软著项目推荐 深度学习的智能中文对话问答机器人
文章目录
- 0 简介
- 1 项目架构
- 2 项目的主要过程
- 2.1 数据清洗、预处理
- 2.2 分桶
- 2.3 训练
- 3 项目的整体结构
- 4 重要的API
- 4.1 LSTM cells部分:
- 4.2 损失函数:
- 4.3 搭建seq2seq框架:
- 4.4 测试部分:
- 4.5 评价NLP测试效果:
- 4.6 梯度截断,防止梯度爆炸
- 4.7 模型保存
- 5 重点和难点
- 5.1 函数
- 5.2 变量
- 6 相关参数
- 7 桶机制
- 7.1 处理数据集
- 7.2 词向量处理seq2seq
- 7.3 处理问答及答案权重
- 7.4 训练&保存模型
- 7.5 载入模型&测试
- 8 最后
0 简介
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的中文对话问答机器人
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 项目架构
整个项目分为 数据清洗 和 建立模型两个部分。
(1)主要定义了seq2seq这样一个模型。
首先是一个构造函数,在构造函数中定义了这个模型的参数。
以及构成seq2seq的基本单元的LSTM单元是怎么构建的。
(2)接着在把这个LSTM间单元构建好之后,加入模型的损失函数。
我们这边用的损失函数叫sampled_softmax_loss,这个实际上就是我们的采样损失。做softmax的时候,我们是从这个6000多维里边找512个出来做采样。
损失函数做训练的时候需要,测试的时候不需要。训练的时候,y值是one_hot向量
(3)然后再把你定义好的整个的w[512*6000]、b[6000多维],还有我们的这个cell本身,以及我们的这个损失函数一同代到我们这个seq2seq模型里边。然后呢,这样的话就构成了我们这样一个seq2seq模型。
函数是tf.contrib.legacy_seq2seq.embedding_attention_seq2seq()
(4)最后再将我们传入的实参,也就是三个序列,经过这个桶的筛选。然后放到这个模型去训练啊,那么这个模型就会被训练好。到后面,我们可以把我们这个模型保存在model里面去。模型参数195M。做桶的目的就是节约计算资源。
2 项目的主要过程
前提是一问一答,情景对话,不是多轮对话(比较难,但是热门领域)
整个框架第一步:做语料
先拿到一个文件,命名为.conv(只要不命名那几个特殊的,word等)。输入目录是db,输出目录是bucket_dbs,不存在则新建目录。
测试的时候,先在控制台输入一句话,然后将这句话通过正反向字典Ids化,然后去桶里面找对应的回答的每一个字,然后将输出通过反向字典转化为汉字。
2.1 数据清洗、预处理
读取整个语料库,去掉E、M和空格,还原成原始文本。创建conversion.db,conversion表,两个字段。每取完1000组对话,插入依次数据库,批量提交,通过cursor.commit.
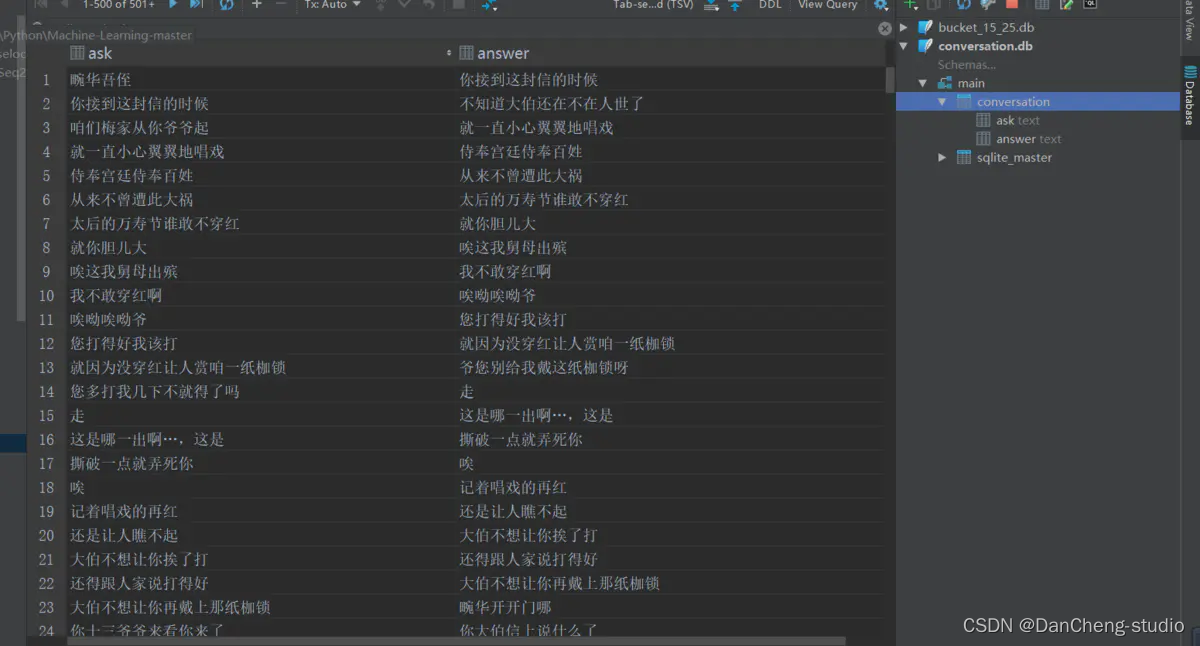
2.2 分桶
从总的conversion.db中分桶,指定输入目录db, 输出目录bucket_dbs.
检测文字有效性,循环遍历,依次记录问题答案,每积累到1000次,就写入数据库。
for ask, answer in tqdm(ret, total=total):if is_valid(ask) and is_valid(answer):for i in range(len(buckets)):encoder_size, decoder_size = buckets[i]if len(ask) <= encoder_size and len(answer) < decoder_size:word_count.update(list(ask))word_count.update(list(answer))wait_insert.append((encoder_size, decoder_size, ask, answer))if len(wait_insert) > 10000000:wait_insert = _insert(wait_insert)break
将字典维度6865未,投影到100维,也就是每个字是由100维的向量组成的。后面的隐藏层的神经元的个数是512,也就是维度。
句子长度超过桶长,就截断或直接丢弃。
四个桶是在read_bucket_dbs()读取的方法中创建的,读桶文件的时候,实例化四个桶对象。
2.3 训练
先读取json字典,加上pad等四个标记。
lstm有两层,attention在解码器的第二层,因为第二层才是lstm的输出,用两层提取到的特征越好。
num_sampled=512, 分批softmax的样本量(
训练和测试差不多,测试只前向传播,不反向更新
3 项目的整体结构
s2s.py:相当于main函数,让代码运行起来
里面有train()、test()、test_bleu()和create_model()四个方法,还有FLAGS成员变量,
相当于静态成员变量 public static final string
decode_conv.py和data_utils.py:是数据处理
s2s_model.py:
里面放的是模型
里面有init()、step()、get_batch_data()和get_batch()四个方法。构造方法传入构造方法的参数,搭建S2SModel框架,然后sampled_loss()和seq2seq_f()两个方法
data_utils.py:
读取数据库中的文件,并且构造正反向字典。把语料分成四个桶,目的是节约计算资源。先转换为db\conversation.db大的桶,再分成四个小的桶。buckets
= [ (5, 15), (10, 20), (15, 25), (20, 30)]
比如buckets[1]指的就是(10, 20),buckets[1][0]指的就是10。
bucket_id指的就是0,1,2,3
dictionary.json:
是所有数字、字母、标点符号、汉字的字典,加上生僻字,以及PAD、EOS、GO、UNK 共6865维度,输入的时候会进行词嵌入word
embedding成512维,输出时,再转化为6865维。
model:
文件夹下装的是训练好的模型。
也就是model3.data-00000-of-00001,这个里面装的就是模型的参数
执行model.saver.restore(sess, os.path.join(FLAGS.model_dir,
FLAGS.model_name))的时候,才是加载目录本地的保存的模型参数的过程,上面建立的模型是个架子,
model = create_model(sess, True),这里加载模型比较耗时,时间复杂度最高
dgk_shooter_min.conv:
是语料,形如: E
M 畹/华/吾/侄/
M 你/接/到/这/封/信/的/时/候/
decode_conv.py: 对语料数据进行预处理
config.json:是配置文件,自动生成的
4 重要的API
4.1 LSTM cells部分:
cell = tf.contrib.rnn.BasicLSTMCell(size)cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=dropout)cell = tf.contrib.rnn.MultiRNNCell([cell] * num_layers)对上一行的cell去做Dropout的,在外面裹一层DropoutWrapper
构建双层lstm网络,只是一个双层的lstm,不是双层的seq2seq
4.2 损失函数:
tf.nn.sampled_softmax_loss( weights=local_w_t,
b labels=labels, #真实序列值,每次一个
inputs=loiases=local_b,
cal_inputs, #预测出来的值,y^,每次一个
num_sampled=num_samples, #512
num_classes=self.target_vocab_size # 原始字典维度6865)
4.3 搭建seq2seq框架:
tf.contrib.legacy_seq2seq.embedding_attention_seq2seq(encoder_inputs, # tensor of input seq 30decoder_inputs, # tensor of decoder seq 30tmp_cell, #自定义的cell,可以是GRU/LSTM, 设置multilayer等num_encoder_symbols=source_vocab_size,# 编码阶段字典的维度6865num_decoder_symbols=target_vocab_size, # 解码阶段字典的维度 6865embedding_size=size, # embedding 维度,512num_heads=20, #选20个也可以,精确度会高点,num_heads就是attention机制,选一个就是一个head去连,5个就是5个头去连output_projection=output_projection,# 输出层。不设定的话输出维数可能很大(取决于词表大小),设定的话投影到一个低维向量feed_previous=do_decode,# 是否执行的EOS,是否允许输入中间cdtype=dtype)4.4 测试部分:
self.outputs, self.losses = tf.contrib.legacy_seq2seq.model_with_buckets(
self.encoder_inputs,
self.decoder_inputs,
targets,
self.decoder_weights,
buckets,
lambda x, y: seq2seq_f(x, y, True),
softmax_loss_function=softmax_loss_function
)
4.5 评价NLP测试效果:
在nltk包里,有个接口叫bleu,可以评估测试结果,NITK是个框架
from nltk.translate.bleu_score import sentence_bleu
score = sentence_bleu(
references,#y值
list(ret),#y^
weights=(1.0,)#权重为1
)
4.6 梯度截断,防止梯度爆炸
clipped_gradients, norm = tf.clip_by_global_norm(gradients,max_gradient_norm)
tf.clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None)
通过权重梯度的总和的比率来截取多个张量的值。t_list是梯度张量, clip_norm是截取的比率,这个函数返回截取过的梯度张量和一个所有张量的全局范数
4.7 模型保存
tf.train.Saver(tf.global_variables(), write_version=tf.train.SaverDef.V2)
5 重点和难点
5.1 函数
def get_batch_data(self, bucket_dbs, bucket_id):
def get_batch(self, bucket_dbs, bucket_id, data):
def step(self,session,encoder_inputs,decoder_inputs,decoder_weights,bucket_id):
5.2 变量
batch_encoder_inputs, batch_decoder_inputs, batch_weights = [], [], []
6 相关参数
model = s2s_model.S2SModel(data_utils.dim, # 6865,编码器输入的语料长度data_utils.dim, # 6865,解码器输出的语料长度buckets, # buckets就是那四个桶,data_utils.buckets,直接在data_utils写的一个变量,就能直接被点出来FLAGS.size, # 隐层神经元的个数512FLAGS.dropout, # 隐层dropout率,dropout不是lstm中的,lstm的几个门里面不需要dropout,没有那么复杂。是隐层的dropoutFLAGS.num_layers, # lstm的层数,这里写的是2FLAGS.max_gradient_norm, # 5,截断梯度,防止梯度爆炸FLAGS.batch_size, # 64,等下要重新赋值,预测就是1,训练就是64FLAGS.learning_rate, # 0.003FLAGS.num_samples, # 512,用作负采样forward_only, #只传一次dtype){"__author__": "qhduan@memect.co","buckets": [[5, 15],[10, 20],[20, 30],[40, 50]],"size": 512,/*s2s lstm单元出来之后的,连的隐层的number unit是512*/"depth": 4,"dropout": 0.8,"batch_size": 512,/*每次往里面放多少组对话对,这个是比较灵活的。如果找一句话之间的相关性,batch_size就是这句话里面的字有多少个,如果要找上下文之间的对话,batch_size就是多少组对话*/"random_state": 0,"learning_rate": 0.0003,/*总共循环20次*/"epoch": 20,"train_device": "/gpu:0","test_device": "/cpu:0"}7 桶机制
7.1 处理数据集
语料库长度桶结构
(5, 10): 5问题长度,10回答长度
每个桶中对话数量,一问一答为一次完整对话
Analysis
(1) 设定4个桶结构,即将问答分成4个部分,每个同种存放对应的问答数据集[87, 69, 36,
8]四个桶中分别有87组对话,69组对话,36组对话,8组对话;
(2) 训练词数据集符合桶长度则输入对应值,不符合桶长度,则为空;
(3) 对话数量占比:[0.435, 0.78, 0.96, 1.0];
7.2 词向量处理seq2seq
获取问答及答案权重
参数:
- data: 词向量列表,如[[[4,4],[5,6,8]]]
- bucket_id: 桶编号,值取自桶对话占比
步骤:
- 问题和答案的数据量:桶的话数buckets = [(5, 10), (10, 15), (20, 25), (40, 50)]
- 生成问题和答案的存储器
- 从问答数据集中随机选取问答
- 问题末尾添加PAD_ID并反向排序
- 答案添加GO_ID和PAD_ID
- 问题,答案,权重批量数据
- 批量问题
- 批量答案
- 答案权重即Attention机制
- 若答案为PAD则权重设置为0,因为是添加的ID,其他的设置为1
Analysis
-
(1) 对问题和答案的向量重新整理,符合桶尺寸则保持对话尺寸,若不符合桶设定尺寸,则进行填充处理,
问题使用PAD_ID填充,答案使用GO_ID和PAD_ID填充; -
(2) 对问题和答案向量填充整理后,使用Attention机制,对答案进行权重分配,答案中的PAD_ID权重为0,其他对应的为1;
-
(3) get_batch()处理词向量;返回问题、答案、答案权重数据;
返回结果如上结果:encoder_inputs, decoder_inputs, answer_weights.
7.3 处理问答及答案权重
参数:session: tensorflow 会话.encoder_inputs: 问题向量列表decoder_inputs: 回答向量列表answer_weights: 答案权重列表bucket_id: 桶编号which bucket of the model to use.forward_only: 前向或反向运算标志位
返回:一个由梯度范数组成的三重范数(如果不使用反向传播,则为无)。平均困惑度和输出
Analysis
-
(1) 根据输入的问答向量列表,分配语料桶,处理问答向量列表,并生成新的输入字典(dict), input_feed = {};
-
(2) 输出字典(dict), ouput_feed = {},根据是否使用反向传播获得参数,使用反向传播,
output_feed存储更新的梯度范数,损失,不使用反向传播,则只存储损失; -
(3) 最终的输出为分两种情况,使用反向传播,返回梯度范数,损失,如反向传播不使用反向传播,
返回损失和输出的向量(用于加载模型,测试效果),如前向传播;
7.4 训练&保存模型
步骤:
-
检查是否有已存在的训练模型
-
有模型则获取模型轮数,接着训练
-
没有模型则从开始训练
-
一直训练,每过一段时间保存一次模型
-
如果模型没有得到提升,减小learning rate
-
保存模型
-
使用测试数据评估模型
global step: 500, learning rate: 0.5, loss: 2.574068747580052 bucket id: 0, eval ppx: 14176.588030763274 bucket id: 1, eval ppx: 3650.0026667220773 bucket id: 2, eval ppx: 4458.454110999805 bucket id: 3, eval ppx: 5290.083583183104
7.5 载入模型&测试
(1) 该聊天机器人使用bucket桶结构,即指定问答数据的长度,匹配符合的桶,在桶中进行存取数据;
(2) 该seq2seq模型使用Tensorflow时,未能建立独立标识的图结构,在进行后台封装过程中出现图为空的现象;
从main函数进入test()方法。先去内存中加载训练好的模型model,这部分最耗时,改batch_size为1,传入相关的参数。开始输入一个句子,并将它读进来,读进来之后,按照桶将句子分,按照模型输出,然后去查字典。接着在循环中输入上句话,找对应的桶。然后拿到的下句话的每个字,找概率最大的那个字的index的id输出。get_batch_data(),获取data [('天气\n', '')],也就是问答对,但是现在只有问,没有答get_batch()获取encoder_inputs=1*10,decoder_inputs=1*20 decoder_weights=1*20step()获取预测值output_logits,

8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
软著项目推荐 深度学习的智能中文对话问答机器人
文章目录 0 简介1 项目架构2 项目的主要过程2.1 数据清洗、预处理2.2 分桶2.3 训练 3 项目的整体结构4 重要的API4.1 LSTM cells部分:4.2 损失函数:4.3 搭建seq2seq框架:4.4 测试部分:4.5 评价NLP测试效果:4.6 梯度截断…...
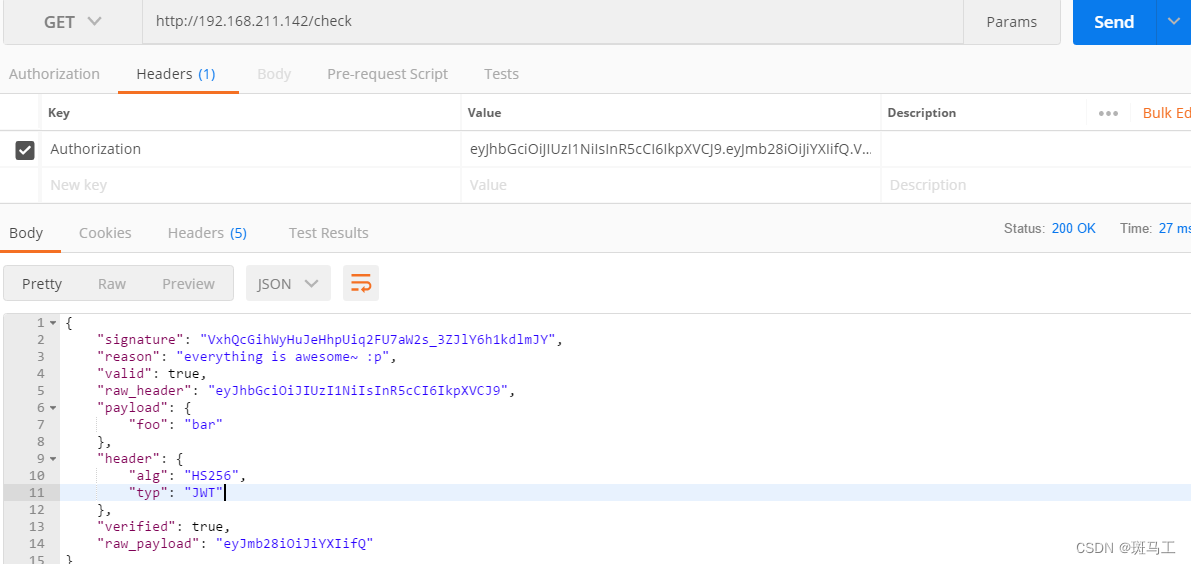
灰度发布专题---3、Nginx+Lua灰度发布
上一章已经讲解了配置文件灰度发布、应用版本灰度发布、API网关灰度发布实现,但如果用户这时候在代理层如何做灰度发布呢? 代理层灰度发布分析 用户无论访问应用服务还是静态页,都要经过Nginx代理层,我们可以在Nginx这里做灰度发…...

冬天来了,波司登的高端化“春天”不远了?
最近,羽绒服频繁“贵”上热搜。 在众多热搜词条中,一条“国产羽绒服卖到7000元”的话题一度将波司登推上了舆论的风口浪尖。 对此,波司登在最新的业绩说明会上进行了回应,公司表示:“波司登旗下主品牌及子品牌将形成差…...

Vue3.0优点详解
相对于Vue2.0 3.0有了比较大的改进,优势主要有以下几点: 一、性能提升 1、Vue3.0的响应式系统使用了Proxy代理对象,取代了Vue2.0中的Object.defineProperty,使得Vue3.0的响应式系统更快、更灵活。 2、Vue3.0对TypeScript的支持更…...

Unity3D URP 自定义范围的特效热扭曲详解
前言 Unity3D URP(Universal Render Pipeline)是Unity官方推出的一款渲染管线,可以实现高效、高质量的图形渲染。在URP中,我们可以通过自定义特效来增强游戏的视觉效果。本文将详细解释如何使用URP实现一个自定义范围的特效热扭曲…...

Apache Flink(一):Apache Flink是什么?
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录...

Wordpress自动定时发布怎么开通-Wordpress怎么自动发布原创文章
在当今数字化时代,博客已经成为许多人分享观点、经验和知识的重要平台。然而,对于博主们来说,每天按时发布一篇又一篇的文章可能是一项具有挑战性的任务。为了解决这个问题,一些创新的工具应运而生,其中包括WordPress的…...
)
VUE项目中问题学习总结(一)
文章目录 🍁自定义组件使用🍁clearInterval函数的使用🌿定时器的作用 🍁localStorage的使用🌿设置数据🌿获取数据🌿更新数据🌿删除数据 🍁VUE国际化配置🍁项目…...

使用K-means把人群分类
1.前言 K-mean 是无监督的聚类算法 算法分类: 2.实现步骤 1.数据加工:把数据转为全数字(比如性别男女,转换为0 和 1) 2.模型训练 fit 3.预测 3.代码 原数据类似这样(source:http:img-blog.csdnimg.cn…...

静态HTTP和动态HTTP有什么区别
静态HTTP是指网页内容在服务器上以静态文件的形式存在,每个页面都是固定的,不能根据用户的操作或输入进行改变。当用户请求一个静态页面时,服务器直接将页面的HTML代码返回给用户的浏览器进行显示。静态HTTP服务器的主要优点是速度快、简单易…...

分享66个在线客服JS特效,总有一款适合您
分享66个在线客服JS特效,总有一款适合您 66个在线客服JS特效下载 链接:https://pan.baidu.com/s/1VqM6ASgKRFdQ8RyzbsX4uA?pwd6666 提取码:6666 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气࿰…...

Backend - Django JsonResponse HttpResponse
目录 一、关系 二、使用 (一)data 字典传值 1. JsonResponse 2. HttpResponse 3. 例子 (二)JsonResponse 有一个 safe 参数 (三)前端接收 1. 接收 JsonResponse 回传的值 2. 接收 HttpResponse 回…...

第四阶|自在行草 暄桐教室,林曦书法 从书法之美到生活之美
我这有很多的课程,需要了可以取用 新一期(入门课),目前已经更新完毕。 新一期(第一阶),目前已经更新完毕。 新一期(第二阶),目前已经更新完毕。 新一期&#…...

kubernetes详解——从入门到入土(更新中~)
k8s简介 编排工具:系统层面ansible、saltstackdocker容器docker compose docker swarm docker machinedocker compose:实现单机容器编排docker swarm:实现多主机整合成为一个docker machine:初始化新主机mesos marathonmesos …...
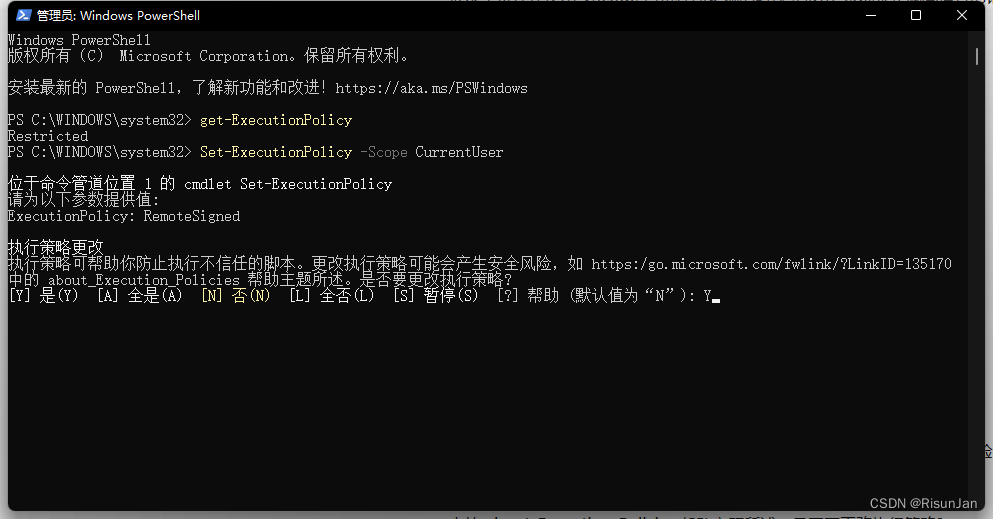
VScode异常处理 (因为在此系统上禁止运行脚本)
在使用 VScode 自带程序终端的时候会报出"系统禁止脚本运行的错误" 这是由于 Windows PowerShell执行策略导致的 解决办法 管理员身份运行 Windows PowerShell执行:get-ExecutionPolicy1,显示Restricted2执行:Set-ExecutionPoli…...

(5h)Unity3D快速入门之Roll-A-Ball游戏开发
DAY1:Unity3D安装 链接 DAY2:构建场景,编写代码 链接 内容:WASD前后左右移动、摄像机跟随 DAY3:待更新 DAY4:待更新 DAY5:待更新...

分享86个选项卡TABJS特效,总有一款适合您
分享86个选项卡TABJS特效,总有一款适合您 86个选项卡TABJS特效下载链接:https://pan.baidu.com/s/1NBtPP2tT5YQqi6c744tCqg?pwd6666 提取码:6666 Python采集代码下载链接:采集代码.zip - 蓝奏云 学习知识费力气࿰…...
【Linux】Linux基础
文章目录 学习目标操作系统不同应用领域的主流操作系统虚拟机 Linux系统的发展史Linux内核版和发行版 Linux系统下的文件和目录结构单用户操作系统vs多用户操作系统Windows和Linux文件系统区别 Linux终端命令格式终端命令格式查阅命令帮助信息 常用命令显示文件和目录切换工作目…...

动态规划求解 fibonacci 数列
动态规划: 动态规划的基本思想是:将原问题拆分为若干子问题,自底向上的求解。是自底向上的求解,即是先计算子问题的解,再得出原问题的解。 思路: 创建一个数组,大小为n1,用于存储斐波那契数列的值。数组的…...

js最大公约数的实现有哪些办法
在JavaScript中,有几种常见的方法可以实现最大公约数(GCD)的计算。以下是其中一些方法: 辗转相除法(欧几里德算法): 辗转相除法是一种基于递归的算法,用于计算两个数的最大公约数。它…...

春联生成模型在网络安全领域的创新应用
春联生成模型在网络安全领域的创新应用 1. 引言 春节贴春联是传统习俗,但你可能没想到,生成春联的AI模型还能在网络安全领域大显身手。随着网络威胁日益复杂,传统的安全提示和警示方式往往显得生硬枯燥,用户容易忽略重要信息。而…...

罗技PUBG压枪宏技术指南:从弹道控制到参数优化的实战方案
罗技PUBG压枪宏技术指南:从弹道控制到参数优化的实战方案 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 绝地求生(PUBG&…...

达梦PAI P系列实战:如何为金融核心系统部署国产数据库一体机
达梦PAI P系列金融级部署实战:从架构设计到性能调优的全链路指南 在金融数字化转型的深水区,核心业务系统的数据库选型正面临前所未有的挑战。某全国性商业银行的科技负责人曾向我透露,他们在2022年数据库升级项目中做过一次压力测试…...

Phi-3-vision-128k-instruct效果实测:128K长上下文下的跨图逻辑推理能力
Phi-3-vision-128k-instruct效果实测:128K长上下文下的跨图逻辑推理能力 1. 模型概述 Phi-3-Vision-128K-Instruct是当前最先进的轻量级开放多模态模型,属于Phi-3模型家族的最新成员。这个模型最引人注目的特点是支持128K的超长上下文窗口,…...

国内OpenClaw玩家圈共识:智创聚合API才是真香选择
你是否也曾对OpenClaw(龙虾)的强大能力心动不已,却在部署第一步——配置AI大模型时望而却步?直接使用官方API,高昂的Token费用让人肉疼;尝试部署本地开源模型,繁琐的技术门槛又令人头疼。但在国…...

Python 免费开源库精选:那些“不要钱”却“值千金”的神器
⚠️ 再次长文预警!前方是“免费开源”的宝藏海洋!⚠️📢 写在前面(老规矩): 嘿,朋友!既然你看到了这里,说明你对 Python 的**“免费午餐”很感兴趣!…...

前端面试基础知识整理【Day-11】
前言 前端面试基础知识整理【Day-1】-CSDN博客 前端面试基础知识整理【Day-2】-CSDN博客 前端面试基础知识整理【Day-3】-CSDN博客 前端面试基础知识整理【Day-4】-CSDN博客 前端面试基础知识整理【Day-5】-CSDN博客 前端面试基础知识整理【Day-6】-CSDN博客 前端面试基…...

064远程教育网站系统-springboot+vue
文末领取项目源码springbootvue 1.登录2.注册3.首页请文末卡片dd我获取源码...

Gatt社区贡献指南:如何参与开源项目并提交PR
Gatt社区贡献指南:如何参与开源项目并提交PR 【免费下载链接】gatt Gatt is a Go package for building Bluetooth Low Energy peripherals 项目地址: https://gitcode.com/gh_mirrors/ga/gatt Gatt是一个用于构建蓝牙低功耗(BLE)外设…...

Lilith窗口管理器实战:终端模拟器与文件管理器使用教程
Lilith窗口管理器实战:终端模拟器与文件管理器使用教程 【免费下载链接】lilith x86-64 os made in crystal 项目地址: https://gitcode.com/gh_mirrors/li/lilith Lilith是一款基于Crystal语言开发的x86-64操作系统,其内置的窗口管理器提供了简洁…...