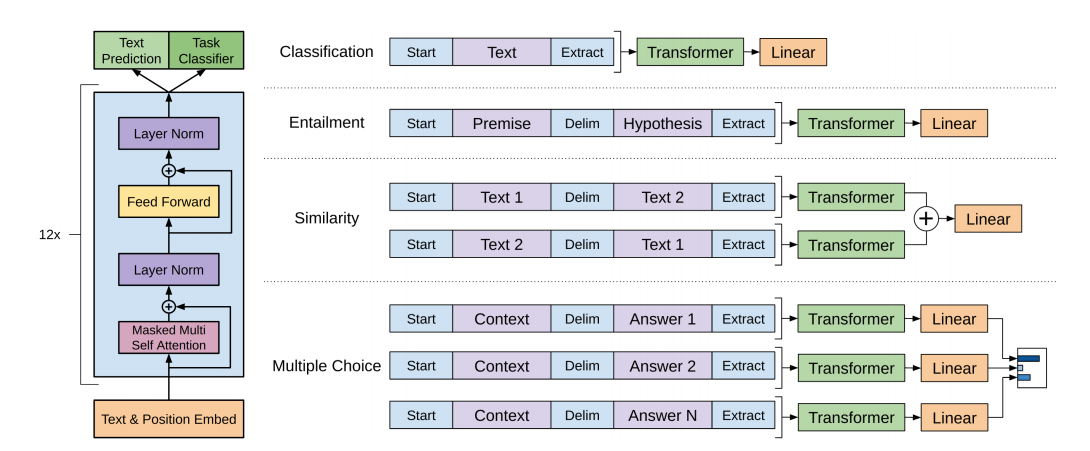
[GPT-1]论文实现:Improving Language Understanding by Generative Pre-Training
Efficient Graph-Based Image Segmentation
- 一、完整代码
- 二、论文解读
- 2.1 GPT架构
- 2.2 GPT的训练方式
- Unsupervised pre_training
- Supervised fine_training
- 三、过程实现
- 3.1 导包
- 3.2 数据处理
- 3.3 模型构建
- 3.4 模型配置
- 四、整体总结
论文:Improving Language Understanding by Generative Pre-Training
作者:Alec Radford,Karthik Narasimhan,Tim Salimans,Ilya Sutskever
时间:2018
一、完整代码
这里我们使用tensorflow代码进行实现
# 完整代码在这里
import tensorflow as tf
import keras_nlp
import jsondef get_merges():with open('./data/GPT_merges.txt') as f:merges = f.read().split('\n')return mergesmerges = get_merges()
vocabulary = json.load(open('./data/GPT_vocab.json'))tokenizer = keras_nlp.tokenizers.BytePairTokenizer(vocabulary=vocabulary,merges=merges
)pad = tokenizer.vocabulary_size()
start = tokenizer.vocabulary_size() + 1
end = tokenizer.vocabulary_size() + 2corpus = open('./data/shakespeare.txt').read()
data = tokenizer(corpus)
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.batch(63, drop_remainder=True)
def process_data(x):x = tf.concat([tf.constant(start)[tf.newaxis], x, tf.constant(end)[tf.newaxis]], axis=-1)return x[:-1], x[1:]dataset = dataset.map(process_data).batch(16)inputs, outputs = dataset.take(1).get_single_element()class GPT(tf.keras.Model):def __init__(self, vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads, dropout=0.1):super().__init__()self.embedding = keras_nlp.layers.TokenAndPositionEmbedding(vocabulary_size=vocabulary_size,sequence_length=sequence_length,embedding_dim=embedding_dim,)self.lst = [keras_nlp.layers.TransformerDecoder(intermediate_dim=intermediate_dim,num_heads=num_heads,dropout=dropout,) for _ in range(num_layers)]self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, x):decoder_padding_mask = x!= 0 output = self.embedding(x)for item in self.lst:output = item(output, decoder_padding_mask=decoder_padding_mask)output = self.dense(output)return outputvocabulary_size = tokenizer.vocabulary_size() + 3
sequence_length= 64
embedding_dim=512
num_layers=12
intermediate_dim=1024
num_heads=8gpt = GPT(vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads)gpt(inputs)
gpt.summary()def masked_loss(label, pred):mask = label != padloss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none')loss = loss_object(label, pred)mask = tf.cast(mask, dtype=loss.dtype)loss *= maskloss = tf.reduce_sum(loss)/tf.reduce_sum(mask)return lossdef masked_accuracy(label, pred):pred = tf.argmax(pred, axis=2)label = tf.cast(label, pred.dtype)match = label == predmask = label != padmatch = match & maskmatch = tf.cast(match, dtype=tf.float32)mask = tf.cast(mask, dtype=tf.float32)return tf.reduce_sum(match)/tf.reduce_sum(mask)gpt.compile(loss=masked_loss,optimizer='adam',metrics=[masked_accuracy]
)gpt.fit(dataset, epochs=3)
二、论文解读
GPT全称为Generative Pre-Training,即生成式的预训练模型;
2.1 GPT架构
其模型架构非常简单,就是Transformer的decoder修正后的叠加,因为这是文本生成任务,并没有类似于seq2seq翻译模型的对应句子,GPT的处理方式是直接把Transformer中的decoder中的CrossAtention直接删除;
如图所示:蓝色方框部分为Transformer的decoder层,其中红色方框部分为被删除的多头注意力层;
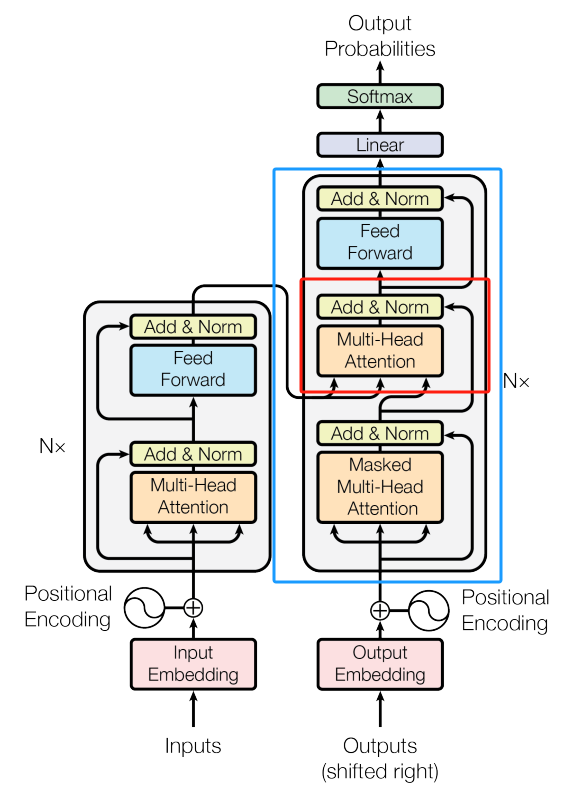
得到的模型如下:
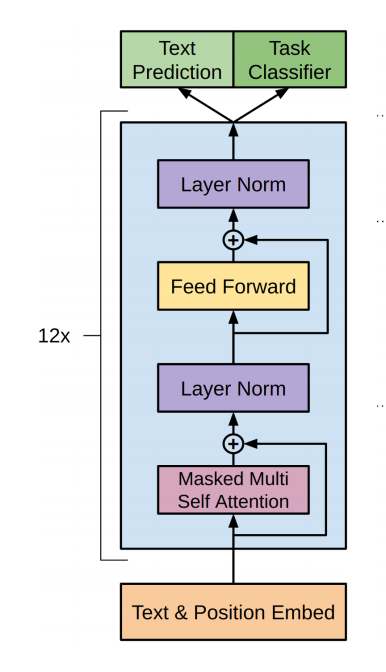
是不是特别简单;
2.2 GPT的训练方式
首先要声明的是GPT采用的是semi-supervised即半监督学习方法,其本质是一个两阶段的训练过程,第一阶段是无监督学习,就是单纯的利用Transformer的decoder来做预测下一个词的任务;第二阶段是有监督学习,利用带标签的语料信息对模型进行训练;
接下来对这两个过程进行详细的分析;
Unsupervised pre_training
原文如图所示:

其根本目的是最大化语言模型的极大似然估计,其本质就是一个链式法则取对数;
L 1 ( u ) = l o g ( P ( u i , u i − 1 , … , u 1 ) ) P ( u i , u i − 1 , … , u 1 ) = P ( u 1 ) ⋅ P ( u 2 ∣ u 1 ) ⋅ P ( u 3 ∣ u 2 , u 1 ) ⋅ ⋅ ⋅ P ( u i ∣ u i − 1 , … , u 1 ) \begin{aligned} & L_1(u) = log(P(u_i,u_{i-1},\dots,u_1)) \\ \\ & P(u_i,u_{i-1},\dots,u_1) = P(u_1)·P(u_2|u_1)·P(u_3|u_2,u_1)···P(u_i|u_{i-1},\dots,u_1) \end{aligned} L1(u)=log(P(ui,ui−1,…,u1))P(ui,ui−1,…,u1)=P(u1)⋅P(u2∣u1)⋅P(u3∣u2,u1)⋅⋅⋅P(ui∣ui−1,…,u1)
而下面计算 P P P 的过程,就是利用 mask 的机制来制造类似于RNN的过程;
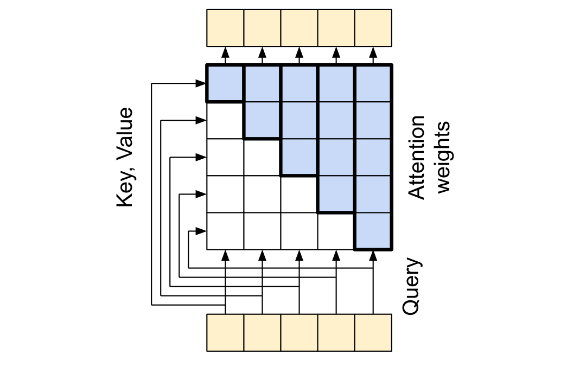
如果对注意力机制不理解的,可以去看一下Attention Is All You Need这篇论文,我也在其他博客中简单介绍了一下;
Supervised fine_training
原文如图所示:

与unsupervised pre_training不同的是,其去掉了最后一层的 W e W_e We换成了一个新的参数 W y W_y Wy,利用新的参数去预测新的标签;这里我的理解是这样的,在unsupervised pre_training中,我们相当于在大炮不停调整弹药量,大炮的对准方向 W e W_e We也在不停的向下一个单词调整;当弹药合理时,方向正确时,我们调整大炮方向去攻打supervised fine_tuning;
这里的目标函数进行了一次正则化处理,避免一味的调整方向而忽略了弹药量;
L 3 ( C ) = L 2 ( C ) + λ L 1 ( C ) L_3(C) = L_2(C) + \lambda L_1(C) L3(C)=L2(C)+λL1(C)
至此,模型的训练就结束了;
三、过程实现
3.1 导包
这里使用tensorflow,keras_nlp和json三个包进行过程实现;
import tensorflow as tf
import keras_nlp
import json
3.2 数据处理
第一部分是无监督训练,我们需要导入一段长文本构建数据集进行训练即可,这里我们使用莎士比亚的作品 storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt;
第二部分是有监督训练,我们可以使用CoLA语料进行文本分类,CoLA语料来自GLUE Benchmark中的The Corpus of Linguistic Acceptability;
def get_merges():with open('./data/GPT_merges.txt') as f:merges = f.read().split('\n')return mergesmerges = get_merges()
vocabulary = json.load(open('./data/GPT_vocab.json'))tokenizer = keras_nlp.tokenizers.BytePairTokenizer(vocabulary=vocabulary,merges=merges
)pad = tokenizer.vocabulary_size()
start = tokenizer.vocabulary_size() + 1
end = tokenizer.vocabulary_size() + 2corpus = open('./data/shakespeare.txt').read()
data = tokenizer(corpus)
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.batch(63, drop_remainder=True)
def process_data(x):x = tf.concat([tf.constant(start)[tf.newaxis], x, tf.constant(end)[tf.newaxis]], axis=-1)return x[:-1], x[1:]dataset = dataset.map(process_data).batch(16)inputs, outputs = dataset.take(1).get_single_element()
# inputs
# <tf.Tensor: shape=(16, 64), dtype=int32, numpy=
# array([[50258, 5962, 220, ..., 14813, 220, 1462],
# [50258, 220, 44769, ..., 220, 732, 220],
# [50258, 16275, 470, ..., 220, 1616, 220],
# ...,
# [50258, 220, 1350, ..., 220, 19205, 198],
# [50258, 271, 220, ..., 54, 18906, 220],
# [50258, 10418, 268, ..., 40, 2937, 25]])>3.3 模型构建
在这里构建模型:
class GPT(tf.keras.Model):def __init__(self, vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads, dropout=0.1):super().__init__()self.embedding = keras_nlp.layers.TokenAndPositionEmbedding(vocabulary_size=vocabulary_size,sequence_length=sequence_length,embedding_dim=embedding_dim,)self.lst = [keras_nlp.layers.TransformerDecoder(intermediate_dim=intermediate_dim,num_heads=num_heads,dropout=dropout,) for _ in range(num_layers)]self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, x):decoder_padding_mask = x!= 0 output = self.embedding(x)for item in self.lst:output = item(output, decoder_padding_mask=decoder_padding_mask)output = self.dense(output)return outputvocabulary_size = tokenizer.vocabulary_size() + 3
sequence_length= 64
embedding_dim=512
num_layers=12
intermediate_dim=1024
num_heads=8gpt = GPT(vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads)gpt(inputs)
gpt.summary()
构建模型结构如下:
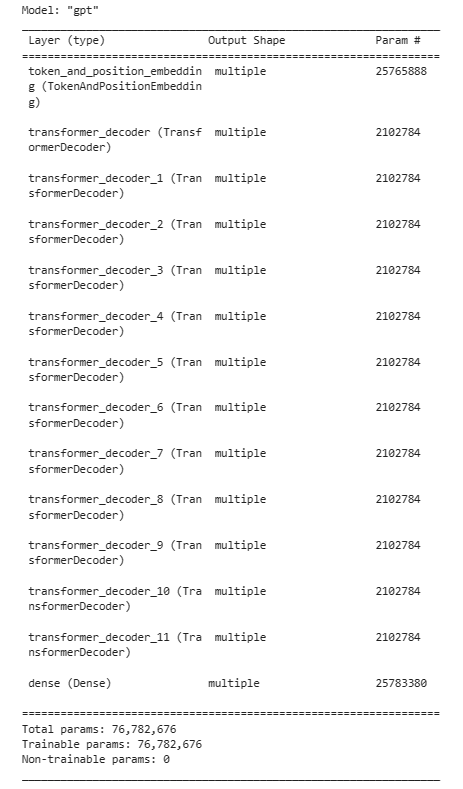
3.4 模型配置
模型配置如下:
def masked_loss(label, pred):mask = label != padloss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none')loss = loss_object(label, pred)mask = tf.cast(mask, dtype=loss.dtype)loss *= maskloss = tf.reduce_sum(loss)/tf.reduce_sum(mask)return lossdef masked_accuracy(label, pred):pred = tf.argmax(pred, axis=2)label = tf.cast(label, pred.dtype)match = label == predmask = label != padmatch = match & maskmatch = tf.cast(match, dtype=tf.float32)mask = tf.cast(mask, dtype=tf.float32)return tf.reduce_sum(match)/tf.reduce_sum(mask)gpt.compile(loss=masked_loss,optimizer='adam',metrics=[masked_accuracy]
)gpt.fit(dataset, epochs=3)
训练过程不知道为什么masked_accuracy一直不变,需要分析;

四、整体总结
模型结构很简单,但是在实现过程中出现了和Bert一样的问题;
相关文章:
[GPT-1]论文实现:Improving Language Understanding by Generative Pre-Training
Efficient Graph-Based Image Segmentation 一、完整代码二、论文解读2.1 GPT架构2.2 GPT的训练方式Unsupervised pre_trainingSupervised fine_training 三、过程实现3.1 导包3.2 数据处理3.3 模型构建3.4 模型配置 四、整体总结 论文:Improving Language Understa…...

23种设计模式之C++实践(一)
23种设计模式之C++实践 1. 简介2. 基础知识3. 设计模式(一)创建型模式1. 单例模式——确保对象的唯一性1.2 饿汉式单例模式1.3 懒汉式单例模式比较IoDH单例模式总结2. 简单工厂模式——集中式工厂的实现简单工厂模式总结3. 工厂方法模式——多态工厂的实现工厂方法模式总结4.…...
华为OD机试 - 园区参观路径(Java JS Python C)
题目描述 园区某部门举办了Family Day,邀请员工及其家属参加; 将公司园区视为一个矩形,起始园区设置在左上角,终点园区设置在右下角; 家属参观园区时,只能向右和向下园区前进,求从起始园区到终点园区会有多少条不同的参观路径。 输入描述 第一行为园区的长和宽; 后…...
【ARM Trace32(劳特巴赫) 使用介绍 12 -- Trace32 常用命令之 d.dump | data.dump 介绍】
文章目录 Trace32 常用命令之 d.dump | data.dump 介绍1 字节显示 (Byte)4 字节显示(word)8 字节显示(通常long)十进制显示显示指定列数显示地址范围内的值 Trace32 常用命令之 d.dump | data.dump 介绍 在 TRACE32 调试环境中&a…...

【Git】Git撤销操作
记录一下,方便后续查找,不全,后续再做补充。 丢弃当前工作区未提交的修改 # 丢弃所有修改 git checkout .# 丢弃某个文件修改 git checkout 文件名丢弃本地已经提交的代码 (1)撤销最近一次提交 如果我们在最近一次提…...
改造python3中的http.server为简单的文件上传下载服务
改造 修改python3中的http.server.SimpleHTTPRequestHandler,实现简单的文件上传下载服务 simple_http_file_server.py: # !/usr/bin/env python3import datetime import email import html import http.server import io import mimetypes import os …...

Fiddler抓包工具之fiddler的composer可以简单发送http协议的请求
一,composer的详解 右侧Composer区域,是测试接口的界面: 相关说明: 1.请求方式:点开可以勾选请求协议是get、post等 2.url地址栏:输入请求的url地址 3.请求头:第三块区域可以输入请求头信息…...

14、pytest像用参数一样使用fixture
官方实例 # content of test_fruit.py import pytestclass Fruit:def __init__(self, name):self.name nameself.cubed Falsedef cube(self):self.cubed Trueclass FruitSalad:def __init__(self, *fruit_bowl):self.fruit fruit_bowlself._cube_fruit()def _cube_fruit(s…...

C++ Primer Plus第十三章笔记
目录 基类 构造函数:访问权限的考虑 1.2 派生类和基类之间的特殊关系 继承:is-a关系 多态公有继承 静态联编和动态联编 指针和引用类型的兼容性 虚成员函数和动态联编 虚函数的注意事项 构造函数 析构函数 友元 没有重新定义 重新定义将隐…...

【JavaEE】单例模式
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文于《JavaEE》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&…...
)
第十五届蓝桥杯模拟赛(第二期 C++)
俺自己做的噢,还未核实答案,若有差错,望斧正。 第一题 小蓝要在屏幕上放置一行文字,每个字的宽度相同。小蓝发现,如果每个字的宽为 36 像素,一行正好放下 30 个字,字符之间和前后都没有任何空隙…...
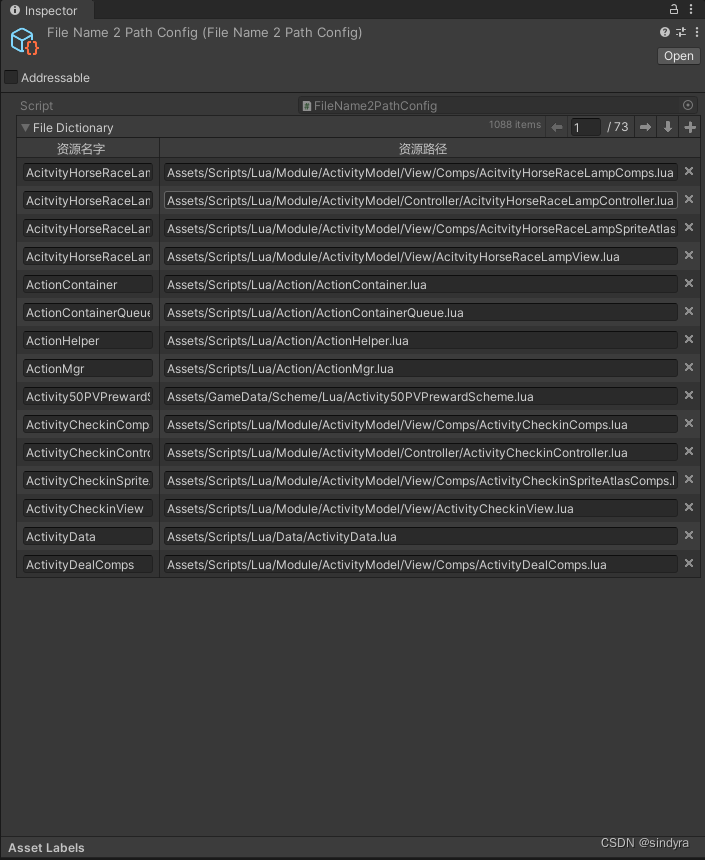
关于Unity中字典在Inspector的显示
字典在Inspector的显示 方法一:实现ISerializationCallbackReceiver接口 《unity3D游戏开发第二版》记录 在编辑面板中可以利用序列化监听接口特性对字典进行序列化。 主要继承ISerializationCallbackReceiver接口 实现OnAfterDeserialize() OnBeforeSerialize() …...
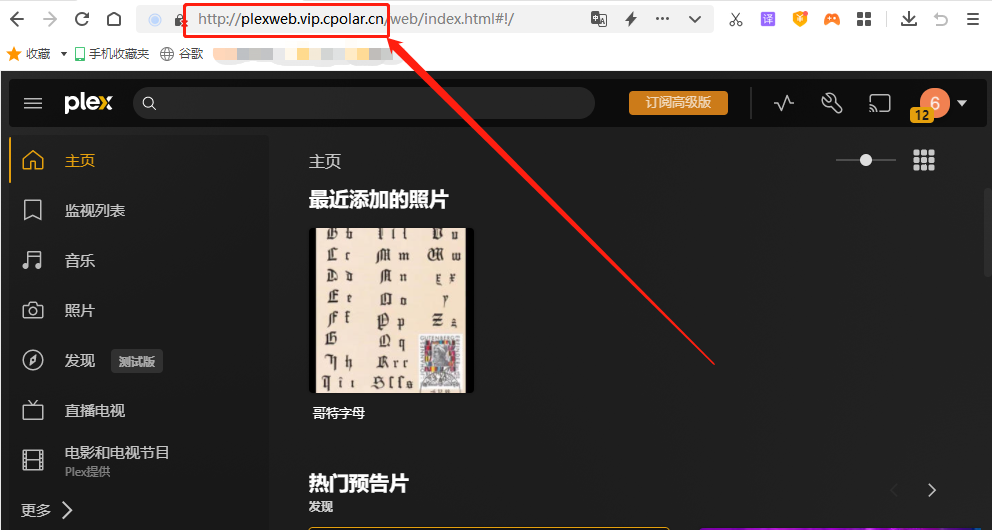
使用Plex结合cpolar搭建本地私人媒体站并实现远程访问
文章目录 1.前言2. Plex网站搭建2.1 Plex下载和安装2.2 Plex网页测试2.3 cpolar的安装和注册 3. 本地网页发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4. 公网访问测试5. 结语 1.前言 用手机或者平板电脑看视频,已经算是生活中稀松平常的场景了,特别是各…...
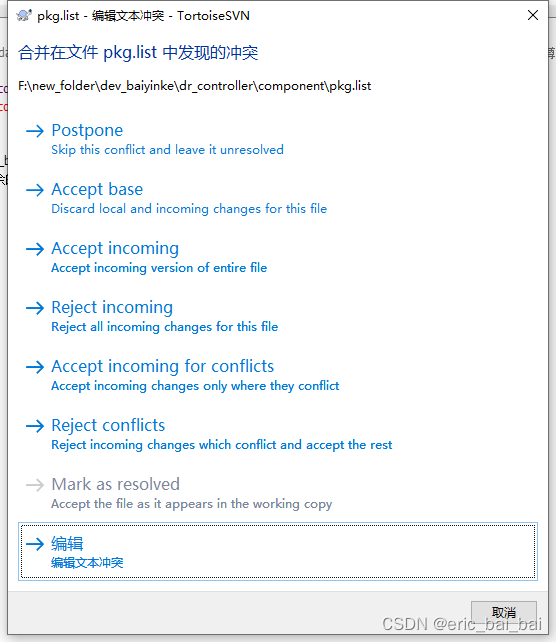
svn合并冲突时每个选项的含义
合并冲突时每个选项的含义 - 这个图片是 TortoiseSVN(一个Subversion(SVN)客户端)的合并冲突解决对话框。当你尝试合并两个版本的文件并且出现差异时,你需要解决这些差异。这个对话框提供了几个选项来处理合并冲突&…...

指针、数组与函数例题3
1、字符串复制 题目描述 设计函数实现字符串复制功能,每个字符串长度不超过100,不要使用系统提供的strcpy函数 输入要求 从键盘读入一个字符串到数组b中,以换行符结束 输出要求 将内容复制到另一个数组a中,并分别输出数组a和…...

ThreeJs样例 webgl_shadow_contact 分析
webgl_shadow_contact 官方样例中,对阴影的渲染比较特殊,很值得借鉴,学习渲染阴影的思路;这个例子中对阴影的渲染,并没有使用任何光源,没有用shadowmap的常规方式 渲染阴影;而是使用了深度材质T…...
)
Nginx(缓冲区)
先来思考一个问题,接入Nginx的项目一般请求流程为:“客户端→Nginx→服务端”,在这个过程中存在两个连接:“客户端→Nginx、Nginx→服务端”,那么两个不同的连接速度不一致,就会影响用户的体验(…...

MQTT协议理解并实践
MQTT是一个轻量的发布订阅模式消息传输协议,专门针对低带宽和不稳定网络环境的物联网应用设计 MQTT协议根据主题来分发消息进行通信,支持通配符匹配,可以低开销的使用数百万Topic进行一对一,一对多双向通信。 协议特点 1. 开放…...
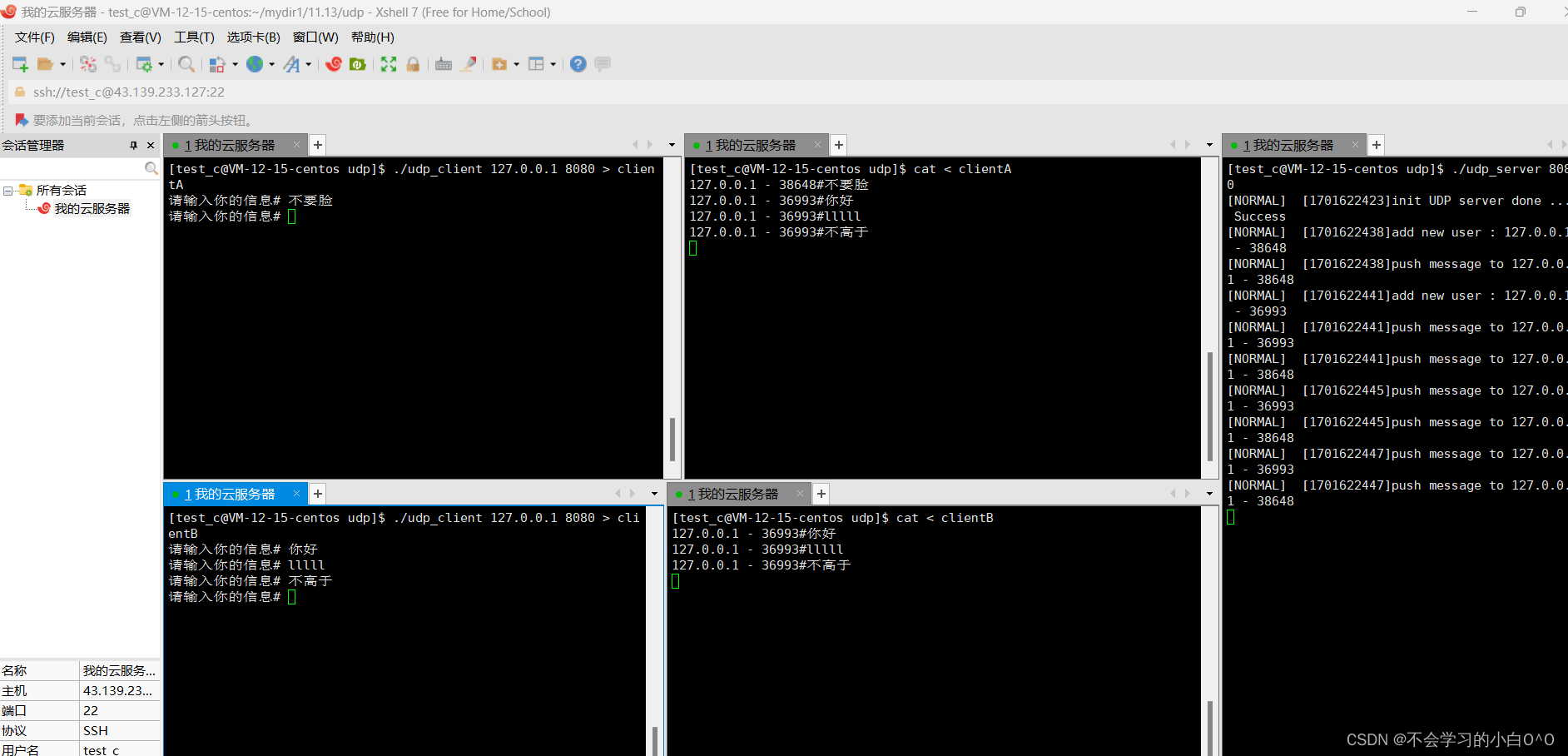
实现一个简单的网络通信下(udp)
时间过去好久了,先回忆一下上一篇博客的代码!! 目前来看,我们客户端发一条消息,我服务器收到这一条消息之后呢,服务器也知道了是谁给我发来的消息,紧接这就把这条消息放进buffer当中,…...

Linux中office环境LibreOffice_7.6.2下载
阿里云盘:LibreOffice_7.6.2 使用:下载的文件为exe文件,双击exe文件即可获取到文件 LibreOffice_7.6.2安装: 解压:tar -zxvf LibreOffice_7.6.2_Linux_x86-64_rpm.tar.gz 移动到RPMS目录:cd LibreOffice_7…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...