【微服务】Nacos注册中心
🚩本文已收录至专栏:微服务探索之旅
👍希望您能有所收获
👍Nacos和Eureka一样也可以充当服务的注册中心,让我们一起看看有何区别?
点击跳转👉【微服务】Eureka注册中心
👍Nacos除了可以做注册中心,同样可以当作配置管理来使用。
了解配置管理用法点击跳转👉【微服务】Nacos配置管理
一.引入
-
Nacos是阿里巴巴的产品,现在是SpringCloud中的一个组件。相比于Eureka其功能更加丰富,在国内受欢迎程度较高。
-
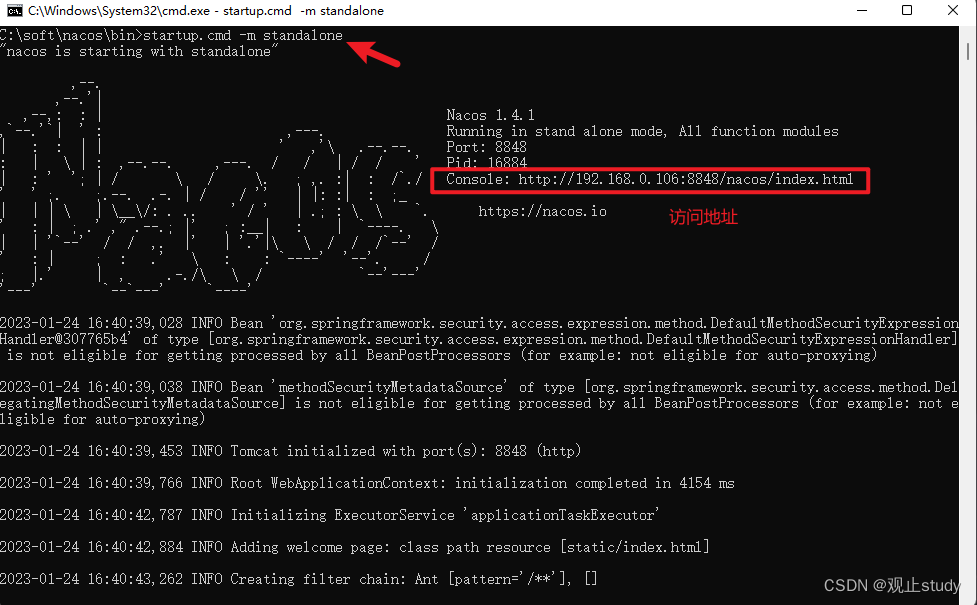
使用前可根据官网Nacos 快速开始安装并通过指令单机模式运行Nacos。
-
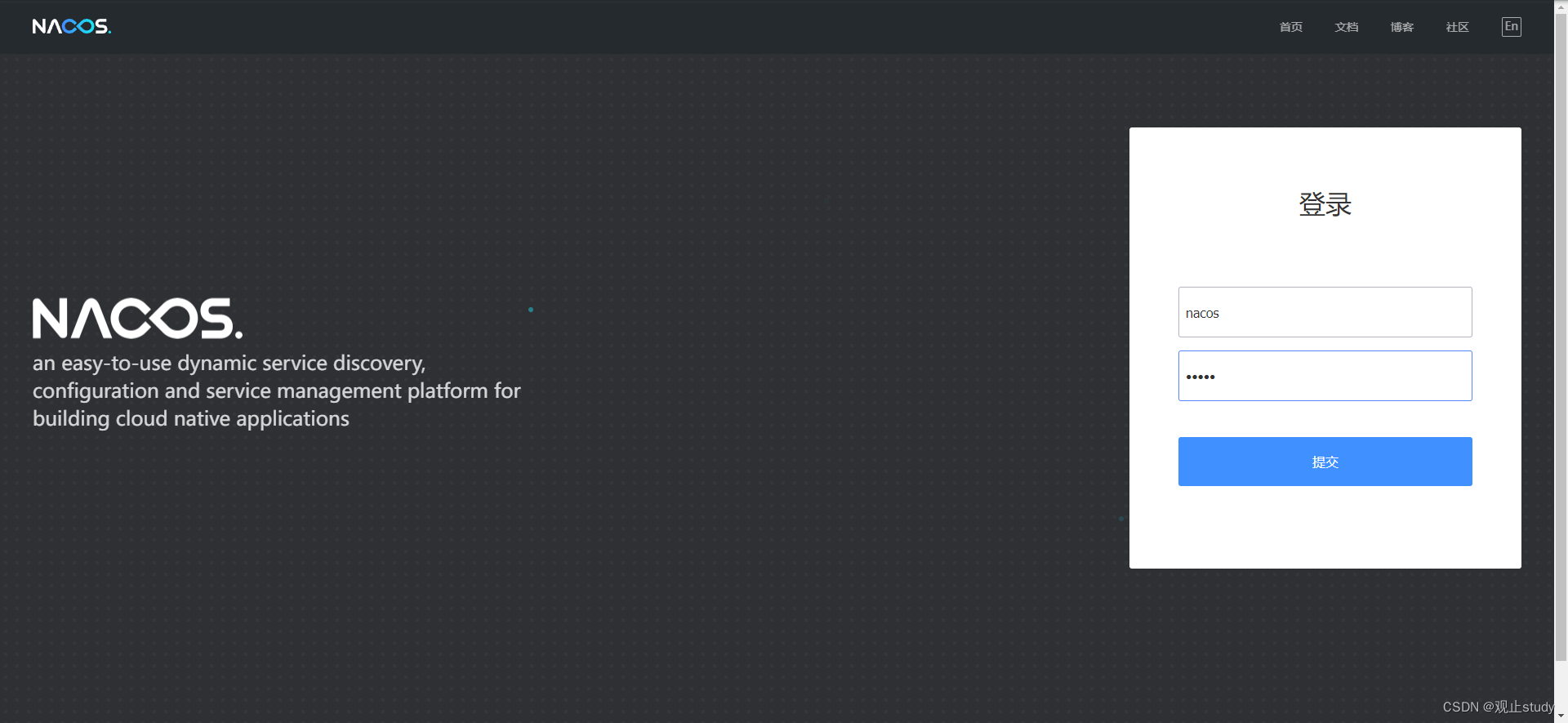
启动后访问Console地址:http://192.168.0.106:8848/nacos/index.html看到如下页面即可,账号密码都为nacos
-
接下来让我们一起在项目中使用它~
二.使用
(1) 前言
Nacos是SpringCloudAlibaba的组件,而SpringCloudAlibaba也遵循SpringCloud中定义的服务注册、服务发现规范。因此使用Nacos和使用Eureka对于微服务来说,并没有太大区别。
主要差异在于:
- 依赖不同
- 服务地址不同
(2) 引入依赖
- 在父工程的pom文件中的
<dependencyManagement>中引入SpringCloudAlibaba的管理依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>2.2.6.RELEASE</version><type>pom</type><scope>import</scope>
</dependency>
- 在子工程的pom文件中引入nacos-discovery依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
- 注:如果不通过父工程统一管理版本依赖,在子工程中使用需要指定具体版本。
(3) 配置地址
在子工程user-service和order-service的application.yml中添加nacos地址:
spring:cloud:nacos:server-addr: localhost:8848 # nacos服务端地址
(4) 测试
-
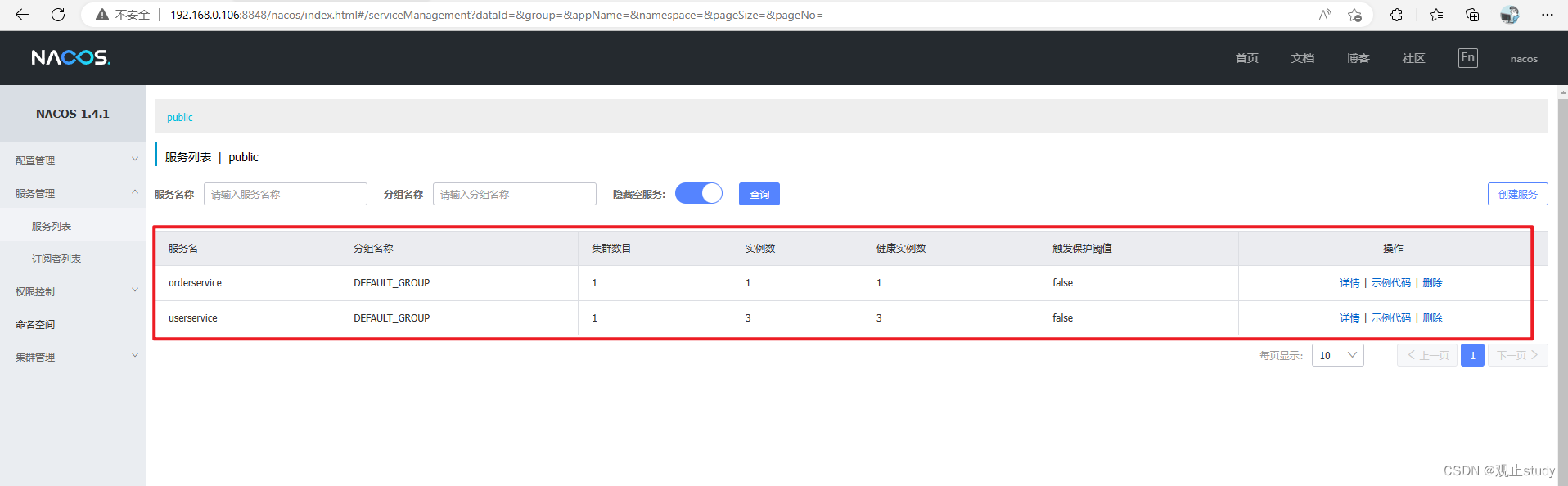
启动微服务后,在浏览器中登录nacos管理页面,可以看到微服务注册信息:
-
点击操作下方的详情我们可以看到更加详细的信息
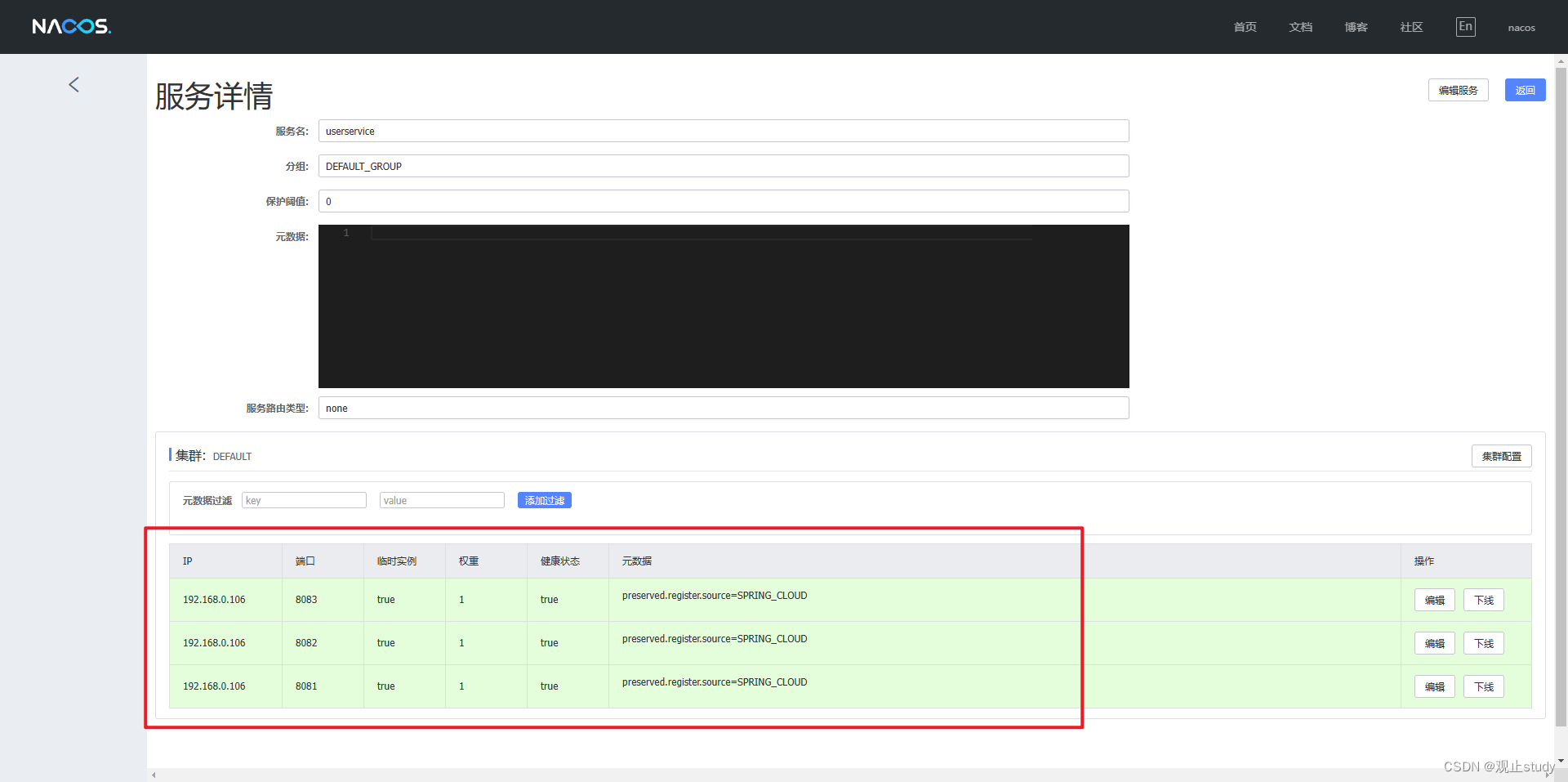
如此表明我们已经成功在项目中引入Nacos了。
三.服务分级存储模型
(1) 前言
-
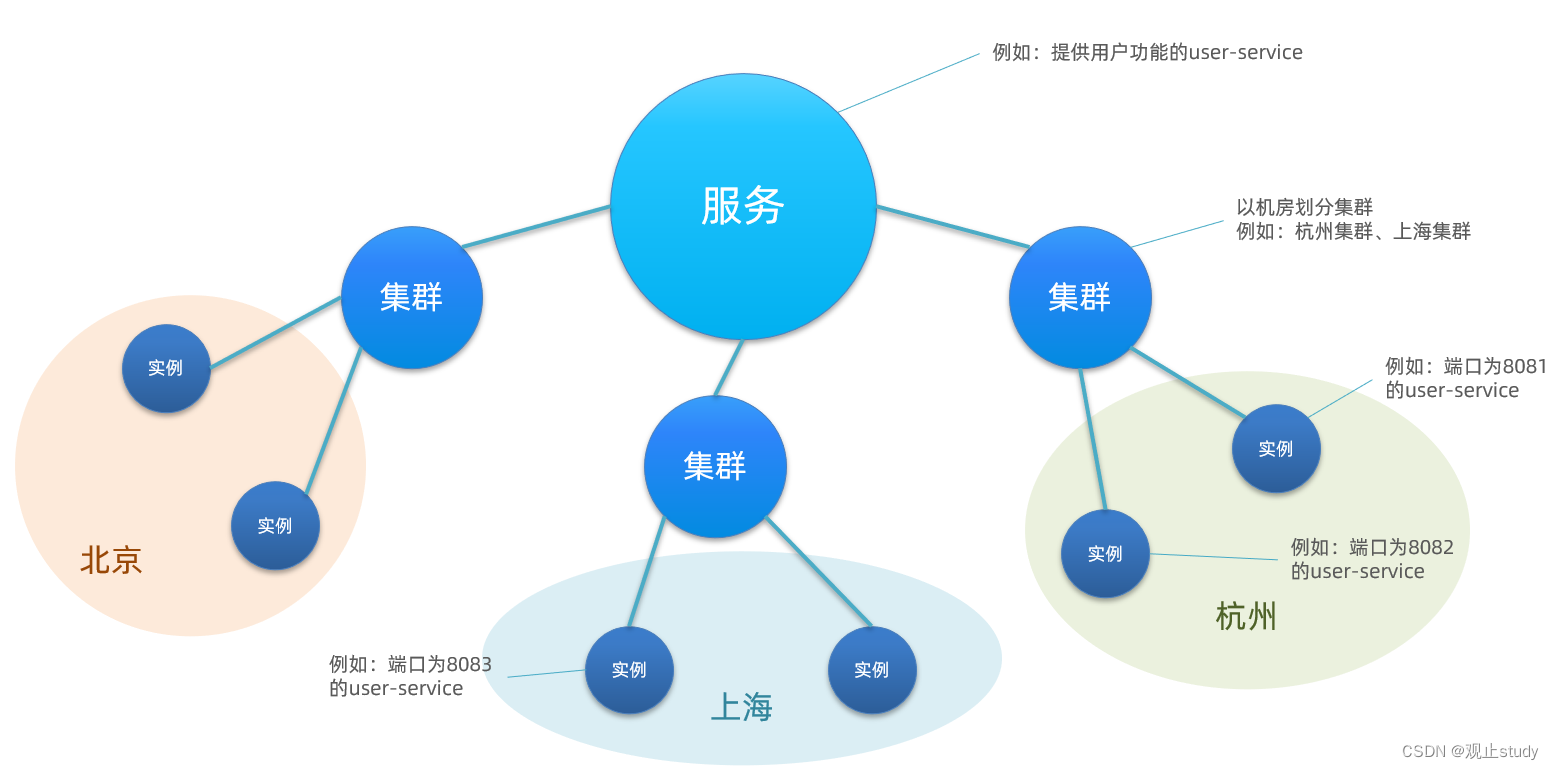
一个服务可以有多个实例,例如我们的user-service,可以有:
-
127.0.0.1:8081
-
127.0.0.1:8082
-
127.0.0.1:8083
-
-
假如这些实例分布于全国各地的不同机房,例如:
-
127.0.0.1:8081,在上海机房
-
127.0.0.1:8082,在上海机房
-
127.0.0.1:8083,在杭州机房
-
-
Nacos就将同一机房内的实例划分为一个集群。
-
总的来说:假设user-service是一个服务,而一个服务可以包含多个集群,如杭州、上海,每个集群下可以有多个实例,形成分级模型,如图:
-
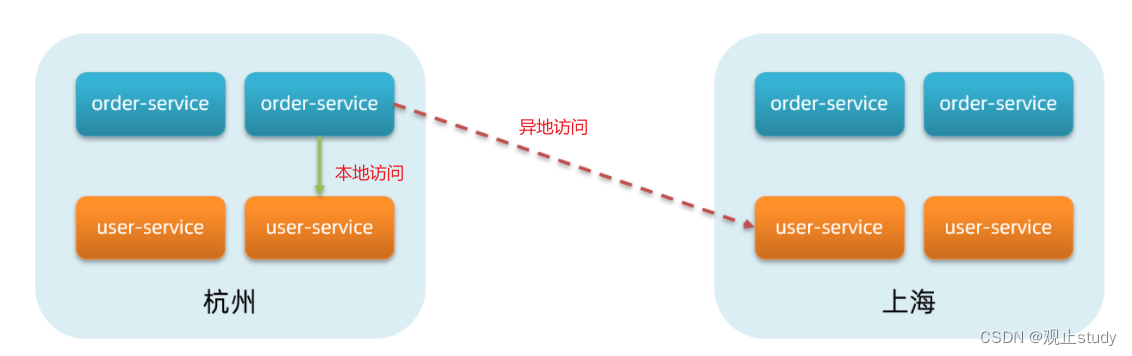
当微服务互相访问时,应该尽可能先访问同集群实例,因为本地访问速度更快。当本集群内不可用时,才访问其它集群。例如:
-
总结:Nacos引入集群概念就是为了防止出现跨集群调用,尽可能的避免。
(2) 配置集群
修改子工程user-service服务的application.yml文件,添加集群配置:
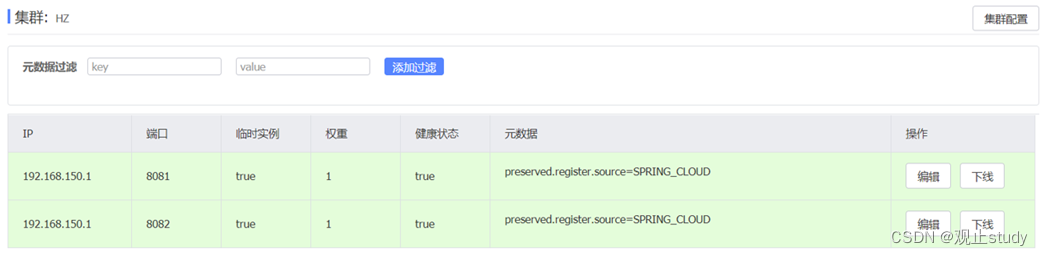
spring:cloud:nacos:server-addr: localhost:8848 # nacos服务端地址discovery:cluster-name: HZ # 集群名称,也就是机房所在位置
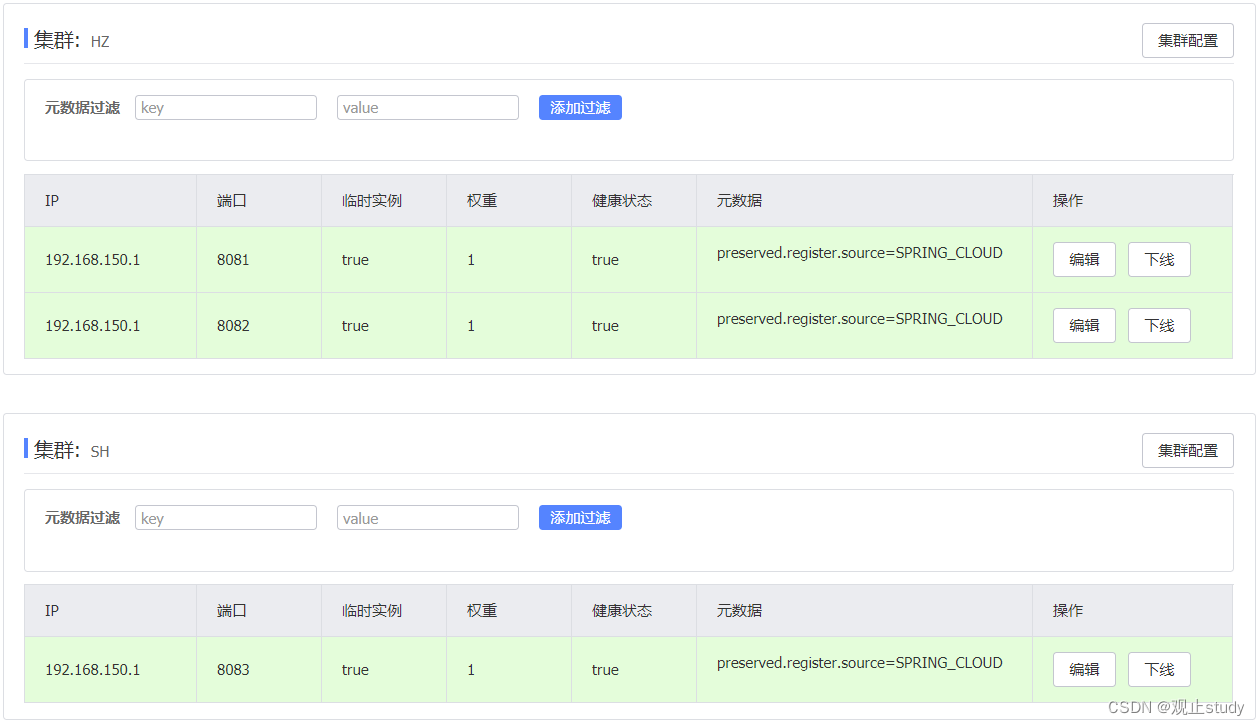
重启两个user-service实例后,我们可以在nacos控制台看到下面结果:
我们再次复制一个user-service启动配置,添加属性:
-Dserver.port=8083 -Dspring.cloud.nacos.discovery.cluster-name=SH
配置如图所示:
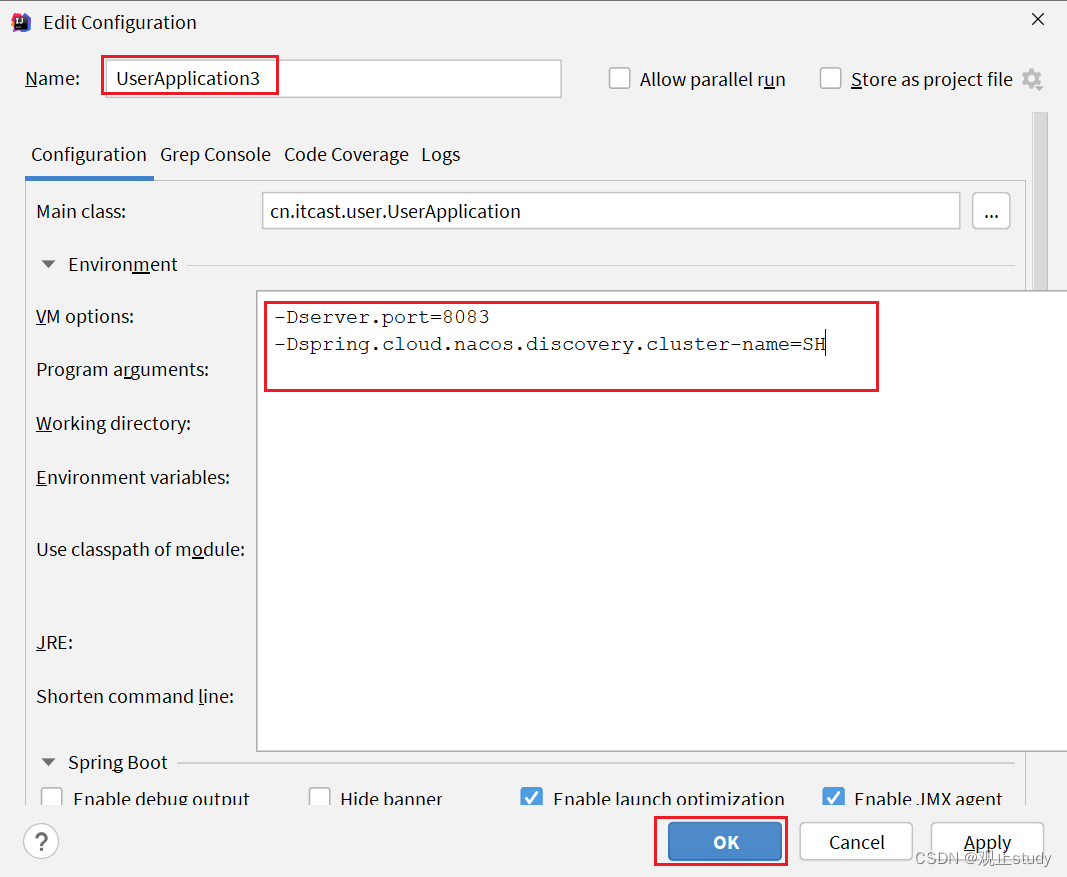
启动UserApplication3后再次查看nacos控制台:
(3) 同集群优先的负载均衡
-
注意:默认的
ZoneAvoidanceRule并不能实现根据同集群优先来实现负载均衡。 -
我们需要修改负载均衡规则为
NacosRule,实现优先从同集群中挑选实例。 -
修改order-service的application.yml文件,
- 给order-service添加集群配置:
spring:cloud:nacos:server-addr: localhost:8848discovery:cluster-name: HZ # 集群名称- 修改负载均衡规则:
userservice: # 要调用的微服务名称ribbon:NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则 -
至此可以实现同集群优先调用,当本地集群都无法调用时则会选择其他集群并给出警告信息。

四.权重配置
(1) 前言
-
实际部署中会出现这样的场景:
- 服务器设备性能有差异,部分实例所在机器性能较好,另一些较差,我们希望性能好的机器承担更多的用户请求。
-
但默认情况下NacosRule是同集群内随机挑选,不会考虑机器的性能问题。
-
因此,Nacos提供了权重配置来控制访问频率,权重越大则访问频率越高。
(2) 修改权重
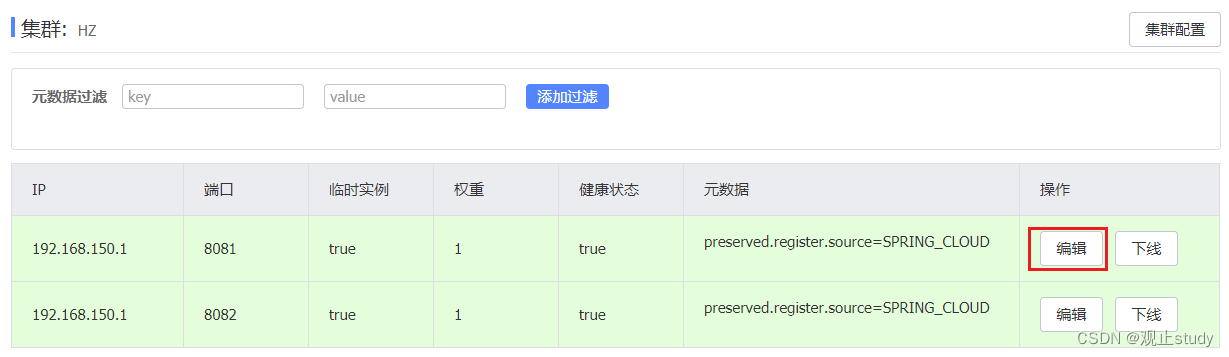
-
在nacos控制台,找到user-service的实例列表,点击编辑,即可修改权重:
-
在弹出的编辑窗口,修改权重(范围0~1,权重越高访问频率越高):
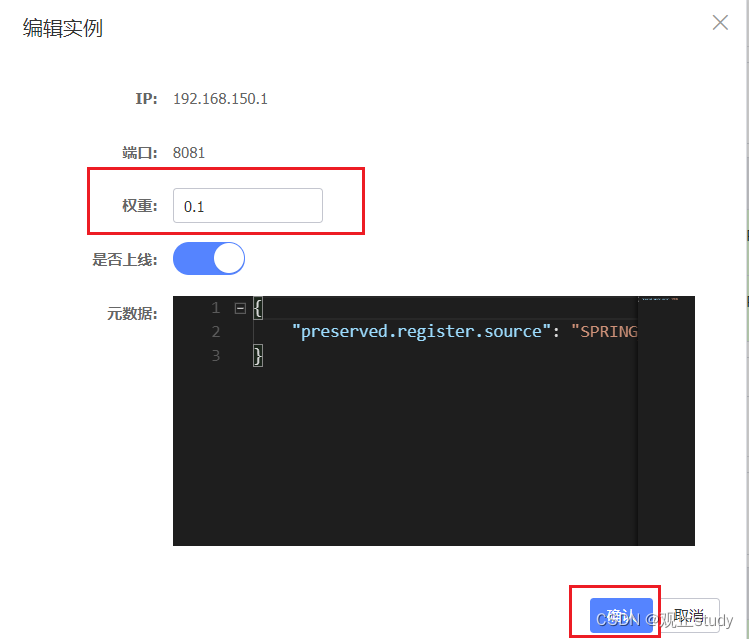
注意:如果权重修改为0,则该实例永远不会被访问
五.环境隔离
(1) 前言
Nacos提供了namespace来实现多环境隔离功能。
- nacos中可以有多个namespace
- namespace下可以有group、service等
- 不同namespace之间相互隔离,例如不同namespace的服务互相不可见
(2) 配置
(2.1) 创建namespace
-
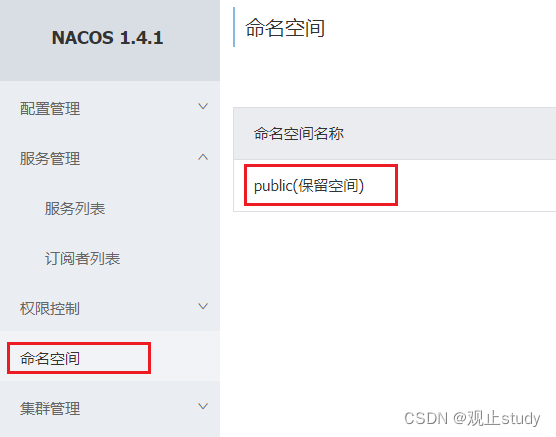
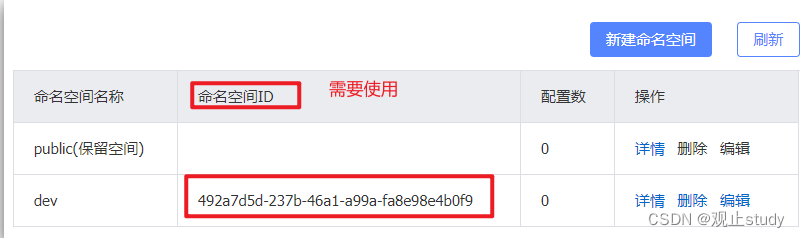
默认情况下,所有service、data、group都在同一个namespace,名为public:
-
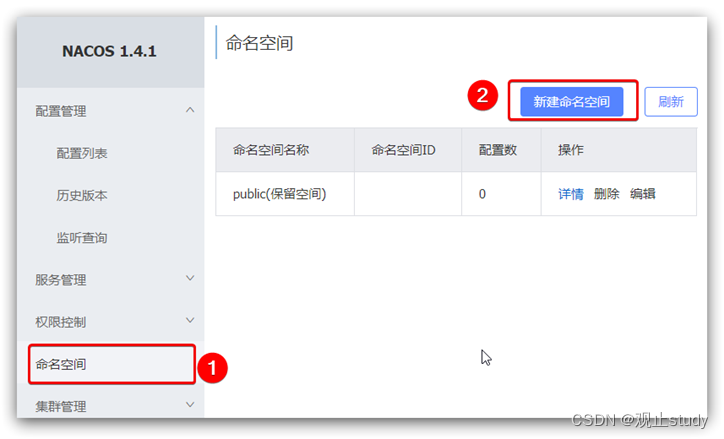
我们可以点击页面新增按钮,添加一个namespace:
-
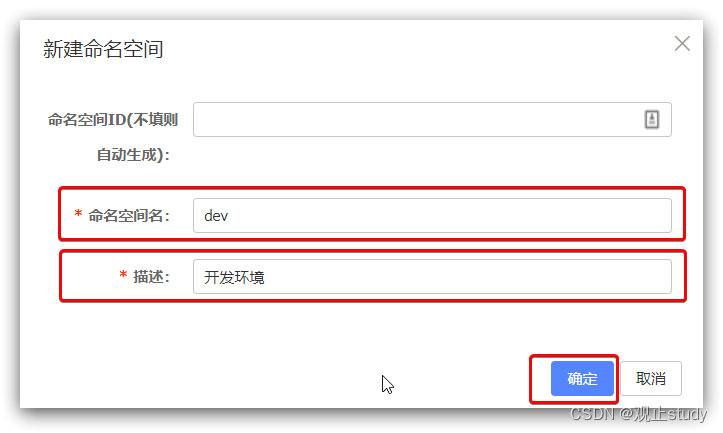
填写表单:
-
然后就能在页面看到一个新的namespace:
(2.2) 给微服务配置namespace
- 给微服务配置namespace只能通过修改配置来实现。
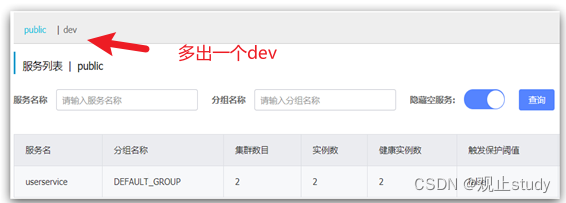
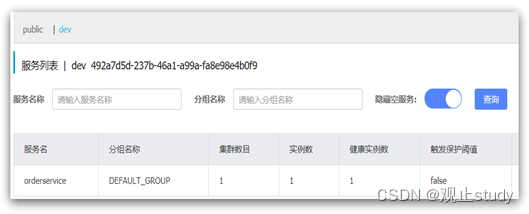
例如,修改order-service的application.yml文件:
spring:cloud:nacos:server-addr: localhost:8848discovery:cluster-name: HZnamespace: 492a7d5d-237b-46a1-a99a-fa8e98e4b0f9 # 命名空间,填上述ID
重启order-service后,访问控制台,可以看到下面的结果:
(3) 测试
- 此时访问order-service,因为所在namespace不同,会导致找不到userservice,控制台会报错:

六.Nacos与Eureka的区别
Nacos的服务实例分为两种类型:
-
临时实例:如果实例宕机超过一定时间,会从服务列表剔除,默认的类型。
-
非临时实例:如果实例宕机,不会从服务列表剔除,也可以叫永久实例。
配置一个服务实例为永久实例:
spring:cloud:nacos:discovery:ephemeral: false # 设置为非临时实例
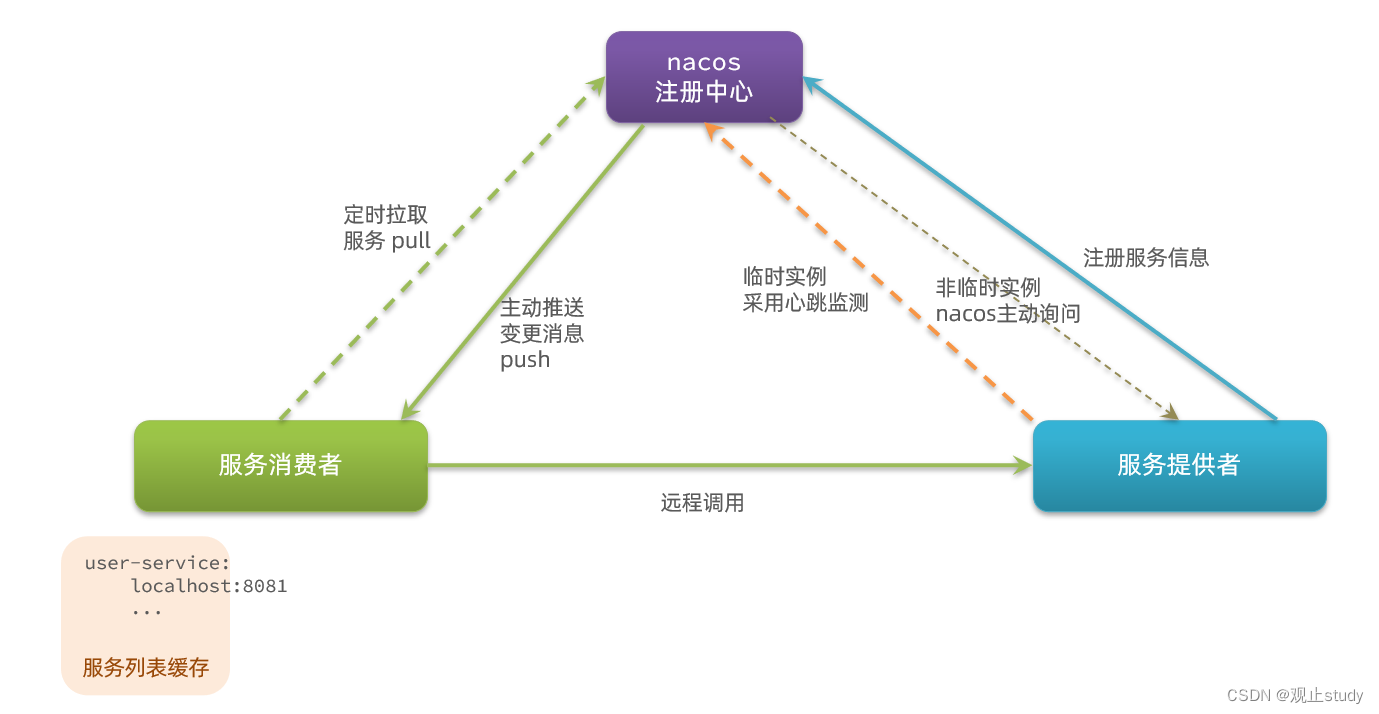
Nacos和Eureka整体结构类似,服务注册、服务拉取、心跳等待,但是也存在一些差异:

-
Nacos与eureka的共同点
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
-
Nacos与Eureka的区别
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
相关文章:
【微服务】Nacos注册中心
🚩本文已收录至专栏:微服务探索之旅 👍希望您能有所收获 👍Nacos和Eureka一样也可以充当服务的注册中心,让我们一起看看有何区别? 点击跳转👉【微服务】Eureka注册中心 👍Nacos除了可…...

跟开发打了半个月后,我终于get报bug的正确姿势了
在测试人员提需求的时候,大家经常会看到,测试员和开发一言不合就上BUG。然后开发一下就炸了,屡试不爽,招招致命。 曾经看到有个段子这么写道: 不要对程序员说,你的代码有BUG。他的第一反应是:…...

js万能类型检测Object.prototype.toString.call——定制Object.prototype.toString.call的检测结果
javascript的类型检测 1、typeof typeof操作符可以检测js的基础数据类型,包括number、string、boolean、undefined。因为null在二进制存储的值与object相同,所以typeof检测null会返回object。此为特例 2、instanceof instanceof操作符可以检测某个对…...
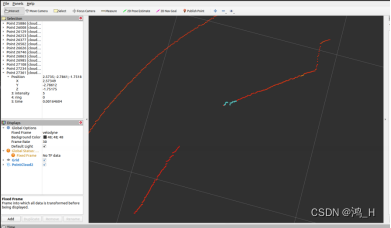
激光slam学习笔记2--激光点云数据结构特点可视化查看
背景:不同厂商的激光点云结果存在一定差异,比如有些只有xyz,有些包含其他,如反光率、时间戳、ring等。如何快速判断是个值得学习的点 概要:对于rosbag类型的激光点云,介绍使用rviz快速查看点云结构特点 如…...
SpringBoot笔记【JavaEE】
SpringBoot概念、创建和运行 1.什么是SpringBoot?为什么学习SpringBoot? Spring Boot 就是 Spring 框架的脚⼿架,它就是为了快速开发 Spring 框架⽽诞⽣的。 2.Spring Boot优点 快速集成框架【提供启动添加依赖的功能】内容运行容器【无需…...

目标检测算法之voxelNet与pointpillars对比
算法对比 3D目标检测发展简史 点云目标检测目前发展历经VoxelNet、SECOND、PointPillars、PV-RCNN。 2017年苹果提出voxelnet,是最早的一篇将点云转成voxel体素进行3D目标检测的论文。 然后2018年重庆大学的一个研究生Yan Yan在自动驾驶公司主线科技实习的时候将vo…...
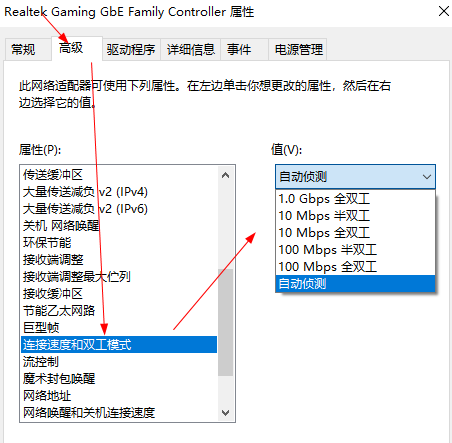
电脑里的连接速度双工模式是什么?怎么设置
双工模式包括全双工、半双工模式。1.半双工1、半双工数据传输允许数据在两个方向上传输,但是,在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信。所谓半双工就是指一个时间段内只有一个动作发生。早期的对…...
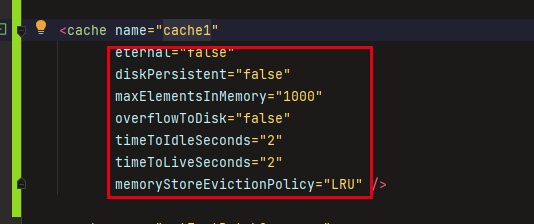
springboot整合单机缓存ehcache
区别于redis的分布式缓存,ehcache是纯java进程内的单机缓存,根据不同的场景可选择使用,以下内容主要为springboot整合ehcache以及注意事项添加pom引用<dependency><groupId>net.sf.ehcache</groupId><artifactId>ehc…...

在阿里干了2年的测试,总结出来的划水经验
测试新人 我的职业生涯开始和大多数测试人一样,开始接触都是纯功能界面测试。那时候在一家电商公司做测试,做了一段时间,熟悉产品的业务流程以及熟练测试工作流程规范之后,效率提高了,工作比较轻松,这样我…...
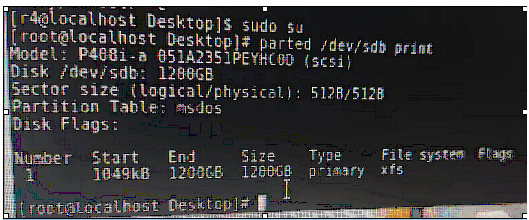
硬盘分类及挂载硬盘知识补充和介绍
一、硬盘介绍Linux硬盘分IDE硬盘和SCSI硬盘,目前基本上是SCSI硬盘1.对于IDE硬盘,驱动器标识符为"hdx~",其中"hd"表明分区所在设备的类型,这里是指IDE硬盘了。"x"为盘号(a为基本盘,b为基…...
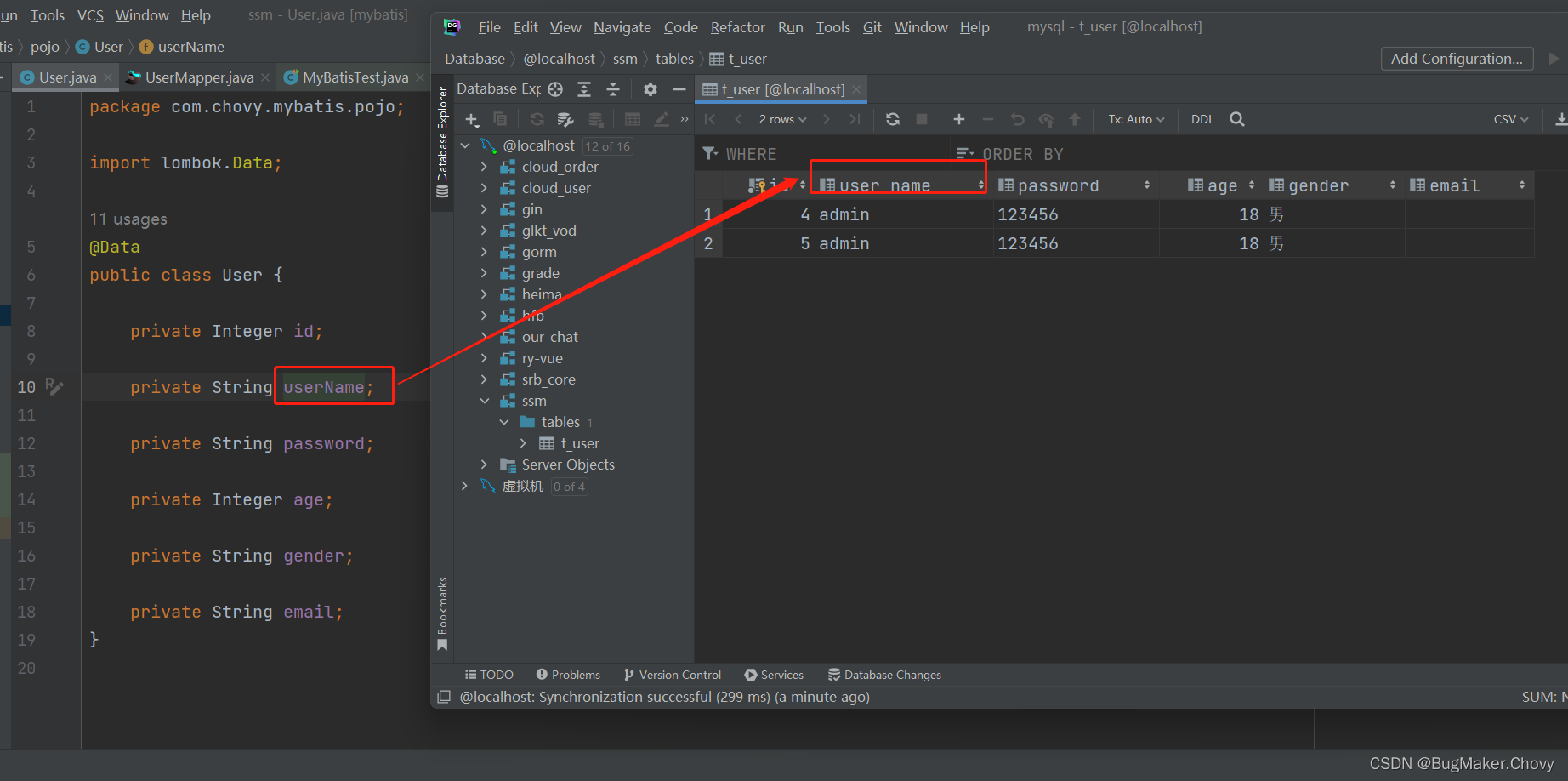
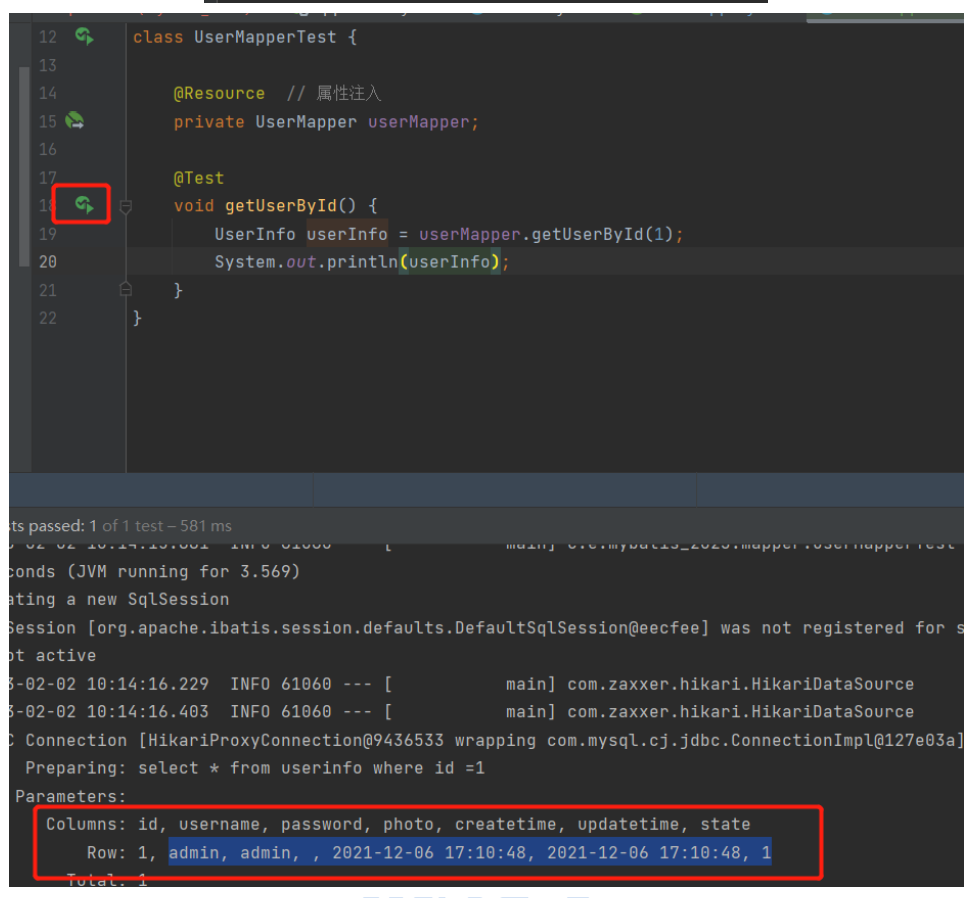
【MyBatis】自定义映射resultMap
8.1、resultMap处理字段和属性的映射关系 若字段名和实体类中的属性名不一致,则可以通过resultMap设置自定义映射 <!--resultMap:设置自定义映射属性:id:表示自定义映射的唯一标识type:查询的数据要映射的实体类的…...

mysql的锁和事务
mysql的锁 读写锁: 读锁是共享锁,多个用户在同一时刻可以读取同一资源,相互不受干扰写锁是排他锁,写锁会阻塞其他的写锁和读锁,这样可以确保在指定的时间内,只有一个用户可以写入 锁的颗粒度: …...

为什么B站中的弹幕可以不遮挡人物
上班逛B站时摸鱼时,看到了满屏的弹幕,而且还不挡脸,突然心血来潮来看看它是怎么实现的? 不难发现弹幕其实它就是有一个蒙版层div,遮挡在视频组件的上方,z-index层级设置的比较高(这里是11&…...
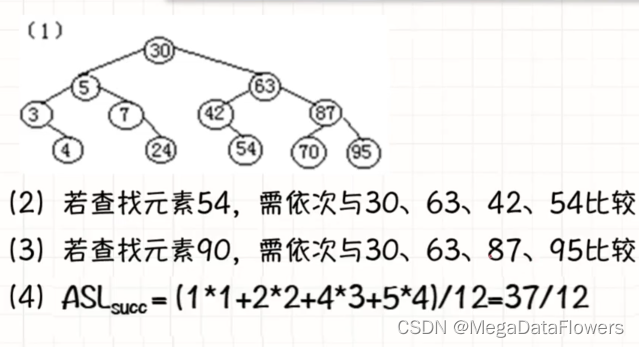
数据结构 第八章 查找(静态查找表)
集合 1、集合中的数据元素除了属于同一集合外,没有任何的逻辑关系 2、在集合中,每个数据元素都有一个区别于其他元素的唯一标识(键值或者关键字值) 3、集合的运算: 1 查找某一元素是否存在(内部查找、外部查找) 2 将集合中的元素按照它的唯一标识进行排序4、集合的…...
)
【Python基础】数据类型(元组、列表)
文章目录二. 数据类型2.1 元组 tuple2.1.1 定义特性2.1.2 拼接拷贝2.1.3 元组拆包2.1.4 元组方法 count2.2 列表 list2.2.1 基础定义2.2.2 增删操作2.2.3 连接联合2.2.4 其他常规操作2.2.5 列表推导式2.2.6 生成器表达式2.x 小结:何时使用元组或列表二. 数据类型 Py…...

你了解互联网APP搜索和推荐的背后逻辑么?
1.搜索和推荐无处不在我们习惯了百度、Google、360搜索的便捷,输入你想要搜索的关键词,立马呈现给你一批对应的结果,供你筛选。我们也经常上淘宝、京东、拼多多购物,输入想买的商品,瞬间列出一页一页的商品清单供我们选…...

Bug的级别,按照什么划分
Bug分类和定级一、bug的定义二、bug的类型三、bug的等级四、bug的优先级一、bug的定义一般是指不满足用户需求的则可以认为是bug,狭义指软件程序的漏洞或缺陷,广义指测试工程师或用户提出的软件可改进的细节、或与需求文档存在差异的功能实现等对应三个测…...
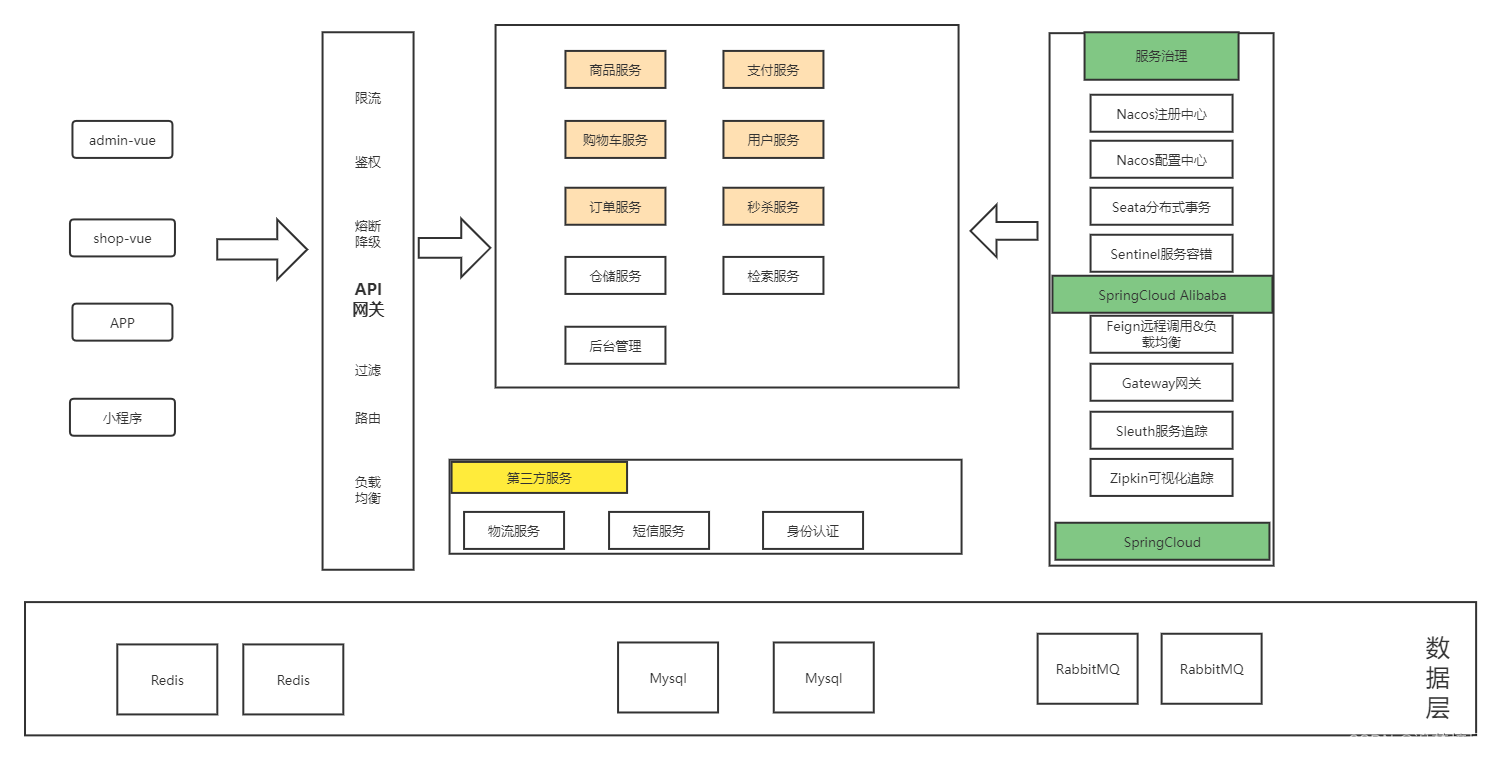
微服务项目简介
项目简介 项目模式 电商模式:市面上有5种常见的电商模式,B2B、B2C、 C2B、 C2C、O2O; 1、B2B模式 B2B (Business to Business),是指 商家与商家建立的商业关系。如:阿里巴巴 2、B2C 模式 B2C (Business to Consumer), 就是我们经常看到的供…...

SLAM中坐标轴旋转及ros的接口解释
读完几个loam算法,满篇的坐标轴旋转,还是手写的(作者,用eigen写不好嘛。。。),我滴天适应了好久…,今天就总结一下坐标轴旋转问题。 一、首先,我们看一下ros中关于欧拉角旋转的函数:setRPY、set…...
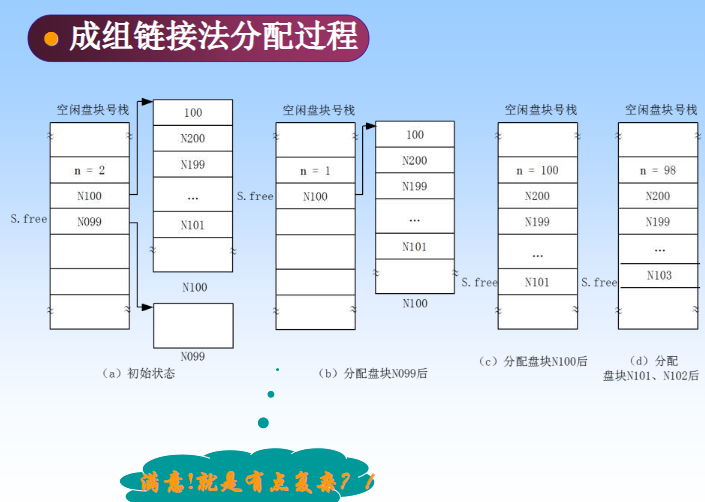
文件管理(9)
文件管理 0 引言 为什么要引入文件系统? 信息管理的需要:用户面前提供一种规格化的机制,方便用户对文件的存取、提高效率。操作系统本身需要–操作系统本身也不是常驻内存的,也有大量的信息需要存于外存。 1 文件定义 文件&a…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...
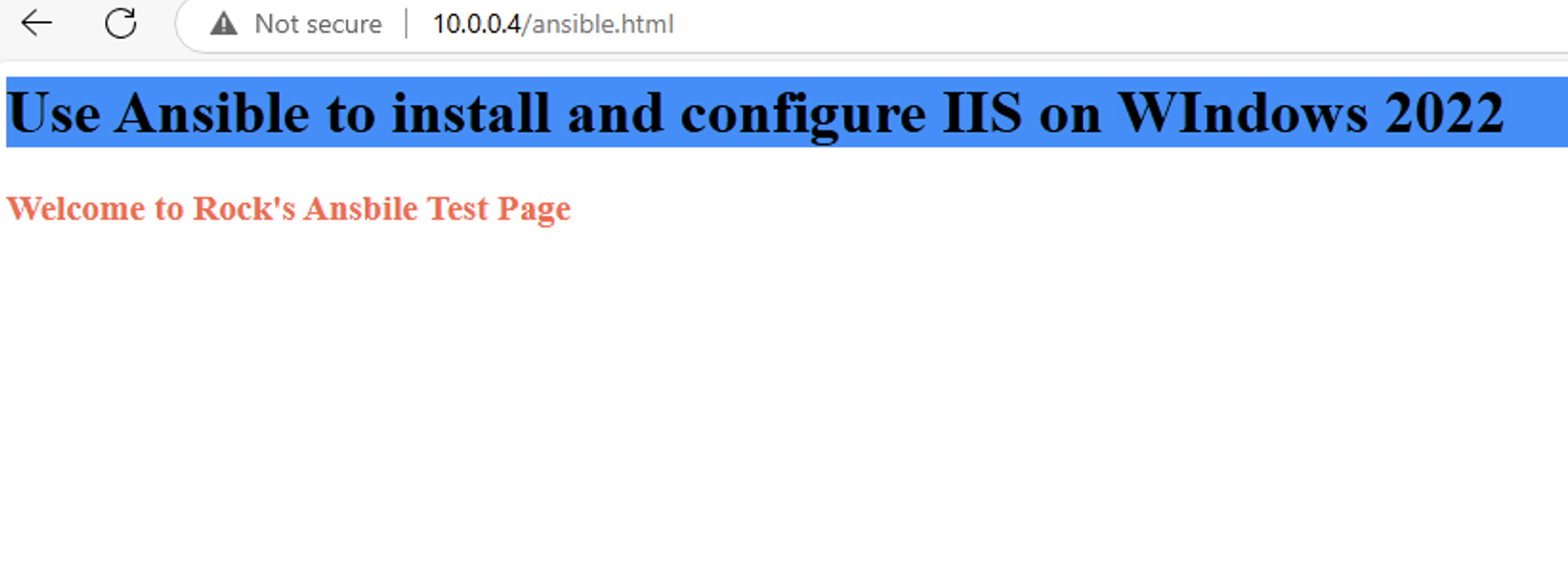
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...