Mysql数据库09——分组聚合函数
类似pandas里面的groupby函数,SQL里面的GROUP BY子句也是可以达到分组聚合的效果。
常用的聚合函数有COUNT(),SUM(),AVG(),MAX(),MIN(),其用法看名字都看的出来,下面一一介绍
聚合函数
COUNT()计数
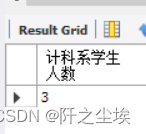
统计student表中计科系学生的人数。
SELECT COUNT(*) AS 计科系学生人数
FROM student WHERE institute='计算机学院';
COUNT函数的参数都是星号(*),除了星号可以当COUNT函数的参数以外,字段名也可以当函数参数。当字段名作为函数参数时,如果该字段中没有NULL值,则与星号作函数参数的效果相同。而如果字段中含有NULL值,加上DISTINCT函数,则统计个数时会排除含有NULL值的记录,请看下面的例子。
从foreign_teacher表中,统计外籍教师的所有人数、拥有电话的人数和拥有email的教师人数。
SELECT COUNT(*) AS 外籍教师总人数, COUNT(DISTINCT tel) AS 有电话的人数,
COUNT(DISTINCT email) AS 有email的人数 FROM foreign_teacher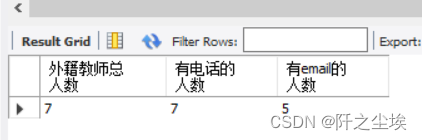
统计外籍教师中,没有email的教师人数。
分析:统计没有email的教师人数,其实就是在统计该字段上有几个NULL值。下面是具体的解决办法。
SELECT COUNT(*) AS 没有email的人数
FROM foreign_teacher
WHERE email IS NULL; 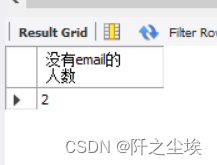
使用SUM函数求某字段的和
在course表中,求所有课程的总学分。
求所有课程的总学分,就是把学分字段的所有数值累加起来,下面的语句完成了这一任务。
SELECT SUM(credit) AS 总学分 FROM course; 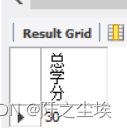
SUM函数不仅可以累加所有记录值以外,同COUNT函数一样,也可以只将满足条件的记录值累加起来,请看下面的例子。
在course表中,求课程类型为“必修”的课程的学分总和。
SELECT SUM(credit) AS 必修课的学分总和
FROM course WHERE type='必修' ; 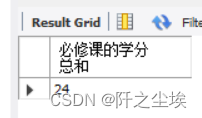
从score表中,求“计算机基础”课的考试成绩总和。
分析:因为score表中只有课号,而并没有课名,因此,首先,需要从course表中,查找“计算机基础”课的课号,其次,才能从score表中,通过“计算机基础”课的课号,查找满足条件的记录,最后,将考试成绩通过SUM函数加起来得到总和。所以,下面使用了两条SELECT语句。
SELECT ID AS 计算机基础课号
FROM course WHERE course='计算机基础'; 
运行上面的查询语句后得到结果中显示了“计算机基础”课的课号为“004”,根据这一结果,从Score表中,求“计算机基础”课的考试成绩总和。
SELECT SUM(result1) AS 计算机基础总成绩 FROM score WHERE c_id='004';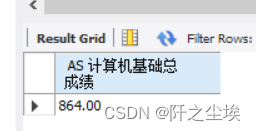
使用AVG函数求某字段的平均值
数据库操作中,除了求字段和以外,还经常需要求字段的平均值。AVG函数用于求字段的平均值,其用法和SUM函数的用法基本相同。AVG函数的参数也必须是数值类型的字段名或者结果为数值的表达式。
从score表中,求“计算机基础”课的考试成绩的平均分。
SELECT AVG(result1) AS 计算机基础平均成绩 FROM score
WHERE c_id IN (SELECT ID FROM course WHERE course="计算机基础");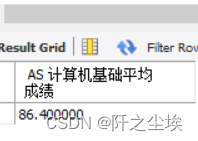
使用MAX、MIN函数求最大、最小值
MAX和MIN函数用于求指定字段中的最大值和最小值,例如,想要知道student表中,最早(最晚)的出生日期是多少时便可以用到MAX(MIN)函数。MAX和MIN两个函数可以用于文本类型、数值类型和日期时间类型的字段上。这两个函数都忽略含有NULL值的记录。下面通过例题学习这两个函数的用法。
从score表中,求“计算机基础”课的考试成绩的最高分和最低分。
SELECT MAX(result1) AS 最高分数, MIN(result1) AS 最低分数 FROM score
WHERE c_id IN (SELECT ID FROM course WHERE course='计算机基础');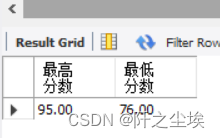
求年龄最小(出生日期最大)的学生的姓名,出生日期和所属院系。
SELECT name AS 姓名, birthday AS 出生日期, institute AS 所属院系
FROM student WHERE birthday IN (SELECT MAX(birthday) FROM student);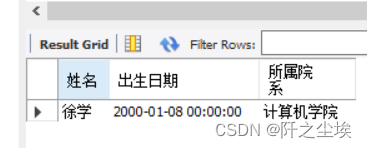
注意:WHERE子句后的条件表达式不能写成如下形式。
birthday= MAX(birthday),原因是,聚合函数不能出现在WHERE子句中。
统计汇总相异值(不同值)记录
数据库操作中,有时需要统计相异值记录,例如,统计Student表中的学生来自几个地区等。这时可以使用DISTINCT关键字完成统计任务。
统计student表中的学生来自几个地区。
分析:本例只要统计出不同来源地的个数即可。由于student表中的来源地字段中有重复值出现,因此,必须将重复值去掉,然后才能使用COUNT函数统计个数。
SELECT COUNT(DISTINCT(origin)) AS 地区个数 FROM student;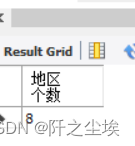
除COUNT函数可以使用DISTINCT以外,上面介绍的其它4个聚合函数中也能使用DISTINCT关键字。
SUM(),AVG(),MAX(),MIN()都是会忽略NULL值的。
数据分组
开始介绍groupby语句。
groupby用来查看一个分类变量有多少类会很快捷。
将student表中的数据,按所属院系字段分组。
SELECT institute FROM student GROUP BY institute;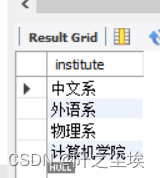
这里需要说明的一点是,如果将上面的SELECT子句字段列表中的“institute”改为星号(*),则会产生一系列的错误 。
通过错误提示可以得到如下启示,如果查询语句带有GROUP BY子句,则SELECT子句中通常不单独使用星号通配符。如果非要单独使用星号通配符,则应当在GROUP BY子句中列出表的所有字段名,字段名之间用逗号分隔。不过这样会使GROUP BY子句失去它的作用。因为,此时并不是按单个字段分组,而是使用GROUP BY后列出的所有字段的组合分组。
如果SELECT子句后是字段名列表,而这些字段名又不在聚合函数中,则应当在GROUP BY子句中列出所有这些字段名。此时,需要注意的还是,分组是按GROUP BY后的所有字段的组合分组,而并非是按单个字段分组。例如“GROUP BY institute, name”表示只有某几个记录中的所属院系和姓名都相同时才把这些记录分为一组。
聚合函数与分组配合使用
将数据分成小组的的很大原因是用于统计汇总,而统计汇总通常都要使用聚合函数,因此,聚合函数和分组经常被人们放在一起使用。
统计student表中,男生的总人数和女生的总人数。
SELECT sex AS 性别, COUNT(*) AS 人数
FROM student GROUP BY sex;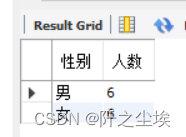
统计student表中,每个院系的男生人数。
SELECT institute AS 所属院系, COUNT(*) AS 男生人数
FROM student WHERE sex="男" GROUP BY institute;
GROUP BY子句中也可以有表达式,就是说可以按照表达式的结果分组数据。
为了方便查看哪一年雇佣了多少名外籍教师,在foreign_teacher表中按雇佣日期的年份统计人数。
SELECT YEAR(hiredate) AS 雇佣年份, COUNT(*) 雇用人数
FROM foreign_teacher GROUP BY YEAR(hiredate);除COUNT函数以外,GROUP BY子句还可以与其它聚合函数配合使用,下面是SUM函数与GROUP BY子句配合使用的例子。
统计查询course表中必修课的学分总和与选修课的学分总和。
SELECT type AS 类型, SUM(credit) AS 学分总和
FROM course GROUP BY type;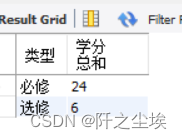
查询数据的直方图
直方图是表示不同实体之间数据相对分布的条状图。在一个查询语句中使用GROUP BY子句,不仅可以查询数据,又可以格式化数据生成图表。请看下面的例题。
从student表中,查询一个表示每个院系学生人数的直方图。
SELECT institute AS 所属院系, RPAD("",COUNT(*)*2,"=") AS 人数对比图
FROM student GROUP BY institute;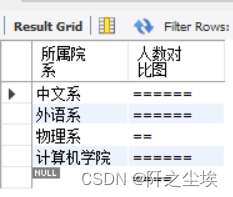
排序分组结果
如果想排序分组结果,则应当用使用ORDER BY子句。ORDER BY子句要放在GROUP BY子句的后面。实际上,ORDER BY子句要永远放在其它子句的后面。
在student表中,统计每个院系的学生人数,并按学生人数降序排序。
SELECT institute AS 所属院系, COUNT(*) AS 人数
FROM student GROUP BY institute ORDER BY COUNT(*) DESC; 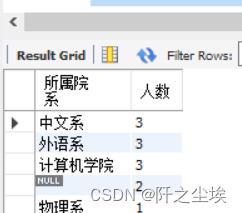
翻转查询结果
从student表中,查询每个院系的男生人数和女生人数。
SELECT institute AS 所属院系, sex AS 性别, COUNT(*) AS 人数
FROM student GROUP BY institute , sex ORDER BY institute;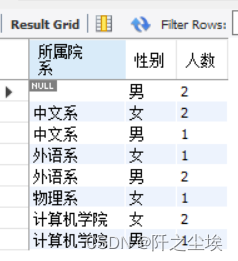
执行查询语句后得到的数据虽然正确无误,但是,当人们查看时会很不方便
在MySQL或SQL Server环境中,CASE表达式和GROUP BY子句联合使用会得到很多有用的数据表示,其中就包括反转查询结果的数据表示,请看下面的语句。
SELECT institute AS 所属院系, COUNT(CASE WHEN sex='男' THEN 1 ELSE NULL END) AS 男生人数,
COUNT(CASE WHEN sex='女' THEN 1 ELSE NULL END) AS 女生人数
FROM student GROUP BY institute;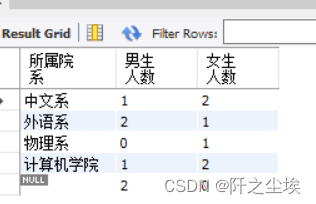
(其实就是类似pandas里面的.unstack()的用法,反解堆就行。)
使用HAVING子句设置分组查询条件
HAVING子句用于设置分组查询条件,即过滤不需要的分组。该子句通常和GROUP BY子句一起使用。单独使用HAVING子句没有太大的意义。
在student表中,统计计算机系和外语系的学生人数,并按学生人数降序排序。
SELECT institute AS 所属院系, COUNT(*) AS 人数
FROM student GROUP BY institute
HAVING institute IN('计算机学院','外语系')
ORDER BY COUNT(*);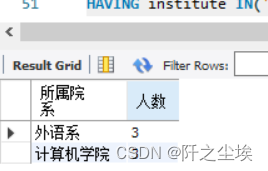
另一种实现方式:用WHERE子句代替HAVING子句,其语句如下所示。
SELECT institute AS 所属院系, COUNT(*) AS 人数
FROM student WHERE institute IN('计算机学院','外语系')
GROUP BY institute ORDER BY COUNT(*);
HAVING子句与WHERE子句的区别
HAVING子句与WHERE子句之后都写条件表达式,而且都会根据条件表达式的结果筛选数据。但它们是有区别的,主要区别汇总如下。
通常,HAVING子句总是和GROUP BY 子句配合使用,而WHERE子句可以不用任何子句的配合。下面来看一个非常典型的例子,该例题只能用HAVING子句筛选条件。
统计score表中,考试总成绩大于450分的学生的信息。
SELECT s_id AS 学号, SUM(result1) AS 考试总成绩
FROM score GROUP BY s_id HAVING SUM(result1)>=450
ORDER BY 考试总成绩 DESC; 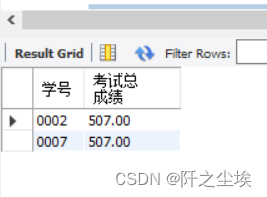
本例,必须用HAVING子句指定筛选条件,因为只有HAVING子句中才能使用聚合函数,而WHERE子句中不能使用聚合函数。下面使用前面介绍过的一个例题,演示WHERE子句不能用HAVING子句代替的情况。
统计student表中,每个院系的男生人数。
SELECT institute AS 所属院系,COUNT(*) AS 男生人数
FROM student WHERE sex='男' GROUP BY institute;
相关文章:
Mysql数据库09——分组聚合函数
类似pandas里面的groupby函数,SQL里面的GROUP BY子句也是可以达到分组聚合的效果。 常用的聚合函数有COUNT(),SUM(),AVG(),MAX(),MIN(),其用法看名字都看的出来,下面一一介绍 聚合函数 COUNT()计数 统计student表中计科系学生的人数。 SE…...

第43章 菜单实体及其约束规则的定义实现
1 Core.Domain.Security.Menu namespace Core.Domain.Security { /// <summary> /// 【菜单--类】 /// <remarks> /// 摘要: /// 通过该实体类及其属性成员,用于实现当前程序【Core】.【领域】.【安全】.【菜单】实体与“[ShopDemo].[…...

OpenAI最重要的模型【CLIP】
最近的 AI 突破 DALLE和 Stable Diffusion有什么共同点? 它们都使用 CLIP 架构的组件。 因此,如果你想掌握这些模型是如何工作的,了解 CLIP 是先决条件。 此外,CLIP 已被用于在 Unsplash 上索引照片。 但是 CLIP 做了什么&…...

分享112个JS菜单导航,总有一款适合您
分享112个JS菜单导航,总有一款适合您 112个JS菜单导航下载链接:https://pan.baidu.com/s/1Dm73d2snbu15hZErJjTXxg?pwdfz1c 提取码:fz1c Python采集代码下载链接:https://wwgn.lanzoul.com/iKGwb0kye3wj base_url "h…...
MySQL 3:MySQL数据库基本操作 DQL
数据库管理系统的一个重要功能是数据查询。数据查询不应简单地返回数据库中存储的数据,还应根据需要对数据进行过滤,确定数据的显示格式。MySQL 提供了强大而灵活的语句来实现这些操作。MySQL数据库使用select语句查询数据。 select [all|distinct]<…...

sql语句的优化
sql优化 优化数据访问 查询性能低下最基本的原因是访问的数据太多,大部分性能低下的查询都可以通过减少访问的数据量来优化所以关于低效的查询,需要确认是否检索了大量不需要的数据,以及mysql服务器层是否在分析大量不需要的数据 因为有些查…...

Shell脚本之——自动安装JDK
目录 1.修改主机名 2.创建文件,单独存放Shell脚本 3.编写Shell脚本 4.Shell脚本命令简介 (1)文件头 (2)打印命令 (3)设置全局变量 (4)条件判断 (5)解压 (6)文件重命名 (7)在/etc/profile指定行插入 5.完整脚本内容 6.重启环境变量 7.判断java是否配置…...
大数据---Hadoop安装Hadoop简易版
编写自动安装Hadoop的shell脚本 完整流程: 大数据—Hadoop安装教程(二) 文章目录编写自动安装Hadoop的shell脚本上传压缩包编写shell脚本vim hadoopautoinstall.sh运行上传压缩包 在opt目录下创建连个目录install和soft 将压缩包上传到install目录下 …...
)
Spring框架中使用到的设计模式以及对应的类(方法)
模板方法--->postProcessBeanFactory,onFresh、initPropertySource装饰器模式--->BeanWrapper委托者模式--->BeanDefinitionParseDelegate策略模式--->ClassPathXmlApplicationContext、FileSystemApplicationContext、XMLBeanDefinitionReader、Proper…...

类和类的定义
6.2 类和类的定义 面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如学生类,而实例是根据类创建出来的一个个具体的对象,每个对象都拥有相同的方法&…...

丝绸之路——NFT 系列来袭!
丝绸之路的经历讲述了汉朝时代的一个重要历史事件。该系列中的 NFT 带有中国这段黄金时代令人愉悦的视觉元素,使其成为值得收藏的物品。 NFT 系列介绍 敦煌女神像01(左);汉代士兵(中);敦煌女神像…...

配置CMAKE编译环境:VSCODE + MinGW
一. MinGW安装 MinGW(Minimalist GNU For Windows)是个精简的Windows平台C/C、ADA及Fortran编译器,相比Cygwin而言,体积要小很多,使用较为方便。 MinGW最大的特点就是编译出来的可执行文件能够独立在Windows上运行。 MinGW的组成ÿ…...
六、mybatis与spring的整合
Spring整合Mybaits的步骤 引入依赖 在Spring整合Mybaits的时候需要引入一个中间依赖包mybatis-spring <dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.5</version> </dependency&g…...
JavaWeb--JDBC
JDBC1 JDBC概述1.1 JDBC概念1.2 JDBC本质1.3 JDBC好处2 JDBC快速入门2.1 编写代码步骤2.2 具体操作3 JDBC API详解3.1 DriverManager3.2 Connection3.2.1 获取执行对象3.2.2 事务管理3.3 Statement3.3.1 概述3.3.2 代码实现3.4 ResultSet3.4.1 概述3.4.2 代码实现3.5 案例3.6 P…...

大数据框架之Hadoop:入门(四)Hadoop运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。 Hadoop官方网站:http://hadoop.apache.org/ 4.1本地运行模式 4.1.1官方Grep案例 1.创建在hadoop文件夹下面创建一个input文件夹 [roothdp101 hadoop]# mkdir input2.将Hadoop的xml配…...

《爆肝整理》保姆级系列教程python接口自动化(十一)--发送post【data】(详解
简介 前面登录的是传 json 参数,由于其登录机制的改变没办法演示,然而在工作中有些登录不是传 json 的,如 jenkins 的登录,这里小编就以jenkins 登录为案例,传 data 参数,给各位童鞋详细演练一下。 一、…...

【微服务】Nacos注册中心
🚩本文已收录至专栏:微服务探索之旅 👍希望您能有所收获 👍Nacos和Eureka一样也可以充当服务的注册中心,让我们一起看看有何区别? 点击跳转👉【微服务】Eureka注册中心 👍Nacos除了可…...

跟开发打了半个月后,我终于get报bug的正确姿势了
在测试人员提需求的时候,大家经常会看到,测试员和开发一言不合就上BUG。然后开发一下就炸了,屡试不爽,招招致命。 曾经看到有个段子这么写道: 不要对程序员说,你的代码有BUG。他的第一反应是:…...

js万能类型检测Object.prototype.toString.call——定制Object.prototype.toString.call的检测结果
javascript的类型检测 1、typeof typeof操作符可以检测js的基础数据类型,包括number、string、boolean、undefined。因为null在二进制存储的值与object相同,所以typeof检测null会返回object。此为特例 2、instanceof instanceof操作符可以检测某个对…...
激光slam学习笔记2--激光点云数据结构特点可视化查看
背景:不同厂商的激光点云结果存在一定差异,比如有些只有xyz,有些包含其他,如反光率、时间戳、ring等。如何快速判断是个值得学习的点 概要:对于rosbag类型的激光点云,介绍使用rviz快速查看点云结构特点 如…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...