Elasticsearch:以 “Painless” 方式保护你的映射
Elasticsearch 是一个很棒的工具,可以从各种来源收集日志和指标。 它为我们提供了许多默认处理,以便提供最佳用户体验。 但是,在某些情况下,默认处理可能不是最佳的(尤其是在生产环境中); 因此,今天我们将深入探讨避免 “映射污染” 的方法。
什么是“映射”,为什么会有污染?
与任何数据存储解决方案一样,必须有一个模式(schema)等效设置来说明如何处理数据字段(例如存储和处理/分析); 此设置在 Elasticsearch 下称为 “映射(mapping)”。
与大多数不同,如果未指定,Elasticsearch 会为模式设置提供默认处理。 举个例子,当我们创建一个文档并引入一个全新的数据索引时,Elasticsearch 会尝试为我们猜测正确的字段映射。 是的~这是一个猜测! 因此,在大多数情况下,我们会毫无问题地摄取该文档,并自动完成。 干杯~但是等等……
- 猜测的映射可能未优化(例如,任何整数字段都将映射到占用 64 位内存的数据类型 “long”,但是如果你的整数字段范围仅从 0~5 ......可能是 “byte” 或 “short” 就足够了,只需要 8 到 16 位内存)
- 有些字段对我们来说毫无意义,因此我们应该在摄取之前排除它们以免引入映射污染
如何避免映射污染 —— Painless 脚本处理器方法
我们可以使用脚本处理器创建一个摄取管道,以在最终摄取发生之前删除目标字段。
用例:删除名称长度超过 15 个字符的字段。
也许我们的数据与随机生成的 UUID(超过 15 个字符长)下的一些元数据一起出现,并且不知何故我们永远不需要这些元数据。 因此,为避免映射污染,我们需要在一开始就排除此类字段。 以下是检查文档中可能字段长度的示例:
# pipeline to script and loop around all fields in a
# context
POST _ingest/pipeline/_simulate
{"pipeline": {"processors": [{"script": {"source": """boolean flag = false;java.util.Set keys = ctx.keySet();for (String key : keys) {if (key.length()>15) {flag = true;}}ctx["has_long_fields"] = flag;"""}}]},"docs": [{"_source": {"very_very_long_field": "balabalabalabalabala"}},{"_source": {"age": 12}}]
}上面的命令的响应为:
{"docs": [{"doc": {"_index": "_index","_id": "_id","_version": "-3","_source": {"very_very_long_field": "balabalabalabalabala","has_long_fields": true},"_ingest": {"timestamp": "2023-03-01T06:40:53.22560943Z"}}},{"doc": {"_index": "_index","_id": "_id","_version": "-3","_source": {"has_long_fields": false,"age": 12},"_ingest": {"timestamp": "2023-03-01T06:40:53.225907596Z"}}}]
}我们可以清楚地看到 2 个测试文档的结果:第一个包含一个字段 very_very_long_field,结果为 true,而第二个只包含一个 age 字段,结果为 false。
这里的技巧是 ctx.keySet() 方法。 此方法返回一个 Set 接口,其中包含文档下可用的所有 “field-names”。 获得 Set 后,我们可以开始迭代它并应用我们的匹配逻辑。
一个棘手的事情是......这个集合还包含元数据字段,如 _index 和 _id,因此当我们应用一些字段匹配逻辑时,也要注意这些字段。
下一个示例将说明如何从我们的文档上下文中删除相应的字段:
# remove long fields...
POST _ingest/pipeline/_simulate
{"pipeline": {"processors": [{"script": {"source": """boolean flag = false;java.util.Set keys = ctx.keySet();java.util.List fields = new java.util.ArrayList();for (String key : keys) {if (!key.startsWith("_") && key.length() > 10) {fields.add(key); }}// look through and delete those long field(s)if (fields.size() > 0) {for (String field: fields) {ctx.remove(field);}flag = true;}ctx["has_removed_long_fields"] = flag;""" }}]},"docs":[{"_source": {"very_very_long_field": "balabalabalabalabala","another_long_field": "wakkakakakaka","age": 13,"name": "Felis"}},{"_source": {"desc": "dkjfdkjfkdjfkdfjk","address": "wakkakakakaka","age": 13,"name": "Felis"}}]
}上面命令的返回值为:
{"docs": [{"doc": {"_index": "_index","_id": "_id","_version": "-3","_source": {"name": "Felis","age": 13,"has_removed_long_fields": true},"_ingest": {"timestamp": "2023-03-01T06:45:46.164088718Z"}}},{"doc": {"_index": "_index","_id": "_id","_version": "-3","_source": {"name": "Felis","address": "wakkakakakaka","age": 13,"desc": "dkjfdkjfkdjfkdfjk","has_removed_long_fields": false},"_ingest": {"timestamp": "2023-03-01T06:45:46.164113593Z"}}}]
}魔法是 ctx.remove(“fieldname”)。 很简单不是吗? 另请注意,我们对字段匹配逻辑 !key.startsWith(“_”) && key.length()>10 应用了更精确的规则,因此不会考虑所有元字段(例如 _index)。
还引入了一个 ArrayList 来存储目标字段名称。 你可能会问为什么我们不在循环期间直接从文档上下文中删除该字段? 原因是如果我们尝试这样做,则会爆发一个异常,描述对文档上下文的并发修改。 因此,我们需要延迟删除过程,并且此 ArrayList 会跟踪这些字段名称。
最后,还有另一种情况,我们的文档可能涉及多个级别/层次结构。 以下示例说明如何确定字段是 “leaf” 字段还是 “branch” 字段:
# remove the inner field
POST _ingest/pipeline/_simulate
{"pipeline": {"processors": [{"script": {"source": """java.util.Set keys = ctx.keySet();java.util.ArrayList fields = new java.util.ArrayList();for (String key : keys) {// access the value; check the typeif (key.startsWith("_")) {continue;}Object value = ctx[key];if (value != null) {// it is a MAP (equivalent to the "object" structure of a json field)if (value instanceof java.util.Map) {// inner fields loopjava.util.Map innerObj = (java.util.Map) value;for (String innerKey: innerObj.keySet()) {if (innerKey.length() > 10) {//Debug.explain("a long field >> "+innerKey);fields.add(key+"."+innerKey);}}} else {if (key.length() > 10) {fields.add(key);}}}}if (fields.size()>0) {for (String field:fields) {// is it an inner field?int idx = field.indexOf(".");if (idx != -1) {ctx[field.substring(0, idx)].remove(field.substring(idx+1));} else {ctx.remove(field); }}}"""}}]},"docs": [{"_source": {"age": 13,"very_very_very_long_field": "to be removed","outer": {"name": "Felix","very_very_long_field": "dkjfdkjfkdjfkdfjk"}}}]
}上面的响应为:
{"docs": [{"doc": {"_index": "_index","_id": "_id","_version": "-3","_source": {"outer": {"name": "Felix"},"age": 13},"_ingest": {"timestamp": "2023-03-01T06:54:51.610568095Z"}}}]
}一个很长的代码……为了检查该字段是 “leaf” —— 普通字段还是 “branch” —— 另一层字段(例如对象); 我们需要检查字段值的类型 java.util.Map 的值实例。
instanceof 方法有助于验证提供的值是否与特定的 Java 类类型匹配。
接下来,我们需要再次迭代 Set of inner-object fields 以应用我们的匹配规则。 使用 ArrayList 的相同技术将应用于跟踪目标字段名称,以便在稍后阶段删除。
最后,通过 ctx.remove(“fieldname”) 删除字段。 但是这次,我们还需要检查这个字段是 leaf 还是 branch 字段。 对于 branch 字段,它将以 outer-object-name.inner-field-name 的格式出现。 我们需要先提取 outer-object-name 并在删除 inner-field-name 之前访问其上下文 -> ctx[field.substring(0, idx)].remove(field.substring (idx+1))
举个例子:outer.very_very_long_field
- idx(“.”分隔符所在的 index) = 5
- field.substring(0, idx) = "outer"
- field.substring(idx+1) = "very_very_long_field"
- 因此…… ctx[field.substring(0, idx)].remove(field.substring(idx+1)) = ctx[“outer”].remove(“very_very_long_field”)
干得好 ~ 这是避免贴图污染的 “Painless” 脚本方法。
如何避免映射污染 —— 索引的动态设置方法
有时,我们可能不介意引入一个映射污染; 然而~我们不希望那些无意义的字段是可搜索或可聚合的。 只是我们让那些无意义的字段充当虚拟对象,你可以看到它们(在 _source 字段下可用)但永远无法对它们应用任何操作。 如果是这样的话……我们可以更改索引的动态设置。
PUT test_dynamic
{"mappings": {"dynamic": "false","properties": {"name": {"type": "text"},"address": {"dynamic": "true","properties": {"street": {"type": "keyword"}}},"work": {"dynamic": "strict","properties": {"department": {"type": "keyword"},"post": {"type": "keyword"}}}}}
}我们通过如下的方法来摄入一些数据:
# all good, everything matches the mapping
POST test_dynamic/_doc
{"name": "peter parker","address": {"street": "20 Ingram Street","state": "NYC"},"work": {"department": "daily bugle"}
}# added a non-searchable "age" and a searchable field "address.post_code"
POST test_dynamic/_doc
{"age": 45,"name": "Edward Elijah","address": {"post_code": "344013"}
}很显然,在上面,age 不在之前的映射中定义。由于我们在映射中设置 dynamic 为 false,age 这个字段将不能被用于搜索:
| dynamic | doc indexed? | fields searchable | fields indexed? | mapping updated? |
|---|---|---|---|---|
| true | Yes | Yes | Yes | Yes |
| runtime | Yes | Yes | No | No |
| false | Yes | No | No | No |
| strict | No |
GET test_dynamic/_search
{"query": {"match": {"age": 45}}
}上面搜索的结果为空。有关动态映射的文章,请详细阅读文章 “Elasticsearch:Dynamic mapping”。
我们接着进行如下的搜索:
GET test_dynamic/_search
{"query": {"match": {"address.post_code": "344013"}}
}上面的搜索显示的是一个文档:
"hits": [{"_index": "test_dynamic","_id": "Z2X8m4YBRPmzDW_iGJOb","_score": 0.2876821,"_source": {"age": 45,"name": "Edward Elijah","address": {"post_code": "344013"}}}]我们执行如下的命令:
# exception as work.salary is forbidden
POST test_dynamic/_doc
{"age": 45,"name": "Prince Tomas","address": {"post_code": "344013"},"work": {"salary": 10000000}
}上面命令返回的结果为:
{"error": {"root_cause": [{"type": "strict_dynamic_mapping_exception","reason": "mapping set to strict, dynamic introduction of [salary] within [work] is not allowed"}],"type": "strict_dynamic_mapping_exception","reason": "mapping set to strict, dynamic introduction of [salary] within [work] is not allowed"},"status": 400
}这是因为 work 字段的属性为 strict。我们不可以为这个字段添加任何新的属性。
如何避免映射污染 —— 通过预处理方法删除字段
这里讨论的最后一种方法是在传递给 Elasticsearch 之前删除无意义的字段......以及如何? 嗯……自己写程序,对文档进行预处理~:)))))
这确实是一种有效的方法,但可能并不适合所有人; 因为需要一些编程知识。 有时,如果我们在传递给 Elasticsearch 之前对文档进行预处理,它可能会更加灵活,因为我们可以完全控制文档的修改(由于编程语言的功能)。
相关文章:

Elasticsearch:以 “Painless” 方式保护你的映射
Elasticsearch 是一个很棒的工具,可以从各种来源收集日志和指标。 它为我们提供了许多默认处理,以便提供最佳用户体验。 但是,在某些情况下,默认处理可能不是最佳的(尤其是在生产环境中); 因此&…...
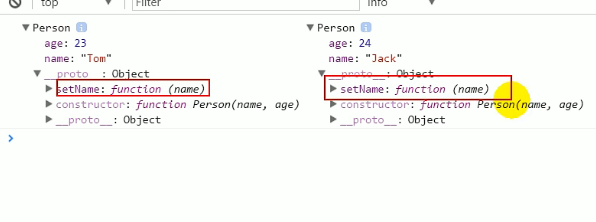
js几种对象创建方式
适用于不确定对象内部数据方式一:var p new Object(); p.name TOM; p.age 12 p.setName function(name) {this.name name; }// 测试 p.setName(jack) console.log(p.name,p.age)方式二: 对象字面量模式套路:使用{}创建对象,同…...

阿里云服务器ECS适用于哪些应用场景?
云服务器ECS具有广泛的应用场景,既可以作为Web服务器或者应用服务器单独使用,又可以与其他阿里云服务集成提供丰富的解决方案。 云服务器ECS的典型应用场景包括但不限于本文描述,您可以在使用云服务器ECS的同时发现云计算带来的技术红利。 阿…...
Ajax学习笔记01
引入 翻译成中文就是“异步的Javascript和XML”。即使用Javascript语言与服务器进行异步交互,传输的数据为XML(当然,传输的数据不只是XML)。 AJAX 不是新的编程语言,而是一种使用现有标准的新方法。 AJAX 最大的优点…...
Jinja2----------过滤器的使用、控制语句
目录 1.过滤器的使用 1.过滤器和测试器 2.过滤器 templates/filter.html app.py 效果 3.自定义过滤器 app.py templates/filter.html 效果 2.控制语句 1.if app.py templates/control.html 2.for app.py templates/control.htm 1.过滤器的使用 1.过滤器和测…...
面试了1个自动化测试,开口40W年薪,只能说痴人做梦...
公司前段缺人,也面了不少测试,结果竟然没有一个合适的。一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资在10-20k,面试的人很多,但平均水平很让人失望。看简历很多都是3年工作经验,但面试…...
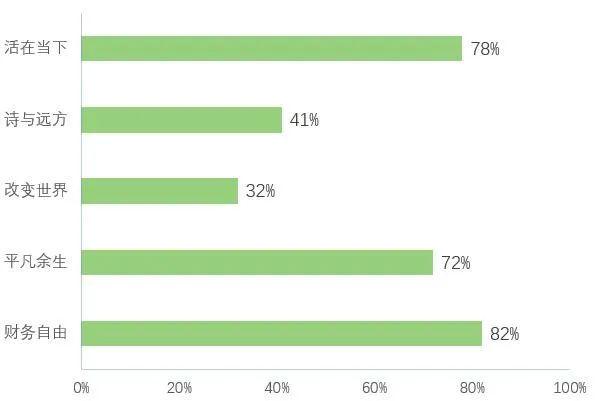
冲鸭!33% 程序员月薪达到 5 万元以上~
2023年,随着互联网产业的蓬勃发展,程序员作为一个自带“高薪多金”标签的热门群体,被越来越多的人所关注。在过去充满未知的一年中,他们的职场现状发生了一定的改变。那么,程序员岗位的整体薪资水平、婚恋现状、职业方…...
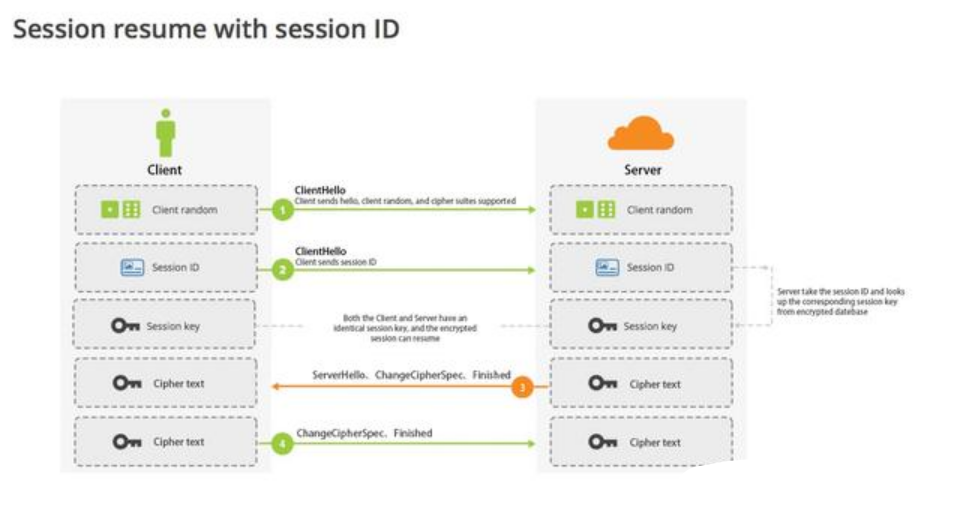
【RSA】HTTPS中SSL/TLS握手时RSA前后端加密流程
SSL/TLS层的位置 SSL/TLS层在网络模型的位置,它属于应用层协议。接管应用层的数据加解密,并通过网络层发送给对方。 SSL/TLS协议分握手协议和记录协议,握手协议用来协商会话参数(比如会话密钥、应用层协议等等)&…...

clion在linux设置桌面启动图标(jetbrains全家桶均适用)
clion在linux设置桌面启动图标(jetbrains全家桶均适用) 网上大部分步骤都只是pycharm的教程,其实对于jetbrains全家桶都适合,vs code编辑器也可以这样。 刚开始是使用pycharm在linux设置的教程,参照:http…...
Java数据结构LinkedList单链表和双链表模拟实现及相关OJ题秒AC总结知识点
本篇文章主要讲述LinkedList链表中从初识到深入相关总结,常见OJ题秒AC,望各位大佬喜欢 一、单链表 1.1链表的概念及结构 1.2无头单向非循环链表模拟实现 1.3测试模拟代码 1.4链表相关面试OJ题 1.4.1 删除链表中等于给定值 val 的所有节点 1.4.2 反转…...
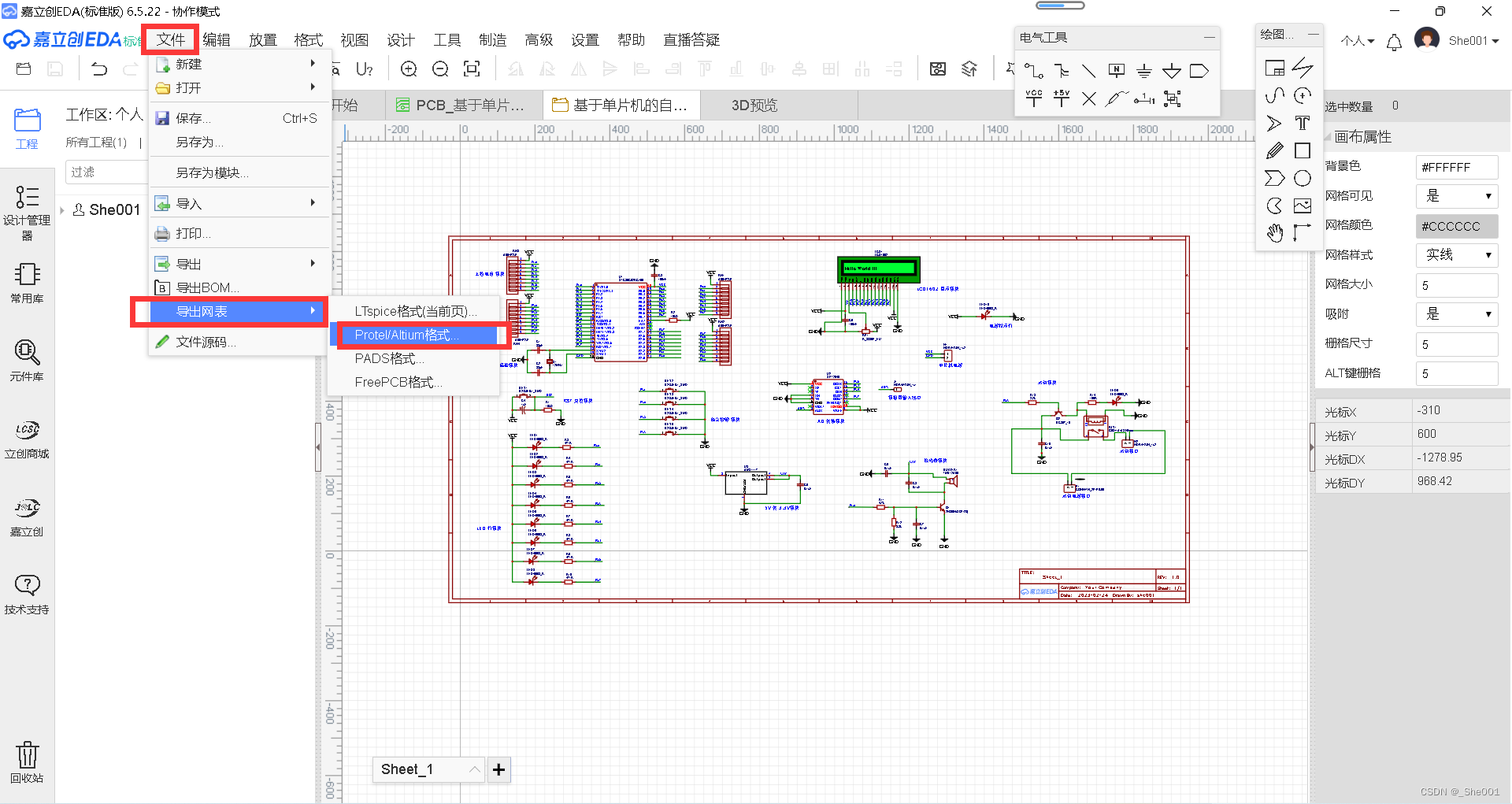
立创EDA 学习 day01 应用下载安装,基本使用的操作
1.下载网站 1.链接:立创EDA下载-立创EDA官方版-PC下载网 (pcsoft.com.cn) 2.安装立创EDA 1.直接 next (简单的操作) 3.注册账号 1. 最好注册一个账号,等下在原理图转PCB 板的时候要登录,才可以。 4.新建工程 1.新…...
)
华为OD机试真题Python实现【火星文计算】真题+解题思路+代码(20222023)
火星文计算 题目 已经火星人使用的运算符号为# $ 其与地球人的等价公式如下 x#y=2*x+3*y+4 x$y=3*x+y+2 x y是无符号整数 地球人公式按照 c 语言规则进行计算 火星人公式中$符优先级高于#相同的运算符按从左到右的顺序运算 🔥🔥🔥🔥🔥👉👉👉👉👉👉 华…...

yolov8 修改类别 自定义数据集
yolov8 加载yolo网络模型 yolov8n.yaml nc: 80 # number of classes 分类数量 depth_multiple: 0.33 # scales module repeats 重复规模 width_multiple: 0.25 # scales convolution channels 缩放卷积通道 backbone head 指定配置 coco128.yaml path: ../datasets/coco128 # d…...
Linux环境下验证python项目
公司大佬开发的python rpa跑数项目,Windows运行没问题后,需要搭建一个linux环境进行验证,NOW START! Install VMware官网 下载好之后打开按步骤安装 最后一步会让填许可证(密钥),这里自行百…...

MAC开发使用技巧
1. 查看所有安装的程序 您可以通过以下步骤在 macOS 中查看所有已安装的程序: 点击屏幕左上角的苹果图标,选择“关于本机”。 在打开的窗口中,选择“系统报告”。 在系统报告窗口中,选择“软件”选项卡,然后选择“安…...

第三章-OpenCV基础-7-形态学
前置 形态学主要是从图像中提取分量信息,该分量信息通常是图像理解时所使用的最本质的形状特征,对于表达和描绘图像的形状有重要意义。 大体就是通过一系列操作让图像信息中的关键信息更加凸出。同时,形态学的操作都是基于灰度图进行。 相关操作最主要…...
 部署)
DeepFaceLab 中Ubuntu(docker gpu) 部署
DeepFaceLab 在windows图形界面部署比较多,下面用ubuntu 部署在服务器上。部署过程中python版本,或者protobuf版本可能有问题,所以建议用docker 代码下载 cd /trainssdgit clone --depth 1 https://github.com/nagadit/DeepFaceLab_Linux.g…...

分析帆软填报报表点提交的逻辑
1 点提交这里首先会校验数据,校验成功后就去入库数据,这里不分析校验,分析下校验成功后数据是怎么入库的。 2 我们知道当点提交时,发送的请求中的参数为 op=fr_write,cmd=submit_w_report. 在帆软报表中op表示服务,cmd表示服务中的一个动作处理。比如op=fr_write这个服务…...

【ROS学习笔记9】ROS常用API
【ROS学习笔记9】ROS常用API 文章目录【ROS学习笔记9】ROS常用API前言一、 初始化二、 话题与服务相关对象三、 回旋函数四、时间函数五、其他函数Reference写在前面,本系列笔记参考的是AutoLabor的教程,具体项目地址在 这里 前言 ROS的常用API…...

客户关系管理挑战:如何保持客户满意度并提高业绩?
当今,各行业市场竞争愈发激烈,对于保持客户满意度并提高业绩是每个企业都面临的挑战。而客户关系管理则是实现这一目标的关键,因为它涉及到与客户的互动和沟通,以及企业提供优质的产品和服务。在本文中,我们将探讨客户…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...