大数据框架之Hadoop:入门(四)Hadoop运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:http://hadoop.apache.org/
4.1本地运行模式
4.1.1官方Grep案例
1.创建在hadoop文件夹下面创建一个input文件夹
[root@hdp101 hadoop]# mkdir input
2.将Hadoop的xml配置文件复制到input
[root@hdp101 hadoop]# cp etc/hadoop/*.xml input
3.执行share目录下的MapReduce程序
[root@hdp101 hadoop]# bin/hadoop jar #HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input output 'dfs[a-z.]+'
4.查看输出结果
[root@hdp101 hadoop]# cat output/*
4.1.2官方WordCount案例
1.创建在hadoop文件夹下面创建一个wcinput文件夹
[root@hdp101 hadoop]# mkdir wcinput
2.在wcinput文件下创建一个wc.input文件
[root@hdp101 hadoop]# cd wcinput
[root@hdp101 wcinput]# touch wc.input
3.编辑wc.input文件
[root@hdp101 wcinput]# vi wc.input
在文件中输入如下内容
hadoop yarn
hadoop mapreduce
vagrant
vagrant
保存退出::wq
4.回到Hadoop目录/opt/module/hadoop
5.执行程序
[root@hdp101 hadoop]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput wcoutput
6.查看结果
[root@hdp101 hadoop]# cat wcoutput/part-r-00000
hadoop 2
mapreduce 1
vagrant 2
yarn 1
4.2伪分布式运行模式
4.2.1启动HDFS并运行MapReduce程序
1.分析
(1)配置集群
(2)启动、测试集群增、删、查
(3)执行WordCount案例
2.执行步骤
(1)配置集群
(a)配置:hadoop-env.sh
Linux系统中获取 JDK 的安装路径:
[root@hdp101 ~]# echo #JAVA_HOME
/opt/module/java
修改 JAVA_HOME 路径:
export JAVA_HOME=/opt/module/java
(b)配置:core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name><value>hdfs://hdp101:9000</value>
</property><!-- 指定Hadoop运行时产生文件的存储目录 -->
<property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop/data/tmp</value>
</property>
(c)配置:hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property><name>dfs.replication</name><value>1</value>
</property>
(2)启动集群
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
[root@hdp101 hadoop]# hdfs namenode -format
(b)启动NameNode
[root@hdp101 hadoop]# hadoop-daemon.sh start namenode
(c)启动DataNode
[root@hdp101 hadoop]# hadoop-daemon.sh start datanode
(3)查看集群
(a)查看是否启动成功
[root@hdp101 hadoop]# jps
2385 NameNode
2482 DataNode
2556 Jps
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
(b)web端查看HDFS文件系统
http://hdp101:50070/dfshealth.html#tab-overview
注意:如果不能查看,看如下帖子处理
http://www.cnblogs.com/zlslch/p/6604189.html
(c)查看产生的Log日志
说明:在企业中遇到Bug时,经常根据日志提示信息去分析问题、解决Bug。
当前目录:/opt/module/hadoop/logs
[root@hdp101 logs]# ll
total 60
-rw-r--r-- 1 root root 23196 Jan 13 23:08 hadoop-root-datanode-hdp101.log
-rw-r--r-- 1 root root 718 Jan 13 23:08 hadoop-root-datanode-hdp101.out
-rw-r--r-- 1 root root 27202 Jan 13 23:08 hadoop-root-namenode-hdp101.log
-rw-r--r-- 1 root root 718 Jan 13 23:08 hadoop-root-namenode-hdp101.out
-rw-r--r-- 1 root root 0 Jan 13 23:08 SecurityAuth-root.audit
(d)思考:为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
[root@hdp101 hadoop]# cd data/tmp/dfs/name/current/
[root@hdp101 current]# cat VERSION
...
clusterID=CID-12c1d64b-aac8-402a-b561-ac59e073b089
...[root@hdp101 current]# cd /opt/module/hadoop/data/tmp/dfs/data/current/
[root@hdp101 current]# cat VERSION
...
clusterID=CID-12c1d64b-aac8-402a-b561-ac59e073b089
...
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
(4)操作集群
(a)在HDFS文件系统上创建一个input文件夹
[root@hdp101 hadoop]# hdfs dfs -mkdir -p /user/root/input
(b)将测试文件内容上传到文件系统上
[root@hdp101 hadoop]# hdfs dfs -put wcinput/wc.input /user/root/input/
(c)查看上传的文件是否正确
[root@hdp101 hadoop]# hdfs dfs -ls /user/root/input/
[root@hdp101 hadoop]# hdfs dfs -cat /user/root/input/wc.input
(d)运行MapReduce程序
[root@hdp101 hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/root/input/ /user/root/output
(e)查看输出结果
命令行查看:
[root@hdp101 hadoop]# hdfs dfs -cat /user/root/output/*
浏览器查看,如图2-34所示
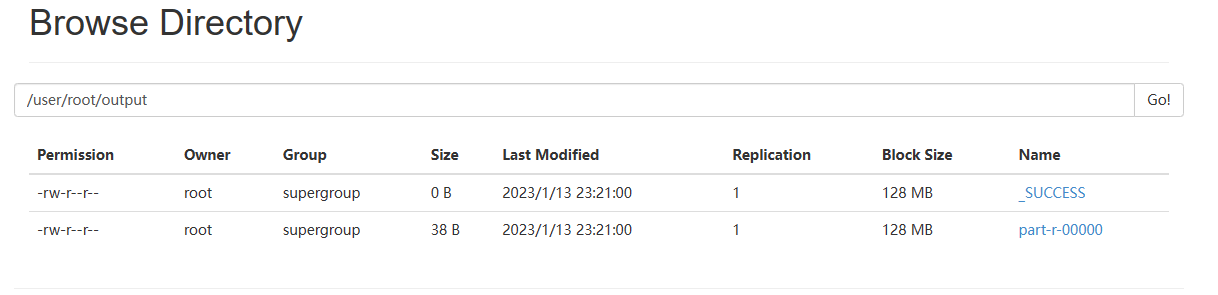
(f)将测试文件内容下载到本地
[root@hdp101 hadoop]# hdfs dfs -get /user/root/output/part-r-00000 ./wcoutput/
(g)删除输出结果
[root@hdp101 hadoop]# hdfs dfs -rm -r /user/root/output
4.2.2启动YARN并运行MapReduce程序
1.分析
(1)配置集群在YARN上运行MR
(2)启动、测试集群增、删、查
(3)在YARN上执行WordCount案例
2.执行步骤
(1)配置集群
(a)配置yarn-env.sh
配置一下 JAVA_HOME
export JAVA_HOME=/opt/module/java
(b)配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property><!-- 指定YARN的ResourceManager的地址 -->
<property><name>yarn.resourcemanager.hostname</name><value>hdp101</value>
</property>
(c)配置:mapred-env.sh
配置一下 JAVA_HOME
export JAVA_HOME=/opt/module/java
(d)配置:(对mapred-site.xml.template重新命名为) mapred-site.xml
[root@hdp101 hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@hdp101 hadoop]# vi mapred-site.xml<!-- 指定MR运行在YARN上 -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
(2)启动集群
(a)启动前必须保证NameNode和DataNode已经启动
(b)启动ResourceManager
[root@hdp101 hadoop]# yarn-daemon.sh start resourcemanager
(c)启动NodeManager
[root@hdp101 hadoop]# yarn-daemon.sh start nodemanager
(3)集群操作
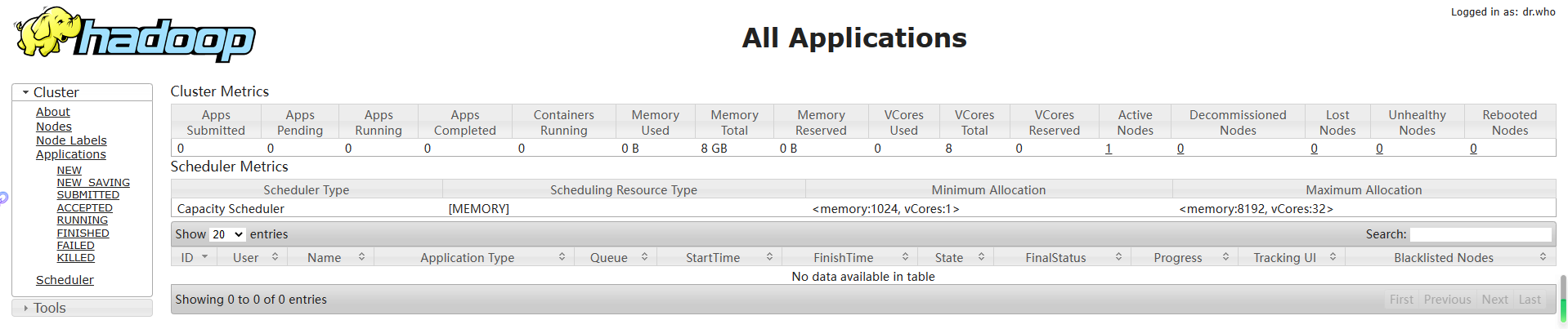
(a)YARN的浏览器页面查看,如下图所示
http://hdp101:8088/cluster
(b)删除文件系统上的output文件
[root@hdp101 hadoop]# hdfs dfs -rm -R /user/root/output
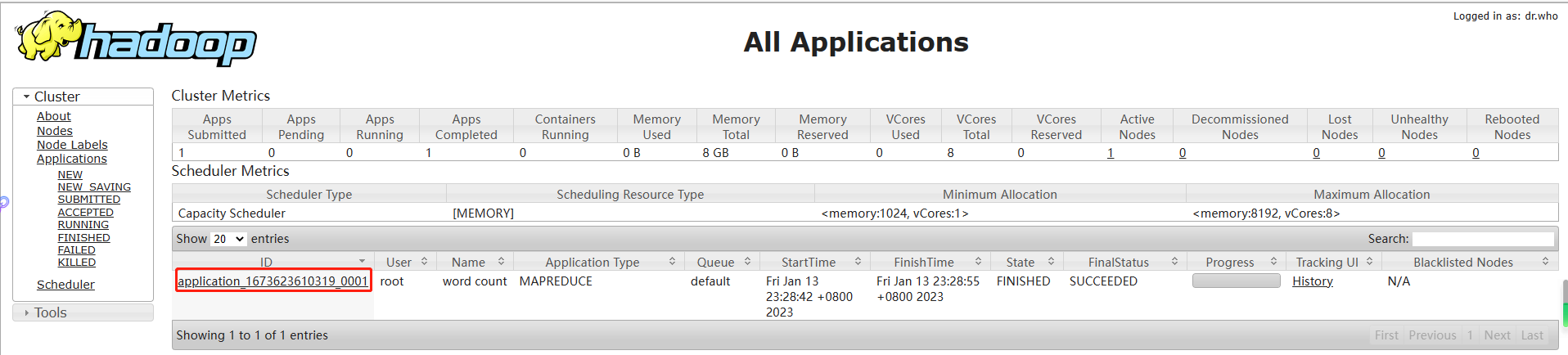
(c)执行MapReduce程序
[root@hdp101 hadoop]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/root/input /user/root/output
(d)查看运行结果,如下图所示
[root@hdp101 hadoop]# hdfs dfs -cat /user/root/output/*
4.2.3配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1.配置mapred-site.xml
[root@hdp101 hadoop]# vi mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hdp101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hdp101:19888</value>
</property>
2.启动历史服务器
[root@hdp101 hadoop]# mr-jobhistory-daemon.sh start historyserver
3.查看历史服务器是否启动
[root@hdp101 hadoop]# jps
4.查看JobHistory
http://hdp101:19888/jobhistory
4.2.4配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
1.配置yarn-site.xml
[root@hdp101 hadoop]# vi yarn-site.xml
在该文件里面增加如下配置。
<!-- 日志聚集功能使能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property><!-- 日志保留时间设置7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
2.关闭NodeManager 、ResourceManager和HistoryManager
[root@hdp101 hadoop]# yarn-daemon.sh stop resourcemanager
[root@hdp101 hadoop]# yarn-daemon.sh stop nodemanager
[root@hdp101 hadoop]# mr-jobhistory-daemon.sh stop historyserver
3.启动NodeManager 、ResourceManager和HistoryManager
[root@hdp101 hadoop]# yarn-daemon.sh start resourcemanager
[root@hdp101 hadoop]# yarn-daemon.sh start nodemanager
[root@hdp101 hadoop]# mr-jobhistory-daemon.sh start historyserver
4.删除HDFS上已经存在的输出文件
[root@hdp101 hadoop]# hdfs dfs -rm -R /user/root/output
5.执行WordCount程序
[root@hdp101 hadoop]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/root/input /user/root/output
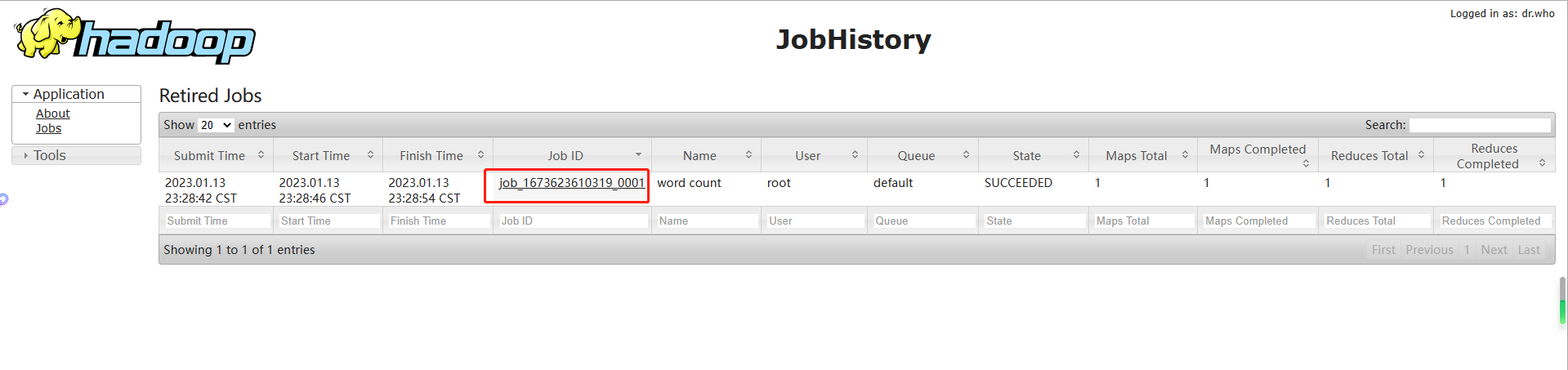
6.查看日志,如图2-37,2-38,2-39所示
http://hdp101:19888/jobhistory

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RkOZQ1BM-1676101720232)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20230113233621271.png)]
4.2.5配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| core-default.xml | hadoop-common-2.7.7.jar/ core-default.xml |
| hdfs-default.xml | hadoop-hdfs-2.7.7.jar/ hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-2.7.7.jar/ yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-2.7.7.jar/ mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在#HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
4.3完全分布式运行模式(开发重点)
分析:
1)准备3台客户机(关闭防火墙、静态ip、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群
4.3.1虚拟机准备
详见3.1章。
4.3.2编写集群分发脚本xsync
1.scp(secure copy)安全拷贝
(1)scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r $pdir/$fname $user@hdp$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
(3)案例实操
(a)在hdp101上,将hdp101中/opt/module目录下的软件拷贝到hdp102上。
[root@hdp101 /]# scp -r /opt/module root@hdp102:/opt/module
(b)在hdp101上,将hdp101服务器上的/opt/module目录下的软件拷贝到hdp103上。
[root@hdp101 /]# scp -r /opt/module root@hdp103:/opt/module
注意:拷贝过来的/opt/module目录,别忘了在hdp102、hdp103修改所有文件的,所有者和所有者组为root用户。
(d)将hdp101中/etc/profile文件拷贝到hdp102的/etc/profile上。
[root@hdp101 ~]# scp /etc/profile root@hdp102:/etc/profile
(e)将hdp101中/etc/profile文件拷贝到hdp103的/etc/profile上。
[root@hdp101 ~]# scp /etc/profile root@hdp103:/etc/profile
注意:拷贝过来的配置文件别忘了source一下/etc/profile,。
2.rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -rvl $pdir/$fname $user@hdp$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
选项参数说明
| 选项 | 功能 |
|---|---|
| -r | 递归 |
| -v | 显示复制过程 |
| -l | 拷贝符号连接 |
(2)案例实操
(a)把hdp101机器上的/opt/software目录同步到hdp102服务器的root用户下的/opt/目录
[root@hdp101 opt]# rsync -rvl /opt/software/ root@hdp102:/opt/software
3.xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -rvl /opt/module root@hdp103:/opt/
(b)期望脚本:
xsync要同步的文件名称
(c)说明:在/opt/module/init_bin这个目录下存放的脚本,root用户可以在系统任何地方直接执行。
(3)脚本实现
(a)在/opt/module/目录下创建init_bin目录,并在bin目录下xsync创建文件,文件内容如下:
[root@hdp101 ~]# mkdir /opt/module/init_bin
[root@hdp101 ~]# cd /opt/module/init_bin/
[root@hdp101 init_bin]# touch xsync
[root@hdp101 init_bin]# vi xsync
在该文件中编写如下代码
#!/bin/bash# 获取输出参数,如果没有参数则直接返回
pcount=$#
if [ $pcount -eq 0 ]
thenecho "no parameter find !";exit;
fi# 获取传输文件名
p1=$1
filename=`basename $p1`
echo "load file $p1 success !"# 获取文件的绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo "file path is $pdir"# 获取当前用户
user=`whoami`# 拷贝文件到从机(这里注意主机的host需要根据你的实际情况配置,要与你具体的主机名对应)
for host in hdp101 hdp102 hdp103;
docurrent_hostname=`cat /etc/hostname`if [ "$current_hostname" != "$host" ];thenecho "================current host is $host================="rsync -rvl $pdir/$filename $user@$host:$pdirfi
doneecho "complate !"
(b)修改脚本 xsync 具有执行权限
[root@hdp101 bin]# chmod a+x xsync
(c)调用脚本形式:xsync 文件名称
[root@hdp101 bin]# xsync /opt/module/init_bin
注意:如果将xsync放到/opt/module/init_bin目录下仍然不能实现全局使用,可以在/etc/profile中加入环境变量
# init shell bin
export INIT_SHELL_BIN=/opt/module/init_bin
export PATH=${INIT_SHELL_BIN}:$PATH
source /etc/profile
4.3.3集群配置
1.集群部署规划
| hdp101 | hdp102 | hdp103 | |
|---|---|---|---|
| HDFS | NameNodeDataNode | DataNode | SecondaryNameNodeDataNode |
| YARN | NodeManager | ResourceManagerNodeManager | NodeManager |
2.配置集群
(1)核心配置文件
配置core-site.xml
[root@hdp101 hadoop]# vi core-site.xml
在该文件中编写如下配置
<!-- 指定HDFS中NameNode的地址 -->
<property><name>fs.defaultFS</name><value>hdfs://hdp101:9000</value>
</property><!-- 指定Hadoop运行时产生文件的存储目录 -->
<property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop/data/tmp</value>
</property>
(2)HDFS配置文件
配置hadoop-env.sh
[root@hdp101 hadoop]# vi hadoop-env.sh
export JAVA_HOME=/opt/module/java
配置hdfs-site.xml
[root@hdp101 hadoop]# vi hdfs-site.xml
在该文件中编写如下配置
<property><name>dfs.replication</name><value>3</value>
</property><!-- 指定Hadoop辅助名称节点主机配置 -->
<property><name>dfs.namenode.secondary.http-address</name><value>hdp103:50090</value>
</property>
(3)YARN配置文件
配置yarn-env.sh
[root@hdp101 hadoop]# vi yarn-env.sh
export JAVA_HOME=/opt/module/java
配置yarn-site.xml
[root@hdp101 hadoop]# vi yarn-site.xml
在该文件中增加如下配置
<!-- Reducer获取数据的方式 -->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property><!-- 指定YARN的ResourceManager的地址 -->
<property><name>yarn.resourcemanager.hostname</name><value>hdp102</value>
</property>
(4)MapReduce配置文件
配置mapred-env.sh
[root@hdp101 hadoop]# vi mapred-env.sh
export JAVA_HOME=/opt/module/java
配置mapred-site.xml
[root@hdp101 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@hdp101 hadoop]# vi mapred-site.xml
在该文件中增加如下配置
<!-- 指定MR运行在Yarn上 -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
3.在集群上分发配置好的Hadoop配置文件
[root@hdp101 hadoop]# xsync /opt/module/hadoop/
4.查看文件分发情况
[root@hdp102 hadoop]# cat /opt/module/hadoop/etc/hadoop/core-site.xml
4.3.4集群单点启动
(1)如果集群是第一次启动,需要格式化NameNode
[root@hdp101 hadoop]# hadoop namenode -format
(2)在hdp101上启动NameNode
[root@hdp101 hadoop]# hadoop-daemon.sh start namenode
[root@hdp101 hadoop]# jps
1584 Jps
1513 NameNode
(3)在hdp101、hdp102以及hdp103上分别启动DataNode
[root@hdp101 hadoop]# hadoop-daemon.sh start datanode
[root@hdp101 hadoop]# jps
1617 DataNode
1513 NameNode
1691 Jps
[root@hdp102 hadoop]# hadoop-daemon.sh start datanode
[root@hdp102 hadoop]# jps
1265 Jps
1191 DataNode
[root@hdp103 hadoop]# hadoop-daemon.sh start datanode
[root@hdp103 hadoop]# jps
1318 Jps
1244 DataNode
(4)思考:每次都一个一个节点启动,如果节点数增加到1000个怎么办?
早上来了开始一个一个节点启动,到晚上下班刚好完成,下班?
4.3.5 SSH无密登录配置
1.配置ssh
(1)基本语法
ssh另一台电脑的ip地址
(2)ssh连接时出现Host key verification failed的解决方法
[root@hdp101 opt] # ssh 192.168.10.103
The authenticity of host '192.168.10.103 (192.168.10.103)' can't be established.
RSA key fingerprint is cf:1e:de:d7:d0:4c:2d:98:60:b4:fd:ae:b1:2d:ad:06.
Are you sure you want to continue connecting (yes/no)?
Host key verification failed.
(3)解决方案如下:直接输入yes
2.无密钥配置
(1)免密登录原理,如下图所示
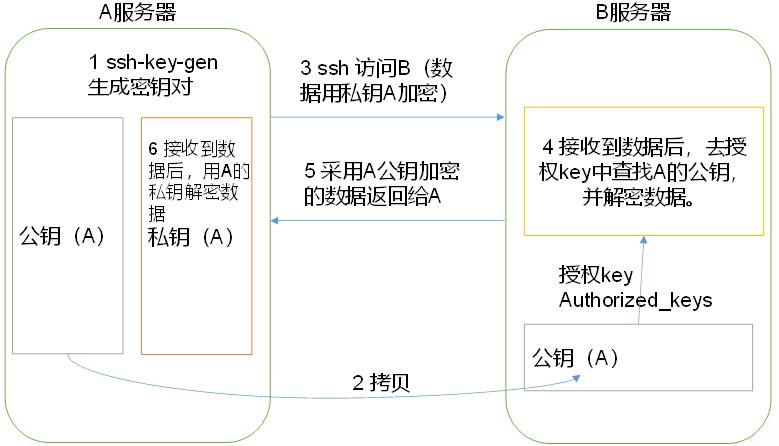
(2)生成公钥和私钥:
[root@hdp101 hadoop]# ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[root@hdp101 hadoop]# ssh-copy-id hdp101
[root@hdp101 hadoop]# ssh-copy-id hdp102
[root@hdp101 hadoop]# ssh-copy-id hdp103
注意:
还需要在hdp102上采用root账号,配置一下无密登录到hdp101、hdp102、hdp103;
还需要在hdp103上采用root账号,配置一下无密登录到hdp101、hdp102、hdp103服务器上。
3…ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过得无密登录服务器公钥 |
4.3.6群起集群
1.配置slaves
[root@hdp101 hadoop]# vi /opt/module/hadoop/etc/hadoop/slaves
在该文件中增加如下内容:
hdp101
hdp102
hdp103
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[root@hdp101 hadoop]# xsync slaves
2.启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[root@hdp101 hadoop]# hdfs namenode -format
(2)启动HDFS
[root@hdp101 hadoop]# start-dfs.sh
[root@hdp101 hadoop]# jps
2037 DataNode
2248 Jps
1902 NameNode
[root@hdp102 hadoop]# jps
1424 Jps
1347 DataNode
[root@hdp103 hadoop]# jps
1542 Jps
1400 DataNode
1499 SecondaryNameNode
(3)启动YARN
[root@hdp102 hadoop]# start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
(4)Web端查看SecondaryNameNode
(a)浏览器中输入:http://hdp103:50090/status.html
(b)查看SecondaryNameNode信息,如下图所示。
3.集群基本测试
(1)上传文件到集群
上传小文件
[root@hdp101 hadoop]# hdfs dfs -mkdir -p /user/root/input
[root@hdp101 hadoop]# hdfs dfs -put wcinput/wc.input /user/root/input
上传大文件
[root@hdp101 hadoop]# bin/hadoop fs -put /opt/software/hadoop.tar.gz /user/root/input
(2)上传文件后查看文件存放在什么位置
(a)查看HDFS文件存储路径
[root@hdp101 subdir0]# pwd
/opt/module/hadoop/data/tmp/dfs/data/current/BP-620459927-192.168.10.101-1673658795395/current/finalized/subdir0/subdir0
(b)查看HDFS在磁盘存储文件内容
[root@hdp101 subdir0]# cat blk_1073741825
hadoop yarn
hadoop mapreduce
vagrant
vagrant
(3)拼接
[root@hdp101 subdir0]# cat blk_1073741836>>tmp.file
[root@hdp101 subdir0]# cat blk_1073741837>>tmp.file
[root@hdp101 subdir0]# tar -zxvf tmp.file
(4)下载
[root@hdp101 hadoop]# bin/hadoop fs -get /user/root/input/hadoop.tar.gz ./
4.3.7集群启动/停止方式总结
1.各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start/stop namenode/datanode/secondarynamenode
(2)启动/停止YARN
yarn-daemon.sh start/stop resourcemanager/nodemanager
2.各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
4.3.8集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。

配置时间同步具体实操:
1.时间服务器配置(必须root用户)
(1)检查ntp是否安装
[root@hdp101 ~]# rpm -qa|grep ntp
ntp-4.2.6p5-29.el7.centos.2.x86_64
ntpdate-4.2.6p5-29.el7.centos.2.x86_64
(2)修改ntp配置文件
[root@hdp101 ~]# vi /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改/etc/sysconfig/ntpd 文件
[root@hdp101 ~]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[root@hdp101 ~]# service ntpd status
[root@hdp101 ~]# service ntpd start
(5)设置ntpd服务开机启动
[root@hdp101 ~]# chkconfig ntpd on
2.其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[root@hdp102 ~]# crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate hdp101
(2)修改任意机器时间
[root@hdp102 ~]# date -s "2023-1-13 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[root@hdp102 ~]# date
说明:测试的时候可以将10分钟调整为1分钟,节省时间。
相关文章:
大数据框架之Hadoop:入门(四)Hadoop运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。 Hadoop官方网站:http://hadoop.apache.org/ 4.1本地运行模式 4.1.1官方Grep案例 1.创建在hadoop文件夹下面创建一个input文件夹 [roothdp101 hadoop]# mkdir input2.将Hadoop的xml配…...

《爆肝整理》保姆级系列教程python接口自动化(十一)--发送post【data】(详解
简介 前面登录的是传 json 参数,由于其登录机制的改变没办法演示,然而在工作中有些登录不是传 json 的,如 jenkins 的登录,这里小编就以jenkins 登录为案例,传 data 参数,给各位童鞋详细演练一下。 一、…...

【微服务】Nacos注册中心
🚩本文已收录至专栏:微服务探索之旅 👍希望您能有所收获 👍Nacos和Eureka一样也可以充当服务的注册中心,让我们一起看看有何区别? 点击跳转👉【微服务】Eureka注册中心 👍Nacos除了可…...

跟开发打了半个月后,我终于get报bug的正确姿势了
在测试人员提需求的时候,大家经常会看到,测试员和开发一言不合就上BUG。然后开发一下就炸了,屡试不爽,招招致命。 曾经看到有个段子这么写道: 不要对程序员说,你的代码有BUG。他的第一反应是:…...

js万能类型检测Object.prototype.toString.call——定制Object.prototype.toString.call的检测结果
javascript的类型检测 1、typeof typeof操作符可以检测js的基础数据类型,包括number、string、boolean、undefined。因为null在二进制存储的值与object相同,所以typeof检测null会返回object。此为特例 2、instanceof instanceof操作符可以检测某个对…...
激光slam学习笔记2--激光点云数据结构特点可视化查看
背景:不同厂商的激光点云结果存在一定差异,比如有些只有xyz,有些包含其他,如反光率、时间戳、ring等。如何快速判断是个值得学习的点 概要:对于rosbag类型的激光点云,介绍使用rviz快速查看点云结构特点 如…...
SpringBoot笔记【JavaEE】
SpringBoot概念、创建和运行 1.什么是SpringBoot?为什么学习SpringBoot? Spring Boot 就是 Spring 框架的脚⼿架,它就是为了快速开发 Spring 框架⽽诞⽣的。 2.Spring Boot优点 快速集成框架【提供启动添加依赖的功能】内容运行容器【无需…...

目标检测算法之voxelNet与pointpillars对比
算法对比 3D目标检测发展简史 点云目标检测目前发展历经VoxelNet、SECOND、PointPillars、PV-RCNN。 2017年苹果提出voxelnet,是最早的一篇将点云转成voxel体素进行3D目标检测的论文。 然后2018年重庆大学的一个研究生Yan Yan在自动驾驶公司主线科技实习的时候将vo…...
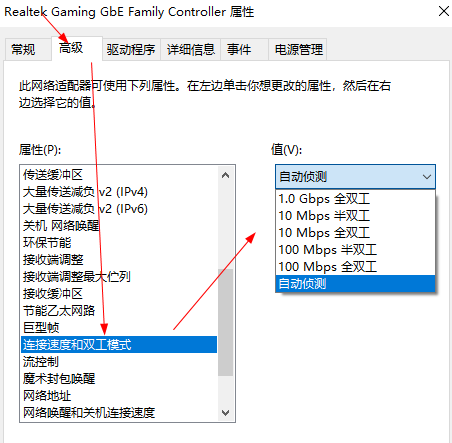
电脑里的连接速度双工模式是什么?怎么设置
双工模式包括全双工、半双工模式。1.半双工1、半双工数据传输允许数据在两个方向上传输,但是,在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信。所谓半双工就是指一个时间段内只有一个动作发生。早期的对…...
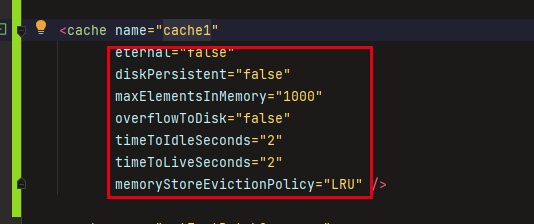
springboot整合单机缓存ehcache
区别于redis的分布式缓存,ehcache是纯java进程内的单机缓存,根据不同的场景可选择使用,以下内容主要为springboot整合ehcache以及注意事项添加pom引用<dependency><groupId>net.sf.ehcache</groupId><artifactId>ehc…...

在阿里干了2年的测试,总结出来的划水经验
测试新人 我的职业生涯开始和大多数测试人一样,开始接触都是纯功能界面测试。那时候在一家电商公司做测试,做了一段时间,熟悉产品的业务流程以及熟练测试工作流程规范之后,效率提高了,工作比较轻松,这样我…...
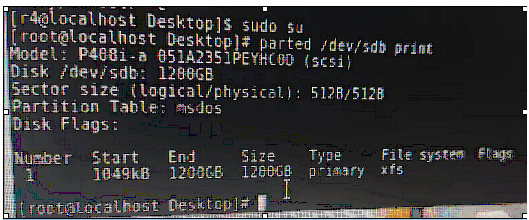
硬盘分类及挂载硬盘知识补充和介绍
一、硬盘介绍Linux硬盘分IDE硬盘和SCSI硬盘,目前基本上是SCSI硬盘1.对于IDE硬盘,驱动器标识符为"hdx~",其中"hd"表明分区所在设备的类型,这里是指IDE硬盘了。"x"为盘号(a为基本盘,b为基…...
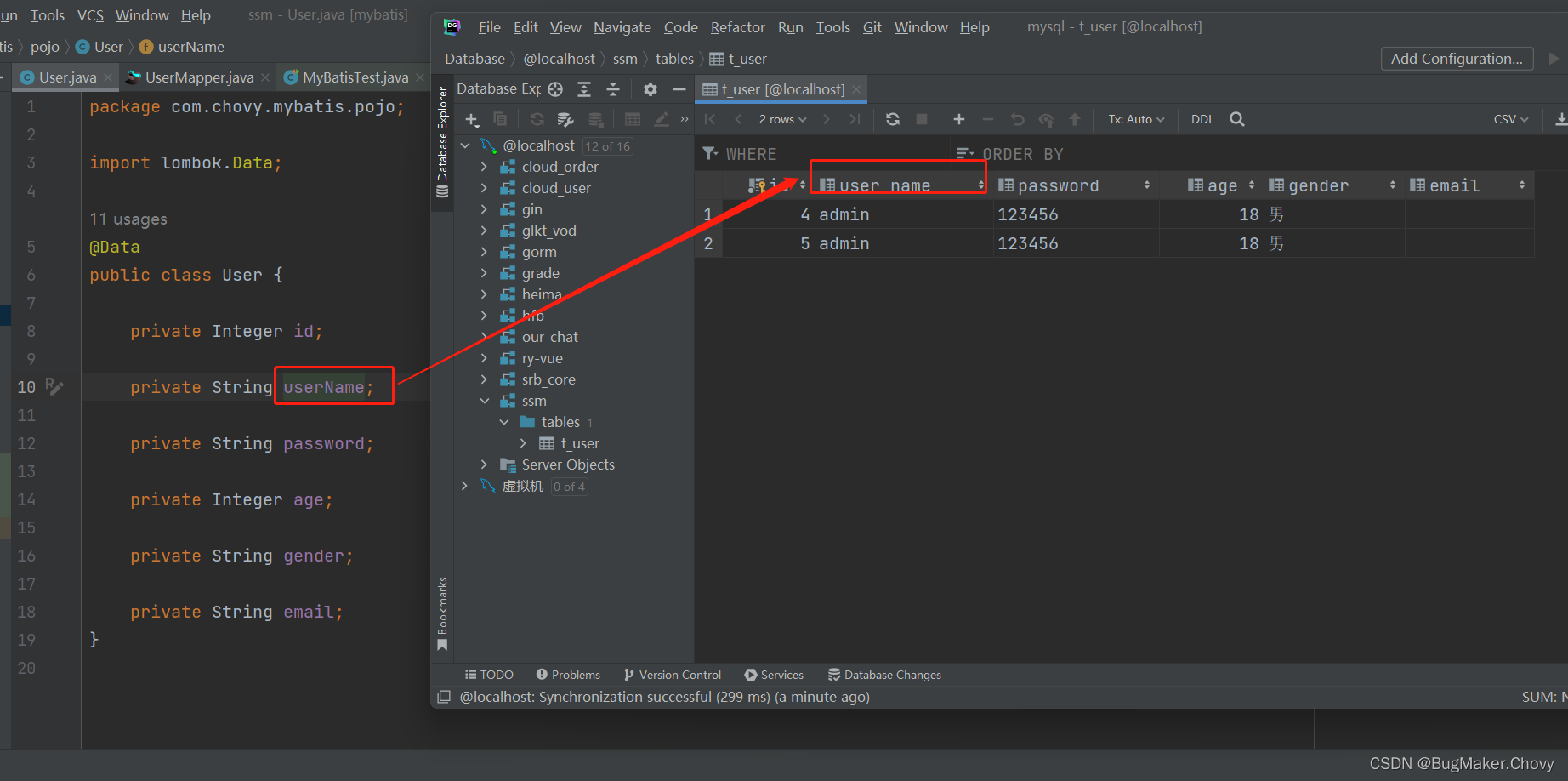
【MyBatis】自定义映射resultMap
8.1、resultMap处理字段和属性的映射关系 若字段名和实体类中的属性名不一致,则可以通过resultMap设置自定义映射 <!--resultMap:设置自定义映射属性:id:表示自定义映射的唯一标识type:查询的数据要映射的实体类的…...

mysql的锁和事务
mysql的锁 读写锁: 读锁是共享锁,多个用户在同一时刻可以读取同一资源,相互不受干扰写锁是排他锁,写锁会阻塞其他的写锁和读锁,这样可以确保在指定的时间内,只有一个用户可以写入 锁的颗粒度: …...

为什么B站中的弹幕可以不遮挡人物
上班逛B站时摸鱼时,看到了满屏的弹幕,而且还不挡脸,突然心血来潮来看看它是怎么实现的? 不难发现弹幕其实它就是有一个蒙版层div,遮挡在视频组件的上方,z-index层级设置的比较高(这里是11&…...
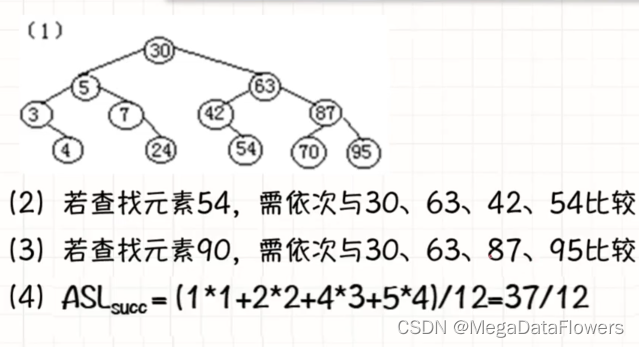
数据结构 第八章 查找(静态查找表)
集合 1、集合中的数据元素除了属于同一集合外,没有任何的逻辑关系 2、在集合中,每个数据元素都有一个区别于其他元素的唯一标识(键值或者关键字值) 3、集合的运算: 1 查找某一元素是否存在(内部查找、外部查找) 2 将集合中的元素按照它的唯一标识进行排序4、集合的…...
)
【Python基础】数据类型(元组、列表)
文章目录二. 数据类型2.1 元组 tuple2.1.1 定义特性2.1.2 拼接拷贝2.1.3 元组拆包2.1.4 元组方法 count2.2 列表 list2.2.1 基础定义2.2.2 增删操作2.2.3 连接联合2.2.4 其他常规操作2.2.5 列表推导式2.2.6 生成器表达式2.x 小结:何时使用元组或列表二. 数据类型 Py…...

你了解互联网APP搜索和推荐的背后逻辑么?
1.搜索和推荐无处不在我们习惯了百度、Google、360搜索的便捷,输入你想要搜索的关键词,立马呈现给你一批对应的结果,供你筛选。我们也经常上淘宝、京东、拼多多购物,输入想买的商品,瞬间列出一页一页的商品清单供我们选…...

Bug的级别,按照什么划分
Bug分类和定级一、bug的定义二、bug的类型三、bug的等级四、bug的优先级一、bug的定义一般是指不满足用户需求的则可以认为是bug,狭义指软件程序的漏洞或缺陷,广义指测试工程师或用户提出的软件可改进的细节、或与需求文档存在差异的功能实现等对应三个测…...
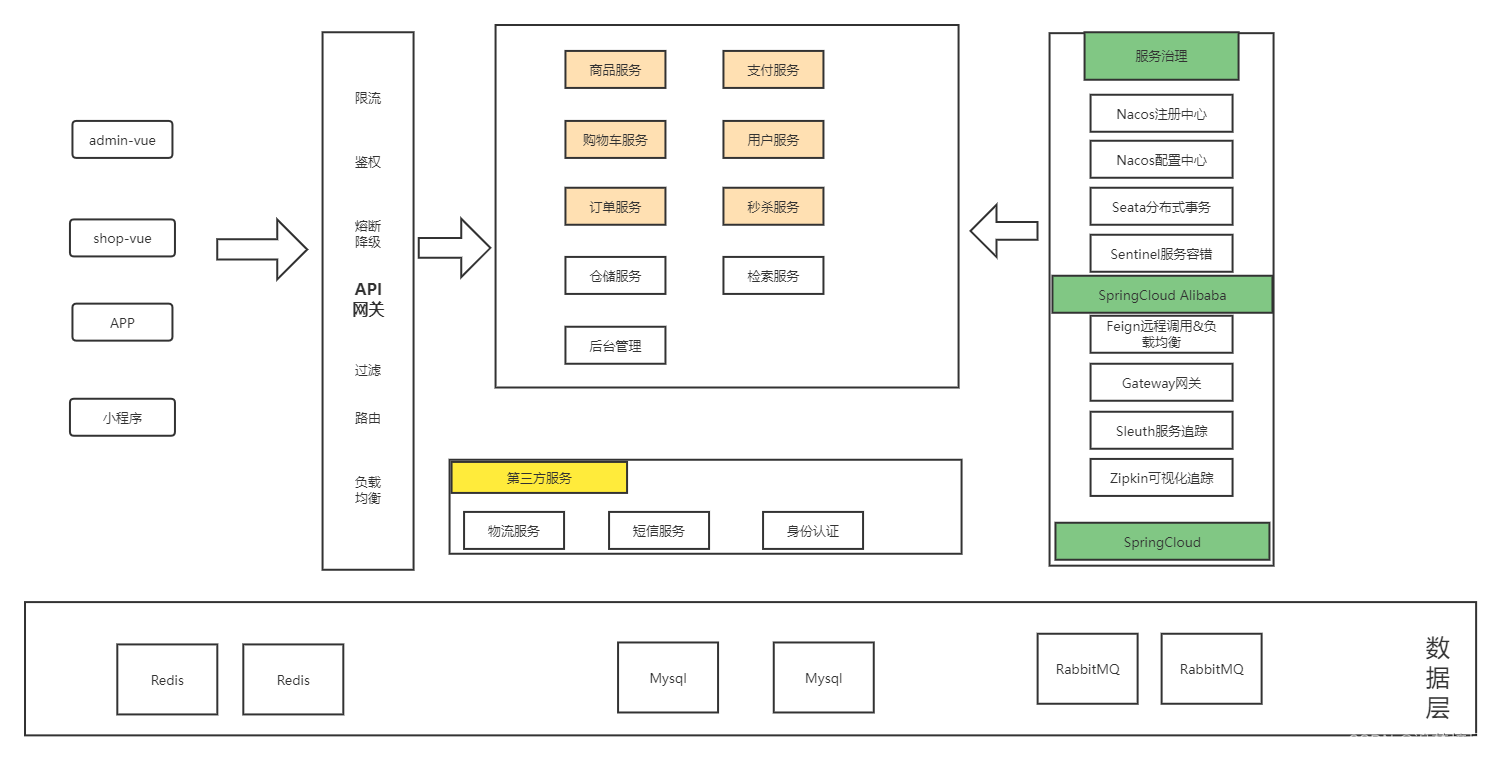
微服务项目简介
项目简介 项目模式 电商模式:市面上有5种常见的电商模式,B2B、B2C、 C2B、 C2C、O2O; 1、B2B模式 B2B (Business to Business),是指 商家与商家建立的商业关系。如:阿里巴巴 2、B2C 模式 B2C (Business to Consumer), 就是我们经常看到的供…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...
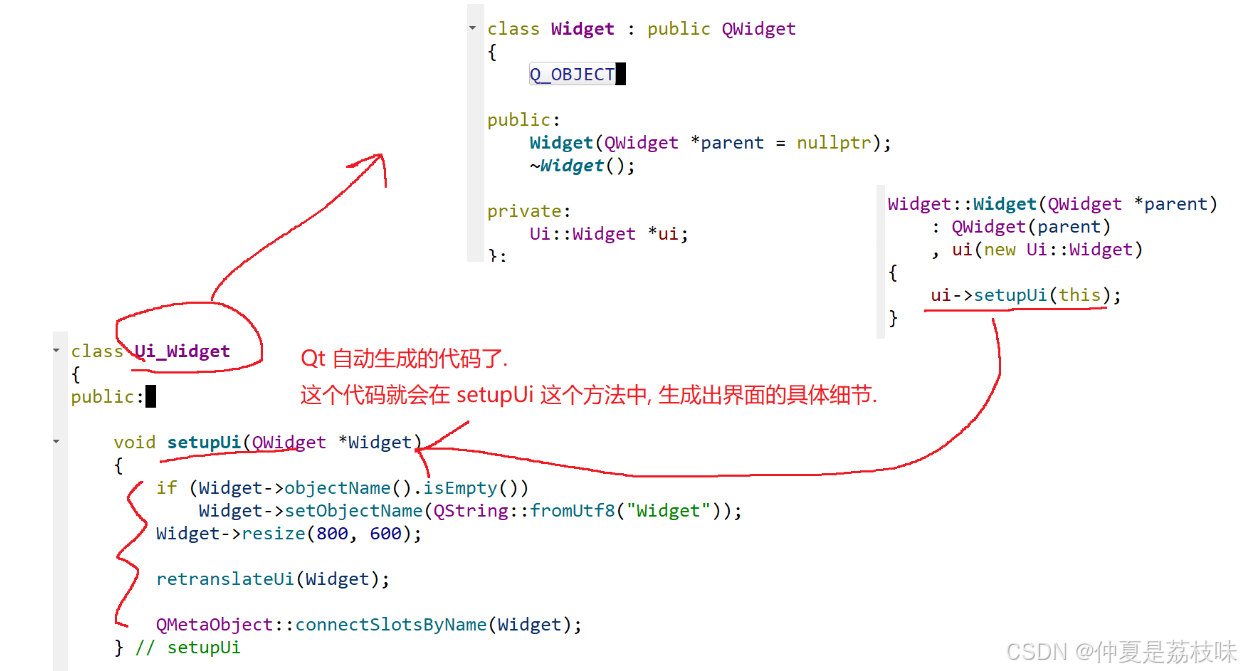
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...

LUA+Reids实现库存秒杀预扣减 记录流水 以及自己的思考
目录 lua脚本 记录流水 记录流水的作用 流水什么时候删除 我们在做库存扣减的时候,显示基于Lua脚本和Redis实现的预扣减 这样可以在秒杀扣减的时候保证操作的原子性和高效性 lua脚本 // ... 已有代码 ...Overridepublic InventoryResponse decrease(Inventor…...
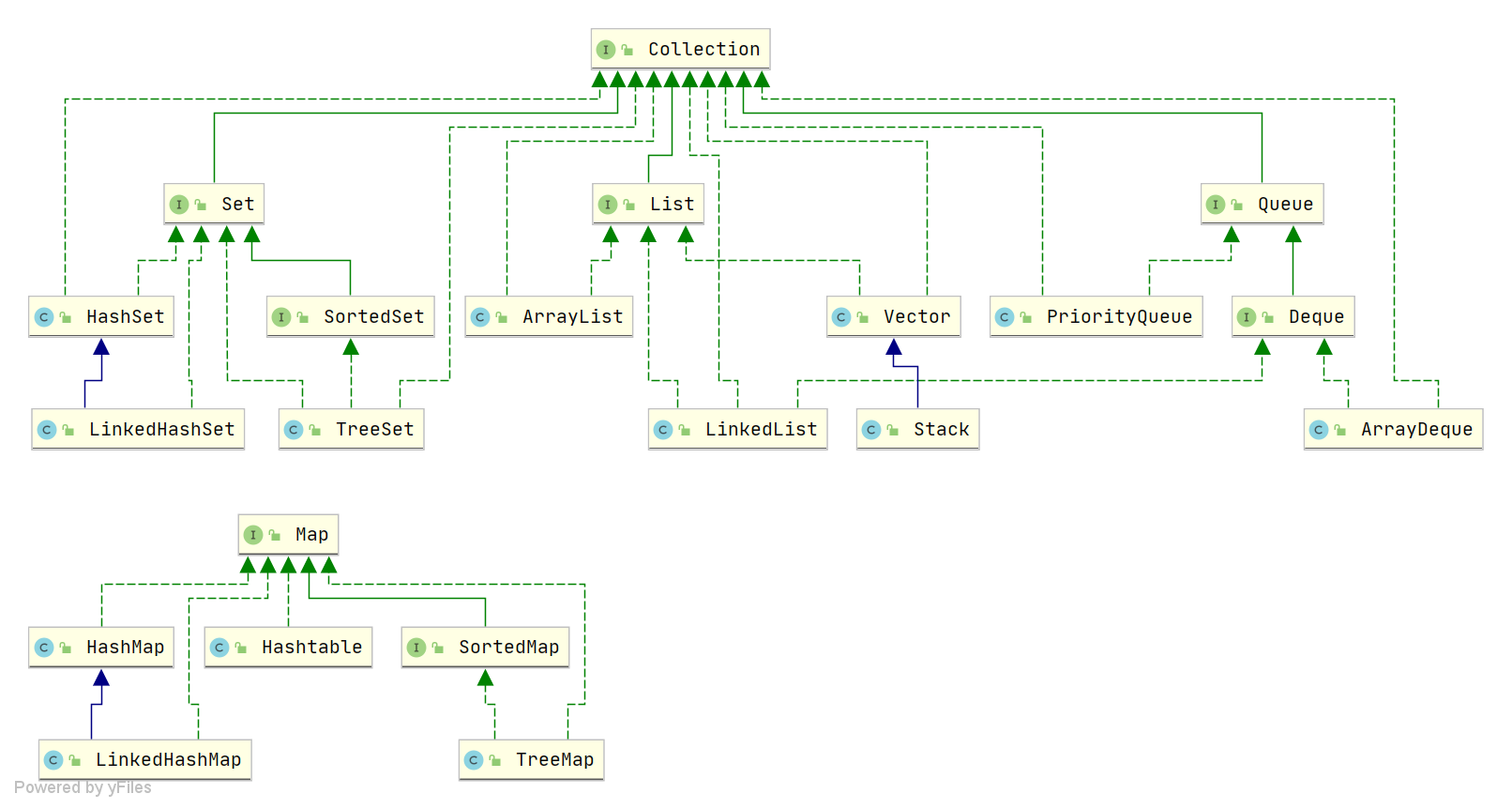
Java中HashMap底层原理深度解析:从数据结构到红黑树优化
一、HashMap概述与核心特性 HashMap作为Java集合框架中最常用的数据结构之一,是基于哈希表的Map接口非同步实现。它允许使用null键和null值(但只能有一个null键),并且不保证映射顺序的恒久不变。与Hashtable相比,Hash…...