Zookeeper+Kafka集群
注:本章使用的Kafka为2.7.0版本
Zookeeper概述
1.Zookeeper定义
Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。
2.Zookeeper工作机制
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
也就是说 Zookeeper = 文件系统 + 通知机制。
3.Zookeeper特点
- (1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
- (2)Zookeepe集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
- (3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
- (4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行,即先进先出。
- (5)数据更新原子性,一次数据更新要么成功,要么失败。
- (6)实时性,在一定时间范围内,Client能读到最新数据。
4.Zookeeper数据结构
ZooKeeper数据模型的结构与Linux文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
5.Zookeeper应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
●统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。
●统一配置管理
(1)分布式环境下,配置文件同步非常常见。一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群。对配置文件修改后,希望能够快速同步到各个节点上。
(2)配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper上的一个Znode。
各个客户端服务器监听这个Znode。一旦 Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
●统一集群管理
(1)分布式环境中,实时掌握每个节点的状态是必要的。可根据节点实时状态做出一些调整。
(2)ZooKeeper可以实现实时监控节点状态变化。可将节点信息写入ZooKeeper上的一个ZNode。
监听这个ZNode可获取它的实时状态变化。
●服务器动态上下线
客户端能实时洞察到服务器上下线的变化。
●软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
5.Zookeeper选举机制
●第一次启动选举机制
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。
服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。
此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
●非第一次启动选举机制
(1)当ZooKeeper 集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
1)服务器初始化启动。
2)服务器运行期间无法和Leader保持连接。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
1)集群中本来就已经存在一个Leader。
对于已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,
对于该机器来说,仅仅需要和 Leader机器建立连接,并进行状态同步即可。
2)集群中确实不存在Leader。
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,
并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
选举Leader规则:
- 1.EPOCH大的直接胜出
- 2.EPOCH相同,事务id大的胜出
- 3.事务id相同,服务器id大的胜出
注:
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。
在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑速度有关。
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。
每投完一次票这个数据就会增加
部署Zookeeper集群
1.实验组件
#准备3台服务器做Zookeeper集群
20.0.0.10
20.0.0.20
20.0.0.302.安装前准备
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0#安装JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version#将apache-zookeeper-3.5.7-bin.tar.gz压缩包上传至/opt目录3.安装Zookeeper
#三台服务器一齐操作
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /opt/zookeeper#修改配置文件
cd /opt/zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
--2--
tickTime=2000
#通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒--5--
initLimit=10
#Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s--8--
syncLimit=5
#Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer--12--修改
dataDir=/opt/zookeeper/data
#指定保存Zookeeper中的数据的目录,目录需要单独创建--添加--
dataLogDir=/opt/zookeeper/logs
#指定存放日志的目录,目录需要单独创建--15--
clientPort=2181
#客户端连接端口--末尾添加集群信息--
server.1=20.0.0.10:3188:3288
server.2=20.0.0.20:3188:3288
server.3=20.0.0.30:3188:3288

#在每个节点上创建数据目录和日志目录
mkdir /opt/zookeeper/data
mkdir /opt/zookeeper/logs#在每个节点的dataDir指定的目录下创建一个 myid 的文件,不同节点分配1、2、3
echo 1 > /opt/zookeeper/data/myid
echo 2 > /opt/zookeeper/data/myid
echo 3 > /opt/zookeeper/data/myid#配置 Zookeeper 启动脚本
vim /etc/init.d/zookeeper#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/opt/zookeeper'
case $1 in
start)echo "---------- zookeeper 启动 ------------"$ZK_HOME/bin/zkServer.sh start
;;
stop)echo "---------- zookeeper 停止 ------------"$ZK_HOME/bin/zkServer.sh stop
;;
restart)echo "---------- zookeeper 重启 ------------"$ZK_HOME/bin/zkServer.sh restart
;;
status)echo "---------- zookeeper 状态 ------------"$ZK_HOME/bin/zkServer.sh status
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac#设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper#分别启动 Zookeeper
service zookeeper start#查看当前状态
service zookeeper status
Kafka概述
1.为什么需要消息队列
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
2.使用消息队列的好处
(1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
在软件系统中,解耦的概念与上述比喻类似。高度耦合的系统中,各个组件之间的关系非常紧密,修改其中一个组件可能会影响其他组件。而低耦合的系统中,各个组件之间的关系更加独立,修改一个组件不会波及其他组件。
解耦使得系统更容易维护、扩展和修改,因为它减少了组件之间的依赖性。
(2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
(3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。
如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。
使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
(5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3.消息队列的两种模式
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
(2)发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目标对象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
RabbitMQ:
RabbitMQ支持点对点模型,其中消息生产者将消息发送到队列,而消息消费者从队列中接收和处理消息。
Apache Kafka:
Kafka的消息发布/订阅模型也可以被视为一种点对点通信模型,特别是在具有多个消费者时。
每个消费者组中的消费者将收到相同的消息,实现了一对多的发布/订阅和一对一的点对点模型。
4.Kafka定义
Kafka是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据实时处理领域。
5.Kafka特性
●高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。
每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力。
●可扩展性
kafka 集群支持热扩展
●持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
●容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
●高并发
支持数千个客户端同时读写
6.Kafka系统架构
经纪人(Broker):Kafka集群由多个经纪人组成,每个经纪人是一台运行Kafka服务的服务器。
经纪人存储主题分区中的数据,处理生产者和消费者的请求,以及维护元数据。
主题(Topic):Kafka数据流的基本单元是主题,它类似于一个数据流管道。生产者将数据发布到主题,而消费者从主题中订阅数据。主题可以被分区,每个分区可以看作是主题的子数据流,具有自己的偏移量(Offset)。
分区(Partition):每个主题可以分成多个分区,每个分区是数据的有序子集。分区允许Kafka进行水平扩展,以处理大量数据。消息在分区中按照偏移量有序存储,消费者可以独立读取每个分区的数据。
副本(Replica):为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
Leader:每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
Follower:Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写。如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
生产者(Producer):生产者是将数据发布到Kafka主题的组件。它负责将消息写入主题,生产者可以将消息发送到指定的主题和分区。
消费者(Consumer):消费者是从Kafka主题中读取数据的组件。它可以订阅一个或多个主题,
然后从主题的分区中读取消息。每个消费者都有一个唯一的消费者组ID,Kafka通过消费者组来实现负载均衡和容错性。
消费者组(Consumer Group):由多个 consumer 组成,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的组。将多个消费者集中到一起去处理某一个 Topic 的数据,可以更快的提高数据的消费能力。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,防止数据被重复读取。消费者组之间互不影响。
偏移量(Offset):偏移量是每个消息在分区中的唯一标识,消费者使用偏移量来跟踪已读取的消息位置。偏移量存储在Kafka中,消费者可以通过提交偏移量来记录已处理的消息。
Zookeeper:Kafka 通过 Zookeeper 来存储集群的 meta 信息。由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。zookeeper的作用就是,生产者push数据到kafka集群,就必须要找到kafka集群的节点在哪里,这些都是通过zookeeper去寻找的。消费者消费哪一条数据,也需要zookeeper的支持,从zookeeper获得offset,offset记录上一次消费的数据消费到哪里,这样就可以接着下一条数据进行消费。
7.Kafka工作流程
生产者将消息发送到指定的主题,每个消息都附带一个可选的键(Key)和值(Value)。
主题可以有多个分区,生产者将消息写入一个分区。
经纪人(Broker)接收到消息后,将其存储在分区中,并分配一个唯一的偏移量。
在 Kafka 中,偏移量(Offset)是一个用于标识消费者在一个特定分区中已经读取到的消息位置的标记。
每个分区的每个消费者都会有一个偏移量,它表示下一条将要读取的消息的位置。
偏移量是一个64位的整数,表示在分区中消息的唯一位置。
Kafka 的消息是持久化的,一旦消息被写入分区,它就会保留一段时间,供消费者在需要时读取。
通过使用偏移量,消费者可以准确地指定它想要从哪个位置开始消费消息。
偏移量的重要性体现在以下几个方面:
消息的唯一标识: 每个消息都有一个在分区内的唯一偏移量,它可以被用作消息的全局唯一标识。
精确的消费位置: 消费者可以通过指定偏移量,精确地确定从哪个位置开始消费消息。
这是在重新启动消费者或者切换到不同的消费者时非常有用的功能。
消费者组的偏移量管理: 在消费者组中,Kafka 会追踪每个消费者的偏移量。
当新的消费者加入或离开消费者组时,Kafka 负责协调和管理这些消费者的偏移量。
至少一次语义: 消费者可以选择手动提交偏移量,确保消息至少被消费一次。
这是通过将偏移量与成功处理消息的应用程序逻辑关联来实现的。
在 Kafka 中,有两种类型的偏移量:
消费者组偏移量(Group Offsets): 由 Kafka 内部管理,用于追踪消费者组中每个消费者的偏移量。
自定义偏移量(Commit Offsets): 由应用程序管理,消费者可以选择手动提交偏移量,以实现更细粒度的偏移量控制。
消费者订阅一个或多个主题,并从指定分区中读取消息。消费者使用偏移量来跟踪已读取的消息。
消费者可以以不同的速率读取消息,Kafka支持多个消费者组,每个组可以独立消费消息,从而实现负载均衡和水平扩展。
Kafka保留消息一定的时间,这个时间可以配置,一般情况下,已读取的消息会被保留一段时间,以便允许消费者重新读取。
Kafka的分布式特性、数据持久性、高吞吐量和水平扩展性使其成为处理大规模数据流的强大工具,可用于多种用途,
包括日志收集、实时数据分析、事件驱动架构等。
部署Kafka集群
1.安装Kafka
cd /opt
--上传kafka_2.13-2.7.0.tgz包--
tar zxvf kafka_2.13-2.7.0.tgz
mv kafka_2.13-2.7.0 kafka/#修改配置文件
cd /opt/kafka/config/
cp server.properties server.properties.bak
vim server.properties
--21--
broker.id=0
#broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2--31--
listeners=PLAINTEXT://20.0.0.10:9092
#指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改--42--
num.network.threads=3
#broker 处理网络请求的线程数量,一般情况下不需要去修改--45--
num.io.threads=8
#用来处理磁盘IO的线程数量,数值应该大于硬盘数--48--
socket.send.buffer.bytes=102400
#发送套接字的缓冲区大小--51--
socket.receive.buffer.bytes=102400
#接收套接字的缓冲区大小--54--
socket.request.max.bytes=104857600
#请求套接字的缓冲区大小--60--
log.dirs=/var/log/kafka
#kafka运行日志存放的路径,也是数据存放的路径--65--
num.partitions=1
topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖--69--
num.recovery.threads.per.data.dir=1
#用来恢复和清理data下数据的线程数量--103--
log.retention.hours=168
#segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除--110--
log.segment.bytes=1073741824
#一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
#Kafka 以日志文件的形式维护其数据,而这些日志文件被分割成多个日志段。当一个日志段达到指定的大小时,就会创建一个新的日志段。--123--
zookeeper.connect=20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181
#配置连接Zookeeper集群地址#修改全局配置
vim /etc/profile
--添加--
export KAFKA_HOME=/opt/kafka
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile#配置Zookeeper启动脚本
vim /etc/init.d/kafka#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/opt/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac#设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka#分别启动Kafka
service kafka start2.Kafka命令行操作
#创建topic
kafka-topics.sh --create --zookeeper 20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181 --replication-factor 2 --partitions 3 --topic test1----------------------------------------------------------------------------------------
--bootstrap-server:定义 bootstrap-server 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个IP即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
----------------------------------------------------------------------------------------#查看当前服务器钟的所有topic
kafka-topics.sh --list --zookeeper 20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181#查看某个topic的详情
[root@apache config]# kafka-topics.sh --describe --zookeeper 20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181
Topic: test1 PartitionCount: 3 ReplicationFactor: 2 Configs: Topic: test1 Partition: 0 Leader: 0 Replicas: 0,2 Isr: 0Topic: test1 Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0Topic: test1 Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1----------------------------------------------------------------------------------------
Partition:分区编号 Leader:每个分区都有一个领导者(Leader),领导者负责处理分区的读写操作。Replicas:每个分区可以有多个副本(Replicas),用于提供冗余和容错性。Isr:ISR(In-Sync Replicas)表示当前与领导者保持同步的副本。
----------------------------------------------------------------------------------------#发布消息
kafka-console-producer.sh --broker-list 20.0.0.10:9092,20.0.0.20:9092,20.0.0.30:9092 --topic test1#消费消息
kafka-console-consumer.sh --bootstrap-server 20.0.0.10:9092,20.0.0.20:9092,20.0.0.30:9092 --topic test1 --from-beginning
#--from-beginning:会把主题中以往所有的数据都读取出来#修改分区数
kafka-topics.sh --zookeeper 20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181 --alter --topic test1 --partitions 6#删除 topic
kafka-topics.sh --delete --zookeeper 20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181 --topic test1


相关文章:
Zookeeper+Kafka集群
注:本章使用的Kafka为2.7.0版本 Zookeeper概述 1.Zookeeper定义 Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。 2.Zookeeper工作机制 Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理…...
Sunshine+Moonlight+Android手机串流配置(局域网、无手柄)
目录 前言Sunshine(服务端)ApplicationConfigurationGeneralAdvance Moonlight(客户端)配对打开虚拟手柄串流按键调整退出串流 原神,启动! 前言 写这篇文章单纯是因为搜来搜去没有很符合我需求的教程&#…...
 并由函数返回被删元素的值。空出的位 置由最后一个元素填补,若顺序表为空,则显示出错信息并退出运行。)
从顺序表中删除具有最小值的元素(假设唯一) 并由函数返回被删元素的值。空出的位 置由最后一个元素填补,若顺序表为空,则显示出错信息并退出运行。
题目描述:从顺序表中删除具有最小值的元素(假设唯一) 并由函数返回被删元素的值。空出的位置由最后一个元素填补,若顺序表为空,则显示出错信息并退出运行。 bool DeleteMin(SqList &L,int &min){if(L.length 0)return false;min L…...
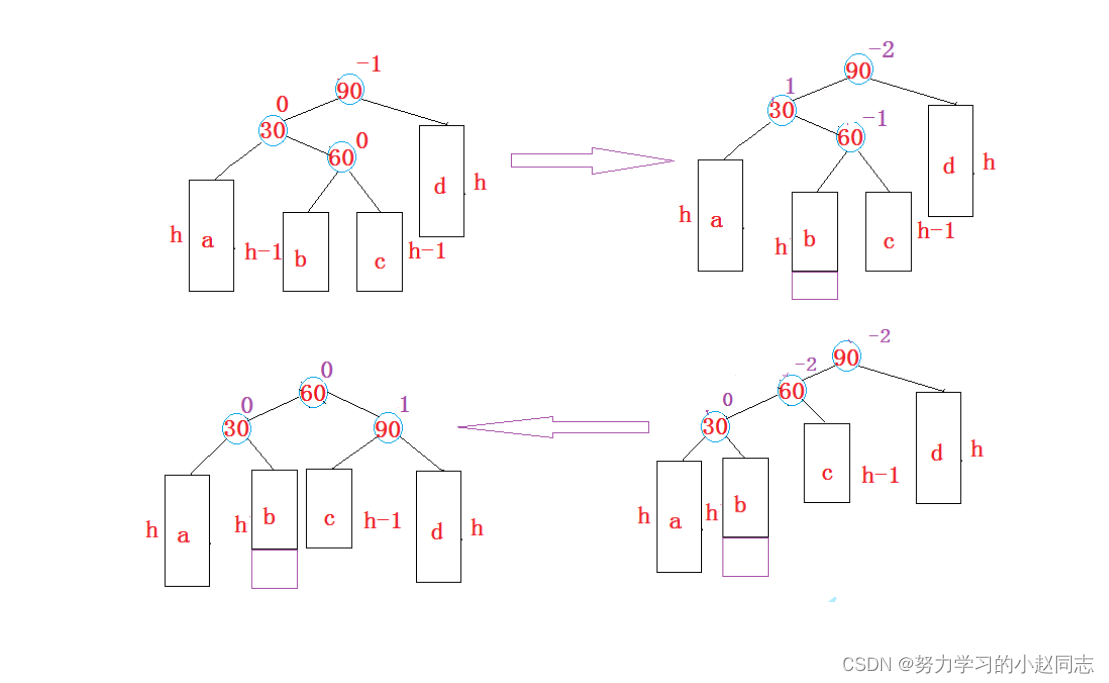
详解—[C++ 数据结构]—AVL树
目录 一.AVL树的概念 二、AVL树节点的定义 三、AVL树的插入 3.1插入方法 四、AVL树的旋转 1. 新节点插入较高左子树的左侧---左左:右单旋 2. 新节点插入较高右子树的右侧---右右:左单旋 3.新节点插入较高左子树的右侧---左右:先左单旋…...
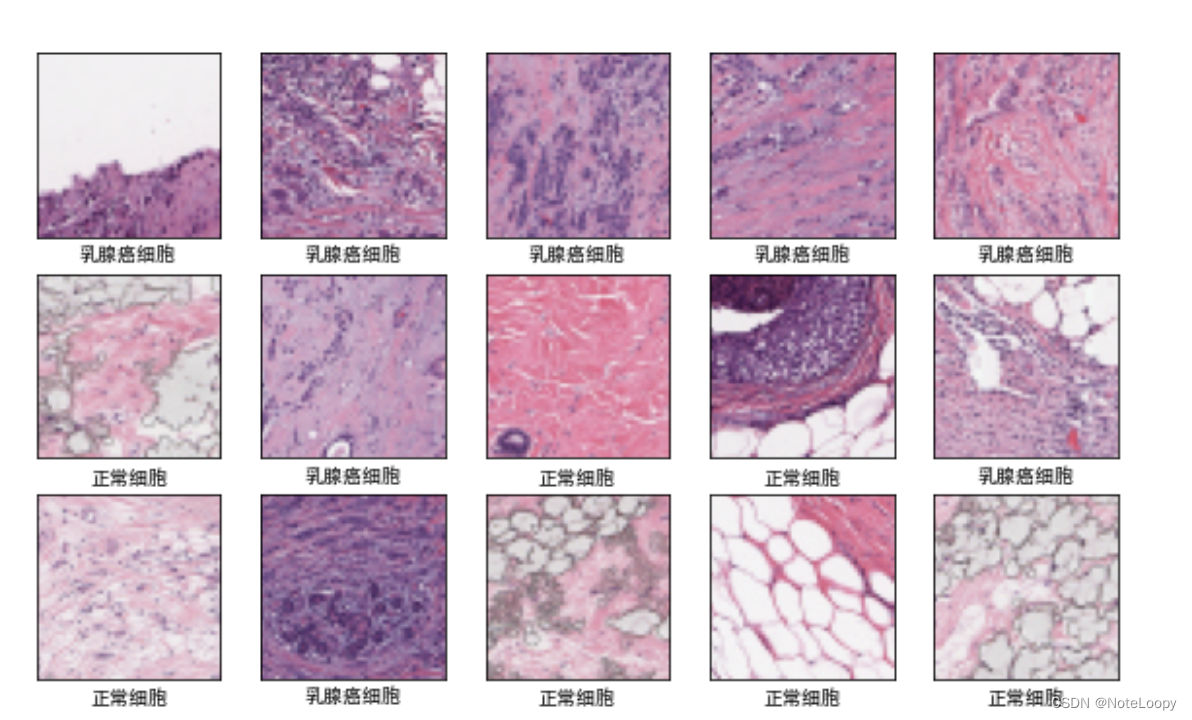
卷积神经网络(CNN):乳腺癌识别.ipynb
文章目录 一、前言一、设置GPU二、导入数据1. 导入数据2. 检查数据3. 配置数据集4. 数据可视化 三、构建模型四、编译五、训练模型六、评估模型1. Accuracy与Loss图2. 混淆矩阵3. 各项指标评估 一、前言 我的环境: 语言环境:Python3.6.5编译器…...
有文件实体的后门无文件实体的后门rootkit后门
有文件实体后门和无文件实体后门&RootKit后门 什么是有文件的实体后门: 在传统的webshell当中,后门代码都是可以精确定位到某一个文件上去的,你可以rm删除它,可以鼠标右键操作它,它是有一个文件实体对象存在的。…...

GPT实战系列-大模型训练和预测,如何加速、降低显存
GPT实战系列-大模型训练和预测,如何加速、降低显存 不做特别处理,深度学习默认参数精度为浮点32位精度(FP32)。大模型参数庞大,10-1000B级别,如果不注意优化,既耗费大量的显卡资源,…...

SQL Sever 基础知识 - 数据排序
SQL Sever 基础知识 - 二 、数据排序 二 、对数据进行排序第1节 ORDER BY 子句简介第2节 ORDER BY 子句示例2.1 按一列升序对结果集进行排序2.2 按一列降序对结果集进行排序2.3 按多列对结果集排序2.4 按多列对结果集不同排序2.5 按不在选择列表中的列对结果集进行排序2.6 按表…...

vscode配置使用 cpplint
标题安装clang-format和cpplint sudo apt-get install clang-format sudo pip3 install cpplint标题以下settings.json文件放置xxx/Code/User目录 settings.json {"sync.forceDownload": false,"workbench.sideBar.location": "right","…...
C++ 系列 第四篇 C++ 数据类型上篇—基本类型
系列文章 C 系列 前篇 为什么学习C 及学习计划-CSDN博客 C 系列 第一篇 开发环境搭建(WSL 方向)-CSDN博客 C 系列 第二篇 你真的了解C吗?本篇带你走进C的世界-CSDN博客 C 系列 第三篇 C程序的基本结构-CSDN博客 前言 面向对象编程(OOP)的…...
C++ 指针详解
目录 一、指针概述 指针的定义 指针的大小 指针的解引用 野指针 指针未初始化 指针越界访问 指针运算 二级指针 指针与数组 二、字符指针 三、指针数组 四、数组指针 函数指针 函数指针数组 指向函数指针数组的指针 回调函数 指针与数组 一维数组 字符数组…...

.locked、locked1勒索病毒的最新威胁:如何恢复您的数据?
导言: 网络安全问题变得愈加严峻。.locked、locked1勒索病毒是近期备受关注的一种恶意软件,给用户的数据带来了巨大威胁。本文将深入探讨.locked、locked1勒索病毒的特征,探讨如何有效恢复被其加密的数据,并提供一些建议…...
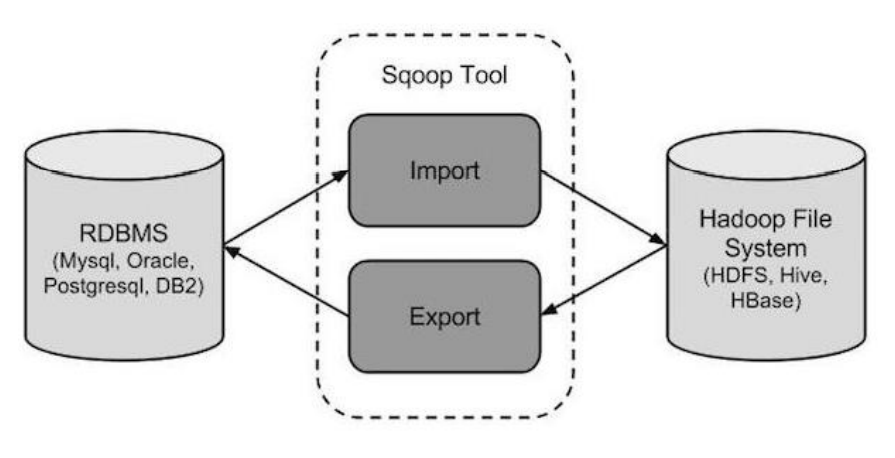
Apache Sqoop使用
1. Sqoop介绍 Apache Sqoop 是在 Hadoop 生态体系和 RDBMS 体系之间传送数据的一种工具。 Sqoop 工作机制是将导入或导出命令翻译成 mapreduce 程序来实现。在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。 Hadoop 生态系统包括:HDFS、Hi…...

【UGUI】实现UGUI背包系统的六个主要交互功能
在这篇教程中,我们将详细介绍如何在Unity中实现一个背包系统的六个主要功能:添加物品、删除物品、查看物品信息、排序物品、搜索物品和使用物品。让我们开始吧! 一、添加物品 首先,我们需要创建一个方法来添加新的物品到背包中。…...
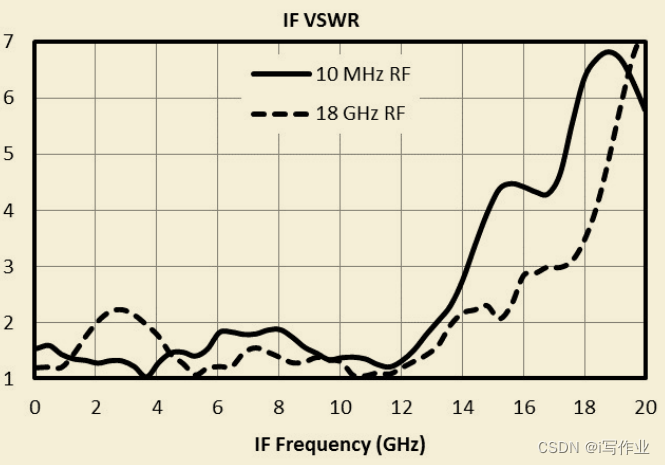
电压驻波比
电压驻波比 关于IF端口的电压驻波比 一个信号变频后,从中频端口输出,它的输出跟输入是互异的。这个电压柱波比反映了它输出的能量有多少可以真正的输送到后端连接的器件或者设备。...

Open3D 最小二乘拟合二维直线(直接求解法)
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。爬虫网站自重。 一、算法原理 平面直线的表达式为: y = k x + b...
)
面试题目总结(二)
1. IoC 和 AOP 的区别 控制反转(Ioc) 和面向切面编程(AOP) 是两个不同的概念,它们在软件设计中有着不同的应用和目的。 IoC 是一种基于对象组合的编程模式,通过将对象的创建、依赖关系和生命周期等管理权交给外部容器或框架来实现程序间的解耦。IoC 的…...

TrustZone概述
目录 一、概述 1.1 在开始之前 二、什么是TrustZone? 2.1 Armv8-M的TrustZone 2.2 Armv9-A Realm Management Ext...

[go 面试] Go Kit中读取原始HTTP请求体的方法
关注公众号【爱发白日梦的后端】分享技术干货、读书笔记、开源项目、实战经验、高效开发工具等,您的关注将是我的更新动力! 在Go Kit中,如果你想读取未序列化的HTTP请求体,可以使用标准的net/http包来实现。以下是一个示例,演示了如何完成这个任务: package mainimport …...

小程序如何刷新当前页面?
在小程序中,刷新当前页面通常有两种方法: 使用 wx.navigateBack 方法: wx.navigateBack({delta: 1 }) 这将返回上一页,并刷新页面。你可以通过调整 delta 参数来控制返回的页面数。例如,如果你想要返回到两页之前的页…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

接口自动化测试:HttpRunner基础
相关文档 HttpRunner V3.x中文文档 HttpRunner 用户指南 使用HttpRunner 3.x实现接口自动化测试 HttpRunner介绍 HttpRunner 是一个开源的 API 测试工具,支持 HTTP(S)/HTTP2/WebSocket/RPC 等网络协议,涵盖接口测试、性能测试、数字体验监测等测试类型…...