pandas——DataFrame基本操作(二)【建议收藏】
pandas——DataFrame基本操作(二)
文章目录
- pandas——DataFrame基本操作(二)
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
- 1.修改数据
- 2.缺失值
- 3.合并
- 1.concat合并
- 2.使用append方法合并
- 3.使用merge进行合并
- 4.使用join进行连接
一、实验目的
熟练掌握pandas中DataFrame的修改元素值、缺失值处理、合并操作的方法
二、实验原理
concat合并:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False)
objs: series,dataframe或者是panel构成的序列lsit。
axis: 需要合并链接的轴,0是行,1是列,默认为axis=0。
join:连接的方式 inner,或者outer,默认为join=‘outer’
keys:合并的同时增加分区。
ignore_index:忽略索引,默认为False,当为True时,合并的两表就按列字段对齐。
merge合并:
pandas的merge方法提供了一种类似于SQL的内存链接操作,官网文档提到它的性能会比其他开源语言的数据操作(例如R)要高效。
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True, indicator=False,validate=None)
merge的参数:
left/right:两个不同的DataFrame
on:指的是用于连接的列索引名称。必须存在左右两个DataFrame对象中,如果没有指定且其他参数也未指定则以两个DataFrame的列名交集做为连接键
left_on:左则DataFrame中用作连接键的列名;这个参数中左右列名不相同,但代表的含义相同时非常有用。right_on:右则DataFrame中用作 连接键的列名。
left_index:使用左则DataFrame中的行索引做为连接键。
right_index:使用右则DataFrame中的行索引做为连接键。
how:指的是合并(连接)的方式有inner(内连接),left(左外连接),right(右外连接),outer(全外连接);默认为inner。
sort:根据DataFrame合并的keys按字典顺序排序,默认是True,如果置false可以提高表现。
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(‘_x’,‘_y’)
copy:默认为True,总是将数据复制到数据结构中;大多数情况下设置为False可以提高性能
indicator:在 0.17.0中还增加了一个显示合并数据中来源情况;如只来自于左边(left_only)、两者(both)。
merge的默认合并方法:merge用于表内部基于 index-on-index 和 index-on-column(s) 的合并,但默认是基于index来合并。
join连接:
主要用于索引上的合并
join(self, other, on=None, how='left', lsuffix='', rsuffix='',sort=False)
其中参数的意义与merge方法基本相同,只是join方法默认为左外连接how=left
1.默认按索引合并,可以合并相同或相似的索引,不管他们有没有重叠列。
2.可以连接多个DataFrame
3.可以连接除索引外的其他列
4.连接方式用参数how控制
5.通过lsuffix=‘’, rsuffix=‘’ 区分相同列名的列
三、实验环境
Python 3.6.1以上
jupyter notebook
四、实验内容
练习pandas中DataFrame的修改元素值、缺失值处理、合并操作。
五、实验步骤
1.修改数据
1.通过字典对象创建一个DataFrame。
import numpy as np
import pandas as pd
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df)
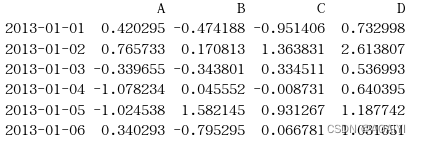
2.新建一个值为[1,2,3,4,5,6],索引index为2013-01-02到2013-01-07的Series,并将series赋值给df作为df新增的F列。
s1=pd.Series([1,2,3,4,5,6],index=pd.date_range('20130102',periods=6))
print(s1)
df['F']=s1
print(df)
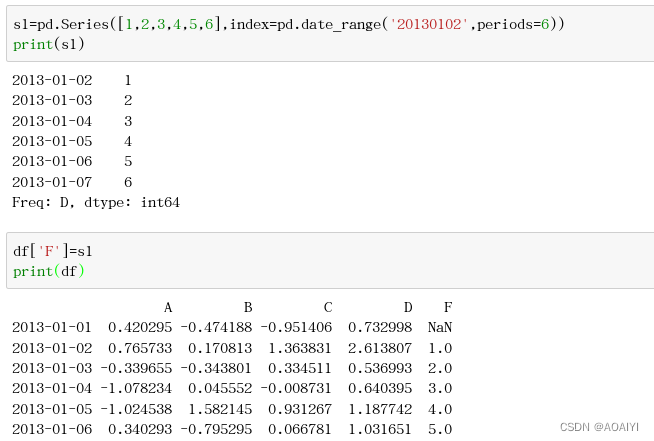
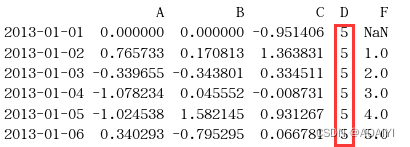
3.使用loc方法把df的D列值修改为5*len(df)。
df.loc[:,'D']=np.array([5]*len(df))
print(df)
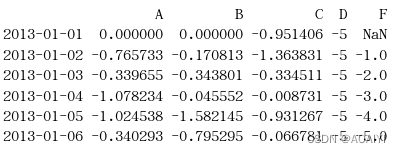
4.使用copy方法将df赋值给df2,使用where语句将df2中满足df2>0条件的值修改为-df2。
df2=df.copy()
df2[df2>0]=-df2
print(df2)
2.缺失值
1.使用reindex方法将df的行列索引同时重新索引,使行index=date[0:4],列索引culumns=list(df.columns+[‘E’]),并返回一个新的数据帧df1,然后使用loc方法将df1中行索引为dates[0]和dates[1],列为“E"的值修改为1。
df1=df.reindex(index=dates[0:4],columns=list(df.columns)+['E'])
print(df1)
df1.loc[dates[0]:dates[1],'E']=1
print(df1)
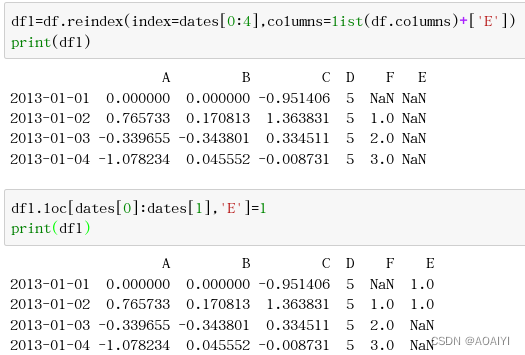
2.使用dropna方法删除df1中任何包含缺失值的行。
df1.dropna(how='any')

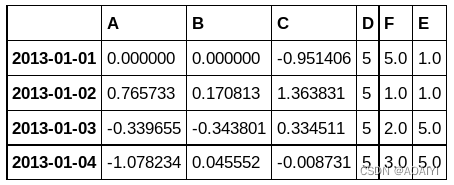
3.使用fillna方法,将df1中所有的缺失值用5填充。
print(df1)
df1.fillna(value=5)
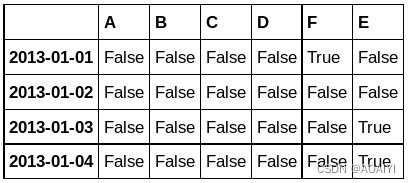
4.使用isnull方法判断df1中的值是否为缺失值,是缺失值返回True,否则返回False,返回一个由布尔值组成的数据帧。
pd.isnull(df1)
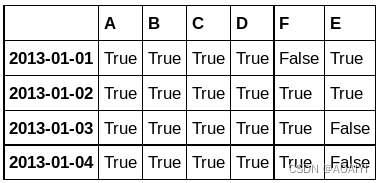
5.使用notnull判断df1中的值是否为缺失值,返回一个由布尔值组成的数据帧。
pd.notnull(df1)
3.合并
1.concat合并
1.创建数据帧df1、df2、df3,使用concat函数将df1\df2\df3进行合并。
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']},index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],'B': ['B4', 'B5', 'B6', 'B7'],'C': ['C4', 'C5', 'C6', 'C7'],'D': ['D4', 'D5', 'D6', 'D7']},index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],'B': ['B8', 'B9', 'B10', 'B11'],'C': ['C8', 'C9', 'C10', 'C11'],'D': ['D8', 'D9', 'D10', 'D11']},index=[8, 9, 10, 11])
result = pd.concat([df1,df2,df3])
print('df1:\n',df1,'\ndf2:\n',df2,'\ndf3:\n','\nresult:\n',result)
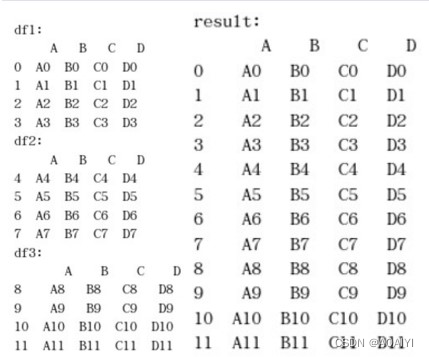
2.将df1,df2,df3进行合并,并将合并后的数据帧进行分区为keys=[‘x’,‘y’,‘z’]。
result1 = pd.concat([df1,df2,df3], keys=['x', 'y', 'z'])
print(result1)

3.新建一个数据帧df4,将df1与df4进行列项合并,axis=1。
df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],'D': ['D2', 'D3', 'D6', 'D7'],'F': ['F2', 'F3', 'F6', 'F7']},index=[2, 3, 6, 7])
result2=pd.concat([df1,df4],axis=1)
print(result2)
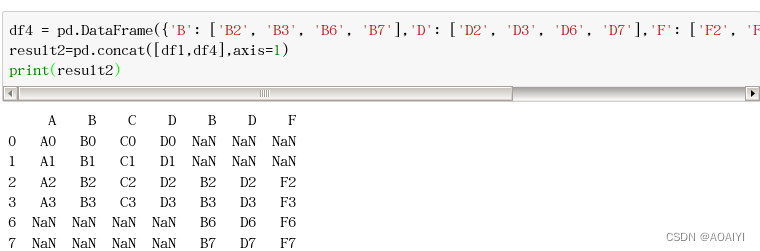
4.df1与df4进行列项合并axis=1,合并方式为内部合并join=‘inner’。
result3=pd.concat([df1,df4],axis=1,join='inner')
print(result3)

2.使用append方法合并
1.使用append方法将df1与df2合并。
df1.append(df2)
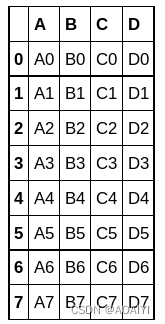
2.使用append方法将df1与df4合并。
df1.append(df4)
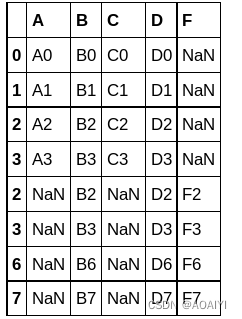
3…使用append方法将df1与df2、df3合并。
df1.append([df2,df3])
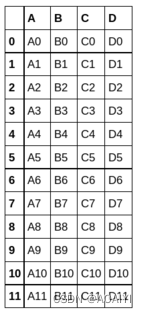
3.使用merge进行合并
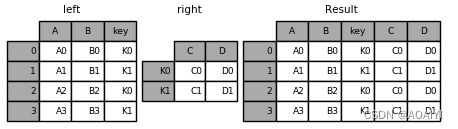
1.创建两个数据帧left、right,使用merge函数按key列将left与right进行连接。
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on='key')
print( left,right,result)
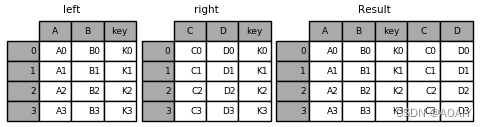
2.复合key的合并方法,使用merge的时候可以选择多个key作为复合可以来对齐合并。
创建两个数据帧left、right,使用merge函数按[key1,key2]列将left与right进行连接。
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K0', 'K1'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],'key2': ['K0', 'K0', 'K0', 'K0'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on=['key1', 'key2'])
print( left,right,result)
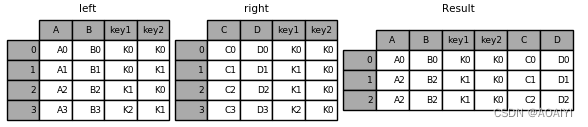
3.使用merge函数按[key1,key2]列将left与right进行左表连接。
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K0', 'K1'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],'key2': ['K0', 'K0', 'K0', 'K0'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
print( left,right,result)
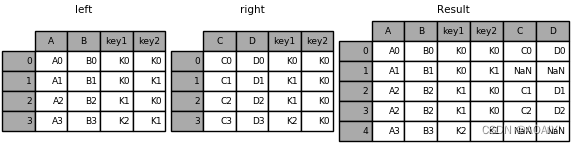
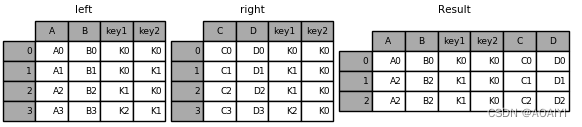
4.使用merge函数按[key1,key2]列将left与right进行右表连接。
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
print(result)
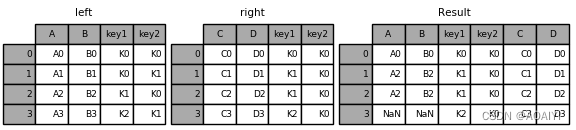
5.使用merge函数按[key1,key2]列将left与right进行外表连接。
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
print(result)
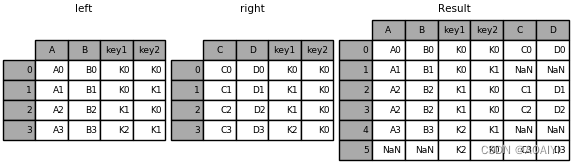
6.使用merge函数按key1,key2列将left与right进行内表连接。
result = pd.merge(left, right, how='inner', on=['key1', 'key2'])
print(result)
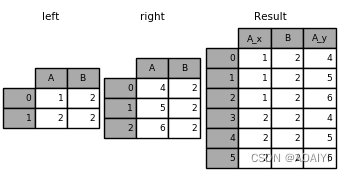
7.创建两个都只有A、B两列的数据帧left,right,使用merge函数按B列将left与right进行外表连接,可以看到除连接列B以外的列名相同时,会在列名后加上区分的后缀。
left = pd.DataFrame({'A' : [1,2], 'B' : [2, 2]})
right = pd.DataFrame({'A' : [4,5,6], 'B': [2,2,2]})
result = pd.merge(left, right, on='B', how='outer')
print(result)
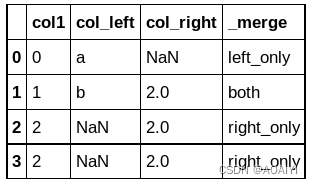
8.创建两个数据帧df1、df2,使用merge函数按col1列将df1与df2进行外表连接,并使用参数indicator显示出每列值在合并列中是否出现。
df1 = pd.DataFrame({'col1': [0, 1], 'col_left':['a', 'b']})
df2 = pd.DataFrame({'col1': [1, 2, 2],'col_right':[2, 2, 2]})
pd.merge(df1, df2, on='col1', how='outer', indicator=True)
4.使用join进行连接
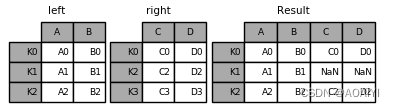
1.创建两个数据帧left、right,使用join方法将left与right连接。
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],'B': ['B0', 'B1', 'B2']},index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],'D': ['D0', 'D2', 'D3']},index=['K0', 'K2', 'K3'])
result = left.join(right)
print(left,'\n',right,'\n',result)
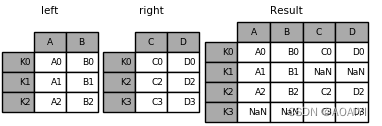
2.使用join方法将left与right进行外表连接
result = left.join(right, how='outer')
print(left,'\n',right,'\n',result)
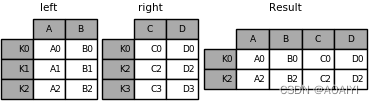
3.使用join方法将left与right进行内表连接.
result = left.join(right, how='inner')
print(left,'\n',right,'\n',result)
4.创建两个数据帧left、right,使用join方法按key列将left与right连接。
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3'], 'key': ['K0', 'K1', 'K0', 'K1']})
right = pd.DataFrame({'C': ['C0', 'C1'],'D': ['D0', 'D1']},index=['K0', 'K1'])
result = left.join(right, on='key')
print(left,'\n',right,'\n',result)
相关文章:
pandas——DataFrame基本操作(二)【建议收藏】
pandas——DataFrame基本操作(二) 文章目录pandas——DataFrame基本操作(二)一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤1.修改数据2.缺失值3.合并1.concat合并2.使用append方法合并3.使用merge进行合并4.使用…...

PostgreSQL查询引擎——General Expressions Grammar之restricted expression
General expressions语法规则定义在src/backend/parser/gram.y文件中,其是表达式语法的核心。有两种表达式类型:a_expr是不受限制的类型,b_expr是必须在某些地方使用的子集,以避免移位/减少冲突。例如,我们不能将BETWE…...

从某种程度上来看,产业互联网是一次对于互联网的弥补和修正
如果对当下我们正在经历的这样一个时代进行一次定义的话,我更加愿意将其划归到产业互联网的范畴里。可能有人会说,这与产业互联网并无联系,因为从本质上来看,当下我们所经历的这样一个时代,其实是与互联网并没有太多联…...

【C#Unity题】1.委托和事件在使用上的区别是什么?2.C#中 == 和 Equals 的区别是什么?
1.委托和事件在使用上的区别是什么? 委托和事件是C#中的重要概念,通俗来讲,委托是一个可以指向特定方法的指针,可以将委托分配给不同的脚本,使它们能够完成不同的任务。而事件则是一种使用委托实现的通知机制ÿ…...

FFmpeg5.0源码阅读——内存池AVBufferPool
摘要:FFmpeg中大多数数据存储比如AVFrame,AVPacket都是通过AVBufferRef管理的,而承载数据的结构为AVBuffer。本文主要通过FFmpeg源码来分析下FFmpeg中AVBuffer相关的实现。 关键字:AVBuffer、AVBufferPool、AVBufferPool 1. AVBufferRef 1.…...

Python学习------起步7(字符串的连接、删除、修改、查询与统计、类型判断及字符串字母大小写转换)
目录 前言: 1.字符串的连接 join() 函数 2.字符串的删除&取代 replace()函数 3.字符串的修改&切割 (1)strip() 函数 (2)lstrip()函数 和 rstrip()函数 (3)split()函数-->…...
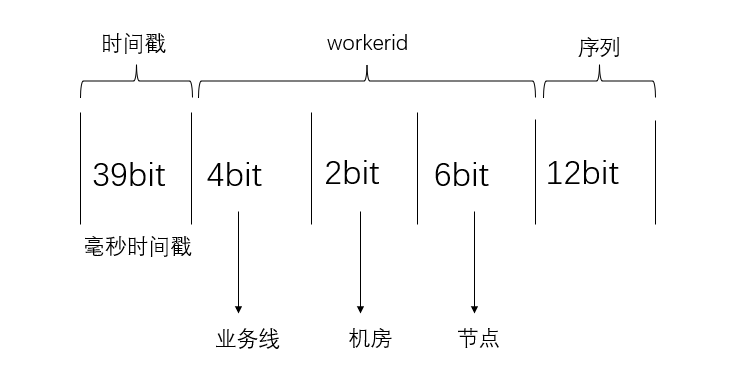
雪花算法snowflake
snowflake中文的意思是 雪花,雪片,所以翻译成雪花算法。它最早是twitter内部使用的分布式环境下的唯一ID生成算法。在2014年开源。雪花算法产生的背景当然是twitter高并发环境下对唯一ID生成的需求,得益于twitter内部高超的技术,雪…...

Part 4 描述性统计分析(占比 10%)——上
文章目录【后续会持续更新CDA Level I&II备考相关内容,敬请期待】【考试大纲】【考试内容】【备考资料】1、统计基本概念1.1、统计学的含义及应用1.1.1、统计学的含义1.2.1、统计学的应用1.2、统计学的基本概念1.2.1、数据及数据的分类1.2.2、总体和样本1.2.3、…...
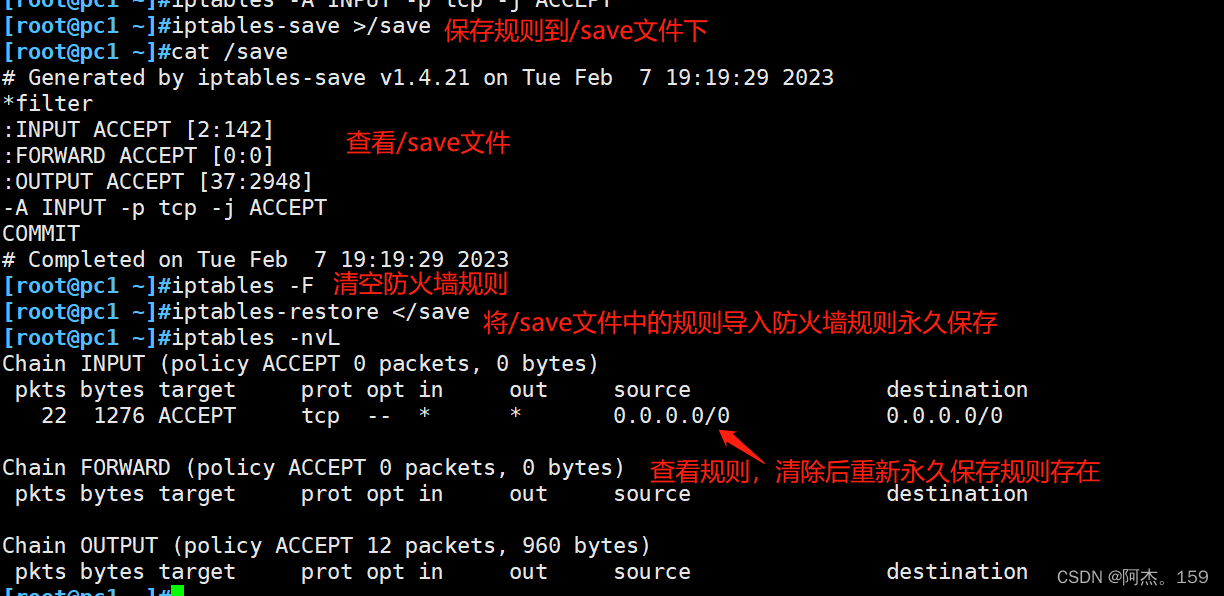
Linux系统安全:安全技术和防火墙
目录 一、安全技术 1、安全技术 2、防火墙分类 二、防火墙 1、iptables五表五链 2、黑白名单 3、iptables基本语法 4、iptables选项 5、控制类型 6、隐藏扩展模块 7、显示扩展模块 8、iptables规则保存 9、自定义链使用 一、安全技术 1、安全技术 ①入侵检测系统…...

【干货】Python:turtle库的用法
【干货】Python:turtle库的用法1. turtle库概述2. turtle库与基本绘图2.1 导入库的三种方式2.1.12.1.22.1.32.2 窗体函数2.2 画笔状态函数2.2.1 seed(s)2.2.2 random()2.2.3 randint(a, b)2.2.4 getrandbits(k)2.2.5 randrange(start, stop[ , step])2.2.6 uniform(…...

信息安全与网络安全有什么区别?
生活中我们经常会听到要保障自己的或者企业的信息安全。那到底什么是信息安全呢?信息安全包含哪些内容?与网络安全又有什么区别呢?今天我们就一起来详细了解一下。什么叫做信息安全?信息安全定义如下:为数据处理系统建…...

花了5年时间,用过市面上95%的工具,终于找到这款万能报表工具
经常有粉丝问我有“哪个报表工具好用易上手?”或者是“有哪些适合绝大多数普通职场人的万能报表工具?” 从这里我大概总结出了大家选择报表工具最期望满足的3点: (1)简单易上手:也就是所谓的学习门槛要低…...

ESP32S3系列--SPI主机驱动详解(一)
一、目的SPI是一种串行同步接口,可用于与外围设备进行通信。ESP32S3自带4个SPI控制器外设,其中SPI0/SPI1内部专用,共用一组信号线,通过一个仲裁器访问外部Flash和PSRAM;SPI2/3各自使用一组信号线;开发者可以使用SPI2/3控制外部SPI…...

2023开工开学火热!远行的人们,把淘特箱包送上顶流
春暖花开,被疫情偷走的三年在今年开学季找补回来了。多个数据反馈,居民消费意愿大幅提升。在淘特上,开工开学节点就很是明显:1月30日以来,淘特箱包品类甚至远超2022年双11,成为开年“第一爆品”。与此同时&…...
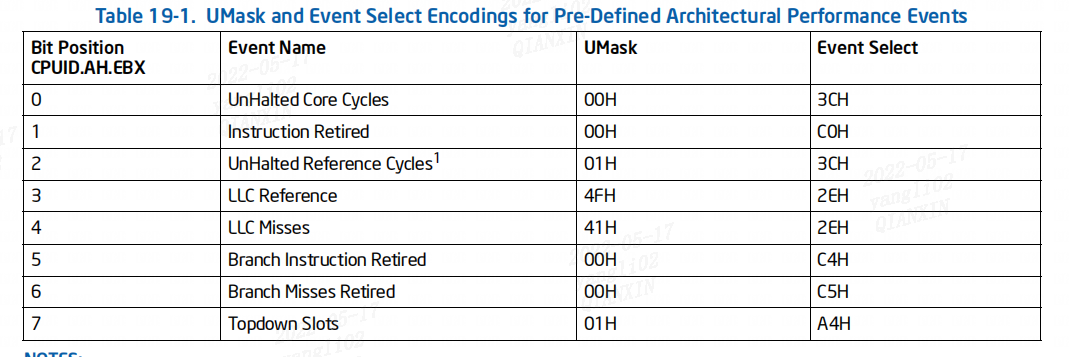
Intel x86_64 PMU简介
文章目录前言一、性能监控概述二、CPUID information三、架构性能监控3.1 架构性能监控 Version 13.1.1 架构性能监控 Version 1 Facilities3.1.2 预定义的体系结构性能事件3.1.3 cmask demo测试参考资料前言 Intel 64 和 IA-32 架构提供了 PMU(Performance Monito…...
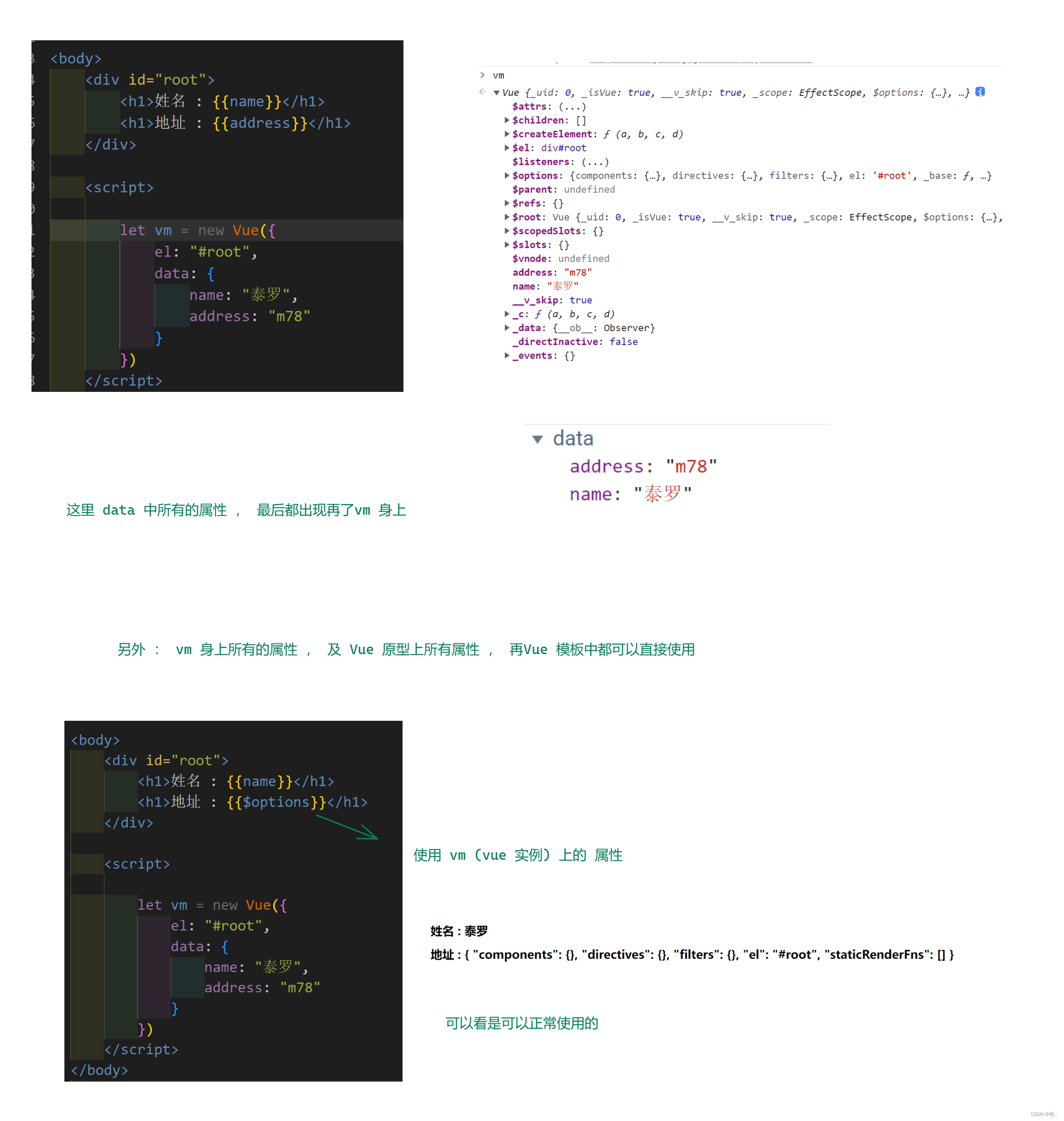
Vue (2)
文章目录1. 模板语法1.1 插值语法1.2 指令语法2. 数据绑定3. 穿插 el 和 data 的两种写法4. MVVM 模型1. 模板语法 root 容器中的代码称为 vue 模板 1.1 插值语法 1.2 指令语法 图一 : 简写 : v-bind: 是可以简写成 : 的 总结 : …...

ESP8266 + STC15基于AT指令通过TCP通讯协议获取时间
ESP8266 + STC15基于AT指令通过TCP通讯协议获取时间 如果纯粹拿32位的ESP8266模块给8位的单片机仅供授时工具使用,有点大材小用了。这里不讨论这个拿esp8266来单独开发使用。本案例只是通过学习esp8266 AT指令功能来验证方案的可行性。 🔖STC15 单片机采用的是:STC15F2K60S…...

谈谈Spring中Bean的生命周期?(让你瞬间通透~)
目录 1.Bean的生命周期 1.1、概括 1.2、图解 2、代码示例 2.1、初始化代码 2.2、初始化的前置方法和后置方法(重写) 2.3、Spring启动类 2.4、执行结果 2.5、经典面试问题 3.总结 1.Bean的生命周期 1.1、概括 Spring中Bean的生命周期就是Bean在…...
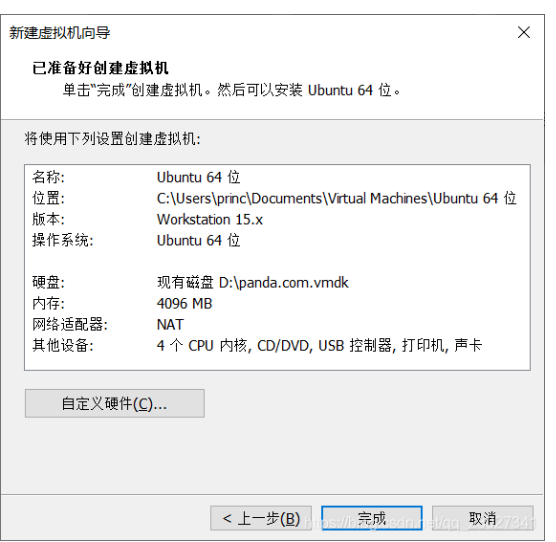
如何将VirtualBox虚拟机转换到VMware中
转换前的准备 首先需要你找到你的virtualbox以及VM安装到哪个文件夹里了,需要将这两个文件夹添加进环境变量Path中。 如果你记不清了,可以用everything全局搜索一下“VBoxManage.exe’以及“vmware-vdiskmanager.exe”,看一眼这个程序放到哪…...
)
洞庭龙梦(开发技巧和结构理论集)
1、经验来源,单一获取方式。进行形态等级展示。唯一游戏系统经验来源。无主线和支线剧情。2、玩家使用流通货币(充值货币),到玩家空间商城充值游戏,两人以上玩家进行游戏,掉落道具。交易系统游戏玩法&#…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

(一)单例模式
一、前言 单例模式属于六大创建型模式,即在软件设计过程中,主要关注创建对象的结果,并不关心创建对象的过程及细节。创建型设计模式将类对象的实例化过程进行抽象化接口设计,从而隐藏了类对象的实例是如何被创建的,封装了软件系统使用的具体对象类型。 六大创建型模式包括…...
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...