Elasticsearch索引全生命周期管理一网打尽
文章目录
- 一、索引增删改查
- 1.1、创建索引
- 1.2、查询索引
- 1.3、修改索引
- 1.4、删除索引
- 二、索引关闭和打开
- 2.1、关闭索引
- 2.2、打开索引
- 三、索引收缩和拆分
- 3.1、索引收缩
- 3.2、索引拆分
- 3.2.1、索引拆分的工作过程
- 3.2.2、为什么Elasticsearch不支持增量的重新分片?
- 3.2.3、如何监控Split的进度
- 四、索引克隆
- 4.1、索引克隆
- 4.2、索引克隆的过程
- 4.3、索引克隆的监控
- 五、索引滚动
- 六、索引冻结和解冻
- 6.1、索引冻结
- 6.2、索引解冻
- 七、索引解析
公众号:MCNU云原生,欢迎微信搜索关注,更多干货,及时掌握。
索引(Index)是Elasticsearch中最重要的概念之一,也是整个Elasticsearch操作的基础,它是相互关联的文档的一个集合。在Elasticsearch种,数据存储为 JSON 文档,每个文档将一组键(字段或属性的名称)与其对应的值(字符串、数字、布尔值、日期、地理位置或其他类型的数据)相关联,Elasticsearch 使用一种称为倒排索引的数据结构,旨在实现非常快速的全文搜索。倒排索引列出了出现在任何文档中的每个唯一单词,并标识了每个单词出现的所有文档。
Elasticsearch提供了Index APIs用于Elasticsearch生命周期的管理,包括索引的创建、查询、删除和设置,索引的冻结和解冻、拆分和收缩等,掌握索引的管理是Elasticsearch开发、运维的基础能力,也有助于Elasticsearch的优化。
一、索引增删改查
1.1、创建索引
创建一个索引可以使用Elasticsearch提供的API,其格式如下:
PUT /<index>
其中为要创建的索引的名称,是一个必须的参数,所有的字母都必须是小写形式。在创建索引的同时还可以进行相关的设置:
-
索引的设置,如分片的数量、副本的数量等。
-
索引字段的映射
-
索引别名设置
一个不做任何设置的,单纯创建索引的请求如下:
curl -X PUT "localhost:9200/my-index-000001?pretty"{"acknowledged" : true,"shards_acknowledged" : true,"index" : "my-index-000001"
}
响应体中“acknowledged”为true代表索引已经成功在Elasticsearch集群中创建,“shards_acknowledged”为true则代表在请求超时之前所有的索引分片的副本分片也全部准备完毕。当然,即使“acknowledged”和"shards_acknowledged"都为false,只能代表超时之前没有完成,后续集群还是可能最终成功创建了索引。
创建索引的API还支持Query Parameters和Request Body,其中的参数均是可选的参数。
Query Parameters支持以下参数:
wait_for_active_shards
代表请求等待多少个分片active以后返回,默认值为1,代表只等待主分片返回即可。设置为all则代表等待所有的分片为active(主分片和副本分片),可以设置为1~(number_of_replicas+1)。master_timeout
代表连接主节点的超时时间,默认为30s。timeout
等待响应的超时时间,默认为30s。
Request Body也支持三个参数:
-
aliases
aliases是一个数组对象,内部对象alias是一个必须的参数,可以有以下的属性,这些属性本身都是可选的: -
- filter
DSL表达式,用于限制使用别名可以访问的文档。 - index_routing
用于进行索引时计算分片,如果指定了这个值将会在索引的时候覆盖默认的routing。 - is_hidden
布尔值,默认为false,当设置为true时代表别名是隐藏不可用的,所有拥有相同别名的索引的is_hidden的值必须是设置成一样的。 - is_write_index
标记作为别名的写索引,一个别名同时只能有一个写索引,默认为false。 - routing
用于索引和查询时路由到对应的分片。 - search_routing
用于进行搜索时计算分片,如果指定了这个值将会在进行搜索的时候覆盖默认的routing。
- filter
-
mappings
mappings参数指定了索引的字段的映射关系,包括字段名称、字段类型、映射参数等。 -
settings
针对单个索引级别的设置,可以分为static(静态)和dynamic(动态)索引设置,static静态设置只能用于索引创建或者已关闭的索引,而dynamic的设置可以是针对一个活跃的索引生效,这些设置可以是主分片数量、副本分片数量等。
以下代码示例同时指定了Query Parameters和Request Body**:**
curl -X PUT -H 'Content-Type:application/json' --data
'{"settings":{"index":{"number_of_shards":3,"number_of_replicas":2}},"mappings":{"user":{"properties":{"id":{"type":"keyword"},"name":{"type":"text"}}}},"aliases":{"alias_1":{},"alias_2":{"filter":{"term":{"id":"440581873934746511"}},"routing":"shard-1","is_hidden":false,"is_write_index":false}}
}' "localhost:9200/my-index-000001?pretty&wait_for_active_shards=1&master_timeout=60s&timeout=60s"
1.2、查询索引
通过Get index API,可以查询一个或者多个索引的相关信息,其API格式如下:
GET /<target>
其中target可以是数据流、索引,还可以是一个别名,多个索引之间使用逗号分隔,target还支持模糊查询(*),如果查询所有的索引,可以使用*或者_all。如果集群开启了安全权限控制,那么要查询索引信息需要获得view_index_metadata或者manage的索引操作权限。以下为查询的具体案例:
curl -X GET "localhost:9200/my-index-000001?pretty"
Get index API支持带url查询参数,这些参数都是可选参数,主要有以下几个:
-
allow_no_indices
默认为true,如果为false的话,则如果使用了模糊查询、索引别名、_all作为目标查询,则一旦没有对应的索引或者索引已关闭,则返回错误。即便是多目标查询,如“foo*,boo*”,存在foo开头的索引而不存在boo开头的索引的话,也会返回错误。 -
expand_wildcards
指示了如果使用了模糊查询,可以匹配的索引的类型(状态),默认值为open。all
openclosedhiddennone
-
features
指定返回的索引的信息,多个值之间可以使用逗号分隔,可选值为:aliases,mappings和settings,默认值为aliases,mappings,settings。 -
flat_settings
如果设置为true,代表返回的settings信息以水平的格式返回,默认值为false。 -
include_defaults
是否在响应中返回默认的设置,默认为false,这个值比较有用,设置为true可以看到所有的默认值。 -
ignore_unavaliable
默认值为false,一旦查询的索引不存在则报错。 -
local
如果为true,请求只从本地节点获取信息。默认为false,这意味着从主节点检索信息。 -
master_timeout
连接到主节点的超时时间。
1.3、修改索引
索引本身是不能被修改的,当我们说修改索引,实际上是指修改索引的别名、字段映射(mapping)和配置(settings)。
- 修改别名
别名的修改,是通过同时执行remove和add操作来实现的,该操作中的两个动作是原子性的,不会存在别名被删除的瞬间产生没有指向任何索引的问题,以下代码为将my-index从索引my-index-000001解除,然后重新绑定在索引my-index-000002上。
POST /_aliases{"actions" : [{ "remove" : { "index" : "my-index-000001", "alias" : "my-index" } },{ "add" : { "index" : "my-index-000002", "alias" : "my-index" } }]}
- 修改mapping
curl -X PUT "localhost:9200/my-index-000001/_mapping?pretty" -H 'Content-Type: application/json' -d'
{"properties": {"email": {"type": "keyword"}}
}
'
- 修改settings
支持多个索引、data stream和别名,支持模糊搜索,使用*或者_all可以指定所有的data stream和别名。
curl -X PUT "localhost:9200/my-index-000001/_settings?pretty" -H 'Content-Type: application/json' -d'
{"index" : {"number_of_replicas" : 2,"number_of_shards":2}
}
'
1.4、删除索引
删除索引将删除其文档、分片和元数据。它不删除相关的Kibana组件,如数据视图、可视化或仪表板。
如果集群开启了安全权限控制,那么要查询索引信息需要获得delete_index或者manage的索引操作权限。
删除索引将删除其文档、分片和元数据。它不删除相关的Kibana组件,如数据视图、可视化或仪表板。
不能删除数据流(data stream)的写索引,要删除当前写索引,必须滚动data stream,创建新的写索引。
删除索引的API如下:
DELETE /<index>
是必须参数,指定索引名称,多个索引可以用逗号分割,不支持使用别名,默认情况下也不支持使用模糊匹配,确实需要使用模糊匹配的,需要将集群参数action.destructive_requires_name设置为false。
Delete Index API类似Get Index API,同样支持URL查询参数,这些参数包括allow_no_indices、expand_wildcards、ignore_unavailable、master_timeout、timeout,含义类似,不再赘述。
以下是删除索引的案例代码:
curl -X DELETE "localhost:9200/my-index-000001?pretty"
二、索引关闭和打开
2.1、关闭索引
默认情况下,索引一旦被创建出来就是打开的状态,但是在某些情况下可能需要关闭索引,例如一旦老旧不需要使用到的索引。关闭索引将阻塞所有对这个索引的读/写操作,关闭的索引不必维护索引或搜索文档的内部数据结构,从而可以减少集群上开销。
关闭索引的操作做会消耗大量磁盘空间,这可能会在托管环境中导致问题。可以通过集群设置API将cluster.indices.close.enable设置为false来禁用索引的关闭,默认为true。
curl -X POST "localhost:9200/my-index-000001/_close?pretty"
{"acknowledged": true,"shards_acknowledged": true,"indices": {"my-index-000001": {"closed": true}}
}
当一个索引被打开或者关闭,master节点负责重启分片,这些分片都会经历recovery过程,打开或者关闭索引后都会自动进行分片数据的复制,以保证有足够的副本分片以保证高可用性。
默认情况下只支持匹配全名称的特定的索引,但是如果设置了参数action.destructive_requires_name为false,则可以使用*或者_all指代所有的索引,但这种情况下一旦有一个索引匹配失败则会报错。
2.2、打开索引
curl -X POST "localhost:9200/my-index-000001/_open?pretty"
{"acknowledged" : true,"shards_acknowledged" : true
}
open API用于重新打开被关闭的索引,如果目标是一个data stream,则打开这个data stream背后对应的所有的索引。
默认情况下只支持匹配全名称的特定的索引,但是如果设置了参数action.destructive_requires_name为false,则可以使用*或者_all指代所有的索引,但这种情况下一旦有一个索引匹配失败则会报错。
三、索引收缩和拆分
3.1、索引收缩
对于索引分片数量,我们一般在模板中统一定义,在数据规模比较大的集群中,索引分片数一般也大一些,在我的集群中设置为 24。但是,并不是所有的索引数据量都很大,这些小数据量的索引也同样有较大的分片数。在 elasticsearch 中,主节点管理分片是很大的工作量,降低集群整体分片数量可以降低 recovery 时间,减小集群状态的大小。很多时候,冷索引不会再有数据写入,此时,可以使用 shrink API 缩小索引分配数。缩小完成后,源索引可删除。
shrink API 是 ES5.0之后提供的新功能,他并不对源索引进行操作,他使用与源索引相同的配置创建一个新索引,仅仅降低分配数。由于添加新文档时使用对分片数量取余获取目的分片的关系,原分片数量是新分片倍数。如果源索引的分片数为素数,目标索引的分片数只能为1.
将现有索引缩小为具有更少主分片的新索引,一个索引要能够被shrink进行缩小,需要满足以下三个条件:
- 索引是可读的
- 索引中每个分片的副本必须位于同一个节点上。(注意,“所有分片副本”不是指索引的全部分片,无论主分片还是副分片,满足任意一个就可以,分配器也不允许将主副分片分配到同一节点。所以可以是删除了所有的副本分片,也可以是把所有的副本分片全部放在同一个节点上。)
- 索引的状态必须为green
为了使分片分配更容易,可以先删除索引的复制分片,等完成了shrink操作以后再重新添加复制分片。
可以使用以下代码,实现删除所有的副本分片,将所有的主分片分配到同一个节点上,并且设置索引状态为只读:
curl -X PUT "localhost:9200/my_source_index/_settings?pretty" -H 'Content-Type: application/json' -d'
{"settings": {"index.number_of_replicas": 0, "index.routing.allocation.require._name": "shrink_node_name", "index.blocks.write": true }
}
'
重新分配源索引的分片可能需要一段时间,可以使用_cat API跟踪进度,或者使用集群健康API通过wait_for_no_relocating_shards参数等待所有分片完成重新分配。
当完成以上步骤以后就可以进行shrink操作了,以下为_shrink API的格式:
POST /<index>/_shrink/<target-index>PUT /<index>/_shrink/<target-index>
以下案例将索引my-index-000001缩小主分片到shrunk-my-index-000001索引。
curl -X POST "localhost:9200/my-index-000001/_shrink/shrunk-my-index-000001?pretty"
{"settings": {"index.number_of_replicas": 1,"index.number_of_shards": 1,"index.codec": "best_compression""index.routing.allocation.require._name": null, "index.blocks.write": null }"aliases": {"my_search_indices": {}}
}
收缩索引API允许您将现有索引收缩为主分片更少的新索引。目标索引中请求的主分片数量必须是源索引中主分片数量的一个因子。例如,包含8个主碎片的索引可以收缩为4个、2个或1个主碎片,或者包含15个主碎片的索引可以收缩为5个、3个或1个主碎片。如果索引中的碎片数量是一个质数,那么它只能收缩为一个主分片。在收缩之前,索引中每个分片的一个(主或副本)副本必须存在于同一个节点上。
如果当前索引是是一个data stream的写索引,则不允许进行索引收缩,需要对data stream进行回滚,创建一个新的写索引,才可以对当前索引进行收缩。
整个索引收缩的过程如下:
- 创建一个新的目标索引,其定义与源索引相同,但主分片的数量较少。
- 将段从源索引硬链接到目标索引。(如果文件系统不支持硬链接,那么所有的段都被复制到新的索引中,这是一个非常耗时的过程。此外,如果使用多个数据路径,不同数据路径上的分片需要一个完整的段文件拷贝,如果它们不在同一个磁盘上,因为硬链接不能跨磁盘工作)
- 恢复目标索引,就好像它是一个刚刚重新打开的关闭索引。
3.2、索引拆分
Elasticsearch提供了Split API,用于将索引拆分到具有更多主分片的新索引。Split API的格式如下:
POST /<index>/_split/<target-index>PUT /<index>/_split/<target-index>
要完成整个Split的操作需要满足以下条件:
- 索引必须是只读的。
- 集群的状态必须是green。
- 目标索引的主分片数量必须大于源索引的主分片数量。
- 处理索引拆分的节点必须有足够的空闲磁盘空间来容纳现有索引的第二个副本。
以下API请求可以将索引设置为只读:
curl -X PUT "localhost:9200/my_source_index/_settings?pretty" -H 'Content-Type: application/json' -d'
{"settings": {"index.blocks.write": true }
}
'
如果当前索引是是一个data stream的写索引,则不允许进行索引拆分,需要对data stream进行回滚,创建一个新的写索引,才可以对当前索引进行拆分。
以下是使用Split API进行索引拆分的请求案例,Split API支持settings和aliases。
curl -X POST "localhost:9200/my-index-000001/_split/split-my-index-000001?pretty" -H 'Content-Type: application/json' -d'
{"settings": {"index.number_of_shards": 2},"aliases": {"my_alias":{}}
}
'
index.number_of_shards指定的主分片的数量 必须是源分片数量的倍数。
索引拆分可以拆分的分片的数量由参数index.number_of_routing_shards决定,路由分片的数量指定哈希空间,该空间在内部用于以一致性哈希的形式在各个 shard 之间分发文档。 例如,将 number_of_routing_shards 设置为30(5 x 2 x 3)的具有5个分片的索引可以拆分为 以2倍 或 3倍的形式进行拆分。换句话说,可以如下拆分:
5→10→30(拆分依次为2和3)
5→15→30(拆分依次为3和2)
5→30(拆分6)
index.number_of_routing_shards 是一个静态配置,可以在创建索引的时候指定,也可以在关闭的索引上设置。其默认值取决于原始索引中主分片的数量,默认情况下,允许按2的倍数分割最多1024个分片。但是,必须考虑主碎片的原始数量。例如,使用5个主碎片创建的索引可以被分割为10、20、40、80、160、320,或最多640个碎片。
如果源索引只有一个主分片,那么可以被拆分成为任意数量的主分片。
3.2.1、索引拆分的工作过程
- 创建一个与源索引定义一样的目标索引,并且具有更多的主分片。
- 将段从源索引硬链接到目标索引。(如果文件系统不支持硬链接,那么所有的段都会被复制到新的索引中,这是一个非常耗时的过程。)
- 对所有的文档进行重新散列。
- 目标索引进行Recover。
3.2.2、为什么Elasticsearch不支持增量的重新分片?
大多数的键值存储都支持随着数据的增长实现自动分片的自动扩展,为什么Elasticsearch不支持呢?
最经典的方案在于新增一个分片,然后将新的数据存储到这个新增加的分片,但是这种方案在Elasticsearch中可能会造成索引的瓶颈,整体的结构会变得比较复杂,因为Elasticsearch需要去定位文档到底归属于在哪一个分片,这意味着需要使用不同的哈希方案重新平衡现有数据。
键值存储系统解决这个问题的方案一般是使用一致性哈希,当分片数从N增加到N+1时,一致性哈希只需要对1/N的key进行重新分配。但是Elasticsearch分片的本质实际上是Lucene的索引,而从Lucene索引删除一小部分的数据,通常比键值存储系统的成本要高得多。所以Elasticsearch选择在索引层面上进行拆分,使用硬链接进行高效的文件复制,以避免在索引间移动文档。
对于仅追加数据而没有修改、删除等场景,可以通过创建一个新索引并将新数据推送到该索引,同时添加一个用于读操作的涵盖旧索引和新索引的别名来获得更大的灵活性。假设旧索引和新索引分别有M和N个分片,这与搜索一个有M+N个分片的索引相比没有任何开销。
3.2.3、如何监控Split的进度
使用Split API进行索引拆分,API正常返回并不意味着Split的过程已经完成,这仅仅意味着创建目标索引的请求已经完成,并且加入了集群状态,此时主分片可能还未被分配,副本分片可能还未创建成功。
一旦主分片完成了分配,状态就会转化为initializing,并且开始进行拆分过程,直到拆分过程完成,分片的状态将会变成active。
可以使用**_cat recovery API**来监控Split进程,或者可以使用集群健康API通过将**wait_for_status**参数设置为黄色来等待所有主分片分配完毕。
四、索引克隆
Elasticsearch Clone API可以用于Elasticsearch索引数据的复制和备份。
4.1、索引克隆
索引克隆不会克隆源索引的元数据,包括别名、ILM阶段定义、CCR follower相关信息,克隆API将会复制除了index.number_of_replicas和index.auto_expand_replicas之外的所有配置,这两个特殊的配置可以在克隆API的请求中显式指定。Clone API的格式如下:
POST /<index>/_clone/<target-index>PUT /<index>/_clone/<target-index>
索引满足可以克隆的条件是:
- 源索引是只读的
- 整个集群的状态是green的。
- 处理索引拆分的节点必须有足够的空闲磁盘空间来容纳现有索引的第二个副本。
参照之前讲过的内容,仍然可以通过将index.blocks.write设置为true来确保索引是可读的状态。以下是克隆API的案例:
curl -X POST "localhost:9200/my_source_index/_clone/my_target_index?pretty" -H 'Content-Type: application/json' -d'
{"settings": {"index.number_of_shards": 5 },"aliases": {"my_search_indices": {}}
}
'
注意:index.number_of_shards的值必须与源索引的主分片数量一致。
4.2、索引克隆的过程
- 创建一个具备和源索引定义一样的目标索引。
- 然后将源索引中的段(segment)硬链接到目标索引中。
- 目标索引进行Recover。
4.3、索引克隆的监控
使用Clone API进行索引的克隆,API正常返回并不意味着Clone的过程已经完成,这仅仅意味着创建目标索引的请求已经完成,并且加入了集群状态,此时主分片可能还未被分配,副本分片可能还未创建成功。
一旦主分片完成了分配,状态就会转化为initializing,并且开始进行克隆过程,直到克隆过程完成,分片的状态将会变成active。
可以使用**_cat recovery API**来监控Clone进程,或者可以使用集群健康API通过将**wait_for_status**参数设置为黄色来等待所有主分片分配完毕。
五、索引滚动
rollover API是Elasticsearch提供的一个很好用的功能。我们都知道在MySQL中一旦数据量比较大,可能会存在分库分表的情况,例如根据时间每个月一个表。rollover功能就类似这种情况,它的原理是先创建一个带别名的索引,然后设定一定的规则(例如满足一定的时间范围的条件),当满足该设定规则的时候,Elasticsearch会自动建立新的索引,别名也自动切换指向新的索引,这样相当于在物理层面自动建立了索引的分区功能,当查询数据落在特定时间内时,会到一个相对小的索引中查询,相对所有数据都存储在一个大索引的情况,可以有效提升查询效率。
rollover API会为data stream或者索引别名创建一个新的索引。(在Elasticsearch 7.9之前,一般使用索引别名的方式来管理时间序列数据,在Elasticsearch之后data stream取代了这个功能,它需要更少的维护,并自动与数据层集成)。
rollover API的效果依据待滚动的索引别名的情况不同而有不同的表现:
- 如果一个索引别名对应了多个索引,其中一个一定是写索引,rollover创建出新索引的时候会设置
is_write_index为true,并且上一个被滚动的索引的is_write_index设置为false。 - 如果待滚动的索引别名对应的只有一个索引,那么在创建新的索引的同时,会删除原索引。
使用rollover API的时候如果指定新的索引的名称,并且原索引以“-”结束并且以数字结尾,那么新索引将会沿用名称并且将数字增加,例如原索引是my-index-000001那么新索引会是my-index-000002。
如果对时间序列数据使用索引别名,则可以在索引名称中使用日期来跟踪滚动日期。例如,可以创建一个别名来指向名为<my-index-{now/d}-000001>的索引,如果在2099年5月6日创建索引,则索引的名称为my-index-2099.05.06-000001。如果在2099年5月7日滚动别名,则新索引的名称为my-index-2099.05.07-000002。
rollover API的格式如下:
POST /<rollover-target>/_rollover/POST /<rollover-target>/_rollover/<target-index>
rollover API也支持Query Parameters和Request Body,其中Query parameters支持wait_for_active_shards、master_timeout、timeout和dry_run,特别说一下dry_run,如果将dry_run设置为true,那么这次请求不会真的执行,但是会检查当前索引是否满足conditions指定的条件,这对于提前进行测试非常有用。
Request Body支持aliases、mappings和settings(这三个参数只支持索引,不支持data stream)和conditions。
特别展开讲一下conditions。这是一个可选参数,如果指定了conditions,则需要在满足conditions指定的一个或者多个条件的情况下才会执行滚动,如果没有指定则无条件滚动,如果需要自动滚动,可以使用ILM Rollover。
conditions支持的属性有:
max_age
从索引建立开始算起的时间周期,支持Time Units,如7d、4h、30m、60s、1000ms、10000micros、500000nanos。max_docs
索引主分片的数量达到设定的值;max_size
所有主分片的大小之和达到了设定值,可以通过_cat indices API进行查询,其中pri.store.size的值就是目标值。max_primary_shard_size
所有主分片中存在主分片的大小达到了设定值,可以通过_cat shards API查看分片的大小,store值代表每个分片的大小,prirep代表了分片是primary分片还是replica分片。max_primary_shard_docs
所有主分片中存在主分片的文档大小达到了设定值,可以通过_cat shards API查询,其中的docs字段代表了分片上文档数量的大小。
以下为rollover一个data stream的一个案例:
curl -X POST "localhost:9200/my-data-stream/_rollover?pretty" -H 'Content-Type: application/json' -d'
{"conditions": {"max_age": "7d","max_docs": 1000,"max_primary_shard_size": "50gb","max_primary_shard_docs": "2000"}
}
'
响应信息如下:
{"acknowledged": true,"shards_acknowledged": true,"old_index": ".ds-my-data-stream-2099.05.06-000001","new_index": ".ds-my-data-stream-2099.05.07-000002","rolled_over": true,"dry_run": false,"conditions": {"[max_age: 7d]": false,"[max_docs: 1000]": true,"[max_primary_shard_size: 50gb]": false,"[max_primary_shard_docs: 2000]": false}
}
以下为rollover一个索引别名的一个案例:
- 创建一个索引并且设置为write index
# PUT <my-index-{now/d}-000001>
curl -X PUT "localhost:9200/%3Cmy-index-%7Bnow%2Fd%7D-000001%3E?pretty" -H 'Content-Type: application/json' -d'
{"aliases": {"my-alias": {"is_write_index": true}}
}
'
- 请求rollover API
curl -X POST "localhost:9200/my-alias/_rollover?pretty" -H 'Content-Type: application/json' -d'
{"conditions": {"max_age": "7d","max_docs": 1000,"max_primary_shard_size": "50gb","max_primary_shard_docs": "2000"}
}
'
如果别名的索引名称使用日期数学表达式,并且按定期间隔滚动索引,则可以使用日期数学表达式来缩小搜索范围。例如,下面的搜索目标是最近三天内创建的索引。
# GET /<my-index-{now/d}-*>,<my-index-{now/d-1d}-*>,<my-index-{now/d-2d}-*>/_search
curl -X GET "localhost:9200/%3Cmy-index-%7Bnow%2Fd%7D-*%3E%2C%3Cmy-index-%7Bnow%2Fd-1d%7D-*%3E%2C%3Cmy-index-%7Bnow%2Fd-2d%7D-*%3E/_search?pretty"
六、索引冻结和解冻
索引的冻结是Elasticsearch提供的一个用于减少内存开销的操作,这个功能在7.14版本中被标记为Deprecated,在Version 8以后,已经对堆内存的使用进行了改进,冻结和解冻的功能不再适用。
这里简单的进行操作演示,如果是7.x版本仍然可以作为参照。
6.1、索引冻结
索引冻结API在Elasticsearch7.14版本被定义为Deprecated,在这个版本以后不建议使用。
索引冻结以后除了保存一些必要的元数据信息意外,将不再占用系统负载,索引将会变成只读,类似force merge等操作将无法执行。
API格式如下:
POST /my-index-000001/_freeze
6.2、索引解冻
API格式如下:
POST /<index>/_unfreeze
以下为索引解冻操作的代码案例:
curl -X POST "localhost:9200/my-index-000001/_unfreeze?pretty"
七、索引解析
Elasticsearch提供了Resolve index API用于辅助进行索引的解析,根据提供的索引/别名/数据流的名称或者模式匹配,查询出当前集群中匹配的索引的信息。以下为API的格式:
GET /_resolve/index/<name>
案例如下:
curl -X GET "localhost:9200/_resolve/index/f*,remoteCluster1:bar*?expand_wildcards=all&pretty"{"indices": [ {"name": "foo_closed","attributes": ["closed" ]},{"name": "freeze-index","aliases": ["f-alias"],"attributes": ["open"]},{"name": "remoteCluster1:bar-01","attributes": ["open"]}],"aliases": [ {"name": "f-alias","indices": ["freeze-index","my-index-000001"]}],"data_streams": [ {"name": "foo","backing_indices": [".ds-foo-2099.03.07-000001"],"timestamp_field": "@timestamp"}]
}
这个API的作用多为辅助,实际使用不多,细节的参数可以参考官方的文档。
相关文章:

Elasticsearch索引全生命周期管理一网打尽
文章目录一、索引增删改查1.1、创建索引1.2、查询索引1.3、修改索引1.4、删除索引二、索引关闭和打开2.1、关闭索引2.2、打开索引三、索引收缩和拆分3.1、索引收缩3.2、索引拆分3.2.1、索引拆分的工作过程3.2.2、为什么Elasticsearch不支持增量的重新分片?3.2.3、如…...

MySQL的SELECT
简单SELECT语句我们从最简单的SELECT语句开始起简单的SELECT语句: SELECT {*, column [alias], . } FROM table; 说明: –SELECT列名列表。*表示所有列。 –FROM 提供数据源(表名/视图名) –默认选择所有行例子 查询数据:select * from stude…...

conda 搭建tensorflow-GPU和pycharm以及VS2022 软件环境配置
conda 搭建tensorflow-GPU和pycharm以及VS2022 软件环境配置一、TensorFlow 环境配置安装1. Anaconda下载安装2.conda创建tensorflow环境二、pycharm以及VS2022 环境配置2.1 pycharm 软件安装以及环境配置2.2.1 pycharm 软件安装2.2.2 pycharm 软件conda环境配置2.2 Visual Stu…...
HACKTHEBOX——Teacher
nmapnmap -sV -sC -p- -T4 -oA nmap 10.10.10.153nmap只发现了对外开放了80端口,从http-title看出可能是某个中学的官网http打开网站确实是一个官网,查看每个接口看看有没有可以利用的地方发现了一个接口,/images/5.png,但是响应包…...
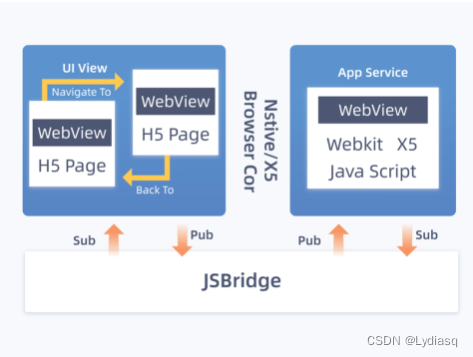
干货| Vue小程序开发技术原理
目前应用最广的三大前端框架分别是Vue、 React 和 Angular 。其中,不管是 BAT 大厂,还是创业公司,Vue 都有广泛的应用。如今,再随着移动开发小程序的蓬勃发展,Vue也广泛应用到了小程序开发当中。今天,就来详…...

unity-web端h5记录
title: unity-web端h5记录 categories: Unity3d tags: [unity, web, h5] date: 2023-02-23 17:00:53 comments: false mathjax: true toc: true unity-web端h5记录 前篇 5款常用的html5游戏引擎以及优缺点分析 - https://imgtec.eetrend.com/blog/2022/100557792.htmlUnity We…...
基于部标JT808的车载视频监控需求与EasyCVR视频融合平台解决方案设计
一、方案背景 众所周知,在TSINGSEE青犀视频解决方案中,EasyCVR视频智能融合共享平台主要作为视频汇聚平台使用,不仅能兼容安防标准协议RTSP/Onvif、国标GB28181,互联网直播协议RTMP,私有协议海康SDK、大华SDK…...
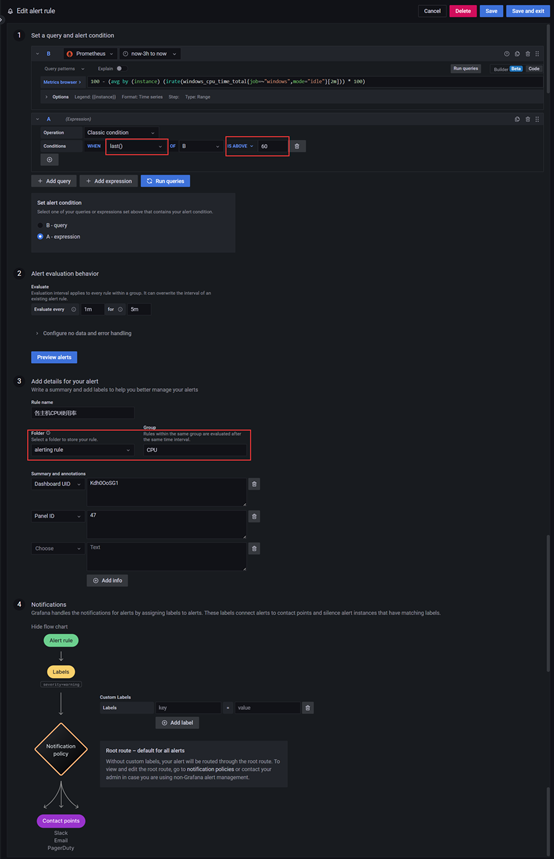
Grafana邮件及告警配置
之前部署过服务器的监控组件程序,本在部署时也进行邮件及告警配置,但未进行文档整理,在这儿进行展示。之前用过Grafana的7.*的版本,在进行邮件配置还比较OK,但在配置告警时,太繁琐,还要自己去写…...

Springboot Java多线程操作本地文件,加读写锁,阻塞的线程等待运行中的线程执行完再查询并写入
Springboot Java多线程操作本地文件,加读写锁,阻塞的线程等待运行中的线程执行完再查询并写入1、读写锁2、文件锁3、Synchronized和Lock的区别1、读写锁 在 Spring Boot 中进行多线程操作本地文件并加读写锁可以使用 Java 的 java.nio.file 包中提供的文…...

WebRTC拥塞控制算法——GCC介绍
网络拥塞是基于IP协议的数据报交换网络中常见的一种网络传输问题,它对网络传输的质量有严重的影响, 网络拥塞是导致网络吞吐降低, 网络丢包等的主要原因之一, 这些问题使得上层应用无法有效的利用网络带宽获得高质量的网络传输效果…...

大数据技术之Maxwell基础知识
大数据技术之Maxwell基础知识 文章目录大数据技术之Maxwell基础知识0、写在前面1、Maxwell 概述1.1 Maxwell 定义1.2 Maxwell 工作原理1.2.1 MySQL 主从复制过程1.2.2 Maxwell 的工作原理1.2.3 MySQL 的 binlog1.3 Maxwell与Cannal对比2. Maxwell 使用2.1 Maxwell 安装部署2.1.…...
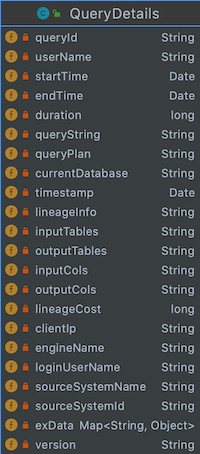
元数据管理实践数据血缘
元数据管理实践&数据血缘 什么是元数据?元数据MetaData狭义的解释是用来描述数据的数据,广义的来看,除了业务逻辑直接读写处理的那些业务数据,所有其它用来维持整个系统运转所需的信息/数据都可以叫作元数据。比如…...

SQL的优化【面试工作】
SQL的优化 最近看到群友在讨论这块的优化,感觉不管工作和面试,都是用上的,记录下吧!(不然又记不住) 优化点: 处理和优化复杂的 SQL 查询可以有以下几个方向: 1.优化查询语句本身 首先,可以优化 SQL 查询语句本身,尽量让其更加简洁、高效。 …...

Kotlin 40. Dependency Injection 依赖注入以及Hilt在Kotlin中的使用,系列3:Hilt 注释介绍及使用案例
一起来学Kotlin:概念:27. Dependency Injection 依赖注入以及Hilt在Kotlin中的使用,系列3:Hilt 注释介绍及使用案例 此系列博客中,我们将主要介绍: Dependency Injection(依赖注入)…...

1000亿数据、30W级qps如何架构?来一个天花板案例
1000亿级存储、30W级qps系统如何架构?来一个天花板案例 说在前面 在尼恩的(50)读者社群中,经常遇到一个 非常、非常高频的一个架构面试题,类似如下: 千万级数据,如何做系统架构?亿…...
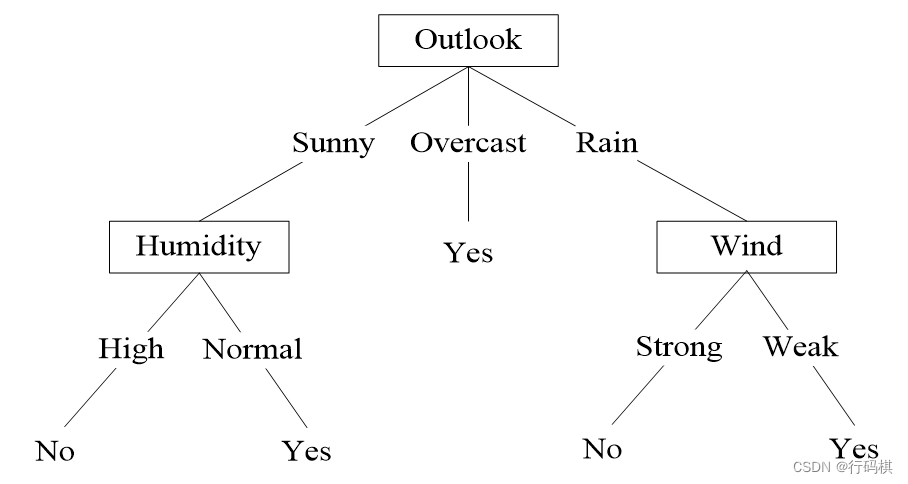
人工智能及其应用(蔡自兴)期末复习
人工智能及其应用(蔡自兴)期末复习 相关资料: 人工智能期末复习 人工智能复习题 人工智能模拟卷 人工智能期末练习题 1 ⭐️绪论 人工智能:人工智能就是用人工的方法在机器(计算机)上实现的智能࿰…...
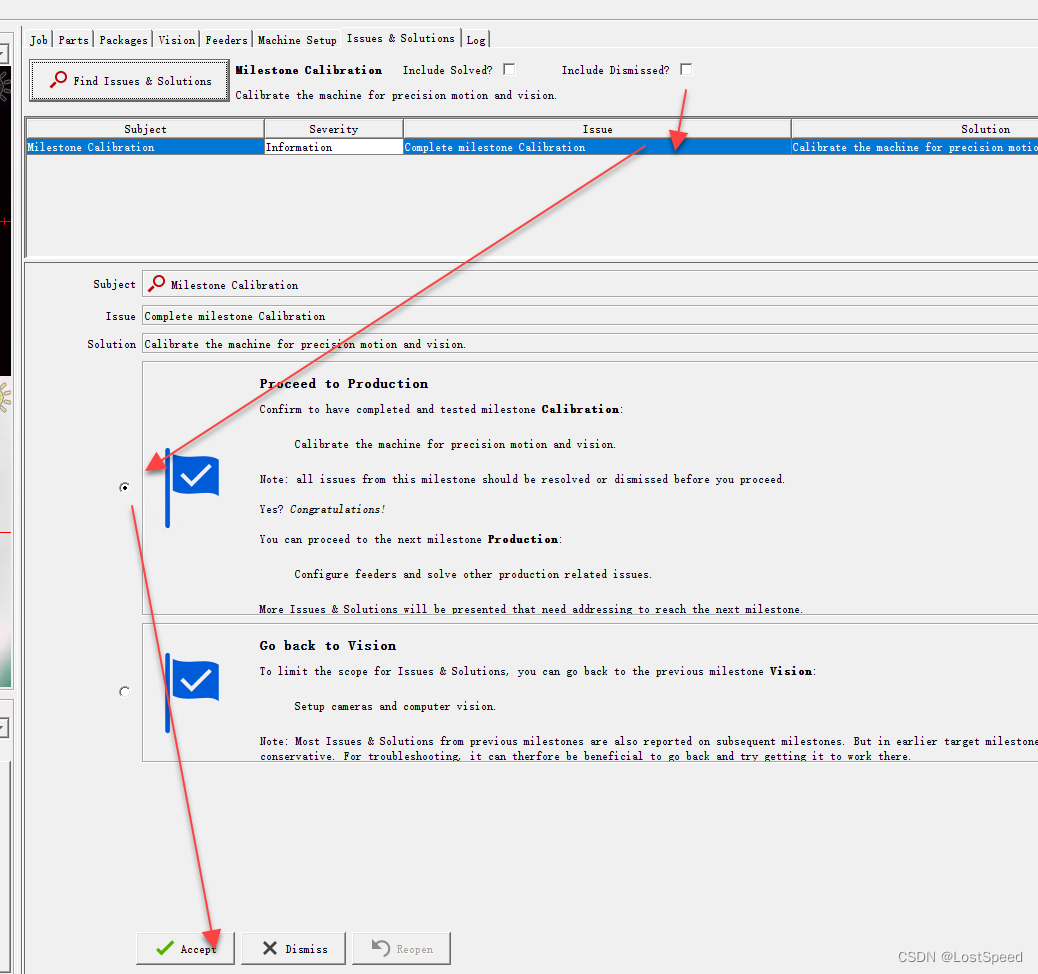
openpnp - configure - 矫正里程碑
文章目录openpnp - configure - 矫正里程碑概述备注ENDopenpnp - configure - 矫正里程碑 概述 进入矫正里程碑了 查找问题 现在第一个问题是X轴的齿隙矫正 根据提示, 将顶部相机移动到主基准点上, 选择容差(就选用默认的0.025), 开始矫正. 正好开机后, 使能了视觉原点归零. …...
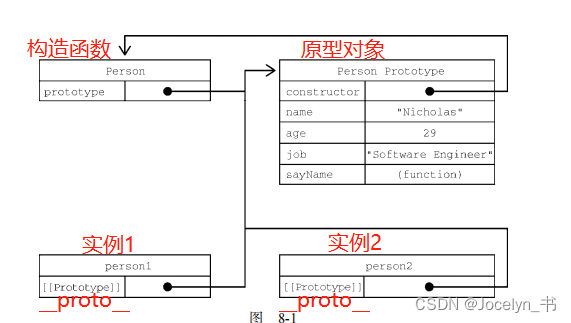
JavaScript高级程序设计读书分享之8章——8.2创建对象
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 创建Object的实例 let person new Object(); person.name "Nicholas"; person.age 29; person.job "Software Engineer"; person.sayName function() { console.log(this…...

关于Could not build wheels for opencv-python-headless, which is...报错的解决方案
在通过最新版pip在线安装package:opencv-python-headless的时候,会产生报错信息,主要为 ERROR: Failed building wheel for opencv-python-headless ERROR: Could not build wheels for opencv-python-headless, which is required to insta…...
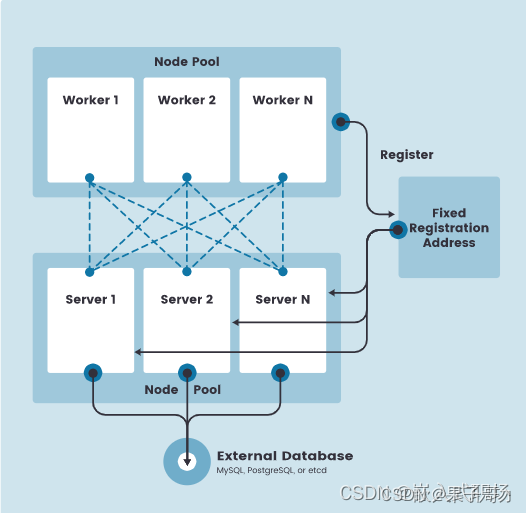
【K3s】第1篇 K3s入门级介绍及架构详解
1、什么是 K3s? K3s 是一个轻量级的 Kubernetes 发行版,它针对边缘计算、物联网等场景进行了高度优化。K3s 有以下增强功能: 打包为单个二进制文件。使用基于 sqlite3 的轻量级存储后端作为默认存储机制。同时支持使用 etcd3、MySQL 和 PostgreSQL 作…...

MOOTDX终极指南:Python通达信数据接口让量化分析变得简单高效
MOOTDX终极指南:Python通达信数据接口让量化分析变得简单高效 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 你是否曾为获取股票数据而烦恼?面对复杂的API接口和繁琐的数据…...

CosyVoice-300M Lite实战案例:在线教育语音课件生成系统
CosyVoice-300M Lite实战案例:在线教育语音课件生成系统 1. 为什么在线教育需要专属语音合成系统? 你有没有遇到过这样的场景:一位初中物理老师想为“浮力原理”这节课制作配套音频讲解,但反复试了三款主流TTS工具——要么普通话…...

别再让WIFI信号‘水土不服’!Android 13高通平台国家码配置保姆级教程
Android 13高通平台WIFI国家码配置实战指南 当你的设备跨越国界,WIFI信号却开始"水土不服"——连接不稳定、速度骤降甚至完全无法使用。这背后往往不是硬件问题,而是国家码配置这个隐形门槛在作祟。作为深耕Android系统开发多年的技术专家&am…...
)
银河麒麟V10 SP1下使用rsync实现多客户端定时数据备份(避坑指南)
银河麒麟V10 SP1多客户端数据同步全链路配置与优化实战 在IT运维工作中,数据备份如同氧气般不可或缺。想象一下,当数十台客户端设备同时运行时,如何确保关键业务数据能够安全、高效地集中备份?银河麒麟V10 SP1作为国产操作系统的…...

如何快速上手Notepad--:3步完成跨平台文本编辑器的配置与使用
如何快速上手Notepad--:3步完成跨平台文本编辑器的配置与使用 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...

手把手教你优化SiC MOSFET模块:从铜带键合到双面散热的5个关键技术
SiC MOSFET功率模块封装优化实战:五大关键技术深度解析 在电力电子领域,碳化硅(SiC)MOSFET功率模块正逐步取代传统硅基IGBT,成为高效率、高功率密度应用的首选。然而,要充分发挥SiC材料的性能优势,封装技术面临前所未…...

如何掌握Node-lru-cache的fetchMethod:异步数据获取的终极指南
如何掌握Node-lru-cache的fetchMethod:异步数据获取的终极指南 【免费下载链接】node-lru-cache A fast cache that automatically deletes the least recently used items 项目地址: https://gitcode.com/gh_mirrors/no/node-lru-cache Node-lru-cache是一个…...

DAMOYOLO-S基础教程:理解count字段与实际业务中目标计数逻辑映射
DAMOYOLO-S基础教程:理解count字段与实际业务中目标计数逻辑映射 1. 从一次“数数”的困惑说起 前两天,一个做零售分析的朋友找我帮忙。他兴奋地告诉我,他们用上了最新的AI目标检测模型,想自动统计货架上的商品数量。他上传了一…...

Simula:革命性Linux VR桌面窗口管理器完全指南
Simula:革命性Linux VR桌面窗口管理器完全指南 【免费下载链接】Simula Linux VR Desktop 项目地址: https://gitcode.com/gh_mirrors/si/Simula Simula是一款专为Linux系统打造的革命性VR桌面窗口管理器,它将传统的桌面操作体验带入虚拟现实空间…...

Qwen3-TTS语音合成教程:长文本自动分段与上下文语义连贯性保障
Qwen3-TTS语音合成教程:长文本自动分段与上下文语义连贯性保障 语音合成新体验:Qwen3-TTS让长文本语音合成变得简单自然,支持10种语言,3秒声音克隆,端到端延迟仅97ms 1. 快速了解Qwen3-TTS Qwen3-TTS-12Hz-1.7B-Base是…...