CSV文件中使用insert 函数在指定列循环插入不同数据
文章目录
- 一、系统、工具要求
- 二、需求
- 三、代码实现:
- 四、核心代码解读
- 五、逐行更改某一列数据
- 六:实现在文件的末尾增加指定内容列
一、系统、工具要求
- pandas
- python
- csv
Windows 系统
二、需求
我有两个文件:
文件一:subject_main.csv
文件二:merged_file.csv
其中,文件一与文件二的ID列是有关系,就是,这两个文件的ID列的值是一样的,但是位置可能不一样。
现在有个需求就是,将 subject_main.csv 中,ID 所在的 subject_main 列的值,存入到 文件一:subject_main.csv中 ID列值与文件二ID值相同的行。
举个例子:
文件一:
有:
ID ,name,age,class
10005,’ ’ ,’ ‘,’ ’
10008,’ ’ ,’ ‘,’ ’
文件二:
有:
ID,身高
10008,155
10005,185
我希望的最终输出的文件是:
ID ,name,age,身高,class
10005,’ ’ ,’ ‘,’ ‘,185,’ ’
10008,’ ‘,’ ‘,’ ‘,155,’ ’
明白需求了吧=====
三、代码实现:
import pandas as pd# 读取第一个csv文件
df1 = pd.read_csv('subject_main.csv')# 读取第二个csv文件
df2 = pd.read_csv('merged_file.csv')if 'subject_main' not in df2.columns:df2.insert(2, 'subject_main', " ")# 遍历第一个csv文件的每一行
a = 1
for index, row in df1.iterrows():id_value_1 = row['id'] # 获取当前行的ID值id_value_2 = df2['id']# 在第二个文件中查找相同ID的行matching_row = df2.index[id_value_2 == id_value_1].tolist()# print(matching_row)for i in matching_row:df2.at[i, 'subject_main'] = row['subject']a += 1print(f'出于数据的第:{a}行')# # # 将更新后的DataFrame保存为新的csv文件
df2.to_csv('new_data.csv', index=False)
四、核心代码解读
# 如果df2中存在相同的ID值,则更新其'subject_main'列
matching_indices = df2.index[df2['id'] == id_value_1].tolist()
for i in matching_indices:df2.at[i, 'subject_main'] = row['subject']
1… matching_indices = df2.index[df2['id'] == id_value_1].tolist():
df2['id'] == id_value_1:这个表达式比较df2中的’id’列的每个值是否等于从df1中提取的id_value_1。这会返回一个布尔序列(True或False值)。
df2.index[...]:取出满足条件的那些行的索引。
.tolist():将这些索引转换成Python列表。
2 … for i in matching_indices::这个循环遍历刚才找到的匹配索引的列表。
3… df2.at[i, 'subject_main'] = row['subject']:
df2.at[i, 'subject_main']:at是pandas的一个函数,用来快速访问某个特定的单元格。这里它用于访问df2中索引为i的行、列名为'subject_main'的单元格。
row['subject']:这是在当前迭代中从df1的当前行获取的'subject'列的值。
整条语句的意思是将df1中当前行的'subject'列的值赋给df2中索引为i、列名为'subject_main'的单元格。
… …结合在一起,这段代码就是在对df1进行迭代的过程中,对于每一行,都在df2中找到与之id值相同的所有行,并将这些行的'subject_main'列更新为df1中该行的'subject'列的值。这样,就实现了将df1中的某些数据插入到df2中指定的位置。
五、逐行更改某一列数据
源码实现:
import csvname_column_values = []# 需要更改的文件
with open('new_data.csv', 'r', encoding='utf-8') as file:reader = csv.DictReader(file)for row in reader:name_value = row['id'] # 获取'ID'列的值new_value = "PRO" + name_valuerow['id'] = new_value # 更新'ID'列的值name_column_values.append(row)fieldnames = reader.fieldnames# 新生成的文件
with open('new_data_2.csv', 'w', newline='', encoding='utf-8') as file:writer = csv.DictWriter(file, fieldnames=fieldnames)writer.writeheader()writer.writerows(name_column_values)
代码实现的是,上面文件的中的ID列数值,进行一些基本改造
六:实现在文件的末尾增加指定内容列
with open(fileName, 'r', encoding='utf-8') as file:reader = csv.DictReader(file)rows = list(reader)
print(rows)
# # 添加新列的数据
for row in rows:# 在这里根据需要进行逻辑处理,计算新列的值new_value = "Product"row[':LABEL'] = new_value #增加一个名字为 ':LABEL' 的列。
# 将修改后的数据写入新的CSV文件
fieldnames = reader.fieldnames
# fieldnames = reader.fieldnames
# with open('./newdata.csv', 'w', newline='', encoding='utf-8') as file:
with open(newFileName, 'w', newline='', encoding='utf-8') as file:writer = csv.DictWriter(file, fieldnames=fieldnames)writer.writeheader()writer.writerows(rows)
其中的参数说明:
fileName:需要增加内容的文件
newFileName:新增后生成的内容
在NLP中,计算序列相似度可以使用多种方法,从简单的字符串匹配到复杂的语义分析,以下是一些常见的技术:
编辑距离(Levenshtein距离): 这是一个衡量两个字符串相似度的经典方法,它通过计算将一个字符串转换成另一个字符串所需的最少单字符编辑操作次数(插入、删除或替换)来表示。
余弦相似度: 在这种方法中,文本首先被转换为向量(例如,使用词袋模型),然后计算这两个向量之间的余弦角度,以此来度量它们的相似性。
Jaccard相似度: 这种方法计算两组之间的交集与并集的比例,通常用于衡量基于集合(如单词集合)的相似度。
n-gram重叠: n-gram是一个序列中连续的n项,通常用来衡量两个文本序列的局部相似性。比较两个序列共有的n-gram数量可以提供它们的相似度。
基于词嵌入的相似度: 用预训练的词嵌入(如Word2Vec或GloVe)来表示文本,可以捕捉到词汇的语义信息,然后通过计算向量之间的距离(如余弦距离)来衡量相似性。
序列对齐: 比如Smith-Waterman算法和Needleman-Wunsch算法,这些主要用于生物信息学中,但在考虑到结构化文本数据时也可以借鉴。
变换器模型(如BERT, GPT-3): 这些先进的深度学习模型能够生成具有丰富语义层面相似度的文本表示,适合更复杂的相似性判断任务。
语义文本相似度(Semantic Textual Similarity, STS): 该任务涉及计算两个文本片段的相似度得分,通常是在0到1或者0到5之间,代表从不相关到完全语义相同的程度。
选择哪种方法取决于特定应用场景和需求。在实际操作中,可能需要根据任务的特点和数据的性质进行调整和优化。
相关文章:

CSV文件中使用insert 函数在指定列循环插入不同数据
文章目录 一、系统、工具要求二、需求三、代码实现:四、核心代码解读五、逐行更改某一列数据六:实现在文件的末尾增加指定内容列 一、系统、工具要求 pandaspythoncsv Windows 系统 二、需求 我有两个文件: 文件一:subject_ma…...
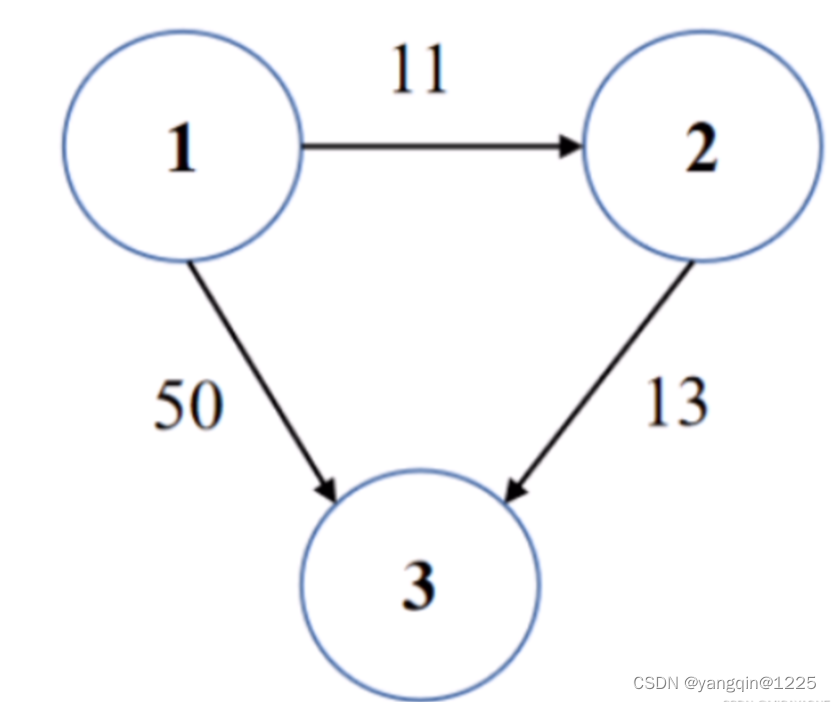
【华为OD题库-064】最小传输时延I-java
题目 某通信网络中有N个网络结点,用1到N进行标识。网络通过一个有向无环图.表示,其中图的边的值表示结点之间的消息传递时延。 现给定相连节点之间的时延列表times[]{u,v, w),其中u表示源结点,v表示目的结点࿰…...
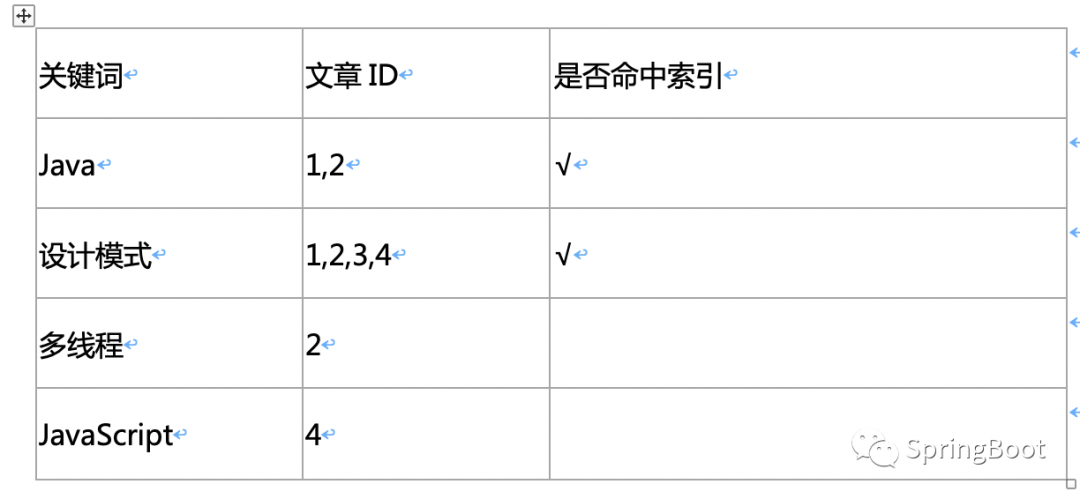
全文检索[ES系列] - 第495篇
历史文章(文章累计490) 《国内最全的Spring Boot系列之一》 《国内最全的Spring Boot系列之二》 《国内最全的Spring Boot系列之三》 《国内最全的Spring Boot系列之四》 《国内最全的Spring Boot系列之五》 《国内最全的Spring Boot系列之六》 M…...

【预计IEEE出版|EI征稿通知】第六届下一代数据驱动网络国际学术会议 (NGDN 2024)
第六届下一代数据驱动网络国际学术会议 (NGDN 2024) The Sixth International Conference on Next Generation Data-driven Networks 2024年4月26-28日 | 中国沈阳 基于前几届在英国埃克塞特 (ISPA 2020) 、中国沈阳 (TrustCom 2021) 和中国武汉 (IEEETrustCom-2022) 成功举…...

C++软件在Win平台运行总结
Windows平台: 1.需要安装运行库:无论是exe还是动态库用的哪种平台工具集(visual2010-visual2019)进行编译,需要安装对应的运行时库vc_redist.x64.exe/vc_redist.x86.exe。比如Exe用的是VisualStdio2010工具集编译,其中链接的一个…...
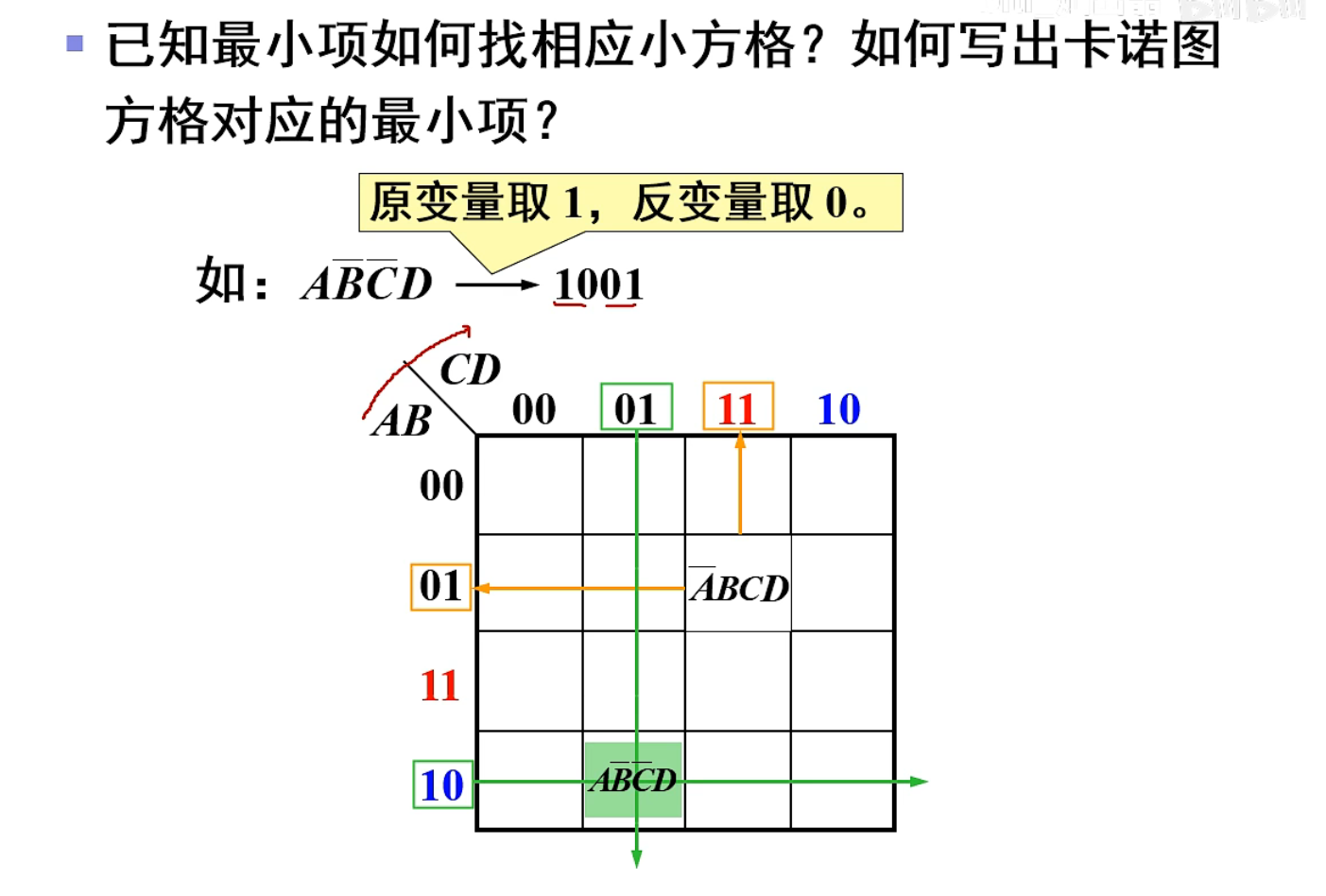
【数电笔记】16-卡诺图绘制(逻辑函数的卡诺图化简)
目录 说明: 最小项卡诺图的组成 1. 相邻最小项 2. 卡诺图的组成 2.1 二变量卡诺图 2.2 三表变量卡诺图 2.3 四变量卡诺图 3. 卡诺图中的相邻项(几何相邻) 说明: 笔记配套视频来源:B站;本系列笔记并…...
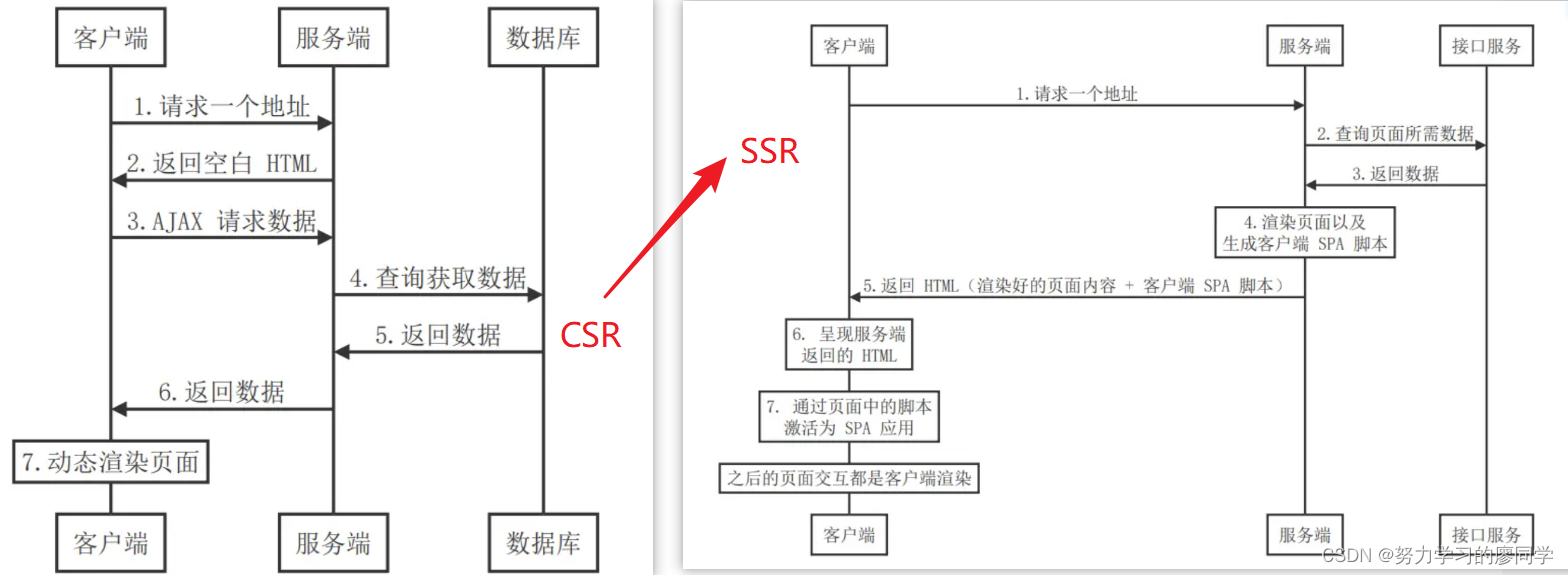
前端面试灵魂提问(1)
1.自我介绍 2.在实习中,你负责那一模块 3.any与unknow的异同 相同点:any和unkonwn 可以接受任何值 不同点:any会丢掉类型限制,可以用any 类型的变量随意做任何事情。unknown 变量会强制执行类型检查,所以在使用一个…...
Linux中项目部署步骤
安装jdk,tomcat 安装步骤 1,将压缩包,拷贝到虚拟机中。 通过工具,将文件直接拖到虚拟机的/home下 2,回到虚拟机中,查看/home下,有两个压缩文件 3,给压缩文件做解压缩操作 tar -z…...

cmd下查看python命令的用法
在cmd下,可以运行python --help或者py --help来查看python命令的用法。例如:...
)
大型语言模型在实体关系提取中的应用探索(二)
上一篇文章我们探讨了如何使用大语言模型进行实体关系的抽取。本篇文章我们将进一步探索这个话题。比较一下国内外几款知名大模型在相同的实体关系提取任务下的表现。由于精力有限,我们无法全面测试各模型的实体关系抽取能力,因此,看到的效果…...

Easy Excel设置表格样式
1. 设置通用样式 import com.alibaba.excel.annotation.ExcelProperty; import com.alibaba.excel.annotation.write.style.*; import com.fasterxml.jackson.annotation.JsonFormat; import com.xxx.npi.config.easypoi.EasyExcelDateConverter; import lombok.Data; import …...
HarmonyOS/OpenHarmony应用开发
OpenHarmony是由开放原子开源基金会(OpenAtom Foundation)孵化及运营的开源项目, 目标是面向全场景、全连接、全智能时代, 搭建一个智能终端设备操作系统的框架和平台, 促进万物互联产业的繁荣发展。 了解OpenHarmony HarmonyOS是华为通过OpenHarmony项目,结合商业…...
孩子都能学会的FPGA:第二十一课——用线性反馈移位寄存器实现伪随机序列
(原创声明:该文是作者的原创,面向对象是FPGA入门者,后续会有进阶的高级教程。宗旨是让每个想做FPGA的人轻松入门,作者不光让大家知其然,还要让大家知其所以然!每个工程作者都搭建了全自动化的仿…...

国内 AI 成图第一案!你来你会怎么判?
我国目前并未出台专门针对网络爬虫技术的法律规范,但在司法实践中,相关判决已屡见不鲜,K 哥特设了“K哥爬虫普法”专栏,本栏目通过对真实案例的分析,旨在提高广大爬虫工程师的法律意识,知晓如何合法合规利用…...

快速登录界面关于如何登录以及多账号列表解析以及config配置文件是如何读取(1)
快速登录界面关于如何登录以及多账号列表解析以及config配置文件是如何读取 1、快速登录界面关于如何登录以及快速登录界面账号如何显示 如图所示:根据按下按钮一键登录中途会发生什么。 关于一键登录按钮皮肤skin的设置: <Button name"QuickLoginOkBtn" text&q…...
finebi 新手入门案例
finebi 新手入门案例 连锁超市销售数据分析 步骤: 准备公共数据新建分析主题处理数据在数据中分析在图形中分析数据大屏 准备公共数据 点击公共数据 点击新建文件夹 修改文件夹名称 上传数据 鼠标悬停在文件夹上,右侧出现 鼠标悬停在文件夹上&#x…...
)
1. 小游戏(贪心)
题干: 谷同学很喜欢玩计算机游戏,特别是战略游戏,但是有时他不能尽快找到解所以常常感到很沮丧。现在面临如下问题:他必须在一个中世纪的城堡里设防,城堡里的道路形成一棵无向树。要在结点上安排最少的士兵使得他们可以…...

记录 | c++打印变量类型
c打印变量类型: 使用 typeid(变量名).name() int main(){std::cout << "type of ss : " << typeid(ss).name() << std::endl; }...
nodejs_vue+vscode美容理发店会员管理系统un1dm
按照设计开发一个系统的常用流程来描述系统,可以把系统分成分析阶段,设计阶段,实现阶段,测试阶段。所以在编写系统的说明文档时,根据系统所处的阶段来描述系统的内容。 绪论:这是对选题的背景,意…...
C语言 操作符详解
C语言学习 目录 文章目录 前言 一、算术操作符 二、移位操作符 2.1 左移操作符 2.2 右移操作符 三、位操作符 3.1 按位与操作符 & 3.2 按位或操作符 | 3.3 按位异或操作符 ^ 四、赋值操作符 五、单目操作符 5.1 逻辑反操作符! 5.2 正值、负值-操作符 5.3 取地址…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量 Hermes Agent 是一个流行的 AI 代理开发框架࿰…...