Redis学习笔记:缓存运用常见问题
这是本人学习的总结,主要学习资料如下
- 马士兵教育
目录
- 1、数据一致性的问题
- 1.1、新增数据一致性的问题
- 1.2、修改/删除一致性问题
- 1.2.1、操作分析
- 1.2.1、总结和再深入
- 2、缓存穿透,缓存击穿和缓存雪崩
- 2.1、缓存穿透(查不到)
- 2.1.1、 解决方式
- 2.2、缓存击穿(过期没找到)
- 2.2.1、解决方法
- 2.3、缓存雪崩
- 2.3.1、解决方式
- 3、数据倾斜
- 3.1、热点key
- 3.1.1、什么是热点key
- 3.1.2、发现热点key
- 3.1.3、解决热点Key
- 3.2、bigKey
- 3.2.1、什么是bigKey
- 3.2.2、发现热点key
- 3.2.3、解决bigKey
1、数据一致性的问题
1.1、新增数据一致性的问题
所谓新增数据一致性的问题就是,新增数据时,缓存和数据库都要存数据,有一方失败一方成功导致的数据不一致的问题。
这种情况一般不用担心,如果真的很担心那可以在存数据前加一个消息中间件,让缓存和数据库消费这个中间件。因为中间件消费失败了会多次尝试,这就可以解决不一致的问题。

1.2、修改/删除一致性问题
1.2.1、操作分析
在涉及到缓存和数据库的修改和删除时,根据操作先后也就分为四种情况。
- 先更新缓存,后更新数据库。
- 先删除缓存,后更新数据库。
- 先更新数据库,后更新缓存。
- 先更新数据库,后删除缓存。
下面就逐一分析其可行性。
- 先更新缓存, 后更新数据库。
线程A和线程B并发更新数据,线程A先更新,线程B后更新。按照预期,因为线程B后更新那么最后结果应该以线程B的为准。
但如果线程A更新缓存后,还没来得及更新数据库时,线程B就把缓存和数据库更新好了,之后线程A才继续更新数据库,那这时候就出现缓存是最新数据而数据库是旧数据的情况,缓存不一致出现。
下图是流程图,左边是正常情况,右边是不一致的情况。

- 先删除缓存, 后更新数据库
线程A删除缓存后,还没来得及更新数据库时,线程B查询数据。
一般线程B现在缓存查数据,查不到,转而查数据库,但这时线程A还没更新好,于是线程B拿到的是旧数据。
现成B拿到旧数据后会顺便把旧数据更新到缓存中,于是现在就出现数据库时新数据,而缓存是旧数据的不一致。

-
更新数据库,后更新缓存
线程A和线程B并发更新数据,线程A先更新,线程B后更新。按照预期,因为线程B后更新那么最后结果应该以线程B的为准。
但如果线程A更新数据库后还没来得及更新缓存,线程B已经更新了数据库和缓存,那么现在数据库就是数据库是最新数据,而缓存是旧数据的不一致情况。

-
先更新数据库,后删除缓存
特殊情况就是,在线程A更新数据库之前,线程B来查数据,并且缓存因为各种原因正好没数据,所以B就去数据库查数据。
这里B拿到的是旧数据,之后A更新数据库完成,B就拿着旧数据回填到缓存中。但是A会删除缓存,这样别的线程再来查数据就会因为缓存没数据去数据库拿最新的数据回填到缓存中。这样就避免了数据不一致的情况。并且为了防止线程B拿到数据库旧数据后,在线程A第二次删缓存后才将旧数据回填到缓存造成数据库是新数据,缓存是旧数据的不一致,线程A更新完数据库后还睡眠一段时间,然后才删除缓存。这样就能保证第二次删除缓存发生在在线程B插入缓存之后。

教程里提到需要延迟双删,即在这个基础上,在线程A更新数据库前也删除一次缓存,加上更新后的删除,总共两次删除,所以叫延迟双删。
不过我自己觉得第一次删除没必要,似乎只有后一次删除也能避免数据不一致。
1.2.1、总结和再深入
所以面对修改/删除的一致性问题,最好的方法是先更新数据库,后删除缓存,并且有需要的话可以延时删除缓存。
还有两种加强的方式,都是在延时这里做文章。
第一种是线程A更新数据库以后将删除缓存的操作放到延迟消息队列中,这样可以避免缓存删除失败的风险,同时也让线程A更新完数据库后不必再睡眠,可以抽身做其他的事。这种方式唯一的缺点是增加了系统的复杂度。
另一种方式是数据库插入后会更新一种叫binlog的东西,我们让一个线程订阅binlog的发布,然后消费发布信息删除缓存。这种方式的缺点是获取binlog会引起I/O,效率不是很高。
2、缓存穿透,缓存击穿和缓存雪崩
2.1、缓存穿透(查不到)
一般的模型当中,一次查询会优先到redis中查询,如果没有查询到才进行mysql查询。但如果mysql中也没有对应数据,那这两次查询就无功而返。

一般情况下以上查询没什么问题。但在高并发的场景下,如果有大量请求想查询同一字段,而这一字段又不存在,那就会在短时间内进行大量的mysql查询,造成数据库崩溃,这就是缓存穿透。
2.1.1、 解决方式
-
第一种是设空值。在
redis中设空值,第一次在数据库中没查到数据就设一个空值在redis。这样的相同查询就在redis中查到空值就返回结束,不用麻烦数据库。等到以后真正有了值,数据库会更新到缓存中。
-
布隆过滤器。布隆过滤器可以快速判定一个元素不在集合中。如果在查询前加入布隆过滤器,布隆过滤器里的数据和数据库同步。当查询查不存在的元素布隆过滤器直接处理,不用麻烦到数据库和缓存。

2.2、缓存击穿(过期没找到)
redis缓存中设置的值总是有过期时间,如果有一个超热点在失效的那一刻迎来了大量的请求,这些请求发现redis里没有数据,就会转到mysql中查询。
数据从mysql中取出,重新存到redis中有个时间差,在这个时间差内的所有请求都会查询mysql,那mysql就有可能承受不住压力崩溃。这就是缓存击穿。
2.2.1、解决方法
缓存击穿的核心问题是查数据库返回值设到redis中有时间差,这段时间对同一个值有大量查询。
那我们可以给关于这个值的查询加一个锁,只要有一个线程去查询数据库就够了。伪代码如下。
public String getValue(String key) {String value = redis.get(key);//为空则需要加锁查询if(value == null) {// 如果返回1,则成功获取锁if(redis.setnx(hash(key), 60) == 1) {String value = db.getValue(key);redis.set(key, value);return value;} else {// 不成功则休眠一段时间再获取值试试Thread.sleep(60);return getValue(key);}} else{return value;}
}
2.3、缓存雪崩
指某一时间段内,缓存集中过期,或者redis宕机,大量请求在redis中得到不到数据就转向数据库中查询,导致数据库崩溃。
2.3.1、解决方式
第一当然是依靠集群哨兵的故障恢复,一个节点挂了,就需要故障恢复启用其他节点接替工作。
另外还有下面几种做法。
- 避免设置统一过期时间。缓存的过期时间不要太集中。
- 功能降级。比如双十一期间一些不重要的功能可以暂停,避免查询过多。
3、数据倾斜
3.1、热点key
3.1.1、什么是热点key
比如微博里经常出现一些热点事件,明星结婚之类的,导致微博突然崩溃。
这是因为大厂往往用redis的集群作缓存,一个话题就存在一个节点中。一个话题如果过热就引起大量查询,导致某一节点压力突然变大直接崩溃。
这就是热点key导致的数据倾斜。
3.1.2、发现热点key
一般有四个方法,每个方法都不完美,只能根据实际情况甄选。
他们分别是客户端监控,monitor,hotkeys和TCP抓包。
- 第一个是在客户端监控每一个
key,查询一次就+1,如果查询一定时间内超过一定的阈值就上报或者其他处理。
这种方式实现很简单,缺点也很明显,就是代码侵入性,客户端的代码不得不增加不应该有的内容,而且监控每一个key也是不小的负担。
- 第二个是用
redis命令monitor,输入这个指令后相当于订阅了redis的一个服务,当有命令执行时就会收到命令的解析。
比如下面的示例。
127.0.0.1:6900> monitor
OK
1677459065.262425 [0 127.0.0.1:54894] "set" "aaaa" "v1"
使用这种方法就意味着需要额外的开销去存储这些日志并解析,数据量大的时候开销就很大。
- 在
4.0.3以后,reids推出了hotKeys命令专门用于统计热点。具体示例如下。
首先先大量读取某一个key,多执行几次set命令即可,然后执行redis-cli --hotkeys命令获取热点。
MacBook-Pro:etc user$ redis-cli --hotkeys# Scanning the entire keyspace to find hot keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).Error: ERR An LFU maxmemory policy is not selected, access frequency not tracked. Please note that when switching between policies at runtime LRU and LFU data will take some time to adjust.
上面是常见的错误,因为redis是基于LFU的内存淘汰策略,所以要先开启策略选项才能使用hotkyes的功能。
127.0.0.1:6379> config set maxmemory-policy volatile-lfu
OK
然后可以使用hotkeys命令了,可以看到,它统计出k1这个key短时间内有6次查询。
MacBook-Pro:etc user$ redis-cli --hotkeys# Scanning the entire keyspace to find hot keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).[00.00%] Hot key 'k1' found so far with counter 6-------- summary -------Sampled 3 keys in the keyspace!
hot key found with counter: 6 keyname: k1
这个方法的问题是,hotkeys是一个全局命令,他需要扫描所有的key,这同样是个不小的开销。
- 最后一种方法比较高级,就是抓
reids的TCP的包然后解析。常用的插件是ELK packetbeat,这个的麻烦点是维护成本高,且有丢包的风险
3.1.3、解决热点Key
- 使用二级缓存,比如
Guava-cache,hcache,JVM对象内存等。将热点数据存到内存中,这样就不用访问redis,减轻redis的压力。 key分散。我们的key可以分成很多子key,当然子key不是乱命名的。这些子key需要均匀地落到集群的每一个节点,这样热点数据存储压力就分散了。
3.2、bigKey
3.2.1、什么是bigKey
bigKey是指单个key车占用的存储空间过大。String类型的一般是value过大,一般超过10kb就算bigKey了。
非String类型的就是集合,Hash,列表。他们的大体现在里面的元素过多。
他们的危害也比较明显,体积过大让存取都消耗较大 ,无论是空间复杂度还是时间复杂度都不友好。
- 造成单节点内存空间使用不均匀。
Redis执行命令时,遇到该类型的key耗时较多。- 网络传输这种key容易造成拥堵。
3.2.2、发现热点key
redis自带命令:我们先设一个比较大的值
127.0.0.1:6379> set k1 dfnoqihudygouvhqihbghdsuygqfhsdgoiuqgt7687uhvit6871ygh2bdyf71tuidgbhgsft7681ghb23ysdf687iu1gb2jhodgyt67879u1bjdhuog8f6712uh3bnkhguoidt78f61723hbnkgdoyv8t7982uh3nbjhulos867tfy892u3hjbjlhoua78ft2e
OK
然后可以使用redis自带的命令redis-cli --bigkeys。
MacBook-Pro:etc $ redis-cli --bigkeys# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).[00.00%] Biggest string found so far 'k2' with 2 bytes
[00.00%] Biggest string found so far 'name' with 3 bytes
[00.00%] Biggest string found so far 'k1' with 194 bytes-------- summary -------Sampled 3 keys in the keyspace!
Total key length in bytes is 8 (avg len 2.67)Biggest string found 'k1' has 194 bytes0 lists with 0 items (00.00% of keys, avg size 0.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
3 strings with 199 bytes (100.00% of keys, avg size 66.33)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)这种方式是全局命令,在有大量key的生产环境需要谨慎使用。
- 使用
debug命令:使用debug object k1可以得到k1这个单个key的信息。那么我们就可以一批一批地过一遍所有的key找到bigkey。
127.0.0.1:6379> debug object k1
Value at:0x600002554020 refcount:1 encoding:raw serializedlength:196 lru:10373635 lru_seconds_idle:6214367
关于遍历这个命令,遍历的操作可以使用scan命令来完成。
scan cursor [MATCH pattern] [COUNT count] , 可以像分页一样地一页一页的遍历所有元素。这种遍历方式不一定能完全遍历所有的key,当遍历时有新数据插入就可能遍历不到。不过能遍历到绝大部分的元素,用来寻找bigKey还是很可靠的。
scan,关键字。cursor,下标,可以理解成元素的下标,访问第一页的元素时cursor=0。[MATCH match],可以省略,通配符匹配。[COUNT count],每页返回的元素个数。这个不能保证每页都返回这个数目,只能保证尽量接近。
下面是例子 ,总共遍历30个元素。方法的第一个返回值是下一页元素的下标,范围下一页时cursor要等于这个值。第二个返回值才是这一页的key。scan是循环遍历,遍历到最后一页下一页就是第一页。
127.0.0.1:6379> scan 0 count 10
1) "26"
2) 1) "k19"2) "k2"3) "k5"4) "k11"5) "k13"6) "k3"7) "k10"8) "k30"9) "k26"10) "k24"
127.0.0.1:6379> scan 26 count 10
1) "3"
2) 1) "k23"2) "k20"3) "k1"4) "k28"5) "k25"6) "k9"7) "k8"8) "k12"9) "k14"10) "k22"11) "k18"12) "k16"
127.0.0.1:6379> scan 3 count 10
1) "0"
2) 1) "k27"2) "k29"3) "k4"4) "k15"5) "k21"6) "k6"7) "k17"8) "k7"
3.2.3、解决bigKey
拆分,将bigkey拆分成多个子Key,使这些子Key均匀地分布到各个子节点。
相关文章:
Redis学习笔记:缓存运用常见问题
这是本人学习的总结,主要学习资料如下 马士兵教育 目录1、数据一致性的问题1.1、新增数据一致性的问题1.2、修改/删除一致性问题1.2.1、操作分析1.2.1、总结和再深入2、缓存穿透,缓存击穿和缓存雪崩2.1、缓存穿透(查不到)2.1.1、…...

使用python 脚本挑出coco 数据集中的某一类数据
文章大纲 简介代码样例制作一个走路玩手机数据集简介 MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。 COCO数据集是一个大型的、丰富的物…...
Python虚拟环境(pipenv、venv、conda一网打尽)[通俗易懂]
一、什么是虚拟环境 1. 什么是Python环境 要搞清楚什么是虚拟环境,首先要清楚Python的环境指的是什么。当我们在执行python test.py时,思考如下问题: python哪里来?这个主要归功于配置的系统环境变量PATH,当我们在命…...
Android Kotlin实战之高阶使用泛型扩展协程懒加载详解
前言: 通过前面几篇文章,我们已基本掌握kotlin的基本写法与使用,但是在开发过程中,以及一些开源的API还是会出现大家模式的高阶玩法以及问题,如何避免,接下来讲解针对原来的文章进行一些扩展,解…...

数字映射:数字孪生技术的应用场景及作用
对于许多行业来说,数字孪生技术是未来。数字孪生定义数字孪生不仅仅是某物的副本或克隆,它是对象或系统的动态实时表示。数字孪生是一种虚拟模型,旨在准确反映物理对象。是物理对象、流程、服务或环境的数字表示,其行为和外观与现…...
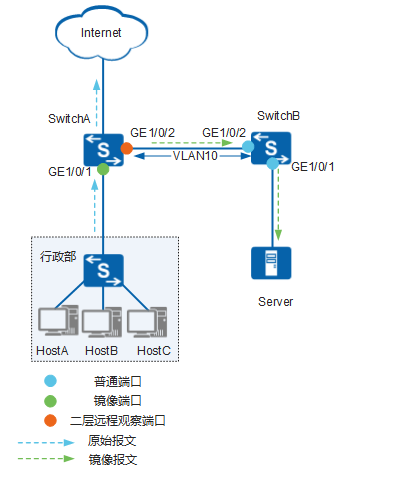
配置二层远程端口镜像案例
实验拓扑: 实验需求: 如图1所示,某公司行政部通过SwitchA与外部Internet通信,监控设备Server通过SwitchB与SwitchA相连。 现在希望Server能够远程对行政部访问Internet的流量进行监控。 操作步骤: 配置观察端口 # 在…...
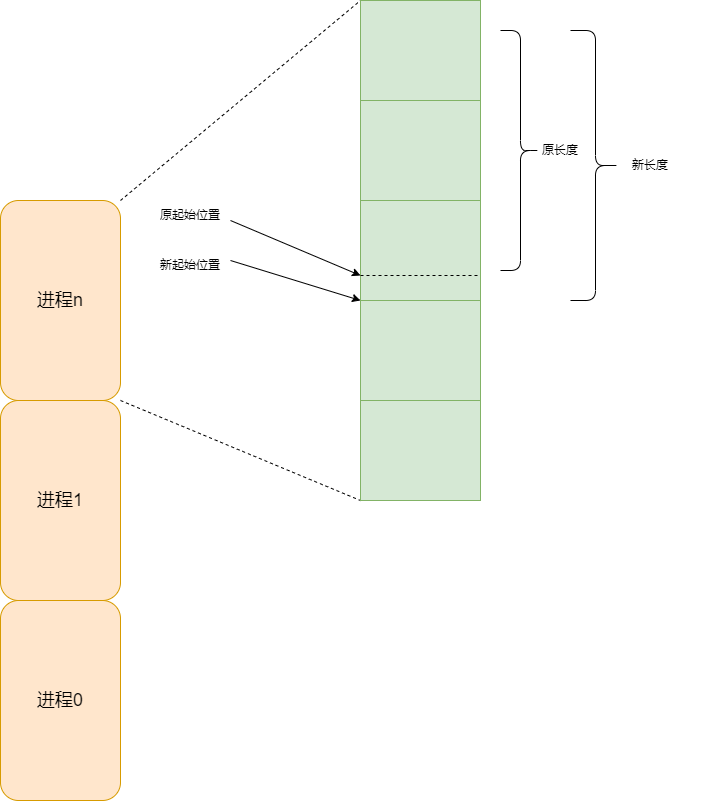
Linux-0.11 kernel目录fork.c详解
Linux-0.11 kernel目录fork.c详解 fork.c中主要实现内核对于创建新的进程的行为。其中copy_process是其最核心的函数。 copy_process int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,long ebx,long ecx,long edx,long fs,long es,long ds,long eip,…...
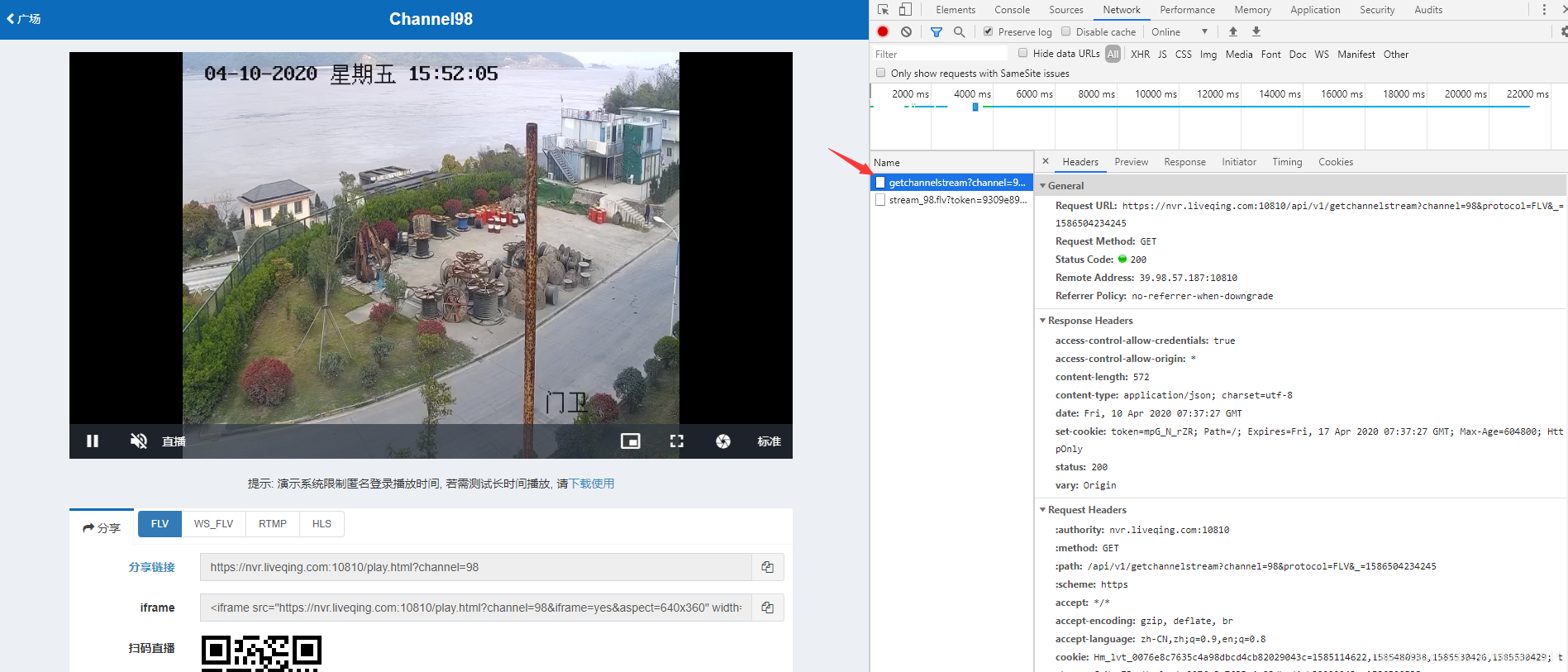
如何或者无插件Web页面监控播放软件LiveNVR的固定视频流地址,实现大屏上墙、播放、视频分析等目的
1、LiveNVR介绍 LiveNVR的安防监控的视频直播,可以按标准的Onvif/RTSP协议接入监控设备,也可以通过海康、大华、天地伟业等厂家私有SDK接入监控,实现web页面的播放和录像回放。 可以分发HTTP-FLV、WS-FLV、WebRTC、RTMP、HLS(M3U8)、RTSP等多…...
)
postman断言脚本(2)
https://learning.postman.com/docs/writing-scripts/script-references/test-examples/#parsing-response-body-data状态码pm.test("Status code is 200",function(){pm.response.to.have.status(200);});pm.test("Status code is 200",()>{pm.expect(…...

js中?.、??的具体用法
1、?. (可选链运算符) 在javascript中如果一个值为null、undefined,直接访问下面的属性, 会报 Uncaught TypeError: Cannot read properties of undefined 异常错误。 而在真实的项目中是会出现这种情况,有这个值就…...
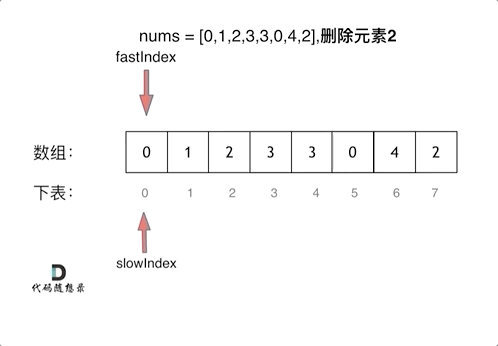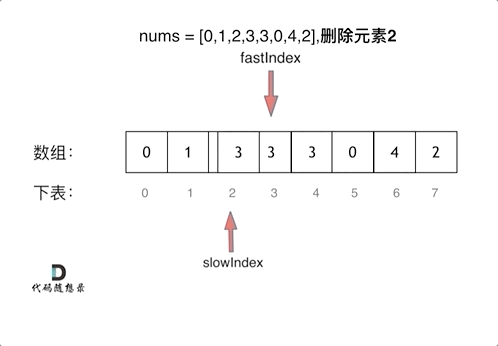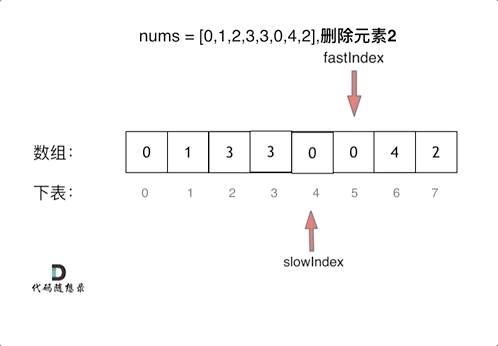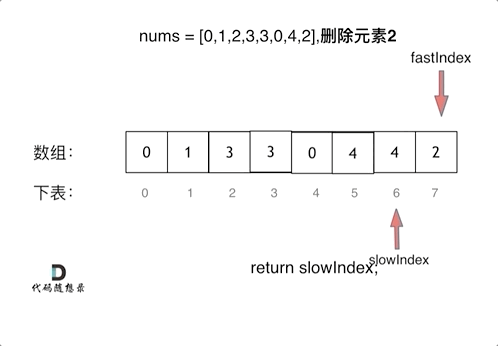
刷题笔记1 | 704. 二分查找,27. 移除元素
704. 二分查找 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。 输入: nums [-1,0,3,5,9,12], target 9 输出: 4 …...

柔性电路板的优点、分类和发展方向
柔性电路板是pcb电路板的一种,又称为软板、柔性印刷电路板,主要是由柔性基材制作而成的一种具有高可靠性、高可挠性的印刷电路板,具有厚度薄、可弯曲、配线密度高、重量轻、灵活度高等特点,主要用在手机、电脑、数码相机、家用电器…...
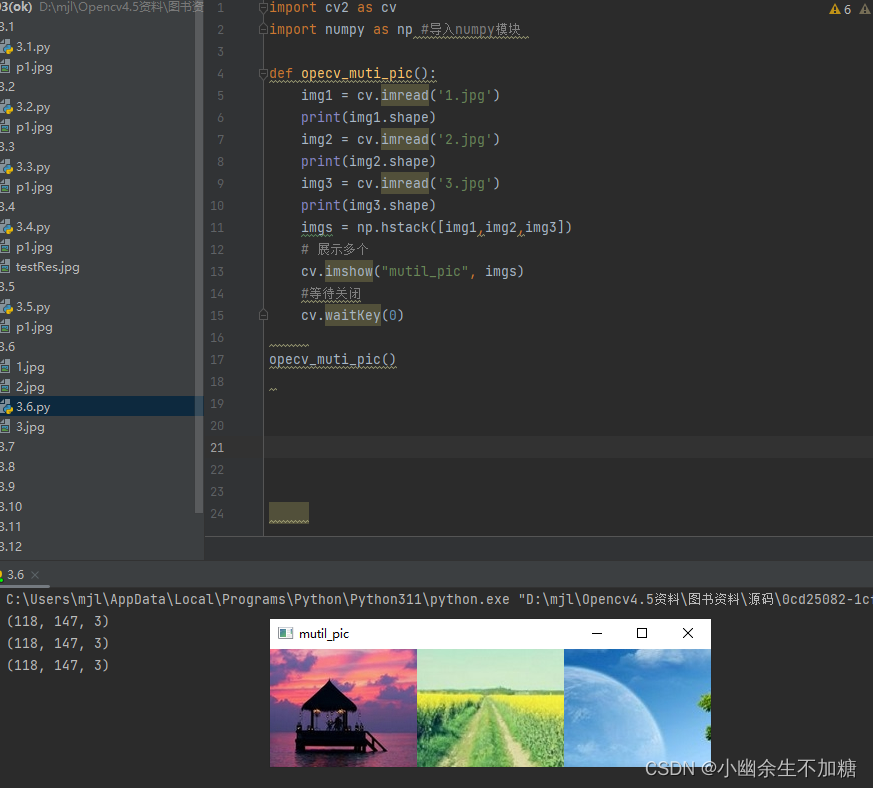
OpenCV入门(二)快速学会OpenCV1图像基本操作
OpenCV入门(一)快速学会OpenCV1图像基本操作 不讲大道理,直接上干货。操作起来。 众所周知,OpenCV 是一个跨平台的计算机视觉库, 支持多语言, 功能强大。今天就从读取图片,显示图片,输出图片信息和简单的…...

Redis源码---有序集合为何能同时支持点查询和范围查询
目录 前言 Sorted Set 基本结构 跳表的设计与实现 跳表数据结构 跳表结点查询 跳表结点层数设置 哈希表和跳表的组合使用 前言 有序集合(Sorted Set)是 Redis 中一种重要的数据类型,它本身是集合类型,同时也可以支持集合中…...
从计费出账加速的设计谈周期性业务的优化思考
1号恐惧症 你有没有这样的做IT的朋友?年纪轻轻,就头发花白或者秃顶,然后每个月周期性的精神不振,一到月底,就有明显的焦虑。如果有,他可能就是运营商行业做计费运营的,请对他好点,特…...

垃圾回收的概念与算法(第四章)
《实战Java虚拟机:JVM故障诊断与性能优化 (第2版)》 第4章 垃圾回收的概念与算法 目标: 了解什么是垃圾回收学习几种常用的垃圾回收算法掌握可触及性的概念理解 Stop-The-World(STW) 4.1. 认识垃圾回收 - 内存管理清洁工 垃圾…...

让您的客户了解您的制造过程“VR云看厂实时数字化展示”
一、工厂云考察,成为市场热点虚拟现实(VR)全景技术问世已久,但由于应用范围较为狭窄,一直未得到广泛应用。国外客户无法亲自到访,从而导致考察难、产品取样难等问题,特别是对于大型制造企业来说…...

CV——day80 读论文:DLT-Net:可行驶区域、车道线和交通对象的联合检测
DLT-Net:可行驶区域、车道线和交通对象的联合检测I. INTRODUCTIONII. ANALYSIS OF PERCEPTIONIV. DLT-NETA. EncoderB. Decoder1) Drivable Area Branch(可行驶区域分支)2) Context Tensor(上下文张量)3) Lane Line Branch(车道线分支)4) Traffic Object Branch(目标检测对象分…...
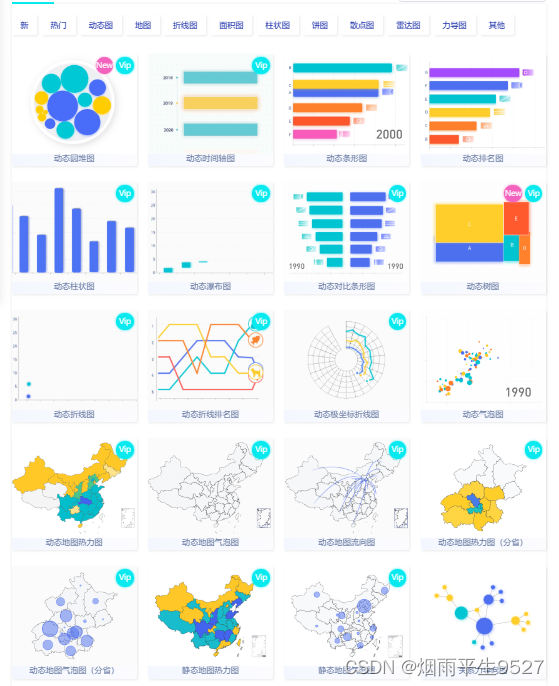
工具篇4.5数据可视化工具大全
1.1 Flourish 数据可视化不仅是一项技术,也是一门艺术。当然,数据可视化的工具也非常多,仅 Python 就有 matplotlib、plotly、seaborn、bokeh 等多种可视化库,我们可以根据自己的需要进行选择。但不是所有的人都擅长写代码完成数…...
)
京东前端二面常考手写面试题(必备)
实现发布-订阅模式 class EventCenter{// 1. 定义事件容器,用来装事件数组let handlers {}// 2. 添加事件方法,参数:事件名 事件方法addEventListener(type, handler) {// 创建新数组容器if (!this.handlers[type]) {this.handlers[type] …...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...