Elasticsearch教程(19) 详解mapping之keyword
Elasticsearch已升级,新版Elasticsearch keyword博客参考下面这篇【Elasticsearch教程8】Mapping字段类型之keyword_elasticsearch的keyword_亚瑟弹琴的博客-CSDN博客
1 前言
本文基于ES7.6,如果是之前版本,是有区别的。
ES支持的字段类型很多,但工作中常用的也就那些核心字段。 一开始学习ES时,掌握好常用的类型,不必要精通每一种,如果工作中遇到了需要用到特殊类型再去研究。
学习一门技术要先广度后深度,不能陷入”只见树木,不见森林“。
2 核心类型
2.1 关键词:keyword
keyword类型通常存储结构性数据,而不是毫无规律可言的文本信息。
2.1.1 适合用keyword的例子
场景 值
订单状态的枚举值 1:未付款;2:已付款;3:申请退款;4:已退款
HTTP状态码 200;400;500;404
手机号/邮箱/性别 对手机号没必要分词,也不需要数学计算,所以也不能设为数字类型
用户画像标签 学生,IT男,屌丝女,孕妈,社会中产
2.1.2 说明
ES把keyword类型的值当作词根存在倒排索引中,不进行分词。
keyword适合存结构化数据,比如name,age,性别,手机号,status(数据状态),tags(标签),HttpCode(404,200,500)等。
字段常用来精确查询,过滤,排序,聚合时,应设为keyword,而不是数值型。
如果某个字段你经常用来做range查询, 你还是设置为数值型(integer,long),ES对数字的range有优化。
还可以把字段设为multi-field,这样又有keyword类型又有数值类型, 方便各个方式的使用。
最长支持32766个UTF-8类型的字符,但放入倒排索引时,只截取前一段字符串,长度由ignore_above参数决定。
2.1.3 实验
(1)创建一个文档
PUT /pigg_user/_doc/1
{
"name": "冬哥",
"age": 32
}
(2)查询数据
GET /pigg_user/_doc/1/_source
#返回结果如下,说明插入成功:
{
"name" : "冬哥",
"age" : 32
}
1
2
3
4
5
6
7
(3)查询name="冬哥"的数据
GET /pigg_user/_search
{
"query": {
"term": {
"name": "冬哥"
}
}
}
#返回结果如下,居然没有搜索到???
{
...省略其它信息...
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
(4)查看文档的mapping
要想探知没有搜到的原因,得先看排查文档的mapping。
发现name是text类型,其下面有一个keyword子类型。
GET /pigg_user/_mapping
#返回如下
{
"pigg_user" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : { #这行的keyword是字段名,全称是name.keyword
"type" : "keyword", #这行的keyword是指类型
"ignore_above" : 256 #这里的ignore_above下面会讲
}
}
}
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
(5)分析原因
如果不设置mapping,ES默认把字符串设为text类型,并包含一个keyword子类型。
name是text类型,“冬哥”这个词已经被拆成“冬”和“哥”这2个词项。
所以上面用term来匹配“冬哥”时,查询不到数据。
简单理解:
“name”这个字段按照“冬”和“哥”2个词存的,根据“冬”或者“哥”都能term查询到文档。
“name.keyword”这个字段存储的是“冬哥”这完整字符串。
#根据name匹配“冬”,可以查询到文档
GET /pigg_user/_search
{
"query": {
"term": {
"name": "冬"
}
}
}
#根据name.keyword匹配"冬哥",可以查询到文档
GET /pigg_user/_search
{
"query": {
"term": {
"name.keyword": "冬哥"
}
}
}
#根据name.keyword匹配"冬",查询不到文档
GET /pigg_user/_search
{
"query": {
"term": {
"name.keyword": "冬"
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2.1.4 手动设置mapping
#先删除之前创建的index
DELETE pigg_user
#设置name为keyword,age为short。
PUT pigg_user
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "short"
}
}
}
}
#新增一个文档
PUT /pigg_user/_doc/1
{
"name": "冬哥",
"age": 32
}
#根据name精确匹配,可以查到数据
GET /pigg_user/_search
{
"query": {
"term": {
"name": "冬哥"
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
2.1.5 ignore_above是什么?
首先随意往ES插一条数据:
put my_index/_doc/1
{
"name": "李星云"
}
1
2
3
4
查看ES自动生成的mapping,name是text类型,其下还有子类型keyword,且"ignore_above" : 256
GET /my_index/_mapping
name定义如下:
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
对于keyword类型, 可设置ignore_above限定字符长度。超过 ignore_above 的字符会被存储,但不会被倒排索引。比如ignore_above=4,”abc“,”abcd“,”abcde“都能存进ES,但是不能根据”abcde“检索到数据。
【1】创建一个keyword类型的字段,ignore_above=4
PUT test_index
{
"mappings": {
"_doc": {
"properties": {
"message": {
"type": "keyword",
"ignore_above": 4
}
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
【2】向索引插入3条数据:
PUT /test_index/_doc/1
{
"message": "abc"
}
PUT /test_index/_doc/2
{
"message": "abcd"
}
PUT /test_index/_doc/3
{
"message": "abcde"
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
此时ES倒排索引是:
词项 文档ID
abc 1
abcd 2
【3】根据message进行terms聚合:
GET /test_index/_search
{
"size": 0,
"aggs": {
"term_message": {
"terms": {
"field": "message",
"size": 10
}
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
返回结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"message" : "abcd"
}
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"message" : "abc"
}
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"message" : "abcde"
}
}
]
},
"aggregations" : {
"term_message" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [#注意这分组里没有”abcde“
{
"key" : "abc",
"doc_count" : 1
},
{
"key" : "abcd",
"doc_count" : 1
}
]
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
【4】根据”abcde“进行term精确查询,结果为空
GET /test_index/_search
{
"query": {
"term": {
"message": "abcde"
}
}
}
然后结果:
"hits" : {
"total" : 0,
"max_score" : null,
"hits" : [ ]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
通过上面结果能知道”abcde“已经存入ES,也可以搜索出来,但是不存在词项”abcde“,不能根据”abcde“作为词项进行检索。
对于已存在的keyword字段,其ignore_above子属性可以修改,但只对新数据有效。
————————————————
版权声明:本文为CSDN博主「亚瑟弹琴」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/winterking3/article/details/108254346
相关文章:
 详解mapping之keyword)
Elasticsearch教程(19) 详解mapping之keyword
Elasticsearch已升级,新版Elasticsearch keyword博客参考下面这篇【Elasticsearch教程8】Mapping字段类型之keyword_elasticsearch的keyword_亚瑟弹琴的博客-CSDN博客 1 前言 本文基于ES7.6,如果是之前版本,是有区别的。 ES支持的字段类型很…...
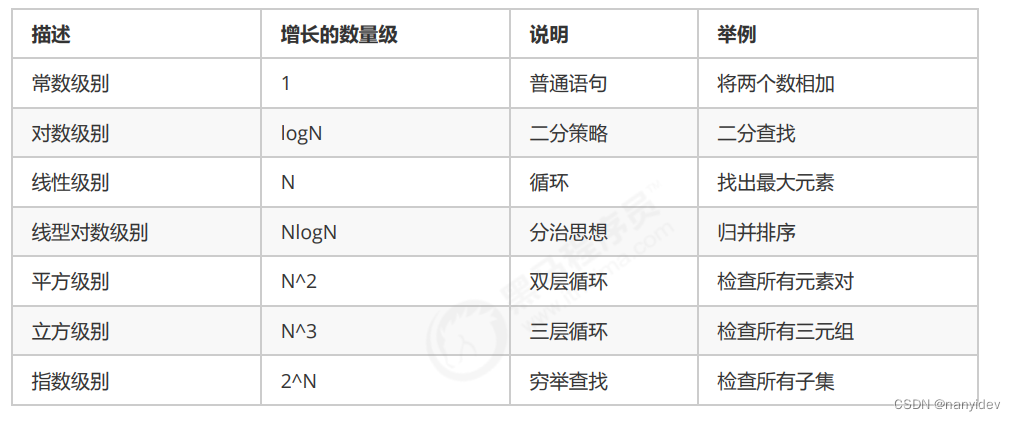
LeetCode算法复杂度分析(时间复杂度空间复杂度)
文章目录前言时间复杂度1.概述2.大O记法3.常见类型空间复杂度1.概述2.常见类型典型算法的复杂度分析1.递归算法2.哈希表前言 我们知道,研究算法的最终目的就是如何花更少的时间,如何占用更少的内存去完成相同的需求。 时间复杂度 1.概述 我们要计算算…...
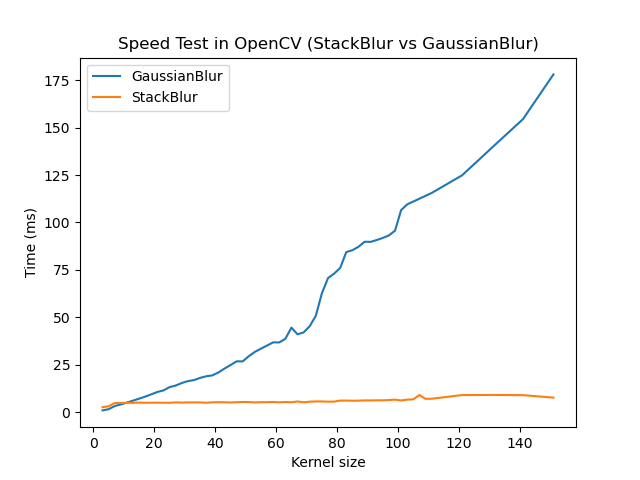
Android OpenCV(七十三):吊打高斯模糊的StackBlur Android 实践
前言 OpenCV 4.7.0 2022年12月28日Release,ChangeLog中提到 Stackblur algorithm implementation. Stackblur是一种高斯模糊的快速近似,由Mario Klingemann发明。其计算耗时不会随着kernel size的增大而增加,专为大kernel size的模糊滤波场景量身定制。 使用建议:当kerne…...

4.排序算法之一:冒泡排序
排序算法稳定性假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]r[j],且r[i]在r[j]之前,而在排序后的序列中,r[…...

python自学之《21天学通Python》(16)——第19章 用Pillow库处理图片
Pillow是Python2.X时代比较流行的Python ImagingLibrary(简称Pillow)图像处理库的分支,并修复了一些bug。Pillow提供了对Python3的支持,为Python3解释器提供了图像处理的功能。和Pillow库一样提供了广泛的文件格式支持、高效的内部…...
发布依赖到maven仓库
maven中央仓库是一个开放的仓库,所以我们也可以把自己开发的jar推送到远程仓库,这样可以直接引入pom依赖使用我们的库。 准备工作 ● 需要一个github账号(程序员必备) ● 网络代理(涉及到的网站通常没版本在国内直接访…...
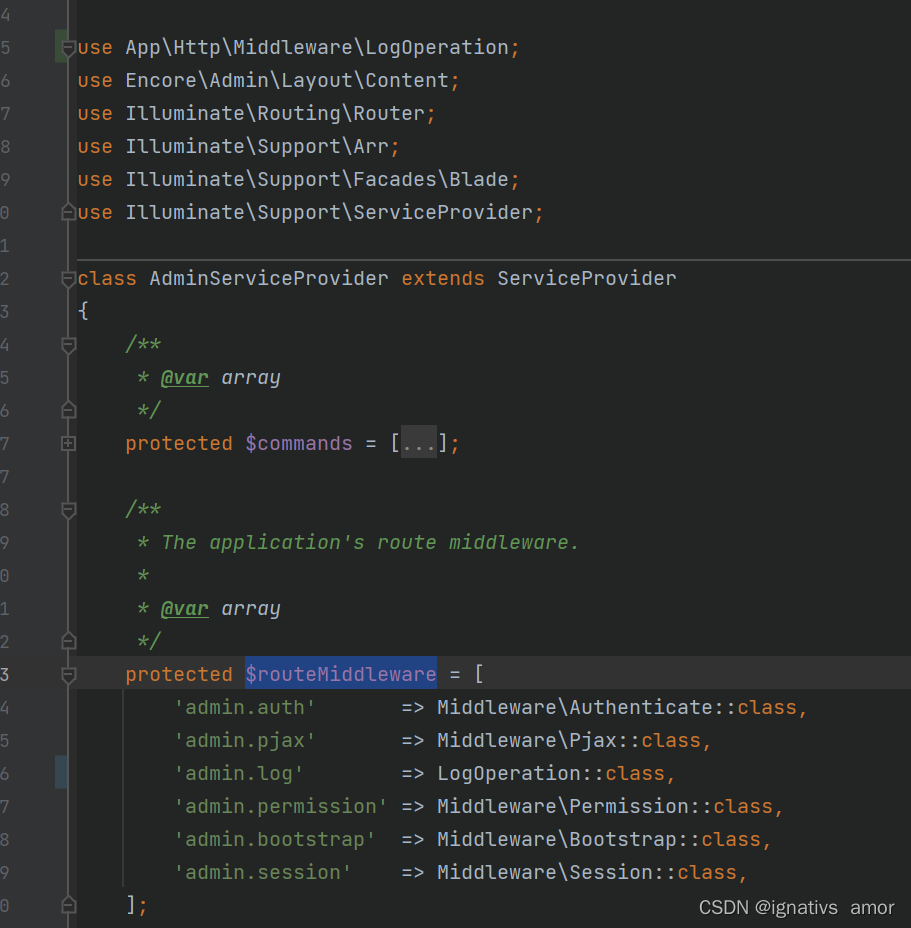
Laravel-admin之自定义操作日志
laravel-admin是封装性极好的框架,自带的就有操作日志的记录,但是对于非开发人员可能看不懂这个日志,所以就想着给修改一下,以谁修改了什么,谁删除了什么,谁审核了什么,谁添加了什么类似&#x…...

用Python做了一个法律查询小工具,非常好用
用Python做了一个法律查询小工具,非常好用效果展示准备工作不会的话可以点我直达代码和视频讲解,我都准备好了主要代码哈喽兄弟,今天给大家分享一个Python tkinter制作法律查询小工具。 光爬虫大家也只能自己用用,就算打包了exe&…...
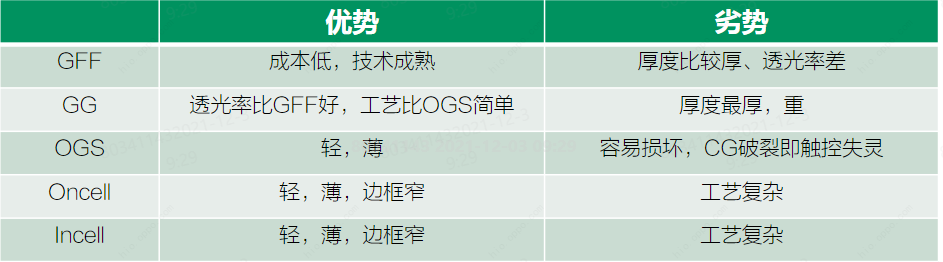
工作篇:触摸屏原理介绍
一、触摸屏概述 触摸屏作为一种新的输入设备,它是目前最简单、方便、自然的一种人机交互方式。 当接触了屏幕上的图形按钮时,屏幕上的触觉反馈系统可根据预先编程的程式驱动各种连结装置,可用以取代机械式的按钮面板,并借由液晶…...
Ep_操作系统面试题-操作系统的分类
答案 单体系统 整个操作系统是以程序集合来编写的,链接在一块形成一个二进制可执行程序,这种系统称为单体系统。 分层系统 每一层都使用下面的层来执行其功能。 微内核 微内核架构的内核只保留最基本的能力,把一些应用放到了用户空间 客户-…...

iframe或document监听滚动事件不起作用
有时候我们会遇到监听iframe或document的滚动事件不起作用的情况,在排除代码写错的情况下,我们应该考虑此时的document是否可以滑动。 1、为什么document不能监听滑动? 就很奇怪,明明页面时有滚动条的,为什么说document不可滑动…...
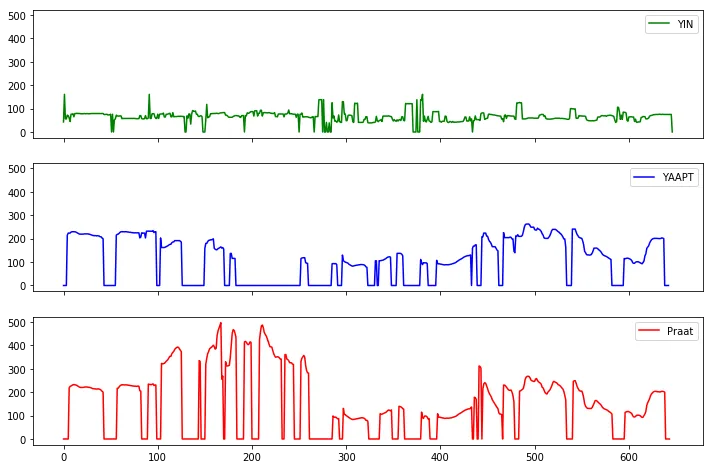
基频估计算法简介
基频估计算法 F0 estimate methods 估计F0的方法可以分为三类:基于时域、基于频域、或混合方法。本文详细介绍了这些方法。 所有的算法都包含如下三个主要步骤: 1.预处理:滤波,加窗分帧等 2.搜寻:可能的基频值F0(候选…...

linux修改DNS 系统版本Kylin V10桌面版
配置DNS在银河麒麟桌面操作系统V10 SP1 中修改DNS信息,直接修改/etc/resolv.conf文件中的DNS信息,不能生效。应该参考如下步骤:一、首先修改 /etc/systemd/resolved.conf文件,在其中添加DNS信息在终端中执行以下命令:s…...

如何使用 AWS Lambda 运行 selenium
借助 AWS Lambda 运行 selenium 来爬取网络数据。 简介 与手动从网站收集数据相比,爬虫可以为我们节省很多时间,对于爬虫的每次请求而言,这相当于 AWS Lambda 的每次函数的运行。 AWS Lambda 是一种将脚本部署到云的简单且价格低廉的服务&…...
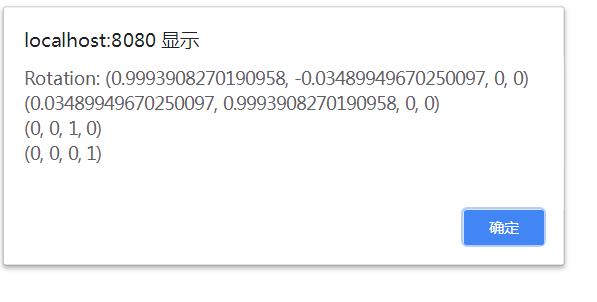
认识Cesium旋转大小变量
前文代码中有如下;矩阵乘以旋转大小,还放入mat; Cesium.Matrix4.multiply(mat, rotationX, mat); 初看以为rotationX是一个数值,因为矩阵可以和数相乘; 但是看它的代码,rotationX是由一长串代码获得的&a…...

异响加持、吐槽声不断,小鹏G9难解困局
小鹏汽车的烦恼就好比红尘中的三千青丝,小鹏G9“惊魂48小时”的恐慌还未平息,车门异响等问题就已经层出不穷,再次将小鹏汽车推上风口浪尖。 可以毫不客气的说,G9承载着小鹏汽车盈利的希望,但在原本处于上升之势的G9却…...

【react】react18的学习
一、安装 $ create-react-app [Project name]默认支持sass 二、核心依赖 react:react 核心 react-dom:用于开发渲染web 应用; react-scripts:封装webpack服务; "start": "react-scripts start&quo…...
Ep_操作系统面试题-什么是线程,线程和进程的区别
1. 一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间),但是每个线程有自己的程序计数器、虚拟机栈和 本地方法栈。 2.进程是资源分配的最小单位,线程是CPU调度的最小单位 视频讲解: https://edu.csdn.net/course/detail/38090 点我…...

最流行的自动化测试工具,总有一款适合你(附部分教程)
前言 在自动化测试领域,自动化工具的核心地位毋庸置疑。本文总结了最顶尖的自动化测试工具和框架,这些工具和框架可以帮助组织更好地定位自己,跟上软件测试的趋势。这份清单包含了开源和商业的自动化测试解决方案。 1)Selenium …...

Shell高级——进程替换vs管道
以下内容源于C语言中文网的学习与整理,如有侵权请告知删除。 1、问题引入 这里将Shell中的“进程替换”与“管道”放在一起讲,是因为两者的作用几乎类似。 进程替换:将一个命令的输出结果传递给另一个(组)命令。 管…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...