、自增值的修改时机
在这两个参数都设置为 1 的时候,自增主键 id 却不能保证是连续的,这是什么原因呢?
假设,表 t 里面已经有了 (1,1,1) 这条记录,这时再执行一条插入数据命令:
insert into t values(null, 1, 1);
这个语句的执行流程就是:
- 执行器调用 InnoDB 引擎接口写入一行,传入的这一行的值是 (0,1,1);
- InnoDB 发现用户没有指定自增 id 的值,获取表 t 当前的自增值 2;
- 将传入的行的值改成 (2,1,1);
- 将表的自增值改成 3;
- 继续执行插入数据操作,由于已经存在 c=1 的记录,所以报 Duplicate key error,语句返回。
对应的执行流程图如下:

可以看到,这个表的自增值改成 3,是在真正执行插入数据的操作之前。
这个语句真正执行的时候,因为碰到唯一键 c 冲突,所以 id=2 这一行并没有插入成功,但也没有将自增值再改回去。
所以,在这之后,再插入新的数据行时,拿到的自增 id 就是 3。
也就是说,出现了自增主键不连续的情况。
如图 3 所示就是完整的演示结果。

可以看到,这个操作序列复现了一个自增主键 id 不连续的现场 (没有 id=2 的行)。
可见,唯一键冲突是导致自增主键 id 不连续的第一种原因。
同样地,事务回滚也会产生类似的现象,这就是第二种原因。
下面这个语句序列就可以构造不连续的自增 id,可以自己验证一下。
insert into t values(null,1,1);
begin;
insert into t values(null,2,2);
rollback;
insert into t values(null,2,2);
//插入的行是(3,2,2)
为什么在出现唯一键冲突或者回滚的时候,MySQL 没有把表 t 的自增值改回去呢?
如果把表 t 的当前自增值从 3 改回 2,再插入新数据的时候,不就可以生成 id=2 的一行数据了吗?其实,MySQL 这么设计是为了提升性能。
假设有两个并行执行的事务,在申请自增值的时候,为了避免两个事务申请到相同的自增 id,肯定要加锁,然后顺序申请。
- 假设事务 A 申请到了 id=2, 事务 B 申请到 id=3,那么这时候表 t 的自增值是 4,之后继续执行。
- 事务 B 正确提交了,但事务 A 出现了唯一键冲突。
- 如果允许事务 A 把自增 id 回退,也就是把表 t 的当前自增值改回 2,那么就会出现这样的情况:表里面已经有 id=3 的行,而当前的自增 id 值是 2。
- 接下来,继续执行的其他事务就会申请到 id=2,然后再申请到 id=3。这时,就会出现插入语句报错“主键冲突”。
而为了解决这个主键冲突,有两种方法:
- 每次申请 id 之前,先判断表里面是否已经存在这个 id。如果存在,就跳过这个 id。但是,这个方法的成本很高。因为,本来申请 id 是一个很快的操作,现在还要再去主键索引树上
判断 id 是否存在。 - 把自增 id 的锁范围扩大,
必须等到一个事务执行完成并提交,下一个事务才能再申请自增 id。这个方法的问题,就是锁的粒度太大,系统并发能力大大下降。
可见,这两个方法都会导致性能问题。造成这些麻烦的罪魁祸首,就是我们假设的这个“允许自增 id 回退”的前提导致的。
因此,InnoDB 放弃了这个设计,语句执行失败也不回退自增 id。
也正是因为这样,所以才只保证了自增 id 是递增的,但不保证是连续的。
四、自增锁的优化
可以看到,自增 id 锁并不是一个事务锁,而是每次申请完就马上释放,以便允许别的事务再申请。其实,在 MySQL 5.1 版本之前,并不是这样的。
在 MySQL 5.0 版本的时候,自增锁的范围是语句级别。也就是说,如果一个语句申请了一个表自增锁,这个锁会等语句执行结束以后才释放。显然,这样设计会影响并发度。
MySQL 5.1.22 版本引入了一个新策略,新增参数 innodb_autoinc_lock_mode,默认值是 1。
- 这个参数的值被设置为 0 时,表示采用之前 MySQL 5.0 版本的策略,即语句执行结束后才释放锁;
- 这个参数的值被设置为 1 时:
- 普通 insert 语句,自增锁在申请之后就马上释放;
- 类似 insert … select 这样的批量插入数据的语句,自增锁还是要等语句结束后才被释放;
- 这个参数的值被设置为 2 时,所有的申请自增主键的动作都是申请后就释放锁。
为什么默认设置下,insert … select 要使用语句级的锁?为什么这个参数的默认值不是 2?
答案是,这么设计还是为了数据的一致性。
一起来看一下这个场景:

在这个例子里,我往表 t1 中插入了 4 行数据,然后创建了一个相同结构的表 t2,然后两个 session 同时执行向表 t2 中插入数据的操作。你可以设想一下,如果 session B 是申请了自增值以后马上就释放自增锁,那么就可能出现这样的情况:
- session B 先插入了两个记录,(1,1,1)、(2,2,2);
- 然后,session A 来申请自增 id 得到 id=3,插入了(3,5,5);
- 之后,session B 继续执行,插入两条记录 (4,3,3)、 (5,4,4)。
你可能会说,这也没关系吧,毕竟 session B 的语义本身就没有要求表 t2 的所有行的数据都跟 session A 相同。
是的,从数据逻辑上看是对的。但是,如果我们现在的 binlog_format=statement,可以设想下,binlog 会怎么记录呢?
由于两个 session 是同时执行插入数据命令的,所以 binlog 里面对表 t2 的更新日志只有两种情况:要么先记 session A 的,要么先记 session B 的。
但不论是哪一种,这个 binlog 拿去从库执行,或者用来恢复临时实例,备库和临时实例里面,session B 这个语句执行出来,生成的结果里面,id 都是连续的。这时,这个库就发生了数据不一致。你可以分析一下,出现这个问题的原因是什么?其实,这是因为原库 session B 的 insert 语句,生成的 id 不连续。
这个不连续的 id,用 statement 格式的 binlog 来串行执行,是执行不出来的。而要解决这个问题,有两种思路:
- 一种思路是,让原库的批量插入数据语句,固定生成连续的 id 值。所以,
自增锁直到语句执行结束才释放,就是为了达到这个目的。 - 另一种思路是,在 binlog 里面把插入数据的操作都
如实记录进来,到备库执行的时候,不再依赖于自增主键去生成。这种情况,其实就是 innodb_autoinc_lock_mode 设置为 2,同时 binlog_format 设置为 row。
因此,在生产上,尤其是有 insert … select 这种批量插入数据的场景时,从并发插入数据性能的角度考虑,建议你这样设置:innodb_autoinc_lock_mode=2 ,并且 binlog_format=row. 这样做,既能提升并发性,又不会出现数据一致性问题。
需要注意的是,这里说的批量插入数据,包含的语句类型是 insert … select、replace … select 和 load data 语句。但是,在普通的 insert 语句里面包含多个 value 值的情况下,即使 innodb_autoinc_lock_mode 设置为 1,也不会等语句执行完成才释放锁。
因为这类语句在申请自增 id 的时候,是可以精确计算出需要多少个 id 的,然后一次性申请,申请完成后锁就可以释放了。
也就是说,批量插入数据的语句,之所以需要这么设置,是因为“不知道要预先申请多少个 id”。
既然预先不知道要申请多少个自增 id,那么一种直接的想法就是需要一个时申请一个。但如果一个 select … insert 语句要插入 10 万行数据,按照这个逻辑的话就要申请 10 万次。
显然,这种申请自增 id 的策略,在大批量插入数据的情况下,不但速度慢,还会影响并发插入的性能。
因此,对于批量插入数据的语句,MySQL 有一个批量申请自增 id 的策略:
- 语句执行过程中,第一次申请自增 id,会分配 1 个;
- 1 个用完以后,这个语句第二次申请自增 id,会分配 2 个;
- 2 个用完以后,还是这个语句,第三次申请自增 id,会分配 4 个;
- 依此类推,
同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。
举个例子,这个语句序列:
insert into t values(null, 1,1);
insert into t values(null, 2,2);
insert into t values(null, 3,3);
insert into t values(null, 4,4);
create table t2 like t;
insert into t2(c,d) select c,d from t;
insert into t2 values(null, 5,5);
insert…select,实际上往表 t2 中插入了 4 行数据。但是,这四行数据是分三次申请的自增 id,第一次申请到了 id=1,第二次被分配了 id=2 和 id=3, 第三次被分配到 id=4 到 id=7。由于这条语句实际只用上了 4 个 id,所以 id=5 到 id=7 就被浪费掉了。
之后,再执行 insert into t2 values(null, 5,5),实际上插入的数据就是(8,5,5)。这是主键 id 出现自增 id 不连续的第三种原因。
五、总结
在 MyISAM 引擎里面,自增值是被写在数据文件上的。而在 InnoDB 中,自增值是被记录在内存的。MySQL 直到 8.0 版本,才给 InnoDB 表的自增值加上了持久化的能力,确保重启前后一个表的自增值不变。
自增值改变的时机,分析了为什么 MySQL 在事务回滚的时候不能回收自增 id。MySQL 5.1.22 版本开始引入的参数 innodb_autoinc_lock_mode,控制了自增值申请时的锁范围。
从并发性能的角度考虑,建议你将其设置为 2,同时将 binlog_format 设置为 row。binlog_format 设置为 row,是很有必要的。
在最后一个例子中,执行 insert into t2(c,d) select c,d from t; 这个语句的时候,如果隔离级别是可重复读(repeatable read),binlog_format=statement。
这个语句会对表 t 的所有记录和间隙加锁。觉得为什么需要这么做呢?
假如原库不对t表所有记录和间隙加锁,如果有其他事物新增数据并先与这个批量操作提交,由于事物的隔离级别是可重复读,t2是看不到新增的数据的。但是记录的binlog是statement格式,备库或基于binlog恢复的临时库,t2会看到新增的数据,出现数据不一致的情况。
相关文章:
Day903.自增主键不能保证连续递增 -MySQL实战
自增主键不能保证连续递增 Hi,我是阿昌,今天学习记录的是关于自增主键不能保证连续递增的内容。 MySql保证了主键是自增,但不相对连续;帮助开发人员快速识别每个行的唯一性,并提高查询效率。 自增主键可以让主键索引…...
02-MyBatis查询-
文章目录Mybatis CRUD练习1,配置文件实现CRUD1.1 环境准备Debug01: 别名mybatisx报错1.2 查询所有数据1.2.1 编写接口方法1.2.2 编写SQL语句1.2.3 编写测试方法1.2.4 起别名解决上述问题1.2.5 使用resultMap解决上述问题1.2.6 小结1.3 查询详情1.3.1 编写接口方法1.…...

外盘国际期货招商:2023年3月关注日历,把握重要投资机会
2023年3月大事件日历 关注大事日历,把握重要投资机会 3月1日:马斯克推出特斯拉宏图第三篇章 3月1-2日:G20外长会议 3月4-5日:全国两会召开 3月9日:中国2月CPI、PPI数据 待定(前次进行日期:…...
Linux学习(9.1)文件系统的简单操作
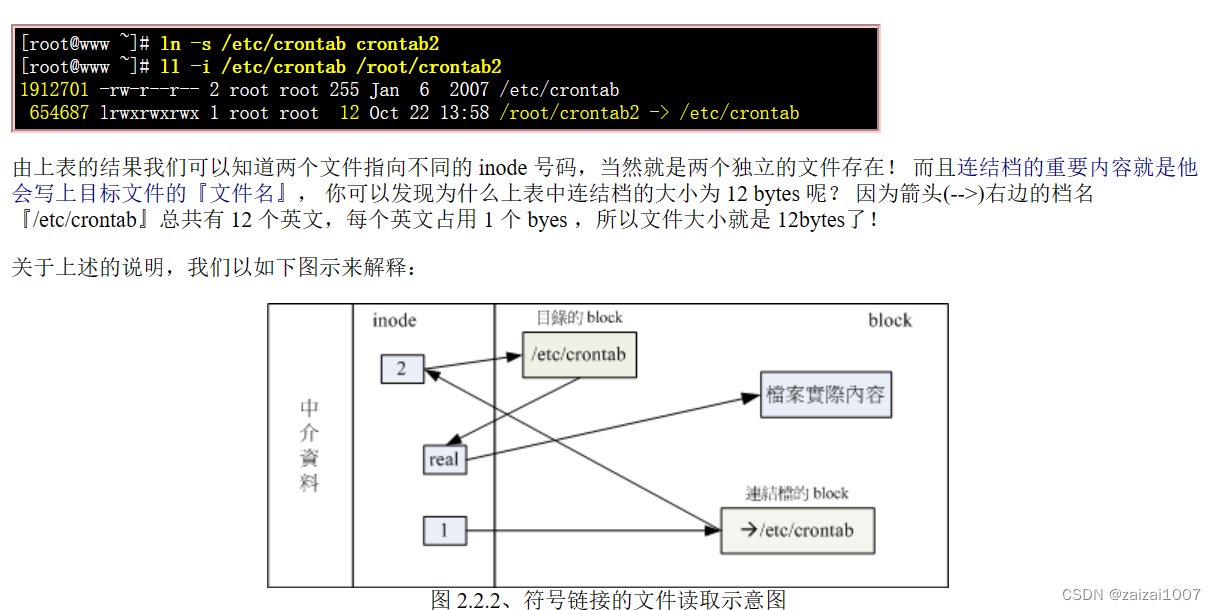
以下内容转载自鸟哥的Linux私房菜 原文:鸟哥的 Linux 私房菜 -- Linux 磁盘与文件系统管理 (vbird.org) 磁盘与目录的容量 df:列出文件系统的整体磁盘使用量;du:评估文件系统的磁盘使用量(常用在推估目录所占容量) df du 实体…...

Hadoop综合案例 - 聊天软件数据
目录1、聊天软件数据分析案例需求2、基于Hive数仓实现需求开发2.1 建库2.2 建表2.3 加载数据2.4 ETL数据清洗2.5 需求指标统计---都很简单3、FineBI实现可视化报表3.1 FineBI介绍3.2 FineBI配置数据3.3 构建可视化报表1、聊天软件数据分析案例需求 MR速度慢—引入hive 背景&a…...

Python进阶-----面向对象1.0(对象和类的介绍、定义)
目录 前言: 面向过程和面向对象 类和对象 Python中类的定义 (1)类的定义形式 (2)深层剖析类对象 前言: 感谢各位的一路陪伴,我学习Python也有一个月了,在这一个月里我收获满满…...

天猫淘宝企业服务为中小微企业打造供应链智能协同网络,让采购不再将就!丨爱分析报告
编者按:近日天猫淘宝企业服务&爱分析联合发布《2023中小微企业电商采购白皮书》,为中小微企业采购数字化带来红利。 某水泵企业:线上客户主要是中小微企业,线上业绩遇到瓶颈,如何突破呢?某焊割设备企业…...

基于四信网络摄像机的工业自动化应用
方案背景 随着数控机床被广泛的应用在工业生产中,数控技术发展成为制造业的核心。 鉴于数控机床的复杂性,以及企业人力储备有限,设备的监控和维护必须借助外部力量,而如何实现车间实时监测成了目前迫切解决的问题。 方案需求 ①兼…...

软件测试2
一 web掐断三大核心技术 HTML:负责网页的结构 CSS:负责网页的美化 JS:负责网页的行为 二 工具的使用 改变HBuilder文字的大小: 工具-视觉主题设置-大小22-确定 三 html简介 中文定义:超文本标记语言 新建一个html…...
leetcode162. 寻找峰值)
(二分查找)leetcode162. 寻找峰值
文章目录一、题目1、题目描述2、基础框架3、原题链接二、解题报告1、思路分析2、时间复杂度3、代码详解三、本题小知识一、题目 1、题目描述 峰值元素是指其值严格大于左右相邻值的元素。 给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值…...
spring boot 配合element ui vue实现表格的批量删除(前后端详细教学,简单易懂,有手就行)
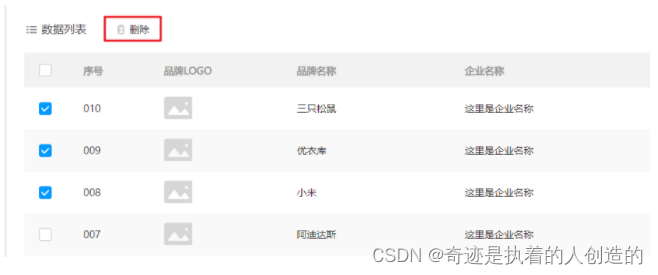
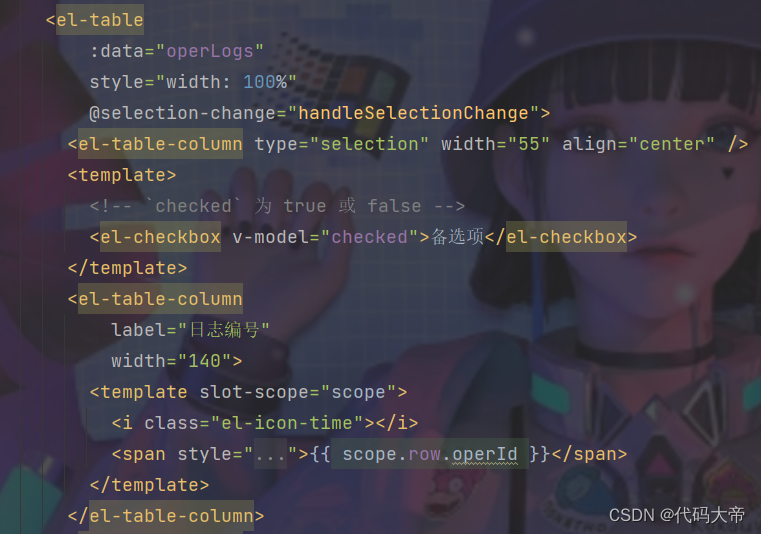
目录 一.前言: 二. 前端代码: 2.1.element ui组件代码 2.2删除按钮 2.3.data 2.4.methods 三.后端代码: 一.前言: 研究了其他人的博客,找到了一篇有含金量的,进行了部分改写实现前后端分离࿰…...
hiveSQL开窗函数详解
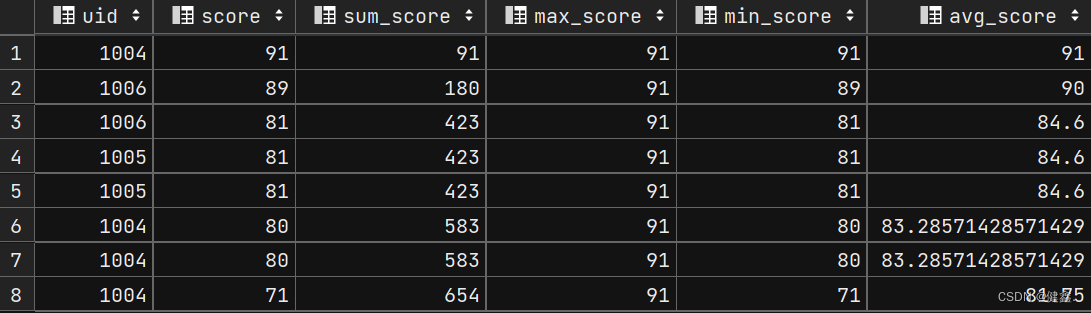
hive开窗函数 文章目录hive开窗函数1. 开窗函数概述1.1 窗口函数分类1.2 窗口函数和普通聚合函数的区别2. 窗口函数的基本用法2.1 基本用法2.2 设置窗口的方法2.2.1 window_name2.2.2 partition by2.2.3 order by 子句2.2.4 rows指定窗口大小窗口框架2.3 开窗函数中加 order by…...

深度学习基础实例与总结
一、神经网络 1 深度学习 1 什么是深度学习? 简单来说,深度学习就是一种包括多个隐含层 (越多即为越深)的多层感知机。它通过组合低层特征,形成更为抽象的高层表示,用以描述被识别对象的高级属性类别或特征。 能自生成数据的中…...

在 WIndows 下安装 Apache Tinkerpop (Gremlin)
一、安装 JDK 首先安装 Java JDK,这个去官网下载即可,我下载安装的 JDK19(jdk-19_windows-x64_bin.msi),细节不赘述。 二、去 Tinkerpop 网站下载 Gremlin 网址:https://tinkerpop.apache.org/ 点击下面…...

从软件的角度看待PCI和PCIE(一)
1.最容易访问的设备是什么? 是内存! 要读写内存,知道它的地址就可以了,不需要什么驱动程序; volatile unsigned int *p 0xffff8811; unsigned int val; *p val; val *p;只有内存能这样简单、方便的使用吗…...

DSP_TMS320F28377D_ADC学习笔记
前言 DSP各种模块的使用,基本上就是 GPIO复用配置、相关控制寄存器的配置、中断的配置。本文主要记录本人对ADC模块的学习笔记。TMS320F28377D上面有24路ADC专用IO,这意味着不需要进行GPIO复用配置。 只需要考虑相关控制寄存器和中断的配置。看代码请直…...
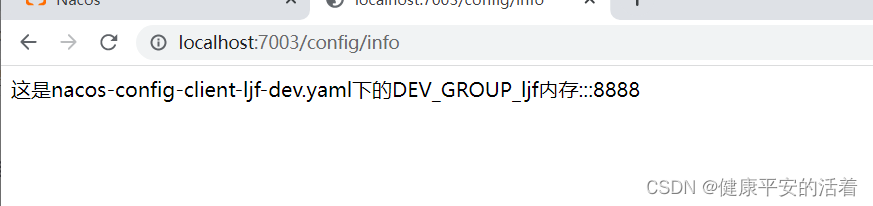
springcloud3 Nacos中namespace和group,dataId的联系
一 Namespance和group和dataId的联系 1.1 3者之间的联系 话不多说,上答案,如下图: namespance用于区分部署环境,group和dataId用于逻辑上区分两个目标对象。 二 案例:实现读取注册中心的不同环境下的配置文件 …...
[YOLO] yolo理解博客笔记
YOLO v2和V3 关于设置生成anchorbox,Boundingbox边框回归的过程详细解读 YOLO v2和V3 关于设置生成anchorbox,Boundingbox边框回归的个人理解https://blog.csdn.net/shenkunchang1877/article/details/105648111YOLO v1网络结构计算 Yolov1-pytorch版 …...

清华源pip安装Python第三方包
一、更换PIP源PIP源在国外,速度慢,可以更换为国内源,以下是国内一些常用的PIP源。豆瓣(douban) http://pypi.douban.com/simple/ (推荐)清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/阿里云 http://mirrors.aliyun.com/pypi/simple/中…...

python线程池【ThreadPoolExecutor()】批量获取博客园标题数据
转载:蚂蚁学python 网址:【【2021最新版】Python 并发编程实战,用多线程、多进程、多协程加速程序运行】 https://www.bilibili.com/video/BV1bK411A7tV/?p8&share_sourcecopy_web&vd_sourced0ef3d08fdeef1740bab49cdb3e96467实战案…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...