C++11(上)
统一的列表初始化
首先要说明:
这个列表初始化和类和对象那里的初始化列表不是一个概念.
{} 初始化
在C++98中, 标准允许使用花括号{}对数组或者结构体元素进行统一的列表初始值设定.
比如:

C语言里面其实就是这样支持的, 所以可以认为C++支持这样就是因为要兼容C.
在C++11中:
C++11扩大了用大括号括起的列表的使用范围, 使其可用于所有的内置类型和用户自定义的类型, 使用初始化列表时, 可添加等号(=), 也可不添加。
struct Point
{int _x;int _y;
};// 一切都可以用列表初始化
// 并且可以省略掉=
int main()
{int x1 = 1;int x2 = { 2 };int x3{ 3 };//可以省略等号int array1[]{ 1, 2, 3, 4, 5 };int array2[5]{ 0 };Point p{ 1, 2 };// C++11中列表初始化也可以适用于new表达式中int* pa = new int[4] { 0 };return 0;
}
C++11支持我们这样使用{}初始化,并且赋值
=也可以省略
创建对象时也可以使用列表初始化方式调用构造函数初始化:
class Date
{
public:Date(int year, int month, int day):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;}
private:int _year;int _month;int _day;
};int main()
{Date d1(2022, 1, 1); // old style// C++11支持的列表初始化,这里会调用构造函数初始化//实际上是构造+拷贝构造,然后优化成直接构造Date d2{ 2022, 1, 2 };Date d3 = { 2022, 1, 3 };Date* p1 = new Date[3]{ d1, d2, d3 };Date* p2 = new Date[3]{ {2022, 11, 25}, {2022, 11, 26}, {2022, 11, 27} };return 0;
}std::initializer_list
除了上面的场景, C++11还支持了STL里面的容器也可以这样去初始化:
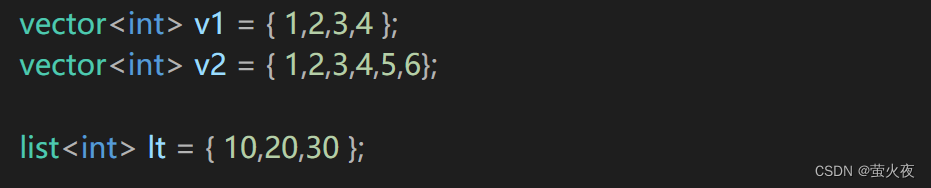
如果按照上面Data列表初始化的理解, 这里是调用vector的构造函数初始化, 但这里的参数是不固定的, vector也没有传这么多参数的构造函数.

而这里我们直接给一个大括号初始化, 和之前数组初始化很像, 那它在这里也是一个数组吗?
我们可以打印看一下它的类型是什么:
int main()
{// the type of il is an initializer_list auto il1 = { 10, 20, 30, 40, 50 };cout << typeid(il1).name() << endl;return 0;
}

它的类型是
initializer_list<int>
为什么这个东西可以赋值给vector呢?
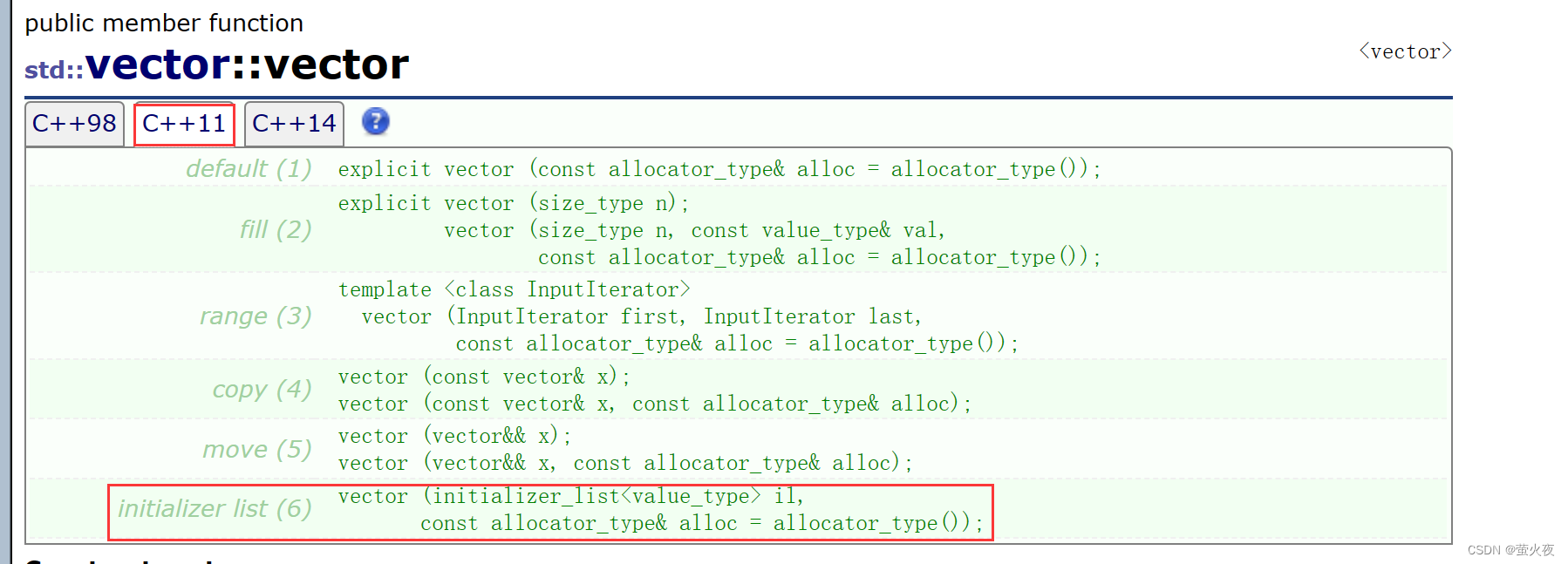
C++11给STL中的这些容器增加了这样一个构造函数, 支持用initializer_list类型的对象去构造vector这些容器, 所以正常使用这个构造应该是这样写:

但这样写也可以, 因为构造函数支持隐式类型转换.

而且也支持将initialize_list的对象进行赋值:

那initializer_list这个类是什么呢?

initializer_list是C++11引入的一种特殊类型, 用于容器初列表始化, 它可以在构造函数或函数参数中以列表的形式传递一组值.
可以认为它就是一个常量数组, 存储在常量区, initializer_list对象中的元素永远是常量值, 我们无法改变initializer_list对象中元素的值.
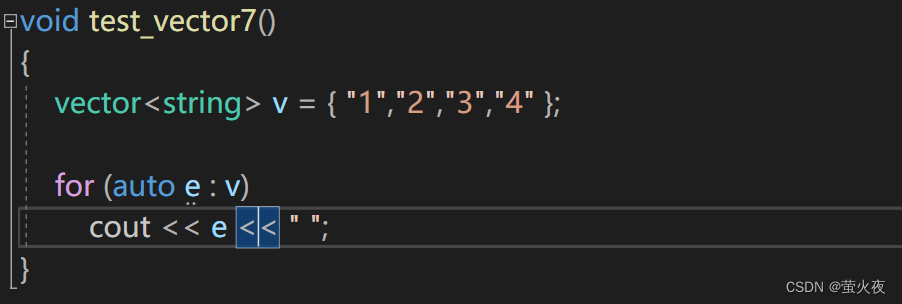
initializer_list也支持迭代器访问, 范围for也可以使用:
int main()
{initializer_list<int> il2 = { 10, 20, 30};initializer_list<int>::iterator it2 = il2.begin();while (it2 != il2.end()){cout << *it2 << " ";++it2;}cout << endl;//for (int e : il2)for (auto e : il2){cout << e << " ";}cout<< endl;return 0;
}
再来看map的列表初始化:
int main()
{pair<string, string> kv1("sort", "排序");map<string, string> dict = {kv1, {"insert", "插入"}, {"get","获取"} };for (auto& kv : dict){cout << kv.first << ":" << kv.second << endl;}return 0;
}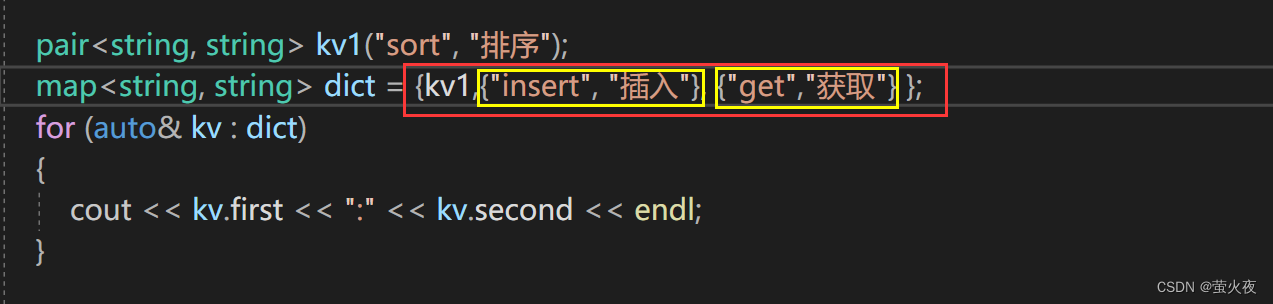

注意区分, 红色框内的{}是initialize_list用来初始化map, 黄色框内的{}是pair的隐式类型转换, 用来构造pair, 所以可以发现当{}内的参数和构造函数一致时, 会识别成构造函数, 当参数不一致时会识别成initialize_list.

接下来再做一件事情:
将我们之前模拟实现过的vector进行改造, 让它也支持用initializer_list进行{}初始化和赋值.
构造:
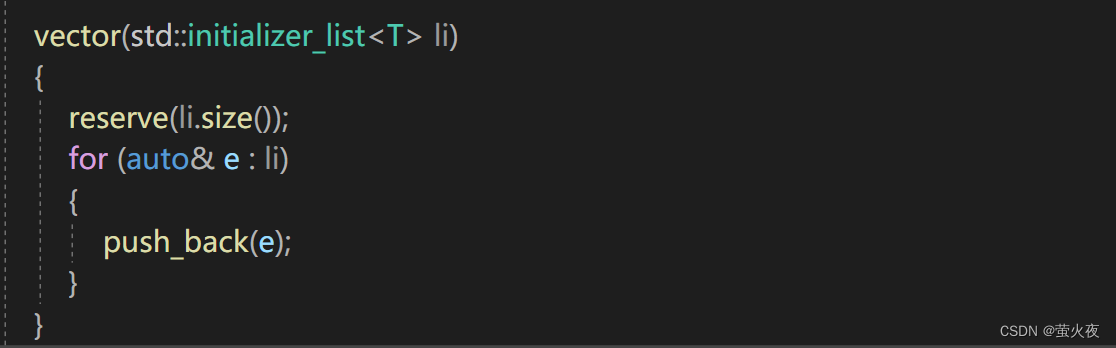

赋值:


声明
c++11提供了多种简化声明的方式
auto
auto之前介绍过
在C++98中auto是一个存储类型的说明符, 表明变量是局部自动存储类型, 但是局部域中定义局部的变量默认就是自动存储类型, 所以auto就没什么价值了.
C++11中废弃auto原来的用法,将其用于实现自动类型推断, 这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初始化值的类型。
decltype
再来看C++11引入的关键字——decltype
declypes可以获取表达式或变量类型
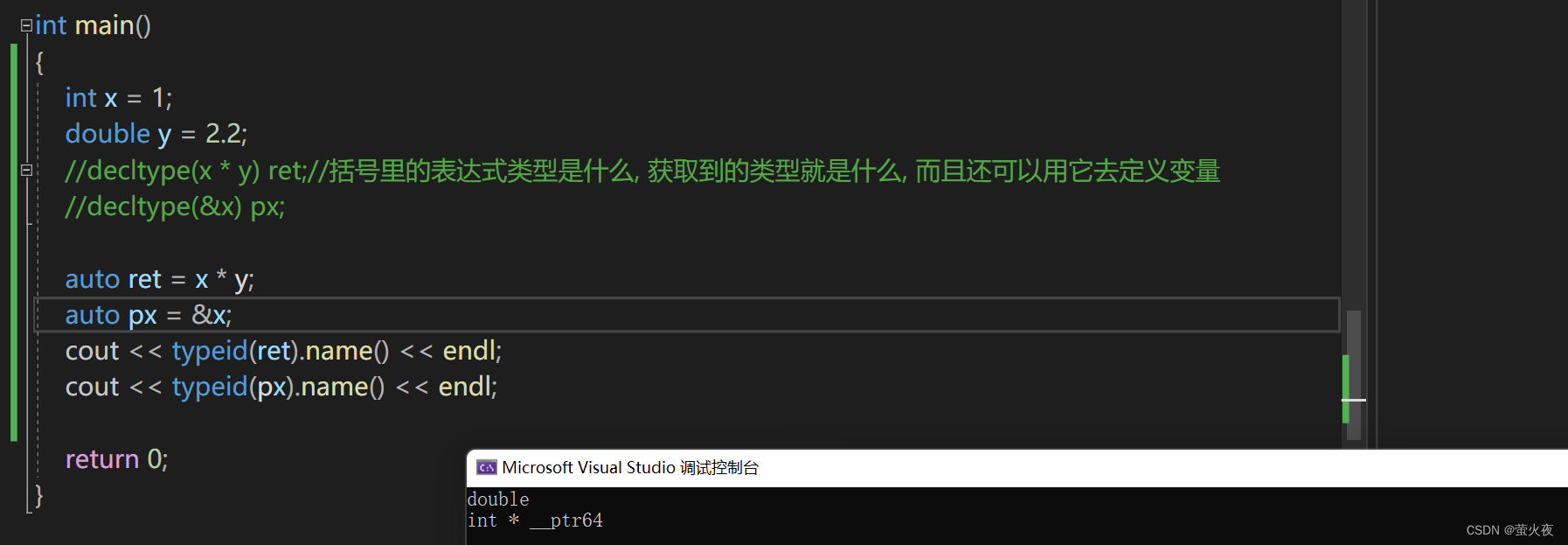
我们之前用过typeid(变量/表达式).name()可以获取变量或表达式的类型, 然后我们可以打印出来查看, 而使用decltype我们可以获取类型并使用这个类型

可以看到decltype获取的类型可以定义变量, 而typeid获得到的类型只能输出.
但是上面的场景用auto也可以实现:
但是有的场景auto就不行, 比如:
我们要定义一个vector, 要求vector里面存储的数据类型跟re 的返回类型一致
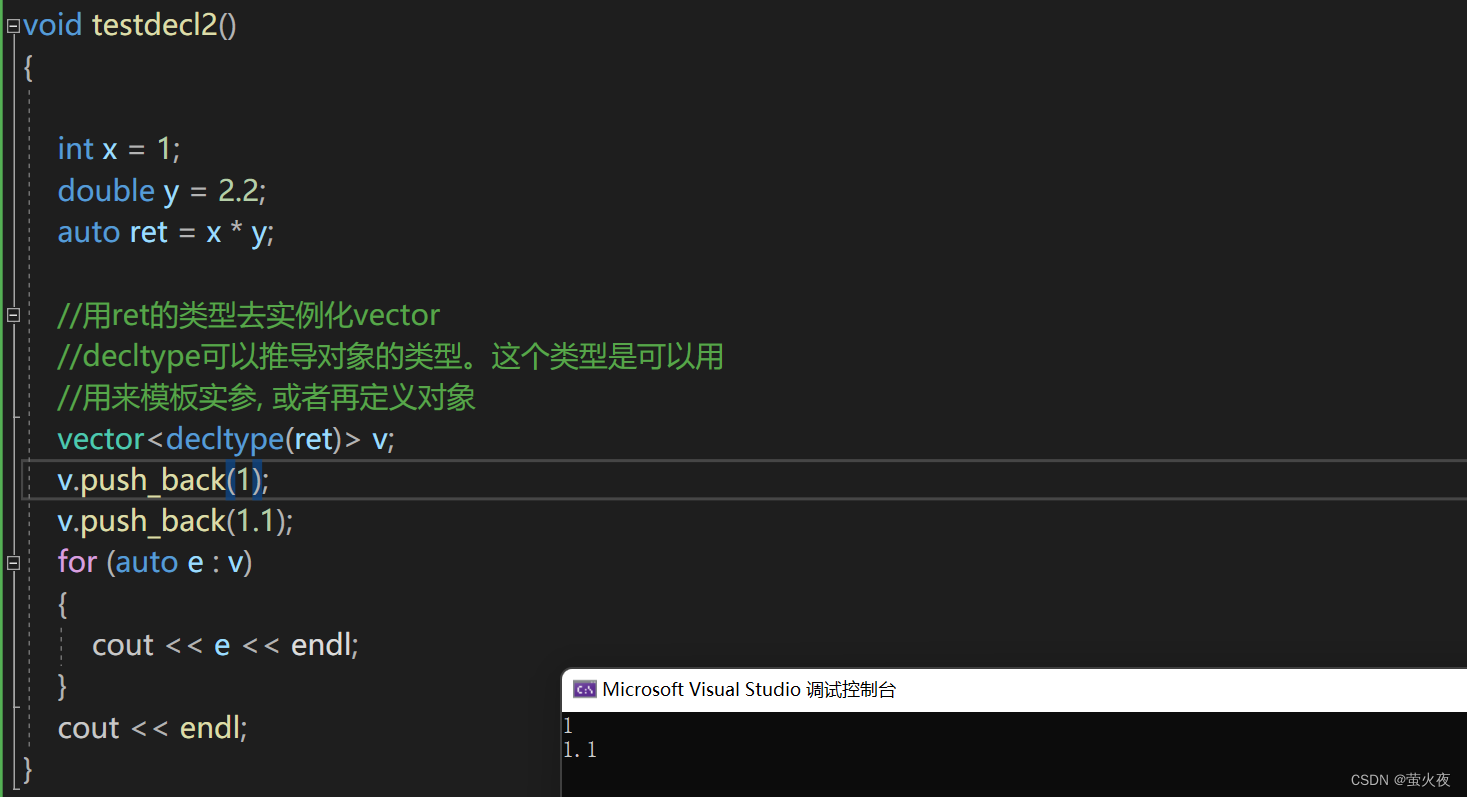
这个场景auto就不行了.
nullptr
nullptr之前也介绍过,由于C++中NULL被定义成字面量0, 这样就可能回带来一些问题, 因为0既能指针常量, 又能表示整形常量. C++98中NULL定义成了0, 但是更希望匹配的是(void*) 0. 所以出于清晰和安全的角度考虑, C++11中新增了nullptr,用于表示空指针。
范围for循环
之前也介绍过
智能指针
后面会单独介绍
STL中的一些变化
新容器
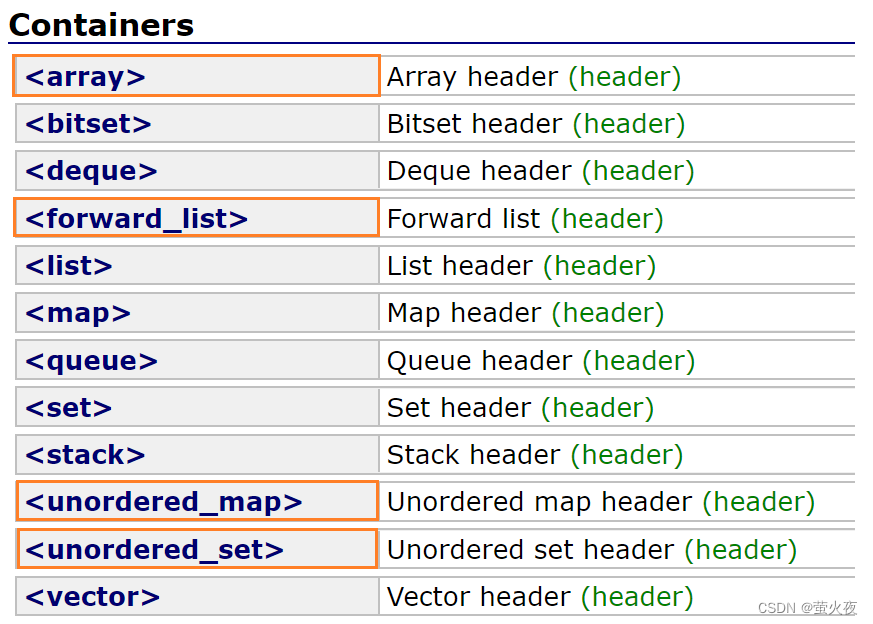
用橘色圈起来是C++11中的一些几个新容器, 但是实际最有用的是unordered_map和unordered_set.
array
array主要是为了替代c静态数组, []访问能更好的检查越界, 但是我们用vector + resize也挺好, vector也能检查边界, array和vector底层不同, array的空间是开在栈上的, vector的空间开在堆上.
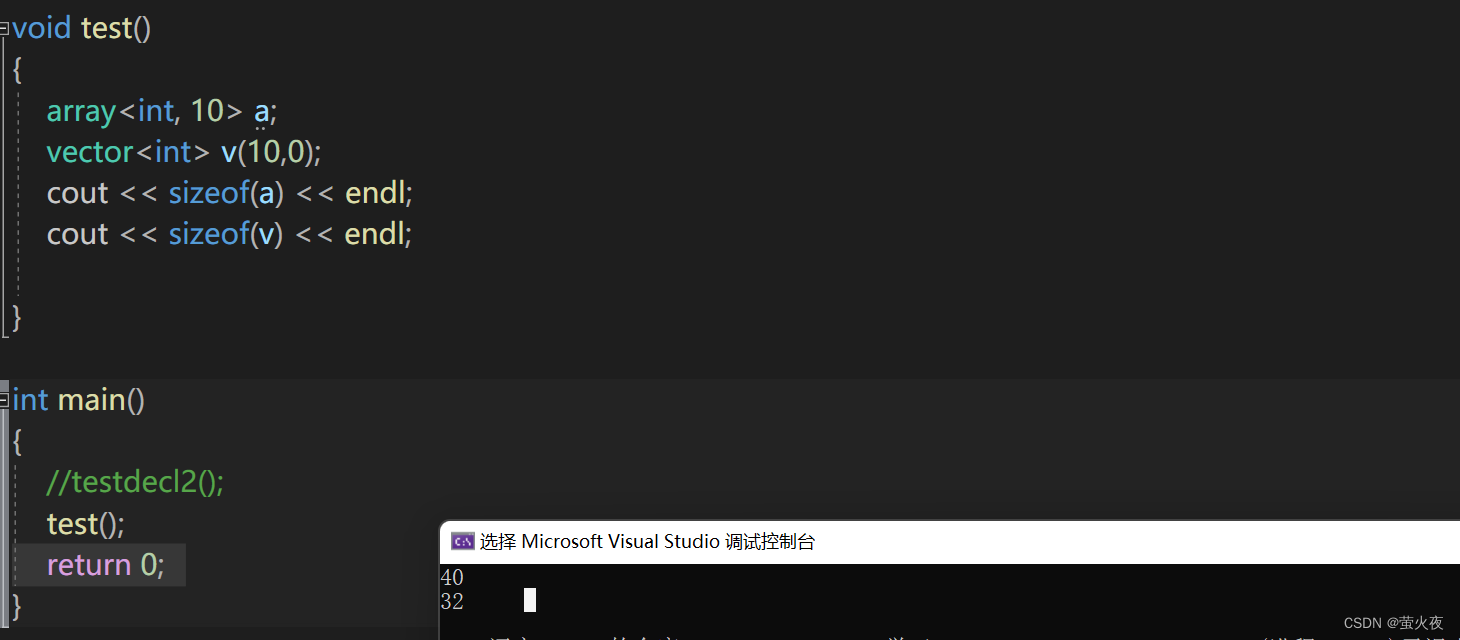
array的对象空间是会变化的, vector对象的空间64位下永远是32,32位下永远是16.
forward_list
forward_list是单链表, 比起list而言, 每个节点可以节省一个指针的空间, 头插头删效率不错, 但是存在的意义很有限, 除非有大量的节省内存的需求或者需要高频头插头删.
新方法:
其次是增加了一些新方法:
const迭代器
比如提供了cbegin和cend方法返回const迭代器等等, 但是实际意义不大, 因为begin和end也是可以返回const迭代器的.
右值引用与移动语义
实际上C++11更新后, 容器中增加的新方法最实用的是右值引用版本插入.
右值引用与移动语义
左值引用和右值引用
传统的C++语法中就有引用的语法, 而C++11中新增了的右值引用语法特性, 所以我们之前学习的引用就叫做左值引用. 无论左值引用还是右值引用, 都是给对象取别名。
左值
什么是左值? 什么是左值引用?
左值是一个表示数据的表达式(如变量名或解引用的指针), 我们可以获取它的地址+可以对它赋值, 左值可以出现赋值符号的左边或者右边, 右值不能出现在赋值符号左边.
定义时const修饰符后的左值, 不能给他赋值, 但是可以取它的地址.
左值引用就是给左值的引用, 给左值取别名.

右值
什么是右值? 什么是右值引用?
右值也是一个表示数据的表达式, 如: 字面常量、匿名对象、表达式返回值, 函数返回值(一般是传值返回, 不能是左值引用返回)等等, 右值只能出现在赋值符号的右边, 不能出现出现在赋值符号的左边, 右值不能取地址.
右值引用就是对右值的引用,给右值取别名.

需要注意的是右值是不能取地址的, 但是给右值取别名后, 会导致右值被存储到特定位置, 且可以取到该位置的地址(右值引用具有左值属性), 下面有更详细的解释.
也就是说例如: 不能取字面量10的地址, 但是rr1引用后, 可以对rr1取地址, 也可以修改rr1. 如果不想rr1被修改, 可以用const int&& rr1 去引用.

rr2不能被修改, 会报错.
左值引用、右值引用本身是左值还是右值?
被声明出来的左、右值引用都是左值。 因为被声明出的左右值引用是有地址的,也位于等号左边。仔细看下边代码:
// 形参是个右值引用
void change(int&& right_value) {right_value = 8;
}int main() {int a = 5; // a是个左值int &ref_a_left = a; // ref_a_left是个左值引用int &&ref_a_right = std::move(a); // ref_a_right是个右值引用change(a); // 编译不过,a是左值,change参数要求右值change(ref_a_left); // 编译不过,左值引用ref_a_left本身也是个左值change(ref_a_right); // 编译不过,右值引用ref_a_right本身也是个左值change(std::move(a)); // 编译通过change(std::move(ref_a_right)); // 编译通过change(std::move(ref_a_left)); // 编译通过change(5); // 当然可以直接接右值,编译通过cout << &a << ' ';cout << &ref_a_left << ' ';cout << &ref_a_right;// 打印这三个左值的地址,都是一样的
}
这个结论后面会用到.
思考
左值引用可以给右值取别名吗?或者说左值引用可不可以引用右值?
一般情况下是不能的:
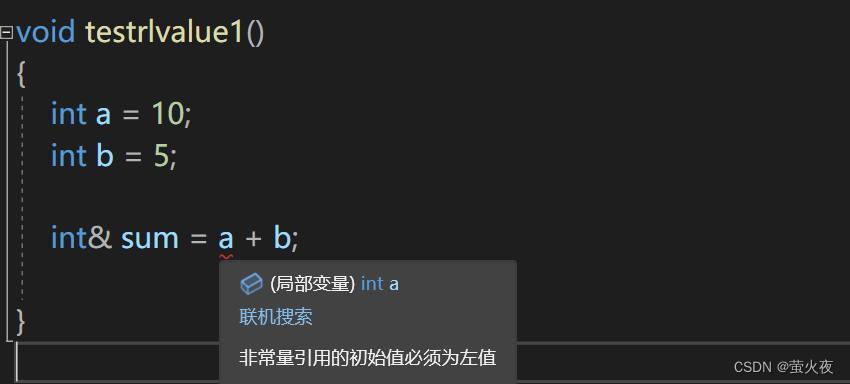
这样是权限的放大 (运算结果一般也放到临时变量里面存一下, 临时变量具有常性), 所以我们加一个const就行了:

那右值引用可以给左值取别名(引用左值)吗?
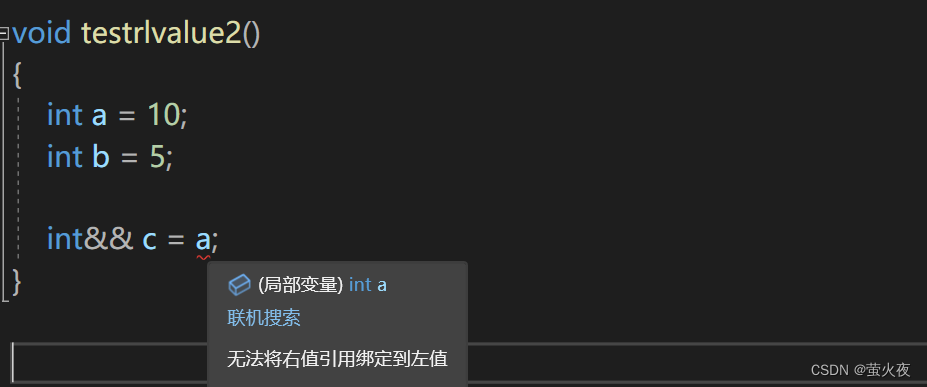
但是右值引用可以给move之后的左值取别名.

move是库里面的一个函数, 它可以把传入的参数arg转换为右值引用(移动语义) :
 左值引用与右值引用总结
左值引用与右值引用总结
左值引用:
1. 左值引用只能引用左值, 不能引用右值.
2. 但是const左值引用既可引用左值, 也可引用右值.

右值引用:
1. 右值引用只能引用右值, 不能引用左值.
2. 但是右值引用可以move以后的左值.

所以其实左值引用其实既可引用左值, 也可引用右值(加const就行了), 那为什么要有右值引用.
右值引用使用场景和意义
移动构造
左值引用既可以引用左值和又可以引用右值, 那为什么C++11还要提出右值引用呢?是不是化蛇添足呢?下面我们来看看左值引用的短板, 右值引用是如何补齐这个短板的.
先以一个简易的string为例, 主要观察其中的拷贝构造和赋值:

#include<iostream>
using namespace std;
#include <assert.h>namespace test
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;string tmp(s._str);swap(tmp);}// 赋值重载string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;}~string(){delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//string operator+=(char ch)string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};}
再实现一个整型转换字符串的函数(只是简易版, 只能处理正数):
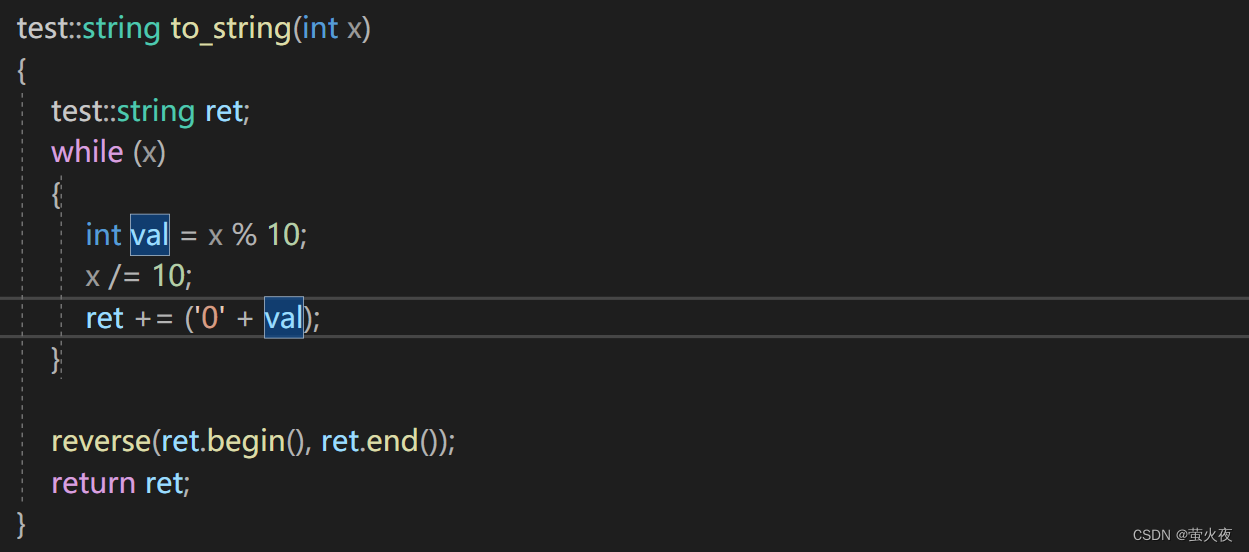
这里左值引用的短板就体现出来了:
当函数返回对象是一个局部变量, 出了函数作用域就不存在了, 就不能使用左值引用返回, 只能传值返回, 这种情况就不能避免拷贝的消耗.
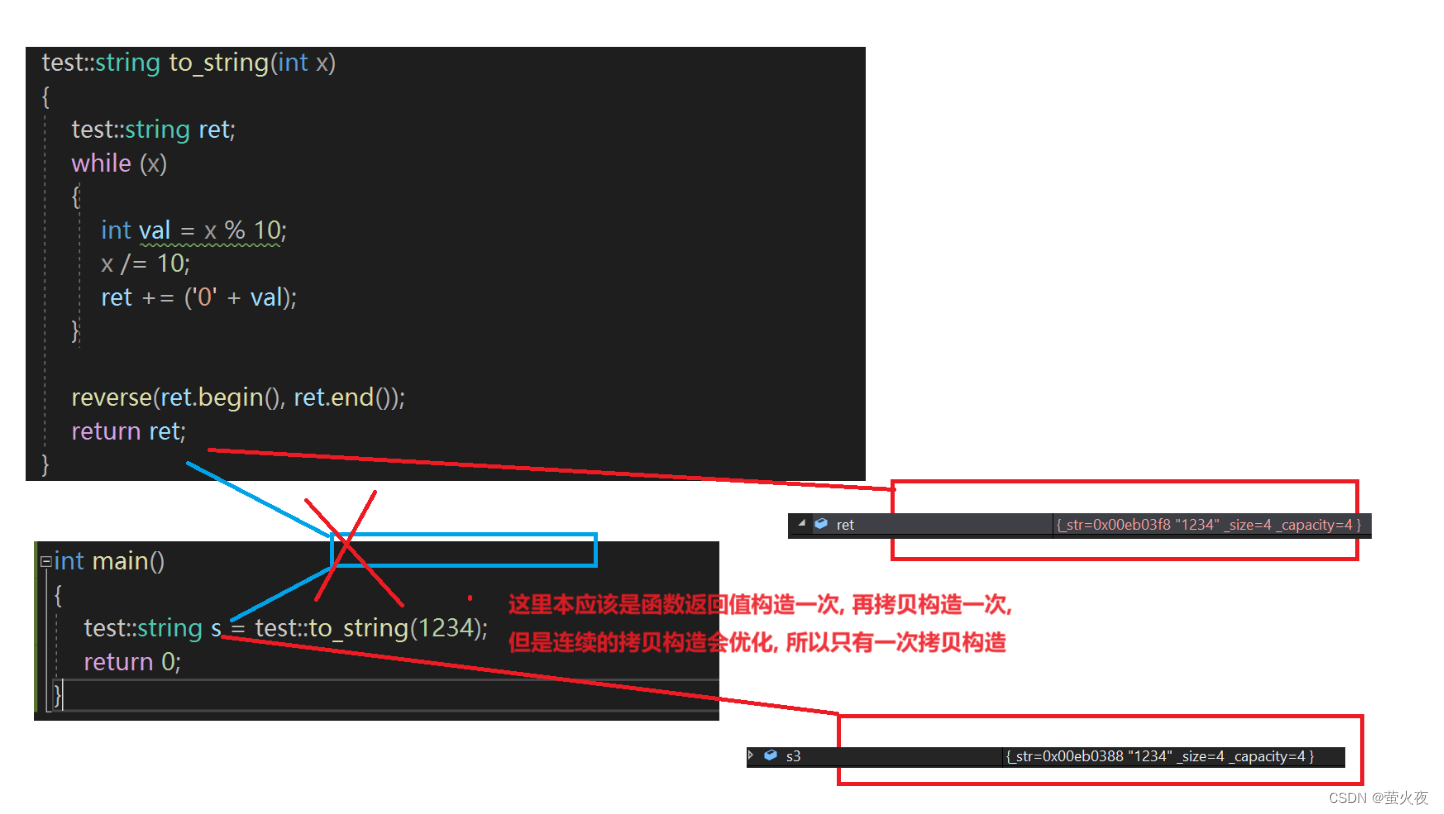
比如to_string函数返回的是局部对象ret, 所以不能引用返回, 因为ret这个局部对象在函数调用结束就销毁了, 所以这里会产生一个临时对象(ret的拷贝) 作为返回值.
main函数:

这里使用vs2019测试, vs2022优化等级太高, 看不出来区别.
可以看到进行了一次深拷贝:

在分析上面的情况之前, 再补充一点:
就算有些地方会把右值分为两种——纯右值和将亡值
一般可以认为内置类型的右值是纯右值,自定义类型的右值是将亡值.
怎么理解将亡?
就是将要死亡, 即即将被销毁的右值, 一般对于将亡值我们可以直接转移它的资源来减少拷贝的消耗, 就像上面的ret, s其实没有必要再用那个临时变量拷贝构造一次, s内部的字符串直接指向那个临时变量即可,.(将亡值一般是针对自定义类型去谈的, 因为一般自定义类型涉及资源管理, 左值引用的缺陷是对于右值的堆空间上的资源无法很好地利用, 需要多次资源申请降低效率, 才需要考虑提高效率这些概念, 所以上面才说一般认为自定义类型的右值是将亡值, 且一般是深拷贝的自定义类型)
现在再增加一个左值:


首先我们要把这两种不同情况区分开来:
上面这两种情况一个是左值一个是右值, 左值就是正常的调用拷贝构造, 现在需要处理的是s3的右值避免让它拷贝构造.

对于ret来说, 按照我们上面说的他是一个将亡值, (这里是一个临时对象保存返回值, 然后它拷贝给s3之后就销毁了).
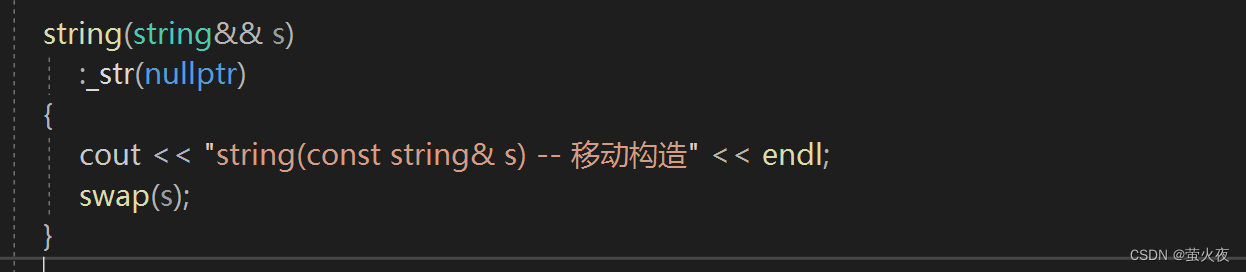
对于一个将亡值, 我们就没有必要再去拷贝它, 针对这样的情况我们可以对它做一个单独的处理, 直接移动它的资源——移动拷贝, 所以我们可以重载一个移动拷贝的函数.
直接把把这个右值交换给我们要构造的string对象就行了, 相当于进行资源的转移, 就减少了拷贝, 反正你这个将亡值马上就要被销毁了。
再次运行发现就调用了移动构造:

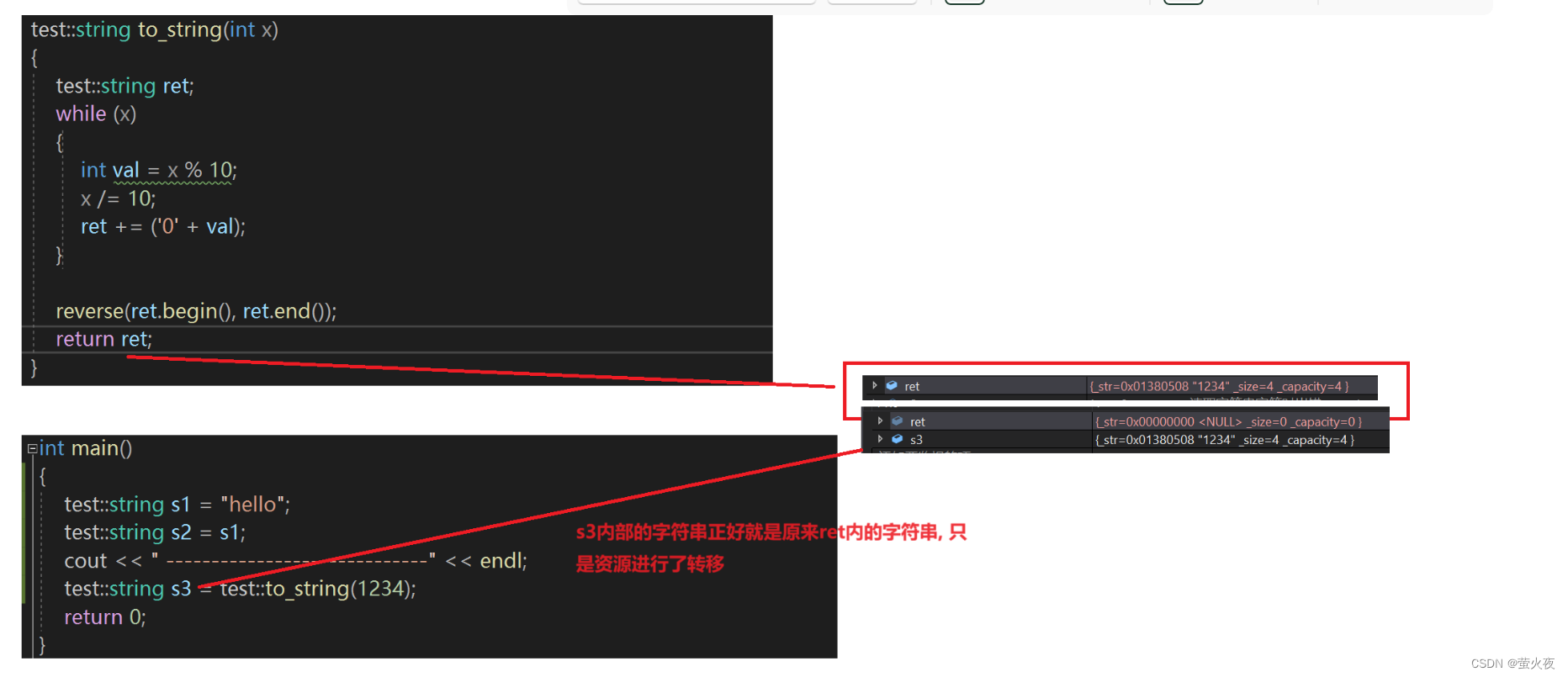
这次没有调用深拷贝的拷贝构造, 而是调用了移动构造, 移动构造中没有新开空间拷贝数据,只是资源的转移, 所以效率提高了.
所以移动构造本质是将参数右值的资源窃取过来, 占为已有, 那么就不用做深拷贝了, 所以它叫做移动构造, 就是窃取别人的资源来构造自己.
注意:
如果对于s2的拷贝构造我也想使用资源转移的移动构造来让s1构造s2呢? 但是s1是左值啊
这时我们就可以使用上面提到的move函数了
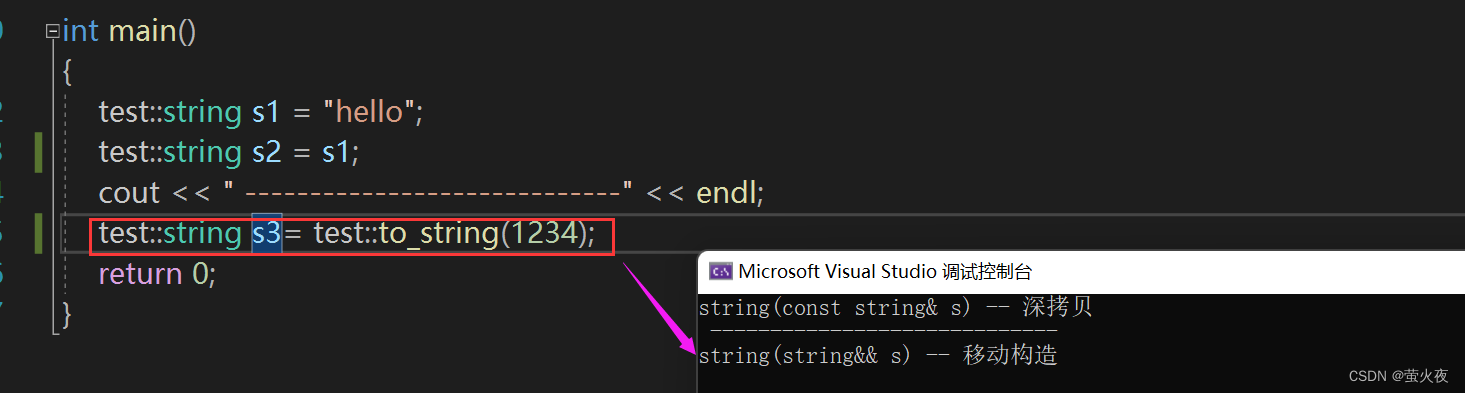 这次就没有调深拷贝了, 而是移动拷贝, 那s的资源是否真的被转移走了呢?
这次就没有调深拷贝了, 而是移动拷贝, 那s的资源是否真的被转移走了呢?

但是这样如果我们后面使用s1它就为空了, 所以也不能随便使用move, 在合适的场景下应用
move函数的参数是一个通用引用(universal reference), 既可以接受左值类型, 也可以接受右值类型, 返回值是传递进来的参数的右值引用.
move只是返回值为右值引用, 并不会真正改变参数的属性, 它的作用是告诉编译器, 我们希望对该对象执行移动操作, 以便能够使用移动构造函数或移动赋值运算符.
有些场景下, 可能真的需要用右值去引用左值实现移动语义。
当需要用右值引用引用一个左值时,可以通过move函数将左值转化为右值引用。
C++11中,std::move()函数位于头文件中,该函数名字具有迷惑性,它并不搬移任何东西,唯一的功能就是返回参数的右值引用(并不会真正改变参数的属性), 然后实现移动语义。
移动赋值
不仅仅有移动构造, 还有移动赋值.

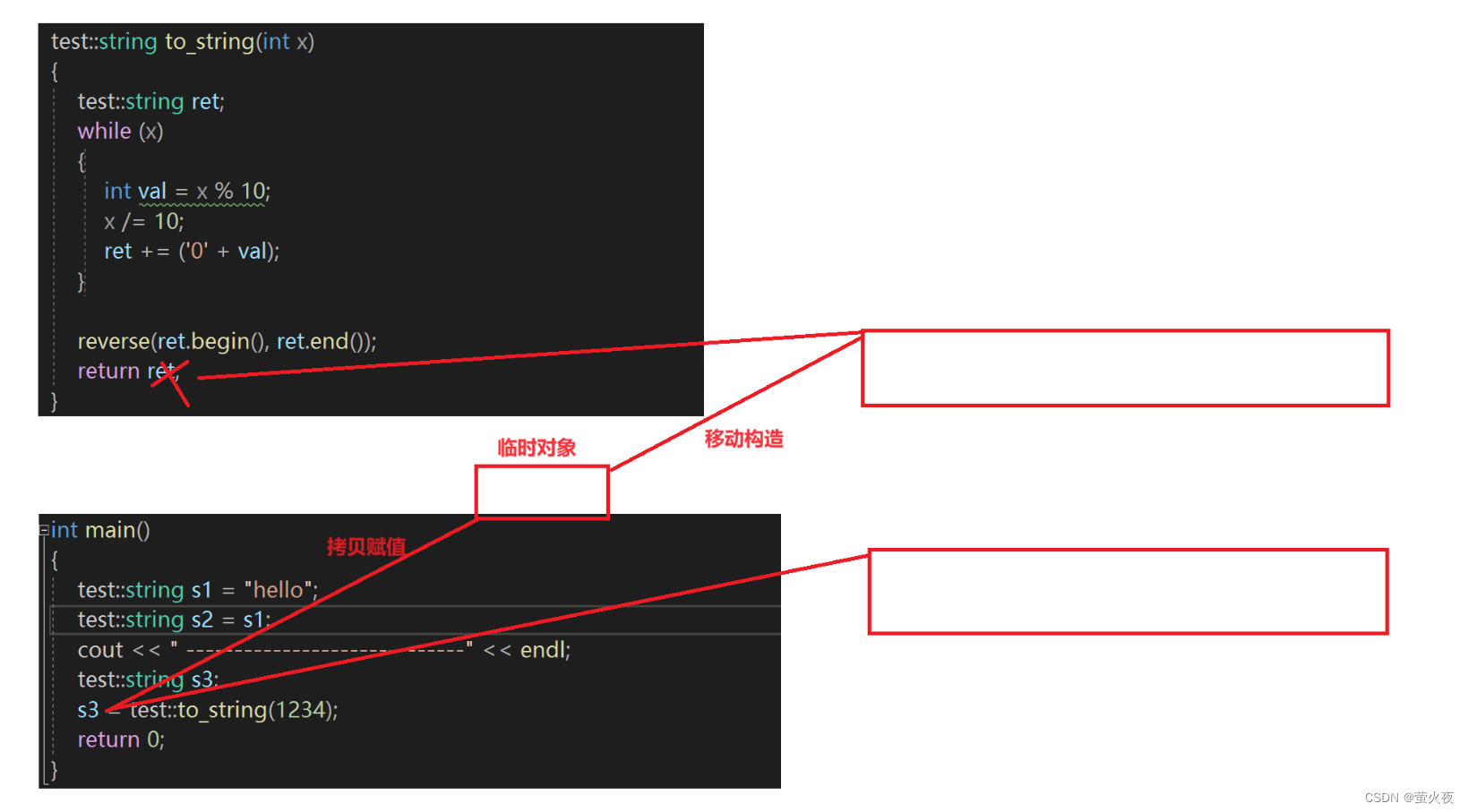 对于这里to_string返回产生的临时变量, 它也是一个将亡值, 所以我们没必要进行深拷贝的赋值, 就可以直接进行移动赋值(这里就不像是上面说的那样直接用ret构造编译器又进行特殊识别, 这里是确实产生了临时变量,因为连续的构造+赋值重载不能优化):
对于这里to_string返回产生的临时变量, 它也是一个将亡值, 所以我们没必要进行深拷贝的赋值, 就可以直接进行移动赋值(这里就不像是上面说的那样直接用ret构造编译器又进行特殊识别, 这里是确实产生了临时变量,因为连续的构造+赋值重载不能优化):



C++11给STL中的容器都增加了移动构造和移动赋值:


其它容器也是, 不一一列举.
右值引用的其他场景
STL库中的swap函数就得到了很大的优化:
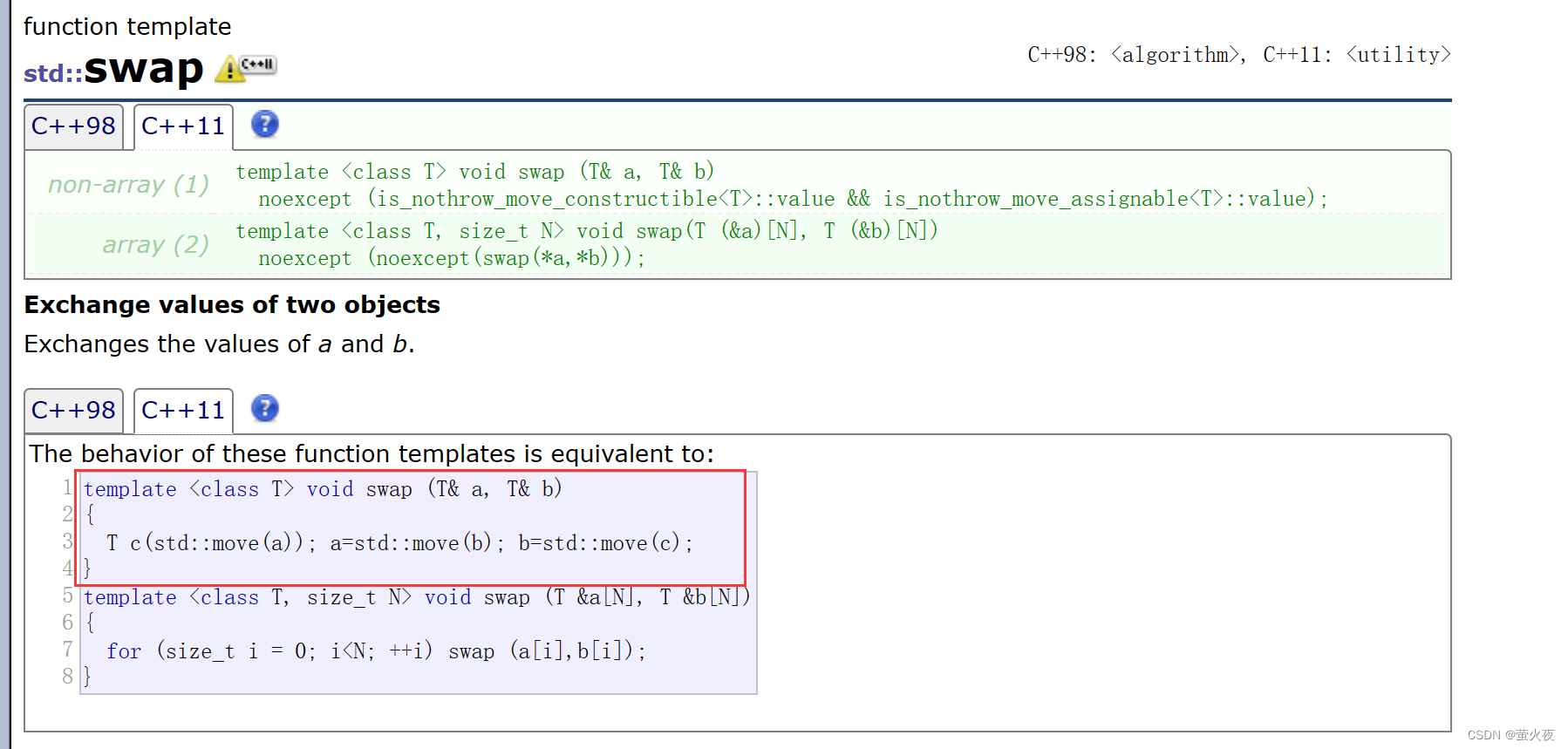
algorithm库里的swap函数得到了很大的优化, 因为它可以不再像C++98里实现的那样, 对于自定义类型的对象, 还要用拷贝构造创建一个临时变量作为中间值交换, 降低效率, 为此string库里还自己实现了swap就是为了避免这样不必要的深拷贝.
对于一些传值返回的场景也得到了优化:

这里直接返回一个vector<vector<int>>如果直接深拷贝代价太大, 而有了移动构造之后就可以放心使用值返回了, 因为只是资源的转移, 并没有实际深拷贝, 而以前C++98为了提高效率, 是将要返回的值作为输出型参数传进去, 不够直观.
右值引用版本的插入接口函数
除了移动构造和移动赋值外:
C++11给STL中容器的插入数据接口函数也都增加右值引用的版本.

那增加了右值引用的版本, 有什么好处呢?
以list为例:


第一个push_back的是s1, s1是一个string对象, 是一个左值, 所以他调用的push_back就是左值引用的那个版本. push_back里面要创建一个新结点链接到链表上, 结点里面存的是string, 所以这里必然要进行string的深拷贝.

第二个push_back插入的是一个字符串, 会先构造成string, 这个string是临时对象声明周期在这一行,是将亡值 , 所以这里就会调第二个右值引用版本的push_back.
那这样的话push_back里面创建新结点时, string的拷贝构造就会调用移动构造了.
万能引用与完美转发
万能引用
模板中的&& 万能引用
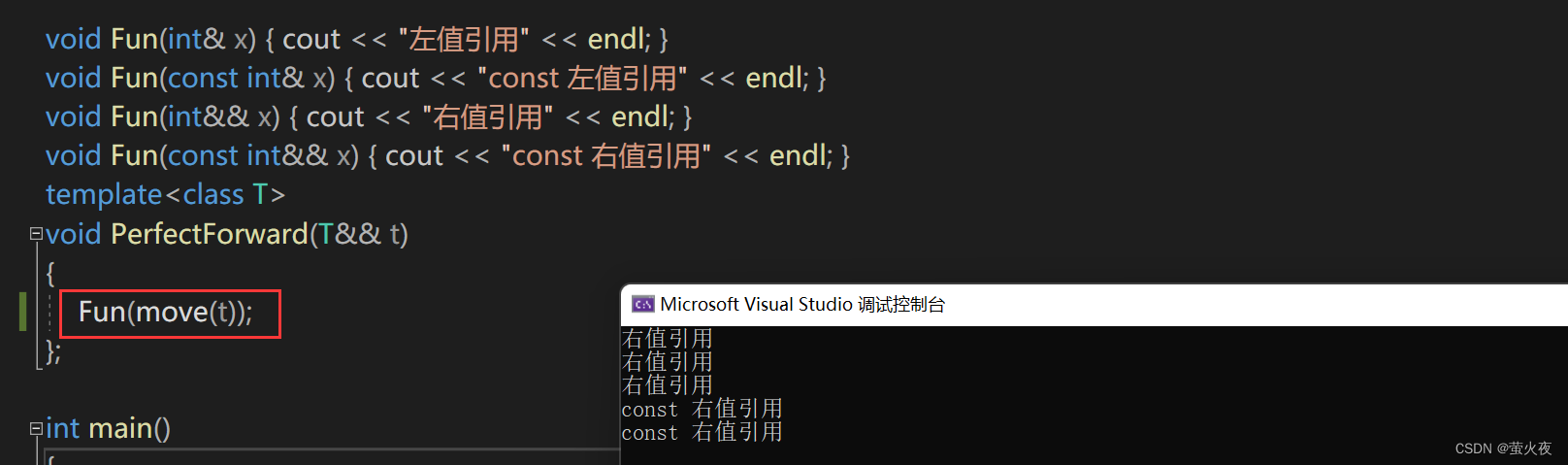
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }这里有4个函数,它们是重载的关系,然后我们给这样一个函数模板:
template<class T>
void PerfectForward(T&& t)
{Fun(t);
};这里模板中的&&不代表右值引用, 而是万能引用, 其既能接收左值又能接收右值:
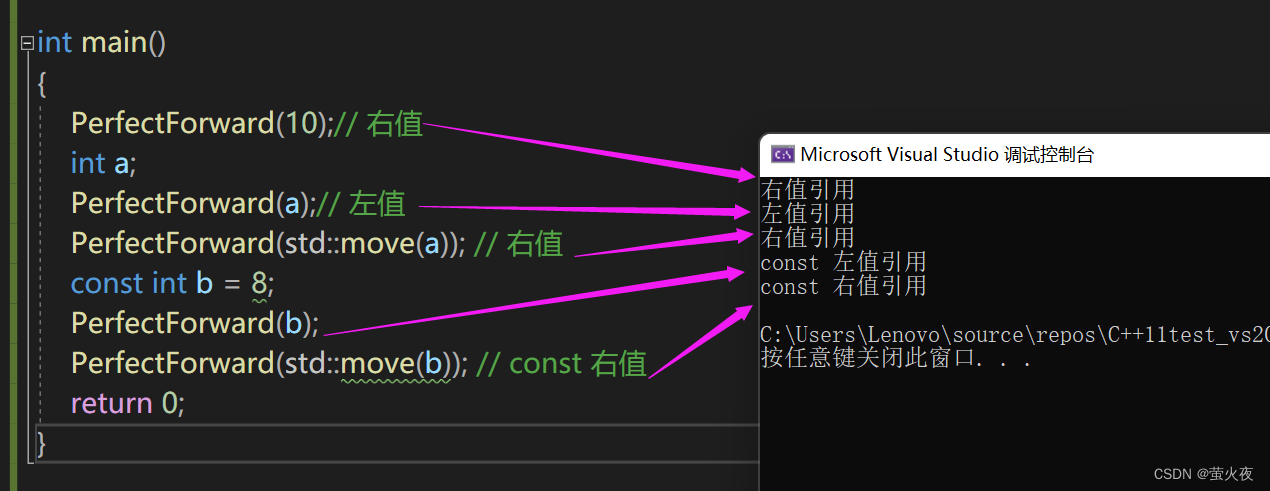
int main()
{PerfectForward(10);// 右值int a;PerfectForward(a);// 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b);//左值PerfectForward(std::move(b)); // const 右值return 0;
}我们传的是左值, 那参数t就是左值引用, 我们传的是右值, 参数t就是右值引用, 所以有些地方也把它叫做引用折叠, 我们传左值的时候, 它好像就把&&折叠了一下一样.
但是, 大家看到我们这里接收t之后又往下传了一层, 把t传给了Fun(), 在PerfectForward函数内部t又往下传给了Fun, 那传给Fun的话t会匹配什么呢?
为什么全部匹配的都是左值引用?
上面提到过:
右值不能取地址, 但是给右值取别名后, 会导致右值被存储到特定位置, 且可以取到该位置的地址, (有名的)右值引用具有左值属性.
这样设计其实是合理的,比如之前的场景:

所以模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力, 但是引用类型的唯一作用就是限制了接收的类型, 后续使用中都退化成了左值, 我们希望能够在传递过程中保持它的左值或者右值的属性, 就需要用我们下面的完美转发.
完美转发及其应用场景
先拷贝一份模拟实现的list:
namespace test
{template<class T>struct list_node{list_node<T>* _next;list_node<T>* _prev;T _data;list_node(const T& x = T()):_next(nullptr), _prev(nullptr), _data(x){}};// 1、迭代器要么就是原生指针// 2、迭代器要么就是自定义类型对原生指针的封装,模拟指针的行为template<class T, class Ref, class Ptr>struct __list_iterator{typedef list_node<T> node;typedef __list_iterator<T, Ref, Ptr> self;node* _node;__list_iterator(node* n):_node(n){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}self& operator++(){_node = _node->_next;return *this;}self operator++(int){self tmp(*this);_node = _node->_next;return tmp;}self& operator--(){_node = _node->_prev;return *this;}self operator--(int){self tmp(*this);_node = _node->_prev;return tmp;}bool operator!=(const self& s){return _node != s._node;}bool operator==(const self& s){return _node == s._node;}};template<class T>class list{typedef list_node<T> node;public:typedef __list_iterator<T, T&, T*> iterator;typedef __list_iterator<T, const T&, const T*> const_iterator;iterator begin(){//iterator it(_head->_next);//return it;return iterator(_head->_next);}const_iterator begin() const{return const_iterator(_head->_next);}iterator end(){return iterator(_head);}const_iterator end() const{//iterator it(_head->_next);//return it;return const_iterator(_head);}void empty_init(){_head = new node(T());_head->_next = _head;_head->_prev = _head;}list(){empty_init();}template <class Iterator>list(Iterator first, Iterator last){empty_init();while (first != last){push_back(*first);++first;}}void swap(list<T>& tmp){std::swap(_head, tmp._head);}list(const list<T>& lt){empty_init();list<T> tmp(lt.begin(), lt.end());swap(tmp);}// lt1 = lt3list<T>& operator=(list<T> lt){swap(lt);return *this;}~list(){clear();delete _head;_head = nullptr;}void clear(){iterator it = begin();while (it != end()){//it = erase(it);erase(it++);}}void push_back(const T& x){insert(end(), x);}void push_front(const T& x){insert(begin(), x);}void pop_back(){erase(--end());}void pop_front(){erase(begin());}void insert(iterator pos, const T& x){node* cur = pos._node;node* prev = cur->_prev;node* new_node = new node(x);prev->_next = new_node;new_node->_prev = prev;new_node->_next = cur;cur->_prev = new_node;}iterator erase(iterator pos){assert(pos != end());node* prev = pos._node->_prev;node* next = pos._node->_next;prev->_next = next;next->_prev = prev;delete pos._node;return iterator(next);}private:node* _head;};
}配合上面用的那个string, 把string里面我们添进去的移动拷贝和移动构造我也先注释掉, 然后执行这样一段代码:


全是深拷贝, 不论左值还是右值, 那我们把string的移动构造和移动拷贝放出来:
依然全是深拷贝, 先来一个个研究.
第一个深拷贝其实是在list初始化的时候进行的,
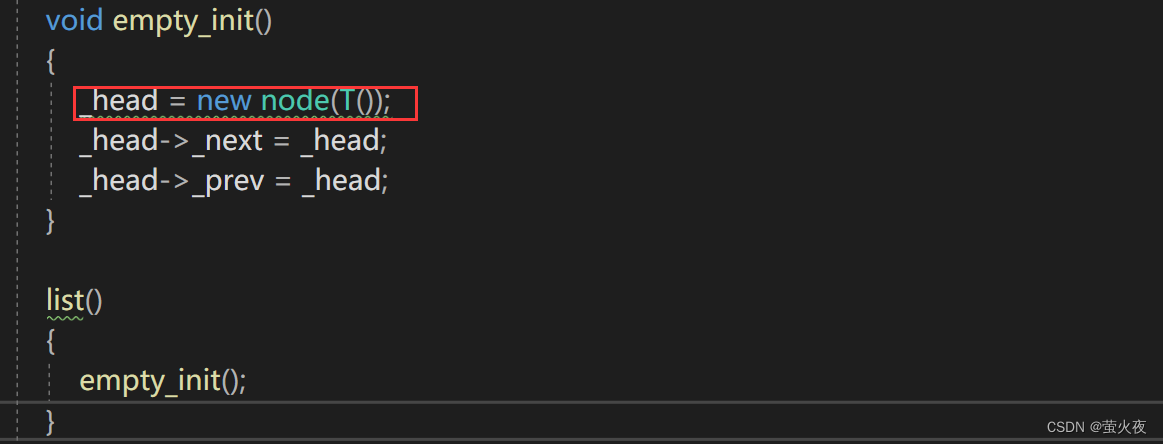
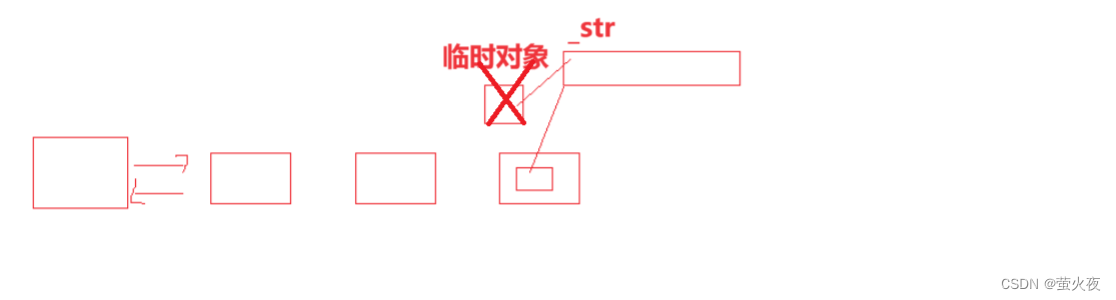
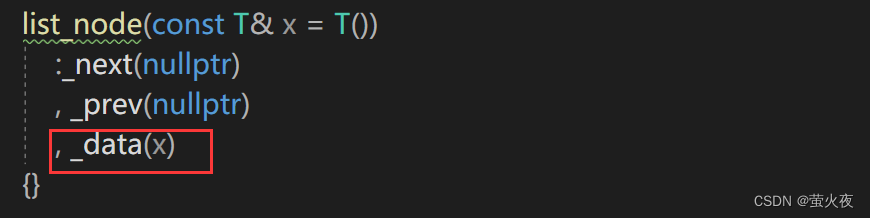 这里_data的初始化还是深拷贝, 所以list_node可以添加一个右值引用版本构造:
这里_data的初始化还是深拷贝, 所以list_node可以添加一个右值引用版本构造:


但是发现还是深拷贝, 这就是上面说到的问题, 右值被右值引用后就变成了左值, 虽然能进入右值引用版本的构造里, 但 _data(x)里的x还是会被识别成左值, 所以可以move(x)

这样_data调用的就是移动构造了.
第二行的深拷贝是不能避免的, 因为它push_back 的是左值, 只能去拷贝构造.

第三和第四行的深拷贝都可以优化, 因为参数是右值, 所以给list的push_back增加右值引用的版本 :
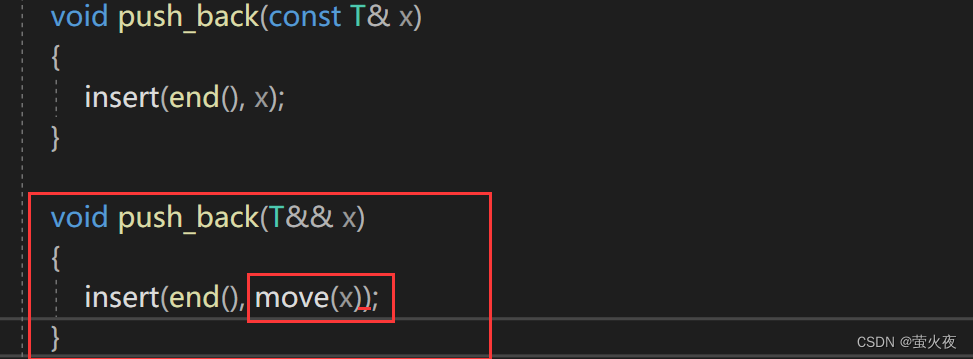
这里存在和上面一样的问题, x是有名的右值引用, 是左值, 需要move成右值传递下去.
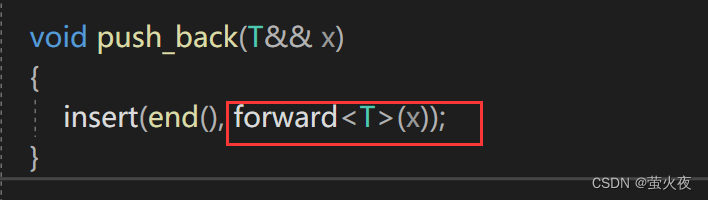
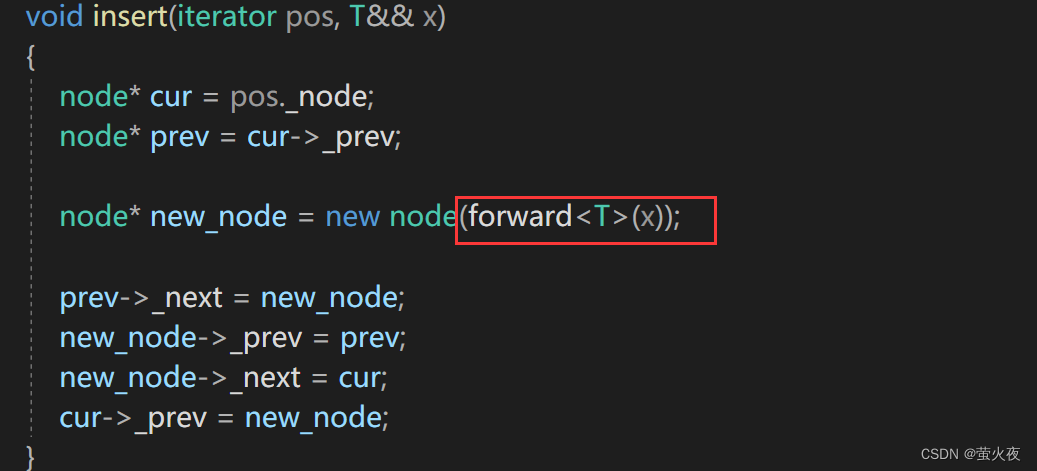
push_back里复用的insert也需要一份右值引用版本:


这样就可以实现右值引用版本的插入接口函数, 但上面的场景用move就可以实现, 回到最开始的那个问题, 只靠move实现不了:
这样又全变成了右值引用, 而我们想要的是参数在传递过程中保持它的左值或者右值的属性, 完美转发就是用来解决这个问题.
完美转发是为了解决传递参数时的临时对象(右值)被强制转换为左值的问题。在C++03中, 可以使用泛型引用来实现完美转发, 但是需要写很多重载函数, 非常繁琐。而在C++11中,引入了std::forward, 可以更简洁地实现完美转发.
因此, 概括来说, std::forward实现完美转发主要用于以下场景:提高模板函数参数传递过程的转发效率。
如何只想在传递过程中保持它的左值或者右值的属性, 这就要用到完美转发. std::forward是C++11中引入的一个函数模板,用于实现完美转发(Perfect Forwarding)。它的作用是根据传入的参数,决定将参数以左值引用还是右值引用的方式进行转发, 也就是说在传参的过程中保留对象原生类型属性.

在给Fun传参的时候进行一次完美转发就可以了.
list里的x用完美转发也可以转换成右值:
新的类功能
默认成员函数
原来C++类中, 有6个默认成员函数:
1. 构造函数
2. 析构函数
3. 拷贝构造函数
4. 拷贝赋值重载
5. 取地址重载
6. const 取地址重载
最后重要的是前4个, 后两个用处不大.
默认成员函数就是我们不写编译器会生成一个默认的, C++11 新增了两个: 移动构造函数和移动赋值运算符重载, 但它们的要求很严格.
针对移动构造函数和移动赋值运算符重载有一些需要注意的点如下:
如果你没有自己实现移动构造函数, 且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任
意一个, 那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数, 对于内置类型成员会执行逐成员按字节拷贝, 自定义类型成员, 则需要看这个成员是否实现移动构造, 如果实现了就调用移动构造, 没有实现就调用拷贝构造.
如果你没有自己实现移动赋值重载函数, 且没有实现析构函数 、拷贝构造、拷贝赋值重载中
的任意一个, 那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内
置类型成员会执行逐成员按字节拷贝, 自定义类型成员, 则需要看这个成员是否实现移动赋
值, 如果实现了就调用移动赋值, 没有实现就调用拷贝赋值.(默认移动赋值跟上面移动构造
完全类似)
如果你提供了移动构造或者移动赋值, 编译器不会自动提供拷贝构造和拷贝赋值.
比如下面这个Person类, 先把拷贝构造, 赋值重载和析构屏蔽, 以保证它会自动生成一个默认移动构造和移动赋值:
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}/*Person(const Person& p):_name(p._name),_age(p._age){}*//*Person& operator=(const Person& p){if(this != &p){_name = p._name;_age = p._age;}return *this;}*//*~Person(){}*/private:test::string _name;int _age;
};int main()
{Person s1;Person s2 = s1;Person s3 = std::move(s1);Person s4;s4 = std::move(s2);return 0;
}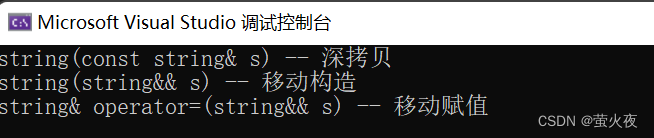
可以看到s2正常调用string拷贝构造, s3和s4都分别调用了移动构造和移动赋值.
如果实现三个函数中其中一个:


就不会生成默认的移动构造和移动赋值, 像之前一样内置类型值拷贝, 自定义类型调用它的拷贝构造.
另外, 如果满足了移动构造的条件但是自定义类型成员没有移动构造, 那还是会去调用它的拷贝构造.
总结:
移动构造的条件看起来很苛刻, 但其实也不算, 因为这三个函数(析构函数+拷贝构造函数+拷贝赋值重载)正常情况下是绑定在一起的, 一般情况下一个类需要实现析构就需要实现拷贝构造和拷贝赋值重载, 这三个一般不会单独出现, 因为析构说明有资源需要释放, 就说明需要有深拷贝. 而如果实现了拷贝构造和拷贝赋值重载, 说明移动构造和移动赋值也需要自己实现, 因为内部的哪些资源需要移动式由自己决定.
类成员变量初始化
C++11允许在类定义时给成员变量初始缺省值, 默认生成构造函数会使用这些缺省值初始化, 这个我们在之前的类和对象章节说了.
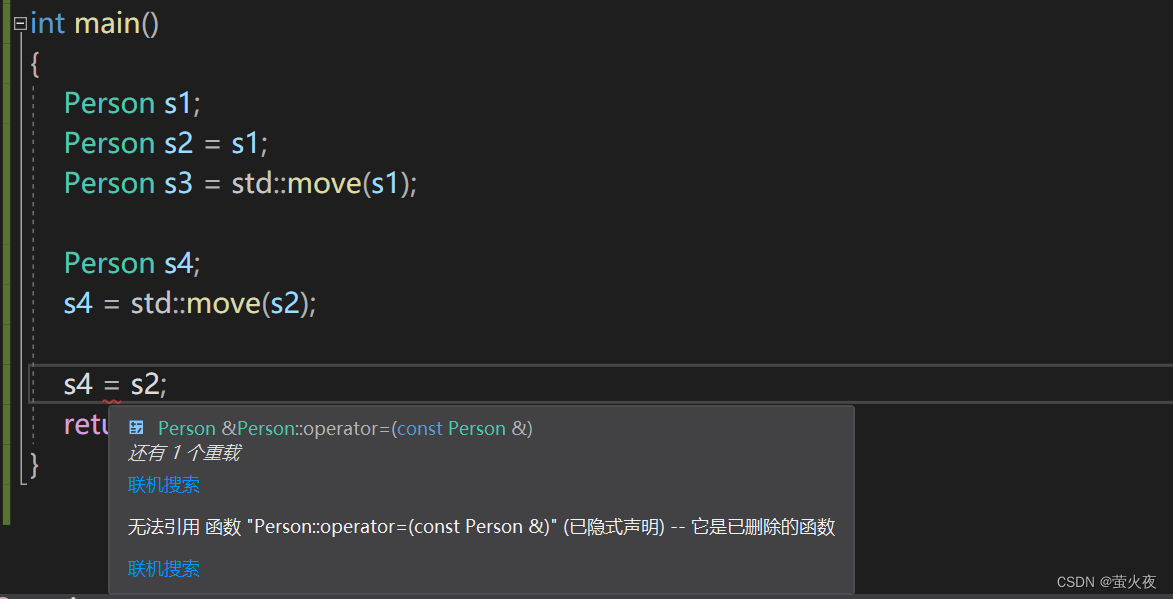
强制生成默认函数的关键字default:
C++11可以让你更好的控制要使用的默认函数, 假设你要使用某个默认的函数, 但是因为一些原
因这个函数没有默认生成.
比如: 我们提供了拷贝构造, 就不会生成移动构造了, 那么我们可以使用default关键字显示指定移动构造生成.
假如现在Person类里的析构有打印的需求, 但这样移动构造就无法默认生成, 这时就可以使用default关键字.

生成了默认的移动构造, 拷贝构造就不会默认生成, 所以这里要有一个拷贝构造, 可以自己写也可以用default默认生成一个, 这里用default生成一个默认的.
生成了默认的移动赋值, 拷贝赋值重载就要自己生成, 但因为这里main函数没用到拷贝赋值重载,所以生不生成都可以:

 如果用到了拷贝赋值重载, 那还是需要生成一个拷贝赋值重载, 不管是默认的还是自己实现一个:
如果用到了拷贝赋值重载, 那还是需要生成一个拷贝赋值重载, 不管是默认的还是自己实现一个:
禁止生成默认函数的关键字delete:
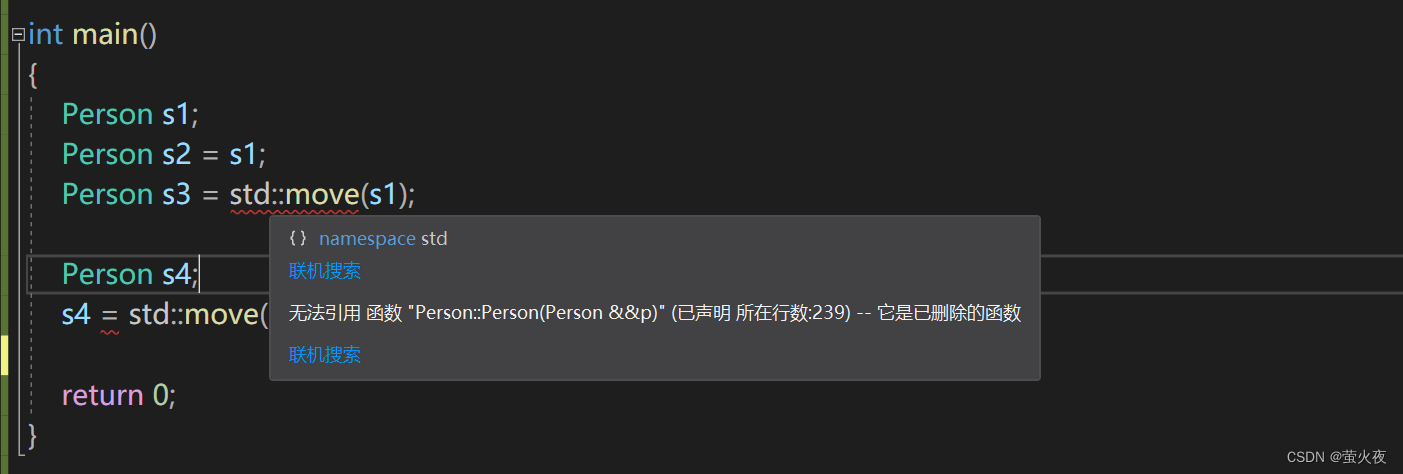
如果能想要限制某些默认函数的生成, 在C++98中, 是该函数设置成private, 并且只声明补丁
已, 这样只要其他人想要调用就会报错. 在C++11中更简单, 只需在该函数声明加上=delete即
可, 该语法指示编译器不生成对应函数的默认版本, 称=delete修饰的函数为删除函数.
比如不想让右值被拷贝, 可以加一个delete:

继承和多态中的final与override关键字
final和override已经在继承和多态章节进行了介绍.
参考阅读:
一文读懂C++右值引用和std::move - 知乎 (zhihu.com)
相关文章:
C++11(上)
统一的列表初始化 首先要说明: 这个列表初始化和类和对象那里的初始化列表不是一个概念. {} 初始化 在C98中, 标准允许使用花括号{}对数组或者结构体元素进行统一的列表初始值设定. 比如: C语言里面其实就是这样支持的, 所以可以认为C支持这样就是因为要兼容C. 在…...

web前端开发规范、HTML规范、JavaScript规范、style规范
MENU 前言目的 HTML规范用法规范注释规范 CSS规范用法规范书写顺序样式覆盖注释规范 JavaScript规范用法规范组件选项注释规范 命名规范目录命名图片命名文件命名方法命名样式命名常用词 工程结构目录构建代码风格 Git规范分支说明使用说明 相关连接 前言 目的 规范的目的是为…...
骨传导耳机会影响听力么?盘点骨传导耳机的好处与坏处都有哪些?
先说结论,使用骨传导耳机是不会影响听力的!并且由于骨传导耳机的特殊传声原理,相比于传统的入耳式耳机,骨传导耳机拥有更多的优点,下面带大家了解一下骨传导耳机的优点和缺点都有哪些。 一、骨传导耳机的优点是什么&a…...

前端与VR/AR:代码的魔法穿越
摘要: 前端开发者们,快戴上VR头盔,准备好进入未知的虚拟世界!本文将深度解析前端如何携手VR/AR技术,创造出更为奇妙的用户体验,同时以幽默的笔调诠释这场代码与虚拟现实的魔法邂逅。 引言 在前端的世界中…...
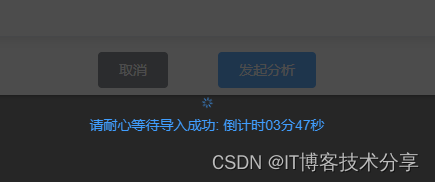
elment Loading 加载组件动态变更 text 值bug记录
先上效果图: 倒计时4分钟组件方法 // 倒计时 4分钟getSencond() {this.countDown 4分00秒this.interval setInterval(() > {this.maxTime--;let minutes Math.floor(this.maxTime / 60);let seconds Math.floor(this.maxTime % 60);minutes minutes < 10 ? 0 minu…...

Typora免费版安装教程(仅供学习)
目录 一、Typora简介二、Typora安装三、Typora补丁四、Typora使用体验五、总结 一、Typora简介 Typora是一款非常流行的Markdown编辑器,它能够将Markdown文本转化为漂亮的排版,并且支持实时预览。Typora具有简单易用的界面,使得用户可以轻松地…...
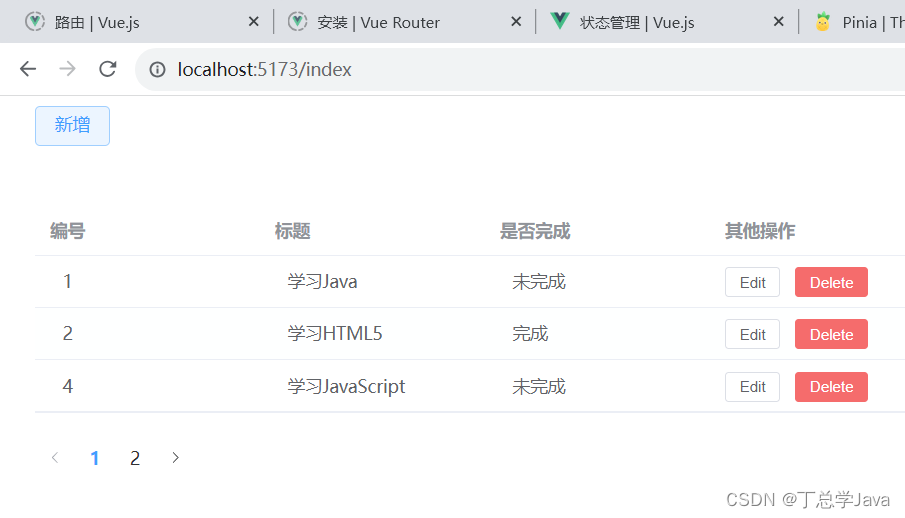
SSM项目实战-前端-添加分页控件-调正页面布局
1、Index.vue <template><div class"common-layout"><el-container><el-header><el-row><el-col :span"24"><el-button type"primary" plain click"toAdd">新增</el-button></el-…...

C语言从入门到实战——常用字符函数和字符串函数的了解和模拟实现
常用字符函数和字符串函数的了解和模拟实现 前言1. 字符分类函数2. 字符转换函数3. strlen的使用和模拟实现4. strcpy的使用和模拟实现5. strcat的使用和模拟实现6. strcmp的使用和模拟实现7. strncpy函数的使用8. strncat函数的使用9. strncmp函数的使用10. strstr的使用和模拟…...
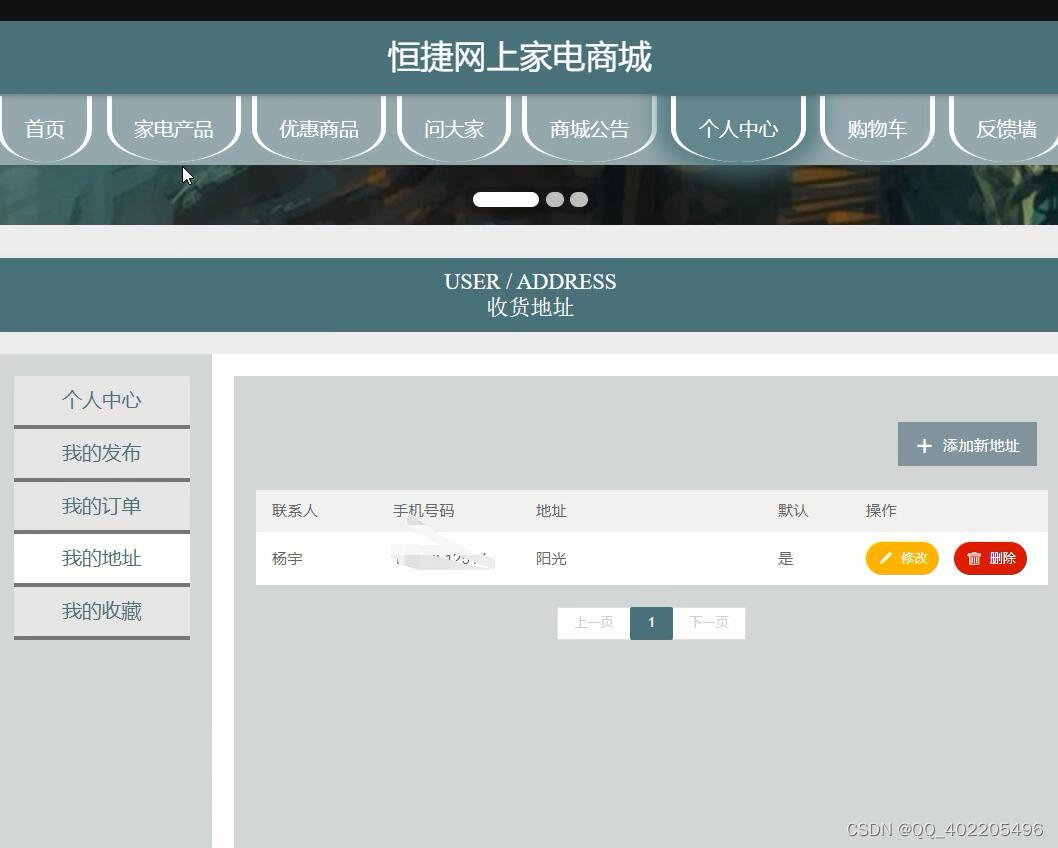
nodejs+vue+elementui网上家电家用电器数码商城购物网站 多商家
基于vue.js的恒捷网上家电商城系统根据实际情况分为前后台两部分,前台部分主要是让用户购物使用的,包括用户的注册登录,查看公告,查看和搜索商品信息,根据分类定位不同类型的商品,将喜欢的商品加入购物车&a…...
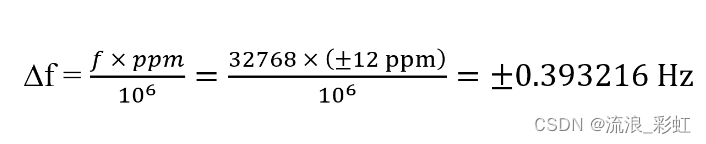
32.768KHz时钟RTC晶振精度PPM值及频差计算
一个数字电路就像一所城市的交通,晶振的作用就是十字路口的信号灯,因此晶振的品质及其电路应用尤其关键。数字电路又像生命体,它的运行就像人身体里的血液流通,它不是由单一的某个器件或器件单元构成,而是由多个器件及…...
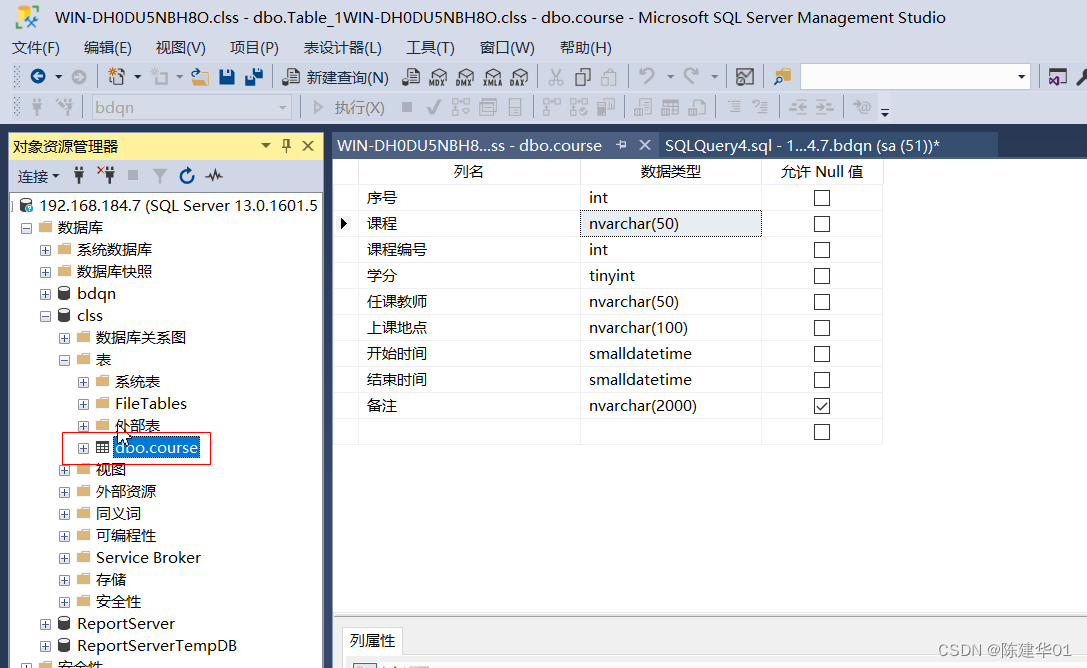
SQL Server 数据库,创建数据表
2.3表的基本概念 表是包含数据库中所有数据的数据库对象。数据在表中的组织方式与在电子表格中相似,都是 按行和列的格式组织的,每行代表一条唯一的记录,每列代表记录中的一个字段.例如,在包含公 司员工信息的表中,每行…...
Vue3引入markdown编辑器--Bytemd
字节跳动开源了一款markdown编辑器,bytemd,项目地址:GitHub - bytedance/bytemd: ByteMD v1 repository 安装 npm i bytemd/vue-next 引入方式如下,再main.js中引入样式 import bytemd/dist/index.css 直接封装一个Markdown编…...

JS实现基数排序
基数排序(Radix Sort)作为一种非比较性的排序算法,以其独特的思想和高效的性能而受到广泛关注。本文将深入研究基数排序的原理、实现方式等。 什么是基数排序 公众号:Code程序人生,个人网站:https://creato…...

【蓝桥杯】二分查找
二分查找 题目描述 输入 n n n 个不超过 1 0 9 10^9 109 的单调不减的(就是后面的数字不小于前面的数字)非负整数 a 1 , a 2 , … , a n a_1,a_2,\dots,a_{n} a1,a2,…,an,然后进行 m m m 次询问。对于每次询问,给出一…...

大于2T磁盘划分并挂接
需要挂接9T多的磁盘做数据磁盘,记录下操作过程 1、使用fdisk -l识别到磁盘 # fdisk -l|grep 9.5 TiB Disk /dev/sdd: 9.5 TiB, 10453950398464 bytes, 20417871872 sectors Disk /dev/sdf: 9.5 TiB, 10453950398464 bytes, 20417871872 sectors Disk /dev/sdh: 9.…...

蓝桥杯每日一题2023.12.3
题目描述 1.移动距离 - 蓝桥云课 (lanqiao.cn) 题目分析 对于此题需要对行列的关系进行一定的探究,所求实际上为曼哈顿距离,只需要两个行列的绝对值想加即可,预处理使下标从0开始可以更加明确之间的关系,奇数行时这一行的数字需…...

Nacos源码解读04——服务发现
Nacos服务发现的方式 1.客户端获取 1.1:先是故障转移机制判断是否去本地文件中读取信息,读到则返回 1.2:再去本地服务列表读取信息(本地缓存),没读到则创建一个空的服务,然后立刻去nacos中读取更新 1.3:读到了就返回,同时开启定时…...
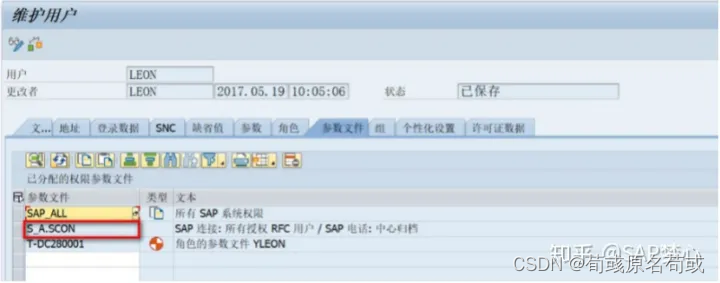
SAP系统邮件功能配置 SCOT <转载>
原文链接:https://zhuanlan.zhihu.com/p/71594578 相信SAP顾问或多或少都会接到用户要求SAP系统能够定时发送邮件的功能,定时将用户需要的信息已邮件的方式发送给固定的人员。 下面就来讲一下SAP发送邮件应该如何配置: 1、RZ10做配置&#…...

数据结构——二叉树(相关术语、性质、遍历过程)
遍历操作 二叉树的层次遍历-CSDN博客 二叉树的基本操作-CSDN博客 二叉树的先序遍历非递归实现-CSDN博客 后序遍历的非递归方式实现-CSDN博客 二叉树:已知先序中序求后序或者其他(秒解)-CSDN博客 因为之前发过一遍,我就不复制…...

详细学习Pyqt5的9种显示控件
Pyqt5相关文章: 快速掌握Pyqt5的三种主窗口 快速掌握Pyqt5的2种弹簧 快速掌握Pyqt5的5种布局 快速弄懂Pyqt5的5种项目视图(Item View) 快速弄懂Pyqt5的4种项目部件(Item Widget) 快速掌握Pyqt5的6种按钮 快速掌握Pyqt5的10种容器&…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...