【机器学习】聚类算法(理论)
聚类算法(理论)
目录
- 一、概论
- 1、聚类算法的分类
- 2、欧氏空间的引入
- 二、K-Means算法
- 1、算法思路
- 2、算法总结
- 三、DBSCAN算法
- 1、相关概念
- 2、算法思路
- 3、算法总结
- 四、实战部分
一、概论
聚类分析,即聚类(Clustering),是指在一大推数据中采用某种方式或准则来将一些具有相同或相似性质和特征的数据划分为一类。聚类是无监督学习的典型算法,相较于有监督学习,由于聚类针对的大多是无标签数据,因此对于最终构建的模型而言,在进行模型评估时会比较麻烦。同时,在对算法进行调参时也会因为这种不确定性而稍带困难。

1、聚类算法的分类
聚类算法的分类有:
-
划分法
划分法(Partitioning Methods),给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K小于N。而且这K个分组满足下列条件:
(1)每一个分组至少包含一个数据纪录;
(2)每一个数据纪录属于且仅属于一个分组(注意:这个要求在某些模糊聚类算法中可以放宽); -
层次法
层次法(Hierarchical Methods),这种方法对给定的数据集进行层次似的分解,直到某种条件满足为止。具体又可分为“自底向上”和“自顶向下”两种方案。例如,在“自底向上”方案中,初始时每一个数据纪录都组成一个单独的组,在接下来的迭代中,它把那些相互邻近的组合并成一个组,直到所有的记录组成一个分组或者某个条件满足为止。 -
密度算法
基于密度的方法(Density-Based Methods),基于密度的方法与其它方法的一个根本区别是:它不是基于各种各样的距离的,而是基于密度的。这样就能克服基于距离的算法只能发现“类圆形”的聚类的缺点。 -
图论聚类法
图论聚类方法解决的第一步是建立与问题相适应的图,图的节点对应于被分析数据的最小单元,图的边(或弧)对应于最小处理单元数据之间的相似性度量。因此,每一个最小处理单元数据之间都会有一个度量表达,这就确保了数据的局部特性比较易于处理。图论聚类法是以样本数据的局域连接特征作为聚类的主要信息源,因而其主要优点是易于处理局部数据的特性。 -
网格算法
基于网格的方法(Grid-Based Methods),这种方法首先将数据空间划分成为有限个单元(cell)的网格结构,所有的处理都是以单个的单元为对象的。这么处理的一个突出的优点就是处理速度很快,通常这是与目标数据库中记录的个数无关的,它只与把数据空间分为多少个单元有关。
代表算法有:STING算法、CLIQUE算法、WAVE-CLUSTER算法; -
模型算法
基于模型的方法(Model-Based Methods),基于模型的方法给每一个聚类假定一个模型,然后去寻找能够很好的满足这个模型的数据集。这样一个模型可能是数据点在空间中的密度分布函数或者其它。它的一个潜在的假定就是:目标数据集是由一系列的概率分布所决定的。
通常有两种尝试方向:基于统计、基于神经网络。
2、欧氏空间的引入
世间万物,皆为混沌。为此,人类世界经历了原始社会、奴隶社会、封建社会、资本主义社会到共产主义社会,这是人类社会从低级到高级的发展过程。但从哲学的角度看来,这实际上是一种从无序到有序的过程。人类社会如此,数学亦是如此。
数字的无穷尽给它的使用带来了极大不便,为此,在一维空间建立了“数轴”,以将这些数字按序列在一条直线上,既便于比较也便于查找与定位,如:𝑥。一维空间最经典的用例,莫过于尺子:用以测量长度。但是地图的出现让人们陷入苦恼,要如何精准地定位一个人的位置呢?“坐标轴”似乎是一个可行的方案:通过在二维平面中,额外增加一条与一维空间中的数轴所垂直的纵向数轴,便能建立一个能海纳百川的空间,此时可用 (𝑥, 𝑦) 定位任意位置。二维空间最典型的用例,莫过于用于进行全球定位的经纬度。在建筑、设计类软件中,处理目标更多的是立体图形,此时,二维空间便显得余力不足。很自然地想到,可采取从一维到二维的相同提升方式,即添加一条与二维平面相垂直的数轴,这样一来就能构建一个涵盖三维空间全部位置的坐标轴,以达到从二维空间到三维空间的提升,此时可用 (𝑥, 𝑦, 𝑧) 定位任意位置。

现在让我们回忆下不同空间中与距离相关的一些定义:
- 在一维空间,两个点 𝑥𝑎, 𝑥𝑏 之间的距离可以用 distance(a,b)=(xa−xb)2=∣xa−xb∣distance(a,b)=\sqrt{(x_a-x_b)^2}=|x_a-x_b|distance(a,b)=(xa−xb)2=∣xa−xb∣ 来表示;
- 在二维空间,两个点 𝐴(𝑥𝑎, 𝑦𝑎) , 𝐵(𝑥𝑏, 𝑦𝑏) 之间的距离可以用 distance(a,b)=(xa−xb)2+(ya−yb)2distance(a,b)=\sqrt{(x_a-x_b)^2+(y_a-y_b)^2}distance(a,b)=(xa−xb)2+(ya−yb)2 来表示;
- 在三维空间,两个点 𝐴(𝑥𝑎, 𝑦𝑎, 𝑧𝑎) , 𝐵(𝑥𝑏, 𝑦𝑏, 𝑧𝑏) 之间的距离可以用 distance(a,b)=(xa−xb)2+(ya−yb)2+(za−zb)2distance(a,b)=\sqrt{(x_a-x_b)^2+(y_a-y_b)^2+(z_a-z_b)^2}distance(a,b)=(xa−xb)2+(ya−yb)2+(za−zb)2来表示;
有关(内)积的定义:
- 在一维空间,两数 𝑥𝑎, 𝑥𝑏 之积为 Mul(𝑎, 𝑏) = 𝑥𝑎𝑥𝑏 ;
- 在二维空间,两个点 𝐴(𝑥𝑎, 𝑦𝑎) , 𝐵(𝑥𝑏, 𝑦𝑏) 之间的(内)积可以用 Mul(𝐴, 𝐵) = 𝑥𝑎𝑥𝑏 + 𝑦𝑎𝑦𝑏来表示;
- 在三维空间,两个点 𝐴(𝑥𝑎, 𝑦𝑎, 𝑧𝑎) , 𝐵(𝑥𝑏, 𝑦𝑏, 𝑧𝑏) 之间的(内)积可以用 Mul(𝐴, 𝐵) = 𝑥𝑎𝑥𝑏 + 𝑦𝑎𝑦𝑏 + 𝑧𝑎𝑧𝑏 来表示。

在二维及以上空间,基于两点 𝑋(𝑥1, 𝑥2, … , 𝑥𝑛) , 𝑌(𝑦1, 𝑦2, … , 𝑦𝑛) 可定义一个具有方向的指标,称其为向量,则可得到:
ξ⃗={a1,a2,…,an}={x1,x2,…,xn}−{y1,y2,…,yn}={x1−y1,x2−y2,…,xn−yn}\vec{\xi} = \{ a_1, a_2, … ,a_n \} = \{ x_1, x_2, …, x_n \} - \{ y_1, y_2, …, y_n \} = \{ x_1 - y_1, x_2 - y_2, …, x_n - y_n \} ξ={a1,a2,…,an}={x1,x2,…,xn}−{y1,y2,…,yn}={x1−y1,x2−y2,…,xn−yn}
对于高维空间,定义两向量的内积为: ξ⃗⋅η⃗=∑i=1naibi=a1b1+a2b2+…+anbn\vec{\xi}·\vec{\eta}=\sum_{i=1}^na_ib_i=a_1b_1+a_2b_2+…+a_nb_nξ⋅η=∑i=1naibi=a1b1+a2b2+…+anbn 这个内积和两点之间的内积算法是一致的。
有时候,我们需要通过两个向量之间的夹角来判断与其相关的一些性质,为此定义了方向余弦,其定义为:
cosθ=ξ⃗⋅η⃗∣ξ⃗∣⋅∣η⃗∣cos \theta=\frac{\vec{\xi}·\vec{\eta}}{|\vec{\xi}|·|\vec{\eta}|} cosθ=∣ξ∣⋅∣η∣ξ⋅η
以上就是在低维空间(一维、二维、三维)构建的一系列“秩序”,以帮助我们理解与使用,而高维空间却因它的抽象性显得较有难度。但是,依然可采取与前面的相同的思路来进行拓展。此时,若将在低纬空间总结的有关距离、(内)积、角相关的定理推广至有限的更高维空间,那这些符合定义的空间则被统称为欧几里得空间(亦即欧式空间,Euclidean Space)。
二、K-Means算法
1、算法思路
K-Means 算法是一种典型的基于划分的聚类算法,它的核心思想是:若将指定数据集的特征投影至 n 维欧氏空间,则数据之间的相似性应当与这些数据的欧氏距离成反比。说简单点就是:越相似的数据,彼此之间离得越近。
其算法流程如下:首先从数据集中随机选取 𝑘 个初始聚类中心 𝐶𝑗 (1 ≤ 𝑗 ≤ 𝑘) ,接下来对每个其余数据对象,均计算出该数据对象与 𝑘 个聚类中心的的欧式距离,并将离目标数据对象最近的聚类中心 𝐶𝑥 作为该数据对象所属的类别。经过这样一次迭代,就完成了一次 K-Means 聚类。接着计算每个簇中数据对象的平均值作为新的聚类中心,进行下一次迭代,直到聚类中心不再变化或达到最大的迭代次数时停止。

上图给出了 K-Means 算法的执行流程(通过观察,显然可将该数据集划分为 2 类,因此取 k = 2):
(a) 算法开始,将指定数据集的特征投影至 n 维欧氏空间;
(b) 随机选取 k = 2 个初始聚类中心;
(c) 对任意数据 x(𝑖) ,算出其与 k 个聚类中心的欧式距离,取其中距离最近的那个类簇作为数据 x(𝑖) 的所属类别(第一次 k-means);
(d) 基于新的类簇分布,算出每个簇中数据对象的平均值作为新的聚类中心;
(e) 对任意数据 x(𝑖) ,算出其与 k 个聚类中心的欧式距离,取其中距离最近的那个类簇作为数据 x(𝑖) 的所属类别(第二次 k-means);
(f) 基于新的类簇分布,算出每个簇中数据对象的平均值作为新的聚类中心;
(f) 之后,算法将执行第三次 k-means,接着当再次计算新的类簇中心时,会发现类簇中心不再发生变化(或变化
范围很小),此时算法停止并返回最终的分类结果。
总的来看,K-Means 算法需要预先指定初始类簇个数和聚类中心,然后再按照样本与类簇中心的距离进行归类与迭代更新。在迭代过程中, K-Means 算法会不断降低各类簇的误差平方和SSE(Sum of Squared Error,SSE),当SSE不再变化或目标函数收敛时,聚类结束,得到最终结果。下面给出 K-Means 算法计算某个数据对象 𝑥(𝑖) 与某类簇中心 𝐶𝑗 的欧氏距离公式:
distance(x(i),Cj)=∑t−1m(xt(i)−Cjt)2distance \left( x^{(i)},C_j \right)=\sqrt{\sum_{t-1}^m{\left( x_t^{(i)}-C_{jt} \right)^2}} distance(x(i),Cj)=t−1∑m(xt(i)−Cjt)2
其中,xt(i)x_t^{(i)}xt(i) 为第 𝑖 个数据对象在第 𝑡 个特征上的取值,𝐶𝑗𝑡 为第 𝑗 个数据对象在第 𝑡 个特征上的取值。
整个数据集的误差平方和 SSE 计算公式为(SSE的大小衡量了聚类结果的好坏):
SSE=∑j=1k∑x(i)∈Cj(distance(x(i),Cj))2SSE=\sum_{j=1}^k\sum_{x^{(i)}∈C_j} \left( distance( x^{(i)},C_j) \right)^2 SSE=j=1∑kx(i)∈Cj∑(distance(x(i),Cj))2
2、算法总结
自此,可总结出 K-Means 算法的步骤:
① 随机选择 k 个样本作为初始簇类的均值向量
② 将每个样本数据划分给离它距离最近的簇;
③ 根据每个样本所属的簇,更新簇类的均值向量;
④ 重复 ②③ 步,当达到设置的迭代次数或类簇的均值向量不再改变时,模型构建完成,输出聚类算法结果。
K-Means 算法非常简单且使用广泛,但是主要存在以下四个缺陷:
- K 值需要人为给定,属于预先知识,大多情况下 K 值的估计非常困难。对于“可以确定 K 值不会太大但不明确具体取值”的场景,可以进行多次迭代运算,然后找出 SSE 值最小的的 K 值作为最终的类簇个数;
- K-Means 算法对初始选取的聚类中心点是敏感的,不同的随机种子点得到的聚类结果完全不同;
- 该算法并不适合所有的数据类型。它不能处理非球形簇、不同尺寸和不同密度的簇;
- 易陷入局部最优解。

从上图不难看出,K-Means算法对于环形簇的分类效果非常糟糕!
三、DBSCAN算法
1、相关概念
DBSCAN(Density-Based Spatial Clustering of Applications with Noise),翻译是“基于密度的带噪声聚类算法”,DBSCAN 将簇定义为“密度相连的点的最大集合”,它把具有足够高密度的区域划分为簇,能在带噪声的数据中发现任意形状的类簇。为理解 DBSCAN 的算法原理,下面先介绍一些相关概念(假设样本集为 𝐷 = {𝑥(1), 𝑥(2), … , 𝑥(𝑛)}):
- 𝝐 − 领域:对于某个样本点 𝑥(𝑗) ∈ 𝐷,其 𝜖 − 领域包含样本集 D 中与 𝑥(𝑗) 的距离不大于 𝜖 的子样本集。即:𝑁𝜖 (𝑥(𝑗))= { 𝑥(𝑖) ∈ 𝐷 | 𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒(𝑥(𝑖), 𝑥(𝑗)) ≤ 𝜖} ,用 | 𝑁𝜖(𝑥(𝑗)) |表示该子样本集中的样本点个数。注:上述距离的计算通常采用欧式距离、曼哈顿距离等。
- 核心对象:对于任意样本 𝑥(𝑗) ∈ 𝐷,如果它的 𝜖 − 领域中包含的样本点个数至少包含 𝑀𝑖𝑛𝑃𝑜𝑖𝑛𝑡𝑠 个样本,即: | 𝑁𝜖(𝑥(𝑗)) | ≥ 𝑀𝑖𝑛𝑃𝑜𝑖𝑛𝑡𝑠,则称 𝑥(𝑗) 为一个核心对象。
- 密度直达:如果 𝑥(𝑖) 位于 𝑥(𝑗) 的 𝜖 − 邻域中,且 𝑥(𝑗) 是核心对象,则称 𝑥(𝑖) 由 𝑥(𝑗) 密度直达。反之不一定成立,即此时不能说 𝑥(𝑗) 由 𝑥(𝑖) 密度直达, 除非 𝑥(𝑖) 也是核心对象,即密度直达不具有对称性。
- 密度可达:对于 𝑥(𝑖) 和 𝑥(𝑗) ,如果存在样本序列 𝑝(1), 𝑝(2), … , 𝑝(𝑡),使得任意 𝑝(𝑘) 均可由 𝑝(𝑘−1) 密度直达(其中 2 ≤ 𝑘 ≤ 𝑡)且 𝑥(𝑗)= 𝑝(1), 𝑥(𝑖)= 𝑝(𝑡),则称 𝑥(𝑖) 由 𝑥(𝑗) 密度可达。也就是说密度可达具有传递性。此时序列中的传递样本 𝑝(1), 𝑝(2), … , 𝑝(𝑡-1) 均为核心对象,因为只有核心对象才能使其他样本密度直达。同时,由密度直达不具有对称性可知,密度可达也不具有对称性。
- 密度相连:对于 𝑥(𝑖) 和 𝑥(𝑗),如果存在核心对象样本 𝑥(𝑡) ,使 𝑥(𝑖) 和 𝑥(𝑗) 均由 𝑥(𝑡) 密度可达,则称 𝑥(𝑖) 和 𝑥(𝑗) 密度相连。密度相连关系满足对称性。
基于下图可以很容易理解上述定义,图中 𝑀𝑖𝑛𝑃𝑜𝑖𝑛𝑡𝑠 = 4,红色的点都是核心对象,因为其 𝜖 − 邻域至少有 4 个样本。黑色的样本是非核心对象。所有核心对象密度直达的样本都在以红色核心对象为中心的圆内,如果不在圆内,则不能密度直达。图中用蓝色箭头连起来的核心对象组成了密度可达的样本序列,此序列是一个簇集。在这些密度可达的样本序列的 𝜖 − 邻域内所有的样本相互都是密度相连的 (注意,此图中有两个簇集)。

2、算法思路
DBSCAN 的聚类定义很简单:由密度可达关系导出最大密度相连的样本集合,即为我们最终聚类的一个簇。簇里面可以有一个或者多个核心对象。如果只有一个核心对象,则簇里其他的非核心对象样本都在这个核心对象的 𝜖 − 邻域里;如果有多个核心对象,则簇里的任意一个核心对象的 𝜖 − 邻域中一定至少有一个其他核心对象,否则这两个核心对象无法密度可达。这些核心对象的 𝜖 − 邻域里的所有样本集合就组成了一个DBSCAN 聚类簇。
现在我们讨论下如何根据 DBSCAN 的聚类定义来对数据集进行聚类。首先,在样本集中选出所有的核心对象并构成一个集合 𝛺;然后,在 𝛺 中任意选择一个数据点作为根,并标记该数据点作为一个新类簇;接下来,寻找所有这个核心对象能够密度可达的样本集合,并将这个集合中的所有点都归类到根所在类簇中,这便找到了一个类(这样得到的所有数据点肯定都是密度相连的)。之后,不断按这样的方式寻找新类簇,直到集合 𝛺 中的所有核心对象都有类别为止。最终,剩余未被归类的数据点即被称为“噪声点”或“离群点”。因此,DBSCAN 算法也可用于识
别噪声点。
基于以上讨论,下面给出 DBSCAN 算法的具体流程:
① 初始化核心对象集合 𝛺 = ∅ ,待查子集合 𝛹 = ∅ ,初始化类簇个数 𝑘 = 0;
② 遍历样本集 𝐷 的元素,如果是核心对象,则将其加入到核心对象集合 𝛺 中;
③ 接下来遍历核心对象集 𝛺 ;
④ 若核心对象集 𝛺 中所有元素都已被访问,则算法结束,否则转入步骤 ⑤;
⑤ 在核心对象集 𝛺 中,随机选择一个未被访问的核心对象 𝛼。首先将其标记为已访问,然后将 𝛼 所属类别标记为 𝑘,最后再将 𝛼 的 𝜖 − 邻域中的所有未被访问数据存放到待查子集合 𝛹 中;
⑥ 如果待查子集合 𝛹 = ∅,则当前类簇 𝐶𝑘 生成完毕,令 𝑘 = 𝑘 + 1,并跳转到 ③。否则,从待查子集合 𝛹 中选出一个数据点 𝜓 。首先将其标记为已访问,并标记所属类别为 𝑘,然后判断 𝜓 是否为核心对象,如果是,则将 𝜓 包含的未被访问的数据点加入到待查子集合 𝛹 中,并跳转到 ⑥。

上图展示了 DBSCAN 算法的执行流程(图中 𝑀𝑖𝑛𝑃𝑜𝑖𝑛𝑡𝑠=4):
- (a) 算法开始,将指定数据集的特征投影至 𝑛 维欧氏空间,并构建核心对象集 𝛺 = ∅ 、待查子集 𝛹 = ∅ 、令初始类簇个数 𝑘 = 0。
- (b) 遍历样本数据集,选出所有的核心对象,并存放至核心对象集合 𝛺 中,即有 𝛺 = {𝐴,𝐵,𝐶,𝐷}。
- (c) 接下来遍历核心对象集 𝛺,直到所有的核心对象都被访问过。开始时,可任意选出一个核心对象,如 𝐴 。首先将其标记为已访问,然后将𝐴 所属类别标记为 𝑘 = 0 ,最后再将 𝐴 的 𝜖 − 邻域中的所有未被访问数据存放进待查子集合 𝛹 中,即有 𝛹 = {𝐴1,𝐴2,𝐴3,𝐵}。
接着,对 𝛹 进行遍历,直到 𝛹 为空。第一次,从 𝛹 中取出数据点 𝐴1 ,首先将𝐴1 标记为已访问,然后将 𝐴1 归类至 𝑘=0,最后判断 𝐴1 不是核心对象,不做处理;第二次,从𝛹 中取出数据点 𝐴2 ,首先将 𝐴2 标记为已访问,然后将 𝐴2 归类至 𝑘 = 0,最后判断 𝐴2 不是核心对象,不做处理;第三次,从 𝛹 中取出数据点 𝐴3,首先将 𝐴3 标记为已访问,然后将 𝐴3 归类至 𝑘 = 0,最后判断 𝐴3 不是核心对象,不做处理;第四次,从 𝛹 中取出数据点 𝐵 ,首先将 𝐵 标记为已访问,然后将 𝐵 归类至 𝑘 = 0,最后判断𝐵 是核心对象,因此,将
𝐵 包含的未被访问的数据点加入到待查子集合 𝛹 中,此时 𝛹 = {𝐵1,𝐵2,𝐶}。(如图(d)所示)。 - (d) 𝛹 不空,继续对 𝛹 进行遍历,直到 𝛹 为空。第一次,从 𝛹 中取出数据点 𝐵1,首先将 𝐵1 标记为已访问,然后将 𝐵1 归类至 𝑘=0,最后判断 𝐵1 不是核心对象,不做处理;第二次,从 𝛹 中取出数据点 𝐵2 ,首先将 𝐵2 标记为已访问,然后将 𝐵2 归类至 𝑘 = 0 ,最后判断 𝐵2 不是核心对象,不做处理;第三次,从 𝛹 中取出数据点 𝐶 ,首先将 𝐶 标记为已访问,然后将 𝐶 归类至 𝑘 = 0 ,最后判断 𝐶 是核心对象,因此,将 𝐶 包含的未被访问的数据点加入到待查子集合 𝛹 中,此时 𝛹 = {𝐶1} (如图(e)所示)。
- (e) 𝛹 不空,继续对 𝛹 进行遍历,直到 𝛹 为空。第一次,从 𝛹 中取出数据点 𝐶1,首先将 𝐶1 标记为已访问,然后将 𝐶1 归类至 𝑘 = 0 ,最后判断 𝐶1 不是核心对象,不做处理。此时,待查子集 𝛹 = ∅,表示当前类簇 𝐶0 已经生成完毕,令 𝑘 = 𝑘+1 = 0+1 = 1,开始寻找下一个类簇。即退至核心对象集合 𝛺 ,继续遍历 𝛺 以寻找尚未被访问过的核心对象。
- (f) 𝛺 = {A,𝐵,𝐶,𝐷} 中,A、𝐵、𝐶 均已被访问,此时仅剩 𝐷 ,将其选出。首先将其标记为已访问,然后将𝐷 所属类别标记为 𝑘 = 1,最后再将 𝐷 的 𝜖 − 邻域中的所有未被访问数据存放进待查子集合 𝛹 中,即有 𝛹 = {𝐷1,𝐷2,𝐷3,𝐷4}。
接着,对 𝛹 进行遍历,直到 𝛹 为空。第一次,从 𝛹 中取出数据点 𝐷1,首先将 𝐷1 标记为已访问,然后将 𝐷1 归类至 𝑘 = 1,最后判断 𝐷1 不是核心对象,不做处理;第二次,从 𝛹 中取出数据点 𝐷2,首先将 𝐷2 标记为已访问,然后将 𝐷2 归类至 𝑘 = 1,最后判断 𝐷2 不是核心对象,不做处理;第三次,从 𝛹 中取出数据点 𝐷3 ,首先将 𝐷3 标记为已访问,然后将 𝐷3 归类至 𝑘 = 1,最后判断𝐷3 不是核心对,不做处理;第四次,从 𝛹 中取出数据点 𝐷4,首先将 𝐷4 标记为已访问,然后将 𝐷4 归类至 𝑘 = 1,最后判断 𝐷4 不是核心对象,不做处理。
此时,待查子集 𝛹 = ∅,表示当前类簇 𝐶1 已经生成完毕,令 𝑘 = 𝑘+1 = 1+1 = 2,开始寻找下一个类簇。即退至核心对象集合 𝛺 ,继续遍历 𝛺 以寻找尚未被访问过的核心对象。 - 𝛺 = {𝐴,𝐵,𝐶,𝐷} 中,所有元素均已被访问,退出算法。
输出所有类簇:𝐶0、𝐶1。
3、算法总结
DBSCAN 算法不是一个完全稳定的算法。例如某些样本可能到两个核心对象的距离都小于 𝜖,但是,由于这两个核心对象不是密度直达,且又不属于同一个类簇,那么如果界定这些样本的类别呢?此时,DBSCAN 通常会采用先来后到的准则,即在算法执行过程中,这些样本先被归到哪一类则最终就隶属于那一类。所以,同一数据集在 DBSCAN 的执行过程中,某些样本最终的归类并不一定严格一致。
DBSCAN 的主要优点:
- 可以对任意形状的稠密数据集进行聚类,而 K-means 聚类算法一般只适用于凸数据集;
- 不需要指定簇的个数;
- 可以在聚类的同时发现异常点,对数据集中的异常点不敏感;
- 聚类结果较稳定(K-means 聚类算法的初始值对聚类结果有很大影响)。
DBSCAN 的主要缺点:
- 当数据集密度不均匀、聚类间距差相差很大时, DBSCAN 的聚类效果较差。
- 当数据集维度较高(即特征较多)时,聚类收敛时间较长(此时可先对数据集进行降维处理)。
- 调参相对于 K-means 算法稍复杂,需要对距离阈值 𝜖 ,邻域样本数阈值 𝑀𝑖𝑛𝑃𝑜𝑖𝑛𝑡𝑠 联合调参,不同的参数组合对最终的聚类效果有较大影响
四、实战部分
本文主要介绍了聚类算法及其相关定义,接着又讲解了其中最具代表的 k-means 、DBSCAN 算法,并重点指出了这两种算法各自的执行流程和优缺点(适用场景)。有关聚类算法的内容,我们最需要了解的是其算法思维和聚类思想。在实践方面,已经有大量的第三方库完成了对这些算法的封装,因此,我们的实践重心要放在如何使用之上。下面附上实战链接:
实战链接
END
相关文章:
【机器学习】聚类算法(理论)
聚类算法(理论) 目录一、概论1、聚类算法的分类2、欧氏空间的引入二、K-Means算法1、算法思路2、算法总结三、DBSCAN算法1、相关概念2、算法思路3、算法总结四、实战部分一、概论 聚类分析,即聚类(Clustering)…...
Docker-用Jenkins发版Java项目-(1)Docke安装Jenkins
文章目录前言环境背景操作流程docker安装及jenkins软件安装jenkins配置登录配置安装插件及创建账号前言 学海无涯,旅“途”漫漫,“途”中小记,如有错误,敬请指出,在此拜谢! 最近新购得了M2的MAC,…...
java集合框架内容整理
主要内容集合框架体系ArrayListLinkedListHashSetTreeSetLinkedHashSet内部比较器和外部比较器哈希表的原理List集合List集合的主要实现类有ArrayList和LinkedList,分别是数据结构中顺序表和链表的实现。另外还包括栈和队列的实现类:Deque和Queue。• Li…...

win10系统安装Nginx
Nginx是一款自由的、开源的、高性能的HTTP服务器和反向代理服务器,同时也提供了IMAP/POP3/SMTP服务。 Nginx可以进行反向代理、负载均衡、HTTP服务器(动静分离)、正向代理等操作。因为最近在公司使用到了Nginx 第一步:下载Nginx …...

数据库学习笔记(2)——workbench和SQL语言
1、workbench简介: 登录客户端的两种方法 在cmd中,只能通过sql语句控制数据库;workbench其实就是一种图形化数据库管理工具,在workbench中既可以通过sql语句控制数据库,也可以通过图形化界面控制数据库。通过workbenc…...

测量学期末考试之名词解释总结
仅供自己参考,且范围不全面.大地水准面与处于静止平衡状态的平均海水面重合,并延伸通过陆地的水准面高程地面点到大地水准面的铅锤距离水准面处于静止状态的水面就是水准面高差两点的水准面之间的铅锤距离垂直角在铅锤面上,瞄准目标的倾斜视线…...
TDengine时序数据库的简单使用
最近学习了TDengine数据库,因为我们公司有硬件设备,设备按照每分钟,每十分钟,每小时上传数据,存入数据库。而这些数据会经过sql查询,统计返回展示到前端。但时间积累后现在数据达到了百万级数据,…...

记录每日LeetCode 2335.装满被子需要的最短总时长 Java实现
题目描述: 现有一台饮水机,可以制备冷水、温水和热水。每秒钟,可以装满 2 杯 不同 类型的水或者 1 杯任意类型的水。 给你一个下标从 0 开始、长度为 3 的整数数组 amount ,其中 amount[0]、amount[1] 和 amount[2] 分别表示需要…...

了解线程池newFixedTheadPool
什么是线程池 操作系统 能够进行运算 调度 的最小单位。线程池是一种多线程处理形式。 为什么引入线程池的概念 解决处理短时间任务时创建和销毁线程代价较大的弊端,可以使用线程池技术。 复用 饭店只有一个服务员和饭店有10个服务员 线程池的种类 newFixedThea…...

IP分片和TCP分段解析--之IP分片
本文目录什么是IP分片为什么会产生IP分片为什么要避免IP分片如何避免IP分片什么是IP分片 IP协议栈将TCP/UDP传输层要求它发送的,但长度大于发送端口MTU的一个数据包,分割成多个IP报文后分多次发送。这些分成多次发送的多个IP报文就是IP分片。 为什么会…...

物联网方向常见通信方式有哪些?
常用的有线通信方式有串口、以太网等。 1、串口 串口通信普及率高、成本低,但是组网能力差,只适合低速率和小数据量的通信 2、以太网接口(网线) 以太网(Ethernet)是目前最普遍的一种局域网 通信技术,它规定了包括 物理层的连线、电子信号和介质访问层协议的内容。 以太…...
windows wireshark抓到未加入组的组播消息
现象 在Windows上开启wireshark,抓到了大量地址为239.255.255.251的组播包。 同时,根据组播相关命令,调用netsh interface ipv4 show joins,显示当前并没加入 239.255.255.251 组播组。 解决 根据IGMP Snooping,I…...
)
【PTA Advanced】1156 Sexy Primes(C++)
目录 题目 Input Specification: Output Specification: Sample Input 1: Sample Output 1: Sample Input 2: Sample Output 2: 思路 代码 题目 Sexy primes are pairs of primes of the form (p, p6), so-named since "sex" is the Latin word for "…...

项目(今日指数)
一 项目架构1.1 今日指数技术选型【1】前端技术【2】后端技术栈【3】整体概览3.2 核心业务介绍1】业务结构预览【2】业务功能简介1.定时任务调度服务XXL-JOB通过RestTemplate多线程动态拉去股票接口数据,刷入数据库; 2.国内指数服务 3.板块指数服务 4.涨…...
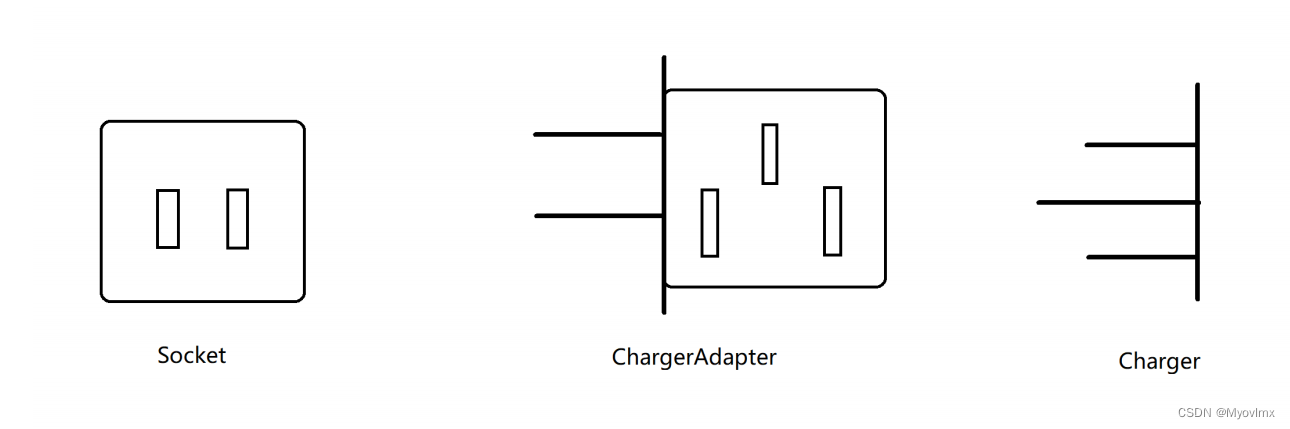
适配器模式(Adapter Pattern)
1.什么是适配器模式? 适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能。 这种模式涉及到一个单一的类,该类负责加入独立的或不兼容的接…...
)
网易一面:select分页要调优100倍,说说你的思路? (内含Mysql的36军规)
背景说明: Mysql调优,是大家日常常见的调优工作。所以Mysql调优是一个非常、非常核心的面试知识点。 在40岁老架构师 尼恩的读者交流群(50)中,其相关面试题是一个非常、非常高频的交流话题。 近段时间,有小伙伴面试网易&#x…...
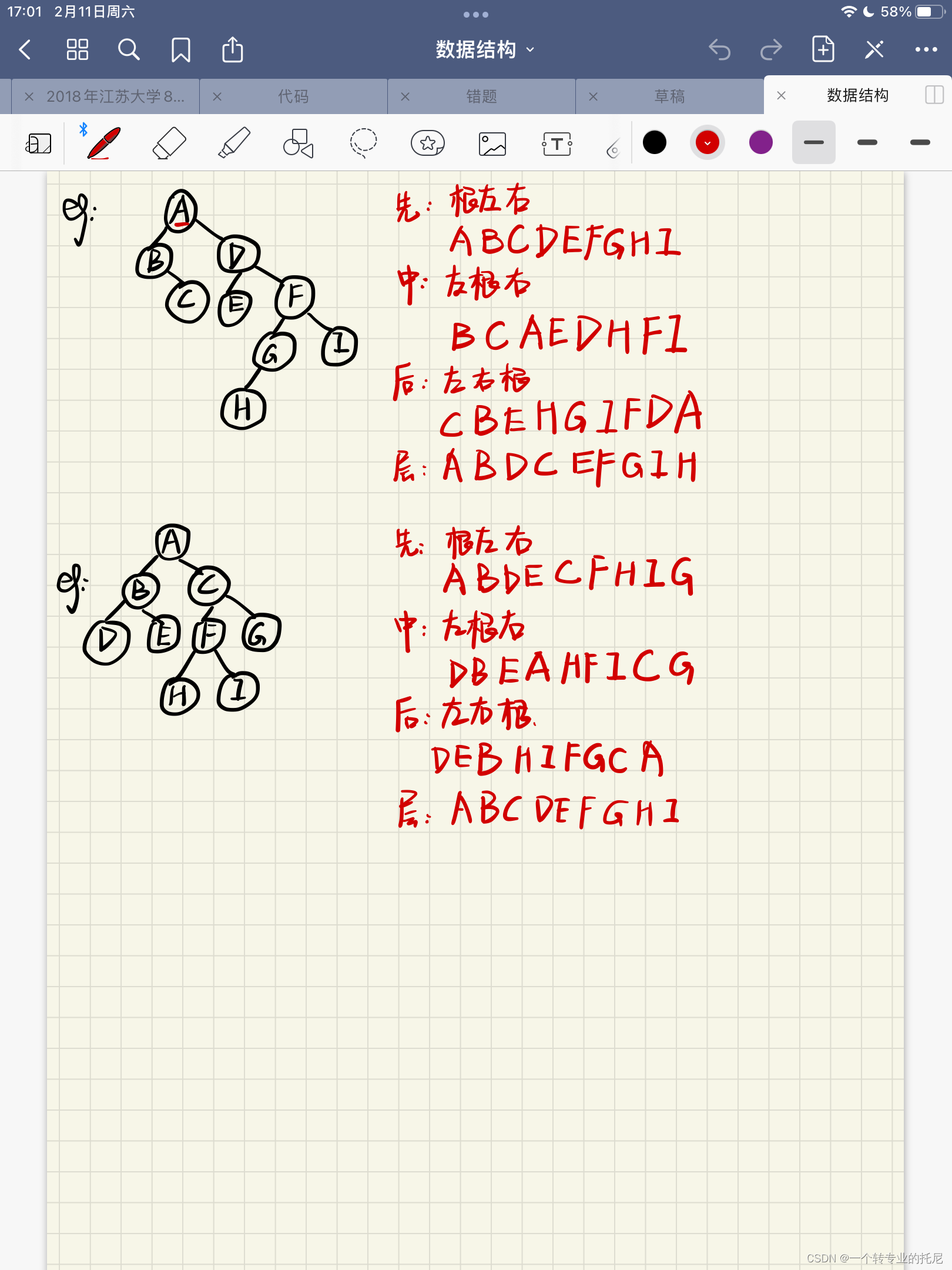
二叉树的遍历 (2023-02-11)
二叉树的遍历 二叉树的遍历分为:先序遍历、中序遍历、后序遍历和层次遍历。 1.先序遍历(根左右) (1)访问根节点 (2)左子树按根左右遍历 (3)右子树按根左右遍历 2.中序…...
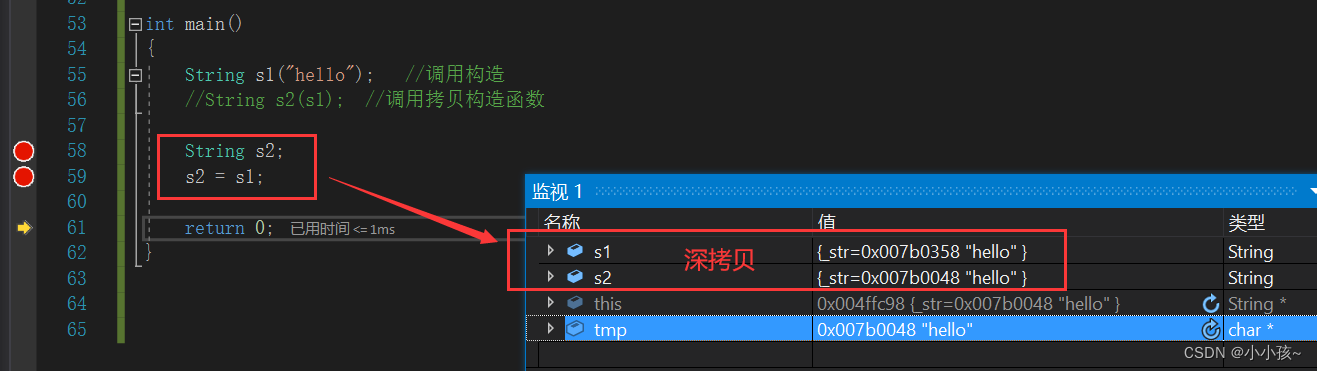
string的深浅拷贝问题
深浅拷贝问题引入浅拷贝深拷贝总结问题引入 对于一个普通的string类: class String { public:String(const char* str ""){//构造函数if (nullptr str)str "";_str new char[strlen(str) 1];strcpy(_str, str);}~String(){//析构函数if …...

C++中的万能头文件
目录一、什么是万能头文件?二、源码三、编译器找不到 bits/stdc.h一、什么是万能头文件? C的万能头文件是: #include <bits/stdc.h>它是一个包含了每一个标准库的头文件。 优点: 在算法竞赛中节约时间;减少了…...

Java 8 Lambda 表达式 Stream
lambda表达式和Stream流是JDK8新增加的新特性,研究本文内容或者运行本文中的demo示例必须安装并使用JDK8以上的JDK版本。demo地址:https://gitee.com/huannzi/bigdataframework/tree/master/src/main/java/com/orkasgb/java 文章目录1、什么是Lambda表达…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...